相关难点:JSON结构混乱引发的连锁困境
在企业数字化转型进程中,非结构化数据的处理已成为核心课题------《福布斯》技术委员会预测,企业数据中80%为非结构化数据,涵盖合同、发票、简历、财报等多种形态。文档解析技术通过OCR、NLP等技术提取关键信息并输出JSON等结构化格式,本应成为破解数据利用难题的利器,但抽取出的JSON结构混乱问题,却让这一过程陷入新的困境,且痛点与企业实际业务高度关联。
首要痛点是数据复用效率极低。 混乱的JSON可能出现字段命名不统一(如"发票金额"同时存在"amount""invoice_money""sum"等多种表述)、层级嵌套无序(核心信息分散在多层嵌套中)、数据类型混乱(金额字段同时存在数字与字符串格式)等问题。财务部门需手动调整JSON格式才能导入对账系统,HR筛选简历时要逐一修正字段名称,原本期望的"自动化提取"最终沦为"半人工处理",与人工录入相比效率提升有限。
其次是数据准确性难以保障。 结构混乱的JSON常伴随信息缺失、字段错配等问题,例如发票解析后"供应商名称"字段与"纳税人识别号"内容错位,合同JSON中"签订日期"字段遗漏年份信息。人工修正过程中,面对海量数据极易出现新的疏漏,而财务对账、合规审计等场景对数据精度要求极高,此类问题可能引发财务风险或合规隐患。
最后是下游系统适配受阻。 企业的ERP、CRM、数据分析平台等下游系统,对输入JSON的格式、字段、数据类型有严格要求。混乱的JSON无法直接对接这些系统,需投入大量技术资源进行定制化开发适配,不仅增加了系统集成成本,还延误了数字化转型的推进周期,让非结构化数据提取的价值大打折扣。
方案介绍:JSON标准化输出的核心解决路径
JSON结构混乱的根源,在于文档解析过程中仅完成了"信息提取",却未实现"结构规整"。解决这一问题的核心方案,是构建"解析+后处理"的完整流程------以文档解析技术为基础提取原始信息,再通过后处理规则对JSON进行规整,其中"规则设计"与"工具支撑"是两大核心要素。
从技术逻辑来看,后处理方案需依托文档解析技术的延伸能力,实现"提取-规整-输出"的闭环。文档解析技术区别于传统OCR的核心优势的在于,它不仅能"识字",更能通过布局分析与语义理解识别信息的上下文关系,这为后处理规则的设计提供了基础------解析过程中记录的信息语义标签(如"金额""日期""姓名"),可作为后处理时字段规整的依据。
具体方案可分为"规则体系设计"与"工具落地支撑"两部分,典型方案如合合信息TextIn文档解析系统,能够精准还原pdf、word、excel、ppt、图片等十余种格式的非结构化文件,将其快速转换为JSON格式返回,同时包含精确的页面元素和坐标信息。 支持识别文本、图像、表格、公式、手写体、表单字段、页眉页脚等各种元素,并支持印章、二维码、条形码等子类型,为LLM推理、训练输入高质量数据,帮助完成数据清洗和文档问答任务,适用于各类AI应用程序,如知识库、RAG、Agent或其他自定义工作流程。
操作步骤讲解:JSON标准化的完整实施流程
登录TextIn文档解析系统,进入"Docflow"功能模块。
TextIn Doclfow的工作流程如下:
相关难点:JSON结构混乱引发的连锁困境
在企业数字化转型进程中,非结构化数据的处理已成为核心课题------《福布斯》技术委员会预测,企业数据中80%为非结构化数据,涵盖合同、发票、简历、财报等多种形态。文档解析技术通过OCR、NLP等技术提取关键信息并输出JSON等结构化格式,本应成为破解数据利用难题的利器,但抽取出的JSON结构混乱问题,却让这一过程陷入新的困境,且痛点与企业实际业务高度关联。
首要痛点是数据复用效率极低。 混乱的JSON可能出现字段命名不统一(如"发票金额"同时存在"amount""invoice_money""sum"等多种表述)、层级嵌套无序(核心信息分散在多层嵌套中)、数据类型混乱(金额字段同时存在数字与字符串格式)等问题。财务部门需手动调整JSON格式才能导入对账系统,HR筛选简历时要逐一修正字段名称,原本期望的"自动化提取"最终沦为"半人工处理",与人工录入相比效率提升有限。
其次是数据准确性难以保障。 结构混乱的JSON常伴随信息缺失、字段错配等问题,例如发票解析后"供应商名称"字段与"纳税人识别号"内容错位,合同JSON中"签订日期"字段遗漏年份信息。人工修正过程中,面对海量数据极易出现新的疏漏,而财务对账、合规审计等场景对数据精度要求极高,此类问题可能引发财务风险或合规隐患。
最后是下游系统适配受阻。 企业的ERP、CRM、数据分析平台等下游系统,对输入JSON的格式、字段、数据类型有严格要求。混乱的JSON无法直接对接这些系统,需投入大量技术资源进行定制化开发适配,不仅增加了系统集成成本,还延误了数字化转型的推进周期,让非结构化数据提取的价值大打折扣。
方案介绍:JSON标准化输出的核心解决路径
JSON结构混乱的根源,在于文档解析过程中仅完成了"信息提取",却未实现"结构规整"。解决这一问题的核心方案,是构建"解析+后处理"的完整流程------以文档解析技术为基础提取原始信息,再通过后处理规则对JSON进行规整,其中"规则设计"与"工具支撑"是两大核心要素。
从技术逻辑来看,后处理方案需依托文档解析技术的延伸能力,实现"提取-规整-输出"的闭环。文档解析技术区别于传统OCR的核心优势的在于,它不仅能"识字",更能通过布局分析与语义理解识别信息的上下文关系,这为后处理规则的设计提供了基础------解析过程中记录的信息语义标签(如"金额""日期""姓名"),可作为后处理时字段规整的依据。
具体方案可分为"规则体系设计"与"工具落地支撑"两部分,典型方案如合合信息TextIn文档解析系统,能够精准还原pdf、word、excel、ppt、图片等十余种格式的非结构化文件,将其快速转换为JSON格式返回,同时包含精确的页面元素和坐标信息。 支持识别文本、图像、表格、公式、手写体、表单字段、页眉页脚等各种元素,并支持印章、二维码、条形码等子类型,为LLM推理、训练输入高质量数据,帮助完成数据清洗和文档问答任务,适用于各类AI应用程序,如知识库、RAG、Agent或其他自定义工作流程。
操作步骤讲解:JSON标准化的完整实施流程
登录TextIn文档解析系统,进入"Docflow"功能模块。
TextIn Doclfow的工作流程如下:

输入文档:支持扫描上传、邮箱收票、SFTP定时、SMB共享、OneDriver、Sharepoint、API调用等多种方式
文件质量优化:基于TextIn图像处理技术,支持切边增强、多图切分、水印去除、印章检测、多套拆分等优化操作
文档分类:可根据需求,建立Invoice、Purchase Order、Debit Note、Credit Note、Credit Note、CN_VAT及其他分类作
抽取定位显示:我们通过TextIn DocFlow工作空间直观展示票据字段抽取的形式,用户也可以自定义字段。
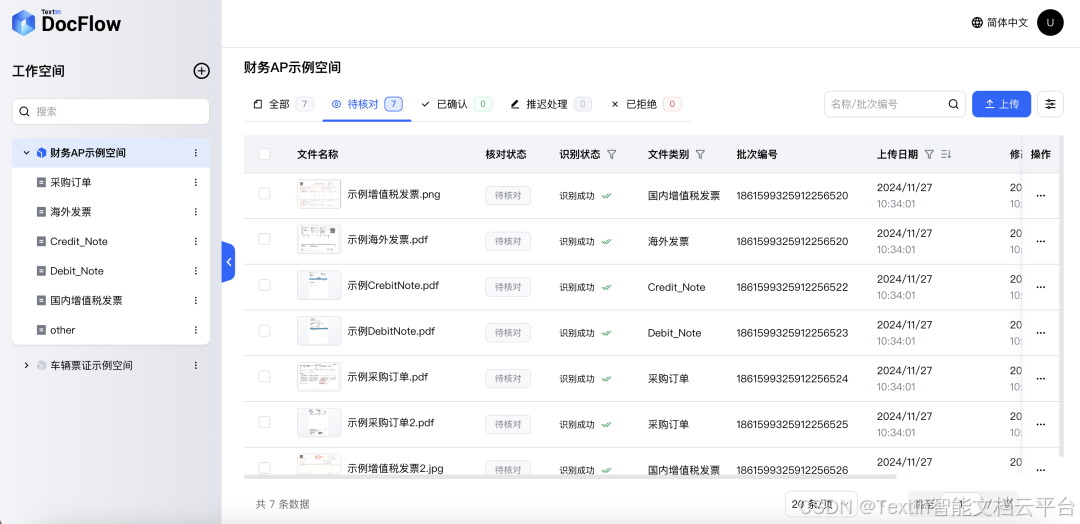
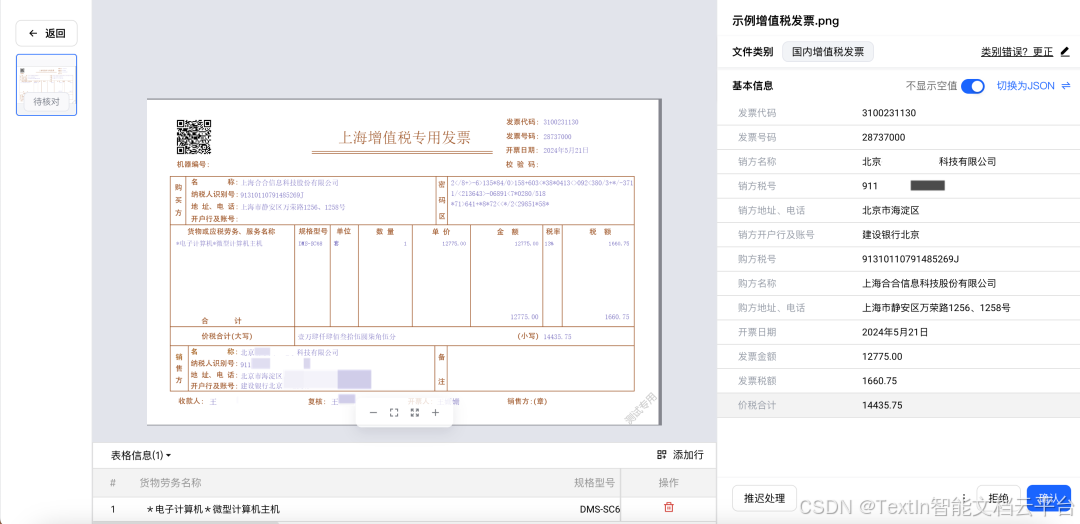
人工确认验证:业务人员可以对抽取结果进行核对确认。
TextIn DocFlow标准化工具拥有免训练开箱即用、灵活配置、产品组件化、集成便捷等特点。
优势亮点:后处理规则带来的核心价值提升
通过JSON标准化输出,不仅解决了结构混乱的直接问题,更从效率、成本、风险控制等多维度为企业创造价值,其核心优势相较于"无后处理的原始解析"显著突出。
其一,大幅提升数据复用效率。标准化JSON可直接对接下游业务系统,彻底摆脱"人工调整格式"的繁琐环节。财务部门处理发票的流程从"解析-修正格式-导入系统"简化为"解析-直接导入",HR筛选简历时可通过标准化字段快速检索关键信息,据企业实践数据统计,数据处理整体效率可提升60%以上,真正实现非结构化数据提取的自动化价值。
其二,保障数据准确性与一致性。通过标准化的字段命名、数据类型转换与校验机制,从源头规避了字段错配、数据格式混乱、信息缺失等问题。与人工修正相比,规则化处理可将数据错误率从人工操作的5%-8%降至0.1%以下,这对于财务对账、合规审计等高精度需求场景至关重要,有效降低因数据错误引发的业务风险。
其三,降低系统集成与维护成本。标准化JSON减少了下游系统的定制化适配需求,企业无需为不同来源的混乱JSON开发专属接口,显著降低系统集成成本。同时,后处理规则支持灵活调整,当业务场景或系统需求变化时,仅需在解析工具中修改规则配置,无需重构整体解析流程,后续维护成本降低50%以上。
其四,衔接文档解析与业务应用的核心环节。基于文档解析的语义理解能力,将提取的原始信息转化为符合业务需求的"可用数据",成为连接文档解析技术与企业实际业务的桥梁,让OCR、NLP等技术的价值真正落地到业务效率提升中。
客户案例:落地成效与数据见证
基于专业的文档解析和抽取能力,TextIn DocFlow能在多样化的场景下实现高效、稳定的票据自动化处理,满足业务需求。
- 财务应付
在应付账款的处理工作中,发票、采购订单、合同、出入库单据的匹配会消耗大量人力。对于涉及跨国业务的企业,该问题更为显著,普通自动化系统往往无法处理版式差异非常大的不同国家发票、单据,需要人工分拣并处理。
TextIn DocFlow能够辅助高效处理发票、匹配采购订单等交易材料,识别差异,减少人工核对可能出现的误差,验证付款并确保及时收款,提供实时报告,保持合规性,加快审批并改进现金流管理。
TextIn DocFlow也支持以插件形式便捷添加到现有系统中,兼容多种票据,同样适用于企业费用报销流程。
- 金融信贷业务
金融业务贷中审核环节,金融机构专注于业务流、信息流、物流、现金流的数据整合及交叉验证,但在产业端数字化水平有限以及合规审核要求严格的背景下,审核人员需要对业务合同、发票、运输单等大量纸质材料的关键信息进行细致的审核校验和交叉比对、认定此次业务的资产信息,继而通过动产融资统一登记公示系统对拟登记资产进行查重以确认其有效性,整个贷中审核过程耗费审核人员大量的时间和精力。
TextIn DocFlow可以通过快速评估申请人资料、评估风险因素、利用数据分析和生成审批建议,提高决策效率,同时确保合规性。
目前,TextIn DocFlow已投入部分跨国公司业务使用,我们收集到以下客户反馈总结:
在某集成电路龙头企业应用中,每单平均处理时间预期从30分钟降低至3分钟,10倍效率提升,避免录入的过程中的人工出错,历史数据可追溯,方便后期回诉;在某汽车行业跨国企业应用中,中国税法的合规稽核通过率99%。