编者按: 如何在资源受限的设备上高效部署大语言模型,同时还尽可能保持其性能表现?
我们今天为大家带来的这篇文章,作者的核心观点是:量化技术通过在模型精度与效率之间寻找最优平衡点,使得大语言模型能够在资源受限的设备上高效部署,而几乎不降低其"智能水平"。
文章从量化的基本原理出发,深入剖析了训练后量化(PTQ)与量化感知训练(QAT)的适用场景,详细解释了缩放因子、零点、对称/非对称量化等关键技术细节,并进一步探讨了高级量化技术(如 GPTQ、AWQ、SmoothQuant)以及 KV 缓存量化等前沿方法。作者还结合实战经验,梳理出一套可落地的量化工作流,并展示了量化在端侧 AI、低成本云部署、长上下文处理等场景中的巨大价值。
作者 | Bhavishya Pandit
编译 | 岳扬
像我们这样的大语言模型,多少有点"养尊处优"。我们钟爱庞大的参数规模、海量的内存和强悍的 GPU。但当有人试图在手机或配备低性能 GPU 的笔记本电脑上运行我们时,现实便会毫不留情地给我们一记耳光。
工程师们如何确保我们在微型设备上依然能流畅智能地运行?
答案就是:量化技术(quantization) ------ 它是现代 AI 模型部署中的一项核心技术。
让我们花点时间,真正理解它。
01 什么是量化技术?
量化的本质在于降低数值的存储精度。 LLM的所有运算都离不开数字------每个权重参数、每次激活值、每一个注意力分数,全都建立在浮点数运算之上。这些数值流畅、连续、无限精确。

但计算机呢?它们更喜欢固定、离散的存储单元(比如整数而不是高精度浮点数)。要么你的数据能塞进去,要么就塞不进去。就像你试图把整个衣柜塞进一个登机箱一样,装得下就装,装不下就没办法。这时候,量化技术站出来说:
"嘿,大语言模型,如果每个数字不再使用 32 位精度,而是砍到 8 位,甚至 4 位呢?你几乎察觉不到差别,但我们能省下大量内存。"
32 位浮点数(FP32)→ 黄金标准
8 位整数(INT8)→ 依然智能,体积要小得多
4 位整数(INT4)→ 超紧凑,只是稍微健忘一点
好吧,但大语言模型为什么要在乎这个?
因为现在的 LLM 实在太臃肿了。数十亿参数需要数十亿个数字。一个 70B 参数的模型若用 FP32 表示,需要 280 GB------这已经不是模型了,这是存储灾难。
量化能把这种情况:"我得靠一整个服务器集群才能跑这个东西"
变成这样:"嘿,我或许能在笔记本上运行它,甚至在手机上也行!"
本质上这就是 AI 模型的瘦身方案 ------ 在保持智能的前提下剔除冗余数据。
但是,压缩数字精度不会损害模型质量吗?
有时候确实会。但量化的精髓(也是整门技术的重点)在于:
在模型最不敏感的地方降低精度
在模型最核心的地方保留准确性
02 量化在大语言模型生命周期中的位置:训练 vs 推理
在我搞清楚"量化是什么"之后,下一个问题便接踵而至:
"挺酷的,但我们到底什么时候做量化?是在训练期间?训练之后?还是两个阶段都需要?"
事实证明,时机的选择非常关键,因为大语言模型非常挑剔。你是在它们学习过程中就引入量化,还是等它们已经记牢所有模式后再量化,表现会大不相同。
2.1 训练后量化(Post-Training Quantization, PTQ)
可以把 PTQ 想象成给模型贴一张便利贴提醒:
"嘿,我要把你的某些数字四舍五入了,试着适应一下。"
你直接拿一个已经完全训练好的模型,然后进行:
- FP32 → INT8 或 INT4
- 可能还会用一些花哨的取整技巧
优点是:
- 快速又便宜:无需重新训练一个 70B 参数的庞然大物
- 易于实验:可以先试试 INT8,看模型是否撑得住,再大胆尝试更低精度
缺点是(我是吃了亏才明白的):
- 精度可能下降:某些网络层对量化极其敏感
- 异常值影响大:如果某个权重特别大,会破坏整个量化尺度,导致所有参数在压缩后严重失真。
- 有时需要保留原精度层:LayerNorm、嵌入层(embedding layers)或语言模型头(LM head)可能得保持在 FP16 精度
2.2 量化感知训练(Quantization-Aware Training, QAT)
QAT 是更成熟、更系统的做法。与其等模型学完后再强迫它适应低精度,不如从一开始训练时就让它习惯。
我探索 QAT 时是这么做的:
- 在训练过程中插入"伪量化层"(fake quantization layers):模型在学习时就看到低精度的数字
- 使用直通估计器(straight-through estimators)让梯度正常流动,使模型能主动适应
- 到训练结束时,权重天然具备对量化噪声的鲁棒性
优点是:
- 最终准确率更高,尤其在极低精度(如 INT4 或 3-bit)时
- 推理更稳定,意外更少
- 可以进行激进量化而不丢失模型的"聪明劲儿"
缺点(我注意到的):
- 耗时:哪怕只部分重训 7B--70B 的模型,成本也很高
- 工程投入大:需要谨慎集成到训练流程中
如何选择(根据我的实验和阅读):
- PTQ → 首选方案。便宜、快速,在 INT8 上效果出奇地好,配合智能取整策略,INT4 也常常有效
- QAT → 仅当你需要最后那 1--2% 的准确率,或要做极低精度(如 4-bit 以下)量化时才用
- 混合方案 → 先做 PTQ,同时将某些关键层回退到 FP16,再对核心层做轻量微调(近似 mini-QAT)
为什么选择在哪个阶段进行量化如此重要?
我意识到,量化不只是一个数学技巧 ------ 它会彻底改变整个部署流程:
- 对纯推理任务,PTQ 往往胜出:显存占用更少,吞吐量更高
- 对需要训练+部署的完整工作流程,QAT 可能更划算:最终模型更小,长上下文处理能力也更强
选择在哪个阶段进行量化的问题归根结底是:
你是想要快速、便宜、基本够用,还是谨慎、稍慢、接近完美?
03 量化技术背后的运作机制
在我搞清楚"何时"量化之后,就不得不弄明白"量化究竟是怎么实现的"。老实说,这个过程出人意料地优雅。量化的核心思想很简单:
把连续且无限精确的数字,映射到一组有限的离散值上,并尽可能保留模型的"智能"。
3.1 理解缩放因子(Scale)与零点(Zero-Point)
想象模型中的这样一个权重:
0.8921374650012345我们真的需要这么多小数位吗?不需要。量化技术是这样做的:
- 选择一个缩放因子(s)→ 决定每个"区间"有多宽
- 选择一个零点(z)→ 将我们的整数对齐到实际数据的范围
公式看起来挺花哨,但概念上其实很简单:
ini
quantized_value = round(original_value / scale) + zero_point当你想还原回 FP32 时:
ini
dequantized_value = (quantized_value - zero_point) * scale3.2 对称量化 vs 非对称量化
我发现,并不是所有量化都一样:
- 对称量化(Symmetric quantization) → 零点为 0,区间以 0 为中心对称
- 优点:更简单,效率极高
- 常用于权重
- 非对称量化(Asymmetric quantization) → 零点可调,正负范围不一定相等
- 优点:能更好地捕捉偏态分布
- 常用于激活值(activations),因为它们通常不是以 0 为中心的
3.3 按张量量化 vs 按通道量化:粒度很重要
起初,我尝试了按张量量化(per-tensor quantization):整个权重矩阵使用一套缩放因子和零点。很简单,但有时会出现灾难性失效。为什么呢?因为 Transformer 很挑剔 ------ 权重矩阵中有些行的数值很大,有些则很小。若整行共用一套缩放因子,结果会是:
- 小数值被挤进同一个区间(导致精度损失)
- 或大数值被截断(产生巨大误差)
解决方案?按通道(per-channel,即按行)量化。
- 每一行都有自己独立的缩放因子(和可能的零点)
- 保留了数值的相对差异
- 与带来的收益相比,其额外的内存开销微乎其微
3.4 取整与截断:微小误差,重大影响
量化并非魔法。它会引入两类误差:
- 取整误差(Rounding error) → 实际值与其最接近的量化区间值之间的差异
- 截断误差(Clipping error) → 当数值超出可表示范围时被强行裁剪
像 GPTQ 或 SmoothQuant 这样的现代 LLM 量化方案,核心就是通过巧妙的取整方法或层间重平衡(rebalancing)来最小化这些误差(后面会细说)。
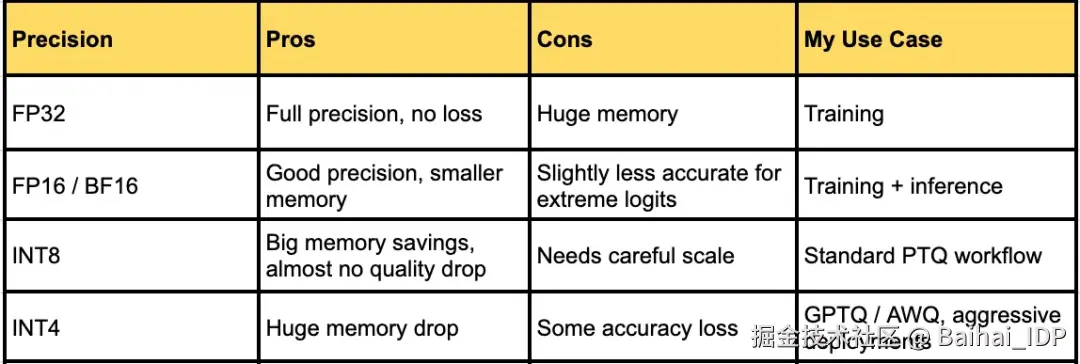
3.5 如何选择量化精度
这是我每天都要面对的问题:
FP32 → INT8 → INT4 → ... 我最多能压缩到多少位?
我的经验是:通常先从 INT8 开始 ------ 安全又经济,只有在采用高级取整技术时,才尝试 INT4。低于 4 比特的量化尚处于实验阶段,除非你准备好对模型进行微调,否则风险很高。
3.6 一个直观的比喻
这是我的思维模型:
- 每个权重 = 一件衣服
- 每个量化区间 = 行李箱里的一个隔层
- 缩放因子 = 你的隔层有多大
- 零点 = 第一个隔层从哪儿开始
04 量化为何有时会带来副作用
量化并非魔法 ------ 如果我们不够谨慎,它可能会微妙地破坏模型性能。这些误差主要来源于以下几个方面:
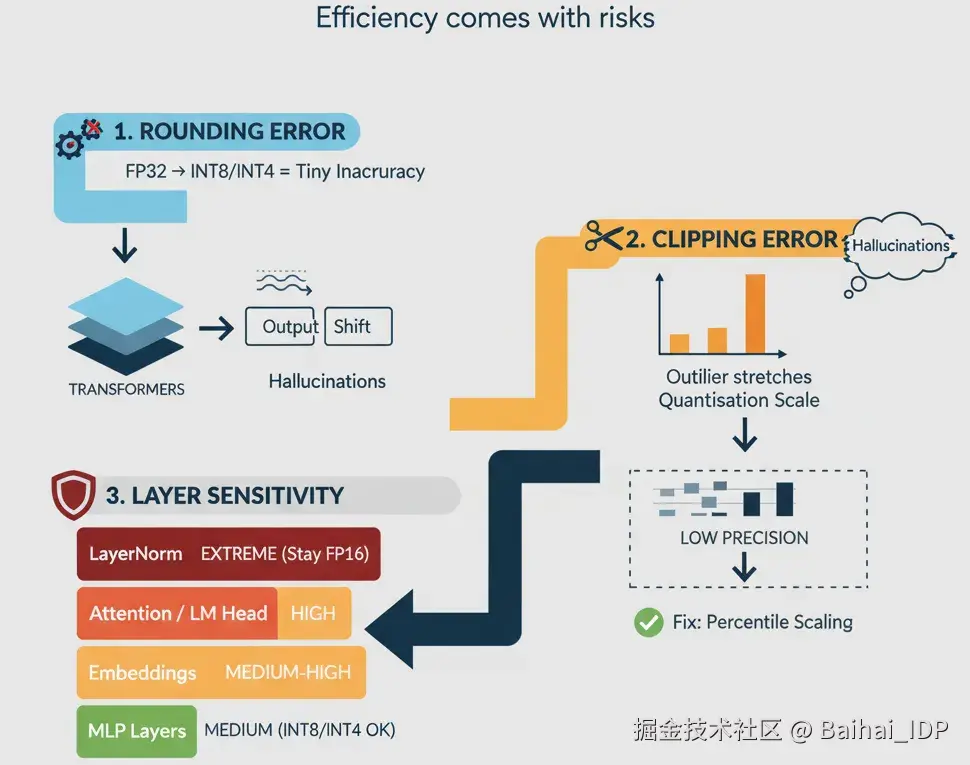
1)取整误差:将 FP32 精度的数值映射到 INT8/INT4 会引入微小的精度损失。
- 单次误差很小,但在 Transformer 中,微小的取整误差会跨层累积。
- 结果:导致注意力分布或词元概率发生细微变化,有时甚至会引发模型幻觉。
2)截断误差:异常值会迫使量化因子变大。
- 这使得大多数权重被压缩到少数几个区间内 → 有效精度大幅下降。
- 实例:LayerNorm 层中一个罕见的大激活值若被截断,就可能导致模型不稳定。
快速应对:采用百分位数法确定缩放因子,代替极值法,或对敏感层特殊处理。
3)网络层敏感度差异:并非所有网络层对量化的反应都相同:
- 注意力投影层(Attention projections) & 语言模型头(LM head) → 高度敏感
- LayerNorm 层 → 极度敏感,通常需保持 FP16 精度
- MLP 层 → 中等敏感,可耐受 INT8/INT4
- 嵌入层(Embeddings) → 中高度敏感,需要小心处理
05 高级量化技术
在经历了取整、截断和敏感网络层带来的种种挑战后,研究人员和工程师们开发出一些巧妙的方法,使得 LLM 即使在 4 位精度下也能表现出色。以下是我了解到的一些核心技术。

5.1 GPTQ:基于 Hessian 矩阵的智能取整
- 核心思想:并非所有取整误差都同等重要。某些权重对模型输出的影响更大。
- GPTQ 通过分析模型的二阶敏感度(Hessian 矩阵)来识别哪些权重可以安全地进行取整处理。
- 效果:即使在大模型中,INT4 权重量化也能几乎保持原始精度。
5.2 AWQ:激活感知量化
- 激活值与权重相互作用,如果在对权重进行取整时不考虑激活值的分布范围,可能会损害模型性能。
- AWQ 根据激活值的统计特征来调整权重量化策略,从而降低推理过程中的误差风险。
5.3 SmoothQuant:层间平衡技术
- 痛点:某些网络层的激活值范围过大,导致均匀量化效率低下。
- SmoothQuant 会在不同层之间对权重和激活值进行重新缩放,但保证它们相乘后的结果(即模型的输出)保持不变。
- 优势:实现更平滑的量化,大幅减小精度损失。
5.4 HQQ 与混合方法
- 该方法将 Hessian 信息与混合精度或分组量化技术相结合。
- 思路:对层中"安全"的部分使用低比特精度,而对敏感部分保留更高精度。
- 该技术在对生产级模型进行 INT4 或更低比特量化时尤为实用。
5.5 混合精度回退机制
- 有些网络层天生抗拒被量化。
- 常见策略:将 LayerNorm、LM Head(语言模型输出头)以及部分嵌入层维持在 FP16 精度,其余部分则量化为 INT4/INT8。
- 权衡:虽略微增加内存占用,却能换来模型质量的大幅提升。
06 KV 缓存量化
如果你曾尝试用大语言模型处理长上下文任务,一定对此深有体会:KV 缓存会疯狂占用内存。每个生成的词元都要为每一层保存键(Key)矩阵和值(Value)矩阵,而模型动辄拥有数十亿参数,内存很快就会被吃光。量化技术此时便派上用场。

6.1 为什么 KV 缓存很重要
- 在解码过程中,Transformer 会为每个历史词元存储键(K)和值(V)。
- 这样就能在计算注意力时访问所有先前词元,无需重复计算。
- 问题在于:对于长提示词(如 8K+ 词元)和超大模型(70B+ 参数),缓存可能占用大部分 GPU 内存。
6.2 INT8/INT4 KV 缓存
- 将键和值以更低精度(如 INT8 或 INT4)存储,可大幅减少内存占用。
- 精度损失极小,因为注意力机制对 K/V 矩阵中的微小取整噪声具有较强的容忍度。
用一种更为直观的方式理解:注意力机制包容性强,就像听 128kbps 的歌曲 ------ 细节虽有损失,但整体旋律依旧清晰。
6.3 反量化 or 直接在整数域中进行计算
两种实现方式:
1)动态反量化(Dequant on-the-fly)
- 在计算注意力时,将 INT8/INT4 临时转回 FP16
- 有轻微计算开销,但内存效率高
2)在整数域中直接计算(Compute directly in integer domain)
- 充分利用支持低精度运算的硬件(如支持 INT8 的 GPU)
- 速度更快、内存数据移动量更少,但工程实现稍复杂
6.4 实用建议
- 将 KV 缓存量化与分层混合精度结合使用,效果最佳。
- INT8 KV 缓存通常很安全;若使用 INT4,建议配合高级取整策略(如 GPTQ 或 AWQ)。
- 务必在长序列上进行测试 ------ 短上下文的基准测试无法暴露潜在的模型幻觉或词元错位问题。
07 量化技术实战工作流
在深入研究了量化的原理、误差来源和高级技巧后,我意识到真正的挑战不在于理解量化,而在于如何安全地实施它而不破坏模型。以下是我的实践方法。
7.1 准备校准数据集
在调整任何权重之前,首先准备一个体量小但具有代表性的数据集:
- 包含 100-500 条覆盖模型典型任务的输入序列
- 目的:记录每一层激活值的数值范围和分布形态,从而为后续的量化过程提供准确的统计依据。
- 原因:如果推理时的激活值分布与校准数据偏差过大,INT4 量化可能会失败
7.2 逐层确定精度
并非所有网络层都能同等程度地适应 INT4 精度:
- MLP 层和大多数注意力权重 → 采用 INT4
- 嵌入层 → 若存在风险则采用 INT8
- LayerNorm、LM Head 及有时首个投影层 → 回退至 FP16 精度
7.3 执行量化操作
- 首先进行训练后量化(PTQ),通常将所有权重转为 INT8,检查模型输出
- 然后使用 GPTQ 或 AWQ 逐步将 MLP /注意力层降至 INT4
- 始终将敏感网络层保持在 FP16 精度
此阶段是迭代过程:应用量化 → 测试 → 调整网络层精度
7.4 评估与调试
这是理论照进现实的环节:
- 使用真实场景的提示词进行测试,而非仅依赖基准数据集
- 检查是否出现幻觉、词元错位或推理能力下降
- 若某网络层表现异常,可选择性地恢复其精度或尝试按通道缩放
7.5 微调(可选步骤)
对于激进的低比特量化(如 INT4、混合 3-4 位量化),有时需要进行轻量级的量化感知微调:
- 在校准数据上训练几个 epoch
- 让模型适应量化引入的噪声
- 通常能将 INT4 的性能表现提升至接近 FP16 水平
7.6 部署就绪
当量化稳定后:
- KV 缓存也进行量化(INT8/INT4),提升内存效率
- 对那些被特意保留为较高精度的层,已采取保护措施
- 模型已通过长上下文任务测试
最终成果:内存占用更小,推理速度更快,精度损失微乎其微。当第一次看到 70B 参数的模型在单张 GPU 上流畅运行时,那种感觉堪称神奇。
08 应用场景
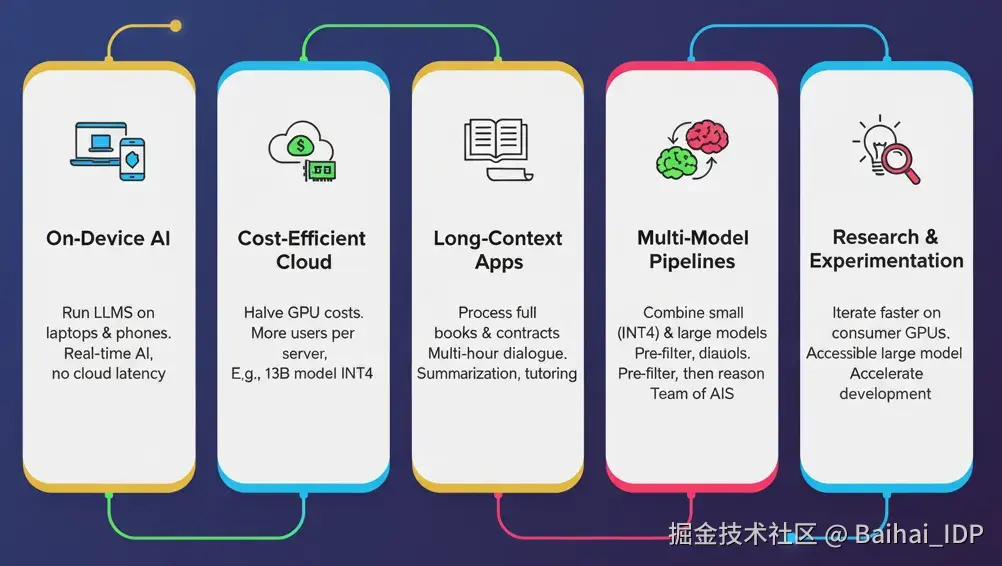
- 端侧 AI(On-Device AI) :量化让我能直接在笔记本、边缘设备甚至手机上运行大语言模型。过去需要多卡 GPU 服务器的模型,如今单张 GPU 就能装下,让 AI 能够进行实时交互,摆脱云端延迟。我用它来做笔记、进行代码补全、当离线聊天助手 ------ 就像把一台超级计算机装进了背包里。
- 高性价比的云端部署(Cost-Efficient Cloud Deployment) :即使在云端,量化也能大幅降低 GPU 内存占用,使单个节点能够服务更多用户,大幅节省运维成本。例如,如果一个 13B 模型在 INT4 精度下的表现几乎与 FP16 相当,但 GPU 内存占用减少了一半,这样使得预算有限的团队也可以部署高性能的 LLM。
- 长上下文应用(Long-Context Applications) :通过降低 KV 缓存的内存占用,使得处理长文档成为可能。借助 INT8 或 INT4 的 KV 缓存,我成功实现了整本书籍的摘要生成、分析法律合同,甚至维持数小时的连续对话而不会爆内存。这让虚拟助手、教学系统和摘要工具能无缝处理超长上下文。
- 多模型协作流水线(Multi-Model Pipelines) :量化模型在混合流水线中表现尤为出色。我经常用小型 INT4 模型做初步筛选或生成初始建议,再将结果交给更大的模型进行最终推理。若无量化技术,并行调度多个模型会很容易超出内存限制。而现在,就像在一台机器上部署了一整个 AI 专家团队。
- 研究与实验(Research and Experimentation) :最后,量化技术让实验变得更快速、更便宜。我可以在消费级 GPU 上迭代新架构、测试模型消融实验或微调模型,无需等待昂贵的专用硬件。这极大加速了我们的学习与实验进程,让大模型研究变得更加触手可及。
END
本期互动内容 🍻
❓你觉得未来大模型会默认以量化形式发布,还是保留"原始精度+按需量化"的模式?
本文经原作者授权,由 Baihai IDP 编译。如需转载译文,请联系获取授权。
原文链接: