tensorflow是10年前开始用的,水了N篇论文后,发现现在的趋势是pytorch,于是开始从0学起,记个笔记。
从入门MNIST开始:
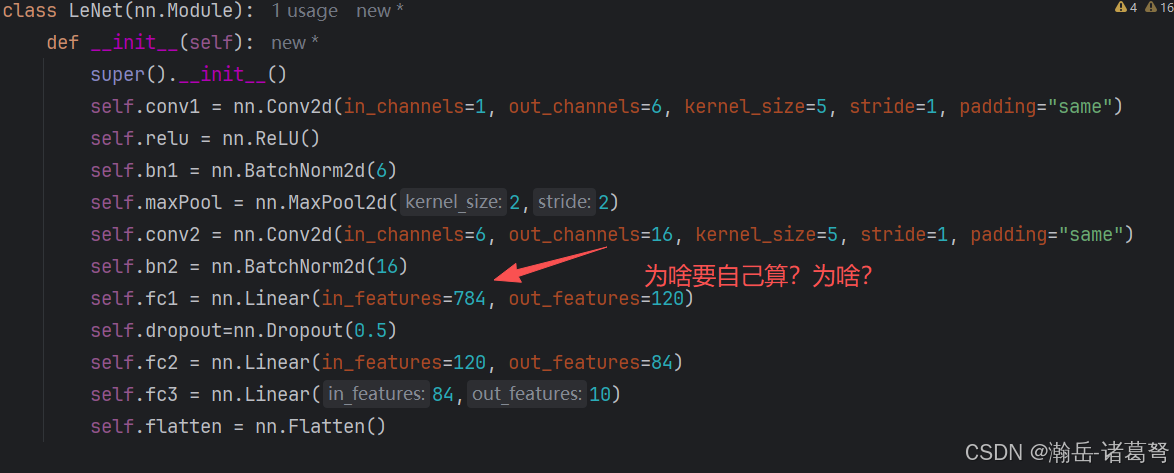
第一个不适应的地方:这里的尺度为啥要自己计算?
对于用惯了tensorflow+keras这种傻瓜式的框架来说,这玩意是太折腾人了。
只能理解为更加严谨。在LeNet的基础之上,加了BN和DropOut。两个和tensorflow不同的地方:
-
BN也需要参数,具体值就是上一层的channel数,tensorflow不用
-
不管是训练还是测试,都需要对模型加一句:model.train()或model.eval(),不然BN或DropOut不起作用(网上这么说的)
第二个不适应的地方:啥都要自己写

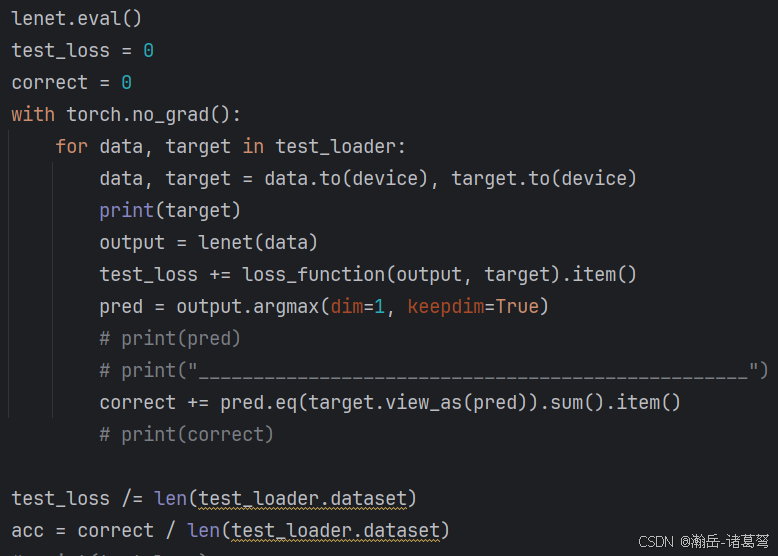
不管是训练,还是evaluate,都需要自己手写代码,tensorflow中,训练直接从history提取loss什么的就行,evaluate就更简单,就一行代码。不过这样的好处也是有的......多写两行代码锻炼代码能力。
疑惑:GPU并没有跑满,很神奇。
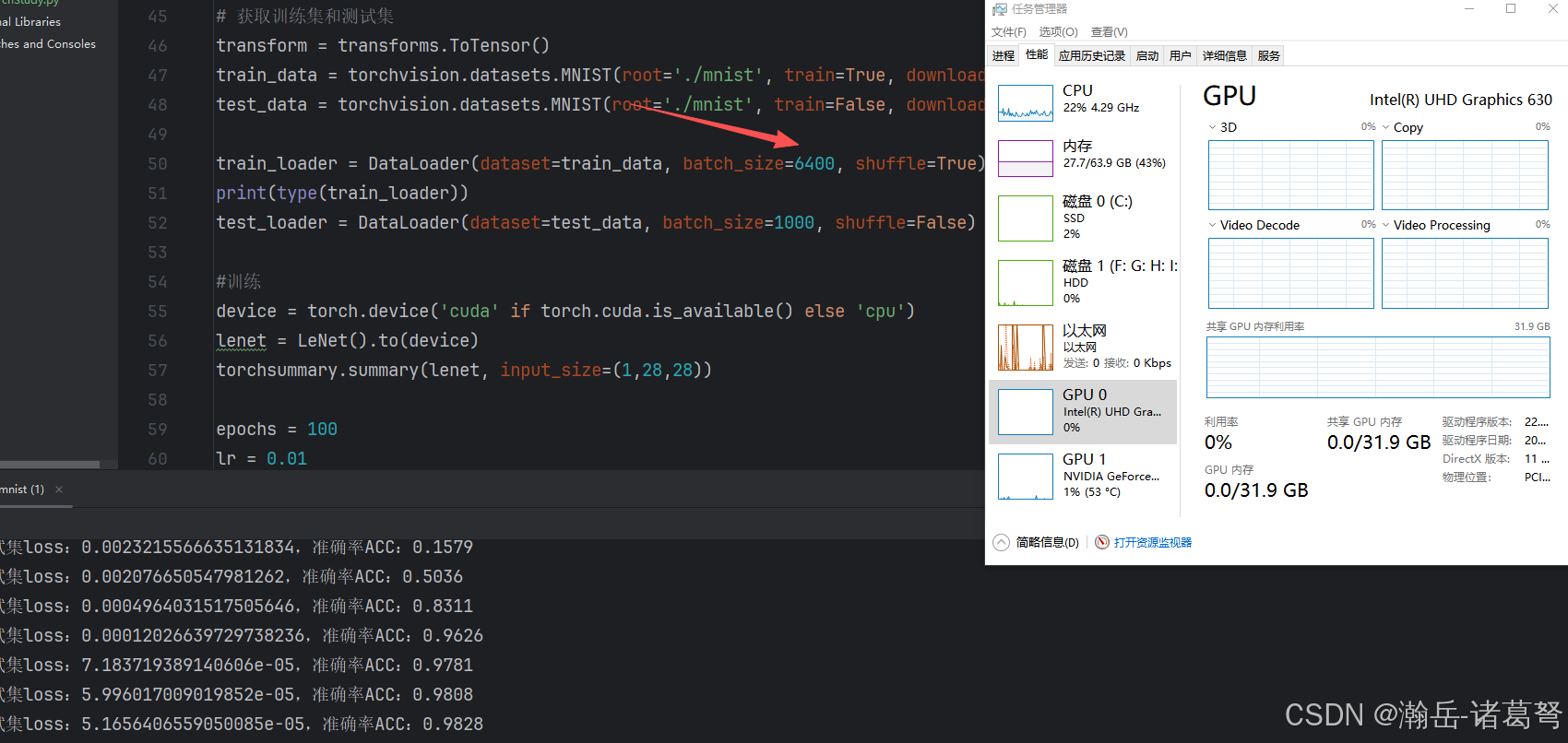 这块从2015年开始陪我征战的1080ti,直接跑不满。放tensorflow下,哪怕是MNIST这种数据集,也在60%左右,很奇怪,不知道用的什么机制。
这块从2015年开始陪我征战的1080ti,直接跑不满。放tensorflow下,哪怕是MNIST这种数据集,也在60%左右,很奇怪,不知道用的什么机制。
学习到了一些比较好的语法糖,比如:
pred.eq(target.view_as(pred)).sum().item()避免了循环的写法,也高效。虽然这是python的基本语法,因为原来evaluate直接出结果,也很少用到。一直傻傻的用循环用了十多年。所以说,论文真是水出来的。