作者:来自 Elastic Alexander Marquardt(www.elastic.co/search-labs... "Alexander Marquardt")
通过在 Elasticsearch 中使用可解释、分群感知的排序来提升电商搜索相关性。了解乘法提升如何在查询时提供稳定、可预测的个性化效果。
Elasticsearch 充满了新功能,可以帮助你为自己的使用场景构建最好的搜索解决方案。了解如何在我们的实践网络研讨会中将这些功能应用到构建现代 Search AI 体验中(www.elastic.co/virtual-eve... "现代 Search AI 体验中")。你也可以开始免费的云试用(cloud.elastic.co/registratio... "免费的云试用"),或在本地机器(elasticstack.blog.csdn.net/article/det... "本地机器")上尝试 Elastic。
概览
在这篇文章中,我们探讨如何使用一种可解释的、乘法提升策略,让 Elasticsearch 的搜索结果对不同电商(www.elastic.co/enterprise-... "电商")用户分群更加相关 ------ 而且不需要任何机器学习的后处理。
引言:为什么个性化很重要
Elasticsearch 在按文本相关性( BM25 )和语义相关性(向量)对结果进行排序方面非常出色。在电商中,这些是必要的,但还不够。两个人可能输入相同的查询,却合理地期望看到不同的结果:
- 一个奢侈品购物者搜索 "red lipstick" 时,会希望高端品牌排在前面。
- 一个预算型购物者则希望更实惠的商品被提升。
- 一个礼物购买者可能更喜欢热门礼包。
目标是在给定查询的情况下,适度提升与用户分群相匹配的商品,使其在列表中上升,但不会破坏底层的相关性。本文展示如何仅使用 function_score(www.elastic.co/docs/refere... "function_score")、一个 keyword 字段,以及小幅乘法提升,来在 Elasticsearch 的相关性之上加入分群感知的个性化。
面向分群个性化的乘法提升
分群个性化中的核心挑战是稳定性。你希望与查询高度相关的商品依然保持相关性,并且在匹配用户分群时获得可控、可解释的提升。常见的问题在于个性化信号被加入总分的方式要么:
- 压过某些查询中的 BM25,要么
- 在其他情况下几乎没有效果。
出现这种情况的原因是大多数提升方法都使用加法评分。但 BM25 的分值尺度会在不同查询和数据集之间发生巨大变化,因此一个固定的加法调整(例如 "分群匹配加 +2.0")有时会对 BM25 造成巨大的影响,而有时又微不足道。
我们真正想要的,是一种保证:如果一个商品对查询匹配度高,并且与用户的分群一致,那么它的得分就能按照一个可控的百分比提升,而不受绝对 BM25 分值大小的影响。我们可以通过一种乘法模式来实现这一点:
ini
`final_score = BM25 × (1 + cohort_overlap × weight_per_cohort)`AI写代码本文展示如何使用 Elasticsearch 的 function_score 查询、产品上的 cohorts 字段,以及查询时传入的用户 cohorts 列表来实现这种模式。
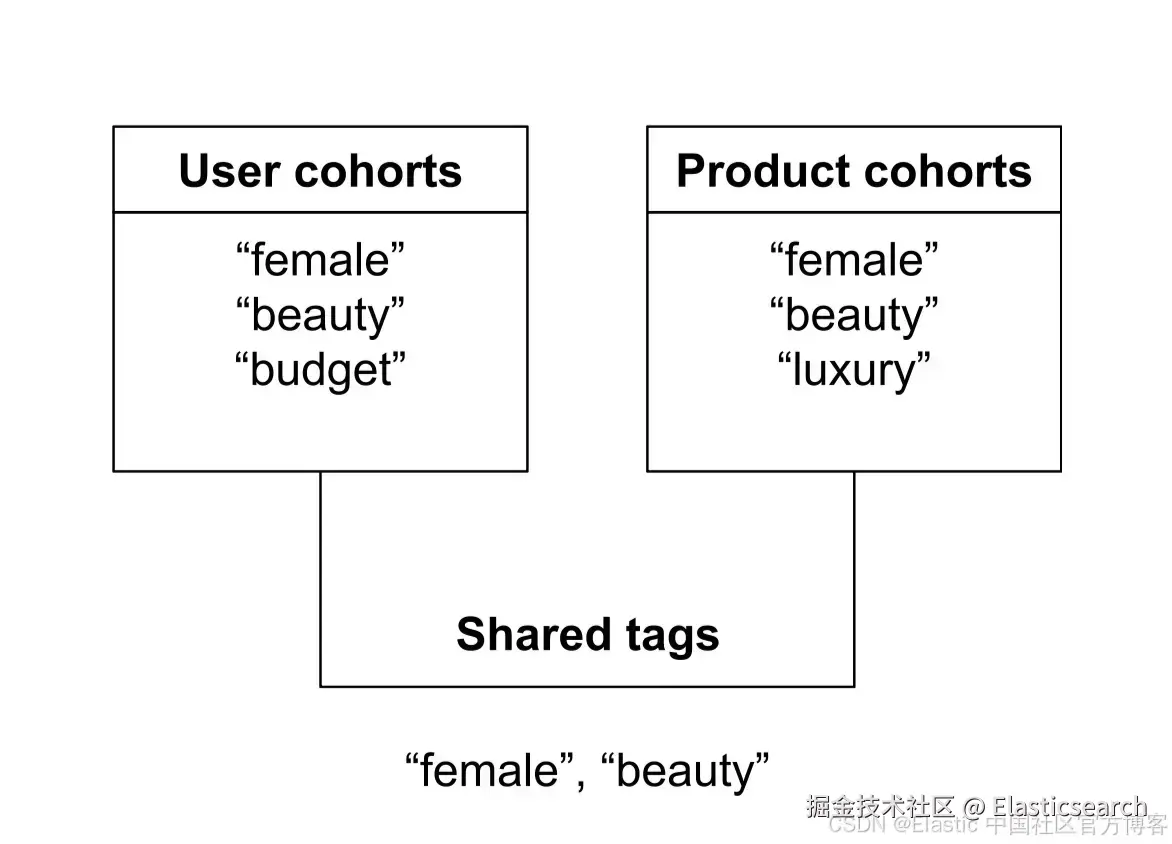
在商品目录中建模分群
启用分群感知排序的最简单方式是把分群视为标签。例如,一个商品可能带有如下标签:
- 口红/Lipstick:"female", "beauty", "luxury"
- 男士止汗剂/Men's deodorant:"male", "personal_care", "sport"
- 亮片唇彩/Glitter gloss:"female", "beauty", "youth", "party"
一个用户或会话则携带根据行为和画像推断出的标签:
- 高收入女性奢侈品购物者:"female", "beauty", "luxury"
- 注重预算的女性购物者:"female", "beauty", "budget"
分群重叠就是用户/会话与商品之间共享标签的数量。没有加权,没有语义相似度 ------ 只是简单的交集。例如,如果用户的 cohorts 是 "female", "beauty", "budget",而某款口红的标签是 "female", "beauty", "luxury",那么重叠数就是 2。
如果某款男士止汗剂的标签是 "male", "personal_care", "sport",那么与同一用户的重叠就是 0。
直觉是:(a) BM25 会根据文档与用户查询的相关程度进行排序,而 (b) 分群重叠会根据商品与用户分群的契合度来提升商品的排序。为了实现这一点,我们将用户分群与商品分群之间的重叠数转换成一个乘法提升,用来对 BM25 进行缩放。
为了避免字段爆炸,我们把所有分群标签放在一个单独的 keyword 字段中,例如:
xml
`
1. {
2. "product_id": "LIP-001",
3. "description": "Premium cherry red lipstick with velvet finish",
4. "cohorts": ["female", "beauty", "luxury"]
5. }
`AI写代码这种方式便于商品运营人员理解,避免出现像 is_female 或 is_luxury 这样成百上千的布尔字段,并且能与 term 过滤高效配合。
为什么加法式提升行不通
一个微妙但重要的点是,即使是标准的 boolean 查询,本质上也是加法的。当 Elasticsearch 给文档评分时,主查询(通常是 must)产生的基础 BM25 分数,加上所有匹配的 should 子句的得分,都会以加法方式累加。也就是说,"加法式提升" 不仅体现在 boost 参数上,它是 boolean 评分机制的基础。
基于加法逻辑的个性化表现不一致,因为 BM25 的分值尺度会因查询和数据集而异。例如,三个商品的基础 BM25 分别可能是 12、8、4,但在更新数据集或修改查询后,又可能变成 0.12、0.08、0.04。在这种情况下,一个加法提升(例如 +2.0)会在基础 BM25 分很小时成为主导力量(在得分 0.12 上加 +2.0,相当于提升约 18 倍),而当基础分很大时又几乎可以忽略(在得分 12 上加 +2.0 仅提升约 1.17 倍)。这会导致排序行为不一致且不可预测。
为什么乘法式提升是正确的形状
如果我们应用乘法提升,其形状始终一致:
ini
`
1. final_score = BM25 × boost
2. boost = 1 + overlap × weight_per_cohort
`AI写代码当 weight_per_cohort = 0.1 时,重叠为 2 会产生 1.2 的提升(20% 增幅),重叠为 1 会产生 1.1 的提升(10% 增幅),重叠为 0 则得到 1.0(无变化)。这意味着,只要商品更符合用户分群,就会得到可预测的百分比提升,而不管它的 BM25 得分是 0.01 还是 10.0。BM25 依然是主要信号;分群契合度只是轻柔地重新塑形排序。
function_score 如何带来乘法行为
为了把分群重叠转换成可控的百分比提升,我们需要一种方法,把正常的 BM25 得分按某个倍数放大,例如 1.1、1.2 或 1.3。Elasticsearch 并不支持在标准查询内部直接进行得分相乘,但 function_score(www.elastic.co/docs/refere... "function_score") 正好提供了这种能力:它允许我们计算一个额外的得分组件,并使用指定的策略(在这个用例中是 "multiply")将其与基础得分组合。
Elasticsearch 的 function_score 让我们能通过三步实现乘法式分群提升。第一,每个分群匹配贡献一个小的权重(例如 0.1)。第二,我们加入一个 1.0 的基线权重,让最终的乘数永远不会低于 1。第三,我们使用 score_mode: "sum" 把所有分群贡献相加,得到一个表示 (1 + overlap × weight) 的提升因子。最后,我们用 boost_mode: "multiply" 将这个提升因子与 BM25 得分相乘,从而得到我们想要的精确乘法行为。
下面的计算展示了最终得分是如何计算的,其中 BM25 是基础相关性;n 是匹配的分群数量;w 是 weight_per_cohort(例如 0.1);additive baseline = 1.0:
ini
`
1. sum_score = baseline + n × w
2. final_score = BM25 × sum_score
`AI写代码所以,对于 2 个重叠的 cohort 且 w = 0.1:
ini
`
1. sum_score = 1.0 + 2 × 0.1 = 1.2
2. final_score = BM25 × 1.2
`AI写代码这正是我们想要的乘法行为。
整合:索引、数据和基线排序
创建一个简单的索引:
less
`
1. PUT product_catalog
2. {
3. "mappings": {
4. "properties": {
5. "product_id": {
6. "type": "keyword"
7. },
8. "description": {
9. "type": "text"
10. },
11. "cohorts": {
12. "type": "keyword"
13. }
14. }
15. }
16. }
`AI写代码索引几个产品:
xml
`
1. POST _bulk
2. { "index": { "_index": "product_catalog", "_id": "LIP-001" }}
3. { "product_id": "LIP-001", "description": "Premium cherry red lipstick with velvet finish", "cohorts": ["female", "beauty", "luxury"] }
4. { "index": { "_index": "product_catalog", "_id": "LIP-002" }}
5. { "product_id": "LIP-002", "description": "Affordable matte red lipstick for everyday wear", "cohorts": ["female", "beauty", "budget"] }
6. { "index": { "_index": "product_catalog", "_id": "LIP-003" }}
7. { "product_id": "LIP-003", "description": "Glitter red gloss for parties and festivals", "cohorts": ["female", "beauty", "youth", "party"] }
`AI写代码"red lipstick"的基线查询可能如下:
xml
`
1. POST product_catalog/_search
2. {
3. "size": 5,
4. "_source": ["product_id", "description"],
5. "query": {
6. "multi_match": {
7. "query": "red lipstick",
8. "fields": ["description"]
9. }
10. }
11. }
`AI写代码这会返回纯 BM25 排序(没有任何 cohort 提升)。在这个例子中,LIP-001 和 LIP-002 的分数会非常接近(或相同),因为它们匹配相同的查询词,频率相似,长度也相当。
关键是相对排序;具体的数值分数可能会因分片配置、分析器差异或 Elasticsearch 版本而不同。
| Product ID | Description | BM25 score |
|---|---|---|
| LIP-001 | Premium cherry red lipstick with velvet finish | 0.603535 |
| LIP-002 | Affordable matte red lipstick for everyday wear | 0.603535 |
| LIP-003 | Glitter red gloss for parties and festivals | 0.13353139 |

Persona A:高收入奢侈品购物者
假设我们知道 Persona A 属于以下 cohorts:
xml
`["female", "beauty", "luxury"]`AI写代码我们将其转换为一组 cohort 过滤器,每个过滤器有一个小权重,再加上一个基线因子:
xml
`
1. GET product_catalog/_search
2. {
3. "explain": true,
4. "query": {
5. "function_score": {
6. "query": {
7. "multi_match": {
8. "query": "red lipstick",
9. "fields": ["description"]
10. }
11. },
12. "functions": [
13. { "filter": { "term": { "cohorts": "female" }}, "weight": 0.1 },
14. { "filter": { "term": { "cohorts": "beauty" }}, "weight": 0.1 },
15. { "filter": { "term": { "cohorts": "luxury" }}, "weight": 0.1 },
16. { "weight": 1.0 }
17. ],
18. "score_mode": "sum",
19. "boost_mode": "multiply"
20. }
21. }
22. }
`AI写代码对于这个 persona,LIP-001("Premium cherry red lipstick with velvet finish")匹配 "female"、"beauty" 和 "luxury",意味着 cohort 重叠为 3,因此提升因子为 1.3。另一方面,LIP-002 和 LIP-003 匹配 "female" 和 "beauty",提升因子为 1.2。
| Product ID | Description | Base BM25 score | Boost factor | New score |
|---|---|---|---|---|
| LIP-001 | Premium cherry red lipstick with velvet finish | 0.603535 | 1.3x (30%) | 0.7845955 |
| LIP-002 | Affordable matte red lipstick for everyday wear | 0.603535 | 1.2x (20%) | 0.724242 |
| LIP-003 | Glitter red gloss for parties and festivals | 0.13353139 | 1.2x (20%) | 0.16023767 |
如同预期,对于这个奢侈品用户,奢侈口红(LIP-001)获得了最大的提升,倾向于在结果中超过类似的替代品。
Persona B:注重预算的购物者
一个注重预算的购物者可能属于以下 cohorts:
xml
`["female", "beauty", "budget"]`AI写代码这个用户的查询几乎与之前的查询相同,只是 cohort 值现在反映的是 "budget" 而不是 "luxury":
xml
`
1. GET product_catalog/_search
2. {
3. "query": {
4. "function_score": {
5. "query": {
6. "multi_match": {
7. "query": "red lipstick",
8. "fields": ["description"]
9. }
10. },
11. "functions": [
12. { "filter": { "term": { "cohorts": "female" }}, "weight": 0.1 },
13. { "filter": { "term": { "cohorts": "beauty" }}, "weight": 0.1 },
14. { "filter": { "term": { "cohorts": "budget" }}, "weight": 0.1 },
15. { "weight": 1.0 }
16. ],
17. "score_mode": "sum",
18. "boost_mode": "multiply"
19. }
20. }
21. }
`AI写代码对于这个 persona,LIP-002("Affordable matte red lipstick for everyday wear")匹配 "female"、"beauty" 和 "budget",意味着 cohort 重叠为 3,因此提升因子为 1.3。另一方面,LIP-001 和 LIP-003 匹配 "female" 和 "beauty",提升因子为 1.2。
| Product ID | Description | Base BM25 score | Boost factor | New score |
|---|---|---|---|---|
| LIP-002 | Affordable matte red lipstick for everyday wear | 0.603535 | 1.3x (30%) | 0.7845955 |
| LIP-001 | Premium cherry red lipstick with velvet finish | 0.603535 | 1.2x (20%) | 0.724242 |
| LIP-003 | Glitter red gloss for parties and festivals | 0.13353139 | 1.2x (20%) | 0.16023767 |
如同预期,对于这个注重预算的用户,预算口红(LIP-002)获得了最大的提升,倾向于在结果中超过类似的替代品。
如何动态构建 cohort 过滤器(Python 示例)
通常,你会在查询时根据用户/会话的 profile 注入 cohort 过滤器。例如:
xml
`
1. user_cohorts = ["female", "beauty"]
2. functions = [
3. { "filter": { "term": { "cohorts": cohort } }, "weight": 0.1 }
4. for cohort in user_cohorts
5. ]
6. # add baseline multiplier
7. functions.append({ "weight": 1.0 })
`AI写代码在 keyword 字段上使用 term 过滤器速度快,对分片缓存友好,并且在 _explain API 中完全可见,该 API 会准确显示哪些过滤器被触发以及应用了哪些权重。
Cohort 分配如何工作
Cohort 分配有意留在 Elasticsearch 外部,也不在本文范围内。然而,来源可能包括:
- 浏览事件("has viewed lipstick" → beauty)
- 性别推断(www.elastic.co/docs/explor... "推断")(来自偏好或营销 profile)
- 设备特征(mobile shopper)
- 位置("urban buyer")
- 历史购买
- 营销细分
- 个性化 cookies
所有这些都是输入信号,但 Elasticsearch 中的评分机制保持不变。Elasticsearch 不需要知道你是如何推断这些 segment 的。这种关注点分离让 Elasticsearch 专注于排序,而你的应用或数据科学层负责推断 segment 的逻辑。
如何选择合适的提升权重
在我们的示例中,每个 cohort 使用 0.1。这个值是可调的。保持在 0.05 到 0.20 之间可能会有良好效果。你应该根据以下因素进行 A/B 测试权重:
- 目录多样性
- 每个产品的 cohort 标签数量
- BM25 的可变性
- 业务目标(收入 vs. 发现 vs. 个性化)
限制每个产品分配的 cohort 数量
给一个产品分配 20 个 cohort 标签会导致:
- 信号噪声
- 商家操纵("给所有东西打上 luxury 标签")
- 可解释性丧失
- 过度提升
作为起点(需通过你自己的测试确认),我们建议:
- 每个产品大约 5 个 cohort。
- 可选的离线验证步骤(ingest pipeline、CI 脚本或索引时检查),当分配超过 5 个标签时发出警告或阻止。
针对用户的自定义 cohort 提升
到目前为止,我们的示例假设每个 cohort 的贡献相同。实际上,有些用户对某些 segment 偏好很强。在某些情况下,你可能知道某些 cohort 对特定用户尤其重要。例如:
- 几乎总是购买奢侈品牌的用户
- 一直选择预算选项的用户
你可以通过为每个 cohort 分配不同权重来实现,而不是固定的 0.1。例如,如果你的应用检测到一个 "super-luxury" 购物者,那么可以如下修改 function scoring:
xml
`
1. "functions": [
2. { "filter": { "term": { "cohorts": "female" }}, "weight": 0.1 },
3. { "filter": { "term": { "cohorts": "beauty" }}, "weight": 0.1 },
4. { "filter": { "term": { "cohorts": "luxury" }}, "weight": 0.2 },
5. { "weight": 1.0 }
6. ]
`AI写代码在上述示例中,匹配 "female" 或 "beauty" 各增加 +0.1,而匹配 "luxury" 增加 +0.2。在这个示例中,匹配所有三个 cohort 的产品将得到:
ini
`boost = 1.0 + 0.1 + 0.1 + 0.2 = 1.4`AI写代码这仍然完全可解释,你可以记录配置("对于这个用户,luxury 的重要性是其他 cohort 的 2 倍")。此外,_explain API 会显示这些数值如何具体贡献到最终分数。
结论:
这种原生 Elasticsearch 的 cohort 个性化方法仅使用轻量级元数据和标准查询构造,同时保持可解释性、稳定性以及对相关性模型的业务控制。它提供精准、可预测的相关性,确保业务目标不会牺牲搜索结果质量。
实现总结
如果你想在生产环境中采用这种模式,高层步骤如下:
- 给每个产品添加一个单一 keyword 字段(cohorts),包含 3--5 个 cohort 标签。
- 在应用逻辑中计算用户/会话的 cohorts(来自浏览、购买历史、CRM 等),并随查询传递。
- 在查询中注入动态 function_score 过滤器,每个用户 cohort 一个,每个带一个小权重(例如 0.1),再加上基线权重(1.0)。
- 将现有 BM25 查询包裹在 function_score 中,使用 score_mode: "sum" 和 boost_mode: "multiply" 应用乘法提升。
- 根据 A/B 实验调优每个 cohort 权重(通常 0.05--0.20),确保 BM25 保持主要信号。
这些步骤让你可以在现有搜索相关性(elasticstack.blog.csdn.net/article/det... "搜索相关性")基础上干净地叠加 cohort 个性化,无需脚本、ML 模型或重大架构更改。
接下来做什么?
这个模式是如何直接在查询中构建复杂相关性规则的强大示例,确保速度和可靠性。
-
更快实现自定义个性化 :如果你准备部署并优化这一高级 cohort 个性化策略,或解决其他复杂相关性挑战,我们的团队可以帮助你快速构建、调优并投入运行 Elasticsearch 解决方案。联系 Elastic Services(www.elastic.co/consulting "Elastic Services") 获取实现此方案及其他高级搜索技术的帮助。
-
加入讨论 :关于高级相关性技术和实现的一般问题,可加入更广泛的 Elastic Stack 社区(discuss.elastic.co/ "更广泛的 Elastic Stack 社区"),参与搜索讨论。
原文:[[www.elastic.co/search-labs...](https://link.juejin.cn?target=https%3A%2F%2Fwww.elastic.co%2Fsearch-labs%2Fblog%2Fecommerce-search-relevance-cohort-aware-ranking-elasticsearch%255D( "https://www.elastic.co/search-labs/blog/ecommerce-search-relevance-cohort-aware-ranking-elasticsearch](")[www.elastic.co/search-labs...](https://link.juejin.cn?target=https%3A%2F%2Fwww.elastic.co%2Fsearch-labs%2Fblog%2Fecommerce-search-relevance-cohort-aware-ranking-elasticsearch "https://www.elastic.co/search-labs/blog/ecommerce-search-relevance-cohort-aware-ranking-elasticsearch") "www.elastic.co/search-labs...;)