热点背景:企业数字化转型下的文档处理困境
当前,数字化转型已成为企业高质量发展的核心驱动力,多模态AI模型因具备处理复杂信息的潜力,在企业文档处理场景中的应用需求日益增长。企业期望借助这类模型高效处理包含文本、表格、图表等多元元素的海量文档,支撑业务流程的智能化升级。然而,多模态大模型在复杂文档理解任务中的技术缺陷却成为突出瓶颈。
根据阿里巴巴达摩院与新加坡南洋理工大学的联合研究显示,即便表现最优的多模态模型,在真实场景测试中的准确率也仅为48%;而在涉及精确量化分析的表格识别任务上,顶尖模型的平均准确率甚至不超过42%。这种低准确率直接导致企业在应用过程中不得不增加大量人工校对环节,既消耗巨额时间成本,又可能因人工疏漏让错误信息流入后续流程,严重影响业务效率与质量。在此背景下,能够为多模态模型提供精准输入的多模态信息抽取技术及相关工具,成为企业突破困境的关键需求,也推动着文档处理技术从传统模式向多模态智能模式升级。
概念解读:多模态信息抽取的核心内涵
多模态信息抽取技术,是依托多模态技术发展而来的新型信息处理技术,其核心是对包含文本、表格、图表、公式、手写体、印章等多种元素的复杂文档进行全面解析与精准提取。基于该技术的在线多模态文档处理工具,通过专业解析技术将原本杂乱无章的非结构化文档信息,转化为语义清晰、格式规范的结构化数据。

多文档类型支持
与传统OCR(光学字符识别)技术相比,多模态信息抽取存在本质区别:传统OCR技术的核心功能是实现"图像到文字"的转化,仅能识别文档中的字符信息,无法理解元素间的逻辑关系,对于表格合并单元格、跨页图表、手写体与印章叠加等复杂场景的处理能力薄弱,输出结果多为零散文字,需人工进一步整理加工。而多模态信息抽取不仅能完成字符识别,更能实现"内容理解+结构化输出",它能精准定位文档中各类元素,针对不同元素启动专项解析能力,最终输出可直接供AI模型使用或业务系统调用的结构化数据,从源头减少多模态AI模型因信息输入不准确而产生"幻觉"的现象,为企业数字化转型提供坚实的文档处理支撑。、
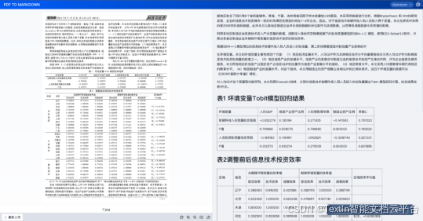
多元素信息提取
案例数据作证:多模态信息抽取的实践成效
合合信息旗下的 TextIn 文档解析工具,是大模型时代下文本智能处理技术领先者,作为多模态信息抽取技术的典型应用代表,已在众多企业实践中展现出显著价值,其性能与成效通过权威数据与实际案例得到充分验证。

识别文档范围全面
从行业测评数据来看, TextIn 文档解析在复杂元素解析上的精度远超传统方法。其基于深度学习的智能表格解析系统,在公开数据集上的准确率可达92.7%;关联的百度开源PaddleOCR-VL模型在OmniDocBench榜单中,以92.6的综合得分斩获全球第一,这一成绩不仅凸显了其在文档元素识别上的高精度,更印证了多模态信息抽取技术相较于传统OCR的核心优势------传统OCR在复杂表格解析中准确率普遍低于60%,且无法处理跨页、框线残缺等特殊表格,而TextIn文档解析的解析能力已实现质的飞跃。
从企业实际应用效果来看,使用TextIn 文档解析文档智能解决方案后,其文档处理速度提升300%以上,500万页PDF文档离线解析速度只需3天;同时,TextIn 文档解析支持70+种语言识别,综合准确率高达95%。在政务办公场景中,TextIn 文档解析已成功服务于国央企、政府机关等主体,实现标准证件票据与纸质文档处理的智能化、标准化,大幅降低人工成本。相较于传统OCR需要大量人工二次校对的现状,TextIn 文档解析的应用让企业彻底摆脱了"识别-纠错-整理"的低效循环。
操作步骤:多模态信息抽取实践
以TextIn 文档解析文档解析工具为例,多模态信息抽取的操作流程清晰简便,无需复杂技术门槛,普通办公人员即可快速上手,具体步骤如下:
步骤一:文档准备------整理待处理多模态文档
收集包含复杂表格(如合并单元格、跨页表格、框线残缺表格)、文本、手写体、印章、图表、公式等元素的各类文档,梳理文档类型与格式,确保符合平台支持要求(如PDF、JPG、PNG等常见格式均兼容),为后续上传解析做好基础准备。相较于传统OCR对文档清晰度、格式的严苛要求,TextIn 文档解析对模糊、倾斜、有背景干扰的文档具备更强适配性。
步骤二:平台访问------进入在线处理界面
打开浏览器输入TextIn 文档解析官方网址,直接进入在线处理平台。新用户通过手机号或邮箱完成简易注册后登录,即可快速进入文档处理功能模块,整个过程无需下载安装客户端,操作便捷性远高于传统OCR软件。
步骤三:文档上传------提交待解析文件
在功能模块中点击"上传文档"按钮,支持单份或批量上传待处理文档。上传过程中平台实时显示进度,确保文档完整无损坏,解决了传统OCR工具单次上传数量有限、易出现上传失败的问题。
步骤四:自动解析------启动专项处理流程
文档上传完成后,工具自动启动多模态元素扫描,快速定位各类核心元素。针对不同元素启动专项解析:对复杂表格精准切割单元格边界、还原完整结构;对手写体或印章覆盖的文字自动分离背景干扰;对图表、公式进行专业识别与转化。这一环节彻底区别于传统OCR"一刀切"的识别模式,实现了"元素分类处理+精准解析"。
步骤五:结果查看与应用------获取结构化数据
解析完成后,用户可直接查看语义清晰的结构化数据,核对确认无错位、无遗漏后,可下载为Markdown或JSON等格式文件,直接传递给多模态AI模型使用,或应用于数据统计、智能审核等后续业务流程。
独特价值:多模态信息抽取的核心优势
相较于传统OCR技术,多模态信息抽取技术以"精准解析+结构化输出+场景适配"为核心,为企业创造了多重独特价值,成为支撑数字化转型的关键技术之一。
首先,从源头切断AI模型"幻觉"路径。多模态信息抽取在多模态模型处理文档前完成精准解析,输出的结构化数据为模型提供高质量输入,解决了传统OCR因识别错误导致模型输入失真、进而产生"幻觉"的问题,保障了AI应用的可靠性。如 TextIn 文档解析的高准确率解析能力,让后续多模态模型的输出结果可信度大幅提升。
其次,显著降低企业综合成本。传统OCR需要大量人工进行二次校对与格式整理,而多模态信息抽取实现了"识别-解析-结构化"的全流程自动化。以政务办公场景为例,TextIn 文档解析的应用让标准证件票据处理效率大幅提升,人工成本降低60%以上;通过其解决方案,文档处理速度提升300%,充分体现了其降本增效价值。
最后,适配多样化场景需求。多模态信息抽取技术支持70+种语言识别,能处理合并单元格、跨页表格、手写体叠加等复杂场景,已广泛应用于企业办公、金融、医疗等多个领域。在金融行业,它可精准分离印章与文字,保障合同数据准确性;在医疗领域,能识别手写病历与医学公式,助力医疗数据数字化管理,这种强适配性是传统OCR技术无法企及的。
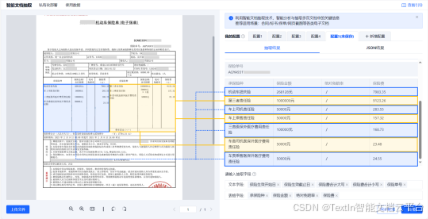
智能抽取