个人主页:chian-ocean
解锁 Vibe Coding 无限畅享模式:如何用 AI Ping + Cline 打造"全模型"开发流

前言:
在'百模大战'的当下,对于我们开发者而言,最头疼的往往不是如何写提示词,而是如何优雅地管理和切换不同的模型。今天对接了 MiniMax,明天由于业务需求又要换成 GLM,繁琐的接口文档、不统一的计费标准以及分散的 API Key 管理,常常让人在写代码前就耗尽了精力。 那么,有没有一种方式,能让我们只用一套标准,就随意调度各大厂商的顶级能力?今天就给大家推荐一个能彻底解放生产力的解决方案AI Ping(点击注册有30米的算力金清程极智)
最近做 AI 开发,说实话,最让我头疼的不是写 Prompt,而是烧钱的速度。
前段时间跑 Agent 测试,GPT-4 和 Claude 3.5 的 API 调用费简直如流水。而且市面上的模型供应商多如牛毛,为了追求性价比,我经常得在几家供应商之间切来切去,维护一堆 API Key,不仅麻烦,还经常遇到这家挂了、那家慢了的情况。
前两天在技术群里看到有人推荐 AI Ping(清程极智) ,号称是"一站式大模型服务评测与 API 调用平台"。我也去试玩了一下,发现它不光能做智能路由 帮我省钱,最重要的是------它现在配合 Vibe Coding 工具居然能免费薅羊毛!
对于 AI 开发者来说,最大的痛点往往不是技术本身,而是**"资源的受限"**。
今天就带大家实操一遍,看看如何打破限制,实现真正的"算力自由"。
第一步:接入"算力聚合中心"
官网直通车:https://www.aiping.cn/
1.1 登陆指挥中心:初识全网聚合架构
首先,访问 AI Ping 官网。映入眼帘的不仅仅是一个简单的登录界面,而是一个庞大的模型调度系统。
它的核心护城河在于**"全网聚合"**的能力。在过去,为了测试不同模型,我们被迫在 OpenAI、Anthropic、DeepSeek 等十几家供应商之间反复横跳,维护繁杂的账户体系。
而 AI Ping 在后台直接打通了行业内 27+ 顶级供应商。这意味着,只需这一个账号,你就瞬间拥有了一个可以随时调配全网数百个大模型的**"算力指挥中心"**。无论是国外的闭源巨头,还是国内的开源新星,都在你的射程范围之内。
它的核心优势在于**"全网聚合"**。不同于我们去一家家申请账号,AI Ping 后台直接打通了行业内 27+ 供应商。这意味着,拥有了这一个账号,你就拥有了一个随时调配全网数百个大模型的"指挥中心"。
1.2 检阅"军火库":数百种算力资源尽在掌控
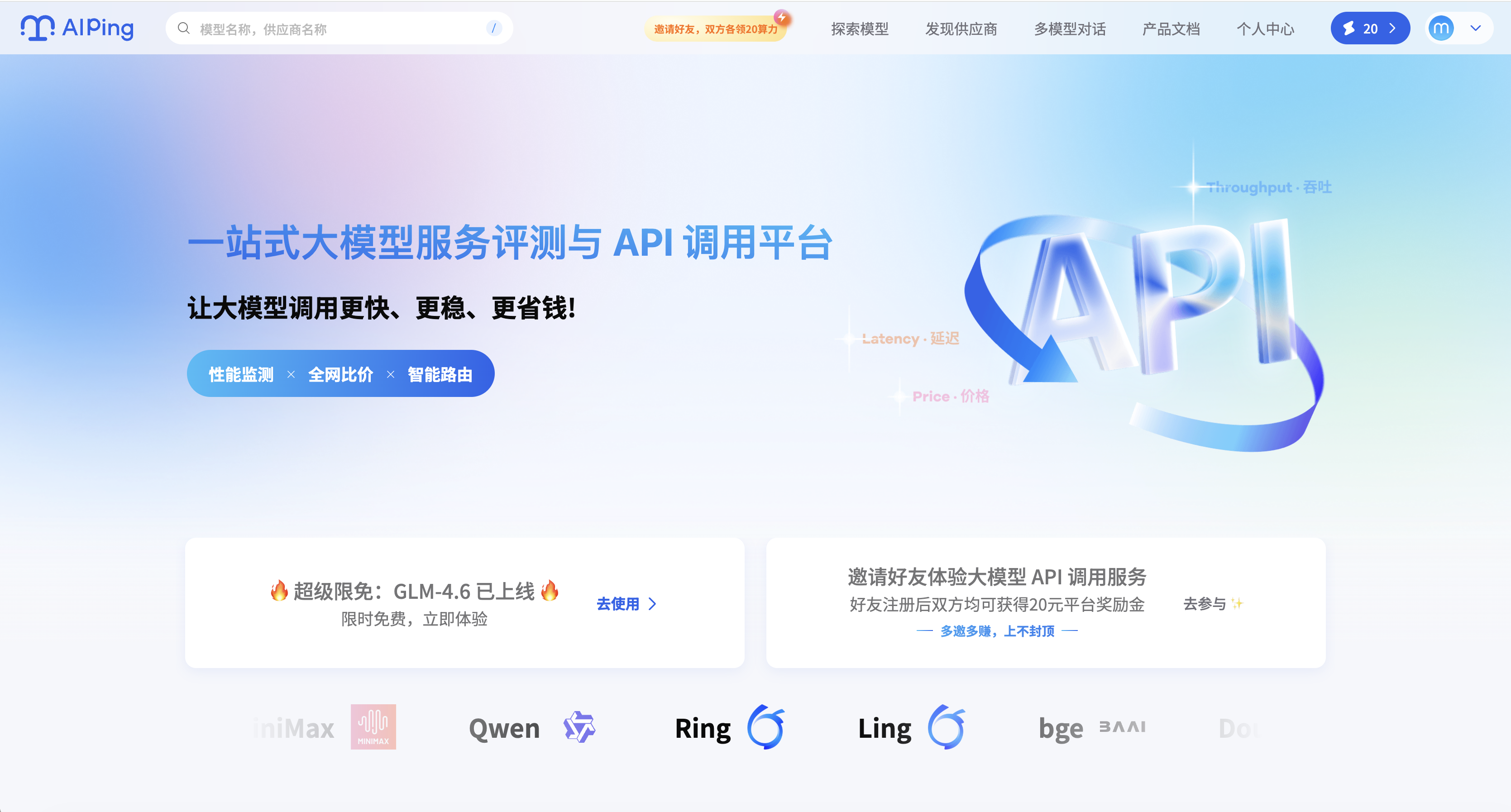
进入后台,点击"探索模型",你会看到一个令人震撼的视图。
这里不再是枯燥的列表,而是一座**"真正的大模型军火库"**。从擅长复杂逻辑推理的 Kimi-Thinking 系列,到拥有极致语感的 MiniMax,再到高性价比的 GLM 和 DeepSeek,所有主流模型矩阵在此一屏尽览。
开发者可以根据任务需求(是需要高并发?还是强逻辑?),像挑选武器一样自由组合这些算力资源。
3. 获取"万能钥匙":One Key for All
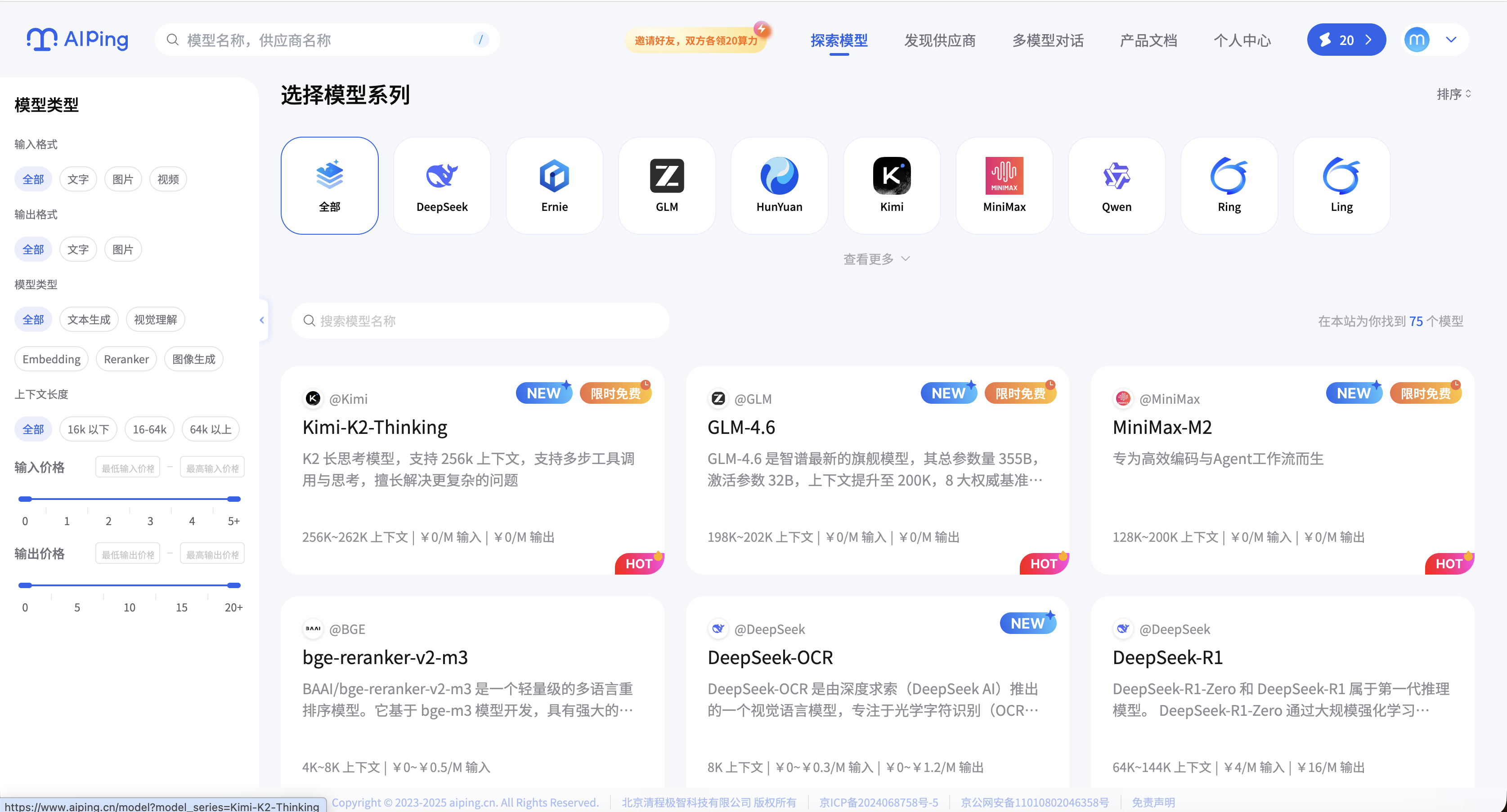
注册完成后,我们不需要复杂的申请流程,直接前往核心区域获取凭证。
- 路径指引: 点击右上角的 【个人中心】 -> 选择 【API密钥】。
在这里,你将获得两样东西:统一的 API Key 和 Base URL。请务必保存好它们,这不仅仅是一串字符,而是你后续解锁 IDE 全模型能力的**"万能钥匙"**。
通过这套标准化的 OpenAI 兼容接口,你彻底告别了碎片化的 Key 管理。无论后端接入了多少家供应商,你的代码里永远只需要维护这一套配置,实现了真正的架构解耦。
第二步:解锁 IDE 的"全模型"能力(以 VSCode + Cline 为例)
拿到了"万能钥匙"后,接下来的操作就是将这股庞大的算力注入到我们的生产力工具中。
我平时最常用的组合是 VSCode + Cline。Cline 作为目前最强的大模型编程插件之一,对 OpenAI 格式的兼容性极佳。配置过程主打一个"即插即用",全程不超过 30 秒。
2.1 安装Cline
- 这里可以选择中文或者英文的版本。
2.2 唤醒配置面板
打开 VSCode,点击侧边栏的 Cline 图标。在插件界面的右上角找到 "齿轮"图标(Settings),点击进入配置页。
2. 选择"万能适配器" (API Provider)
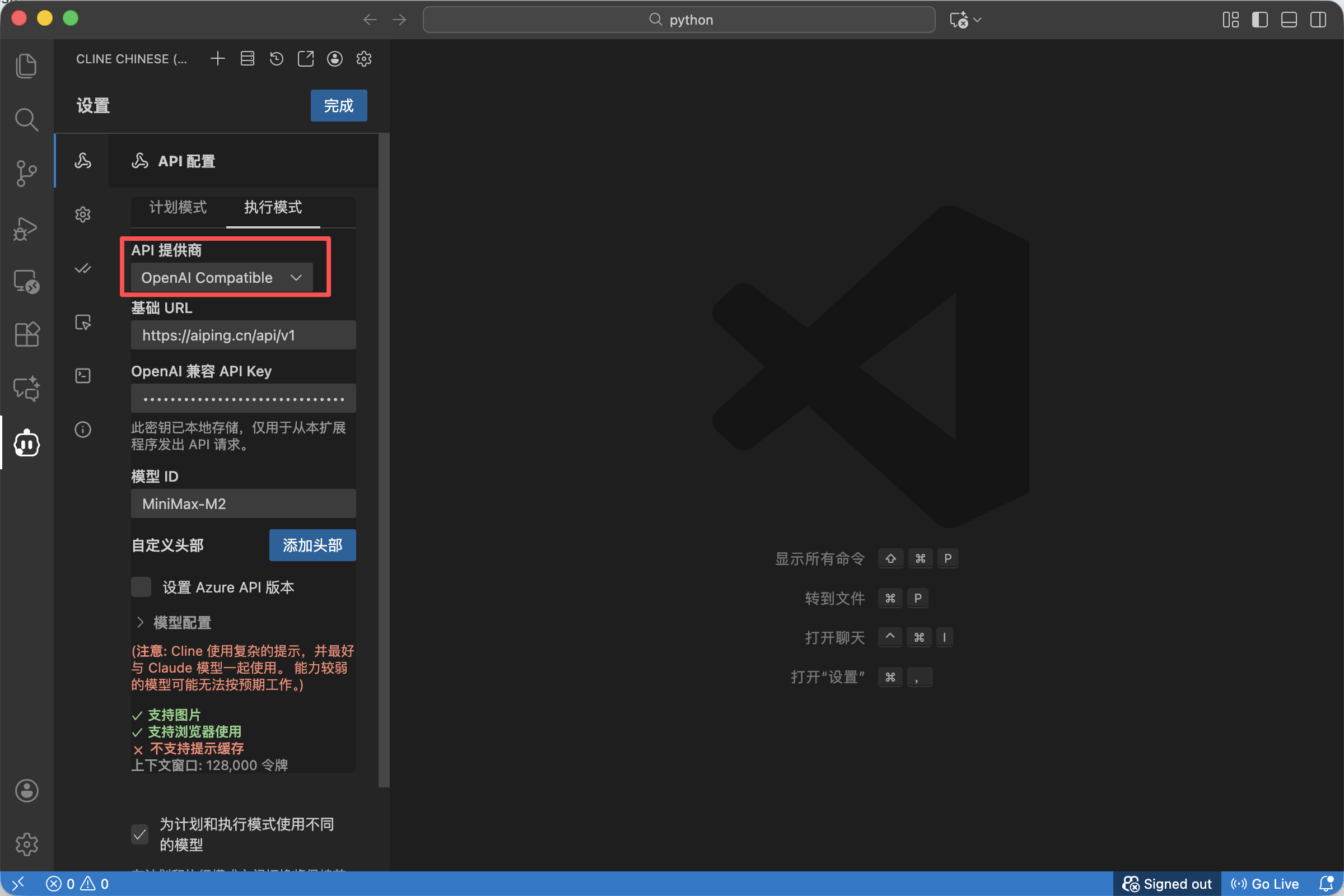
在 API Provider 的下拉菜单中,不要选择特定的厂商,请务必选择 OpenAI Compatible。
- 技术原理解析: 这一步至关重要。因为 AI Ping 采用的是标准化的 OpenAI 接口协议,选择这个选项,意味着 Cline 不再局限于连接 OpenAI 官方,而是打开了连接任意兼容接口的大门。
3. 填入"算力坐标" (Base URL & Key)
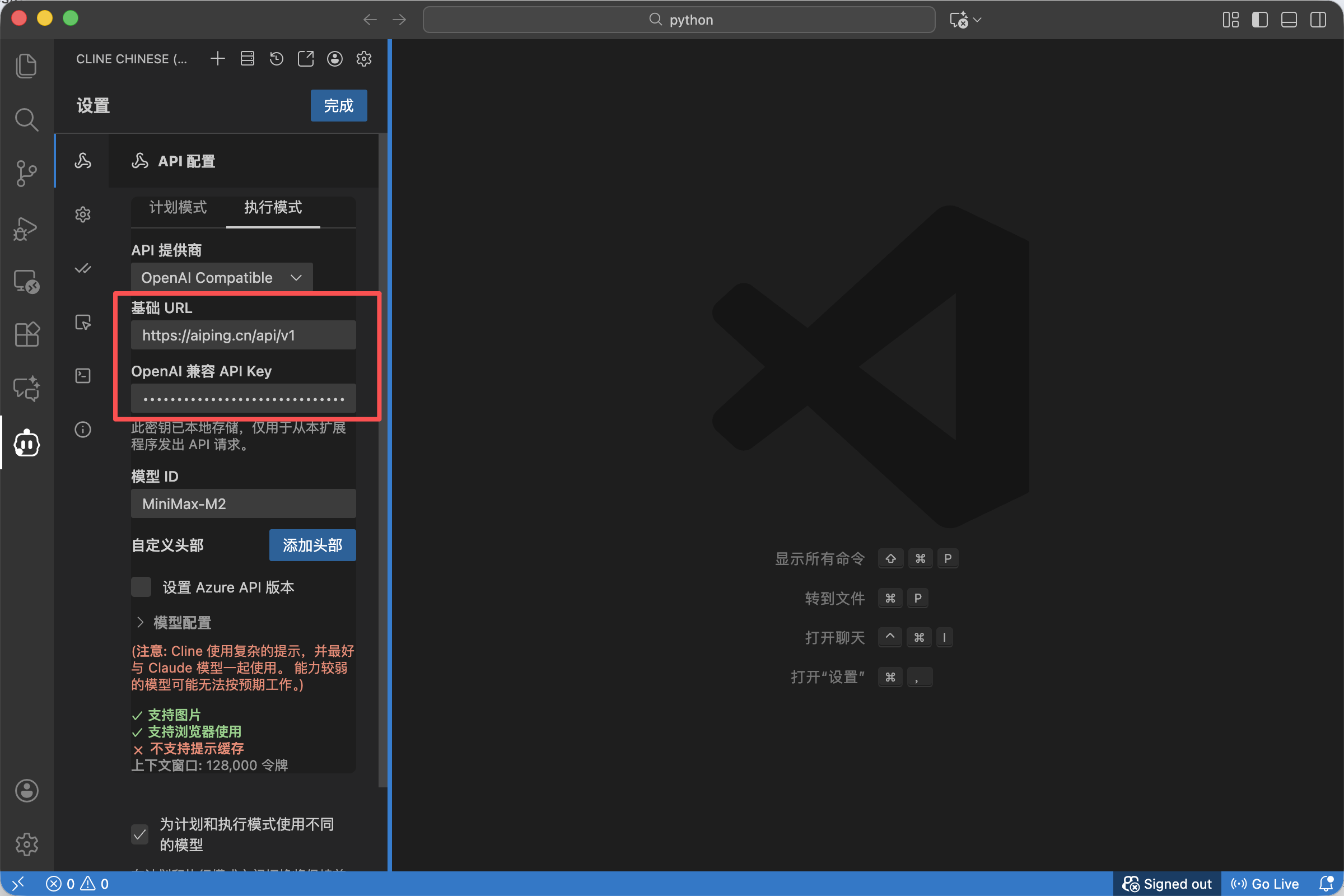
- Base URL: 填入我们在 AI Ping 后台复制的聚合接口地址(通常是 https://aiping.cn/api/v1 或类似地址)。这是我们将 IDE 连接到 AI Ping 智能路由的网关。
- API Key: 将刚才那串
QC-开头的密钥粘贴进去。
4. 指定"核心引擎" (Model ID)
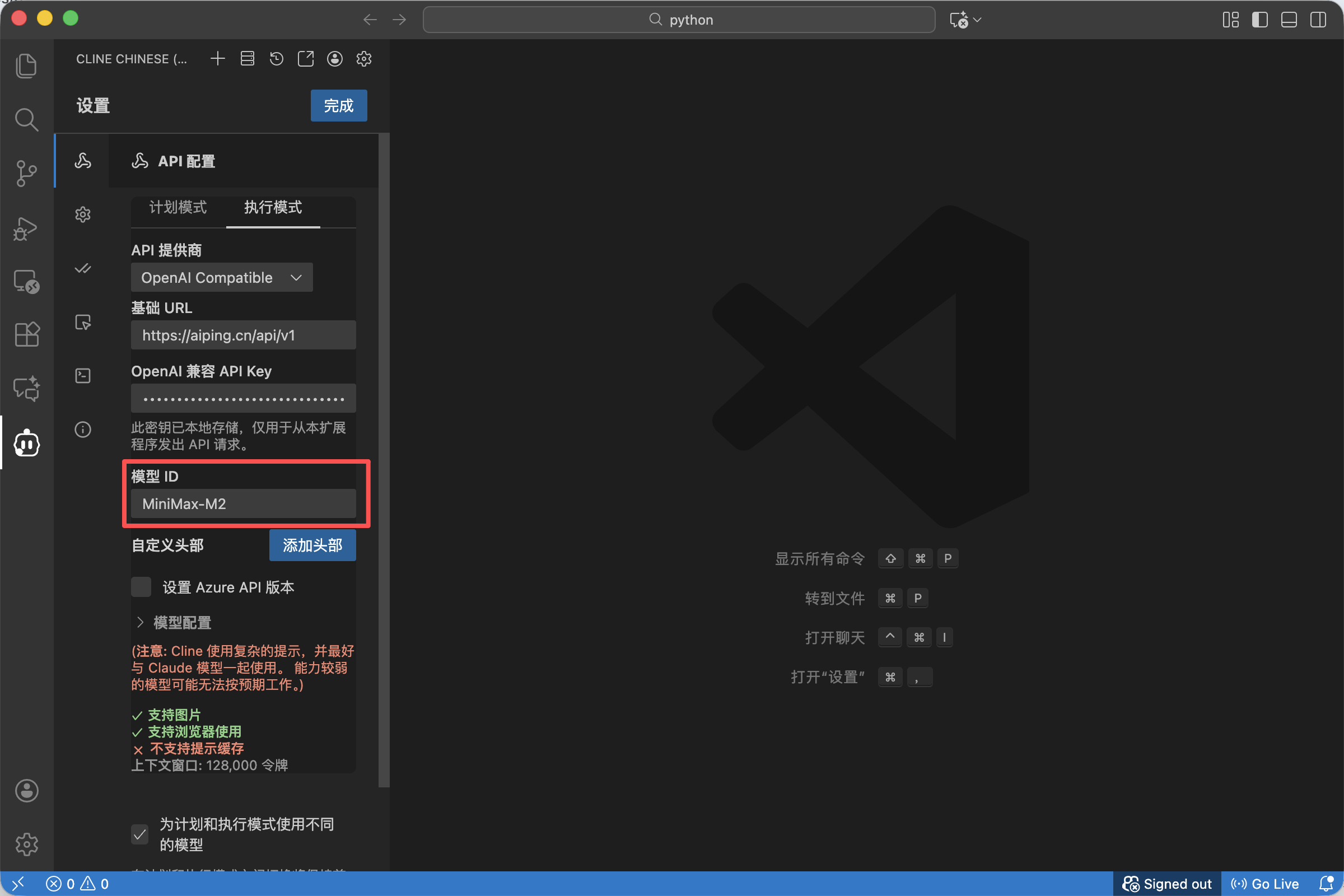
这是最关键的一步,决定了你调用的是哪种算力。
在 Model ID 栏中,手动输入目前开放权益的模型代码。
- 如果你需要极致的语感和代码生成,输入:
MiniMax-M2 - 如果你需要深度推理和逻辑分析,输入:
Kimi-K2-Thinking
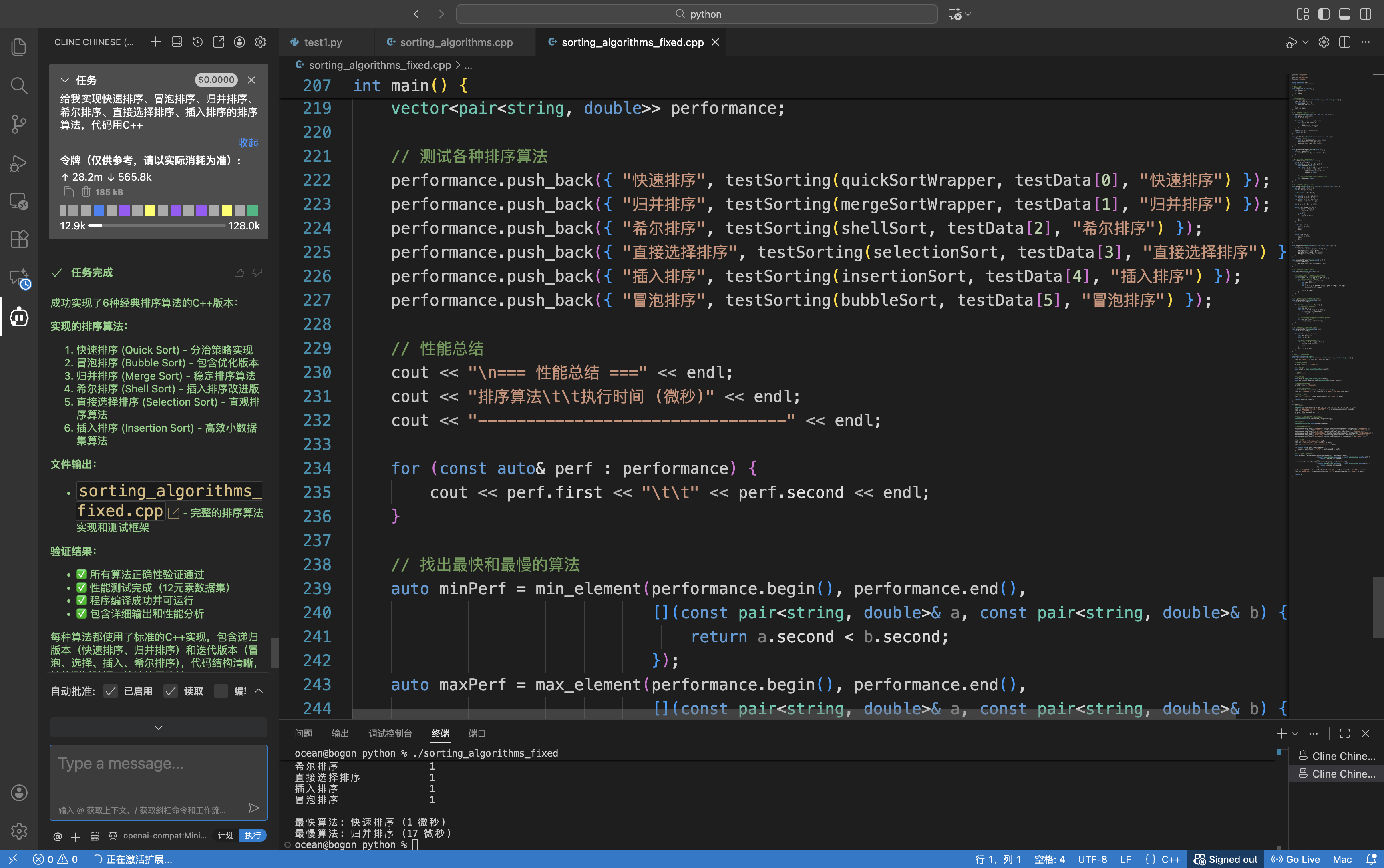
配置完成,我们要验证一下这条"绿色通道"的质量。
我尝试让 AI 进行一段复杂的代码重构任务,并要求它开启深度思考模式(MiniMax-M2)。在 AI Ping 的智能路由加持下,系统自动为我选择了当前网络状况最优的节点。
体验极其丝滑:没有由于并发限制导致的排队,也没有常见的卡顿。这种**"随叫随到"**的响应速度,才是 Vibe Coding 该有的样子。
- prompt: 给我实现快速排序、冒泡排序、归并排序、希尔排序、直接选择排序、插入排序的排序算法,代码用C++
第四步:查看海量吞吐数据
最后,我们回到后台看看数据。
在"用量统计"面板,我们可以清晰地看到刚才那波高强度的开发操作,产生了巨大的 Token 吞吐量。
通常情况下,如此高频的调用会触达很多平台的限制红线。但在 AI Ping 的开放权益期间,这些海量的 Token 消耗被完美承载。我们可以尽情地挥霍算力来优化代码,而无需担心"额度不足"或"资源耗尽"。
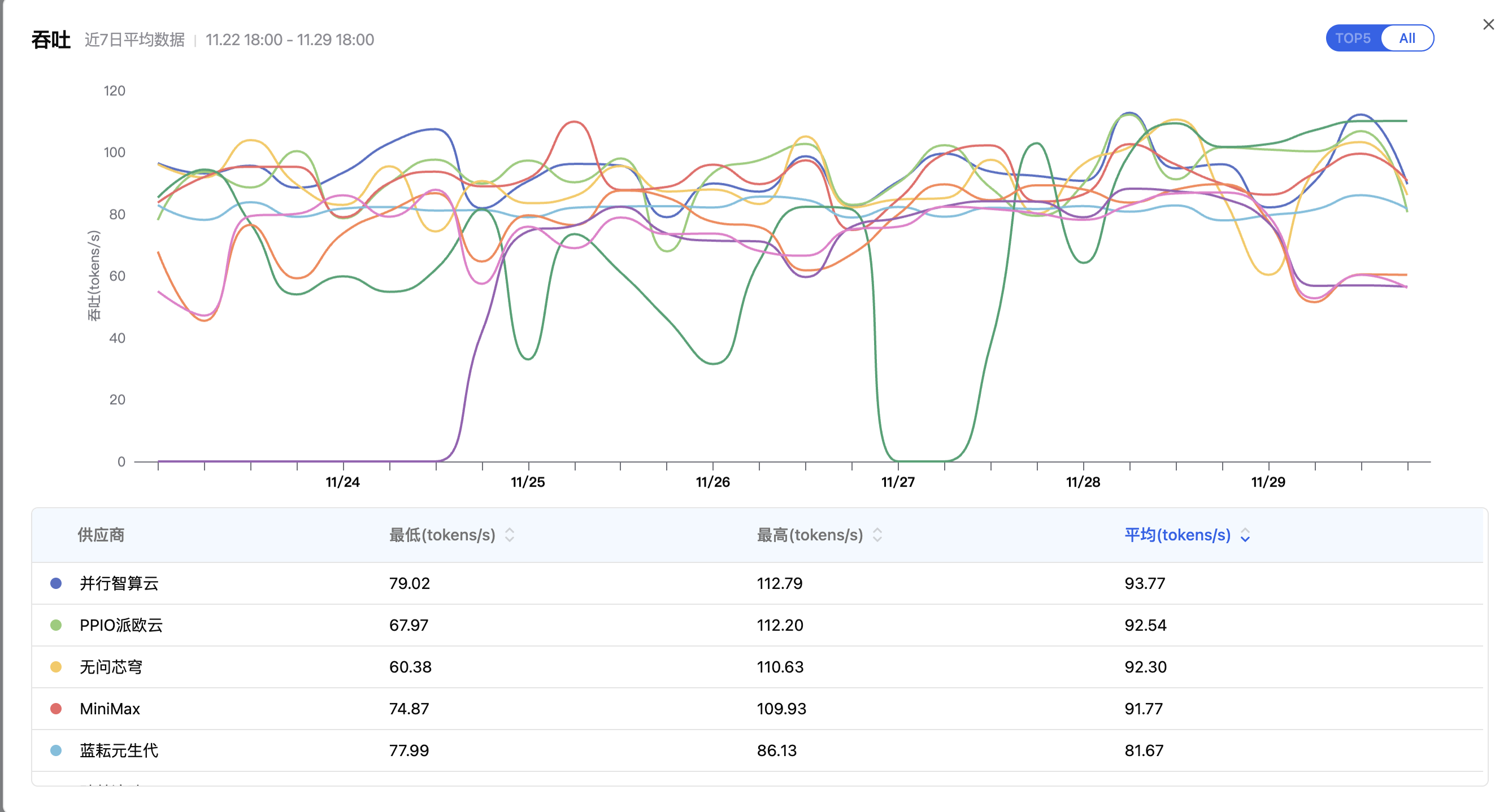
看不见的"算力震荡"
- 供应商的性能是动态的: 请看图中的吞吐曲线,即便是头部大厂,生成速度也在 60~110 tokens/s 之间剧烈波动。
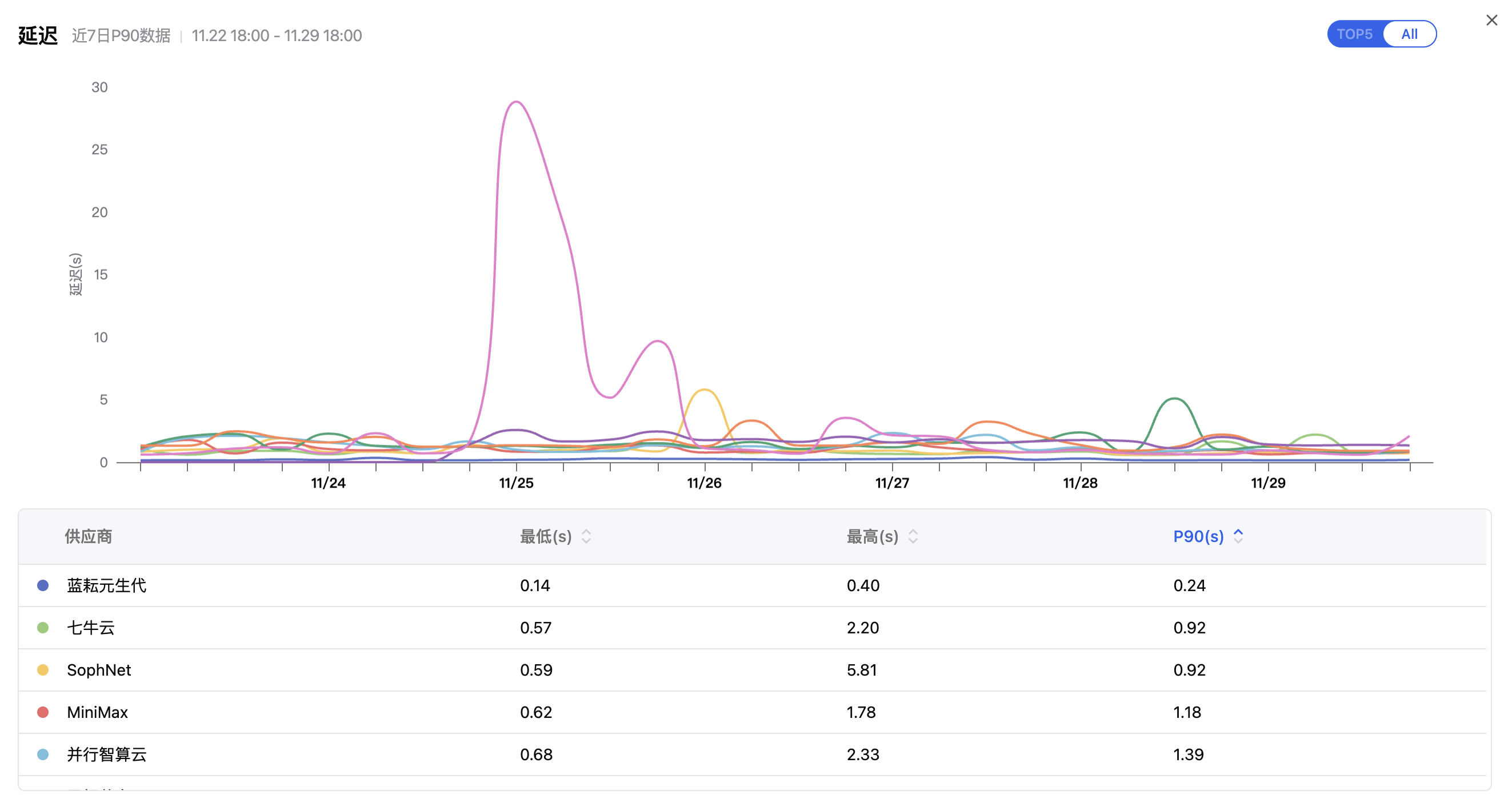
- 单点故障****的风险: 注意延迟图中那个突出的紫色尖峰。11月25日,某家供应商的延迟瞬间升高至 25秒+。
- 如果你直连这家供应商: 在此期间,你的服务稳定性会受到影响,用户可能会频繁遇到请求超时。
- 如果你使用 AI Ping**:** 智能路由算法能迅速感知到延迟异常,并自动将请求切换到表现更稳定的"蓝耘"或"七牛云"节点。
- 这,就是我们需要"大模型路由"的根本原因。**
总结
AI Ping 给我的感觉,就像是为开发者提供了一个**"算力自助餐"**。
通过智能路由和聚合接口,它帮我们打破了不同模型厂商之间的壁垒。特别是利用当下的开放权益期,我们可以毫无顾虑地在项目中引入 MiniMax、GLM 等顶级模型,极大地扩展了开发的边界。
如果你也想体验这种不受束缚、资源拉满的开发快感,建议赶紧去配置一下。