ABSTRACT
本文研究了一种简单而强大的 Vision Transformer(ViT)密集预测任务适配器。与近期那些把视觉专用归纳偏差硬编码进结构的先进变体不同,普通 ViT 因先验假设弱,在密集预测上表现不佳。为此,我们提出 ViT-Adapter,它让普通 ViT 无需改造自身架构,就能达到视觉专用 Transformer 的精度。具体而言,框架主干仍是普通 ViT,可充分利用大规模多模态预训练;迁移到下游任务时,只需插入一个"免预训练"的轻量适配器,即可把图像相关先验注入模型,使其即插即用地完成检测、分割等任务。实验涵盖目标检测、实例分割和语义分割,ViT-Adapter-L 在 COCO test-dev 上分别取得 60.9 box AP 和 53.0 mask AP 的新纪录,且未使用额外检测数据。我们希望 ViT-Adapter 能成为视觉专用 Transformer 的通用替代品,并推动后续研究。代码与模型已开源:https://github.com/czczup/ViT-Adapter
1 INTRODUCTION
近年来,Transformer 在计算机视觉各领域取得了显著成功。得益于注意力机制动态建模能力和长程依赖特性,各类 Vision Transformer(Dosovitskiy 等,2020;Chen 等,2021;Han 等,2021;Li 等,2021c;Wu 等,2022b)迅速在目标检测、语义分割等诸多视觉任务中崛起,性能超越 CNN 模型并达到最先进水平。这些模型主要分为两大类:一类是普通 ViT(Dosovitskiy 等,2020;Touvron 等,2021),另一类是其分层变体(Dong 等,2021;Liu 等,2021b;Wang 等,2021;2022a)。总体而言,后者通过局部空间操作引入视觉特定的归纳偏置,因而通常能取得更佳效果。
然而,普通 ViT(即 vanilla Transformer)仍具备一些不可忽视的优势。典型的例子是多模态预训练(Zhu et al., 2021; 2022; Wang et al., 2022b)。由于 Transformer 源自自然语言处理领域,对输入数据没有任何假设,通过配备不同的分词器(如 patch embedding、Dosovitskiy et al., 2020;3D patch embedding、Liu et al., 2021c;以及 token embedding、Vaswani et al., 2017),普通 ViT 可以利用大规模的多模态数据(包括图像、视频和文本)进行预训练,从而学习到语义丰富的表征。然而,与视觉专用 Transformer 相比,普通 ViT 在密集预测任务上存在明显缺陷:缺乏与图像相关的先验知识,导致收敛速度较慢、性能较低,因而难以在密集预测任务中与视觉专用 Transformer(Huang et al., 2021b; Xie et al., 2021; Wang et al., 2022a)竞争。受 NLP 领域适配器(Houlsby et al., 2019; Stickland & Murray, 2019)的启发,本文旨在开发一种适配器,以缩小普通 ViT 与视觉专用骨干网络在密集预测任务上的性能差距。
为此,我们提出了 Vision Transformer Adapter(ViT-Adapter),这是一个无需预训练的附加网络,能够在不修改原始 ViT 架构的前提下,高效地将普通 ViT 适配到下游的密集预测任务。具体而言,为了将视觉特定的归纳偏置引入普通 ViT,我们为 ViT-Adapter 设计了三个定制模块:(1)空间先验模块,用于从输入图像中捕捉局部语义(空间先验);(2)空间特征注入器,用于将空间先验融入 ViT;(3)多尺度特征提取器,用于重建密集预测任务所需的多尺度特征。
如图1所示,与此前"先在ImageNet等大型图像数据集上预训练,再于下游任务微调"的范式相比,我们的新范式更加灵活:主干网络是通用模型(例如普通ViT),它不仅可以使用图像数据,还能利用多模态数据进行预训练;在迁移到密集预测任务时,我们仅引入一个随机初始化的适配器,即可将与图像相关的先验知识(归纳偏置)注入已预训练好的主干,使其无需修改结构就能胜任下游任务。由此,以ViT为骨干的框架在性能上可与Swin等专为视觉设计的Transformer相媲美,甚至更好。
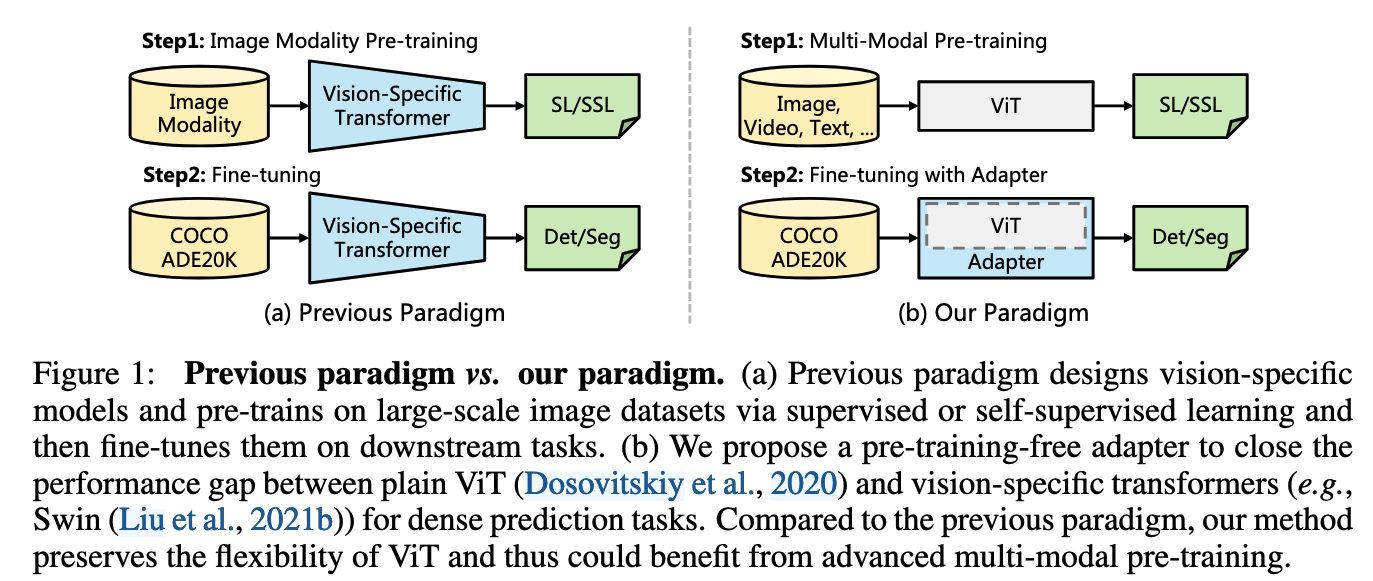
Our main contributions are as follows:
- 我们探索了一种新的范式,用于将视觉特有的归纳偏置(inductive biases)引入原始的 ViT(Vision Transformer)中。这种方式帮助 ViT 在仅使用常规 ImageNet 预训练的条件下,就可以达到与最近 Transformer 变体(Liu et al., 2021b;Wang et al., 2022a)相媲美的性能,并且在多模态预训练中进一步受益。
- 我们设计了一个空间先验模块(spatial prior module)以及两个特征交互操作,用于在不重新设计 ViT 架构的前提下,向其中注入图像先验。这些模块能够补充缺失的局部信息,并为密集预测任务重组细粒度的多尺度特征。
- 我们在多个具有挑战性的基准数据集上评估了 ViT-Adapter,包括 COCO(Lin et al., 2014)和 ADE20K(Zhou et al., 2017)。如图 2 所示,在公平的预训练策略下,我们的模型在性能上持续优于之前的工作。例如,在仅使用 ImageNet-1K 预训练时,ViT-Adapter-B 在 COCO val 上获得了 49.6 的 box AP,比 Swin-B 高出 1.0 个百分点。得益于多模态预训练(Peng et al., 2022),我们的 ViT-Adapter-L 在 COCO test-dev 上达到了 60.9 的 box AP,这是在未使用 Objects365(Shao et al., 2019)等额外检测数据进行训练的情况下目前最好的成绩。
2 RELATED WORK
**Transformers.**近年来,Transformer 已称霸自然语言处理、计算机视觉、语音识别等多模态任务。最初的 vanilla Transformer(Vasovani 等,2017)为机器翻译而生,至今仍是 NLP 的标杆;ViT(Dosovitskiy 等,2020)首次几乎原封不动地把这一架构搬到图像分类。随后,PVT(Wang 等,2021)与 Swin(Liu 等,2021b)引入 CNN 式金字塔结构,赋予模型更多视觉归纳偏置;Conformer(Peng 等,2021)则首次将 CNN 与 Transformer 并联。近来,BEiT(Bao 等,2022)和 MAE(He 等,2021)通过掩码图像建模把 ViT 推向自监督预训练,再次验证普通 ViT 的潜力。尽管设计视觉专用模型是重要方向,但通用架构(如普通 ViT)在掩码建模与多模态预训练中更为灵活且不可或缺。因此,我们开发了一种无需预训练的适配器,在不改动 ViT 结构的前提下注入图像先验,既保留其通用性,又能享受先进多模态预训练的红利。
Decoders for ViT. 密集预测架构通常采用编码器-解码器模式:编码器提取丰富特征,解码器将其聚合并转化为最终预测。近来,借助 ViT 的全局感受野,许多研究直接以 ViT 为编码器,再设计任务专用解码器。SETR(Zheng 等,2021)率先将 ViT 作为骨干,配合多种 CNN 解码器进行语义分割;Segmenter(Strudel 等,2021)同样把 ViT 扩展到分割,但使用 Transformer 解码器;DPT(Ranftl 等,2021)则通过 CNN 解码器把 ViT 用于单目深度估计,取得显著改进。总体而言,这些方法通过设计模态和任务相关的解码器提升了 ViT 的密集预测性能,但仍未解决 ViT 单尺度、低分辨率表征的根本缺陷。
**Adapters.**迄今为止,适配器(adapter)已在自然语言处理领域被广泛应用。PALs(Stickland & Murray, 2019)和 Adapters(Houlsby et al., 2019)在 Transformer 编码器中引入新模块,实现针对特定任务的快速微调,使预训练模型能迅速适配下游 NLP 任务。在计算机视觉领域,也有研究者提出将适配器用于增量学习(Rosenfeld & Tsotsos, 2018)和领域自适应(Rebuffi et al., 2017; 2018)。随着 CLIP(Radford et al., 2021)的出现,许多基于 CLIP 的适配器(Gao et al., 2021; Sung et al., 2021; Zhang et al., 2021)被提出,用于将预训练知识迁移到零样本或少样本下游任务。近期,Li et al. (2021b) 和 ViTDet(Li et al., 2022b)通过引入上采样和下采样模块,尝试将普通 ViT 适配到目标检测任务,如图 3(a) 所示。然而,在常规训练设置下(即使用 ImageNet 监督预训练并微调 36 个 epoch),它们的检测性能仍落后于近期那些充分结合图像先验的模型(Chu et al., 2021b; Dong et al., 2021; Wang et al., 2022a; Wu et al., 2022b)。因此,为 ViT 设计一个强大的密集预测任务适配器仍然是一项挑战。
3 VISION TRANSFORMER ADAPTER
3.1 OVERALL ARCHITECTURE
如图4所示,我们的模型可拆成两部分:
第一部分是普通 ViT(Dosovitskiy 等,2020),由 Patch Embedding 和 L 层 Transformer 编码器组成(图 4(a))。
第二部分是提出的ViT-Adapter(图 4(b)),包含:
1. Spatial Prior Module------从输入图像提取空间局部特征;
2. Spatial Feature Injector------将这些空间先验注入 ViT;
3. Multi-Scale Feature Extractor------把 ViT 的单尺度输出重建为密集预测所需的多层级特征。
对于ViT,首先将输入图像输入到块嵌入中,其中图像被划分为16 × 16个互不重叠的块。之后,这些图像块被展平并投影到D维tokens中,特征分辨率降低到原始图像的1 / 16。然后,这些令牌加上位置嵌入,通过L个编码器层。
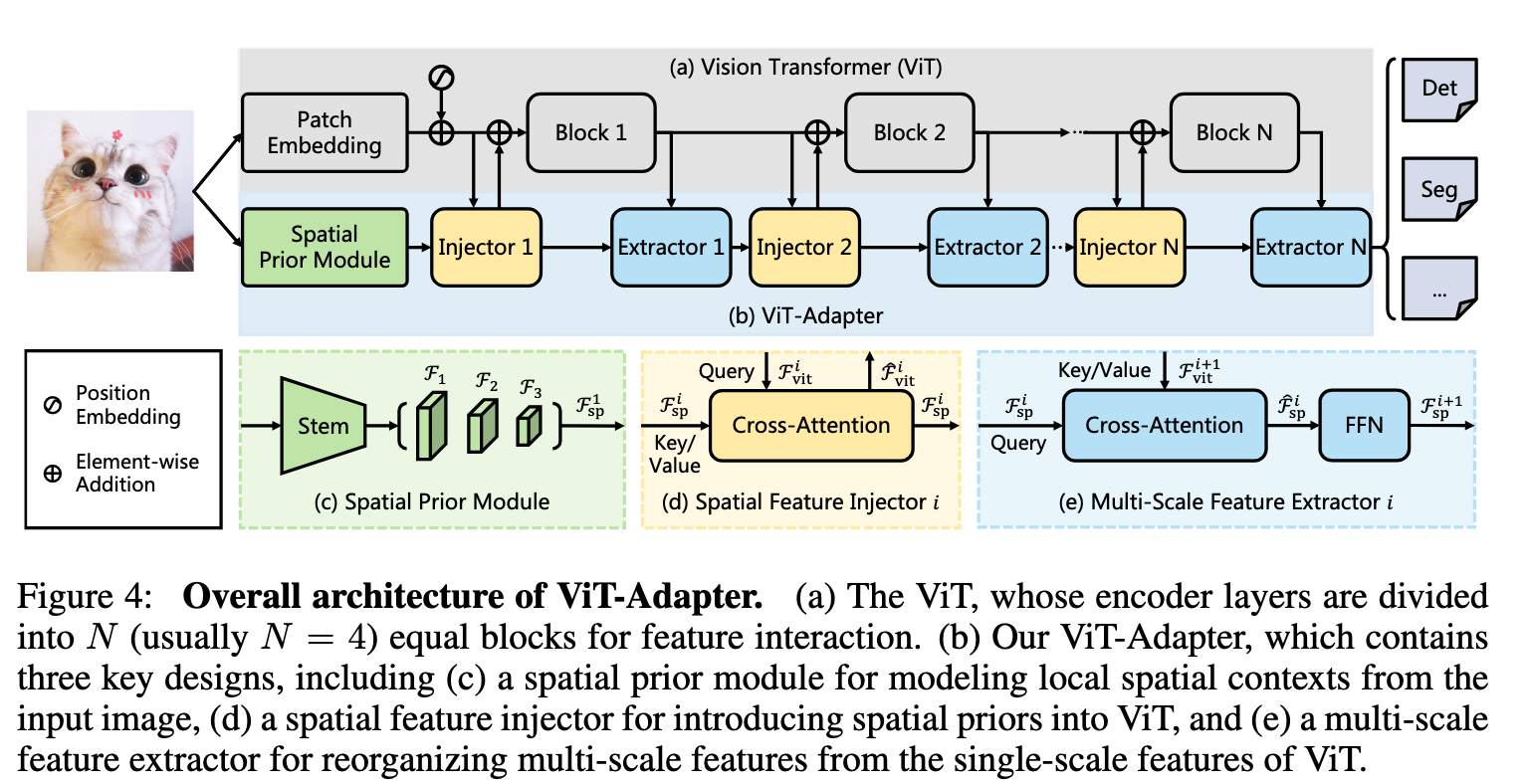
对于 ViT-Adapter,我们首先将输入图像送入空间先验模块,获得三种分辨率(1/8、1/16、1/32)的 D 维空间特征图;随后将这些特征图展平并拼接,作为后续特征交互的输入。具体而言,设交互次数为 N(通常取 4),我们将 ViT 的 L 层 Transformer 编码器均分为 N 个块,每块包含 L/N 层。对于第 i 个块,先通过空间特征注入器将空间先验 F_i^sp 注入该块,再通过多尺度特征提取器从块输出中抽取层次化特征。完成 N 次交互后,得到高质量的多尺度特征,并将其重新拆分为 1/8、1/16 和 1/32 三种分辨率;最后,用 2×2 反卷积对 1/8 特征图上采样,得到 1/4 特征图。由此构建出与 ResNet(He 等,2016)类似分辨率的特征金字塔,可直接用于各类密集预测任务。
3.2 SPATIAL PRIOR MODULE
最近的研究( Wang et al , 2022a ; Wu et al , 2021 ;方军雄等, 2022 ; Park & Kim , 2022)表明卷积可以帮助Transformer更好地捕获局部空间信息。受此启发,我们引入空间先验模块( Spatial Prior Module,SPM )。它旨在与块嵌入层并行地对图像的局部空间上下文进行建模,从而不改变ViT的原始架构。
如图 4(c) 所示,我们借用了 ResNet(He 等,2016)的标准卷积茎干:先由"3 个卷积 + 1 个最大池化"构成初始下采样;接着堆叠若干 stride=2 的 3×3 卷积,每步通道数翻倍、分辨率减半;最后再用几个 1×1 卷积把通道统一投影到 D 维。如此得到空间分辨率分别为 1/8、1/16 和 1/32 的三层特征图 {F1, F2, F3},它们都是 D 维通道。随后将这些特征图展平并拼接,形成长度为 (HW/8² + HW/16² + HW/32²) 的 token 序列 Fs1p ∈ R^(...×D),作为后续与 ViT 交互的"空间先验"输入。
3.3 FEATURE INTERACTION
由于较弱的先验假设,普通视觉里程计在稠密预测任务上的表现不如特定于视觉的变换( Chu et al , 2021a ; Dong et al . , 2021 ; Liu et al . , 2021b ; Wang et al , 2022a)。为了缓解这个问题,我们提出了两个特征交互模块来桥接SPM和ViT的特征图。具体来说,这两个模块主要基于交叉注意力,即空间特征注入器和多尺度特征提取器。
Spatial Feature Injector. 
Multi-Scale Feature Extractor.
在将空间先验注入 ViT 之后,我们将增强后的特征送入 ViT 的第 i 个 block 的剩余编码层,以获得输出特征
,随后,如图 4(e) 所示,我们对空间特征再应用一个由 交叉注意力层(Cross-Attention)和 前馈网络(FFN)组成的模块,以提取多尺度特征。该过程可以表示为:
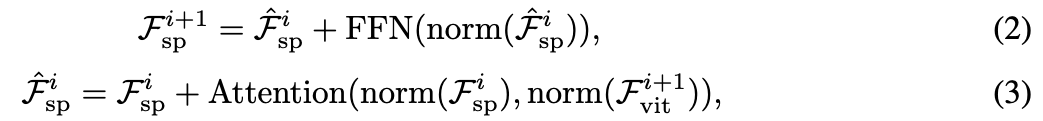

3.4 ARCHITECTURE CONFIGURATIONS
我们为四种尺寸的 ViT 构建了 ViT-Adapter,涵盖 ViT-T、ViT-S、ViT-B 与 ViT-L,对应适配器的参数量分别为 2.5M、5.8M、14.0M 和 23.7M。默认采用可变形注意力(Deformable Attention,Zhu et al., 2020)作为稀疏注意力机制,采样点数固定为 4,注意力头数依次设为 6、6、12、16。特征交互次数 N 取 4,并在最后一次交互中堆叠三个多尺度特征提取器以强化层次表达。此外,我们将适配器中的 FFN 压缩比例设为 0.25 以降低计算量,四种尺寸对应的隐藏维度分别为 48、96、192、256。更多配置细节见附录 B 表 10。