文章目录
-
- 前言
- 一、时序数据库选型的核心考量因素
- [二、IoTDB / TimechoDB:为工业物联网而生](#二、IoTDB / TimechoDB:为工业物联网而生)
-
- [1. 产品体系:"采-存-用"一体化](#1. 产品体系:“采-存-用”一体化)
- [2. 架构优势:高可用、高扩展](#2. 架构优势:高可用、高扩展)
- [3. 企业级增强功能](#3. 企业级增强功能)
- [三、IoTDB + 大模型:时序大模型开启智能分析新范式](#三、IoTDB + 大模型:时序大模型开启智能分析新范式)
-
- [1. 什么是时序大模型?](#1. 什么是时序大模型?)
- [2. Timer 模型家族](#2. Timer 模型家族)
-
- Timer-1(非内置)
- [Timer-XL(V2.0.5.1+ 内置)](#Timer-XL(V2.0.5.1+ 内置))
- [Timer-Sundial(V2.0.5.1+ 内置)](#Timer-Sundial(V2.0.5.1+ 内置))
- [3. 应用场景](#3. 应用场景)
- [4. 一键部署使用](#4. 一键部署使用)
- [四、为什么选择 IoTDB / TimechoDB?](#四、为什么选择 IoTDB / TimechoDB?)
- 总结
前言
在工业4.0、智能制造、能源管理、车联网等场景中,海量设备持续产生高频率、高并发的时序数据 ,对数据库的写入吞吐、存储成本、查询效率和分析能力提出了极高要求。面对这一挑战,时序数据库(Time Series Database, TSDB)成为关键基础设施。
本文将从实际选型角度出发,深入剖析 Apache IoTDB 及其企业版 TimechoDB 的核心优势,并重点介绍其与自研 时序大模型 (Timer 系列)的深度集成,展示"DB + AI"如何赋能下一代工业智能。

官网直达:https://timecho.com
一、时序数据库选型的核心考量因素
企业在选择时序数据库时,通常关注以下维度:
| 维度 | 关键指标 |
|---|---|
| 写入性能 | 单节点/集群每秒可处理多少测点?是否支持乱序、高频写入? |
| 存储成本 | 压缩比如何?能否降低90%+存储开销? |
| 查询能力 | 是否支持复杂时序函数、降采样、窗口计算?响应是否毫秒级? |
| 部署运维 | 是否支持分布式、云边协同?运维是否简单? |
| 生态兼容 | 是否支持 SQL、多语言 API、主流可视化工具? |
| AI 能力 | 是否内置机器学习/深度学习支持?能否实现预测、异常检测? |
| 国产化适配 | 是否通过信创认证?代码是否自主可控? |
在众多开源与商业方案中,Apache IoTDB 凭借其源自清华大学的学术底蕴 、工业级落地验证 和活跃的开源社区 ,已成为全球领先的时序数据库之一,并于2024年登顶国际权威基准测试 TPCx-IoT 性能榜首。
二、IoTDB / TimechoDB:为工业物联网而生
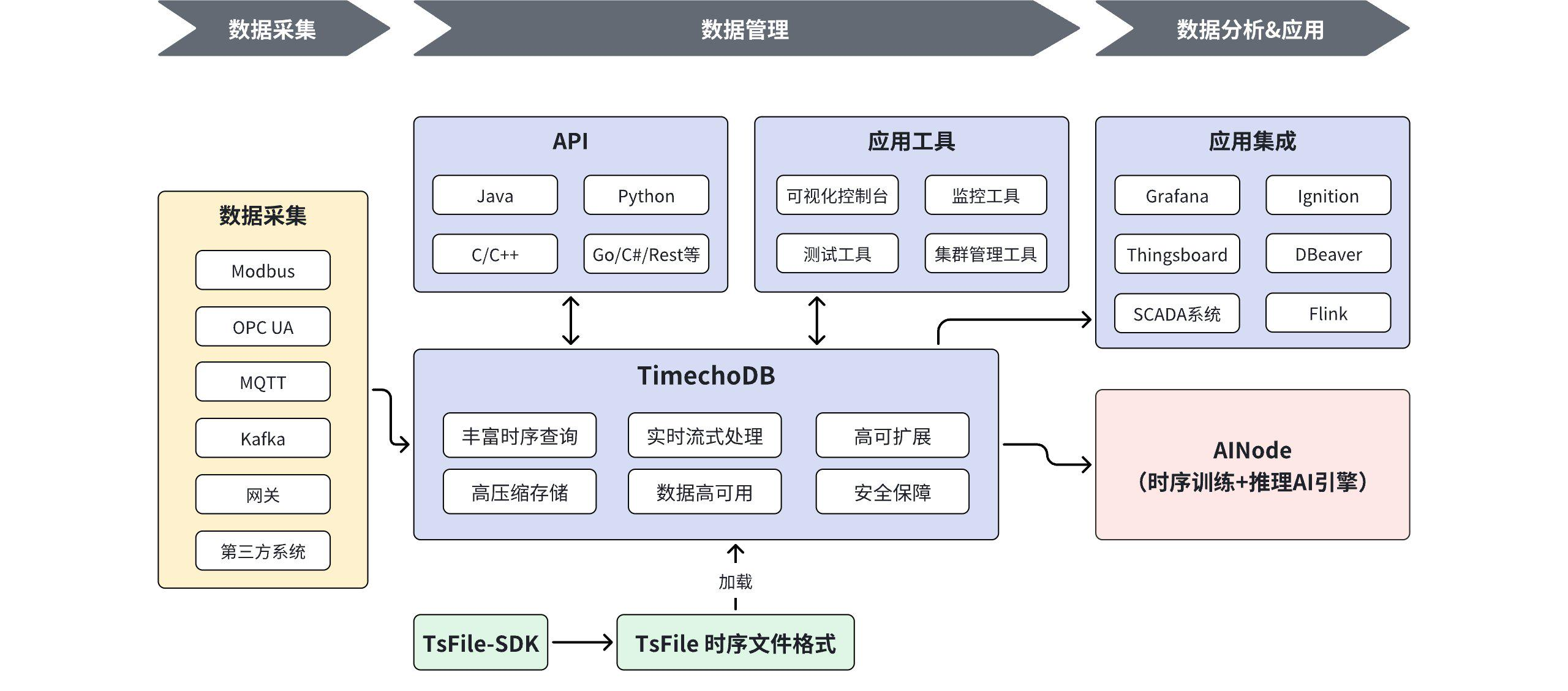
1. 产品体系:"采-存-用"一体化
天谋科技(IoTDB 原厂团队)基于 Apache IoTDB 打造了 TimechoDB 企业版,构建了完整的时序数据生命周期解决方案:
- 数据采集:支持数百种工业协议,适配弱网、断点续传、网闸穿透。
- 数据存储 :基于自研 TsFile 格式,实现 90%+ 高压缩比 ,单机支持 千万级点位/秒写入。
- 数据分析 :内置 AINode 引擎 ,无缝集成 时序大模型,实现预测、填补、异常检测。
- 数据应用 :提供 Workbench 可视化控制台 、Grafana 监控面板 、集群管理工具,极大降低使用门槛。
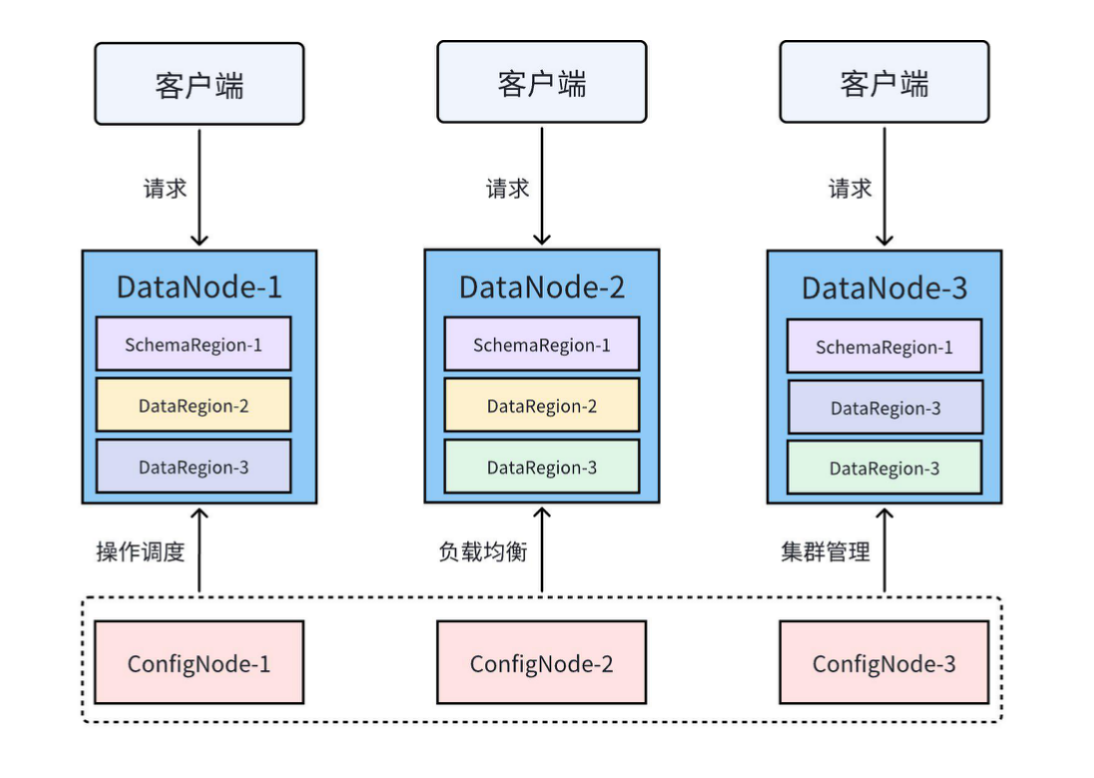
2. 架构优势:高可用、高扩展
TimechoDB 采用 3C3D 分布式架构(3 ConfigNode + 3 DataNode),支持:
- 自动负载均衡:节点增删无需停机,数据自动重分布。
- 7×24 高可用:单点故障不影响服务。
- 云边协同:边缘端轻量部署,数据自动同步至云端。
3. 企业级增强功能
相比社区版,TimechoDB 企业版新增多项工业刚需功能:
| 功能 | Apache IoTDB | TimechoDB |
|---|---|---|
| 双活部署 | ❌ | ✅ |
| 多级存储(冷热温) | ❌ | ✅ |
| 内置数据同步插件 | 仅文件同步 | 实时+批量+加密+压缩 |
| 安全增强(白名单、审计日志) | ❌ | ✅ |
| 国产化适配 | 部分 | ✅(通过多项信创认证) |
| 专业技术服务 | 社区支持 | 原厂专家 + 天级修复 |
案例 :宝武钢铁接入 2000亿时序点 ,写入速度达 3000万/秒 ,压缩比 10倍 ;长安汽车管理 57万辆车 ,查询从分钟级降至 毫秒级。
三、IoTDB + 大模型:时序大模型开启智能分析新范式
传统时序分析依赖 ARIMA、Holt-Winters 等统计模型,泛化能力弱、需大量调参。而 IoTDB 团队自研的 Timer 系列时序大模型 ,将 AI 能力深度嵌入数据库内核,实现"数据不动,模型动"。
1. 什么是时序大模型?
时序大模型是专为时间序列设计的 基础模型 (Foundation Model),基于 Transformer 架构,在 万亿级工业时序数据上预训练,具备:
- 通用特征提取能力
- 零样本/少样本预测
- 多任务统一建模
相关成果已发表于 ICML 2025 Spotlight 等顶级会议。
2. Timer 模型家族
Timer-1(非内置)
- 少样本微调即可达到 SOTA 效果
- 支持灵活输入/输出长度
Timer-XL(V2.0.5.1+ 内置)
- 超长上下文:支持数万个时间点输入
- 多变量预测:覆盖非平稳、协变量场景
- 万亿工业数据预训练:覆盖能源、交通、钢铁等领域
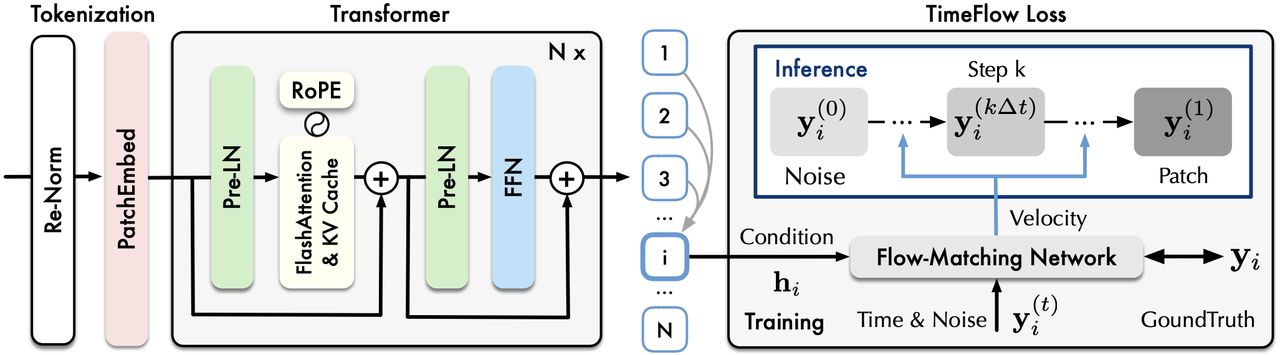
Timer-Sundial(V2.0.5.1+ 内置)
- 1.28亿参数,1万亿时间点预训练
- 生成式架构(Transformer + TimeFlow):可生成多样化预测轨迹
- 概率预测:不仅预测均值,还能评估完整分布
3. 应用场景
| 场景 | 价值 |
|---|---|
| 时序预测 | 提前预警设备故障、预测能耗趋势 |
| 数据填补 | 自动修复传感器断连导致的缺失数据 |
| 异常检测 | 实时识别偏离正常模式的异常行为 |
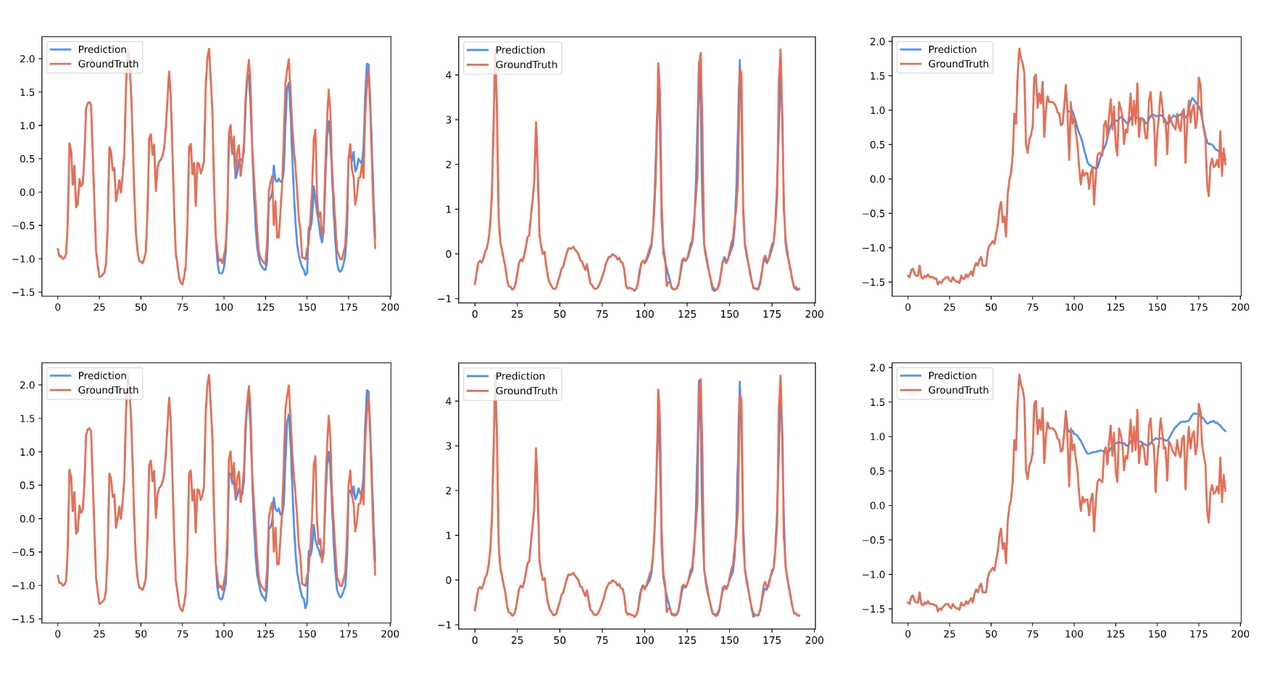
预测曲线(蓝)与真实值(红)高度吻合
4. 一键部署使用
在 TimechoDB 中,只需启动 AINode,即可自动加载内置模型:
sql
-- 查看可用模型
IoTDB> SHOW MODELS;
+---------------------+--------------------+--------+------+
| ModelId| ModelType|Category| State|
+---------------------+--------------------+--------+------+
| sundial| Timer-Sundial|BUILT-IN|ACTIVE|
| timer_xl| Timer-XL|BUILT-IN|ACTIVE|
+---------------------+--------------------+--------+------+用户可通过 SQL 或 API 直接调用模型进行推理,无需搭建独立 AI 平台。
四、为什么选择 IoTDB / TimechoDB?
- 性能领先:单机千万级写入,毫秒级查询,压缩比行业顶尖。
- 工业验证 :已在 国家电网、中国核电、中车四方、华为、京东等百余家头部企业落地。
- AI 原生 :唯一深度集成 时序大模型 的开源时序数据库。
- 国产可控:100% 自主研发,符合信创要求。
- 生态友好:支持 SQL、Java/Python/C++/Go API,无缝对接 Spark、Flink、Grafana。
总结
面对工业场景中海量、高频、高并发的时序数据,传统数据库往往难以兼顾性能、成本与智能分析能力。Apache IoTDB 以卓越的写入吞吐、90%+ 压缩比和毫秒级查询,成为开源时序数据库的标杆;其企业版 TimechoDB 更进一步,提供双活架构、多级存储、信创适配与云边协同等工业级能力。
尤为关键的是,IoTDB 团队率先将 时序大模型(Timer 系列)深度集成至数据库内核,实现"数据不动,模型动"------无需额外 AI 平台,即可在库内完成预测、填补、异常检测等智能任务,大幅降低使用门槛与系统复杂度。
已在国家电网、中车、华为等百余家头部企业落地验证,IoTDB / TimechoDB 不仅是技术优选,更是面向工业智能时代的基础设施。
如果你需要一个 高性能、低成本、易运维、强 AI 能力 的时序数据库, Apache IoTDB (开源) 和 TimechoDB(企业版) 是当前最优解。