文章目录
- [1 视频1](#1 视频1)
- [2 疑问和个人理解](#2 疑问和个人理解)
-
- [2.1 个人理解:什么是MLA](#2.1 个人理解:什么是MLA)
- [2.2 疑问:位置信息是怎么优化的](#2.2 疑问:位置信息是怎么优化的)
- 参考文献
abstract
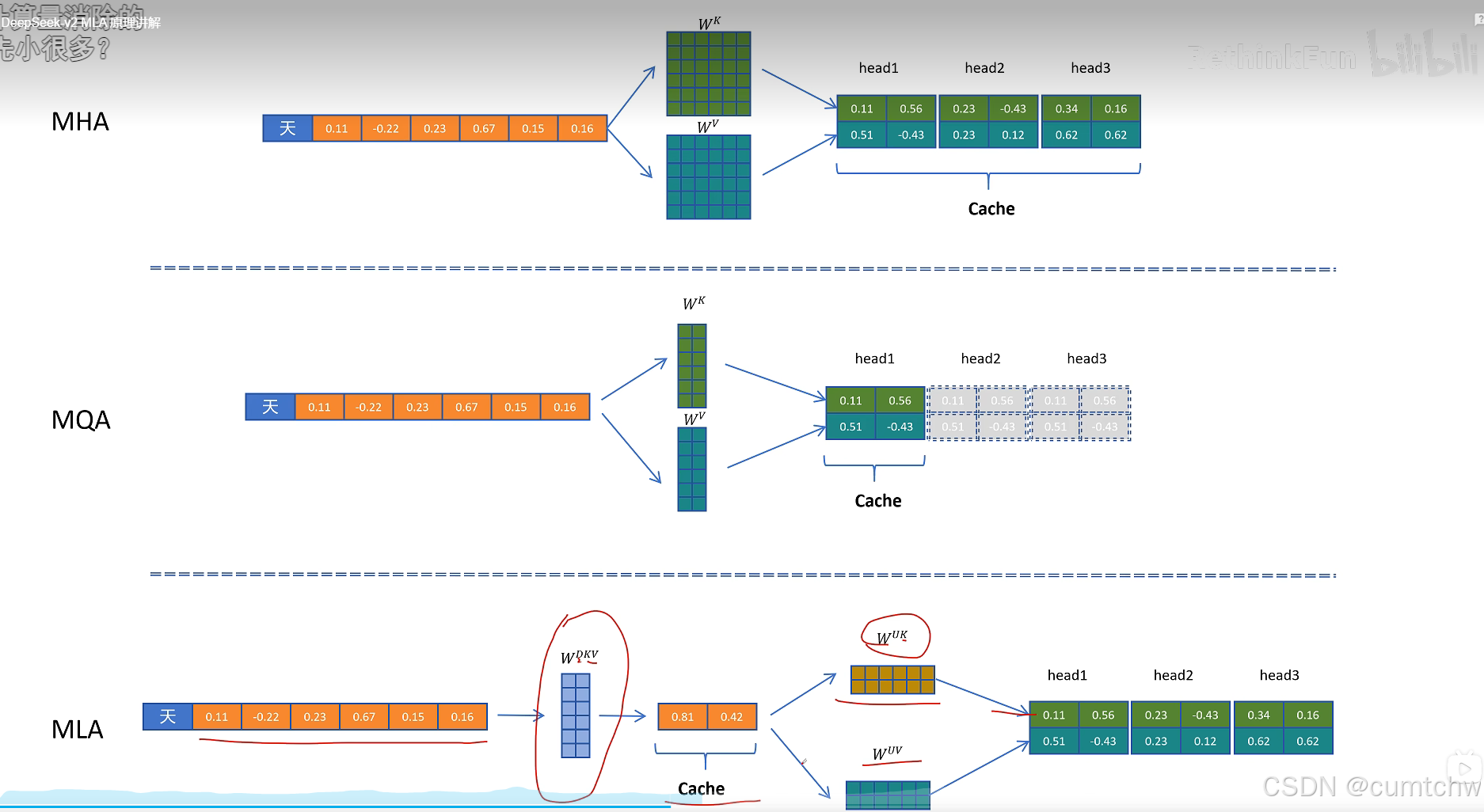
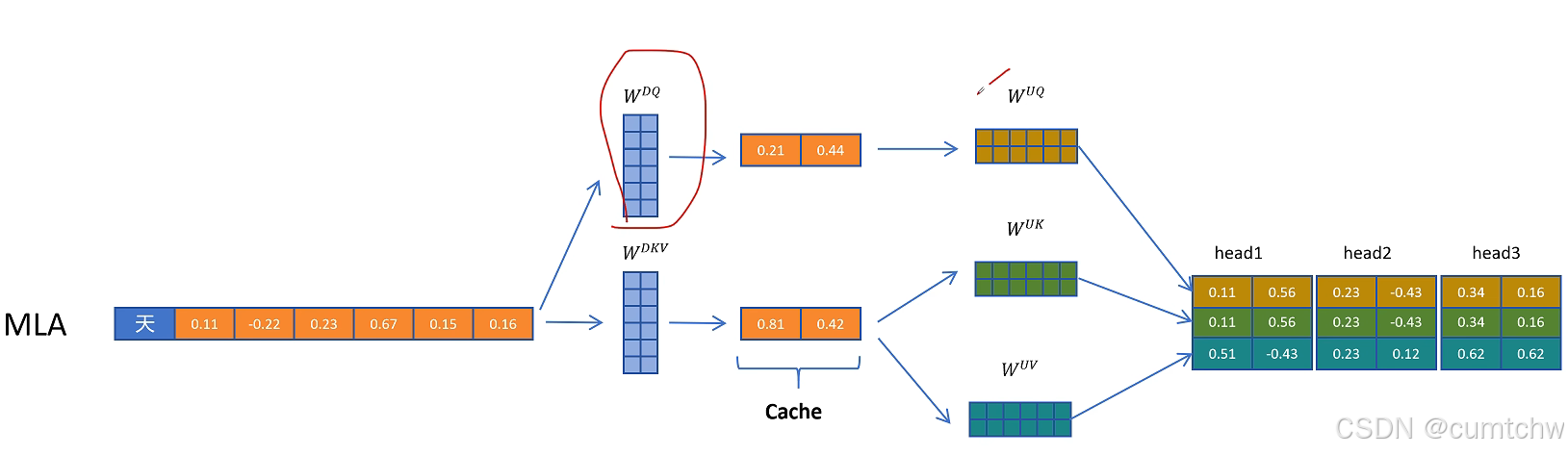
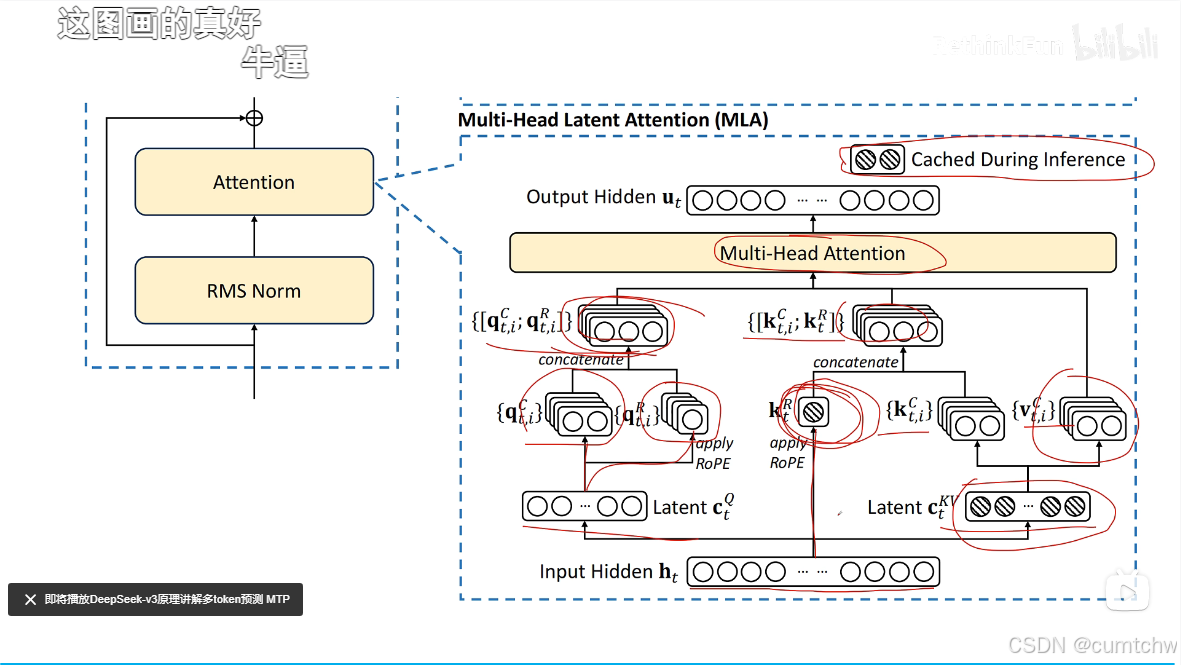
MLA就是压缩KV减少显存占用
增加向量维度表示位置信息,以支持矩阵乘法融合,
1 视频1
视频地址:DeepSeek-v2 MLA 原理讲解
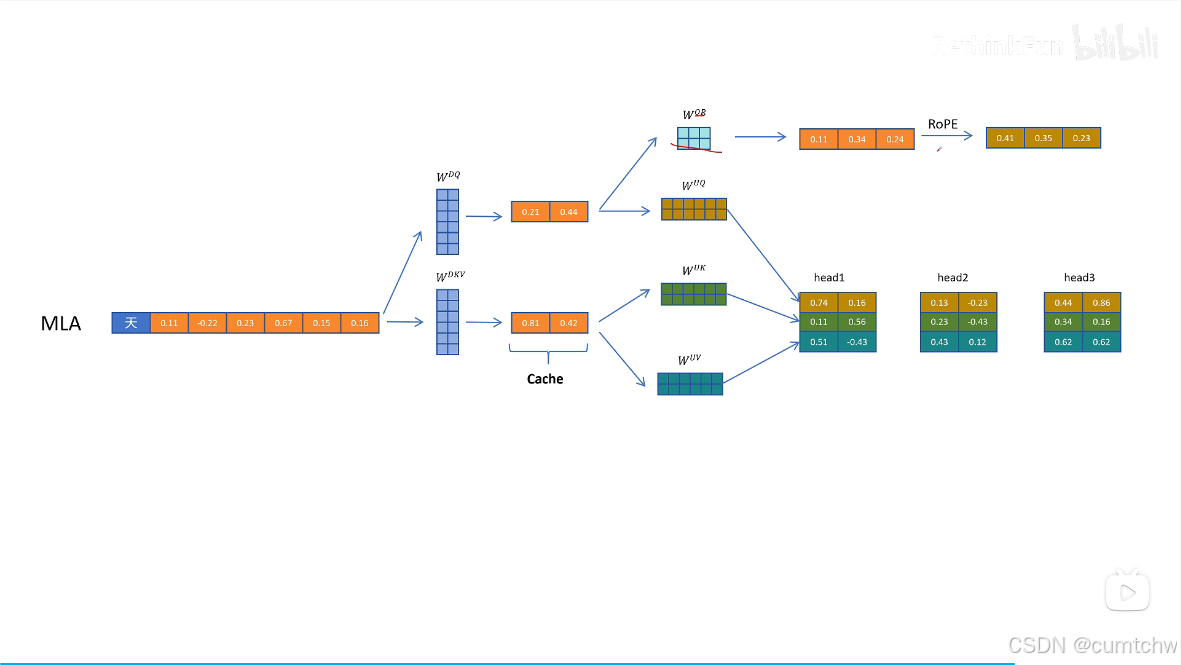
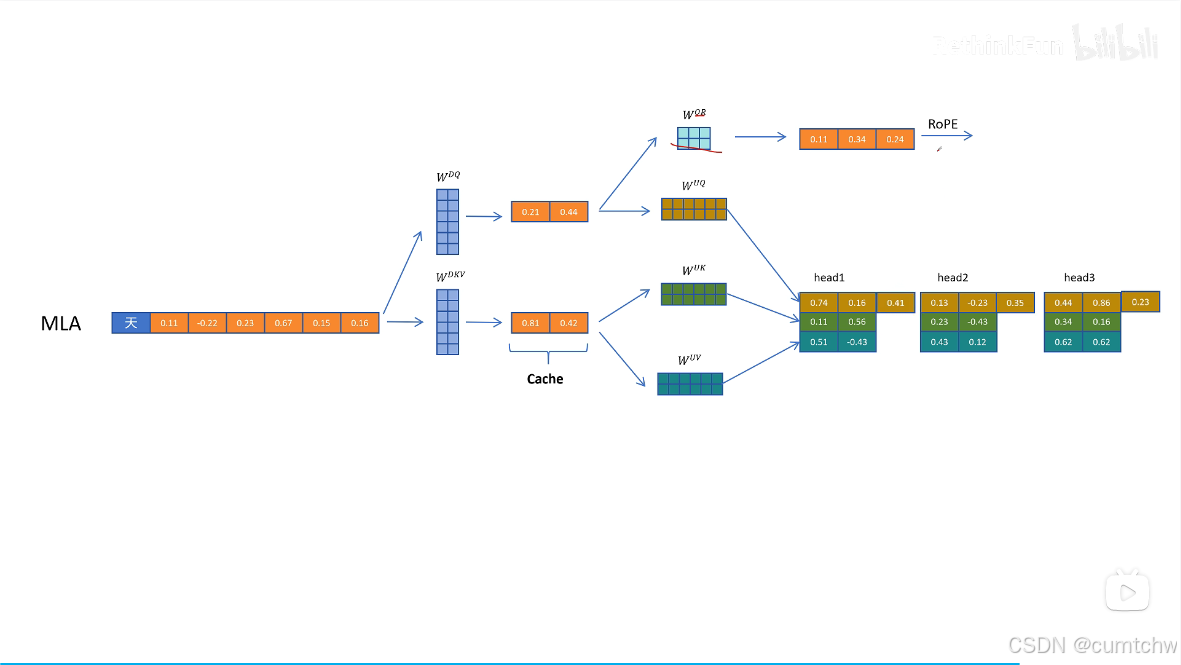
多头潜在注意力怎么解决旋转位置编码的问题

解决方式就是给Q K向量额外增加一些维度来表示位置信息,
2 疑问和个人理解
2.1 个人理解:什么是MLA
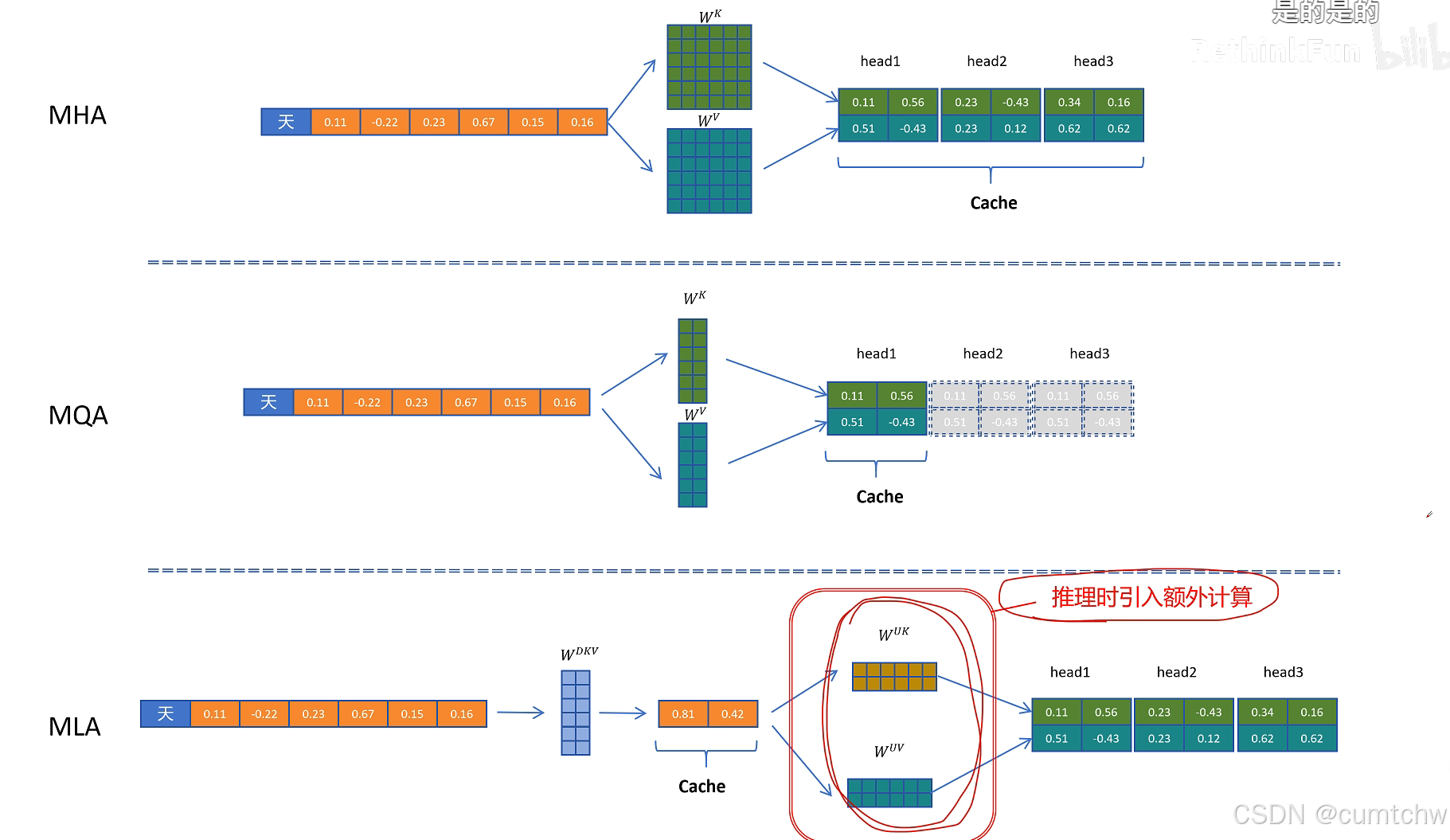
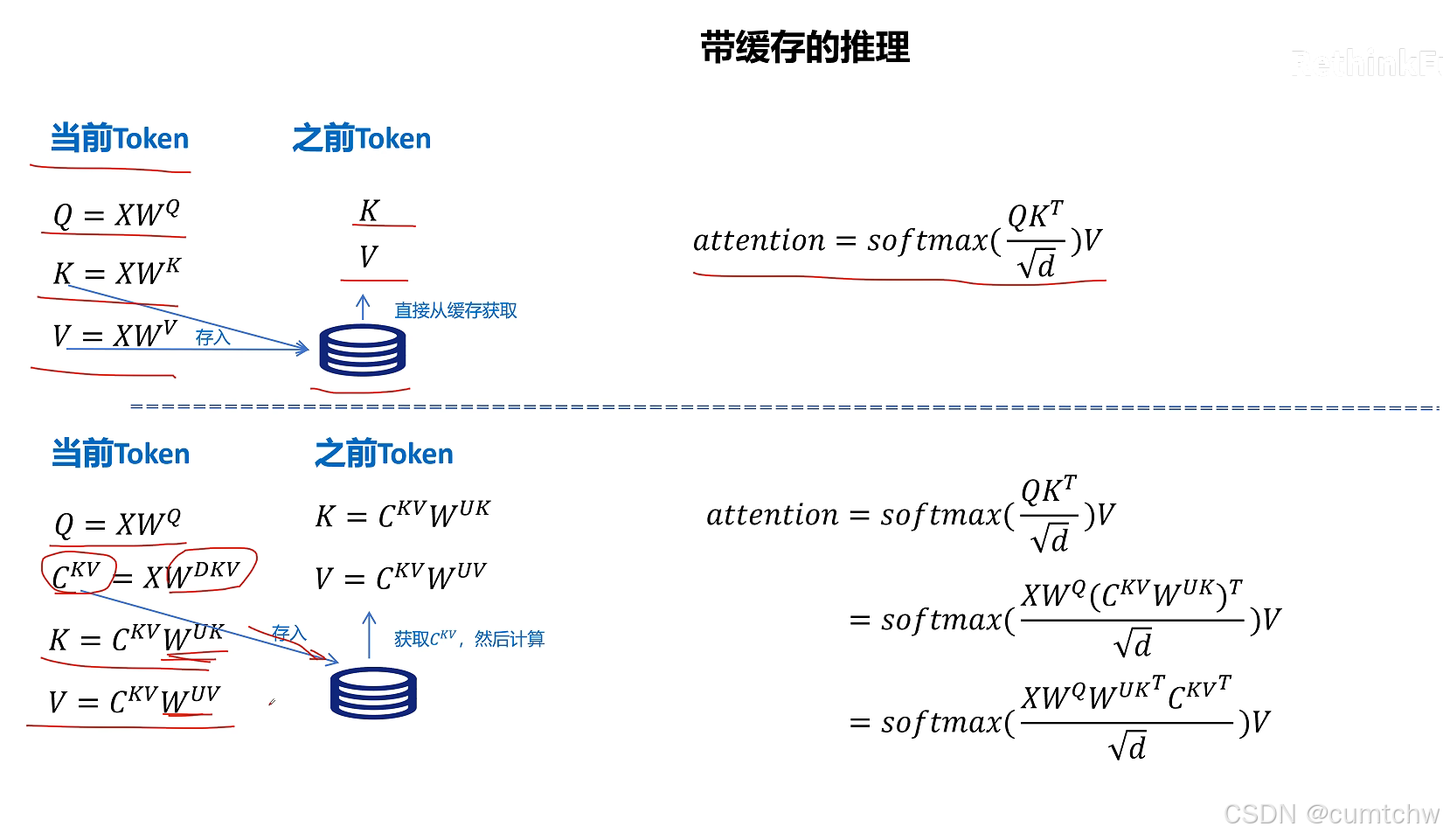
我的理解,什么是MLA,MLA其实就是为了减少KV CACHE的空间占用,用一个矩阵乘以K V然后做了压缩,等后面计算注意力的时候再用一个矩阵乘以压缩后的得到正常的KV,所以所谓的MLA其实一句话总结就是压缩KV节省缓存,其实就跟一个大文件,我压缩包然后放到电脑中,等我真正要看这个文件,我再解压然后去看这个文件,这是一个意思,
2.2 疑问:位置信息是怎么优化的
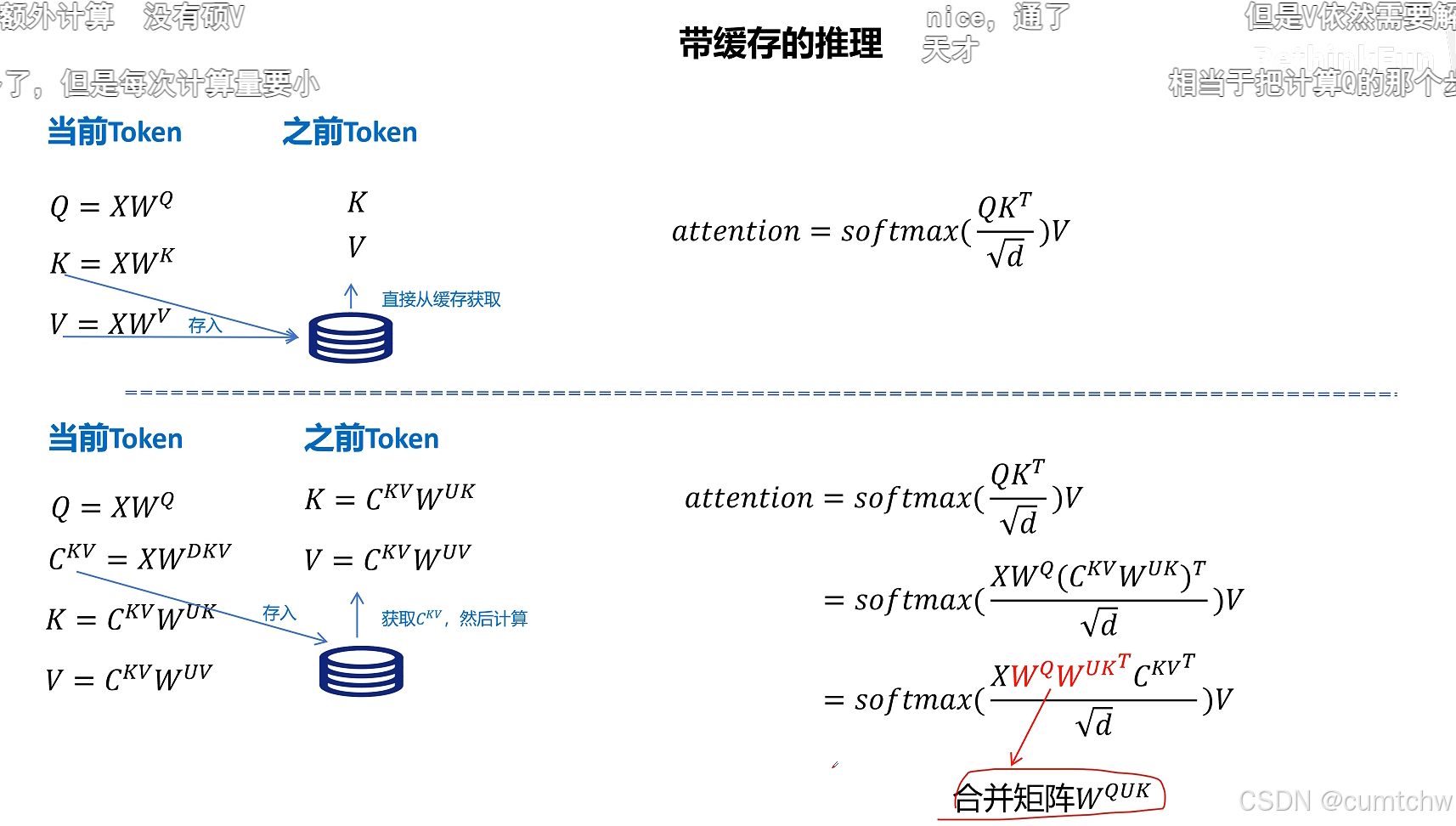
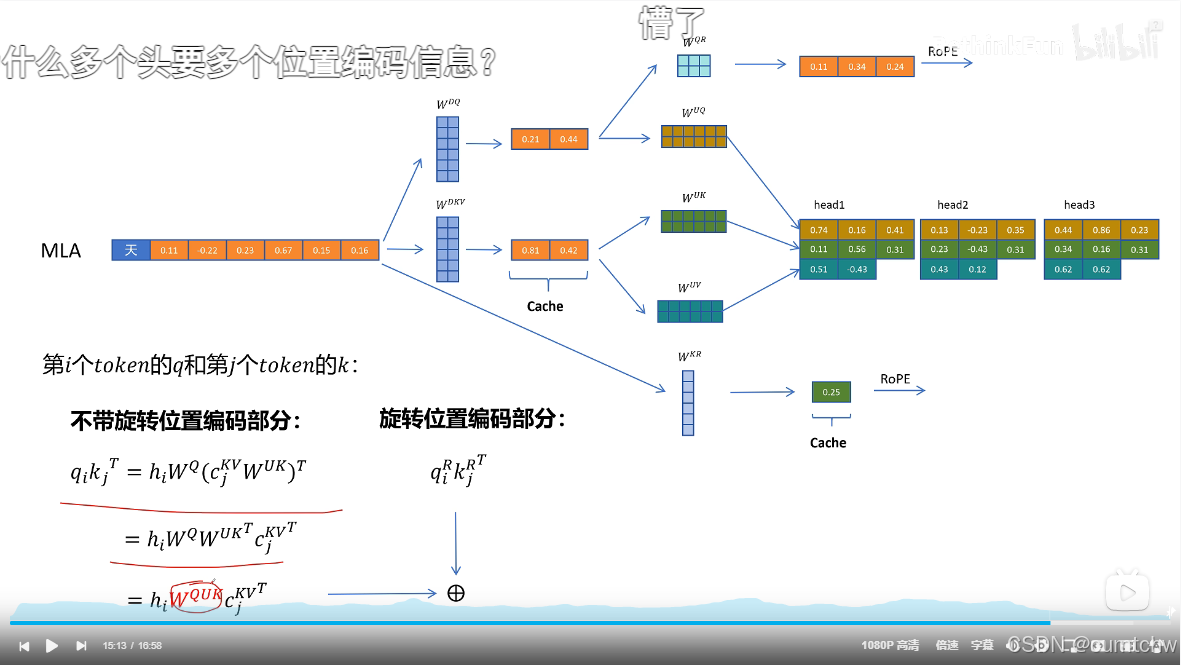
然后他对位置信息还有个优化,就是之前位置信息是通过将Q K乘以一个旋转位置编码矩阵使Q K的向量中包含了位置信息,但是现在如果还是这么做,那么就没法使用矩阵乘法的融合从而减小 运算了,所以DeepSeek采用了另一个方法,就是现在位置信息我不是去乘以Q K 了,而是我通过一个将Q K 乘以一个矩阵然后再用旋转位置编码,然后接着我把得到的这个位置信息加到前面Q K 的维度上,通过增加维度信息来表示位置编码,这样数学推导上就又可以采用矩阵融合的方式了,那么 也就继续可以用矩阵乘法融合从而减小运算律,
其实我觉得他就是位置信息单独计算了,而不是跟之前一样直接乘到Q K上面,