目录
一、引言:释放极致算力,openFuyao如何破局?
1.1、算力时代的"近"与"远"
随着 AI 大模型、自动驾驶、实时数据分析、云计算 等技术的爆发式增长,现代计算系统正承受前所未有的算力需求。大模型训练需要 海量矩阵运算 与 高带宽内存;数据中心要处理 实时海量数据流;企业级业务希望在更低成本下获得更高吞吐与更低时延。结果就是:"算力"成为新的生产力核心,CPU/GPU 集群的每一分性能都至关重要。现在算力对于AI发展来说真的是至关重要。
虽然硬件算力持续增长,CPU、显卡等都的性能都爆发式的增长,但实际系统性能却常常达不到理论值。这究竟是为什么呢?
我总结了如下一些原因:
线程调度不合理、内存分配不均、IO 路径冗余、资源竞争严重。这些都会导致硬件闲置或利用率低下。而且现代多 CPU/多核服务器普遍采用 NUMA。在这种架构下:访问"本地"内存速度快,访问其他节点的"远程"内存延迟显著增加。如果调度不合理,例如线程被放在 A 节点,而它要访问的数据却在 B 节点,就会出现:访问延迟成倍增加、吞吐下降、延迟抖动,最终导致整机性能"打折"。
1.2、openFuyao的答案
openFuyao社区作为面向通算和智算集群软件技术创新的开源社区,致力于为世界提供多样化算力集群软件生态,释放智能无限价值。openFuyao通过开放协作汇聚伙伴与开发者,打造多样化算力互联调度能力,实现集群的算力极致释放与安全可靠。
围绕算力调度、资源管理与场景适配,openFuyao 构建七大核心能力,覆盖关键技术领域:
- 分布式 AI 推理框架:优化 AI 推理部署与运行效率;
- 分布式作业调度:减少分布式任务等待延迟;
- 大规模集群调度:支持万节点级集群高负载可靠运行;
- 在离线混部调度:动态分配资源,提升集群资源利用率;
- NUMA 亲和调度:绑定 CPU 与内存,降低跨节点延迟,提升内存密集型场景性能;
- 异构硬件资源池化:统一管理多架构硬件(CPU/GPU 等);
- 多样化算力使能:极简接入硬件,提升 AI 推理、大数据场景性能。


提供开箱即用的方案,降低生态伙伴集成落地门槛:
- 轻量级容器平台:基于 Kubernetes 构建,覆盖应用全生命周期管理,支持多云异构 K8S 统一管理,适配中小规模企业容器化转型;
- 一站式 AI 推理一体机方案:集成硬件资源、系统软件与预置开源模型,实现 "开箱即生产",苏州农商行等案例中,将业务环境就绪时间从天级缩短至小时级。
NUMA 亲和调度是 openFuyao 七大集群核心能力之一,专门针对非一致内存访问(NUMA)架构的硬件特性设计,核心目标是通过优化 CPU 与内存的调度绑定,减少跨节点内存访问延迟,提升内存密集型、高性能计算场景的算力利用效率。
二、核心解读:深入理解NUMA亲和调度的方法论
2.1、NUMA是什么?为什么需要"亲和"?
NUMA是一种多处理器架构,其中每个处理器都有自己的本地内存,访问本地内存比访问其他处理器的远程内存更快。在现代多核服务器中,NUMA架构已成为标准配置,特别是在高性能计算环境中。
NUMA亲和调度的核心思想是将计算任务尽可能调度到与其所需资源"距离最近"的NUMA节点上,最小化跨节点访问,从而降低内存访问延迟,提升整体系统性能。这对于内存密集型和高性能计算应用尤为重要。
NUMA亲和调度实现原理:
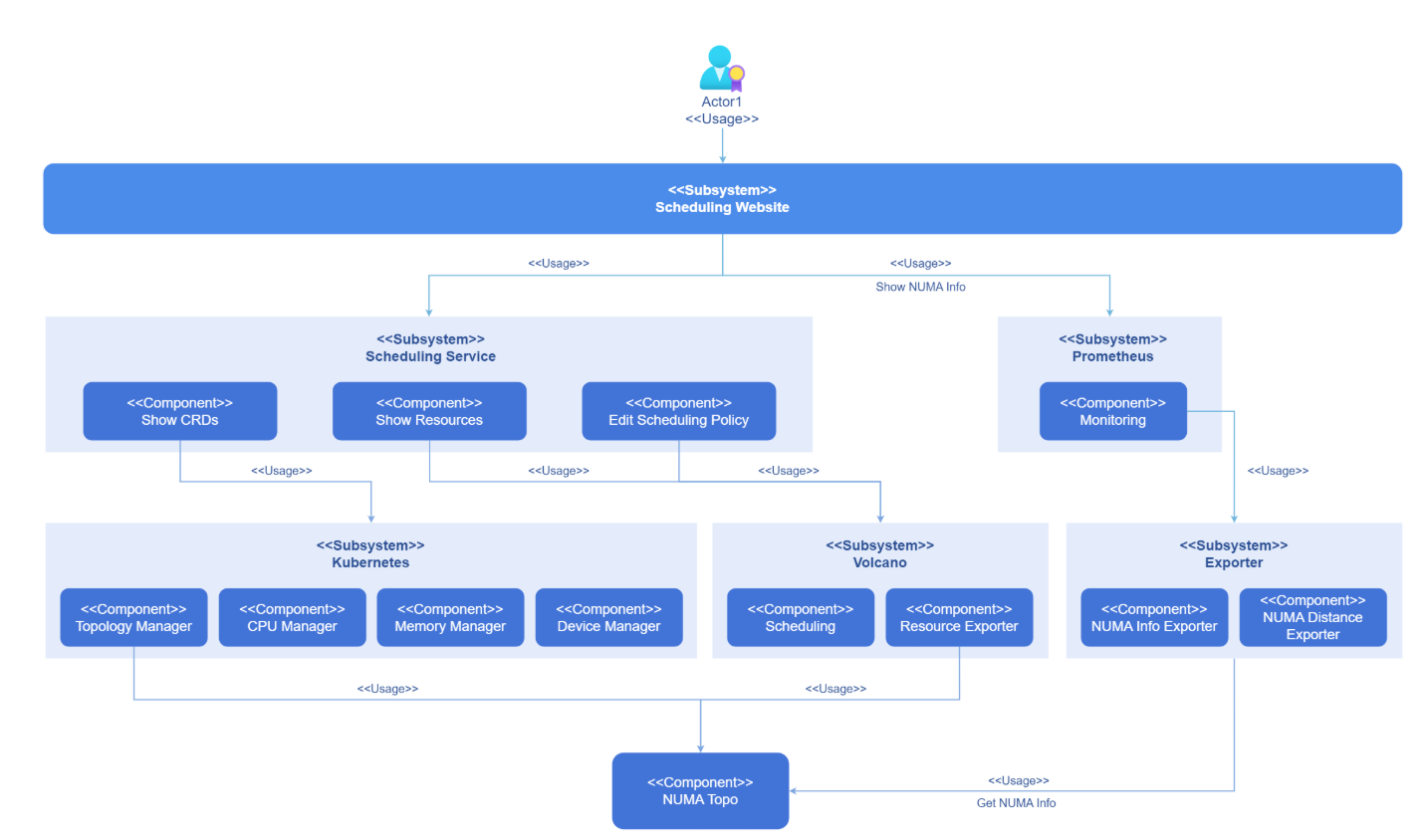
2.2、K8s原生调度的局限性
原生Kubernetes调度器在资源分配时主要关注资源请求量和节点标签匹配,缺乏对NUMA拓扑结构的感知能力。这可能导致如下这些问题:
- Pod被调度到非最优NUMA节点,造成内存访问延迟增加
- CPU和内存资源跨NUMA节点分配,影响性能敏感型应用的运行效率
- 缺乏细粒度的NUMA拓扑感知,无法实现精确的资源优化
2.3、基于Volcano实现的NUMA感知调度机制
核心机制:
以 Volcano 调度引擎为基础,结合 NUMA 架构特性,通过 "拓扑策略配置→节点过滤→CPU / 内存亲和绑定→负载均衡" 闭环实现调度优化:先依据 Pod 拓扑需求筛选节点,再将任务绑定至初始内存分配的 "HOME 节点" 及本地 CPU,搭配节点内 1ms 级、跨节点 200ms 级负载均衡,避免跨节点内存访问。
Volcano NUMA亲和调度的流程:
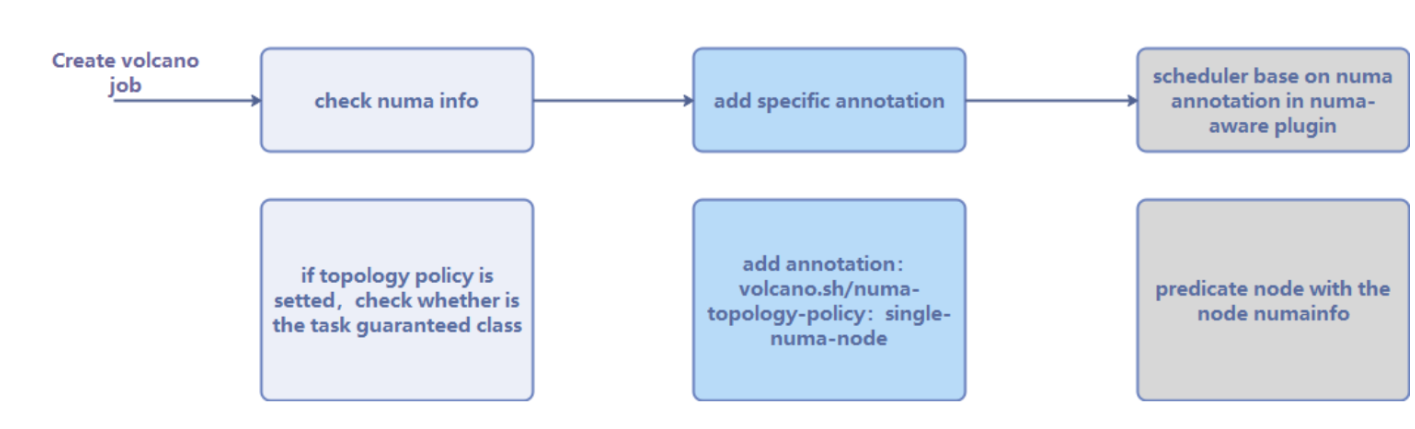
volcano调度:
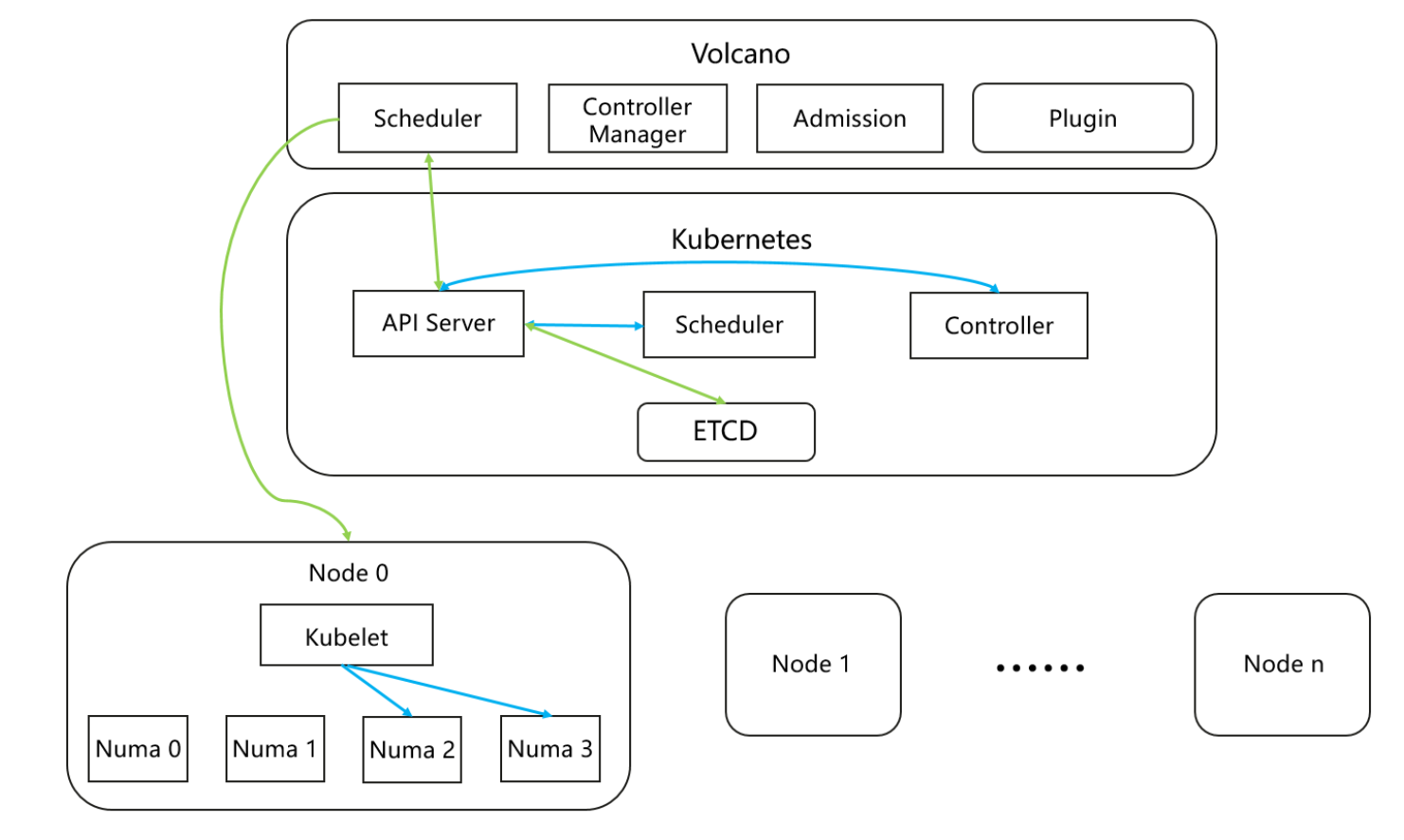
优势:
- 低延迟高吞吐:通过减少跨节点远地内存访问,显著优化内存密集型、时延敏感场景的运行效率,提升业务处理流畅度与稳定性,尤其适配对响应速度要求高的关键业务场景。
- 资源利用率优化:实现 CPU 与内存资源的精准匹配,降低 CPU 因等待远地内存数据产生的空闲时间;同时结合 Volcano 的批量调度能力,进一步提升集群整体资源的使用效率,减少资源浪费。
- 场景适配灵活:支持多种 NUMA 拓扑策略配置,可根据不同业务场景(如 AI 训练、数据库运维、分布式计算等)的算力需求灵活调整调度规则,兼容多元业务场景的差异化诉求。
- 轻量化集成高效:复用 Volcano 成熟的调度框架与底层能力,无需对现有集群架构进行重构,能快速完成调度机制的部署集成;且升级过程不影响业务正常运行,实现高效落地与迭代。
2.4 资源超卖机制
openFuyao 的资源超卖聚焦 "资源高效复用 + 安全可控":通过 oversub-resource 组件采集节点 CPU / 内存的实时负载,基于预设阈值(如 CPU 超配比例、内存水位线)实现物理资源的超额分配,让节点实际承载的资源需求超过硬件标称容量。
同时依托内核级调优组件(如 rubik-agent)动态调整资源优先级,在超卖后资源接近饱和时,限制低优先级资源的占用比例,避免超卖导致节点稳定性风险,最终在不影响核心业务的前提下,将集群资源利用率提升至更高水平。
资源超卖解决方案示例图:
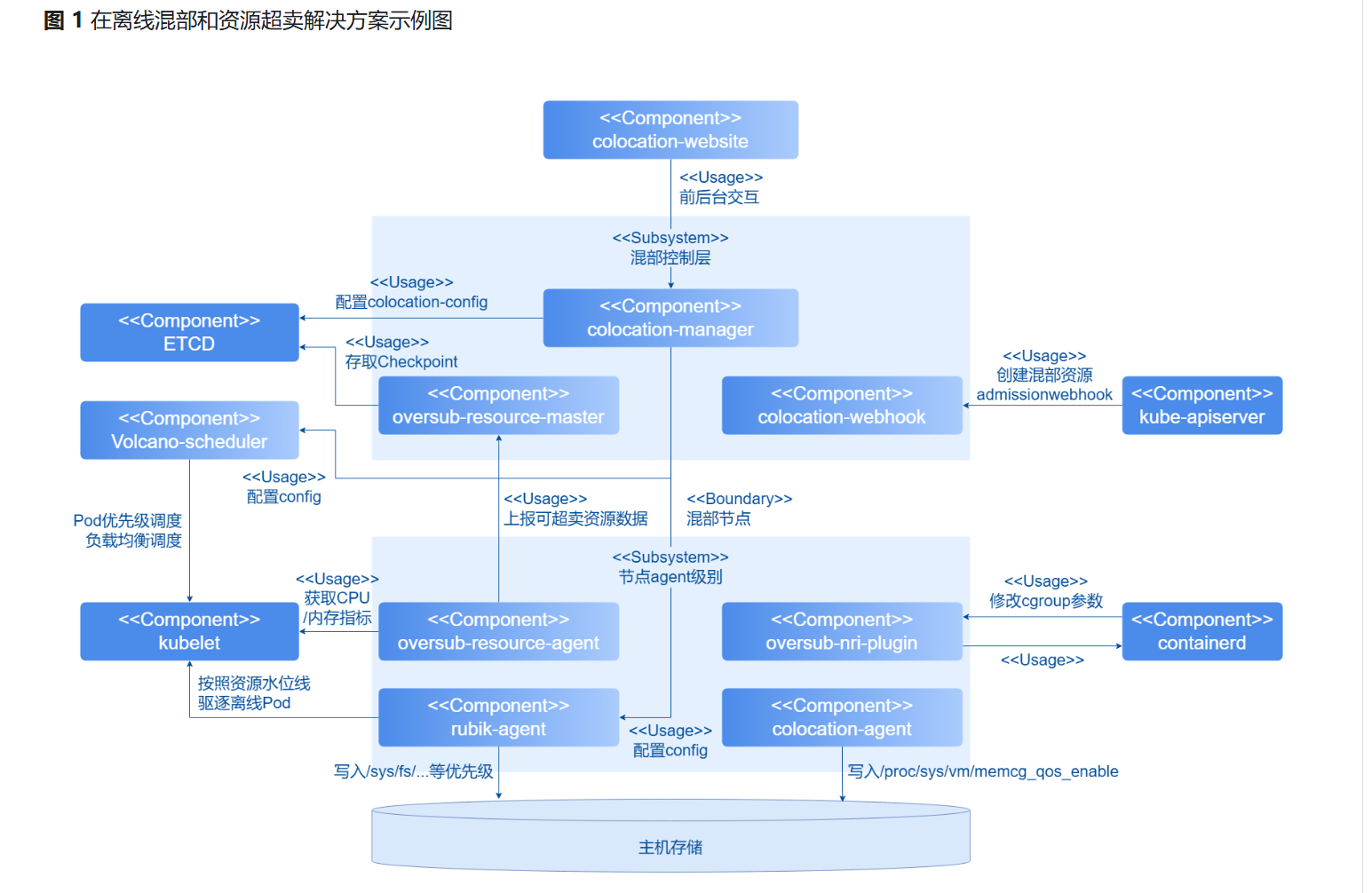
三、实践与价值:NUMA亲和调度的实战演练
3.1、快速上手:在openFuyao中启用NUMA亲和调度
接下来带大家来进行实际的操作,我们按照官网提供的快速入门手册就可以进行快速的安装和部署;
在官网可以直接找到快速入门的教程:
下载软件包:
将已下载的安装包上传至本机,解压后将安装二进制文件移动至系统路径。
也可以执行已下的指令下载:
plain
curl -sfL https://openfuyao.obs.cn-north-4.myhuaweicloud.com/openFuyao/bkeadm/releases/download/v25.09/download.sh | bash将压缩包进行解压:
plain
tar -xvf bkeadm_linux_amd64.tar.gz初始化引导节点:
plain
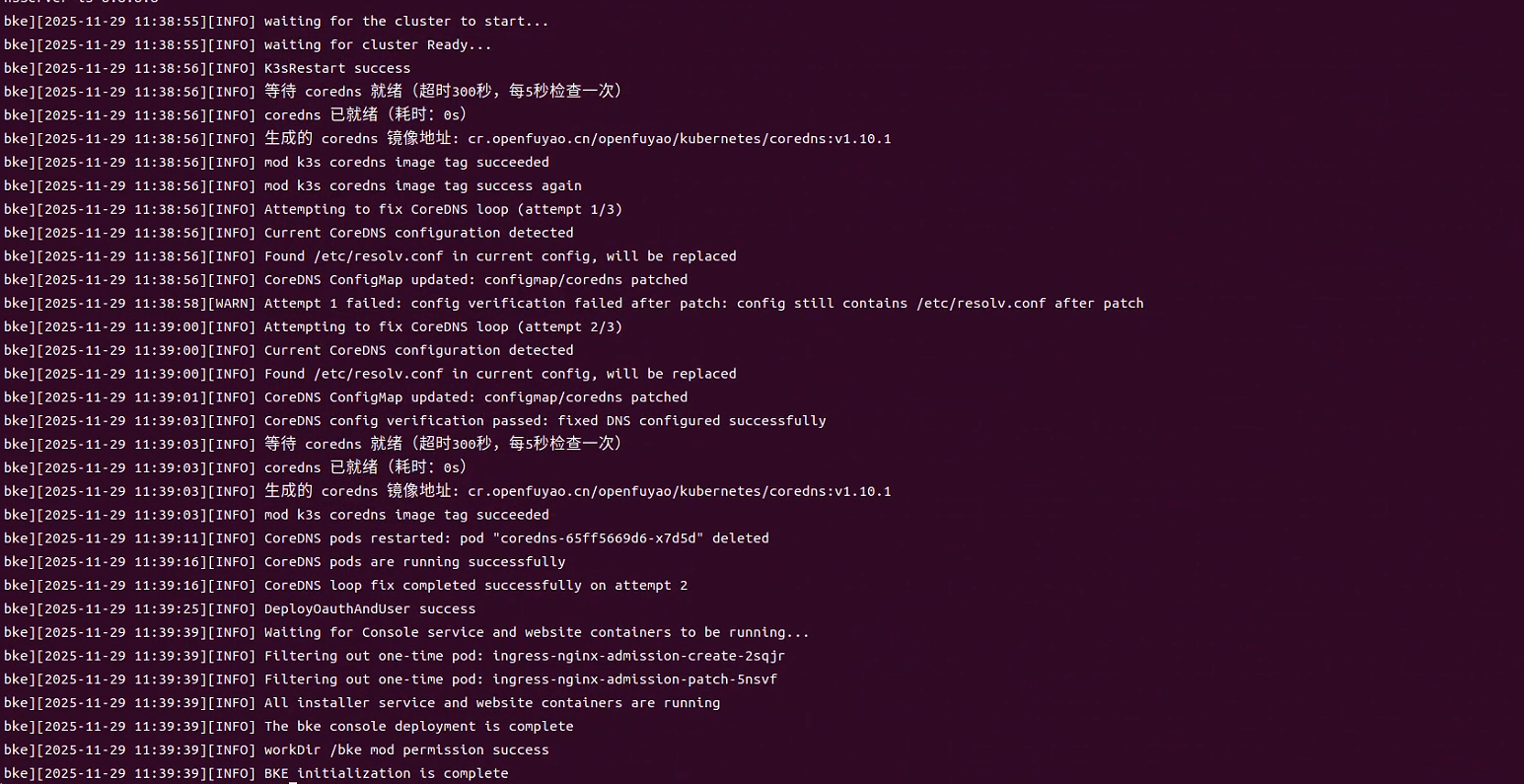
bke init --otherRepo cr.openfuyao.cn/openfuyao/bke-online-installed:v25.09确认节点初始化结果:
执行如下命令,查看机器上所有Pod状态:
plain
kubectl get pod -A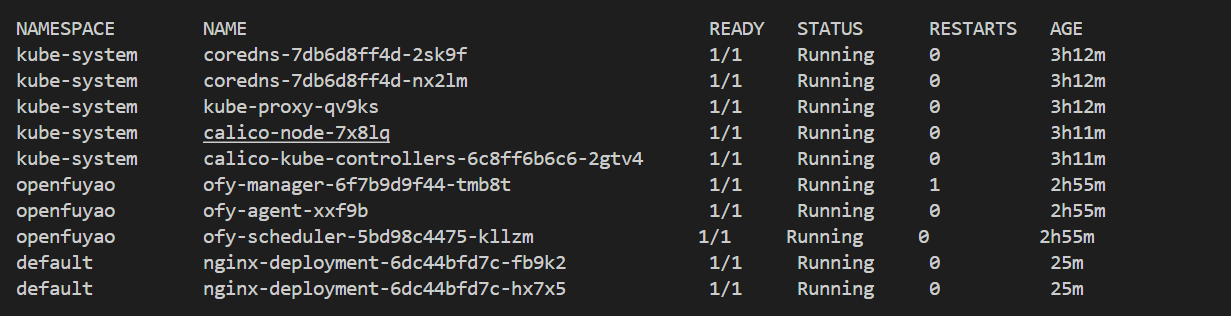
接下来我们就可以在浏览器地址栏输入 http://主节点IP:8080,即可进入 openFuyao 的可视化管理界面(默认账号与密码均为 admin)。登录成功后,可在"集群概览"页面查看节点数量、资源使用情况等信息,以确认安装已正确生效。
要在部署应用时使用NUMA亲和调度,需要在Pod规范中指定Volcano调度器并添加相应的注解:
基础配置示例:
plain
apiVersion: apps/v1
kind: Deployment
metadata:
name: numa-optimized-app
namespace: production
spec:
replicas: 3
selector:
matchLabels:
app: numa-app
template:
metadata:
labels:
app: numa-app
annotations:
scheduling.openfuyao.io/numa-affinity: "best-effort"
scheduling.openfuyao.io/topology-awareness: "enabled"
spec:
schedulerName: volcano # 指定Volcano调度器
containers:
- name: app-container
image: myapp:latest
resources:
requests:
cpu: "4"
memory: "8Gi"
limits:
cpu: "8"
memory: "16Gi"
env:
- name: NUMA_AWARENESS
value: "enabled"高性能计算场景配置:
plain
apiVersion: batch/v1
kind: Job
metadata:
name: hpc-numa-job
spec:
parallelism: 4
template:
metadata:
annotations:
scheduling.openfuyao.io/numa-affinity: "restricted"
scheduling.openfuyao.io/preferred-numa-nodes: "0,1" # 偏好NUMA节点
spec:
schedulerName: volcano
containers:
- name: hpc-app
image: hpc-app:latest
command: ["mpirun", "-np", "16", "./application"]
resources:
requests:
cpu: "16"
memory: "32Gi"
limits:
cpu: "16"
memory: "32Gi"内存密集型应用配置:
plain
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: in-memory-database
spec:
serviceName: database
replicas: 3
template:
metadata:
annotations:
scheduling.openfuyao.io/numa-affinity: "single-numa-node"
scheduling.openfuyao.io/memory-bandwidth: "high"
spec:
schedulerName: volcano
containers:
- name: database
image: redis:latest
command: ["redis-server", "--maxmemory", "24gb"]
resources:
requests:
cpu: "8"
memory: "24Gi"
limits:
cpu: "8"
memory: "24Gi"3.2、效果分析:可视化监控带来的价值
openFuyao 的可视化监控能力,是其实现算力优化与运维提效的核心支撑之一,主要覆盖资源、任务、业务场景三类监控,价值体现在 "降本、提效、稳业务":
- 全链路资源监控通过 Web 控制台提供集群 / 节点级的 CPU、内存、磁盘等资源的实时使用数据,支持近 1 小时 / 1 天 / 7 天的趋势图表,同时覆盖容器、Pod 的运行状态与资源占用。
- 任务与业务场景监控
- 支持 AI 推理场景(如分布式 KVCache)的近实时性能指标监控(如 TTFT 延时、TPS);
- 提供在离线混部场景的 QoS 等级、资源水位等关键数据可视化;
- 集成 Ray 集群健康面板,覆盖分布式作业状态。
- 运维辅助监控内置日志中心,支持按节点、服务类型、时间筛选日志,支持关键词搜索与下载,同时提供硬件(如 NPU)运行状态监控。
带来的价值:
- 资源效率提升:通过可视化资源水位,辅助在离线混部调度更精准,直接提升集群 CPU / 内存利用率;
- 运维成本降低:无需复杂命令行操作,通过 Web 控制台即可完成节点状态、任务故障的快速排查;
- 业务稳定性保障:对 AI 推理、金融支付等时延敏感场景,近实时监控指标可支撑智能决策,减少故障恢复时间。
四、总结与展望:从NUMA亲和到算力全景优化
4.1、核心价值总结
openFuyao 的 NUMA 亲和调度深度适配硬件架构特性,为开发者和企业带来切实价值:
- 性能提升:优化节点级内存访问路径,减少跨节点延迟,对金融交易等性能敏感型应用增益显著。
- 稳定性增强:精准匹配 CPU 与内存资源,避免因资源分配失衡导致的 Pod 启动失败或运行波动。
- 运维简化:通过可视化界面简化 NUMA 拓扑管理与资源分配操作,降低复杂调度策略的配置门槛。
4.2、不止于此:openFuyao算力释放的更大蓝图
NUMA 亲和调度仅是 openFuyao 七大核心集群能力之一,它可与分布式 AI 推理加速(如分布式 KVCache)、在离线混部调度、大规模集群调度等组件深度协同,形成全方位算力优化体系,覆盖从资源管理到场景加速的全链路需求。
openFuyao 社区秉持开放协作理念,诚邀全球开发者、企业伙伴加入,共同参与技术创新、场景落地与标准共建,探索更多多样化算力释放的可能,共建全球领先的算力集群软件生态。