向量加法是一个经典的并行计算示例,非常适合作为学习 CUDA 的起点。任务是将两个等长向量 AAA 和 BBB 中的对应元素相加,结果存储到向量 CCC 中,即 Ci=Ai+BiCi = Ai + BiCi=Ai+Bi。
1. 核心概念回顾
在编写程序之前,我们需要明确 CUDA 中的两个核心角色:
| 角色 | 描述 | 编程环境 |
|---|---|---|
| 主机 (Host) | CPU 及其系统内存。负责程序的串行部分、内存分配和 Kernel 启动。 | 标准 C/C++ 代码 |
| 设备 (Device) | NVIDIA GPU 及其板载内存。负责程序的并行部分(Kernel 代码)的执行。 | CUDA C/C++ 代码 |
2. CUDA 向量加法程序结构
一个完整的 CUDA 向量加法程序通常分为以下六个步骤:
-
主机初始化: 在 CPU 内存中分配和初始化输入数据 AAA 和 BBB。
-
设备内存分配: 在 GPU 全局内存中分配存储空间 d_A,d_B,d_Cd\_A, d\_B, d\_Cd_A,d_B,d_C。
-
数据传输(H →\to→ D): 将输入数据从主机内存 h_A,h_Bh\_A, h\_Bh_A,h_B 复制到设备内存 d_A,d_Bd\_A, d\_Bd_A,d_B。
-
内核启动与执行: 配置线程网格,并在 GPU 上启动 Kernel 函数。
-
数据传输(D →\to→ H): 将计算结果从设备内存 d_Cd\_Cd_C 复制回主机内存 h_Ch\_Ch_C。
-
资源清理: 释放主机和设备上分配的所有内存。
3. CUDA C/C++ 代码实现
我们将程序分为两个主要部分:在 GPU 上执行的并行 Kernel 函数,以及在 CPU 上执行的主机代码。
3.1 Kernel 函数:vectorAdd
Kernel 函数是 CUDA 程序的并行核心,用 __global__ 修饰符声明。
c++
/**
* @brief 在设备 (GPU) 上执行的向量加法 Kernel 函数。
* * @param A 输入向量 A (设备指针)
* @param B 输入向量 B (设备指针)
* @param C 输出向量 C = A + B (设备指针)
* @param N 向量长度
*/
__global__ void vectorAdd(const float* A, const float* B, float* C, int N) {
// 1. 计算当前线程的全局唯一索引 i
// blockIdx.x: 当前线程块的索引 (从 0 到 GridDim.x - 1)
// blockDim.x: 每个线程块的线程数量
// threadIdx.x: 当前线程在块内的索引 (从 0 到 BlockDim.x - 1)
int i = blockIdx.x * blockDim.x + threadIdx.x;
// 2. 边界检查:确保线程索引不超过向量长度 N
// 这样做是为了防止当 N 不是 blockDim.x 的整数倍时,有额外的线程越界访问。
if (i < N) {
// 3. 执行核心计算:并行地计算 C[i] = A[i] + B[i]
C[i] = A[i] + B[i];
}
}代码说明:
-
__global__: 标识符,表示该函数是一个 Kernel,从主机调用并在设备上执行。 -
blockIdx.x和threadIdx.x: 内置变量,用于标识当前线程在并行结构中的位置。通过简单的线性组合,每个线程获得了它应该处理的元素 iii 的唯一索引。 -
并行性: 假设 N=10000N=10000N=10000,如果启动了 100001000010000 个线程,那么 100001000010000 个 CiCiCi 的计算将同时(或并发地)在 GPU 的数千个核心上执行。
3.2 主机代码:main 函数
主机代码负责设置环境、调用 Kernel 并进行验证。
C
#include <iostream>
#include <vector>
#include <cmath> // For std::abs
// 假设 vectorAdd Kernel 定义在上文或其他地方
// __global__ void vectorAdd(const float* A, const float* B, float* C, int N);
void runVectorAddition() {
// 定义向量大小
const int N = 1000000;
const size_t bytes = N * sizeof(float);
// --- 1. 主机初始化 ---
// 在主机 (CPU) 内存上分配和初始化向量
std::vector<float> h_A(N);
std::vector<float> h_B(N);
std::vector<float> h_C(N); // 存储 GPU 结果
std::vector<float> h_ref(N); // 存储 CPU 参考结果
// 初始化输入数据
for (int i = 0; i < N; ++i) {
h_A[i] = (float)i;
h_B[i] = (float)(i * 2);
}
std::cout << "初始化数据完成。向量长度 N = " << N << std::endl;
// --- 2. 设备内存分配 ---
float *d_A, *d_B, *d_C; // 设备指针
// cudaMalloc 函数用于在 GPU 全局内存中分配内存
if (cudaMalloc((void**)&d_A, bytes) != cudaSuccess) exit(EXIT_FAILURE);
if (cudaMalloc((void**)&d_B, bytes) != cudaSuccess) exit(EXIT_FAILURE);
if (cudaMalloc((void**)&d_C, bytes) != cudaSuccess) exit(EXIT_FAILURE);
std::cout << "设备内存分配完成。" << std::endl;
// --- 3. 数据传输 (H -> D) ---
// cudaMemcpy 函数用于在不同内存空间之间进行数据拷贝
cudaMemcpy(d_A, h_A.data(), bytes, cudaMemcpyHostToDevice);
cudaMemcpy(d_B, h_B.data(), bytes, cudaMemcpyHostToDevice);
std::cout << "数据从主机传输到设备完成。" << std::endl;
// --- 4. 配置 Kernel 启动参数 ---
// 线程配置是实现并行性的关键
const int threadsPerBlock = 256; // 每个块 256 个线程
// 计算所需线程块的数量,确保覆盖所有 N 个元素
const int numBlocks = (N + threadsPerBlock - 1) / threadsPerBlock;
// --- 5. Kernel 启动与执行 ---
// Kernel 启动语法:function_name<<<GridDim, BlockDim>>>(args...)
std::cout << "启动 Kernel:Grid size=" << numBlocks << ", Block size=" << threadsPerBlock << std::endl;
vectorAdd<<<numBlocks, threadsPerBlock>>>(d_A, d_B, d_C, N);
// 检查是否有异步错误发生
cudaError_t err = cudaGetLastError();
if (err != cudaSuccess) {
std::cerr << "Kernel 启动失败: " << cudaGetErrorString(err) << std::endl;
exit(EXIT_FAILURE);
}
// 等待设备完成所有计算
cudaDeviceSynchronize();
// --- 6. 数据传输 (D -> H) ---
// 将结果从设备内存 d_C 复制回主机内存 h_C
cudaMemcpy(h_C.data(), d_C, bytes, cudaMemcpyDeviceToHost);
std::cout << "结果从设备传输回主机完成。" << std::endl;
// --- 7. 资源清理 ---
cudaFree(d_A);
cudaFree(d_B);
cudaFree(d_C);
std::cout << "设备内存释放完成。" << std::endl;
// --- 8. 结果验证 ---
// CPU 串行计算参考结果
for (int i = 0; i < N; ++i) {
h_ref[i] = h_A[i] + h_B[i];
}
// 比较 GPU 结果与 CPU 参考结果
int errors = 0;
for (int i = 0; i < N; ++i) {
if (std::abs(h_C[i] - h_ref[i]) > 1e-5) {
errors++;
}
}
if (errors == 0) {
std::cout << "✅ 结果验证成功!CUDA 计算结果正确。" << std::endl;
} else {
std::cout << "❌ 结果验证失败!发现 " << errors << " 个错误。" << std::endl;
}
}
int main() {
runVectorAddition();
return 0;
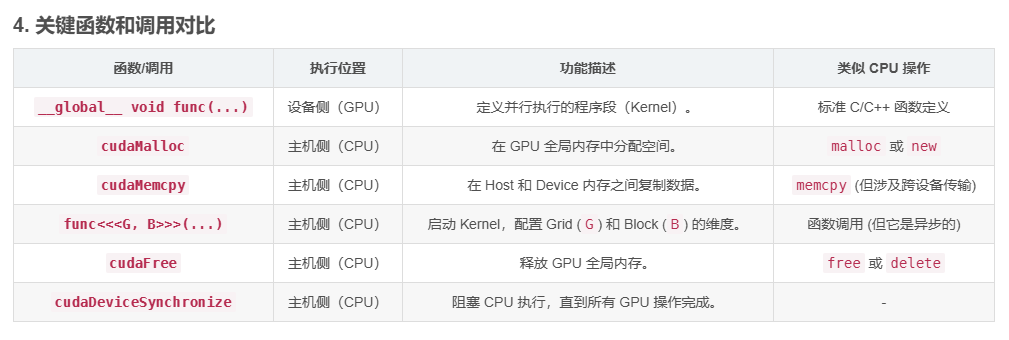
}4. 关键函数和调用对比
| 函数/调用 | 执行位置 | 功能描述 | 类似 CPU 操作 |
|---|---|---|---|
__global__ void func(...) |
设备侧(GPU) | 定义并行执行的程序段(Kernel)。 | 标准 C/C++ 函数定义 |
cudaMalloc |
主机侧(CPU) | 在 GPU 全局内存中分配空间。 | malloc 或 new |
cudaMemcpy |
主机侧(CPU) | 在 Host 和 Device 内存之间复制数据。 | memcpy (但涉及跨设备传输) |
func<<<G, B>>>(...) |
主机侧(CPU) | 启动 Kernel,配置 Grid (G) 和 Block (B) 的维度。 |
函数调用 (但它是异步的) |
cudaFree |
主机侧(CPU) | 释放 GPU 全局内存。 | free 或 delete |
cudaDeviceSynchronize |
主机侧(CPU) | 阻塞 CPU 执行,直到所有 GPU 操作完成。 | - |
5. 编译与运行
CUDA 程序需要使用 NVIDIA 提供的 nvcc (NVIDIA CUDA Compiler) 进行编译。
编译流程:
-
将上述代码保存为
vector_add.cu文件。 -
在命令行中使用
nvcc编译:bashnvcc vector_add.cu -o vector_add -
运行可执行文件:
bash./vector_add
这个向量加法程序简洁而完整地展示了 CUDA 异构编程模型的精髓:CPU 管理资源和任务,GPU 高度并行地执行计算。