论文地址:Extracting Latent Steering Vectors from Pretrained Language Models - ACL Anthology
名词解释
1、自然语言处理(Natural Language Processing,简称NLP)是计算机科学和人工智能领域中的一个重要方向。主要任务是使计算机能够理解和生成自然语言文本。这包括自然语言理解(Natural Language Understanding, NLU)和自然语言生成(Natural Language Generation, NLG)两个部分。
2、可训练解码(Trainable Decoding):通过引入可学习的参数或辅助网络,对语言模型的推断过程(Inference Process)进行干预的方法。其核心在于不改变预训练语言模型(PLM)本身权重的前提下,通过训练一个外部的解码策略(Decoding Policy)或评分函数,来引导模型生成符合特定属性(如特定情感、句法结构)的文本。通常通过以下方式介入:
-
干预概率分布: 它训练一个轻量级的网络,在解码的每一步计算一个额外的得分或是偏置项。
-
联合优化: 最终的输出概率分布不再仅仅取决于基础语言模型(Base LM),而是基础模型与可训练解码模块的联合结果。
与 Fine-tuning 的区别: 微调是直接更新模型参数 ,属于模型层(Model-level)的改变;而 Trainable Decoding 是更新解码策略参数
,属于推断层(Inference-level) 的改变。
3、基于自编码器的模型训练(Training Auto-encoder Based Models):它不直接操作离散的文本符号,而是旨在学习一个连续的、低维的潜在向量空间,即通过训练外部映射网络来构建可控潜空间。在这个空间中,文本的"内容(Content)"与"属性(Attribute/Style)"(如情感、时态等)被尝试分离为独立的变量 。常结合变分自编码器 VAE 或去噪自编码器 DAE,其工作流包含三个关键阶段 :
- 编码(Encoding):通过一个可训练的编码器(Encoder),将离散的源文本序列映射为一个固定长度的连续潜变量向量 。
- 潜空间操控(Latent Space Manipulation):在潜空间内引入一个控制器(Controller)或通过向量算术,对代表特定属性(如情感极性)的维度进行变换。这一步的目标是促使模型生成符合目标属性(例如从消极转为积极)的文本 。
- 解码(Decoding):利用一个解码器(Decoder),根据变换后的潜向量重构出目标文本序列 。
4、GloVe:一种用于获取单词向量表示(Word Embeddings)的无监督学习算法。它结合了全局矩阵分解(Global Matrix Factorization)(如 LSA)和局部上下文窗口(Local Context Window)(如 Word2Vec)两类方法的优点。核心在于利用全局词-词共现矩阵(Global Word-Word Co-occurrence Matrix)来捕捉语义。它通过通读全文算出每个词的"社交圈子",然后把这些词变成一串数字。在这串数字里,意思相近的词住得近,意思相反的词住得远。
5、Adapter-based fine-tuning:保持预训练模型的主体参数冻结(Frozen),仅在 Transformer 的层与层之间插入轻量级的、可训练的神经网络模块(Adapters)。也是一种操控隐藏状态的好方法,但仍需训练。
一、动机
以前如果想控制 GPT-2 这种模型,让它生成某种特定风格(比如把"我讨厌这个东西"变成"我喜欢这个东西"),之前的方式存在以下不足 :
1、Trainable Decoding仍然需要训练新的参数(虽然比微调少),且往往构建了复杂的外部依赖。
2、Fine-tuning需重新训练神经连接,费钱、费时,而且容易把模型本来会的知识搞乱。
3、Smart-prompt design像是在哄小孩,有时候听话,有时候不听话,不稳定。
4、训练额外的解码器: 须要从头训练或微调编码器和解码器组件,构建成本较高 。
二、贡献
作者提出了一种不训练模型(Frozen),直接从模型内部提取出一个"控制向量"(Steering Vector)。只要把这个向量往模型里一插,模型就会输出特定的回复。系统分析了这个潜在空间的一些性质(插值平滑、簇结构、不只是死记硬背等)。
三、方法
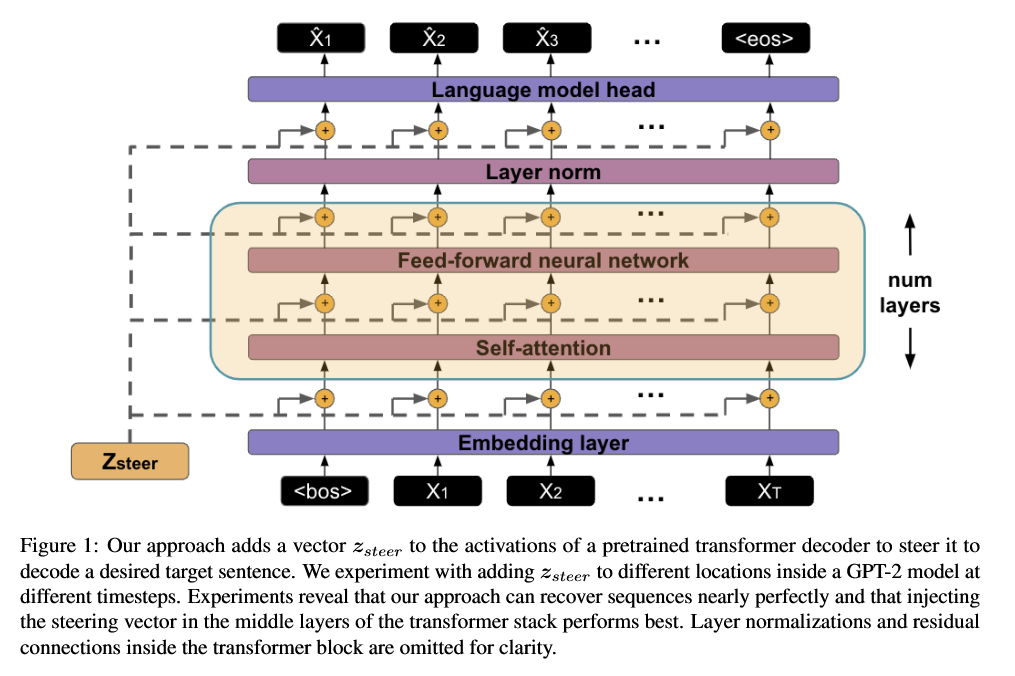
对于每个时间步 t,GPT-2 会有一堆层叠的 Transformer block。每个 block 里有:Embedding、Self-attention、Feed-forward、Layer norm、LM head,作者选择在某些层的位置,把一个固定向量加到隐藏状态上:这就像:给整个解码过程打上一点"全局偏置",让模型偏向某种"轨迹"。
1、提取引导向量
(1)引导向量(Steering Vectors):一个固定长度的向量,可以添加到预训练语言模型的隐藏状态中,从而引导模型生成特定的目标句子,这个向量记作。
固定长度的原因是:使得分析更有意义,允许在同一表示空间中比较不同长度句子的向量。
(2)发现引导向量

- 准备工作:拿来一个训练好的 GPT-2 模型,把它锁死(Frozen),绝对不许改它的参数。选一句目标句子x,比如 "The food is good"。使用xavier正态分布随机初始化一个向量
(一开始这串数字是乱填的)。
为什么用
向量维度d′与投影矩阵
- GPT-2 hidden 维度 d=768。
- 让 steering 向量的维度 d′≤d。
- 如果 d′<d,就用一个半正交矩阵
所以注入的真正东西是
-
前向传播 (Forward Pass):把这个乱填的
-
计算损失 (Loss Calculation):看模型生成的胡话,和的目标句子 "The food is good" 差得有多远。计算交叉熵损失(Cross Entropy Loss)。
把 "使用这个
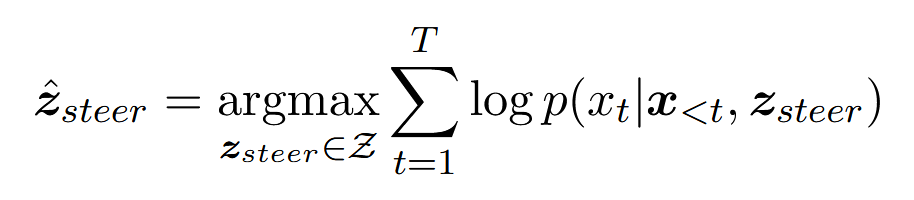
- 反向传播 (Backward Pass):根据这个分数,去修改那个向量
这相当于把 GPT-2 当成一个固定的非线性函数,在它前面加了一个"可调偏置向量",让输出拟合目标句。
- 循环 (Loop):不停地调这个
(3)引导语言模型
提取完某个句子的后:以后想让模型再生成这个句子,只需要给模型一个 BOS(句首 token),在同样的层、同样的时间步,把
加进去,用贪心解码(每步选概率最高的 token,一直到 EOS 或 1024 token)。
实验里都是用贪心,不做 beam search,目的是考察是否能"精确还原"。
2、能否提取引导向量?
(1)实验设置
数据集收集:为了测试这一招在很多不同类型文本上的泛化,所以组合了四个域(英文):movies(Cornell Movie Dialogs(电影对白))、books(NLTK 的 Gutenberg(经典小说))、news(Gigaword 新闻)、wiki(WikiText-103)。
数据预处理:对每个语料做句子切分(NLTK sentence tokenizer),按句长分8个桶(用词级 token 数),分别是5--10, 10--15, ..., 35--40, 40--128,每个桶随机采样 8 句,总共每个域 8×8=64 句。
为了控制句长分布(看短句/长句的难度差异)以及用少量而"覆盖多长度"的样本,便于消融实验。
衡量引导的有效性:BLEU-4。对每个目标句 s,抽出一个,用它解码出句子
,计算 smoothed BLEU-4。
BLEU-4 越接近 100,说明生成的 4-gram n-grams 与原句几乎完全一致,对短句来说基本等价于一字不差。
超参数搜索:初始实验对大多数超参数(如初始化方法和学习率调度)的变化不大,因此在随后的实验中固定它们。作者选择GPT2-117M作为语言模型,在数据集上评估不同的注入位置和注入时间步长下的恢复效果,这两个对结果有显著影响的超参数的情况下,对我们的数据集进行恢复评估。

中间层(Layer 6/7)的self-attn或FFN层最好,其次即使只在第一个时间步加
同时对单层注入(中间层)来说,只在第一步加一次就几乎够了;对所有层都加时,只第一步影响稍大,但仍然很高。这反映出一个有趣现象,即早期时间步的"全局偏置"会通过自回归传播,影响整句的生成。
(2)恢复效果
他们主要关心两个问题:
- 同一个句子是否存在很多完全不同的
- 不同句子的
为此作者取 books 子集的 64 句,每句用 8 个不同随机种子初始化,分别优化。结果63/64 句子,8 次都能完美恢复(BLEU 几乎 100)。再从中挑 20 句,每句 8 个向量 → 共 160 个向量;用 t-SNE 降到 2 维进行可视化。
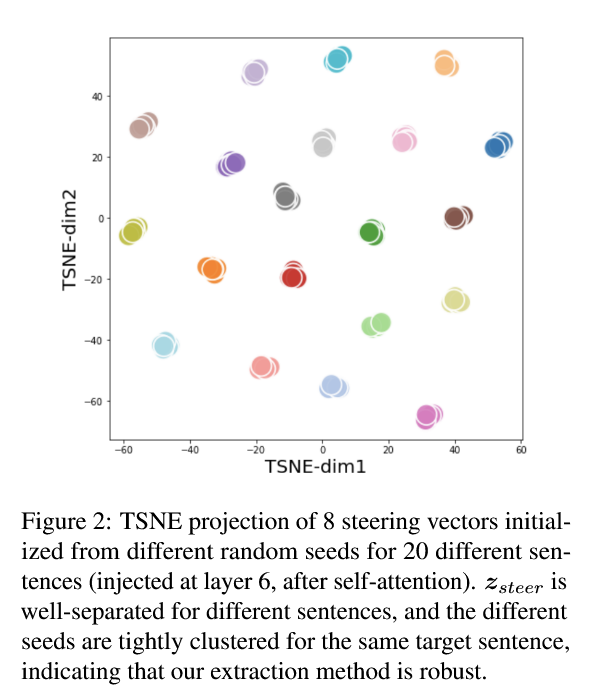
图中每个句子对应一簇点,同一句子各初始化的 8 个点紧密聚成一团,不同句子的簇彼此远离。说明对同一目标句子,优化几乎总会落到一个相近的局部极值区域,这说明"token 空间 ↔ steering 空间"的映射是稳定的。句子之间的"不同",在 latent space 里也体现为簇间距离。
接着作者还做了个小实验:把同一句子 8 个向量取平均,看看还能不能恢复。结果 BLEU=99.4,仍然几乎完美。说明这个空间的"局部线性"也不错,而不是高度非线性乱七八糟。
3、是否可以在潜在的引导空间中进行无监督的情感迁移?
以 Yelp 情感数据集为例(正面 / 负面评论)。对每个句子,都可以抽一个 steering vector z。
- 从训练/验证集中各取 100 个正类句子,抽 steering 向量,求平均得到:
- 同理对负类求平均:
- 定义目标偏移:
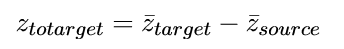 ;
; - 对一条具体句子,它原来的 steering vector 是
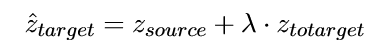 .
.
(1)实验设置:Yelp Sentiment(Yelp Dataset)。抽向量时的注入位置第 7 层 self-attn 后,第一个time step加一次。用 100 条正类 + 100 条负类来算平均向量。在测试集句子上做风格翻转。
(2)评价指标:
- 风格准确率(accuracy):用一个单独训练好的 RoBERTa-base 分类器(监督训练在 Yelp 上),看生成句子被它判成"目标情感"的比例。
- Self-BLEU-4:生成句子 vs 输入原句的 BLEU-4,衡量内容保留程度。越高说明越"原汁原味",但太高可能说明情感没改多少。
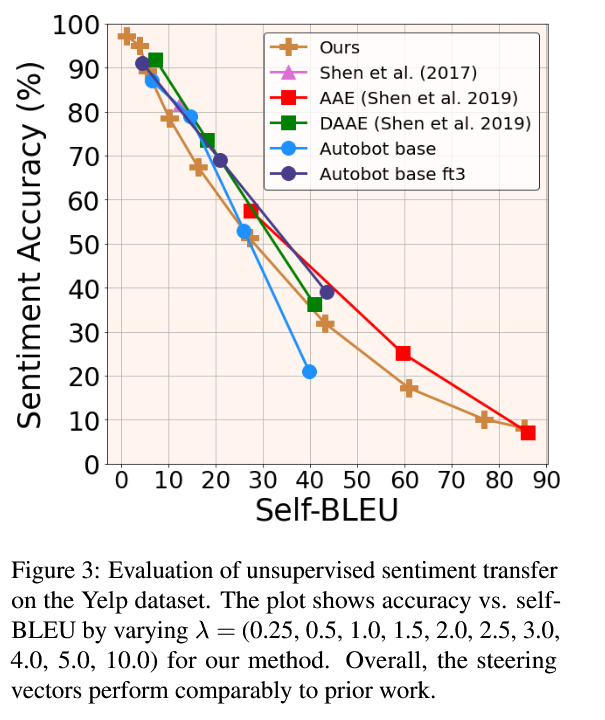
从图中可以看到随着 λ 变大,准确率总体上升(情感变化更强),Self-BLEU 下降(原句被改动更多),他们的性能接近甚至优于一些自动编码器式的专门方法。
结果示例:可以看出:小λ,内容基本不变,情感也几乎没动;稍大 λ 会在保持主干不动的前提下,替换情感核心形容词;再大 λ 容易出现语句重复 / 语法不顺。
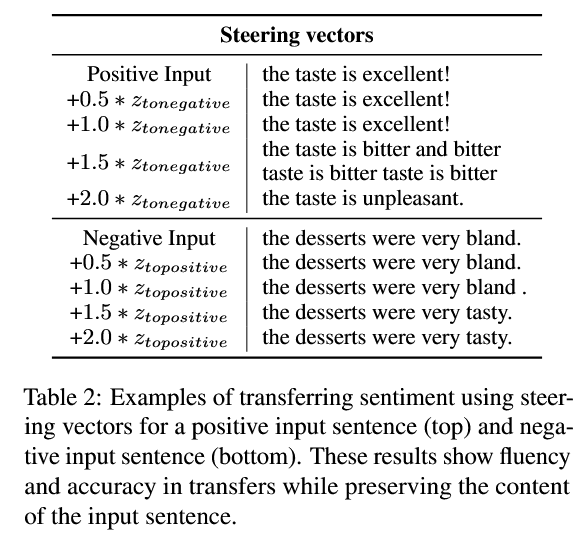
4、引导向量之间的距离是否反映了句子的相似度?
前面已经看见同一句子的多个向量聚一团,于是有了一个自然问题,如果句子 A & B 在语义上比较相近,那它们的 steering 向量的余弦相似度是不是也比较高?
(1)实验:STS-B(STS-B语义文本相似性基准),每对句子有一个人工打的相似度分数(0--5)。
-
对测试集中每个句子单独抽一个
注入层的选择:他们在不同层(尤其中间层)试了一圈(只在第一步加 z_steer)。
-
对每对句子(s1, s2):计算 cos(z1,z2)。
-
把所有对的 cosine 值,与人工相似分数做Spearman 相关(排名相关)和 Pearson 相关。
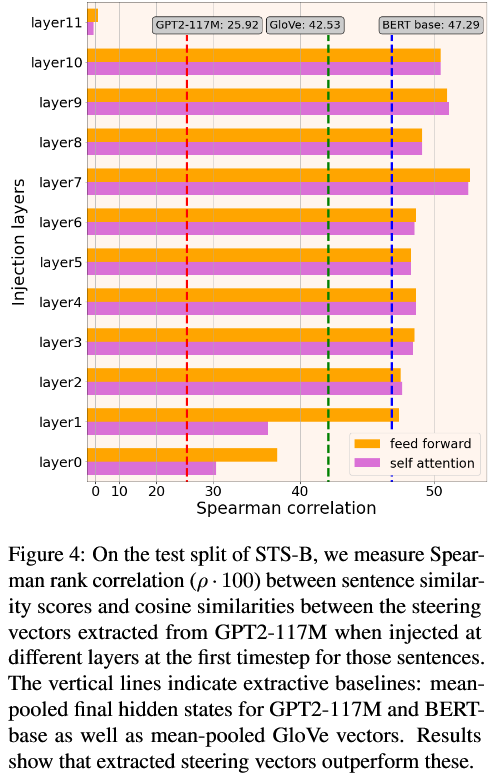
三条纵线是:平均 GPT2 最后一层 hidden state 的余弦相似,平均 BERT-base hidden state,平均 GloVe 词向量。
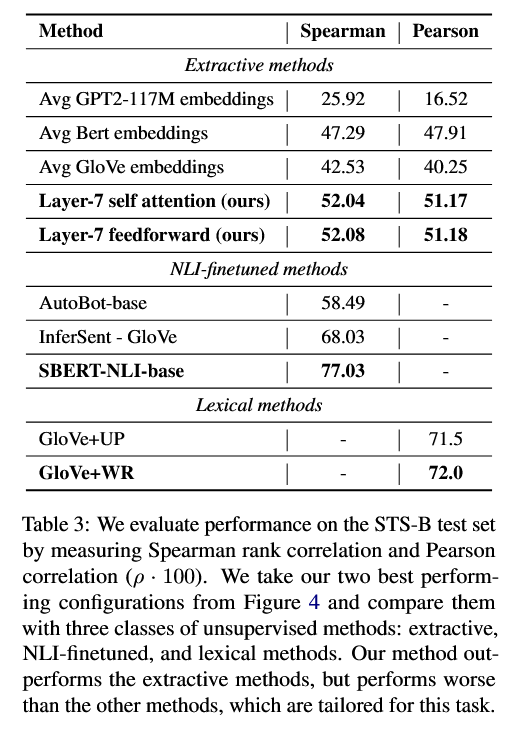
可以看到,中间层(第 7 层)上的 steering vector 表现最好,其 Spearman 相关大约是 52,明显高于那三个简单基线。
(2)与其他方法对比发现作为完全不在 STS 或 NLI 上训练过的纯 unsupervised 表示方法,
steering vectors 的表现优于"简单平均 hidden state / 词向量"。但确实比"专门为语义相似任务训练"的 SBERT / InferSent 等要差,这是意料之中。
5、性质分析
(1)插值(Interpolation):从 Yelp 数据集中随机拿两句,记它们的 steering 向量为 z1,z2,生成一系列线性插值:z(λ)=(1−λ)z1+λz2,其中 λ 从 0 到 1,比如 0,0.1,0.2,...,1。对每个 z(λ) 解码出一句话。

两个句对的插值结果(句对1、句对2),句对1中当 λ 从 0 增大时,生成内容逐渐从句1过渡到句2,有趣的是直到 λ=0.7 左右,句子仍保持正面情感,即情感特征有"惯性"。句对2中第二句里含有 "young"等时间信息,中间插值产生了类似于 "four years ago" 这种组合词,把第一个句子的"四岁(four)"与第二句的"years ago"组合,说明了 latent space 里确实在"混合语义",而不是乱串 token。
即说明这个潜在空间是比较平滑的,而且每个句子附近存在一个"体积"(一个球形区域),
在这个区域内的向量都能 steer 出同一句话。这和前面"同一句句子的 8 个聚成一团,平均后也能恢复"的发现一致。
(2)采样(Sampling):既然这是一个有结构的 latent space,那能不能像 VAE 那样,
直接在这个空间里采一些向量,生成自然句子?
- 从 Yelp 数据集采 4000 个
- 对每一维,统计这 4000 个向量在该维度的均值
- 假设各维独立,整体是一个多维高斯:
- 从这个高斯里采样 24 个新向量,解码输出。
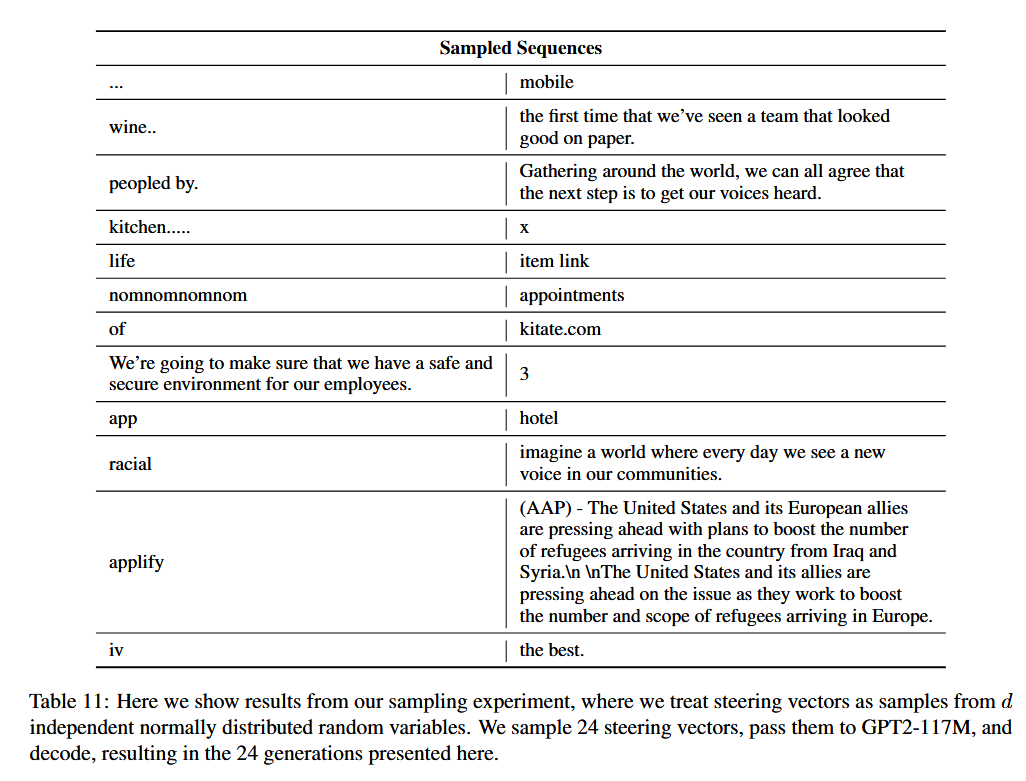
结果大约 5 个样本生成了完整、流畅的句子,大约 19 个只生成了一个词、短语,或半截句子。
所以简单地假设"各维独立、整体是高斯"去采样,并不能稳定地产生好句子,latent steering space 结构更复杂,训练集上的向量只占据这个空间的"子流形",盲目高斯采样大概率落在"不对应自然句"的区域。作者也提到,训练数据本身质量有噪音,但更关键是 Gaussian 假设太粗糙。
(3)内在维度 & 空间复杂度(Intrinsic Dimension & Space Complexity):"Steering 任务的内在维度" =能达到几乎完美恢复所需的的最小维度。
- 分别试 d′=192,384,576,768,其余设定不变;
- 对同样的数据集算恢复 BLEU。
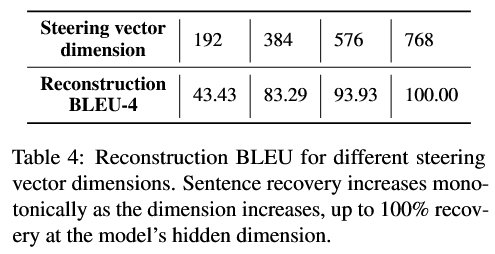
随维度增加,恢复能力单调上升;768(等于模型 hidden 维)时,几乎 100% 恢复;384 维已经能达到 83 BLEU,意味着很多信息可以被压缩到一半维度。同时也发现句子越长,恢复越难,这也符合"编码信息量正比长度"的直觉。
关于空间复杂度:句长 128,假设平均每词 7 个字符(含空格),文本存储约 896 byte。768 维 steering 向量,如果用 fp16(2 byte/维),是 1536 byte。但如果压到 384 维,只要 768 byte,就比直接存文本还省空间。
(4)记忆(Memorization):是否只是"死记硬背字符串"?为此,作者设计了两个"对照版本"的数据集:
- gibberish fold(胡言乱语):句长分布跟 books 一样,但每个 token 从词表里随机采样(独立同分布),所以完全没有语法结构、也没有语义。
- shuffled fold(打乱版):取 books 里的句子,但把词顺序打乱,内容词还在,但语法关系全乱。
然后在这三套数据上分别训练,考察恢复 BLEU。
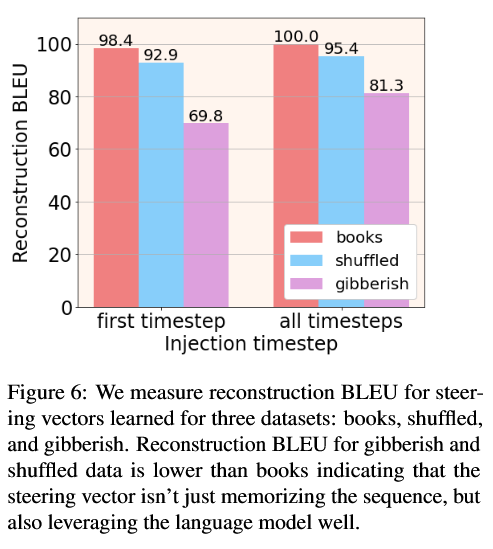
结果books(正常文本)恢复最好,shuffled 其次,gibberish 最差,尤其是只在 first timestep 注入时,normal vs gibberish 的差距更大。说明:steering 向量确实在利用语言模型内部的结构知识,对有真实语言结构的句子更容易恢复,而对完全 random 的序列很难恢复(因为 LM 本身对这种序列的概率极低,要强行把它拉上来需要更怪的)。它们不仅编码 token 的"袋子"(bag of words),还编码顺序信息,因为 shuffled 比 gibberish 好,但仍比原 books 差。
这证明steering vector 不是一个"通用压缩算法",而是"利用 LM 作为先验 + 少量额外信息"一起表达句子。
(5)与提示词工程对比:不往 hidden 层里加,而是把
直接当作额外的"虚拟 token embedding",拼到输入序列前面,让后续所有 token 都能注意到它。
- 把 k 个 steering 向量(每个 768 维)当成 k 个"前缀 token";
- 输入序列变成:
[z1, z2, ..., zk, x_1, x_2, ...]; - 不修改 Transformer 结构。
- 实验了不同 k 值(1,5,10,20,50),看恢复 BLEU:
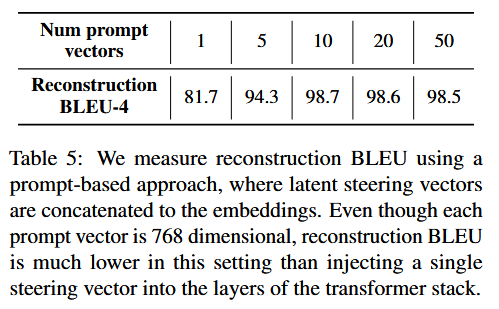
即便当 k=50(总共 50×768 维,远大于单个 768 维 z_steer),BLEU 也还是低于"在中间层直接加一个 z_steer(BLEU 100)"。所以通过 prompt 的方式注入 latent 信息,不如直接改 transformer 中间层,这说明隐藏空间里的"直接注入"能力更强,更适合做精细操纵。这和各种 adapter / LoRA / PPLM 的实践经验是一致的。
四、结论
不训练 encoder-decoder,不训练新的 controller,不 fine-tune LM,只优化每个句子的一个 latent 向量,操作点在Transformer 中间层隐藏状态,而非输出层或 embedding;展示了:几乎完美句子恢复;简单向量算术即可做无监督风格迁移;向量距离部分反映语义相似。这说明,预训练 LM 里已经"自带了"一个有意义的潜在控制空间。只需要想办法把它显式取出来用,而不是再造一套新模型。