1、Prefill的概念
(1)定义
prefill定义:它是LLM推理的第一阶段,将用户输入的完整prompt(比如"你好,今天天气怎么样?")一次性通过整个模型前向传播,计算出所有token的隐藏状态(hidden states)和注意力所需的KV缓存(Key-Value Cache),为后续逐个生成新token做准备。
prompt是用户输入的内容,模型需要先"理解"这段输入,才能开始生成第一个词。这个"理解输入"的过程,就是prefill。
(2)Prefill vs Decode
|--------|------------------------------------|-----------------|
| 特性 | Prefill阶段 | Decode阶段 |
| 输入 | 完整prompt(N个token) | 每次1个新token |
| 输出 | 所有N个token的hidden states + KV Cache | 下一个token的logits |
| 并行性 | 完全并行(一次前向传播处理所有token) | 串行(每步依赖上一步) |
| 是否生成新词 | 不生成(或只生成第11个) | 生成新token |
| 主要目的 | 构建上下文表示 + 初始化KV Cache | 基于上下文继续生成 |
简单类比:
-
Prefill:阅读整篇文章并做笔记(KV Cache)
-
Decode:根据笔记,一句一句往下写
(3)Prefill详细计算流程
假设 prompt = "The", "capital", "of", "France", "is"(5 个 token)
1)步骤 1:Tokenization & Embedding
将 token 转为 ID:123, 456, 789, 101, 202
查 embedding 表 → 得到 shape 为 (5, d) 的向量(d=hidden size,如 2048)
2)步骤 2:Positional Encoding(位置编码)
为每个 token 加上位置信息(Llama 用 RoPE 旋转位置编码)
输出仍是 (5, d)
3)步骤 3:逐层 Transformer 前向传播
对每一层(比如 32 层):
- Self-Attention 计算
对 5 个 token 同时计算:
Query (Q) = X · W_Q → (5, d)
Key (K) = X · W_K → (5, d)
Value (V) = X · W_V → (5, d)
计算 attention scores:
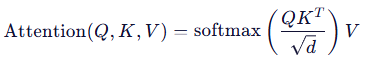
QKᵀ 是 (5, 5) 矩阵 → O(N²) 复杂度
输出加权后的 V → (5, d)
- 保存 KV Cache
把本层的 K 和 V 缓存起来,存入 KV Cache(用于 decode 阶段)
KV Cache 形状:(num_layers, 2, num_heads, seq_len, head_dim)
- MLP(前馈网络)
对每个 token 独立做非线性变换(可并行)
整个过程对 5 个 token 是并行的!GPU 一次性处理所有位置。
4)步骤 4:输出 logits
最后一层输出 (5, d) → 投影到 vocab size → (5, vocab_size)
通常我们只关心最后一个 token 的 logits(用于生成下一个词)
所以 prefill 阶段一般只采样最后一个 token 的输出作为第 1 个生成词
(4)KV Cache的作用
在 decode 阶段,当生成第 6 个 token("Paris")时,模型需要计算:当前 token 对 前 5 个 token 的 attention。
如果没有 prefill 阶段缓存的 K 和 V,每次 decode 都要:重新把整个 prompt 再过一遍模型 → 重复计算!时间复杂度爆炸(生成 T 个 token 需要 O(T×N²))
而有了 KV Cache:Prefill 阶段已计算好前 5 个 token 的 K、V 并缓存,Decode 阶段只需计算当前 token 的 Q,然后与缓存的 K、V 做 attention,复杂度降为 O(T×N)。
(5)核心要点
-
Prefill是LLM推理的第一步,用于处理用户输入的完整prompt
-
它是完全并行的,一次性处理所有的prompt token
-
主要产出是KV Cache,供decode阶段复用,避免重复计算
-
虽然并行,但因 O(N²) attention和显存瓶颈,依然很耗时
-
没有prefill,decode无法高效进行,它是自回归生成的基石
2、分离式Prefill概念
(1)核心思想
将计算密集型的Prefill阶段和内存密集型的Decode阶段拆分到不同的硬件资源上执行,以提升整体系统吞吐、资源利用率和成本效率。
(2)为什么要分离
1)prefill和decode资源需求对比
|---------|----------|--------------|-----------------|---------|
| 阶段 | 计算强度 | 显存带宽 | 显存容量 | 并行性 |
| prefill | 高Flops | 大量权重加载 | 中等(只需存KV Cache) | 完全并行 |
| decode | 低Flops | 频繁读写KV Cache | 需缓存所有请求的KV | 串行生成 |
Prefill吃算例,decode吃显存和内存带宽。用同一类GPU跑两者,资源无法最优利用。
2)实际负载不均衡
用户请求的prompt长度差异大,有的100 token,有的32k token。
如果prefill和decode绑定在同一GPU上:
-
长prompt占用GPU时间久:长prompt的prefill花费时间久
-
decode阶段却让GPU大部分时间空闲
(3)分离式Prefill方法
1)物理或逻辑上分离2个阶段
- prefill节点(Producer):
通常部署在高算力GPU(如A100/H100)上,只负责处理prompt,生成KV Cache
- Decode节点(Consumer):
可部署在高显存GPU或廉价GPU上,只负责基于KV Cache生成后续token
2)高效传输KV Cache
必须快速、低开销地从Prefill节点传给Decode节点。
常见传输方式:
|-------------------------|------------|------------|
| 方式 | 说明 | 适用场景 |
| P2P NCCL/RDMA | GPU-to-GPU | 多机多卡、低延迟 |
| 共享存储(如ExampleConnector) | 写磁盘/共享文件系统 | 单机测试、开发 |
| gRPC/TCP流 | 通用网络传输 | 跨数据中心(有延迟) |
ExampleConnector为示例的connector方式,用于测试使用,并没有出现在vllm的kv_transfer官方的方法中。
3)Request ID必须携带路由信息
在分布式环境下,Prefill节点必须知道把KV Cache发给哪个Decode节点。
因此,request_id不再是简单数字,而是包含目标地址的字符串,比如:
request_id = "192.168.1.10:14579:req_abc123"req_abc123:唯一请求标识
3、实践
单机测试,共享存储的方式。
(1)准备工作
因为ExampleConnector类不是官网的对外的类,所以vllm无法识别到该方法。我们需要手动下载类文件到指定目录下。
执行如下命令:
python -c "import vllm; print(vllm.__path__[0])"找到vllm的安装目录,然后在/vllm/distributed/kv_transfer/kv_connector/v1下放该文件。
验证ExampleConnector是否能使用:
python -c "from vllm.distributed.kv_transfer.kv_connector.v1.example_connector import ExampleConnector; print('Import OK')"(2)编写prefill_example.py
输入长提示(prompt),模型只做一次预填充,生成第一个token。
把中间结果(主要是KV Cache)保存到磁盘
同时把原始prompt+第一个token写入output.txt
代码逻辑:
python
from vllm import LLM, SamplingParams
from vllm.config import KVTransferConfig
def read_prompts():
context = "Hi " * 1000
context2 = "Hey " * 500
return [
context + "Hello, my name is",
context + "The capital of France is",
context2 + "Your name is",
context2 + "The capital of China is",
]
def main():
prompts = read_prompts()
sampling_params = SamplingParams(temperature=0, top_p=0.95, max_tokens=1)
llm = LLM(
model="/data/xiehao/workspace/models/Qwen/Qwen2.5-1.5B-Instruct",
enforce_eager=True,
gpu_memory_utilization=0.8,
kv_transfer_config=KVTransferConfig(
kv_connector="ExampleConnector",
kv_role="kv_both",
kv_connector_extra_config={"shared_storage_path": "local_storage"},
kv_connector_module_path="vllm.distributed.kv_transfer.kv_connector.v1.example_connector"
)
)
outputs = llm.generate(prompts, sampling_params)
new_prompts = []
print("-" * 30)
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
new_prompts.append(prompt + generated_text)
print(f"Prompt: {prompt!r}\nGenerated text: {generated_text!r}")
print("-" * 30)
with open("output.txt", "w") as f:
for prompt in new_prompts:
f.write(prompt + "\n")
print(f"Saved {len(new_prompts)} prompts to output.txt")
if __name__ == "__main__":
main()KVTransferConfig:配置如何传输或存储 KV Cache。
内部的参数:
-
enforce_eager=True:禁用CUDA图优化,调试使用
-
gpu_memory_utilization=0.8:最多使用80%显存
执行命令:VLLM_ENABLE_V1_MULTIPROCESSING=0 CUDA_VISIBLE_DEVICES=0 python prefill_example.py
执行日志:
python
(vllm_python312) [work@iZuf6hp1dkg31metmko4pbZ prefill]$ VLLM_ENABLE_V1_MULTIPROCESSING=0 CUDA_VISIBLE_DEVICES=0 python prefill_example.py
INFO 12-11 16:27:47 [utils.py:253] non-default args: {'seed': None, 'gpu_memory_utilization': 0.8, 'disable_log_stats': True, 'enforce_eager': True, 'kv_transfer_config': KVTransferConfig(kv_connector='ExampleConnector', engine_id='ff1731b4-67c5-4bc5-aba5-d65d958d22b6', kv_buffer_device='cuda', kv_buffer_size=1000000000.0, kv_role='kv_both', kv_rank=None, kv_parallel_size=1, kv_ip='127.0.0.1', kv_port=14579, kv_connector_extra_config={'shared_storage_path': 'local_storage'}, kv_connector_module_path='vllm.distributed.kv_transfer.kv_connector.v1.example_connector', enable_permute_local_kv=False), 'model': '/data/xiehao/workspace/models/Qwen/Qwen2.5-1.5B-Instruct'}
WARNING 12-11 16:27:47 [arg_utils.py:1175] `seed=None` is equivalent to `seed=0` in V1 Engine. You will no longer be allowed to pass `None` in v0.13.
WARNING 12-11 16:27:47 [arg_utils.py:1183] The global random seed is set to 0. Since VLLM_ENABLE_V1_MULTIPROCESSING is set to False, this may affect the random state of the Python process that launched vLLM.
INFO 12-11 16:27:48 [model.py:637] Resolved architecture: Qwen2ForCausalLM
INFO 12-11 16:27:48 [model.py:1750] Using max model len 32768
INFO 12-11 16:27:48 [scheduler.py:228] Chunked prefill is enabled with max_num_batched_tokens=8192.
WARNING 12-11 16:27:48 [vllm.py:601] Enforce eager set, overriding optimization level to -O0
INFO 12-11 16:27:48 [vllm.py:707] Cudagraph is disabled under eager mode
WARNING 12-11 16:27:48 [vllm.py:896] Turning off hybrid kv cache manager because `--kv-transfer-config` is set. This will reduce the performance of vLLM on LLMs with sliding window attention or Mamba attention. If you are a developer of kv connector, please consider supporting hybrid kv cache manager for your connector by making sure your connector is a subclass of `SupportsHMA` defined in kv_connector/v1/base.py.
INFO 12-11 16:27:48 [core.py:93] Initializing a V1 LLM engine (v0.12.0) with config: model='/data/xiehao/workspace/models/Qwen/Qwen2.5-1.5B-Instruct', speculative_config=None, tokenizer='/data/xiehao/workspace/models/Qwen/Qwen2.5-1.5B-Instruct', skip_tokenizer_init=False, tokenizer_mode=auto, revision=None, tokenizer_revision=None, trust_remote_code=False, dtype=torch.bfloat16, max_seq_len=32768, download_dir=None, load_format=auto, tensor_parallel_size=1, pipeline_parallel_size=1, data_parallel_size=1, disable_custom_all_reduce=False, quantization=None, enforce_eager=True, kv_cache_dtype=auto, device_config=cuda, structured_outputs_config=StructuredOutputsConfig(backend='auto', disable_fallback=False, disable_any_whitespace=False, disable_additional_properties=False, reasoning_parser='', reasoning_parser_plugin='', enable_in_reasoning=False), observability_config=ObservabilityConfig(show_hidden_metrics_for_version=None, otlp_traces_endpoint=None, collect_detailed_traces=None, kv_cache_metrics=False, kv_cache_metrics_sample=0.01), seed=0, served_model_name=/data/xiehao/workspace/models/Qwen/Qwen2.5-1.5B-Instruct, enable_prefix_caching=True, enable_chunked_prefill=True, pooler_config=None, compilation_config={'level': None, 'mode': <CompilationMode.NONE: 0>, 'debug_dump_path': None, 'cache_dir': '', 'compile_cache_save_format': 'binary', 'backend': 'inductor', 'custom_ops': ['all'], 'splitting_ops': [], 'compile_mm_encoder': False, 'compile_sizes': [], 'inductor_compile_config': {'enable_auto_functionalized_v2': False, 'combo_kernels': True, 'benchmark_combo_kernel': True}, 'inductor_passes': {}, 'cudagraph_mode': <CUDAGraphMode.NONE: 0>, 'cudagraph_num_of_warmups': 0, 'cudagraph_capture_sizes': [], 'cudagraph_copy_inputs': False, 'cudagraph_specialize_lora': True, 'use_inductor_graph_partition': False, 'pass_config': {'fuse_norm_quant': False, 'fuse_act_quant': False, 'fuse_attn_quant': False, 'eliminate_noops': False, 'enable_sp': False, 'fuse_gemm_comms': False, 'fuse_allreduce_rms': False}, 'max_cudagraph_capture_size': 0, 'dynamic_shapes_config': {'type': <DynamicShapesType.BACKED: 'backed'>}, 'local_cache_dir': None}
INFO 12-11 16:27:48 [parallel_state.py:1200] world_size=1 rank=0 local_rank=0 distributed_init_method=tcp://10.53.5.196:38491 backend=nccl
INFO 12-11 16:27:48 [parallel_state.py:1408] rank 0 in world size 1 is assigned as DP rank 0, PP rank 0, PCP rank 0, TP rank 0, EP rank 0
INFO 12-11 16:27:49 [gpu_model_runner.py:3467] Starting to load model /data/xiehao/workspace/models/Qwen/Qwen2.5-1.5B-Instruct...
INFO 12-11 16:27:49 [cuda.py:411] Using FLASH_ATTN attention backend out of potential backends: ['FLASH_ATTN', 'FLASHINFER', 'TRITON_ATTN', 'FLEX_ATTENTION']
Loading safetensors checkpoint shards: 0% Completed | 0/1 [00:00<?, ?it/s]
Loading safetensors checkpoint shards: 100% Completed | 1/1 [00:00<00:00, 2.70it/s]
Loading safetensors checkpoint shards: 100% Completed | 1/1 [00:00<00:00, 2.70it/s]
INFO 12-11 16:27:49 [default_loader.py:308] Loading weights took 0.43 seconds
INFO 12-11 16:27:50 [gpu_model_runner.py:3549] Model loading took 2.8876 GiB memory and 0.596305 seconds
INFO 12-11 16:27:51 [gpu_worker.py:359] Available KV cache memory: 33.67 GiB
INFO 12-11 16:27:51 [kv_cache_utils.py:1286] GPU KV cache size: 1,260,832 tokens
INFO 12-11 16:27:51 [kv_cache_utils.py:1291] Maximum concurrency for 32,768 tokens per request: 38.48x
INFO 12-11 16:27:51 [factory.py:64] Creating v1 connector with name: ExampleConnector and engine_id: ff1731b4-67c5-4bc5-aba5-d65d958d22b6
WARNING 12-11 16:27:51 [base.py:163] Initializing KVConnectorBase_V1. This API is experimental and subject to change in the future as we iterate the design.
INFO 12-11 16:27:51 [example_connector.py:106] KVTransferConfig(kv_connector='ExampleConnector', engine_id='ff1731b4-67c5-4bc5-aba5-d65d958d22b6', kv_buffer_device='cuda', kv_buffer_size=1000000000.0, kv_role='kv_both', kv_rank=None, kv_parallel_size=1, kv_ip='127.0.0.1', kv_port=14579, kv_connector_extra_config={'shared_storage_path': 'local_storage'}, kv_connector_module_path='vllm.distributed.kv_transfer.kv_connector.v1.example_connector', enable_permute_local_kv=False)
INFO 12-11 16:27:51 [example_connector.py:107] Shared storage path is local_storage
INFO 12-11 16:27:51 [utils.py:117] Connectors do not specify a kv cache layout, defaulting to NHD.
INFO 12-11 16:27:51 [core.py:254] init engine (profile, create kv cache, warmup model) took 1.08 seconds
INFO 12-11 16:27:51 [factory.py:64] Creating v1 connector with name: ExampleConnector and engine_id: ff1731b4-67c5-4bc5-aba5-d65d958d22b6
WARNING 12-11 16:27:51 [base.py:163] Initializing KVConnectorBase_V1. This API is experimental and subject to change in the future as we iterate the design.
INFO 12-11 16:27:51 [example_connector.py:106] KVTransferConfig(kv_connector='ExampleConnector', engine_id='ff1731b4-67c5-4bc5-aba5-d65d958d22b6', kv_buffer_device='cuda', kv_buffer_size=1000000000.0, kv_role='kv_both', kv_rank=None, kv_parallel_size=1, kv_ip='127.0.0.1', kv_port=14579, kv_connector_extra_config={'shared_storage_path': 'local_storage'}, kv_connector_module_path='vllm.distributed.kv_transfer.kv_connector.v1.example_connector', enable_permute_local_kv=False)
INFO 12-11 16:27:51 [example_connector.py:107] Shared storage path is local_storage
INFO 12-11 16:27:51 [llm.py:343] Supported tasks: ('generate',)
Adding requests: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 4/4 [00:00<00:00, 535.24it/s]
Processed prompts: 100%|██████████████████████████████████████████████████████████████████| 4/4 [00:00<00:00, 28.16it/s, est. speed input: 21259.13 toks/s, output: 28.18 toks/s]
------------------------------
Prompt: 'Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hello, my name is'
Generated text: ' the'
------------------------------
Prompt: 'Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi The capital of France is'
Generated text: ' the'
------------------------------
Prompt: 'Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Your name is'
Generated text: ' the'
------------------------------
Prompt: 'Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey The capital of China is'
Generated text: ' '
------------------------------
Saved 4 prompts to output.txt(3)编写decode_example.py
从磁盘读取之前保存的KV Cache。
从output.txt读取prompt+第一个token
模型跳过prefill阶段,直接从已有KV Cache开始,继续生成接下来的token,完成句子。
代码逻辑:
python
from vllm import LLM, SamplingParams
from vllm.config import KVTransferConfig
def read_prompts():
prompts = []
try:
with open("output.txt") as f:
for line in f:
prompts.append(line.strip())
print(f"Loaded {len(prompts)} prompts from output.txt")
return prompts
except FileNotFoundError:
print("Error: output.txt file not found")
exit(-1)
def main():
prompts = read_prompts()
sampling_params = SamplingParams(temperature=0, top_p=0.95, max_tokens=100)
llm = LLM(
model="/data/xiehao/workspace/models/Qwen/Qwen2.5-1.5B-Instruct",
enforce_eager=True,
gpu_memory_utilization=0.8,
max_num_batched_tokens=64,
max_num_seqs=16,
kv_transfer_config=KVTransferConfig(
kv_connector="ExampleConnector",
kv_role="kv_both",
kv_connector_extra_config={"shared_storage_path": "local_storage"},
kv_connector_module_path="vllm.distributed.kv_transfer.kv_connector.v1.example_connector"
)
)
outputs = llm.generate(prompts, sampling_params)
print("-" * 30)
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}\nGenerated text: {generated_text!r}")
print("-" * 30)
if __name__ == "__main__":
main()执行命令:VLLM_ENABLE_V1_MULTIPROCESSING=0 CUDA_VISIBLE_DEVICES=0 python decode_example.py
执行日志:
python
vllm_python312) [work@iZuf6hp1dkg31metmko4pbZ prefill]$ VLLM_ENABLE_V1_MULTIPROCESSING=0 CUDA_VISIBLE_DEVICES=0 python decode_example.py
Loaded 4 prompts from output.txt
INFO 12-11 19:01:42 [utils.py:253] non-default args: {'seed': None, 'gpu_memory_utilization': 0.8, 'max_num_batched_tokens': 64, 'max_num_seqs': 16, 'disable_log_stats': True, 'enforce_eager': True, 'kv_transfer_config': KVTransferConfig(kv_connector='ExampleConnector', engine_id='5c561979-0bc5-4465-951a-0bdb13d71d03', kv_buffer_device='cuda', kv_buffer_size=1000000000.0, kv_role='kv_both', kv_rank=None, kv_parallel_size=1, kv_ip='127.0.0.1', kv_port=14579, kv_connector_extra_config={'shared_storage_path': 'local_storage'}, kv_connector_module_path='vllm.distributed.kv_transfer.kv_connector.v1.example_connector', enable_permute_local_kv=False), 'model': '/data/xiehao/workspace/models/Qwen/Qwen2.5-1.5B-Instruct'}
WARNING 12-11 19:01:42 [arg_utils.py:1175] `seed=None` is equivalent to `seed=0` in V1 Engine. You will no longer be allowed to pass `None` in v0.13.
WARNING 12-11 19:01:42 [arg_utils.py:1183] The global random seed is set to 0. Since VLLM_ENABLE_V1_MULTIPROCESSING is set to False, this may affect the random state of the Python process that launched vLLM.
INFO 12-11 19:01:42 [model.py:637] Resolved architecture: Qwen2ForCausalLM
INFO 12-11 19:01:42 [model.py:1750] Using max model len 32768
INFO 12-11 19:01:42 [scheduler.py:228] Chunked prefill is enabled with max_num_batched_tokens=64.
WARNING 12-11 19:01:42 [vllm.py:601] Enforce eager set, overriding optimization level to -O0
INFO 12-11 19:01:42 [vllm.py:707] Cudagraph is disabled under eager mode
WARNING 12-11 19:01:42 [vllm.py:896] Turning off hybrid kv cache manager because `--kv-transfer-config` is set. This will reduce the performance of vLLM on LLMs with sliding window attention or Mamba attention. If you are a developer of kv connector, please consider supporting hybrid kv cache manager for your connector by making sure your connector is a subclass of `SupportsHMA` defined in kv_connector/v1/base.py.
INFO 12-11 19:01:43 [core.py:93] Initializing a V1 LLM engine (v0.12.0) with config: model='/data/xiehao/workspace/models/Qwen/Qwen2.5-1.5B-Instruct', speculative_config=None, tokenizer='/data/xiehao/workspace/models/Qwen/Qwen2.5-1.5B-Instruct', skip_tokenizer_init=False, tokenizer_mode=auto, revision=None, tokenizer_revision=None, trust_remote_code=False, dtype=torch.bfloat16, max_seq_len=32768, download_dir=None, load_format=auto, tensor_parallel_size=1, pipeline_parallel_size=1, data_parallel_size=1, disable_custom_all_reduce=False, quantization=None, enforce_eager=True, kv_cache_dtype=auto, device_config=cuda, structured_outputs_config=StructuredOutputsConfig(backend='auto', disable_fallback=False, disable_any_whitespace=False, disable_additional_properties=False, reasoning_parser='', reasoning_parser_plugin='', enable_in_reasoning=False), observability_config=ObservabilityConfig(show_hidden_metrics_for_version=None, otlp_traces_endpoint=None, collect_detailed_traces=None, kv_cache_metrics=False, kv_cache_metrics_sample=0.01), seed=0, served_model_name=/data/xiehao/workspace/models/Qwen/Qwen2.5-1.5B-Instruct, enable_prefix_caching=True, enable_chunked_prefill=True, pooler_config=None, compilation_config={'level': None, 'mode': <CompilationMode.NONE: 0>, 'debug_dump_path': None, 'cache_dir': '', 'compile_cache_save_format': 'binary', 'backend': 'inductor', 'custom_ops': ['all'], 'splitting_ops': [], 'compile_mm_encoder': False, 'compile_sizes': [], 'inductor_compile_config': {'enable_auto_functionalized_v2': False, 'combo_kernels': True, 'benchmark_combo_kernel': True}, 'inductor_passes': {}, 'cudagraph_mode': <CUDAGraphMode.NONE: 0>, 'cudagraph_num_of_warmups': 0, 'cudagraph_capture_sizes': [], 'cudagraph_copy_inputs': False, 'cudagraph_specialize_lora': True, 'use_inductor_graph_partition': False, 'pass_config': {'fuse_norm_quant': False, 'fuse_act_quant': False, 'fuse_attn_quant': False, 'eliminate_noops': False, 'enable_sp': False, 'fuse_gemm_comms': False, 'fuse_allreduce_rms': False}, 'max_cudagraph_capture_size': 0, 'dynamic_shapes_config': {'type': <DynamicShapesType.BACKED: 'backed'>}, 'local_cache_dir': None}
INFO 12-11 19:01:43 [parallel_state.py:1200] world_size=1 rank=0 local_rank=0 distributed_init_method=tcp://10.53.5.196:40087 backend=nccl
INFO 12-11 19:01:43 [parallel_state.py:1408] rank 0 in world size 1 is assigned as DP rank 0, PP rank 0, PCP rank 0, TP rank 0, EP rank 0
INFO 12-11 19:01:43 [gpu_model_runner.py:3467] Starting to load model /data/xiehao/workspace/models/Qwen/Qwen2.5-1.5B-Instruct...
INFO 12-11 19:01:44 [cuda.py:411] Using FLASH_ATTN attention backend out of potential backends: ['FLASH_ATTN', 'FLASHINFER', 'TRITON_ATTN', 'FLEX_ATTENTION']
Loading safetensors checkpoint shards: 0% Completed | 0/1 [00:00<?, ?it/s]
Loading safetensors checkpoint shards: 100% Completed | 1/1 [00:00<00:00, 2.67it/s]
Loading safetensors checkpoint shards: 100% Completed | 1/1 [00:00<00:00, 2.67it/s]
INFO 12-11 19:01:44 [default_loader.py:308] Loading weights took 0.42 seconds
INFO 12-11 19:01:44 [gpu_model_runner.py:3549] Model loading took 2.8876 GiB memory and 0.595919 seconds
INFO 12-11 19:01:45 [gpu_worker.py:359] Available KV cache memory: 34.96 GiB
INFO 12-11 19:01:45 [kv_cache_utils.py:1286] GPU KV cache size: 1,309,072 tokens
INFO 12-11 19:01:45 [kv_cache_utils.py:1291] Maximum concurrency for 32,768 tokens per request: 39.95x
INFO 12-11 19:01:45 [factory.py:64] Creating v1 connector with name: ExampleConnector and engine_id: 5c561979-0bc5-4465-951a-0bdb13d71d03
WARNING 12-11 19:01:45 [base.py:163] Initializing KVConnectorBase_V1. This API is experimental and subject to change in the future as we iterate the design.
INFO 12-11 19:01:45 [example_connector.py:106] KVTransferConfig(kv_connector='ExampleConnector', engine_id='5c561979-0bc5-4465-951a-0bdb13d71d03', kv_buffer_device='cuda', kv_buffer_size=1000000000.0, kv_role='kv_both', kv_rank=None, kv_parallel_size=1, kv_ip='127.0.0.1', kv_port=14579, kv_connector_extra_config={'shared_storage_path': 'local_storage'}, kv_connector_module_path='vllm.distributed.kv_transfer.kv_connector.v1.example_connector', enable_permute_local_kv=False)
INFO 12-11 19:01:45 [example_connector.py:107] Shared storage path is local_storage
INFO 12-11 19:01:45 [utils.py:117] Connectors do not specify a kv cache layout, defaulting to NHD.
INFO 12-11 19:01:45 [core.py:254] init engine (profile, create kv cache, warmup model) took 0.84 seconds
INFO 12-11 19:01:45 [factory.py:64] Creating v1 connector with name: ExampleConnector and engine_id: 5c561979-0bc5-4465-951a-0bdb13d71d03
WARNING 12-11 19:01:45 [base.py:163] Initializing KVConnectorBase_V1. This API is experimental and subject to change in the future as we iterate the design.
INFO 12-11 19:01:45 [example_connector.py:106] KVTransferConfig(kv_connector='ExampleConnector', engine_id='5c561979-0bc5-4465-951a-0bdb13d71d03', kv_buffer_device='cuda', kv_buffer_size=1000000000.0, kv_role='kv_both', kv_rank=None, kv_parallel_size=1, kv_ip='127.0.0.1', kv_port=14579, kv_connector_extra_config={'shared_storage_path': 'local_storage'}, kv_connector_module_path='vllm.distributed.kv_transfer.kv_connector.v1.example_connector', enable_permute_local_kv=False)
INFO 12-11 19:01:45 [example_connector.py:107] Shared storage path is local_storage
INFO 12-11 19:01:46 [llm.py:343] Supported tasks: ('generate',)
Adding requests: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 4/4 [00:00<00:00, 580.45it/s]
Processed prompts: 0%| | 0/4 [00:00<?, ?it/s, est. speed input: 0.00 toks/s, output: 0.00 toks/s]
INFO 12-11 19:01:46 [example_connector.py:285] External Cache Hit!
INFO 12-11 19:01:46 [example_connector.py:285] External Cache Hit!
INFO 12-11 19:01:46 [example_connector.py:285] External Cache Hit!
INFO 12-11 19:01:46 [example_connector.py:285] External Cache Hit!
INFO 12-11 19:01:46 [example_connector.py:177] Inject KV cache of 992 tokens to the paged memory
INFO 12-11 19:01:46 [example_connector.py:177] Inject KV cache of 496 tokens to the paged memory
Processed prompts: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 4/4 [00:00<00:00, 5.82it/s, est. speed input: 4397.22 toks/s, output: 582.22 toks/s]
------------------------------
Prompt: 'Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hello, my name is the'
Generated text: ' answer: "The answer is: "The answer is: "The answer is:\nThe answer is:\\n\nThe answer is:\\n\nThe answer is:\\n\nThe answer is:\\n\nThe answer is: is\\n\nThe answer is: "The answer is: "The answer is: "The answer is: "The answer is: "The answer is: "The answer is: "The answer is: "The answer is: "The answer is: "The'
------------------------------
Prompt: 'Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi The capital of France is the'
Generated text: ' first step. 1. 2020-2010 2. 3. 3. 3. 1. 2.. 2.. 2.. 2.. 1.. 1.. 1.. 1.. 1.. 2.. 2.. 2.. 2.. 2.. 2.. 2.. 2.. '
------------------------------
Prompt: 'Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Your name is the'
Generated text: ' best way to store a list of integers from 1 to 1000 in Python?\n```1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. 17. 18. 19. 20. 21. 22. '
------------------------------
Prompt: 'Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey Hey The capital of China is'
Generated text: " a great way to stay active and stay connected with your friends and family. So, we're going to have a fun-filled day filled with fun activities that will keep you entertained. So, we're going to have a fun-filled day filled with fun activities that will keep you entertained. So, we're going to have a fun-filled day filled with fun activities that will keep you entertained. So, we're going to have a fun-filled day filled with fun activities that will keep you entertained. So"
------------------------------测试的例子,输出不完美!