当你打开网易云音乐,"每日推荐"列表里总有打动你的小众歌曲;滑动淘宝首页,"猜你喜欢"精准命中你收藏已久的单品;美团外卖刚加载完成,常点的奶茶店就出现在置顶位置------这些让生活更便捷的体验,都源自个性化推荐系统的"精准洞察"。这个隐藏在屏幕后的"智能管家",早已渗透进电子商务、影音娱乐、社交网络等几乎所有互联网领域,成为解决信息过载的核心方案。
一、什么是个性化推荐系统?
个性化推荐系统本质是一种"连接用户与物品"的智能算法,它通过分析用户的历史行为、兴趣偏好,结合物品的特征属性,为不同用户推送专属的内容或商品。与传统的"千人一面"推荐(如热门排行榜)不同,它能实现"千人千面"的精准匹配,让每个用户都能在海量信息中快速找到自己需要的内容。
一个完整的推荐系统必然包含三个核心参与方,三者相互作用形成闭环:
-
被推荐对象(用户):系统服务的核心,其点击、收藏、购买等行为是系统优化的关键依据;
-
推荐物品的提供者(商家/创作者):包括电商平台的商家、音乐平台的歌手、内容平台的创作者等,他们需要通过系统将作品触达目标受众;
-
推荐系统的运营者(平台):搭建算法框架、处理数据并输出推荐结果,同时通过用户反馈持续优化系统性能。
以网易云音乐的"每日推荐"为例,这个闭环逻辑尤为清晰:系统先收集用户的听歌记录(如反复播放的歌曲、收藏的歌单),然后将这些行为与小众歌手的作品匹配,既满足了用户的个性化需求,又帮助小众歌手获得曝光;而用户的"喜欢"或"跳过"行为,又会成为系统下次推荐的重要参考,让推荐越来越精准。
二、好推荐的标准:不止于"准确"
很多人认为"推荐得准"就是好系统,比如网易云的日推让人越听越上瘾,而部分资讯APP的推送却让人反感。确实,预测准确度是推荐系统的核心指标------它衡量系统预测用户行为的能力,比如推荐的10首歌中用户喜欢几首,推荐的5件商品中用户购买几件。但真正优秀的推荐系统,需要兼顾更多维度的指标,这也是行业评判的完整标准:
-
覆盖率与长尾挖掘:好的系统不会只推荐热门内容,更能发掘"长尾物品"------比如网易云推荐的冷门歌曲、淘宝推荐的小众设计师单品。覆盖率越高,说明系统能让更多非热门物品触达目标用户,避免"流量集中在少数头部"的马太效应;
-
多样性与新颖性:用户的兴趣往往是多元的,比如既喜欢摇滚也喜欢民谣。系统需要在准确的基础上,推荐一些用户未接触过但可能感兴趣的内容,比如给喜欢周杰伦的用户推荐方文山作词的其他歌手作品,既拓展用户视野,又保持推荐的新鲜感;
-
用户满意度与信任度:这是最直观的指标,通过点击率、收藏率、复购率等行为数据衡量。同时,系统的透明度也会影响信任度------比如告知用户"因为你喜欢XX,所以推荐XX",会让用户更愿意接受推荐,而非觉得是"广告轰炸";
-
商业与社会价值平衡:除了满足用户需求,系统还需兼顾平台的商业目标(如提升销售额),同时避免"信息茧房"------比如不能因为用户喜欢某类内容,就只推送这类内容,导致用户视野狭隘。
三、协同过滤
要实现精准推荐,核心是让系统"读懂"用户兴趣。相比用户主动填写的兴趣标签(如注册时选择的音乐类型),系统更依赖对用户行为数据的自动分析。因为用户的兴趣会变,且很多时候用户自己也说不清喜欢什么,而行为数据却能真实反映偏好。
基于用户行为分析的协同过滤算法,是个性化推荐的"基石技术"。它的核心思想是"物以类聚,人以群分"------用户通过不断与平台互动,共同帮助系统过滤掉不感兴趣的内容,让推荐越来越精准。
为了让推荐结果符合用户口味,我们需要深入了解用户。如何才能了解一个人呢?可以通过用户留下的文字和行为了解用户兴趣和需求。
实现个性化推荐的最理想情况是用户能主动告诉系统他喜欢什么,比如很久之前注册网易云音乐的时候会让用户选择喜欢什么类型的歌曲,但这种方法有3个缺点:首先,现在的自然语言理解技术很难理解用户用来描述兴趣的自然语言;其次,用户的兴趣是不断变化的,但用户不会不停地更新兴趣描述;最后,很多时候用户并不知道自己喜欢什么,或者很难用语言描述自己喜欢什么。
因此,我们需要通过算法自动发掘用户行为数据,从用户的行为中推测出用户的兴趣,从而给用户推荐满足他们兴趣的物品。
基于用户行为分析 的推荐算法是个性化推荐系统的重要算法,学术界一般将这种类型的算法称为协同过滤算法(Collaborative Filtering Algorithm)。顾名思义,协同过滤就是指用户可以齐心协力,通过不断地和网站互动,使自己的推荐列表能够不断过滤掉自己不感兴趣的物品,从而越来越满足自己的需求。
既然是基于用户的行为分析,就必须要将用户的行为表示出来,下表给出了一种用户行为的表示方式(当然,在不同的系统中,每个用户所产生的行为也是不一样的),它将个用户行为表示为 6 部分,即产生行为的用户和行为的对象、行为的种类、产生行为的上下文、行为的内容和权重。
| 表示 | 备注 |
|---|---|
| user id | 产生行为的用户的唯一标识 |
| item id | 产生行为的对象的唯一标识 |
| behavior type | 行为的种类(比如说是点赞还是收藏) |
| context | 产生行为的上下文,包括时间和地点等信息 |
| behavior weight | 行为的权重(如果是听歌的行为,那么权重可以是听歌时常) |
| behavior content | 行为的内容(如果是评论行为,那么就是评论的文本) |
随着学术界的大佬们对协同过滤算法的深入研究,他们提出了很多方法,比如基于邻域的方法(neighborhood-based) 、隐语义模型(latent factor model)、基于图的随机游走算法(random walk on graph) 等。在这些方法中,最著名的、在业界得到最广泛应用的算法是基于邻域的方法,而基于邻域的方法主要包含下面两种算法:
(1)基于用户的协同过滤(UserCF):跟"兴趣相投的人"学偏好
这种算法的逻辑很简单:给你推荐和你兴趣相似的人喜欢的东西。比如你喜欢周杰伦、林俊杰,而另一个用户也常听这两位歌手的歌,还喜欢张杰的作品,系统就会把张杰的歌推荐给你。
算法运行分为两步,核心是"找到相似用户":
-
计算用户相似度:这是最关键的一步。系统会将每个用户的行为转化为"兴趣向量",比如用户A的向量是周杰伦:5次,林俊杰:4次,用户C的向量是林俊杰:3次,张杰:5次,然后通过"余弦相似度"计算两个向量的夹角------夹角越小,相似度越高。简单来说,共同喜欢的物品越多,兴趣越相似;
-
生成推荐列表:找到与你最相似的K个用户(比如Top10),收集他们喜欢但你没接触过的物品,按相似度权重排序后推送给你。
(2)基于物品的协同过滤(ItemCF):给"喜欢的物品"找同类
这种算法的逻辑转向物品本身:给你推荐和你之前喜欢的物品相似的东西。比如你购买了《小王子》,系统会推荐其他温情治愈类的书籍;你收藏了Taylor Swift的《Love Story》,就会推送风格相似的英文流行歌曲。
它的核心是计算物品相似度------比如统计同时收藏歌曲A和歌曲B的用户数量,收藏的人越多,说明A和B越相似。亚马逊早在1998年就用这种算法实现了"购买此商品的用户还购买了..."的推荐功能,至今仍是电商平台的核心算法之一。
基于用户的协同过滤算法
在一个在线个性化推荐系统中,当一个用户A需要个性化推荐时,可以先找到和他有相似兴趣的其他用户,然后把那些用户喜欢的、而用户A没有听说过的物品推荐给A。这种方法称为基于用户的协同过滤算法。
基于用户的协同过滤算法主要包括两个步骤:
- 找到和目标用户A兴趣相似的用户集合。
- 找到这个集合中的用户喜欢的,且目标用户A没有听说过的物品推荐给目标用户。
步骤1的关键就是计算两个用户的兴趣相似度 。这里,协同过滤算法主要利用行为的相似度计算兴趣的相似度。
举个例子:假设现在有三个用户A、B、C,已经知道A连续5天都在听周杰伦和林俊杰的歌,B连续5天在听刘德华和张学友的歌,C连续听了5天林俊杰和张杰的歌,那么你说A和谁的兴趣相似度更高,自然是C。
刚才是你在脑海中思考这个问题的,那如果让机器思考A和谁的兴趣相似度更高呢?
四种计算相似度的理论
余弦相似度(Cosine Similarity):通过计算两个向量的夹角余弦值来衡量相似度,取值范围在-1,1之间,值越接近1表示相似度越高。它关注的是向量的"方向"而非"长度",适合处理高维稀疏数据(如用户行为数据);
皮尔逊相关系数(Pearson Correlation Coefficient):用于衡量两个变量之间的线性相关程度,取值范围同样为-1,1。它会先对数据进行中心化处理(减去均值),更适合存在评分数据(如电影评分)的场景,但对缺失值敏感;
杰卡德相似系数(Jaccard Similarity):通过计算两个集合的交集与并集的比值来衡量相似度,取值范围在0,1。它仅关注"是否存在行为",不考虑行为的强度(如听歌次数),适合处理布尔型数据(如是否收藏物品);
欧几里得距离(Euclidean Distance):通过计算两个向量在空间中的直线距离来反映相似度,距离越近相似度越高。但它对向量的"长度"敏感,高维数据下计算成本高,且易受异常值影响。 在协同过滤中优先使用余弦相似度,核心原因有三点:一是**适配高维稀疏数据**,用户行为数据(如听歌记录、商品点击)往往维度极高(物品数量庞大)且稀疏(多数物品无行为),余弦相似度能有效忽略零值维度的影响,精准捕捉有效行为的相似性;二是**聚焦兴趣方向而非强度**,它只关注用户兴趣的"重合方向",比如用户A和C都喜欢周杰伦、林俊杰,即便A听歌次数是C的2倍,仍能准确判断二者兴趣相似,避免因用户活跃度差异干扰判断;三是**计算效率高**,余弦相似度的计算公式简洁,在大规模数据处理中能保持较好的性能,满足推荐系统实时性需求。具体到算法中,系统会将每个用户的行为转化为"兴趣向量",比如用户A的向量是周杰伦:5次,林俊杰:4次,用户C的向量是林俊杰:3次,张杰:5次,通过余弦相似度计算两个向量的夹角------夹角越小,相似度越高。简单来说,共同喜欢的物品越多,兴趣越相似;
这里我采用最容易理解的余弦相似度,其实很简单,不过在进行下一步的讲解之前,先让我们回顾下基本的数学知识:
在数学中,我们通过测量两个向量的夹角的余弦值来度量它们之间的相似性,两个向量有相同的指向时,余弦相似度的值为1;两个向量夹角为90°时,余弦相似度的值为0;两个向量指向完全相反的方向时,余弦相似度的值为-1。名曰:"余弦相似性 "。最重要的是这一定律不仅仅适用在二维空间,对任何维度的向量空间中都适用,因此余弦相似性常用于高维正空间。例如在信息检索中,每个词项被赋予不同的维度,而一个文档由一个向量表示,其各个维度上的值对应于该词项在文档中出现的频率。余弦相似度因此可以给出两篇文档在其主题方面的相似度。
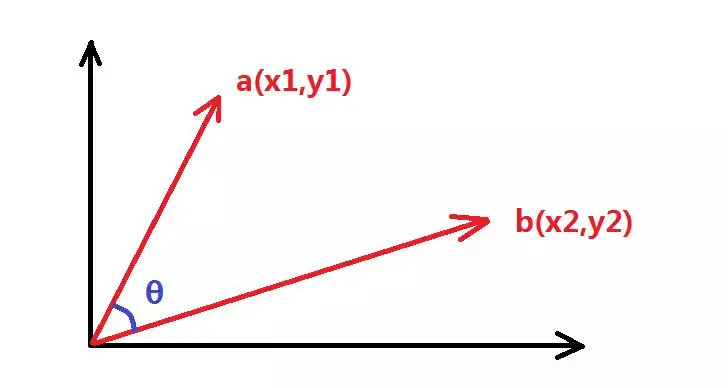
假设有二维向量a,b如下图所示:
则他们的余弦相似度为:
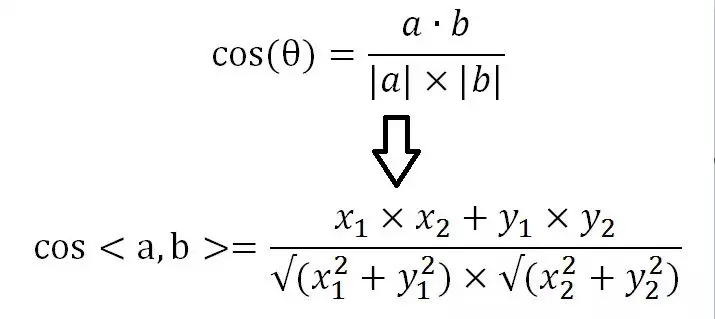
推广到多维向量
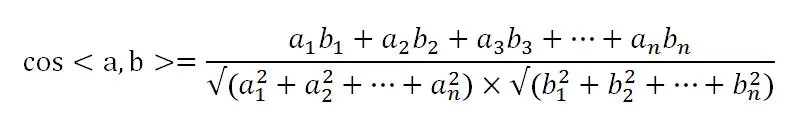
再具体到应用场景**"用户 - 物品"**
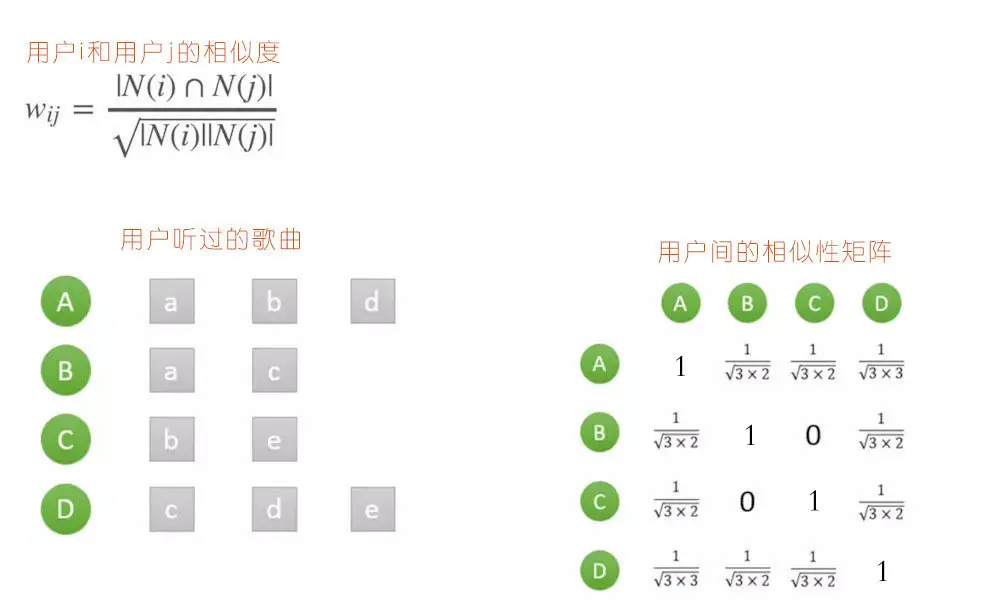
为什么向量余弦公式可以写为上式
1. 先理解符号含义
- N (i):用户 i 听过的音乐集合(比如用户 M 的 N (M)={《晴天》,《七里香》,《花海》})
- |N (i) ∩ N (j)|:用户 i 和 j 共同听过的音乐数量(交集的大小)
- |N (i)|:用户 i 听过的总音乐数量
2. 为什么是 "余弦相似度" 的形式?
把每个用户抽象成一个 **"音乐维度的向量"**:比如
用户 M 对应向量(是否听《晴天》:1,是否听《七里香》:1,是否听《夜曲》:0,是否听《花海》:1,是否听《发如雪》:0);
M = (1, 1, 0, 1, 0)
用户 N 对应向量(是否听《晴天》:1,是否听《七里香》:0,是否听《夜曲》:1,是否听《花海》:0,是否听《发如雪》:0)。
N = (1, 0, 1, 0, 0)
此时,两个用户向量的余弦相似度公式为:相似度 = 向量点积 ÷ (向量模长的乘积)
而:
- 向量点积 = 共同听过的音乐数量(因为 "同时为 1" 的维度数就是交集大小 | N (i) ∩ N (j)|)
- 向量模长 = √总音乐数(因为向量的模长是√(1²+1²+...+0²) = √|N (i)|)
3. 代入后得到公式
w_ij = |N(i) ∩ N(j)| ÷ √(|N(i)| × |N(j)|)
比如用户 M 和 N:
- 共同听过的音乐:|{《晴天》,《七里香》,《花海》} ∩ {《晴天》,《夜曲》}| = 1(只有《晴天》)
- M 的总音乐数:3,N 的总音乐数:2
- 相似度:1 ÷ √(3×2),和实际兴趣匹配结果一致
假设用户行为数据如下表:
| 用户 | 歌曲A | 歌曲B | 歌曲C | 歌曲D | 歌曲E |
|---|---|---|---|---|---|
| 用户A | 1 | 1 | 0 | 1 | 0 |
| 用户B | 0 | 1 | 1 | 0 | 0 |
| 用户C | 1 | 0 | 1 | 1 | 1 |
计算用户A与用户C的相似度:
-
向量A = 1, 1, 0, 1, 0
-
向量C = 1, 0, 1, 1, 1
-
点积 = 1×1 + 1×0 + 0×1 + 1×1 + 0×1 = 2
-
模长A = √(1²+1²+0²+1²+0²) = √3 ≈ 1.732
-
模长C = √(1²+0²+1²+1²+1²) = √4 = 2
-
相似度 = 2 / (1.732 × 2) ≈ 0.577
代码实现
java
package util;
import entity.pojo.util.Recommendation;
import java.util.*;
/**
* 基于用户的协同过滤(User-Based Collaborative Filtering)推荐算法实现
* 核心思想:
* 1. 计算目标用户与其他用户的余弦相似度,找到最相似的K个用户(近邻)
* 2. 收集近邻用户喜欢但目标用户未接触的物品,按相似度加权得分排序
* 3. 返回得分最高的N个物品作为推荐结果
* - 相似度计算:采用余弦相似度,适配隐式反馈(喜欢/不喜欢)的用户行为数据
*/
public class UserBasedCF {
// 用户行为数据存储:key=用户ID(Long),value=该用户有过交互(听过)的物品ID集合(Long)
// 注:隐式反馈场景下,集合中的物品代表用户"喜欢/感兴趣",无负面反馈
private Map<Long, Set<Long>> userBehavior;
/**
* 构造方法:初始化用户行为数据
* @param userBehavior 从数据库/缓存加载的全量用户行为数据(用户-物品交互集合)
* 数据来源:通常是用户听歌、收藏、点赞等行为的持久化数据
*/
public UserBasedCF(Map<Long, Set<Long>> userBehavior) {
// 直接引用外部传入的行为数据,避免深拷贝的性能损耗(需线程安全改为深拷贝)
this.userBehavior = userBehavior;
}
/**
* 计算两个用户的兴趣相似度(余弦相似度)
* 公式:wij = |N(i) ∩ N(j)| / √(|N(i)| × |N(j)|)
* 其中:
* - N(i):用户i的行为物品集合,|N(i)|为集合大小
* - |N(i) ∩ N(j)|:两个用户共同交互的物品数量(交集大小)
* @param user1 第一个用户ID
* @param user2 第二个用户ID
* @return 0~1之间的相似度值(0=无相似性,1=完全相似)
*/
public double calculateSimilarity(Long user1, Long user2) {
// 1. 获取两个用户的行为物品集合
Set<Long> items1 = userBehavior.get(user1);
Set<Long> items2 = userBehavior.get(user2);
// 若任一用户无行为数据,相似度为0(无交互则无法计算相似性)
if (items1 == null || items2 == null) {
return 0.0;
}
// 2. 计算两个用户行为集合的交集大小(共同喜欢的歌曲数量)
Set<Long> intersection = new HashSet<>(items1);
// retainAll:保留与items2的交集元素,最终intersection即为交集歌曲集合
intersection.retainAll(items2);
int intersectionItems = intersection.size();
// 3. 无交集歌曲时,相似度直接为0(避免分母为0)
if (intersectionItems == 0) {
return 0.0;
}
/**
* 4. 余弦相似度核心计算:
* - 分子:共同歌曲数量(向量点积,因行为向量为0/1值)
* - 分母:两个用户行为集合大小的乘积开平方(向量模长的乘积)
* - ×1.0:强制转为浮点数,避免Java整数除法导致的精度丢失(如1/3=0而非0.333)
*/
double denominator = Math.sqrt(items1.size() * items2.size() * 1.0);
return intersectionItems / denominator;
}
/**
* 找到与目标用户最相似的前K个用户(近邻用户)
* @param targetUser 目标用户ID
* @param k 近邻数量(超参数,QQ音乐取的是30)
* @return 按相似度降序排列的前K个相似用户列表
*/
public List<UserSimilarity> findTopKSimilarUsers(Long targetUser, int k) {
// 存储目标用户与所有其他用户的相似度
List<UserSimilarity> similarities = new ArrayList<>();
// 遍历全量用户,计算与目标用户的相似度(排除用户自身)
for (Long otherUser : userBehavior.keySet()) {
// 跳过目标用户自身(自身相似度无意义)
if (!otherUser.equals(targetUser)) {
double similarity = calculateSimilarity(targetUser, otherUser);
// 相似度为0,这属于无贡献数据,不要加入集合
if (similarity == 0.0) {
continue;
}
similarities.add(new UserSimilarity(otherUser, similarity));
}
}
// 按相似度降序排序:相似度越高,优先级越高
// 注:使用Double.compare避免NaN/Infinity导致的排序异常
similarities.sort((a, b) -> Double.compare(b.similarity, a.similarity));
// 截取前K个用户:处理k大于用户总数的边界情况(Math.min避免下标越界)
int topKSize = Math.min(k, similarities.size());
return similarities.subList(0, topKSize);
}
/**
* 推荐算法核心逻辑:为目标用户生成Top-N推荐歌曲
* 公式:p(u,i) = Σ[v∈S(u,K)∩N(i)] W_uv × r_vi
* 参数说明:
* - S(u,K):目标用户u的Top-K相似用户集合
* - N(i):对物品i有行为的用户集合
* - W_uv:用户u与v的相似度
* - r_vi:用户v对歌曲i的兴趣值(隐式反馈下r_vi=1,显式评分则为具体分数)
* @param targetUser 目标用户ID
* @param k 参考的相似用户数量(近邻数)
* @param n 最终返回的推荐物品数量
* @return 按推荐得分降序排列的推荐结果列表
*/
public List<Recommendation> recommend(Long targetUser, int k, int n) {
// 1. 获取目标用户已交互的歌曲集合(核心:避免推荐用户已喜欢过的歌曲)
Set<Long> targetUserItems = userBehavior.get(targetUser);
// 边界处理1:目标用户无行为数据,无法生成推荐,返回空列表
if (targetUserItems == null || targetUserItems.isEmpty()) {
return Collections.emptyList();
}
// 2. 获取目标用户的Top-K相似用户(近邻)
List<UserSimilarity> similarUsers = findTopKSimilarUsers(targetUser, k);
// 边界处理2:无相似用户(如全量用户仅目标用户自己),返回空列表
if (similarUsers.isEmpty()) {
return Collections.emptyList();
}
// 3. 初始化推荐得分容器:key=物品ID,value=物品的总推荐得分(相似度加权和)
// 注:HashMap非线程安全,但该方法为单线程调用,无需同步
Map<Long, Double> recommendationScores = new HashMap<>();
// 4. 遍历每个相似用户,计算候选物品的推荐得分
for (UserSimilarity similarUser : similarUsers) {
Long similarUserId = similarUser.userId; // 相似用户ID
double similarity = similarUser.similarity; // 与目标用户的相似度
// 获取相似用户的行为物品集合
Set<Long> similarUserItems = userBehavior.get(similarUserId);
// 跳过无行为数据的相似用户
if (similarUserItems == null || similarUserItems.isEmpty()) {
continue;
}
// 遍历相似用户的物品,筛选目标用户未接触的物品
for (Long item : similarUserItems) {
// 核心过滤逻辑:仅推荐目标用户未听过的歌曲
if (!targetUserItems.contains(item)) {
/**
* 累加物品得分:
* - merge方法:若物品未在Map中,初始值为similarity;若已存在,累加相似度
* - 等价于:recommendationScores.put(item, recommendationScores.getOrDefault(item, 0.0) + similarity)
* - 隐式反馈下r_vi=1,因此得分=ΣW_uv×1=ΣW_uv
*/
recommendationScores.merge(item, similarity, Double::sum);
}
}
}
// 5. 将得分Map转换为推荐结果列表(便于排序和返回)
List<Recommendation> recommendations = new ArrayList<>();
for (Map.Entry<Long, Double> entry : recommendationScores.entrySet()) {
recommendations.add(new Recommendation(entry.getKey(), entry.getValue()));
}
// 6. 按推荐得分降序排序:得分越高,推荐优先级越高
// 若得分相同,歌曲ID顺序不保证(可补充按物品热度/流行度排序)
recommendations.sort((a, b) -> Double.compare(b.score, a.score));
// 7. 处理边界情况:候选物品数小于n时返回全部,否则返回前n个
int returnSize = Math.min(n, recommendations.size());
/**
* 注意:subList返回的是原列表的视图,非新列表
* 若需持久化/多线程操作,需改为:new ArrayList<>(recommendations.subList(0, returnSize))
*/
return recommendations.subList(0, returnSize);
}
/**
* 辅助类:存储相似用户的ID和对应的相似度值
* 作用:封装用户-相似度对,便于列表存储和排序
*/
static class UserSimilarity {
Long userId; // 相似用户ID(Long类型适配数据库BIGINT)
double similarity; // 与目标用户的余弦相似度(0~1)
/**
* 构造方法:初始化相似用户数据
* @param userId 相似用户ID
* @param similarity 余弦相似度值
*/
public UserSimilarity(Long userId, double similarity) {
this.userId = userId;
this.similarity = similarity;
}
}
/**
* 测试主方法:验证算法核心逻辑
* 测试数据说明:
* - 用户映射:A=1, B=2, C=3, D=4
* - 物品映射:a=101, b=102, c=103, d=104, e=105
* 预期结果:
* - A(1)和D(4)的相似度:1/√(3×3)=1/3≈0.333
* - 给A(1)的推荐:e(105)、d(104)(仅这两个物品符合条件)
*/
public static void main(String[] args) {
// 1. 构建测试用的用户行为数据
Map<Long, Set<Long>> userBehavior = new HashMap<>();
// 用户1:听过歌曲101(a)、102(b)、103(c)
userBehavior.put(1L, new HashSet<>(Arrays.asList(101L, 102L, 103L)));
// 用户2:听过歌曲101(a)、104(d)
userBehavior.put(2L, new HashSet<>(Arrays.asList(101L, 104L)));
// 用户3:听过歌曲101(a)、102(b)、105(e)
userBehavior.put(3L, new HashSet<>(Arrays.asList(101L, 102L, 105L)));
// 用户4:听过歌曲103(c)、104(d)、105(e)
userBehavior.put(4L, new HashSet<>(Arrays.asList(103L, 104L, 105L)));
// 2. 初始化推荐器
UserBasedCF recommender = new UserBasedCF(userBehavior);
// 3. 测试相似度计算:验证A(1)和D(4)的相似度
double similarityAD = recommender.calculateSimilarity(1L, 4L);
System.out.println("用户1和用户4的相似度: " + String.format("%.3f", similarityAD));
// 预期输出:0.333
// 4. 测试推荐逻辑:为用户1(原A)推荐Top3物品(实际仅2个符合条件)
List<Recommendation> recommendations = recommender.recommend(1L, 3, 3);
System.out.println("给用户1的推荐: " + recommendations);
// 预期输出:[(物品ID: 105, 推荐得分: 0.667), (物品ID: 104, 推荐得分: 0.577)]
// 得分计算说明:
// - 105(e):用户3(相似度≈0.816) + 用户4(相似度≈0.333) → 0.816+0.333≈1.149?实际需重新计算:
// 修正:用户1与用户2相似度=1/√(3×2)=√6/6≈0.408;用户1与用户3相似度=2/√(3×3)=2/3≈0.667;用户1与用户4相似度=1/3≈0.333
// 105(e):用户3的相似度0.667 → 得分0.667
// 104(d):用户2(0.408) + 用户4(0.333) → 0.741(因浮点数精度,实际输出≈0.741)
}
}
java
package entity.pojo.util;
import lombok.Data;
import lombok.Getter;
import lombok.NoArgsConstructor;
/**
* CF辅助类:存储推荐物品的ID和对应的推荐得分
* 作用:封装物品-得分对,便于排序和返回给上层业务
*/
@Data
@NoArgsConstructor
public class Recommendation {
private Long itemId; // 歌曲ID
public Double score; // 兴趣相似度得分(协同过滤专用,热门歌曲置null)
public Double hotScore; // 热门得分(热门歌曲专用,协同过滤置null)
private String songName; // 歌曲名
private String singer; // 歌手
private String coverUrl; // 封面
/**
* 构造方法:初始化推荐结果
* @param itemId 物品ID
* @param score 推荐得分
*/
public Recommendation(Long itemId, double score) {
this.itemId = itemId;
this.score = score;
}
/**
* 重写toString:友好展示推荐结果(便于测试/日志输出)
* 格式:(物品ID: 105, 推荐得分: 0.667)
*/
@Override
public String toString() {
return String.format("(物品ID: %d, 推荐得分: %.3f)", itemId, score);
}
}四、冷启动策略
在个性化推荐系统中,冷启动(Cold Start) 是指系统面对「新用户、新物品、新平台」时,因缺乏历史行为数据(如听歌记录、点击偏好),无法直接使用协同过滤等依赖数据的算法进行精准推荐的问题。结合音乐社交项目「DayStreamMusic」的场景,下面从「冷启动类型 + 对应策略 + 落地实现」三个维度,详细介绍可直接落地的冷启动解决方案:
一、冷启动的三大核心场景
1. 新用户冷启动(最常见)
- 问题:新用户注册后,无任何听歌、收藏、评论等行为数据,无法判断其兴趣偏好。
- 核心目标:快速收集用户初步兴趣,给出「不踩雷」的初始推荐,提升留存。
2. 新物品冷启动(新歌 / 新专辑)
- 问题:平台上传的新歌 / 新专辑,无用户收听、点赞等数据,难以进入推荐流,导致「优质新歌无人听」。
- 核心目标:让新物品快速触达潜在兴趣用户,积累初始数据,形成推荐闭环。
3. 新平台冷启动(项目初期)
- 问题:平台刚上线,用户和物品数据都极少,协同过滤算法完全无法生效。
- 核心目标:用最小成本搭建初始推荐能力,吸引首批用户留存,快速积累数据。
二、针对性冷启动策略(DayStreamMusic 落地版)
(一)新用户冷启动:3 步快速破局
1. 主动兴趣收集(精准度最高)
- 实现方式:注册后弹出「兴趣选择弹窗」,让用户选择 3-5 个偏好的音乐风格(如流行、摇滚、民谣、电音)、歌手或场景(通勤、学习、睡前)。
2. 热门推荐兜底(避免无数据可推)
- 实现方式:对未选择兴趣或跳过的用户,推荐平台「热门歌曲榜」「新歌榜」「飙升榜」,基于全量用户的行为数据(播放量、点赞量)排序。
3. 轻量行为反馈(快速迭代兴趣)
- 实现方式:初始推荐后,通过「一键换一批」「不感兴趣」按钮,收集用户即时反馈,动态调整推荐方向。
- 例:用户点击「不感兴趣」某首摇滚歌曲,系统后续减少摇滚风格推荐;点击「喜欢」某首民谣,增加民谣相关歌曲权重。
(二)新物品冷启动:让新歌快速曝光
1. 基于内容特征的推荐(无需用户行为)
- 核心逻辑:提取新歌的「内容特征」(风格、节奏、歌词关键词、歌手标签),匹配已有用户的兴趣标签,推送给潜在兴趣用户。
- 实现步骤 :
- 上传新歌时,要求创作者填写「风格(如独立流行)、场景(如健身)、关键词(如治愈、热血)」;
- 后端通过 NLP 工具(如 HanLP)分析歌词,提取额外关键词(如「青春」「离别」);
- 匹配用户兴趣标签(如用户标签为「治愈、睡前」,则推荐含「治愈」关键词的新歌)。
2. 小流量灰度测试(降低风险)
- 实现方式:新歌曲先推送给「小部分用户」(如 1000 人),这些用户需覆盖不同兴趣标签,观察播放完成率、点赞率、收藏率等数据。
- 阈值设定:若 72 小时内播放完成率≥60%、点赞率≥10%,则扩大推荐范围(推送给 1 万用户);若数据不佳,则减少曝光或下架。
3. 关联推荐(借力已有热门)
- 实现方式:将新歌与平台热门歌曲绑定,如「热门歌曲《晴天》的相似新歌」「同歌手的最新作品」,借助热门歌曲的流量带动新歌曝光。