YOLO(You Only Look Once)
- [一、YOLOE(Real-Time Seeing Anything):实时感知一切](#一、YOLOE(Real-Time Seeing Anything):实时感知一切)
-
- [1️⃣ 模型概述](#1️⃣ 模型概述)
- [2️⃣ 核心思想](#2️⃣ 核心思想)
- [3️⃣ 模型架构](#3️⃣ 模型架构)
- [4️⃣ 可用模型 + 性能对比](#4️⃣ 可用模型 + 性能对比)
- [5️⃣ 视觉提示分割(VPSeg)](#5️⃣ 视觉提示分割(VPSeg))
- [6️⃣ 使用特点:自动下载预训练权重...](#6️⃣ 使用特点:自动下载预训练权重...)
- 二、函数详解
-
- 1、加载模型:YOLOE()
- 2、模型预测:model.predict()
-
- (1)调参建议
- (2)参数列表
-
- [(1)参考图像:refer_image ------ 具备跨图像迁移能力](#(1)参考图像:refer_image —— 具备跨图像迁移能力)
- (1)视觉提示:visual_prompts
- (2)视觉提示分割预测器:YOLOEVPSegPredictor
- 3、输出结果:results0
- 三、项目实战
-
- 1、环境配置
- 2、下载模型
- 3、模型预测
-
- (1)文本提示:text-prompt
- (2)视觉提示:visual-prompt
-
- [(2.1)UI版本:鼠标交互 + 实时调参(可视化效果)](#(2.1)UI版本:鼠标交互 + 实时调参(可视化效果))
- (2.2)支持完全封闭目标:强依赖参数,不同图像需要精调
- (2.3)不支持不封闭目标:效果差
- (2.4)支持视觉提示的跨图像迁移能力:将当前图像的视觉提示迁移到另一张图像中
-
- 注意点1:视觉提示与输入图像尺度的关系
- [注意点2:(自定义)参考图像的视觉提示 + 模板匹配(不推荐,可忽略)](#注意点2:(自定义)参考图像的视觉提示 + 模板匹配(不推荐,可忽略))
- (3)无提示词:prompt-free
Ultralytics YOLO 生态系统,支持目标检测、实例分割、图像分类、姿态估计和目标跟踪等任务。
一、YOLOE(Real-Time Seeing Anything):实时感知一切
1️⃣ 模型概述
主要特点:
实时性能:即便在中小型 GPU(如 NVIDIA RTX 3060)上,也能实现每秒数十帧的推理速度。
多任务统一:支持检测、分割、分类等任务,减少模型切换和存储成本。
视觉提示增强:可通过 Bounding Box 或 Mask 引导模型关注特定区域,提高小样本或单样本推理精度。
支持三种类型的 prompt:
文本提示 (text prompt):使用自然语言指定对象类别(例如,"人"、"交通灯"、"电动滑板车")
视觉提示 (visual prompt):提供要detect物体的参考图像
内部词汇表 (internal vocabulary):使用 YOLOE 的 1200 多个类别的内置词汇表,无需外部提示。
2️⃣ 核心思想
YOLOE 的设计思路沿袭 YOLO 系列的快速单阶段检测理念,同时结合 Transformer 注意力机制和多尺度特征融合,实现视觉提示条件下的精确分割。
核心思想包括:
特征金字塔与多尺度感知
- 通过特征金字塔网络(FPN)或变体结构(SPP、PAFPN)实现不同尺度目标的高效检测和分割。
- 支持从小目标到大目标的统一处理。
视觉提示条件增强
- 将用户提供的视觉提示(Bounding Box / Mask / Class ID)作为额外条件输入 backbone。
- 在卷积或 Transformer Attention 层对提示区域特征进行加权,抑制背景干扰。
- 提高小样本目标或特殊场景下的检测与分割准确性。
统一输出接口
- 模型输出可同时包含边界框(Bounding Box)、类别概率、分割 mask。
- 对于视觉提示场景,可选择仅返回提示区域相关结果。
轻量化与实时推理
- 提供不同规模模型(S / M / L / v8S / v8M / v8L),权衡速度与精度。
- 支持 ONNX、TensorRT 等多平台加速推理。
3️⃣ 模型架构
YOLOE 架构可分为三个主要模块:
Backbone(特征提取器)
- 支持 CNN 或 Transformer 基础骨干,如 CSPDarknet、Swin Transformer 等。
- 输出多尺度特征图,为检测和分割提供丰富的语义信息。
Neck(特征融合层)
- 采用 FPN / PAN / SPP 结构,将不同尺度特征融合。
- 在视觉提示场景下,通过注意力机制对提示区域进行特征增强。
Head(任务解码器)
- 多分支输出:
- 边界框分支:预测目标位置和尺寸。
- 分类分支:输出目标类别概率。
- Mask 分支(可选):输出像素级分割 mask。
- 对于 VPSeg,Head 会将提示区域特征与全局特征融合,执行条件推理。
4️⃣ 可用模型 + 性能对比
(1)文本/视觉提示模型
以下模型全部支持实例分割 + 推理 + 验证 + 训练 + 导出(详细请看官网介绍)
| 模型类型 | 预训练权重 | 参数量 | 输入尺寸 | 推理速度 (ms/img,GPU) | 推理显存占用 |
|---|---|---|---|---|---|
| YOLOE-11S | yoloe-11s-seg.pt |
13.7M | 640×640 | 10--15 | 1.2 GB |
| YOLOE-11M | yoloe-11m-seg.pt | 46.2M | 640×640 | 20--25 | 2.8 GB |
| YOLOE-11L | yoloe-11l-seg.pt |
88.5M | 640×640 | 35--40 | 5.6 GB |
| YOLOE-v8S | yoloe-v8s-seg.pt | 15.3M | 640×640 | 12--18 | 1.3 GB |
| YOLOE-v8M | yoloe-v8m-seg.pt | 48.7M | 640×640 | 22--28 | 3.0 GB |
| YOLOE-v8L | yoloe-v8l-seg.pt |
92.1M | 640×640 | 38--45 | 5.8 GB |
(2)无提示词模型(Prompt-Free,PF)
以下模型全部支持实例分割 + 推理 + 验证 + 训练 + 导出(详细请看官网介绍)
| 模型类型 | 预训练权重 | 参数量 | 输入尺寸 | 推理速度 (ms/img,GPU) | 推理显存占用 |
|---|---|---|---|---|---|
| YOLOE-11S-PF | yoloe-11s-seg-pf.pt | 13.7M | 640×640 | 9--14 | 1.1 GB |
| YOLOE-11M-PF | yoloe-11m-seg-pf.pt | 46.2M | 640×640 | 19--24 | 2.7 GB |
| YOLOE-11L-PF | yoloe-11l-seg-pf.pt | 88.5M | 640×640 | 34--40 | 5.5 GB |
| YOLOE-v8S-PF | yoloe-v8s-seg-pf.pt | 15.3M | 640×640 | 11--17 | 1.2 GB |
| YOLOE-v8M-PF | yoloe-8m-seg-pf.pt | 48.7M | 640×640 | 21--27 | 2.9 GB |
| YOLOE-v8L-PF | yoloe-8l-seg-pf.pt | 92.1M | 640×640 | 36--44 | 5.7 GB |
5️⃣ 视觉提示分割(VPSeg)
视觉提示分割(Visual Prompt Segmentation,VPSeg):是一种基于图像空间的条件提示机制,通过显式输入矩形框、掩码或类别ID,指示模型关注特定区域或目标,从而提升分割与检测效果。该机制与 NLP 中的提示思想相似,但在计算方式上完全依赖像素坐标
- 输入形式:
Bounding Box(矩形框):标注图像中特定对象的位置。Mask(掩码):标注目标区域的像素级区域。类别ID(Optional):标识目标所属类别,用于增强模型分类能力。- 工作原理:
视觉提示在 YOLO-E 中通过两类机制发挥作用:
特征增强:模型在 backbone 的卷积层或 transformer 层,根据视觉提示对特征图进行加权:提示区域 → 特征增强;非提示区域 → 特征抑制或降权。条件推理:模型会将视觉提示作为条件信息,将其与图像全局特征融合:(1)限定模型的空间搜索范围;(2)约束目标的尺度、类别与区域分布;(3)提升密集场景、小物体或细粒度对象的识别能力。
(1)对不封闭目标,高度敏感
- VPSeg 对不封闭或部分覆盖目标表现明显受限。
- 当提示框只覆盖目标部分区域时:
- 检测精度下降,容易漏检或定位偏差。
- 分割结果不完整,边缘或未覆盖部分效果差,模型尝试推测框外区域但精度有限。
视觉提示是否封闭不是关键,重点是目标本身是否封闭。
(2)对未训练数据,置信度偏低
面对训练集未覆盖的对象或新样本,VPSeg 表现有限:
- 置信度显著降低。
- 检测与分割精度下降,漏检或分割不完整。
- 与训练样本差异越大,影响越明显。
6️⃣ 使用特点:自动下载预训练权重...
- 自动下载预训练权重:首次推理时 YOLOE 会自动从 Ultralytics 仓库下载权重,无需手动管理。
- 统一 API:model.predict() 支持常规分割与视觉提示分割,输入统一格式,输出边界框和 mask。
- 可扩展性强:支持 ONNX、TensorRT 导出,可用于工业推理和嵌入式部署。
- 交互式支持:通过鼠标绘制矩形框或 Mask,可快速生成视觉提示,实现 VPSeg 推理。
二、函数详解
1、加载模型:YOLOE()
python
from ultralytics import YOLOE
model = YOLOE(model_path)| 参数名称 | 类型 | 说明 |
|---|---|---|
model |
str / Path / None | 模型权重路径或模型名称(如yoloe-11s-seg.pt) |
task |
str | 任务类型:detect/segment/pose/classify |
args |
dict | 预设参数字典,可覆盖默认行为 |
2、模型预测:model.predict()
YOLOE 的核心调用接口与 YOLOv8 类似,统一使用:
python
def predict(
self,
source=None,
stream: bool = False,
visual_prompts: dict[str, list] = {},
refer_image=None,
predictor=yolo.yoloe.YOLOEVPDetectPredictor,
**kwargs,
):(1)调参建议
输入分辨率 vs 精度/速度:增大 imgsz 能提升小目标检测,但显存与时间成正比上升。置信度阈值 conf:若目标稀疏且需要高召回,将 conf 降低到 0.1;若需要精确检测,提升到 0.4--0.6。NMS iou:重叠对象多时减小 iou(如 0.45)可避免合并不同实例。视觉提示 visual_prompts:当提示不准确或框偏移太多,模型可能"被误导";给出少量高质量提示优于大量低质量提示。半精度 half 与 AMP:GPU 上启用能显著提速;在显存紧张时尤为重要。流式推理 stream=True:对视频或大批量图像更节省内存,但需要异步处理逻辑。自定义 predictor:若需要特殊后处理(例如基于提示的 mask refine),实现/继承 Predictor 并传入 predictor 参数。调试输出:设置 visualize=True(若实现支持)可以导出中间特征用于诊断;也可使用 verbose=True 查看时间统计。
(2)参数列表
| 参数名 | 类型 | 默认值 | 功能说明 |
|---|---|---|---|
source |
str / path / ndarray / list | None | 输入源,可为文件路径、目录、视频流、摄像头ID、numpy图像、图像列表。 |
refer_image |
str / ndarray / PIL | None | 参考图像,用于跨图像视觉提示(VP / VPSeg)。用于引导模型在目标图像中查找结构相似区域。 |
visual_prompts |
dict | None | 视觉提示,可包含bboxes、masks、cls,用于提示分割/检测。 |
predictor |
class | None | 指定预测器类,例如YOLOEVPSegPredictor等。 |
stream |
bool | False | 以生成器方式逐帧输出结果。 |
conf |
float | 0.25 | 推理后处理的置信度阈值。低于此值的检测将被过滤。 |
iou |
float | 0.7 | NMS的IoU阈值,用于抑制高度重叠框。 |
nms |
bool | True | 启用/关闭非极大值抑制。 |
classes |
list / int | None | 仅保留指定类别ID。 |
agnostic_nms |
bool | False | 忽略类别进行NMS。 |
max_det |
int | 300 | 单张图像的最大检测数。 |
imgsz |
int / tuple | 640 | 推理尺寸,整数或(w,h)。 |
device |
str / int | None | 推理设备,如"0"、"cpu"。 |
half |
bool | None | 是否使用FP16半精度。 |
amp |
bool | True | 启用自动混合精度推理。 |
retina_masks |
bool | False | 提升掩码分辨率(仅分割模型)。 |
show |
bool | False | 弹窗展示推理结果。 |
show_labels |
bool | True | 是否在可视化中绘制类别。 |
show_conf |
bool | True | 是否在可视化中绘制置信度。 |
line_thickness |
int | 3 | 绘制边界框线宽。 |
save |
bool | False | 保存可视化图像。 |
save_txt |
bool | False | 保存检测框文本信息。 |
save_conf |
bool | False | 将置信度写入txt结果中。 |
save_crop |
bool | False | 保存裁剪出的目标图像。 |
project |
str | "runs/predict" | 输出根目录。 |
name |
str | "exp" | 输出子目录名称。 |
exist_ok |
bool | False | 目录已存在时是否覆盖。 |
visualize |
bool | False | 导出模型内部特征图。 |
vid_stride |
int | 1 | 视频抽帧步长。 |
verbose |
bool | True | 是否打印推理信息。 |
stream_output_format |
str | None | 流式输出的格式选择。 |
extra_kwargs |
dict | --- | 扩展字段,用于未来扩展,如keep_images等。 |
(1)参考图像:refer_image ------ 具备跨图像迁移能力
refer_image 是整个 YOLOE-VP 系统中的查询源(Query Source),而 visual_prompts 是查询约束(Query Constraint)。
refer_image:用于将参考图像的提示(bbox、mask、类别) 传递到目标图像的推理过程,使得模型能利用先验信息进行更稳定的定位与分割。用于跨图像提示、跨图像分割、跟踪式检测增强等任务。典型用途:
- 从参考图像中取得提示(如参考框、参考掩码)→ 在目标图像中查找相同目标
- 跨帧跟踪、跨视角匹配
- 通过参考图作为"Query"增强实例理解(Meta-Attention)
(1)视觉提示:visual_prompts
YOLOEVPSegPredictor 会将提示传入解码器,提升分割定位精度。
python
# visual_prompts 完整字段
visual_prompts = dict(
bboxes=np.array([[x1, y1, x2, y2], ...]), # 提示框坐标 (N,4)
cls=np.array([class_id, ...]), # 提示框对应类别 ID (N,)
masks=np.ndarray([...]), # 二值掩膜提示 (N,H,W)
points=np.array([[x1, y1], [x2, y2], ...]), # 点提示坐标 (K,2)
point_labels=np.array([1,0,...]), # 点标签:1=正样本,0=负样本 (K,)
scores=np.array([...]), # 提示置信度权重 (N,)
texts=[...], # 文本语义提示列表 (N)
embed=np.ndarray([...]) # 自定义嵌入向量 (D,) 或 (N,D)
)
# 示例代码
visual_prompts = dict(
bboxes=np.array([[320,240,480,480]]), # 一个目标框
cls=np.array([0]), # 类别 ID 0
masks=np.random.randint(0,2,(1,256,256)), # 随机掩膜示例
points=np.array([[350,300],[370,330]]), # 两个点提示
point_labels=np.array([1,0]), # 第一个点正样本,第二个点负样本
scores=np.array([1.0]), # 提示权重 1.0
texts=["target region"], # 文本提示
embed=np.random.rand(1,512) # 随机嵌入向量示例
)参数建议
bboxes + cls:适合快速跨图像迁移或目标定位。bbox 尺寸过小可能导致匹配失败;过大可能引入背景干扰。- 增强分割精度:增加 masks,提升不封闭目标、弱纹理目标的分割效果。
- 精细控制:使用
points + point_labels对模型注意力进行微调。对复杂场景可增加 scores 权重区分重要性。points 建议均匀分布在目标区域,正负点平衡。- 跨模态/高级场景:可增加 texts 或 embed,用于多图像特征对齐或语义驱动分割。
| 参数名 | 类型 | 形状要求 | 说明 | 典型用途 |
|---|---|---|---|---|
| bboxes | ndarray | (N,4) |
每个视觉提示框坐标 [x1, y1, x2, y2] |
强提示目标区域、跨图像匹配后进行提示迁移 |
| cls | ndarray | (N,) |
每个提示框的类别 ID | 强制模型按指定类别解释提示区域 |
| masks | ndarray | (N,H,W) |
二值掩膜提示 | 适用于弱纹理、开口轮廓、边界模糊目标 |
| points | ndarray | (K,2) |
点提示坐标 [x,y] |
类似 SAM 的正/负提示点机制 |
| point_labels | ndarray | (K,) |
点标签:1=正样本、0=负样本 |
指示哪些点属于目标、哪些点属于背景 |
| scores | ndarray | (N,) |
提示置信度权重 | 控制提示对最终输出影响力度 |
| texts | liststr | N |
文本语义提示 | 类似 CLIP,支持"指令式分割" |
| embed | ndarray | (D,) 或 (N,D) |
自定义特征向量提示 | 高级用法,用于冻结 Encoder 时代替文本提示 |
(2)视觉提示分割预测器:YOLOEVPSegPredictor
YOLOE 默认 Predictor 不支持 VPSeg,要启用 VPSeg 必须指定:
python
from ultralytics.models.yolo.yoloe import YOLOEVPSegPredictor
results = model.predict(
source=
predictor=YOLOEVPSegPredictor,
)可调内部参数:
| 参数 | 说明 |
|---|---|
visual_prompt_encoder |
构建提示编码器 |
vp_dropout |
提示编码器 dropout |
vp_fusion |
提示特征与主特征融合策略 |
mask_postprocess |
mask后处理开关 |
box_refine |
结合提示框的边界优化 |
虽然大部分内部参数不能在 API 层直接设置,但理解结构有利于调参。
3、输出结果:results0
YOLOE 的推理结果通常为 results0,代表一张图像的检测/分割/关键点输出结构。
python
results = model.predict(...)
r = results[0](1)results0 字段总览
| 字段名 | 类型 | 典型形状 | 含义 | 说明 / 用途 |
|---|---|---|---|---|
boxes |
ultralytics.engine.results.Boxes |
N×(4+1+1) | 检测框对象 | 内部含 xyxy、conf、cls 等 |
masks |
ultralytics.engine.results.Masks or None |
N×H×W | 分割掩码 | 分割任务时存在 |
keypoints |
ultralytics.engine.results.Keypoints or None |
N×K×2/3 | 关键点 | 姿态任务时存在 |
probs |
Tensor or None | C | 分类置信度 | 分类任务输出 |
speed |
dict | --- | 推理速度统计(ms) | preprocess/inference/postprocess |
orig_img |
ndarray | H×W×3 | 原图 | 处理前的图像 |
path |
str | --- | 原图路径 | 文件名或流名称 |
names |
dictint,str | --- | 类别映射表 | class_id → class_name |
orig_shape |
tuple | (H,W) | 原始尺寸 | 未 resize 前尺寸 |
boxes.xyxy |
ndarray | N×4 | 左上→右下框 | [x1,y1,x2,y2] |
boxes.xywh |
ndarray | N×4 | 中心点框 | [cx,cy,w,h] |
boxes.conf |
ndarray | N | 置信度 | 0--1 |
boxes.cls |
ndarray | N | 类别索引 | int |
masks.data |
ndarray | N×H×W | 二值掩码 | 0/1 |
keypoints.data |
ndarray | N×K×2/3 | 坐标+可见性 | K 取决于模型 |
(2)Boxes(检测框)字段
results[0].boxes 是检测框对象,内部字段如下:
| 字段 | 类型 | 形状 | 说明 |
|---|---|---|---|
boxes.data |
Tensor(N,6) | (x1,y1,x2,y2,conf,cls) | 框总数据 |
boxes.xyxy |
ndarray(N,4) | 左上→右下格式 | 通用检测格式 |
boxes.xywh |
ndarray(N,4) | 中心点格式 | [cx,cy,w,h] |
boxes.conf |
ndarray(N) | 框置信度 | 模型输出 |
boxes.cls |
ndarray(N) | 类别索引 | 需用 names 反查 |
boxes.id |
ndarray(N) or None | 跟踪ID | 仅跟踪任务提供 |
boxes.orig_shape |
tuple | 原始图尺寸 | 用于框映射回原图 |
boxes.is_track |
bool | --- | 指示是否为跟踪框 |
(3)Masks(分割掩码)字段
results[0].masks 仅在分割模型中存在:
| 字段 | 类型 | 形状 | 说明 |
|---|---|---|---|
masks.data |
ndarray(N,H,W) | 二值掩码 | N 个对象的掩码 |
masks.segments |
listlist | 多边形点集 | COCO 格式多边形 |
masks.xyn |
listlist | 归一化多边形 | 适合保存与标注 |
masks.orig_shape |
tuple | (H,W) | 原图尺寸 |
(4)Keypoints(人体关键点)字段详解
| 字段 | 类型 | 形状 | 说明 |
|---|---|---|---|
keypoints.data |
ndarray(N,K,2/3) | 关键点坐标 | x,y,(可见性) |
keypoints.xy |
ndarray(N,K,2) | 像素坐标 | 去掉置信度 |
keypoints.conf |
ndarray(N,K) | 关键点置信度 | K 取决于模型 |
keypoints.orig_shape |
tuple | 原图尺寸 | --- |
(5)probs(分类任务)
分类模型的结果:
| 字段 | 类型 | 说明 |
|---|---|---|
probs.data |
Tensor© | 每类概率 |
probs.top1 |
int | 概率最高类别 |
probs.top1conf |
float | 最高概率 |
probs.names |
dict | 类别名称映射 |
(6)speed(推理性能信息)
| 字段 | 类型 | 单位 | 说明 |
|---|---|---|---|
speed['preprocess'] |
float | ms | 预处理耗时 |
speed['inference'] |
float | ms | 模型推理时间 |
speed['postprocess'] |
float | ms | NMS 等后处理 |
(7)图像信息
| 字段 | 类型 | 说明 |
|---|---|---|
orig_img |
ndarray(H,W,3) | 原始输入图像 |
orig_shape |
tuple(H,W) | 原始尺寸 |
path |
str | 文件路径或流标识 |
names |
dict | 类别名称映射 |
三、项目实战
1、环境配置
python
# 创建虚拟环境
conda create -n yoloe_env python=3.10 -y
conda activate yoloe_env
################################################################################
# 安装PyTorch
pip install torch torchvision --index-url https://download.pytorch.org/whl/cu121
pip install torch torchvision --index-url https://download.pytorch.org/whl/cpu
################################################################################
# 安装Ultralytics(清华源)
pip install --upgrade ultralytics -i https://pypi.tuna.tsinghua.edu.cn/simple
# 其他依赖(清华源)
pip install numpy opencv-python matplotlib -i https://pypi.tuna.tsinghua.edu.cn/simple2、下载模型
Ultralytics YOLO框架会自动从该存储库下载所需的预训练模型(如果本地未找到)。
自动下载过程特点:
- 无需额外配置;
- 默认从Ultralytics官方Hub下载;
- 权重下载一次后会缓存,后续加载速度快;
- 若指定自定义训练的本地权重路径,则不会触发下载。
YOLOE 模型权重托管在 GitHub 的 ultralytics/assets 仓库。手动下载过程(速度更快):
- 进入:https://github.com/ultralytics/assets/releases,在搜索框输入:
yoloe-11s-seg.pt- 下载该文件后,放到你的工作目录,例如:
D:\yoloe\yoloe-11s-seg.pt- 然后代码中:
model = YOLOE("yoloe-11s-seg.pt")- 即可直接运行。
3、模型预测
(1)文本提示:text-prompt
https://docs.ultralytics.com/zh/models/yoloe/#text-prompt
文本提示允许您通过文字描述指定要detect 的类别。下面的代码展示了如何使用 YOLOEdetect 图像中的人和公共汽车:
python
from ultralytics import YOLOE
# Initialize a YOLOE model
model = YOLOE("yoloe-11l-seg.pt") # or select yoloe-11s/m-seg.pt for different sizes
# Set text prompt to detect person and bus. You only need to do this once after you load the model.
names = ["person", "bus"]
model.set_classes(names, model.get_text_pe(names))
# Run detection on the given image
results = model.predict("path/to/image.jpg")
# Show results
results[0].show()(2)视觉提示:visual-prompt
https://docs.ultralytics.com/zh/models/yoloe/#visual-prompt
通过展示目标类别的视觉示例(而不是用文字描述),视觉提示允许您引导模型。
字段 visual_prompts 参数,该参数接受一个包含两个键的字典: bboxes 和 cls。中的每个边界框 bboxes 中的相应条目。 cls 指定该框的类别标签。这种配对告诉模型,"这就是 X 类的样子------现在找到更多类似的。"
类别 ID (cls)在 visual_prompts 用于将每个边界框与提示中的特定类别相关联。它们不是固定的标签,而是您分配给每个示例的临时标识符。唯一的要求是类 ID 必须是连续的,从 0 开始。这有助于模型正确地将每个框与其相应的类相关联。
您可以直接在要运行推理的同一图像中提供视觉提示。例如:
python
import numpy as np
from ultralytics import YOLOE
from ultralytics.models.yolo.yoloe import YOLOEVPSegPredictor
# Initialize a YOLOE model
model = YOLOE("yoloe-11l-seg.pt")
# Define visual prompts using bounding boxes and their corresponding class IDs.
# Each box highlights an example of the object you want the model to detect.
visual_prompts = dict(
bboxes=np.array(
[
[221.52, 405.8, 344.98, 857.54], # Box enclosing person
[120, 425, 160, 445], # Box enclosing glasses
],
),
cls=np.array(
[
0, # ID to be assigned for person
1, # ID to be assigned for glassses
]
),
)
# Run inference on an image, using the provided visual prompts as guidance
results = model.predict(
"ultralytics/assets/bus.jpg",
visual_prompts=visual_prompts,
predictor=YOLOEVPSegPredictor,
)
# Show results
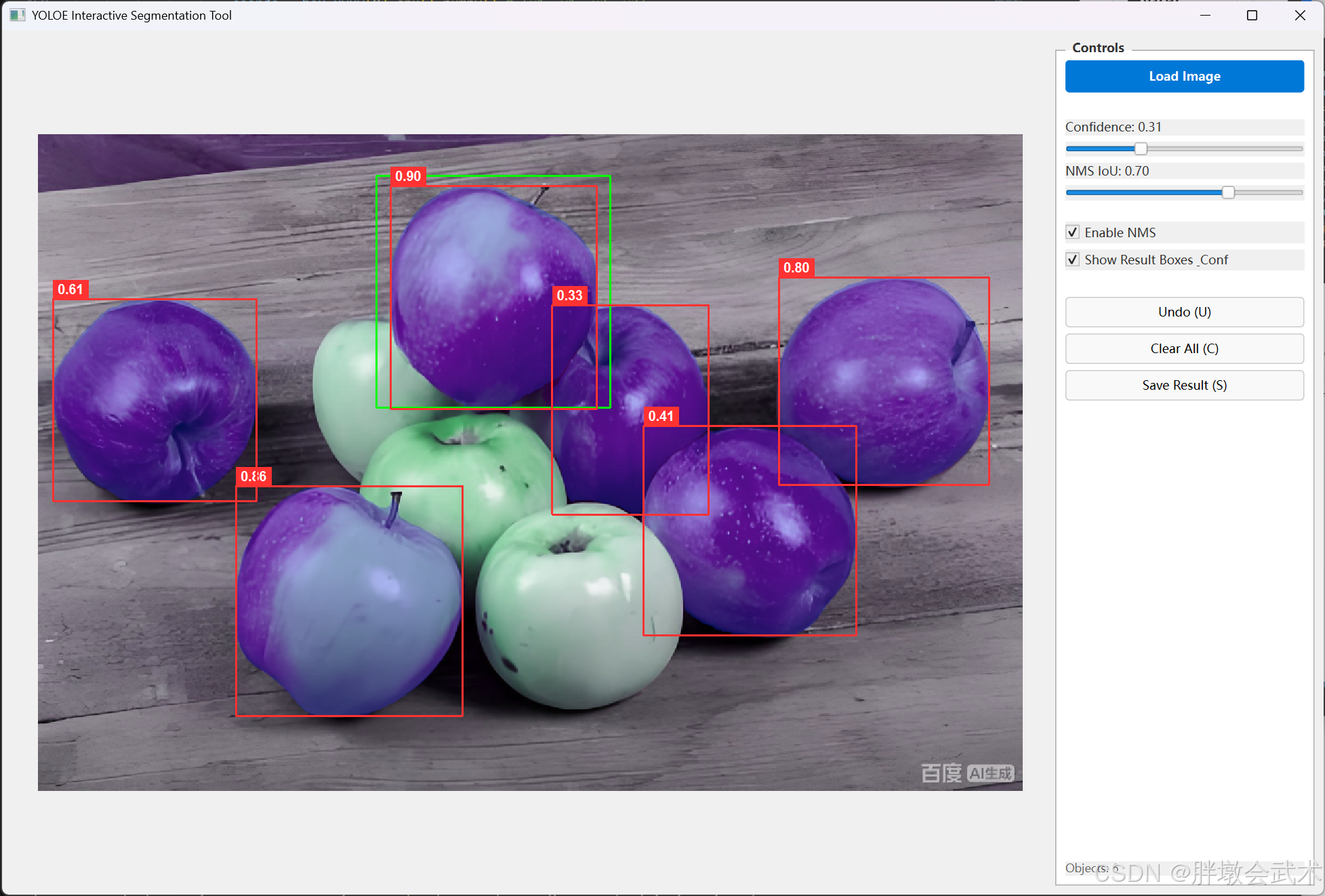
results[0].show()(2.1)UI版本:鼠标交互 + 实时调参(可视化效果)
检测结果:
(1)与模型本身的性能有关
(2)与视觉提示(矩形框)有很大关系,矩形框影响置信度!
(3)视觉提示支持多个矩形框输入,用于增强匹配精度!
python
import sys
import cv2
import numpy as np
from PyQt6.QtWidgets import (QApplication, QMainWindow, QWidget, QVBoxLayout,
QHBoxLayout, QPushButton, QLabel, QSlider,
QFileDialog, QCheckBox, QGroupBox, QSizePolicy)
from PyQt6.QtCore import Qt, QRect, QTimer, pyqtSignal
from PyQt6.QtGui import QImage, QPixmap, QPainter, QPen, QColor, QFont, QFontMetrics
from ultralytics import YOLOE
# 尝试导入 VPSegPredictor
try:
from ultralytics.models.yolo.yoloe import YOLOEVPSegPredictor
except ImportError:
YOLOEVPSegPredictor = None
class ImageCanvas(QWidget):
"""
自定义画布组件:改为继承 QWidget 以解决 Label 塌缩和显示异常问题
"""
box_added = pyqtSignal()
def __init__(self, parent=None):
super().__init__(parent)
self.setMouseTracking(True)
# 设置策略为 Expanding,保证没图的时候也占满布局
self.setSizePolicy(QSizePolicy.Policy.Expanding, QSizePolicy.Policy.Expanding)
# 设置黑色背景,看起来更专业
self.setStyleSheet("background-color: #2b2b2b;")
# --- 数据状态 ---
self.img_orig = None # 原始 RGB 图片
self.img_display = None # 显示用的 QPixmap
self.mask_overlay = None # 推理 Mask
self.bboxes = [] # 用户画的提示框 (Green)
self.result_items = [] # 模型预测的结果框和置信度 (Red)
self.current_start = None
self.current_end = None
self.scale_factor = 1.0
self.offset_x = 0 # 图片居中偏移量
self.offset_y = 0
# --- 显示控制 ---
self.show_results = True # 是否显示预测框和置信度
def load_image(self, file_path):
img_bgr = cv2.imread(file_path)
if img_bgr is None:
return False
self.img_orig = cv2.cvtColor(img_bgr, cv2.COLOR_BGR2RGB)
self.reset_state()
self.update_display_params()
self.update() # 触发重绘
return True
def reset_state(self):
self.bboxes = []
self.result_items = []
self.mask_overlay = None
self.current_start = None
self.current_end = None
def resizeEvent(self, event):
"""窗口大小改变时,重新计算图片缩放比例"""
if self.img_orig is not None:
self.update_display_params()
super().resizeEvent(event)
def update_display_params(self):
"""计算图片在画布中的居中位置和缩放比例"""
if self.img_orig is None: return
canvas_w = self.width()
canvas_h = self.height()
img_h, img_w = self.img_orig.shape[:2]
# 计算保持比例的缩放因子
scale_w = canvas_w / img_w
scale_h = canvas_h / img_h
self.scale_factor = min(scale_w, scale_h) * 0.95 # 留一点边距
new_w = int(img_w * self.scale_factor)
new_h = int(img_h * self.scale_factor)
# 生成显示用的 Pixmap
resized = cv2.resize(self.img_orig, (new_w, new_h))
bytes_per_line = 3 * new_w
q_img = QImage(resized.data, new_w, new_h, bytes_per_line, QImage.Format.Format_RGB888)
self.img_display = QPixmap.fromImage(q_img)
# 计算居中偏移
self.offset_x = (canvas_w - new_w) // 2
self.offset_y = (canvas_h - new_h) // 2
def set_results(self, mask_img_rgb, boxes_data):
"""
设置推理结果
"""
# 1. Mask
if mask_img_rgb is not None:
h, w = self.img_display.height(), self.img_display.width()
resized = cv2.resize(mask_img_rgb, (w, h))
bytes_per_line = 3 * w
q_img = QImage(resized.data, w, h, bytes_per_line, QImage.Format.Format_RGB888)
self.mask_overlay = QPixmap.fromImage(q_img)
else:
self.mask_overlay = None
# 2. Result Boxes (转换到显示坐标)
self.result_items = []
if boxes_data is not None:
for item in boxes_data:
x1, y1, x2, y2, conf = item
# 坐标变换: 原图 -> 缩放 -> 偏移
sx1 = int(x1 * self.scale_factor) + self.offset_x
sy1 = int(y1 * self.scale_factor) + self.offset_y
sx2 = int(x2 * self.scale_factor) + self.offset_x
sy2 = int(y2 * self.scale_factor) + self.offset_y
self.result_items.append({
'rect': (sx1, sy1, sx2, sy2),
'conf': conf
})
self.update()
def toggle_results_display(self, state):
self.show_results = state
self.update()
# --- 坐标转换辅助 ---
def screen_to_image(self, sx, sy):
"""屏幕坐标 -> 原图坐标"""
ix = int((sx - self.offset_x) / self.scale_factor)
iy = int((sy - self.offset_y) / self.scale_factor)
# 边界检查
h, w = self.img_orig.shape[:2]
ix = max(0, min(w, ix))
iy = max(0, min(h, iy))
return ix, iy
# --- 鼠标事件 ---
def mousePressEvent(self, event):
if self.img_orig is None: return
if event.button() == Qt.MouseButton.LeftButton:
self.current_start = event.pos()
self.current_end = event.pos()
self.update()
def mouseMoveEvent(self, event):
if self.img_orig is None: return
if self.current_start:
self.current_end = event.pos()
self.update()
def mouseReleaseEvent(self, event):
if self.img_orig is None: return
if event.button() == Qt.MouseButton.LeftButton and self.current_start:
self.current_end = event.pos()
# 获取屏幕坐标
sx1, sx2 = min(self.current_start.x(), self.current_end.x()), max(self.current_start.x(), self.current_end.x())
sy1, sy2 = min(self.current_start.y(), self.current_end.y()), max(self.current_start.y(), self.current_end.y())
if (sx2 - sx1) > 5 and (sy2 - sy1) > 5:
# 转换回原图坐标存储
ix1, iy1 = self.screen_to_image(sx1, sy1)
ix2, iy2 = self.screen_to_image(sx2, sy2)
self.bboxes.append((ix1, iy1, ix2, iy2))
self.box_added.emit()
self.current_start = None
self.current_end = None
self.update()
# --- 绘图核心 ---
def paintEvent(self, event):
painter = QPainter(self)
# 1. 绘制空状态提示
if self.img_display is None:
painter.setPen(QColor(150, 150, 150))
painter.setFont(QFont("Arial", 16))
painter.drawText(self.rect(), Qt.AlignmentFlag.AlignCenter, "请加载图片 (Load Image)")
return
# 2. 绘制底图 (居中)
painter.drawPixmap(self.offset_x, self.offset_y, self.img_display)
# 3. Mask 覆盖
if self.mask_overlay:
painter.setOpacity(0.6)
painter.drawPixmap(self.offset_x, self.offset_y, self.mask_overlay)
painter.setOpacity(1.0)
# 4. 绘制用户输入的提示框 (绿色 Green)
pen_prompt = QPen(QColor(0, 255, 0), 2)
painter.setPen(pen_prompt)
painter.setBrush(Qt.BrushStyle.NoBrush)
for box in self.bboxes:
# 原图坐标 -> 屏幕坐标
sx1 = int(box[0] * self.scale_factor) + self.offset_x
sy1 = int(box[1] * self.scale_factor) + self.offset_y
sx2 = int(box[2] * self.scale_factor) + self.offset_x
sy2 = int(box[3] * self.scale_factor) + self.offset_y
painter.drawRect(sx1, sy1, sx2-sx1, sy2-sy1)
# 5. 绘制模型预测的结果框和置信度 (红色 Red)
if self.show_results and self.result_items:
pen_res = QPen(QColor(255, 50, 50), 2) # 红色结果框
font = QFont("Arial", 10, QFont.Weight.Bold)
painter.setFont(font)
metrics = QFontMetrics(font)
for item in self.result_items:
rx1, ry1, rx2, ry2 = item['rect']
conf_val = item['conf']
# 画结果框
painter.setPen(pen_res)
painter.setBrush(Qt.BrushStyle.NoBrush)
painter.drawRect(rx1, ry1, rx2-rx1, ry2-ry1)
# 画置信度标签
text = f"{conf_val:.2f}"
text_w = metrics.horizontalAdvance(text) + 10
text_h = metrics.height() + 4
# 标签画在框顶上方
tx = rx1
ty = ry1 - text_h
if ty < 0: ty = ry1
# 标签背景
painter.setPen(Qt.PenStyle.NoPen)
painter.setBrush(QColor(255, 50, 50))
painter.drawRect(tx, ty, text_w, text_h)
# 标签文字
painter.setPen(QColor(255, 255, 255))
painter.drawText(QRect(tx, ty, text_w, text_h), Qt.AlignmentFlag.AlignCenter, text)
# 6. 绘制当前正在拖拽的框 (白色虚线)
if self.current_start and self.current_end:
pen_drag = QPen(QColor(255, 255, 255), 2, Qt.PenStyle.DashLine)
painter.setPen(pen_drag)
painter.setBrush(Qt.BrushStyle.NoBrush)
x = min(self.current_start.x(), self.current_end.x())
y = min(self.current_start.y(), self.current_end.y())
w = abs(self.current_end.x() - self.current_start.x())
h = abs(self.current_end.y() - self.current_start.y())
painter.drawRect(x, y, w, h)
class MainWindow(QMainWindow):
def __init__(self):
super().__init__()
self.setWindowTitle("YOLOE Interactive Segmentation Tool")
self.resize(1300, 850)
self.model_path = "yoloe-11s-seg.pt"
self.model = None
self.cls_id = 0
self.init_ui()
QTimer.singleShot(100, self.load_model)
def init_ui(self):
main_widget = QWidget()
self.setCentralWidget(main_widget)
main_widget.setStyleSheet("background-color: #f0f0f0;") # 全局浅灰背景
layout = QHBoxLayout(main_widget)
# --- 左侧画布区域 ---
# 移除了额外的 canvas_container Widget,直接把 ImageCanvas 放进去
# 因为 ImageCanvas 现在是 QWidget,会自动处理大小
self.canvas = ImageCanvas()
self.canvas.box_added.connect(self.run_inference)
layout.addWidget(self.canvas, stretch=4) # 画布占更多比例
# --- 右侧控制面板 ---
controls = QGroupBox("Controls")
controls.setStyleSheet("""
QGroupBox { font-weight: bold; color: #333; border: 1px solid #aaa; margin-top: 10px; background-color: #fff; }
QGroupBox::title { subcontrol-origin: margin; left: 10px; padding: 0 5px; }
QLabel { color: #333; }
QCheckBox { color: #333; }
""")
controls_layout = QVBoxLayout(controls)
controls_layout.setAlignment(Qt.AlignmentFlag.AlignTop)
# 1. Load Image
btn_load = QPushButton("Load Image")
btn_load.setStyleSheet("""
QPushButton { background-color: #0078d7; color: white; border-radius: 4px; padding: 8px; font-weight: bold; }
QPushButton:hover { background-color: #0063b1; }
""")
btn_load.clicked.connect(self.open_image)
controls_layout.addWidget(btn_load)
controls_layout.addSpacing(20)
# 2. Sliders
# Conf
self.lbl_conf = QLabel("Confidence: 0.25")
slider_conf = QSlider(Qt.Orientation.Horizontal)
slider_conf.setRange(1, 100)
slider_conf.setValue(25)
slider_conf.valueChanged.connect(lambda v: self.update_param_label(v, "conf"))
slider_conf.sliderReleased.connect(self.run_inference)
controls_layout.addWidget(self.lbl_conf)
controls_layout.addWidget(slider_conf)
self.slider_conf = slider_conf
# IoU
self.lbl_iou = QLabel("NMS IoU: 0.70")
slider_iou = QSlider(Qt.Orientation.Horizontal)
slider_iou.setRange(1, 100)
slider_iou.setValue(70)
slider_iou.valueChanged.connect(lambda v: self.update_param_label(v, "iou"))
slider_iou.sliderReleased.connect(self.run_inference)
controls_layout.addWidget(self.lbl_iou)
controls_layout.addWidget(slider_iou)
self.slider_iou = slider_iou
controls_layout.addSpacing(15)
# 3. Checkboxes
self.chk_nms = QCheckBox("Enable NMS")
self.chk_nms.setChecked(True)
self.chk_nms.stateChanged.connect(self.run_inference)
controls_layout.addWidget(self.chk_nms)
# 【功能】 显示预测框和置信度
self.chk_res_box = QCheckBox("Show Result Boxes & Conf")
self.chk_res_box.setChecked(True)
self.chk_res_box.toggled.connect(self.canvas.toggle_results_display)
controls_layout.addWidget(self.chk_res_box)
controls_layout.addSpacing(20)
# 4. Action Buttons
btn_style = "QPushButton { padding: 6px; border: 1px solid #ccc; border-radius: 4px; background-color: #f9f9f9; color: black; } QPushButton:hover { background-color: #e6e6e6; }"
btn_undo = QPushButton("Undo (U)")
btn_undo.setStyleSheet(btn_style)
btn_undo.clicked.connect(self.undo_box)
controls_layout.addWidget(btn_undo)
btn_clear = QPushButton("Clear All (C)")
btn_clear.setStyleSheet(btn_style)
btn_clear.clicked.connect(self.clear_all)
controls_layout.addWidget(btn_clear)
btn_save = QPushButton("Save Result (S)")
btn_save.setStyleSheet(btn_style)
btn_save.clicked.connect(self.save_result)
controls_layout.addWidget(btn_save)
# Status
controls_layout.addStretch()
self.status_label = QLabel("Initializing...")
self.status_label.setStyleSheet("color: #666; font-size: 11px;")
controls_layout.addWidget(self.status_label)
layout.addWidget(controls, stretch=1)
def load_model(self):
self.status_label.setText("Loading model...")
QApplication.processEvents()
try:
self.model = YOLOE(self.model_path)
self.status_label.setText("Model Ready.")
except Exception as e:
self.status_label.setText(f"Model Error: {e}")
def open_image(self):
file_path, _ = QFileDialog.getOpenFileName(self, "Select Image", "", "Images (*.png *.jpg *.jpeg *.bmp)")
if file_path:
if self.canvas.load_image(file_path):
self.status_label.setText(f"Loaded: {file_path.split('/')[-1]}")
# Reset controls
self.run_inference()
def update_param_label(self, value, p_type):
float_val = value / 100.0
if p_type == "conf":
self.lbl_conf.setText(f"Confidence: {float_val:.2f}")
elif p_type == "iou":
self.lbl_iou.setText(f"NMS IoU: {float_val:.2f}")
def undo_box(self):
if self.canvas.bboxes:
self.canvas.bboxes.pop()
self.run_inference()
def clear_all(self):
self.canvas.reset_state()
self.canvas.update()
self.status_label.setText("Cleared.")
def save_result(self):
if self.canvas.img_display:
pixmap = self.canvas.grab()
file_path, _ = QFileDialog.getSaveFileName(self, "Save", "result.png", "Images (*.png)")
if file_path:
pixmap.save(file_path)
self.status_label.setText(f"Saved to {file_path}")
def run_inference(self):
if self.model is None or self.canvas.img_orig is None:
return
self.status_label.setText("Inferencing...")
QApplication.processEvents()
conf = self.slider_conf.value() / 100.0
iou = self.slider_iou.value() / 100.0
use_nms = self.chk_nms.isChecked()
# 注意:canvas.bboxes 现在存储的是原图坐标
visual_prompts = None
if self.canvas.bboxes:
visual_prompts = dict(
bboxes=np.array(self.canvas.bboxes),
cls=np.array([self.cls_id])
)
predict_args = {
"source": self.canvas.img_orig,
"conf": conf,
"iou": iou,
"nms": use_nms,
"retina_masks": True,
}
if visual_prompts:
predict_args["visual_prompts"] = visual_prompts
if YOLOEVPSegPredictor:
predict_args["predictor"] = YOLOEVPSegPredictor
try:
results = self.model.predict(**predict_args)
if results and len(results[0].boxes) > 0:
res = results[0]
# 1. 获取纯 Mask (不带框)
mask_plot = res.plot(boxes=False, probs=False, img=self.canvas.img_orig.copy())
mask_rgb = cv2.cvtColor(mask_plot, cv2.COLOR_BGR2RGB)
# 2. 提取框和置信度
boxes_data = []
for box in res.boxes:
coords = box.xyxy[0].cpu().numpy() # [x1, y1, x2, y2]
score = float(box.conf[0].cpu().numpy())
boxes_data.append((coords[0], coords[1], coords[2], coords[3], score))
self.canvas.set_results(mask_rgb, boxes_data)
self.status_label.setText(f"Objects: {len(boxes_data)}")
else:
self.canvas.set_results(None, None)
self.status_label.setText("No objects.")
except Exception as e:
print(e)
self.status_label.setText("Inference Error.")
def keyPressEvent(self, event):
if event.key() == Qt.Key.Key_U: self.undo_box()
elif event.key() == Qt.Key.Key_C: self.clear_all()
elif event.key() == Qt.Key.Key_S: self.save_result()
if __name__ == "__main__":
app = QApplication(sys.argv)
app.setStyle("Fusion")
window = MainWindow()
window.show()
sys.exit(app.exec())(2.2)支持完全封闭目标:强依赖参数,不同图像需要精调
(2.3)不支持不封闭目标:效果差
增强分割精度:视觉提示中增加 masks,提升不封闭目标、弱纹理目标的分割效果。效果没有想象中那么好
python
import cv2
import numpy as np
from ultralytics import YOLOE
from ultralytics.models.yolo.yoloe import YOLOEVPSegPredictor
import matplotlib.pyplot as plt
def yoloe_vp_mask_inference(img_path, model_path, conf=0.1, class_id=0):
"""
YOLOE-VPSeg 单图像不封闭目标分割
- 支持鼠标绘制矩形生成 mask
- 自动生成 visual_prompts
- 返回绘制结果图像
"""
# -----------------------------
# 1. 读取图像(灰度图)
# -----------------------------
img = cv2.imread(img_path, cv2.IMREAD_GRAYSCALE)
H, W, _ = img.shape
# -----------------------------
# 2. 鼠标回调绘制矩形
# -----------------------------
drawing = False
ix, iy = -1, -1
rect = [0, 0, 0, 0]
def draw_rectangle(event, x, y, flags, param):
nonlocal ix, iy, drawing, rect, img_copy
if event == cv2.EVENT_LBUTTONDOWN:
drawing = True
ix, iy = x, y
elif event == cv2.EVENT_MOUSEMOVE:
if drawing:
img_copy = img.copy()
cv2.rectangle(img_copy, (ix, iy), (x, y), 255, 1)
elif event == cv2.EVENT_LBUTTONUP:
drawing = False
rect = [ix, iy, x, y]
cv2.rectangle(img_copy, (ix, iy), (x, y), 255, 1)
img_copy = img.copy()
cv2.namedWindow("Draw Mask Rectangle", cv2.WINDOW_NORMAL) # 窗口自适应
cv2.imshow("Draw Mask Rectangle", img_copy)
cv2.setMouseCallback("Draw Mask Rectangle", draw_rectangle)
while True:
cv2.imshow("Draw Mask Rectangle", img_copy)
key = cv2.waitKey(1) & 0xFF
if key == 13: # Enter 键确认
break
cv2.destroyAllWindows()
# -----------------------------
# 3. 处理矩形坐标
# -----------------------------
x1, y1, x2, y2 = rect
x1, x2 = sorted([x1, x2])
y1, y2 = sorted([y1, y2])
# -----------------------------
# 4. 生成 mask
# -----------------------------
mask = np.zeros((H, W), dtype=np.uint8)
mask[y1:y2, x1:x2] = 1
masks = mask[np.newaxis, :, :]
# -----------------------------
# 5. 构建 visual_prompts
# -----------------------------
visual_prompts = dict(
masks=masks,
bboxes=np.array([[x1, y1, x2, y2]]),
cls=np.array([class_id]),
scores=np.array([1.0])
)
# -----------------------------
# 6. 加载模型 & 推理
# -----------------------------
model = YOLOE(model_path)
results = model.predict(
source=img_path,
visual_prompts=visual_prompts,
predictor=YOLOEVPSegPredictor,
conf=conf
)
# -----------------------------
# 7. 可视化
# -----------------------------
result_img = results[0].plot()[:, :, ::-1] # BGR->RGB
# 同时显示
plt.figure(figsize=(8,8))
plt.imshow(result_img)
plt.axis("off")
plt.title("YOLOE-VPSeg Result with Mask Prompt")
plt.show()
return result_img, results, visual_prompts
if __name__ == "__main__":
img_path = r"D:\py\line\0095 - 500 kx HAADF-DF-BF DF-S.tif"
model_path = "yoloe-11l-seg.pt"
yoloe_vp_mask_inference(img_path, model_path, conf=0.1)(2.4)支持视觉提示的跨图像迁移能力:将当前图像的视觉提示迁移到另一张图像中
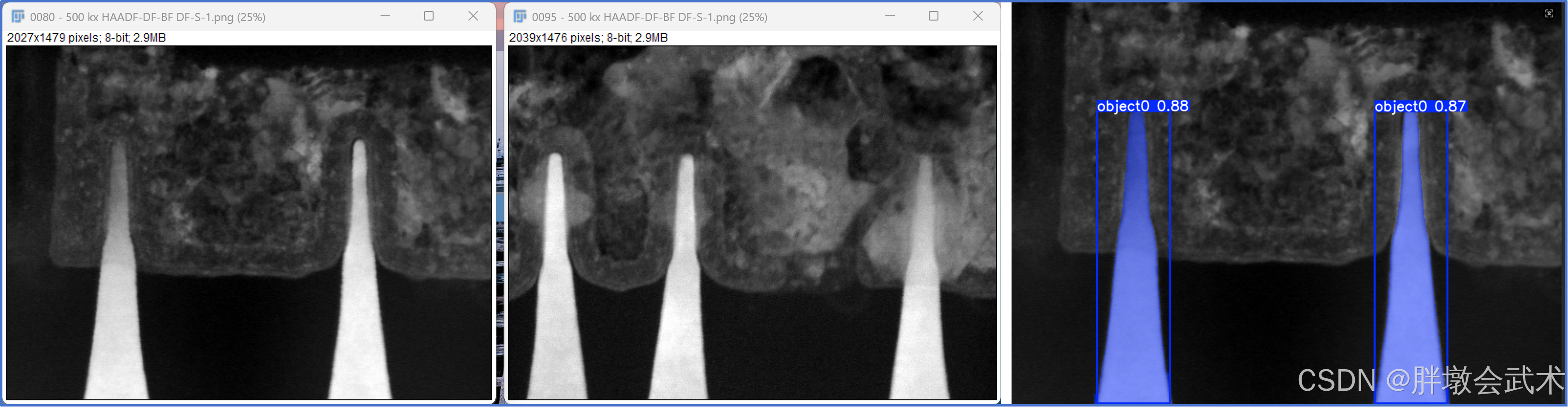
详细请看(1)参考图像:refer_image ------ 具备跨图像迁移能力
python
import numpy as np
from ultralytics import YOLOE
from ultralytics.models.yolo.yoloe import YOLOEVPSegPredictor
# Initialize a YOLOE model
model = YOLOE("yoloe-11l-seg.pt")
# Define visual prompts based on a separate reference image
visual_prompts = dict(
bboxes=np.array([[10, 450, 360, 1470]]), # Box enclosing person
cls=np.array([0]), # ID to be assigned for person
)
# Run prediction on a different image, using reference image to guide what to look for
results = model.predict(
source=r"D:\py\line\0080 - 500 kx HAADF-DF-BF DF-S-1.png", # Target image for detection
refer_image=r"D:\py\line\0095 - 500 kx HAADF-DF-BF DF-S-1.png", # Reference image used to get visual prompts
visual_prompts=visual_prompts,
predictor=YOLOEVPSegPredictor,
)
# Show results
results[0].show()注意点1:视觉提示与输入图像尺度的关系
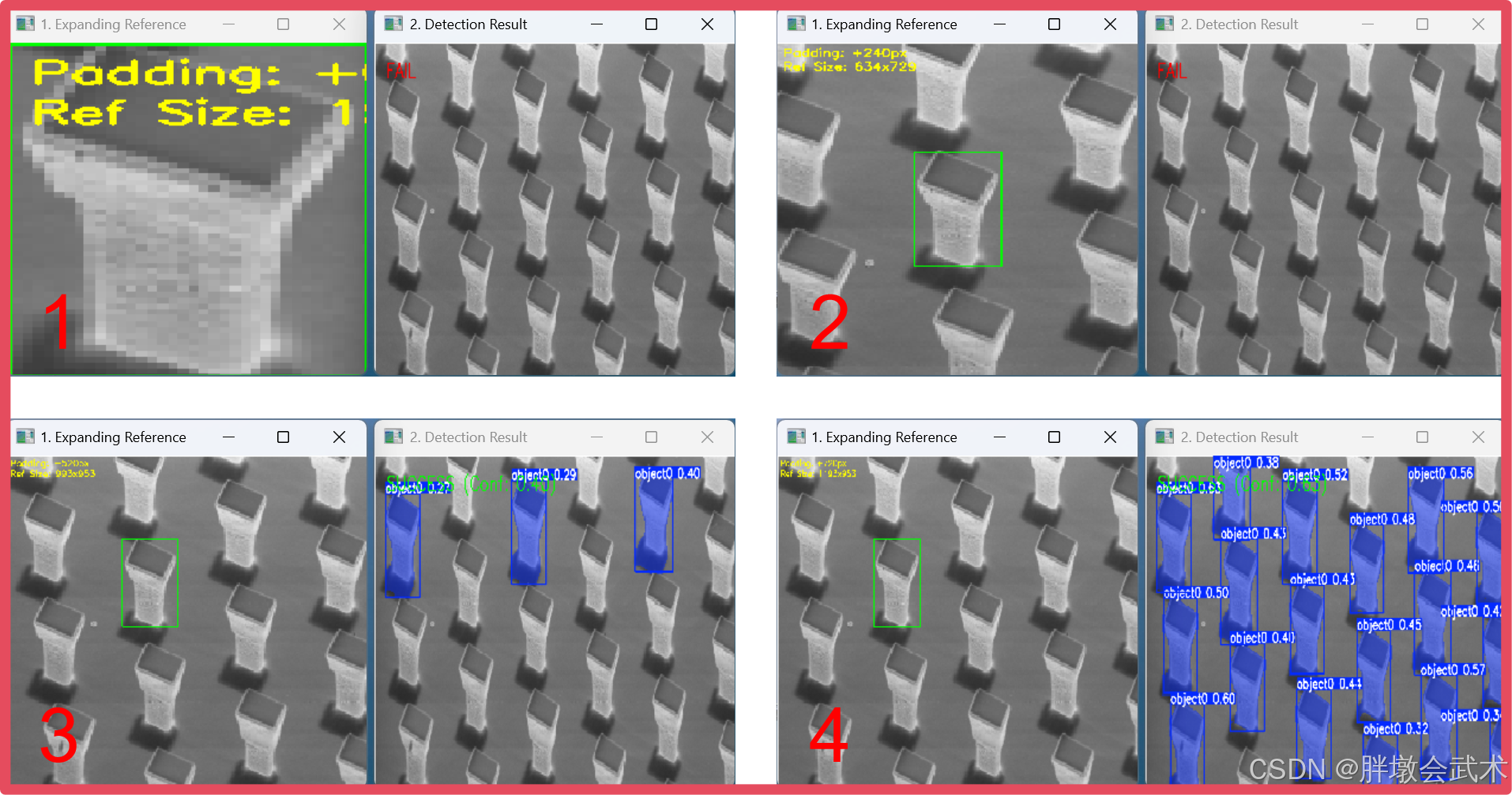
视觉提示与输入图像尺寸具有一定联系,视觉提示在输入图像中的占比越小,精度越好!!!
python
import cv2
import numpy as np
import os
from ultralytics import YOLOE
from ultralytics.models.yolo.yoloe import YOLOEVPSegPredictor
# ================= 配置区域 =================
model_path = "yoloe-11s-seg.pt"
image_path = "20251104.png"
temp_ref_path = "temp_ref_expand.png"
# 你的目标物体坐标 [x1, y1, x2, y2]
obj_bbox = [319, 239, 473, 489]
# 每次向四周扩大多少背景
step_size = 20
# ===========================================
model = YOLOE(model_path)
img_full = cv2.imread(image_path)
h_full, w_full, _ = img_full.shape
# 准备窗口
cv2.namedWindow("1. Expanding Reference", cv2.WINDOW_NORMAL)
cv2.namedWindow("2. Detection Result", cv2.WINDOW_NORMAL)
cv2.moveWindow("1. Expanding Reference", 100, 100)
cv2.moveWindow("2. Detection Result", 600, 100)
print(f"🚀 开始反向扩大测试 | 物体坐标: {obj_bbox}")
print("按【空格】扩大背景,按【Esc】退出...")
# 从 0 开始 (紧贴物体)
current_pad = 0
while True:
# 1. 计算扩大的裁剪范围 (Crop Window)
# 逻辑:以物体为中心,向外扩 current_pad
crop_x1 = max(0, obj_bbox[0] - current_pad)
crop_y1 = max(0, obj_bbox[1] - current_pad)
crop_x2 = min(w_full, obj_bbox[2] + current_pad)
crop_y2 = min(h_full, obj_bbox[3] + current_pad)
# 检查是否已经扩大到原图边缘 (没法再扩了)
if crop_x1 == 0 and crop_y1 == 0 and crop_x2 == w_full and crop_y2 == h_full:
print("✅ 已扩大至全图,测试结束。")
break
# 2. 生成参考图
ref_img = img_full[int(crop_y1):int(crop_y2), int(crop_x1):int(crop_x2)]
ref_h, ref_w = ref_img.shape[:2]
cv2.imwrite(temp_ref_path, ref_img)
# 3. 计算 Visual Prompt BBox (物体在当前 ref_img 里的坐标)
# 因为 ref_img 是基于 obj_bbox 扩大的,所以物体永远在 ref_img 的中心
# 坐标 = 物体在原图的位置 - ref_img 左上角在原图的位置
prompt_x1 = obj_bbox[0] - crop_x1
prompt_y1 = obj_bbox[1] - crop_y1
prompt_x2 = obj_bbox[2] - crop_x1
prompt_y2 = obj_bbox[3] - crop_y1
# 4. 运行预测
visual_prompts = dict(
bboxes=np.array([[prompt_x1, prompt_y1, prompt_x2, prompt_y2]]),
cls=np.array([0]),
)
try:
results = model.predict(
image_path,
visual_prompts=visual_prompts,
predictor=YOLOEVPSegPredictor,
refer_image=temp_ref_path,
conf=0.25,
verbose=False
)
except Exception as e:
print(e)
break
# ================= 可视化展示 =================
# [窗口1] 参考图
viz_ref = ref_img.copy()
# 画绿框:这是物体 (Prompt)
cv2.rectangle(viz_ref, (int(prompt_x1), int(prompt_y1)), (int(prompt_x2), int(prompt_y2)), (0, 255, 0), 2)
# 在绿框外面画一圈红框,表示当前的图片边缘 (让你直观看到背景多了多少)
# cv2.rectangle(viz_ref, (0, 0), (ref_w-1, ref_h-1), (0, 0, 255), 4)
# 显示信息
cv2.putText(viz_ref, f"Padding: +{current_pad}px", (10, 30), cv2.FONT_HERSHEY_SIMPLEX, 0.8, (0, 255, 255), 2)
cv2.putText(viz_ref, f"Ref Size: {ref_w}x{ref_h}", (10, 60), cv2.FONT_HERSHEY_SIMPLEX, 0.8, (0, 255, 255), 2)
# 自动放大显示 (如果图太小看不清)
if ref_w < 400:
scale = 400 / ref_w
viz_ref_show = cv2.resize(viz_ref, (0, 0), fx=scale, fy=scale, interpolation=cv2.INTER_NEAREST)
else:
viz_ref_show = viz_ref
# [窗口2] 结果图
status_text = "FAIL"
status_color = (0, 0, 255)
if results and len(results[0].boxes) > 0:
res_plot = results[0].plot(labels=True, boxes=True)
conf = results[0].boxes.conf[0].item()
status_text = f"SUCCESS (Conf: {conf:.2f})"
status_color = (0, 255, 0)
else:
res_plot = img_full.copy()
# 在结果图上写状态
cv2.putText(res_plot, status_text, (50, 100), cv2.FONT_HERSHEY_SIMPLEX, 2, status_color, 3)
cv2.imshow("1. Expanding Reference", viz_ref_show)
cv2.imshow("2. Detection Result", res_plot)
print(f"Padding: +{current_pad:<4} | RefSize: {ref_w}x{ref_h} | {status_text}")
key = cv2.waitKey(0)
if key == 27: break
current_pad += step_size
cv2.destroyAllWindows()
if os.path.exists(temp_ref_path):
os.remove(temp_ref_path)注意点2:(自定义)参考图像的视觉提示 + 模板匹配(不推荐,可忽略)
初始测试时,本来以为不支持视觉提示迁移,因此才有了该部分的代码优化以及原理解析。但随着使用频率和经验增加,发现model.predict()中参数refer_image是用于实现跨图像迁移能力的,因此下述内容忽略。仅用于个人记录!!!
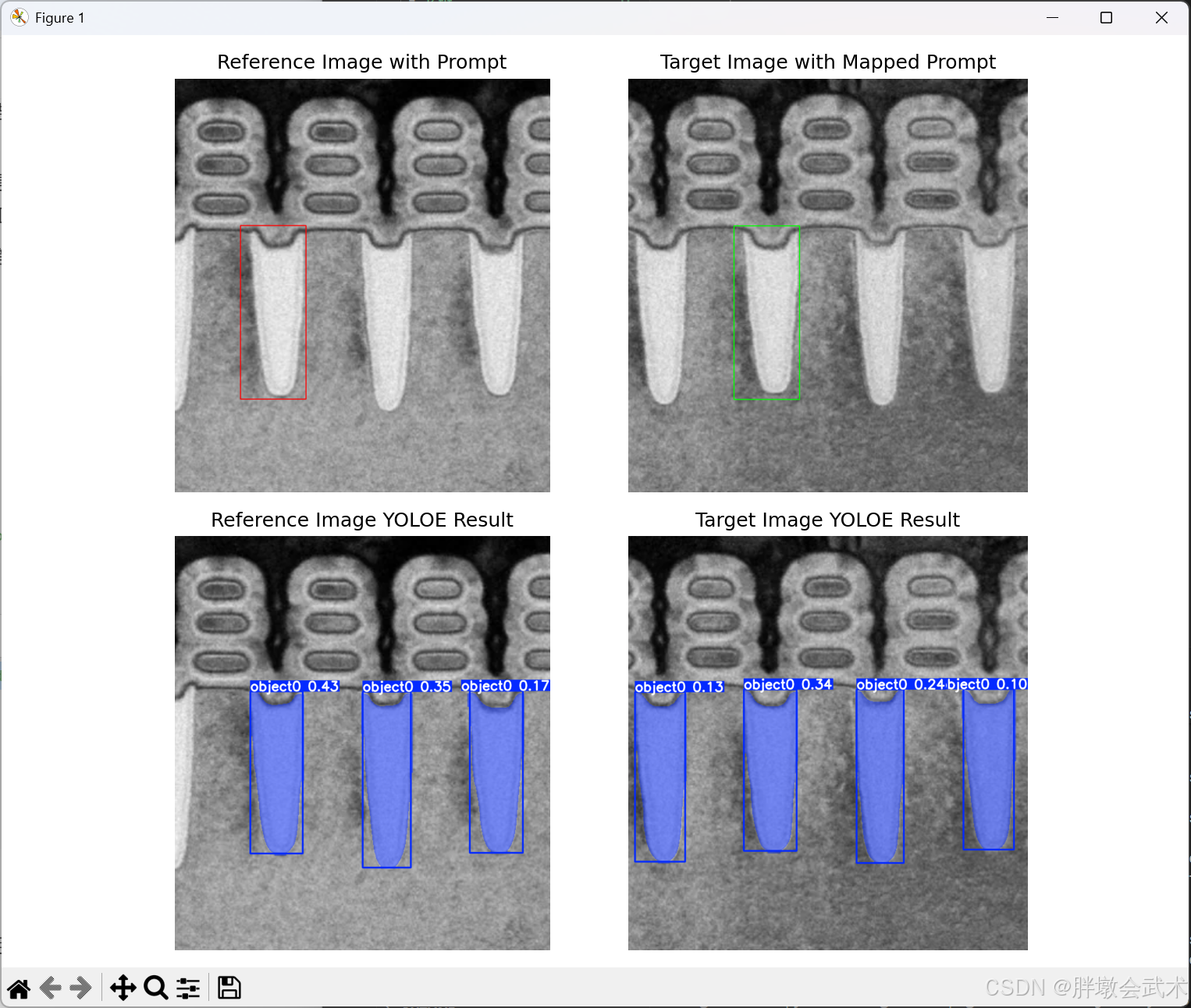
YOLO-E的视觉提示机制:本质上是一种依赖像素坐标的空间条件提示机制,提示信息(如框或掩码)只能在当前图像的特定坐标体系中发挥作用。因此,不具备跨图像、跨任务或跨数据集的提示迁移能力。即:仅在当前图像有效,而不能迁移到其他图像,属于典型的 " 单图条件提示 " 机制。不具备 SAM、PVT-Prompt 或 CLIP/DINO 类型模型中那种可跨图像理解语义提示token的能力。
- 原因
(1)坐标依赖性:提示框/掩码直接基于像素坐标,仅对当前图像成立。
(2)特征绑定性:提示增强是在 backbone 的局部特征上进行,换图后(图像出现位移、缩放、旋转或结构差异)提示框的像素坐标将失效。
(3)缺乏可迁移 token:YOLO-E 没有类似 CLIP/SAM 的提示向量或语义 token,无法在不同图像之间理解同一提示的语义含义。- 如何实现 " 间接迁移 " (依赖外部算法,而非模型自身)
若两张图像的空间布局不一致、倍率不同或存在几何变化,想将参考图像的视觉提示应用到另一张图像,需要通过额外的图像空间变换来间接实现"迁移"。
典型流程如下:
- (1)在参考图像上绘制提示框。
- (2)使用特征匹配或关键点匹配算法(SIFT、ORB 等)在目标图像上找到对应位置。
- (3)将映射后的提示坐标输入 YOLO-E,实现条件推理。
python
import cv2
import numpy as np
import matplotlib.pyplot as plt
from ultralytics import YOLOE
from ultralytics.models.yolo.yoloe import YOLOEVPSegPredictor
# -----------------------------
# 模板匹配 + bbox 定位
# -----------------------------
def map_local_bbox_to_target_template(ref_img_path, target_img_path, bbox):
# 读取图像
ref_img = cv2.imread(ref_img_path)
target_img = cv2.imread(target_img_path)
# 截取参考框区域作为模板
ref_crop = ref_img[bbox[1]:bbox[3], bbox[0]:bbox[2]]
template_gray = cv2.cvtColor(ref_crop, cv2.COLOR_BGR2GRAY)
target_gray = cv2.cvtColor(target_img, cv2.COLOR_BGR2GRAY)
# 模板匹配
result = cv2.matchTemplate(target_gray, template_gray, cv2.TM_CCOEFF_NORMED)
min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(result)
# 匹配位置左上角
top_left = max_loc
h, w = template_gray.shape
mapped_bbox = [top_left[0], top_left[1], top_left[0]+w, top_left[1]+h]
print(f"模板匹配得分: {max_val:.4f}")
return mapped_bbox, ref_crop, top_left, (w,h)
# -----------------------------
# YOLOE 推理 + 可视化
# -----------------------------
def run_yolo_template_prompt(ref_img_path, target_img_path, ref_bbox, class_id=0, conf=0.05, model_path="yoloe-11s-seg.pt"):
# 1. 加载 YOLOE 模型
model = YOLOE(model_path)
# 2. 模板匹配定位
mapped_bbox, ref_crop, top_left, template_size = map_local_bbox_to_target_template(ref_img_path, target_img_path, ref_bbox)
# 3. 构建视觉提示
visual_prompts_ref = dict(bboxes=np.array([ref_bbox]), cls=np.array([class_id]))
visual_prompts_target = dict(bboxes=np.array([mapped_bbox]), cls=np.array([class_id]))
# 4. YOLOE 推理
ref_results = model.predict(ref_img_path, visual_prompts=visual_prompts_ref, predictor=YOLOEVPSegPredictor, conf=conf)
target_results = model.predict(target_img_path, visual_prompts=visual_prompts_target, predictor=YOLOEVPSegPredictor, conf=conf)
# 5. 可视化
ref_img_drawn = cv2.imread(ref_img_path)[:, :, ::-1]
target_img_drawn = cv2.imread(target_img_path)[:, :, ::-1]
# 绘制参考图矩形框
ref_img_prompt = ref_img_drawn.copy()
cv2.rectangle(ref_img_prompt, (ref_bbox[0], ref_bbox[1]), (ref_bbox[2], ref_bbox[3]), (255,0,0), 2)
# 绘制目标图匹配矩形框
target_img_prompt = target_img_drawn.copy()
cv2.rectangle(target_img_prompt, (mapped_bbox[0], mapped_bbox[1]), (mapped_bbox[2], mapped_bbox[3]), (0,255,0), 2)
# 显示模板匹配结果
match_vis = target_img_drawn.copy()
cv2.rectangle(match_vis, (mapped_bbox[0], mapped_bbox[1]), (mapped_bbox[2], mapped_bbox[3]), (0,0,255), 2)
# YOLOE 分割结果
ref_img_result = ref_results[0].plot()[:, :, ::-1]
target_img_result = target_results[0].plot()[:, :, ::-1]
# -----------------------------
# 显示 subplot
# -----------------------------
plt.figure(figsize=(18,8))
plt.subplot(2,2,1)
plt.title("Reference Image with Prompt")
plt.imshow(ref_img_prompt)
plt.axis("off")
plt.subplot(2,2,2)
plt.title("Target Image with Mapped Prompt")
plt.imshow(target_img_prompt)
plt.axis("off")
plt.subplot(2,2,3)
plt.title("Reference Image YOLOE Result")
plt.imshow(ref_img_result)
plt.axis("off")
plt.subplot(2,2,4)
plt.title("Target Image YOLOE Result")
plt.imshow(target_img_result)
plt.axis("off")
plt.tight_layout()
plt.show()
return mapped_bbox
# -----------------------------
# 主函数示例
# -----------------------------
if __name__ == "__main__":
ref_bbox = [200, 450, 400, 980]
ref_img_path = r"D:\py\line\image111-1.png"
target_img_path = r"D:\py\line\image111-2.png"
mapped_bbox = run_yolo_template_prompt(
ref_img_path,
target_img_path,
ref_bbox,
class_id=0,
conf=0.1,
model_path="yoloe-11l-seg.pt"
)
print("Mapped BBox:", mapped_bbox)(3)无提示词:prompt-free
https://docs.ultralytics.com/zh/models/yoloe/#prompt-free
YOLOE 还包括内置词汇的免提示变体。这些模型不需要任何提示,工作方式与传统的YOLO 模型类似。它们不依赖用户提供的标签或视觉示例,而是根据Recognize Anything Model Plus (RAM++) 使用的标签集,从预定义的 4585 个类别列表中detect 对象。
python
from ultralytics import YOLOE
# Initialize a YOLOE model
model = YOLOE("yoloe-11l-seg-pf.pt")
# Run prediction. No prompts required.
results = model.predict("path/to/image.jpg")
# Show results
results[0].show()