一、背景介绍
七猫公司介绍及业务规模
- 七猫是一家深耕文化娱乐行业的互联网企业,总部坐落在上海市前滩中心。七猫旗下原创文学网站七猫中文网于2017年5月正式上线,专注为原创作者提供创作指导、版权运营等全方位一体化服务。七猫拳头产品七猫免费小说 App 于2018年8月正式上线,专注为用户提供正版、免费、优质的网络文学内容阅读服务。现平台用户超 6 亿,规模位列数字阅读行业前列。

原有大数据架构
- 七猫的数仓团队主要是承接七猫各条业务线的离线数据开发、实时数据开发、指标建设、数据治理等工作。
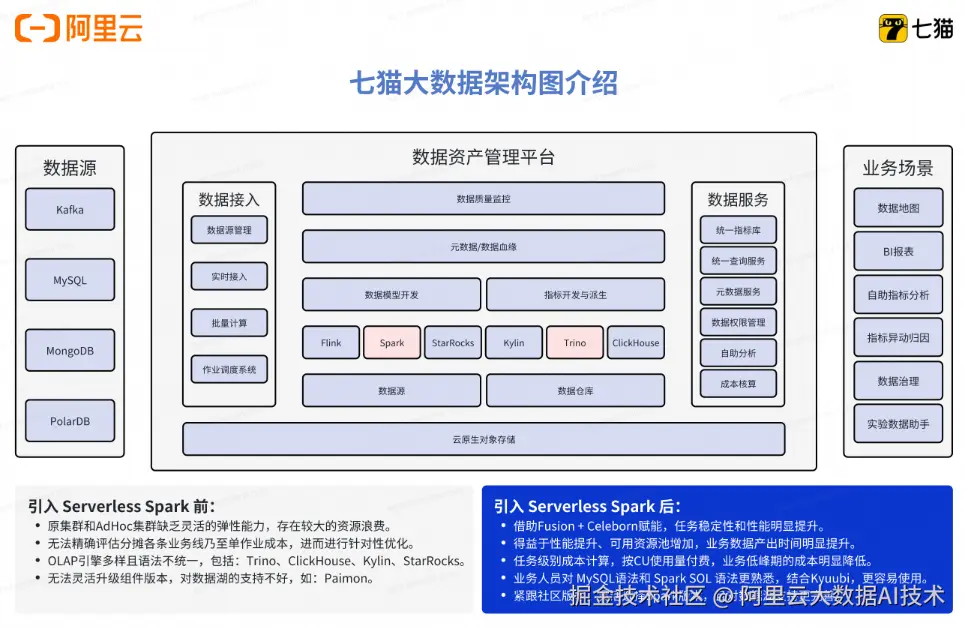
架构痛点分析(多业务线带来复杂分析需求/计算性能瓶颈/开发运维门槛高成本大.......)
1、需求复杂,同时支持数仓工程师,数据分析师,算法工程师等多岗位计算需求
2、计算成本高
- 传统数仓任务在半托管集群下只支持开源 Spark,无法充分利用业界领先的 Native 加速和Remote Shuffle Service 技术提升整体性能进而降本
- 半托管集群和 adhoc 集群缺乏灵活的弹性能力,存在较大的资源浪费
3、 运维复杂
- 半托管集群在资源层需要一定人力介入运维
- Spark 引擎升级,Python 环境管理等常见运维操作复杂且有较大生产风险
- 无法精确评估各条业务线乃至单作业成本,进而进行针对性优化
二、为什么选择阿里云 EMR Serverless Spark
(一)Fusion + Celeborn 赋能,批处理性能全面提升超 50%
在大数据计算场景中,任务性能一直是关注的核心指标。为进一步提升计算效率,Serverless Spark 推出了 Fusion 加速能力,通过向量化SQL加速技术,显著缩短作业执行时间。同时,Serverless Spark 内置了企业级 Celeborn,大幅提升大 Shuffle 作业的稳定性和性能。为验证实际效果,我们选取了三个典型的批处理任务,对比传统 Yarn 环境和 Serverless Spark 的执行效率。
用户行为增量分析任务
- 资源配置: 500C,1500G
- Yarn:32 分钟
- Serverless Spark:10 分钟,提速 69%
Celeborn 有效减少了宽依赖阶段的任务调度与 Shuffle 开销,使整个计算链路更加高效。
用户日志明细处理任务
- 资源配置:500C,1200G
- Yarn:30 分钟
- Serverless Spark:14 分钟,提速 53%
在典型的日志清洗与聚合任务中,Fusion 加速显著提升了宽表 Join 与聚合计算的执行效率。
内容聚合与统计任务
- 资源配置:800C,1200G
- Yarn:71 分钟
- Serverless Spark:38 分钟,提速 46%
面对高达 11TB 的 Shuffle 数据量,Serverless Spark 依然保持稳定的执行性能,有效降低任务时延。
整体来看,Serverless Spark 对计算密集型和IO密集型任务都有大幅优化,三个任务平均提速超过 56%,在复杂 ETL 与大规模数据处理场景中展现出显著优势。相比传统 Yarn 集群,Serverless Spark 不仅具备更强的弹性能力和更低的资源使用成本,通过 Fusion + Celeborn 的优化,更是实现了计算效率与资源性价比的双重提升。 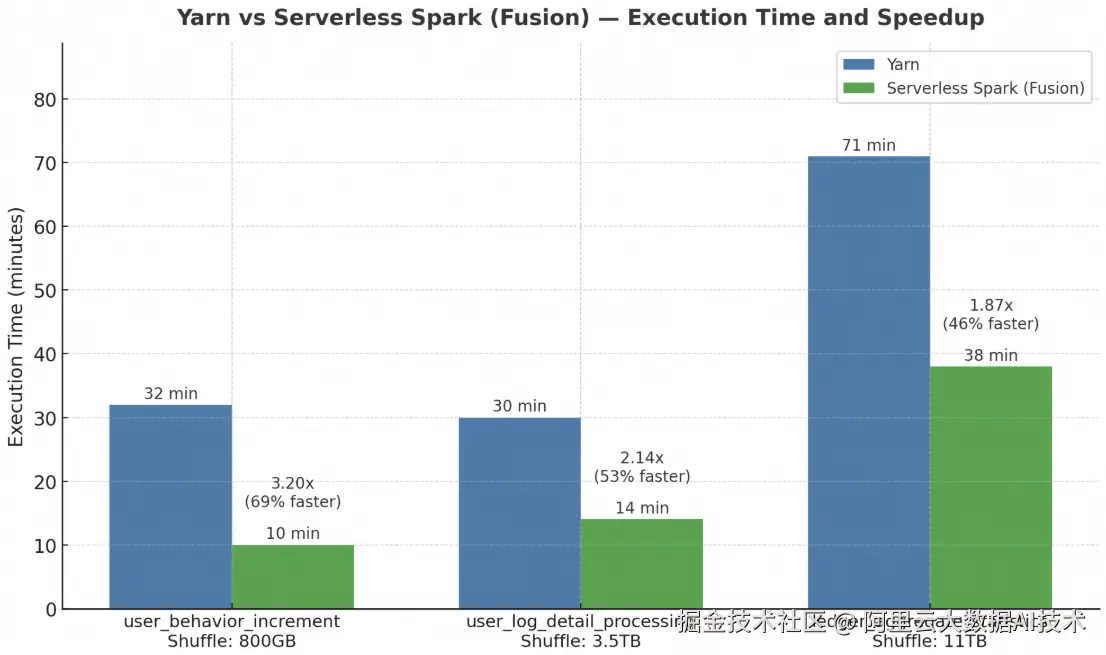
(二)Serverless 模式突破算力瓶颈,实现弹性敏捷的数据处理
📌 问题:传统架构难以应对算力潮汐与资源刚性约束
随着七猫数据作业规模持续增长,大数据集群长期处于高负载运行状态。原有架构存在一些问题:如缺乏灵活的弹性能力,而在白天又存在资源浪费。 传统模式已无法支撑"按需响应、准时交付"的现代数据服务要求,并且原先基于实例级别的资源交付方式,在潮汐时存在浪费。 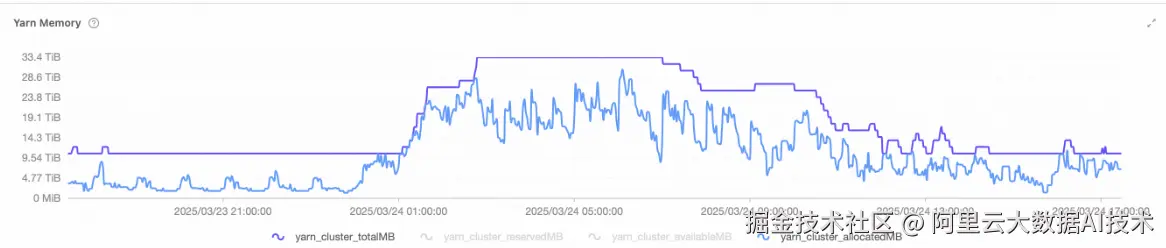
✅ 解决方案:引入 Serverless 弹性算力,构建智能调度新范式
七猫全面拥抱云原生理念,采用 Serverless 模式重构计算层,实现面向业务负载的动态资源供给。核心举措包括:
引入 Serverless Spark ,基于 OSS-HDFS 统一存储层实现计算与存储彻底解耦,支持计算资源秒级弹性伸缩;
利用 Serverless Spark 海量资源池与容器化调度能力,实现 最小粒度 1 核 的精细化资源计量,按实际使用量计费,彻底告别资源预占;
基于 Dataworks 提供的友好的用户交互界面,可以提交管理 Streaming/SQL/PySpark 等多类作业。
高峰期算力爆发能力大幅提升,分钟内即可弹出数千核 vCore 资源,满足瞬时高并发处理需求。该模式实现了从"资源驱动调度"向"业务需求驱动执行"的根本转变。 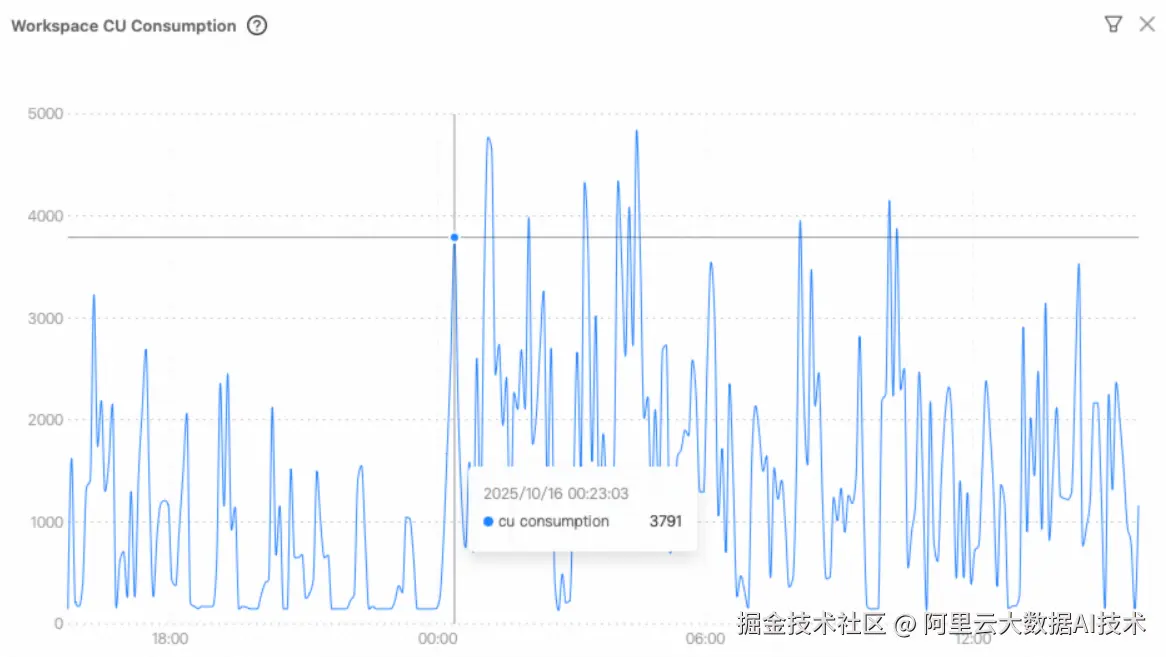
三、技术方案设计 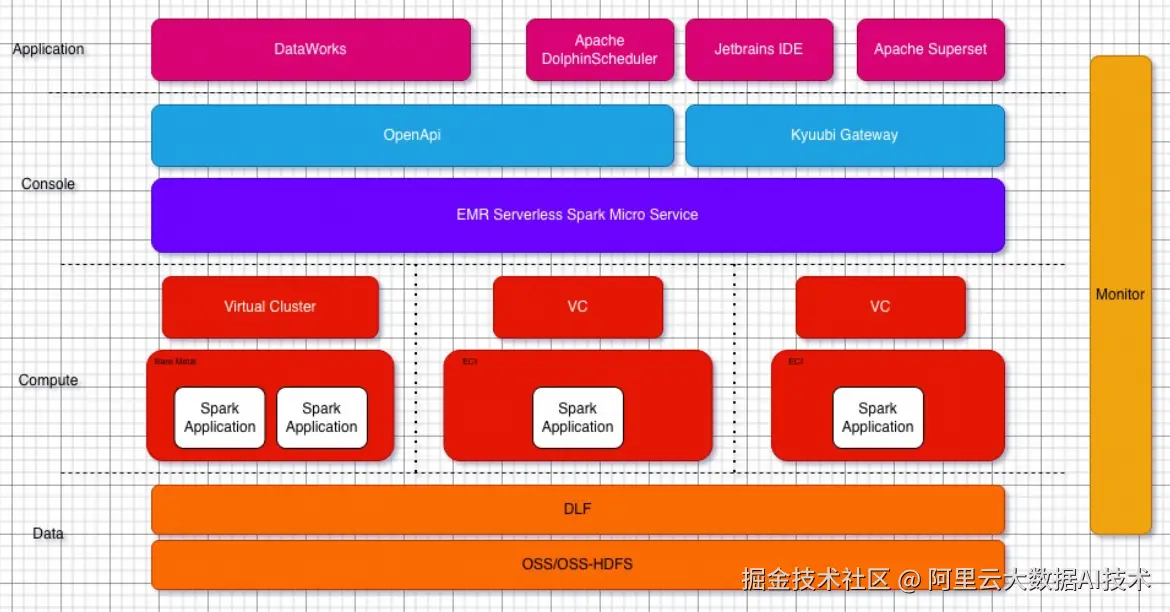
应用层
- 基于阿里云 DataWorks 和自建 Apache DolphinScheduler 进行数仓开发。
- 基于 Jetbrains IDE 产品和自建 Apache Superset 进行报表分析和 adhoc 查询。
接入层
- 通过接入 EMR Serverless Spark 官方提供的 spark-submit 工具进行数仓调度,该工具100%兼容开源 spark-submit 工具,为数仓的整体迁移提供了巨大的便利。
- 通过接入 EMR Serverless Spark 的 Kyuubi Gateway 进行日常数据分析和即席查询。Kyuubi Gateway 同样也提供了100%兼容开源的 restful 和 jdbc 接口,另外在开源基础上增强了云原生部署环境下的稳定性和提交并发性能。
管控面
- 用户无感的全链路多 AZ 高可用,提供稳定安全7 * 24小时的 PAAS 服务。
- 通过资源队列管理能力隔离不同业务团队的资源使用,业务峰谷时期能够快速进行资源上限调整。
- 通过作业级别管理能力进行日常的作业运维和调优,资源使用情况可细化到作业维度,易于进行针对性成本优化。
计算面
-
引擎能力
-
- 数仓 SQL 作业默认开启 fusion 加速提升 SQL 执行性能
-
- 默认使用内置 Celeborn 服务进行 Shuffle,提升大 Shuffle 稳定性
-
极致弹性
-
- 兼容开源 Spark 资源配置支持最短弹性步长为1CU的弹性能力
-
- 依赖资源底座服务保障资源供给
四、迁移后的收益
-
技术层面
-
性能
- 核心任务运行时间缩短30分钟
- 天级报表产出时间提前5小时
-
业务稳定性
- 数仓任务连续60天没有 SLA break
-
运维灵活性
-
不再关心资源层运维,在业务峰谷时期可以进行秒级扩缩容
-
扩缩容步长为1CU,达到接近100%的资源使用率
-
根据作业级别的资源消耗统计快速定位不符合预期的作业并进行针对性优化
-
运行环境隔离,避免作业之间互相干扰,最大程度的降低运维风险
-
作业级别隔离 Spark 版本,可快速测试验证最新版本 Spark 相关 feature
-
作业级别界面化定制 Python 环境,避免黑屏操作全局 Python 环境带来的生产风险
-
-
-
-
财务层面
-
成本优化
-
数仓离线链路成本降低35%
-
adhoc 查询成本降低30%
-
-
-
业务层面
-
业务团队因数据获取效率提升,减少了约 40% 的无效等待时间,可将精力投入到业务优化、产品运营等价值环节。
-
数据准确性的提升(因 Serverless Spark 性能稳定,数据处理出错率降低 90%)让业务避免了因数据错误导致的决策失误损失。
-
五、未来展望
-
推进指标加速层建设,实现 StarRocks 与 Serverless Spark 的自动化协同
-
深化湖仓一体能力,探索 Paimon + Serverless Spark + StarRocks 的端到端优化
-
持续利用 EMR 产品迭代(如统一 Catalog、AI Function)赋能数据智能化