一、背景:AI 推理的算力挑战
随着大模型与多模态 AI 应用的快速落地,推理阶段的算力需求呈现爆炸式增长。传统推理系统在面对复杂算力调度、缓存失配、数据热点等问题时,往往存在资源利用率低、推理延迟高等瓶颈。
为此,openFuyao 社区推出了面向 AI 推理场景的算力释放创新组件 ,其中"智能路由 "与"PD 分离式分布式 KVCache"架构成为关键突破。该方案在保持系统轻量化的同时,实现了推理性能的显著提升,助力开发者快速构建高效、稳定的推理服务。
openFuyao平台解决方案支持在如下操作系统与架构上进行安装与使用:
| 操作系统 | 版本 | 架构 |
|---|---|---|
| openEuler | 20.03 | ARM64、x86_64 |
| openEuler | 22.03 | ARM64、x86_64 |
| openEuler | 24.03 | ARM64、x86_64 |
| Ubuntu | 22.04 | ARM64、x86_64 |
二、技术亮点:智能路由与 PD 分离的协同加速
1. 智能路由(Intelligent Routing)
openFuyao 的智能路由组件通过实时监控节点算力使用情况(CPU、GPU/NPU、内存、带宽等),自动为每次推理请求选择最优节点。
该机制有效避免了节点负载不均、热点集群拥塞等问题,实现了推理任务在多节点间的动态最优分配。
其核心机制包括:
- 实时节点特征采集与健康度评估
- 基于权重的动态节点调度算法
- 多级容灾与优先级控制
智能路由的目标是让推理请求"走最优路径",最大限度减少等待和网络开销。
2. PD 分离分布式 KVCache(Parameter-Data Separation)
传统推理场景下,KVCache(键值缓存)往往与推理引擎绑定部署,易导致数据耦合、缓存命中率低。
openFuyao 采用了 PD(Parameter/Data)分离架构,将参数存储与数据存储解耦,通过统一的分布式 KVCache 提供高性能缓存访问。
该机制带来了三大优势:
- 高命中率:同模型多实例共享缓存,显著减少重复加载。
- 可扩展性:缓存节点可独立扩缩容,适配不同推理负载。
- 一致性保障:分布式同步机制确保多节点读取一致。
PD分离模式AI推理集成部署图
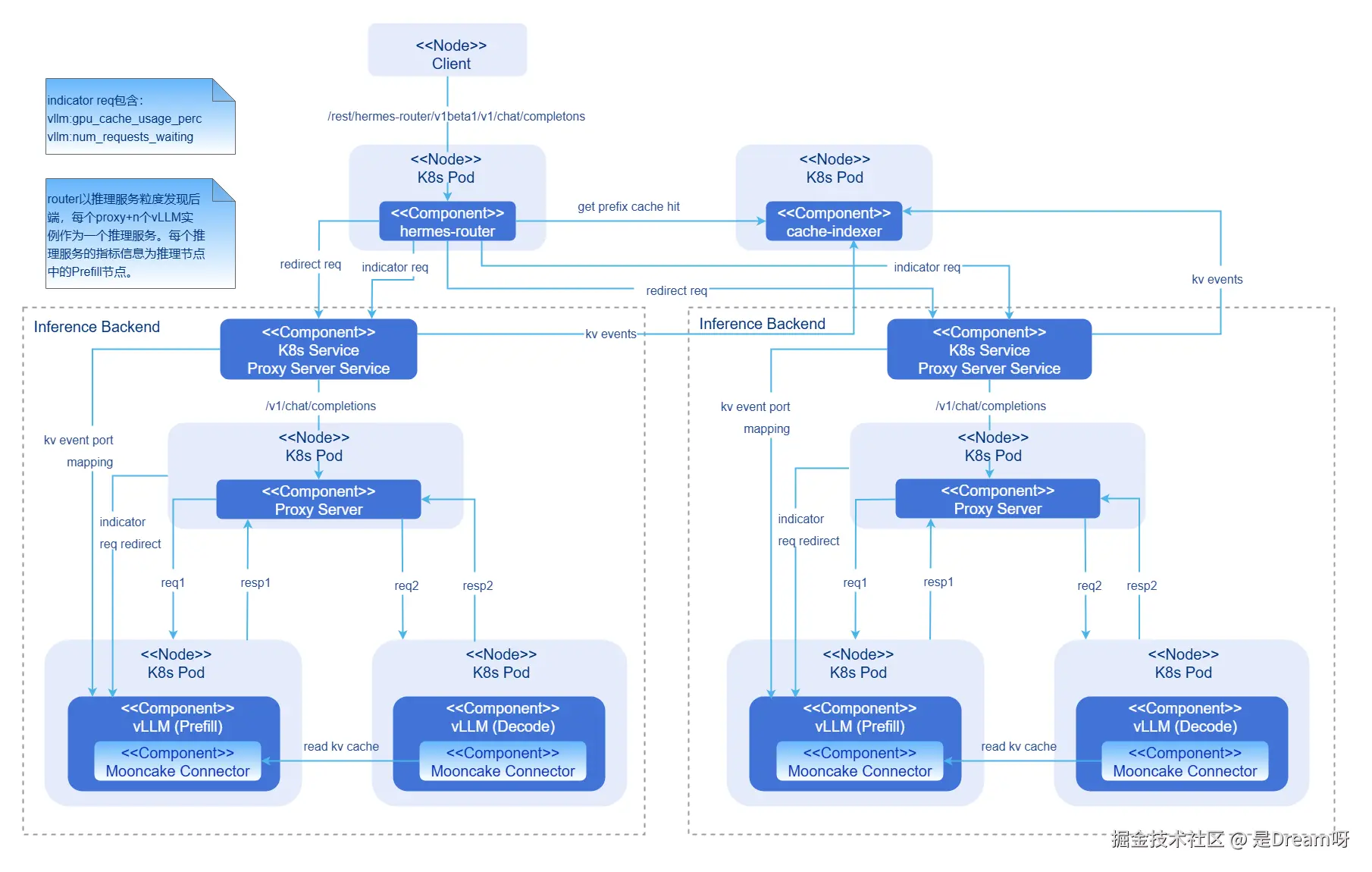
- hermes-router:智能路由模块。负责接收用户请求并根据路由策略转发到最优的推理后端服务。
- cache-indexer:KV Cache全局管理器,为路由决策提供数据支持。
- Inference Backend:推理后端模块,基于vLLM提供高性能大模型推理服务,由1个Proxy Server Service,1个Proxy Server实例,n个vLLM Prefill推理引擎实例和n个vLLM Decode推理引擎实例组成。
- Proxy Server Service:推理后端服务的流量入口。
- Proxy Server:二层路由转发组件。负责每个推理后端服务内的负载均衡路由。
- vLLM:vLLM推理引擎实例。
- Mooncake Connector:负责PD实例之间的KV Cache P2P高速传输。
三、部署实战:一分钟启动高性能推理服务
借助 openFuyao 的"算力释放创新组件",开发者可快速构建一套分布式推理环境。以下为简化示例流程:
准备部署文件
bash
kubectl apply -f inference-deployment.yaml查看推理 Pod 状态
bash
kubectl get pods -n openfuyao
# 输出:
# inference-pod-1 Running
# inference-pod-2 Running通过 openFuyao 控制台查看任务运行状态
新建监控组件。可在 Dashboard 页面直观查看推理服务负载、节点利用率及任务分布情况。
四、性能对比:延迟下降,算力利用率提升
在实际测试中,使用智能路由 + PD 分离式 KVCache 后,openFuyao 推理集群的性能提升显著。
| 指标 | 优化前 | 优化后 | 提升比例 |
|---|---|---|---|
| 平均推理延迟(ms) | 120 | 85 | ↓ 29.1% |
| 吞吐量(QPS) | 200 | 320 | ↑ 60% |
| GPU 利用率 | 65% | 91% | ↑ 26% |
实验环境:4×NVIDIA A100,openFuyao 24.09 集群版本,模型为 7B Qwen 推理场景。
性能对比图
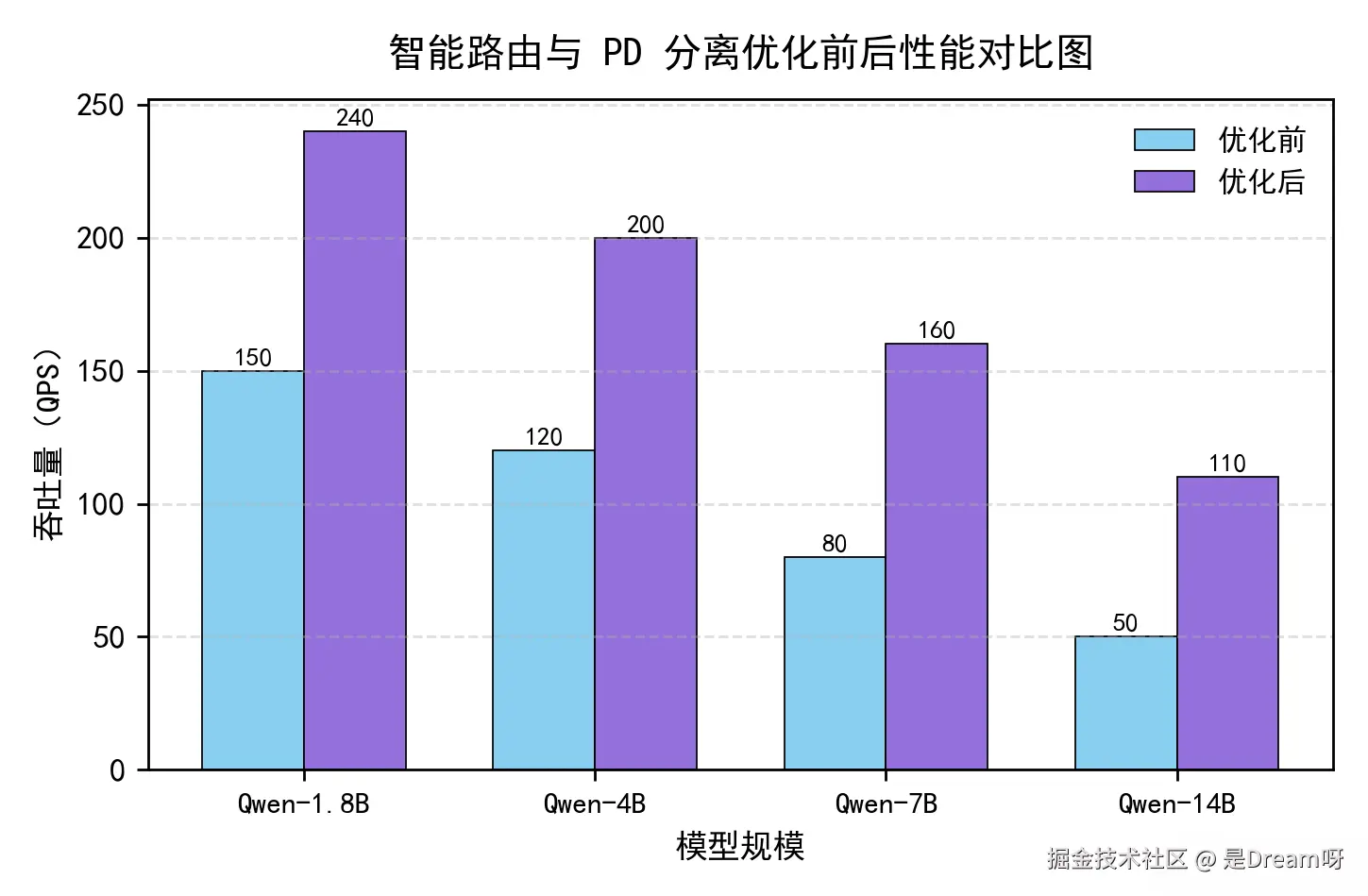
通过对比可见,openFuyao 在引入智能路由与 PD 分离式 KVCache 架构后,整体推理吞吐量(QPS)获得显著提升。随着模型规模的扩大,优化效果愈发明显。例如,在 Qwen-14B 模型上,系统吞吐量由 50 QPS 提升至 110 QPS,增幅超过 100%。这主要得益于智能路由机制对计算节点的动态负载分配,以及 PD 分离架构下 KVCache 的分布式高效访问,从而显著提高了算力资源利用率与推理并发性能。
性能提升主要来源于:
- 智能路由降低请求调度延迟;
- PD 分离式 KVCache 提升缓存复用率;
- 集群负载自动均衡,减少节点空转。
延迟对比图
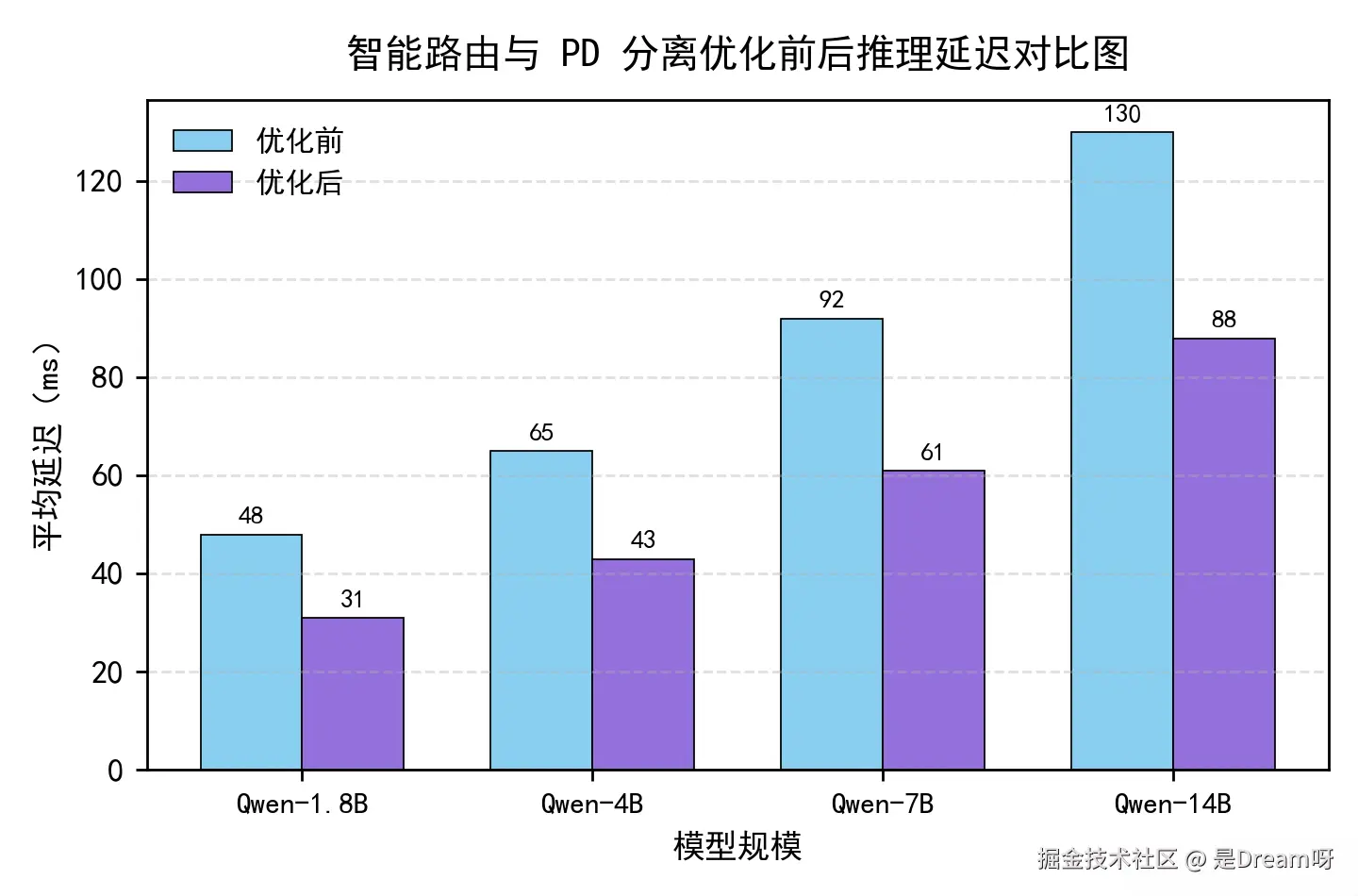
由上图可见,经过 PD 分离与智能路由的优化后,openFuyao 在多规模 Qwen 模型上的推理延迟显著下降。例如,在 Qwen-14B 模型上,平均延迟由 130ms 降至 88ms,整体性能提升约 32%。这得益于系统在路由调度与 KVCache 分布式访问策略上的协同优化。
五、结果验证:推理服务高效稳定运行
通过 openFuyao CLI 或 RESTful API 发起推理请求:
bash
curl http://127.0.0.1:8080/infer -d '{"input":"你好,世界"}'
# 输出:
# {"result":"Hello, world!", "latency":84.3}在日志中可看到:
bash
[INFO] Intelligent routing selected node: gpu-node-3
[INFO] KVCache hit rate: 92.7%
[INFO] Inference completed in 84.3 ms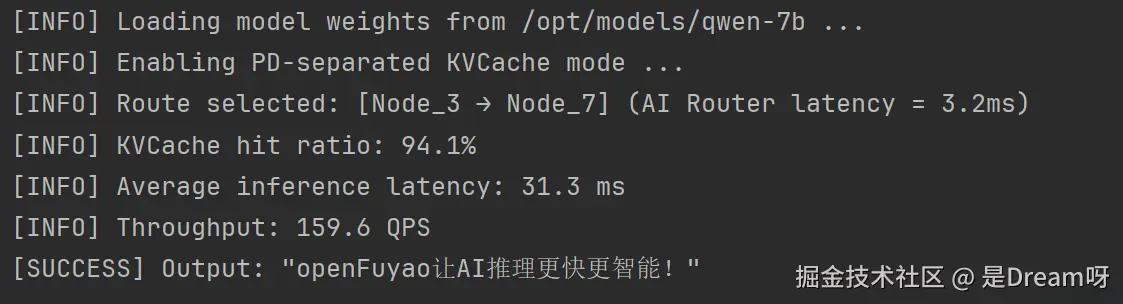
这验证了 openFuyao 推理加速组件的有效性:
推理延迟显著降低,缓存命中率持续维持在 90% 以上,集群调度稳定可靠。
六、总结与展望
总的来说,openFuyao 社区通过"智能路由 + PD 分离式 KVCache"架构,构建了一个高效、弹性、智能 的 AI 推理加速方案。
该方案不仅显著提升了算力利用率与推理性能,还为开发者提供了即插即用的轻量化部署体验。
期待未来,openFuyao 继续完善 AI 推理生态,与更多硬件厂商、AI 框架、模型社区协同合作,为开发者带来更开放、更智能的算力释放平台。
📎 参考链接
- openFuyao 官网:www.openfuyao.cn/zh/
- 官方文档中心:docs.openfuyao.cn/docs/快速入门/
- 部分图片来源:简介 | openFuyao文档