文章目录
- [1 什么是Prefix caching](#1 什么是Prefix caching)
- [2 Eviction](#2 Eviction)
- [3 代码](#3 代码)
-
- [3.1 KC cache的retrieve过程](#3.1 KC cache的retrieve过程)
- [3.2 KV cache store过程](#3.2 KV cache store过程)
- [3.3 eviction代码](#3.3 eviction代码)
- 参考文献
该博客是看学习视频时的简单笔记,感兴趣的可以直接看原视频:EP05 vllm从开源到部署,Prefix Caching和开源答疑
1 什么是Prefix caching
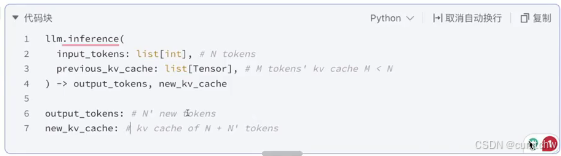
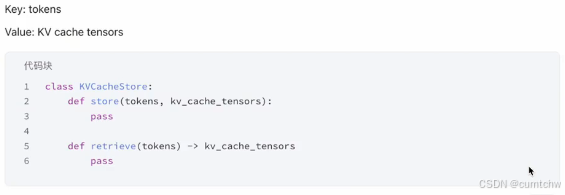
上面其实就是大模型推理的输入和输出是什么,那么接下来抛开vllm框架,如果想完成一个Prefix Caching,那么要是设计一个python的class,需要怎么设计,

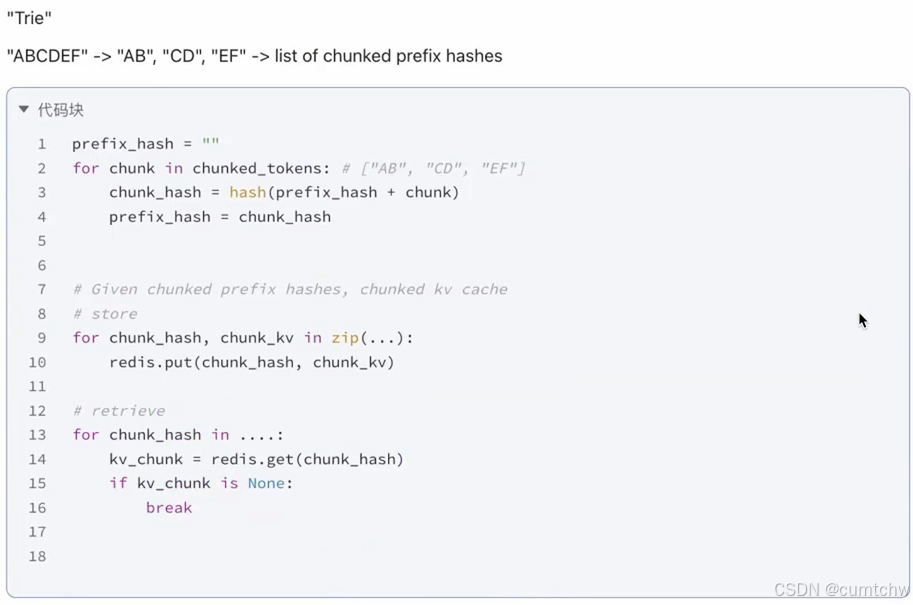
其实就是做最长的前缀匹配。
2 Eviction
由于GPU显存是有限的,不可能一直去保存kv cache,当满了之后就需要将以前的东西丢掉。
3 代码
3.1 KC cache的retrieve过程
vllm/vllm/v1/core/sched/scheduler.py中
python
# Get already-cached tokens.
if request.num_computed_tokens == 0:
# Get locally-cached tokens.
new_computed_blocks, num_new_local_computed_tokens = \
self.kv_cache_manager.get_computed_blocks(
request)vllm/vllm/v1/core/kv_cache_manager.py
python
def get_computed_blocks(self,
request: Request) -> tuple[KVCacheBlocks, int]:
"""Get the computed (cached) blocks for the request.
Note that the computed blocks must be full.
Args:
request: The request to get the computed blocks.
Returns:
A tuple containing:
- A list of blocks that are computed for the request.
- The number of computed tokens.
"""
# Prefix caching is disabled or
# When the request requires prompt logprobs, we skip prefix caching.
if (not self.enable_caching
or (request.sampling_params is not None
and request.sampling_params.prompt_logprobs is not None)):
return self.create_empty_block_list(), 0
# The block hashes for the request may already be computed
# if the scheduler has tried to schedule the request before.
block_hashes = self.req_to_block_hashes[request.request_id]
if not block_hashes:
assert self.block_size is not None
block_hashes = hash_request_tokens(self.caching_hash_fn,
self.block_size, request)
self.req_to_block_hashes[request.request_id] = block_hashes
if self.log_stats:
assert self.prefix_cache_stats is not None
self.prefix_cache_stats.requests += 1
# NOTE: When all tokens hit the cache, we must recompute the last token
# to obtain logits. Thus, set max_cache_hit_length to prompt_length - 1.
# This can trigger recomputation of an entire block, rather than just
# the single last token, because allocate_slots() requires
# num_computed_tokens to be block-size aligned. Removing this limitation
# could slightly improve performance in the future.
max_cache_hit_length = request.num_tokens - 1
computed_blocks, num_new_computed_tokens = (
self.coordinator.find_longest_cache_hit(block_hashes,
max_cache_hit_length))
if self.log_stats:
assert self.prefix_cache_stats is not None
self.prefix_cache_stats.queries += request.num_tokens
self.prefix_cache_stats.hits += num_new_computed_tokens
return KVCacheBlocks(computed_blocks), num_new_computed_tokens这个 函数中先计算了block_hashes,
然后find_longest_cache_hit(block_hashes,这里就是去找最长匹配了,
3.2 KV cache store过程
vllm/vllm/v1/core/block_pool.py中,
python
def cache_full_blocks(
self,
request: Request,
blocks: list[KVCacheBlock],
block_hashes: list[BlockHash],
num_cached_blocks: int,
num_full_blocks: int,
block_size: int,
kv_cache_group_id: int,
hash_fn: Callable,
) -> None:
"""Cache a list of full blocks for prefix caching.
This function takes a list of blocks that will have their block hash
metadata to be updated and cached. Given a request, it computes the
block hashes for the blocks starting from `num_cached_blocks` to
`num_full_blocks`, updating the metadata for each block
and caching them in the `cached_block_hash_to_block`.
Args:
request: The request to cache the blocks.
blocks: All blocks in the request.
block_hashes: Block hashes of the blocks in the request. Note that
this list may be shorter than the blocks list. In this case the
missed block hash will be computed in this function.
num_cached_blocks: The number of blocks that are already cached.
num_full_blocks: The number of blocks that are full and should
be cached after this function.
block_size: Number of tokens in each block.
kv_cache_group_id: The id of the KV cache group.
hash_fn: The hash function to use for block hashes.
"""
if num_cached_blocks == num_full_blocks:
return
new_full_blocks = blocks[num_cached_blocks:num_full_blocks]
assert len(block_hashes) >= num_cached_blocks
new_block_hashes = block_hashes[num_cached_blocks:]
# Update the new blocks with the block hashes through the chain.
if num_cached_blocks == 0:
prev_block_hash_value = None
else:
prev_block = blocks[num_cached_blocks - 1]
assert prev_block.block_hash is not None
prev_block_hash_value = prev_block.block_hash.get_hash_value()
parent_block_hash = prev_block_hash_value
new_hashes: Optional[list[int]] = ([] if self.enable_kv_cache_events
else None)
for i, blk in enumerate(new_full_blocks):
assert blk.block_hash is None
if i < len(new_block_hashes):
# The block hash may already be computed in
# "get_computed_blocks" if the tokens are not generated by
# this request (either the prompt tokens or the previously
# generated tokens with preemption), or by other
# single_type_managers with the same block_size.
# In this case we simply reuse the block hash.
block_hash = new_block_hashes[i]
else:
# Otherwise compute the block hash and cache it in the request
# in case it will be preempted in the future.
blk_idx = num_cached_blocks + i
start_token_idx = blk_idx * block_size
end_token_idx = (blk_idx + 1) * block_size
block_tokens = request.all_token_ids[
start_token_idx:end_token_idx]
assert len(block_tokens) == block_size, (
f"Expected {block_size} tokens, got "
f"{len(block_tokens)} at {blk_idx}th block for request "
f"{request.request_id}({request})")
# Generate extra keys for multi-modal inputs. Note that since
# we reach to this branch only when the block is completed with
# generated tokens, we only need to consider the last mm input.
extra_keys, _ = generate_block_hash_extra_keys(
request, start_token_idx, end_token_idx, -1)
# Compute the hash of the current block.
block_hash = hash_block_tokens(hash_fn, prev_block_hash_value,
block_tokens, extra_keys)
block_hashes.append(block_hash)
# Update and added the full block to the cache.
block_hash_with_group_id = BlockHashWithGroupId(
block_hash, kv_cache_group_id)
blk.block_hash = block_hash_with_group_id
self.cached_block_hash_to_block[block_hash_with_group_id][
blk.block_id] = blk
if new_hashes is not None:
new_hashes.append(block_hash.hash_value)
prev_block_hash_value = block_hash.hash_value
if self.enable_kv_cache_events:
self.kv_event_queue.append(
BlockStored(
block_hashes=new_hashes,
parent_block_hash=parent_block_hash,
token_ids=request.
all_token_ids[num_cached_blocks *
block_size:num_full_blocks * block_size],
block_size=block_size,
lora_id=request.lora_request.id
if request.lora_request else None,
))3.3 eviction代码
vllm/vllm/v1/core/block_pool.py
python
def _maybe_evict_cached_block(self, block: KVCacheBlock) -> bool:
"""
If a block is cached in `cached_block_hash_to_block`, we reset its hash
metadata and evict it from the cache.
Args:
block: The block to evict.
Returns:
True if the block is evicted, False otherwise.
"""
block_hash = block.block_hash
if block_hash and block_hash in self.cached_block_hash_to_block:
block.reset_hash()
del self.cached_block_hash_to_block[block_hash][block.block_id]
if len(self.cached_block_hash_to_block[block_hash]) == 0:
del self.cached_block_hash_to_block[block_hash]
if self.enable_kv_cache_events:
# FIXME (Chen): Not sure whether we should return `hash_value`
# or `(hash_value, group_id)` here. But it's fine now because
# we disable hybrid kv cache manager when kv cache event is
# enabled, so there is only one group.
self.kv_event_queue.append(
BlockRemoved(block_hashes=[block_hash.get_hash_value()]))
return True
return False这个函数在get_new_blocks中被调用
python
def get_new_blocks(self, num_blocks: int) -> list[KVCacheBlock]:
"""Get new blocks from the free block pool.
Note that we do not check block cache in this function.
Args:
num_blocks: The number of blocks to allocate.
Returns:
A list of new block.
"""
if num_blocks > self.get_num_free_blocks():
raise ValueError(
f"Cannot get {num_blocks} free blocks from the pool")
ret: list[KVCacheBlock] = []
idx = 0
while idx < num_blocks:
# First allocate blocks.
curr_block = self.free_block_queue.popleft()
assert curr_block.ref_cnt == 0
# If the block is cached, evict it.
if self.enable_caching:
self._maybe_evict_cached_block(curr_block)
curr_block.incr_ref()
ret.append(curr_block)
idx += 1
return ret他每次先去allocate,然后发现分配不够了,那么就去eviction,
然后具体的LRU驱逐逻辑,可以看一下下面的这个类,这个类里面相当于包含了好几个leetcode题,vllm/vllm/v1/core/kv_cache_utils.py
python
class FreeKVCacheBlockQueue:
"""This class organizes a list of KVCacheBlock objects to a doubly linked
list of free blocks. We implement this class instead of using Python
builtin deque to support removing a block in the middle of the queue
in O(1) time. To close the performance gap to the builtin deque which is
implemented in C++, this class does not allocate any Python objects when
manipulating the linked list. Instead, this class manipulates the
prev_free_block and next_free_block attributes of the given blocks.
The queue is ordered by block ID in the beginning. When a block is allocated
and then freed, it will be appended back with the eviction order:
1. The least recent used block is at the front (LRU).
2. If two blocks have the same last accessed time (allocated by the
same sequence), the one with more hash tokens (the tail of a block
chain) is at the front.
Note that we maintain this order by reversing the block order when free
blocks of a request. This operation is outside of this class.
Args:
blocks: A list of KVCacheBlock objects.
"""