一、字符串拼接与组合
基础拼接
-
CONCAT(str1, str2, ...):连接多个字符串,任意参数为NULL则结果为NULLsqlSELECT CONCAT('Hello', ' ', 'World') -- 'Hello World' -
CONCAT_WS(separator, str1, str2, ...):带分隔符拼接,自动跳过NULL值sqlSELECT CONCAT_WS('-', '2025', '12', '09') -- '2025-12-09'
数据库特有方式
- MySQL/PostgreSQL:支持
||运算符(PostgreSQL推荐) - SQL Server:支持
+运算符(注意类型转换问题) - Oracle:优先使用
||运算符
多行聚合拼接
| 数据库 | 函数 | 特点 |
|---|---|---|
| MySQL | GROUP_CONCAT([DISTINCT] expr [ORDER BY] [SEPARATOR]) |
支持去重和排序,默认长度限制1024 |
| PostgreSQL | string_agg(expr, separator [ORDER BY]) |
排序语法更简洁 |
| SQL Server | STRING_AGG(expr, separator) [WITHIN GROUP (ORDER BY)] |
2017+支持,2022+才支持排序 |
| Oracle | LISTAGG(expr, separator) WITHIN GROUP (ORDER BY) |
必须指定排序,有长度限制 |
sql
GROUP_CONCAT(
[DISTINCT] 字段名 -- 去重
[ORDER BY 排序字段 [ASC|DESC]] -- 排序
[SEPARATOR '分隔符'] -- 自定义分隔符
)
SELECT
country,
GROUP_CONCAT(DISTINCT city) AS unique_cities -- 自动去重
FROM locations
GROUP BY country;
SELECT
dept_id,
GROUP_CONCAT(
employee_name
ORDER BY hire_date DESC -- 按入职时间降序
SEPARATOR ' | ' -- 竖线分隔
) AS seniority_list
FROM employees
GROUP BY dept_id;
SELECT
project_id,
GROUP_CONCAT(
CONCAT(name, '(', emp_id, ')') -- 组合字段
SEPARATOR '; ' -- 分号分隔
) AS project_team
FROM project_members
GROUP BY project_id;二、字符串截取与提取
基础截取
-
SUBSTRING(str, start, length)/SUBSTR():从指定位置提取子串sqlSELECT SUBSTRING('Database', 4, 4) -- 'abas'(从第4位取4个字符) -
LEFT(str, length)/RIGHT(str, length):从左侧/右侧提取sqlSELECT LEFT('Example', 3), RIGHT('Example', 4) -- 'Exa', 'mple'
高级用法
-
动态截取:结合定位函数提取分隔符后的内容
sql-- 提取@后的域名 SELECT SUBSTRING(email, POSITION('@' IN email)+1) FROM users 函数分解: POSITION('@' IN email):查找@符号在email字段中的位置索引(从1开始计数) SUBSTRING(email, position_value + 1):从@符号后一位开始截取子字符串 示例: 若邮箱为user@example.com,结果为example.com 若邮箱为admin@company.co.uk,结果为company.co.uk -
反向截取:MySQL支持负数起始位置(从尾部计数)
sqlSELECT SUBSTRING('HelloWorld', -5) -- 'World'(倒数第5位开始)
三、字符串查找与定位
-
LOCATE(substr, str [, start])(MySQL):返回子串首次出现位置 -
INSTR(str, substr)(Oracle/PostgreSQL):同上,参数顺序相反sqlSELECT LOCATE('world', 'Hello world'), INSTR('Hello world', 'world') -- 均返回7(位置从1开始计数) -
POSITION(substr IN str):SQL标准语法,功能类似 -
CHARINDEX(substr, str)(SQL Server):功能相同
四、字符串替换
基础替换
-
REPLACE(str, old_sub, new_sub):全局替换指定子串sqlSELECT REPLACE('Hello world', 'world', 'SQL') -- 'Hello SQL'
正则替换(高级场景)
| 数据库 | 函数 | 示例 |
|---|---|---|
| MySQL | REGEXP_REPLACE(str, pattern, replace) |
REGEXP_REPLACE('a1b2c3', '[0-9]', '') → 'abc' |
| PostgreSQL | REGEXP_REPLACE(str, pattern, replace) |
支持更丰富的正则语法 |
| Oracle | REGEXP_REPLACE(str, pattern, replace [, flags]) |
可通过flags控制匹配模式 |
五、大小写转换与格式化
-
UPPER(str)/LOWER(str):大小写转换sqlSELECT UPPER('sql'), LOWER('SQL') -- 'SQL', 'sql' -
INITCAP(str)(PostgreSQL/Oracle):首字母大写sqlSELECT INITCAP('hello world') -- 'Hello World'
六、长度计算与修剪
长度计算(注意字符集影响)
-
LENGTH(str):返回字节长度(受字符集影响) -
CHAR_LENGTH(str):返回字符个数(与字符集无关)sql-- UTF-8环境下 SELECT LENGTH('你好'), CHAR_LENGTH('你好') -- 6(3字节/汉字), 2
修剪函数
-
TRIM([BOTH|LEADING|TRAILING] [remstr FROM] str):去除指定字符sqlSELECT TRIM(' Hello '), TRIM(LEADING 'x' FROM 'xxTest') -- 'Hello', 'Test' -
LTRIM(str)/RTRIM(str):仅去除左侧/右侧空格
七、高级字符串操作
填充函数
-
LPAD(str, len, padstr)/RPAD(str, len, padstr):左右填充sqlSELECT LPAD('123', 5, '0'), RPAD('123', 5, '0') -- '00123', '12300'
翻译函数
-
TRANSLATE(str, from_str, to_str):字符级替换sqlSELECT TRANSLATE('123-456', '14', 'AX') -- 'A23-X56'(1→A,4→X)
正则匹配
| 数据库 | 操作符/函数 | 示例 |
|---|---|---|
| MySQL | REGEXP / RLIKE |
WHERE name REGEXP '^[A-Z]' |
| PostgreSQL | ~(区分大小写)/ ~*(不区分) |
WHERE name ~* '^[a-z]' |
| Oracle | REGEXP_LIKE(str, pattern) |
WHERE REGEXP_LIKE(name, '^[A-Z]') |
| SQL Server | PATINDEX('%pattern%', str) |
功能有限,需用%通配符 |
八、数据库差异速查表
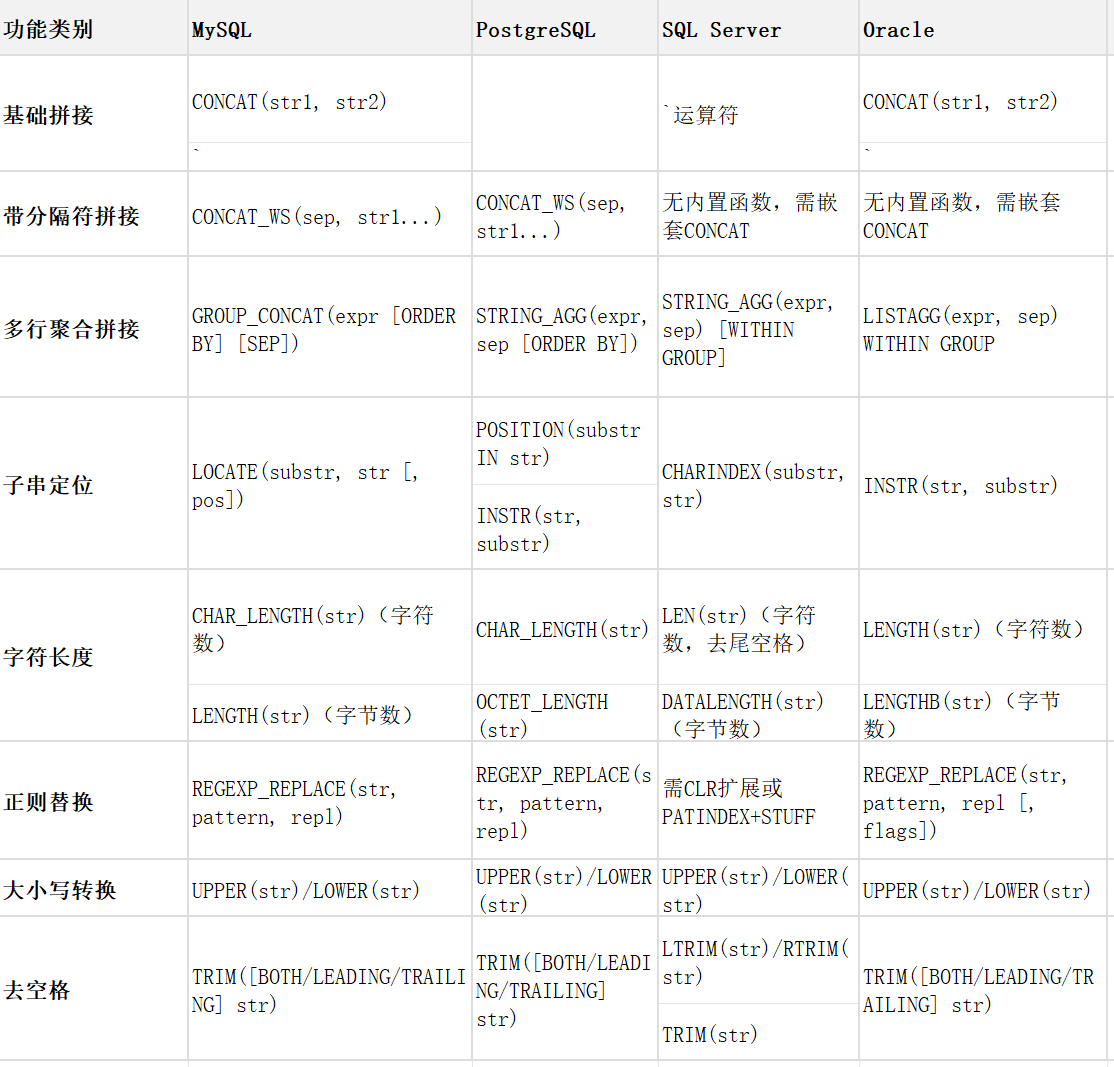
九、性能与最佳实践
-
索引使用:避免在WHERE子句中对索引列使用函数
sql-- 低效:无法使用索引 WHERE LOWER(username) = 'admin' -- 高效:提前标准化存储 WHERE username = 'admin' -- 存储时已转小写 -
NULL处理:优先使用CONCAT_WS处理可能为NULL的字段拼接
-
长度限制:使用GROUP_CONCAT时注意默认长度限制(MySQL)
SET SESSION group_concat_max_len = 1000000; -- 临时调整 -
字符集注意:处理多字节字符时,始终用CHAR_LENGTH判断字符数