1、serier
系数,可以看作是竖起来的list
print(s_1.index)

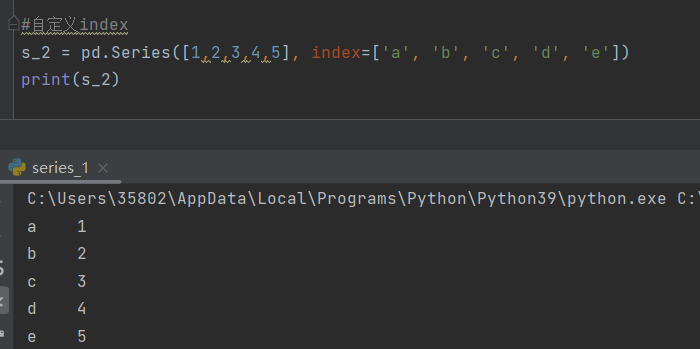
当加入index后,index等于多少,那么它对应的那一行数据的行名就是多少
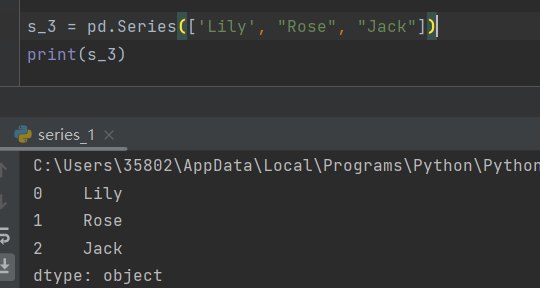
pandas库和numpy库的不同就是,numpy只能处理数值类型的数据,而pandas可以处理字符串等
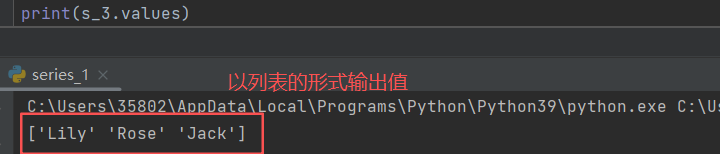
print(s_3.values)
2、操作series
python
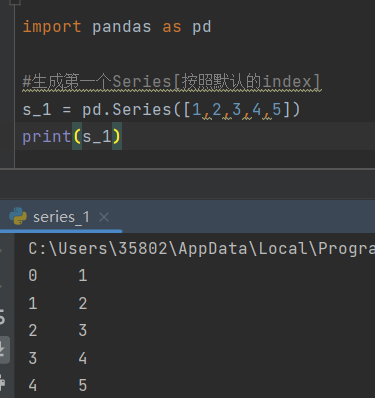
import pandas as pd
s_1 = pd.Series([1,2,3,4,5],
index=['a', 'b', 'c', 'd', 'e'])
s_2 = pd.Series(['lily', 'rose', 'jack'])
#查
"""
(1)通过标签访问
"""
#访问某个元素
print(s_1['d'])
#访问多个元素[Series的切片]
print(s_1['a':'d'])
#访问多个元素
print(s_1[['a', 'd']])
"""
(2)通过索引访问
"""
print(s_2[2])
print(s_2[0:2])
print(s_2[[0, 2]])
print(s_1[4])
#删除
s_1 = s_1.drop('a')
#判断一下某个值是否在Series里面
print('jim' != s_2.values)
#改
s_2[0] = 'Peter'
#创建Series
dic_1 = {"name1": "Peter", "name2":"tim",
"name3":"rose"}
s_4 = pd.Series(dic_1)
print(s_4)
#重置索引
s_4.index = range(0, len(s_4))
print('1')3、pandas.DataFrame()
就是excel表,由多个series拼接而成
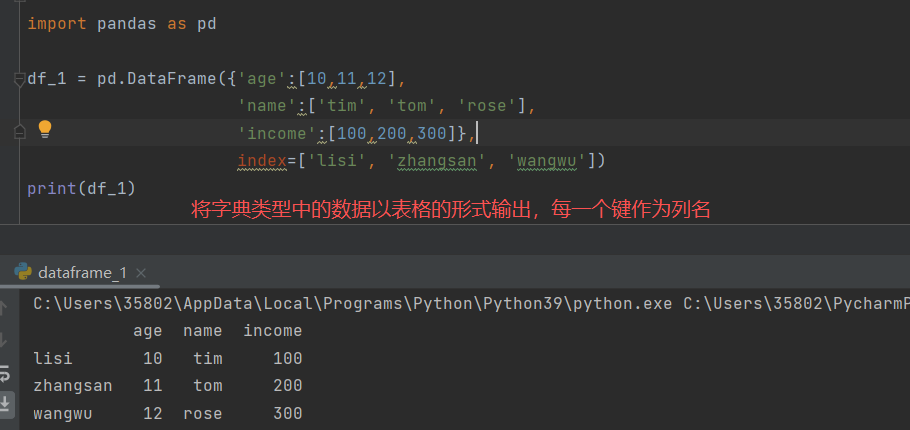
1)属性
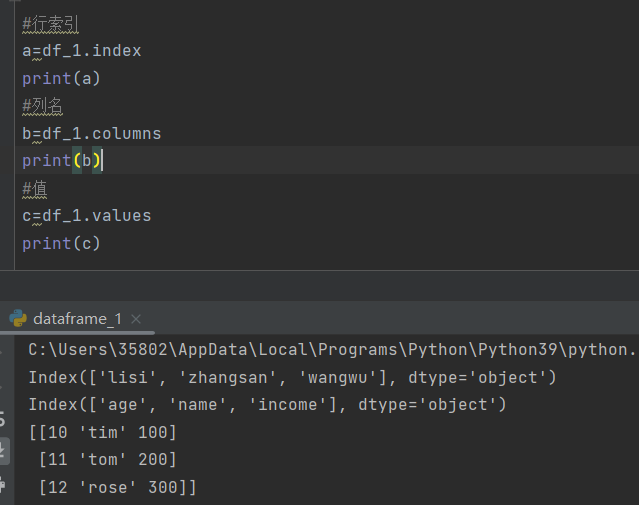
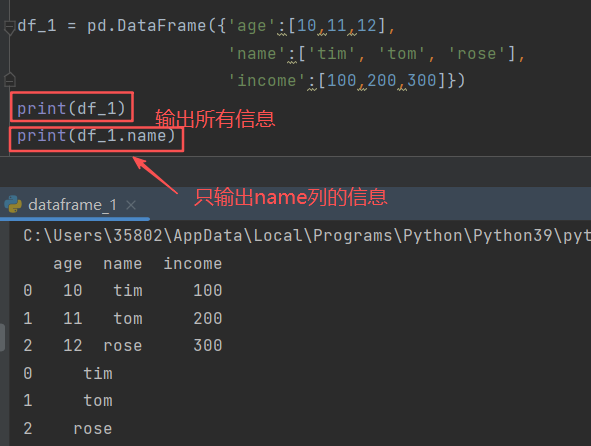
2)常见操作
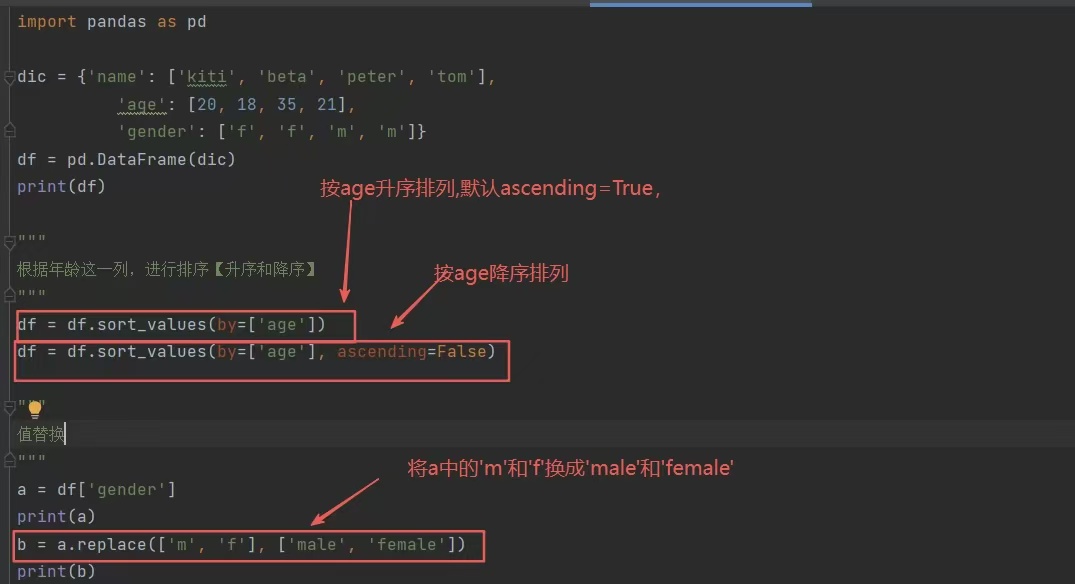
3)简单操作
df.columns:修改列名
df.index:修改行名
df.loc:增加一行
del:删除某列,直接在原数据上删除
df.drop('文件中的内容', axis=1, inplace=False)
:删除某行或某列的内容,若axis=0,则代表删除行,等于1则代表删除列,若inplace=False,表示不知道在原数据上删除,而是返回一个删除后的新表格,否则则在原数据上删除
python
import pandas as pd
df = pd.DataFrame( {'age':[10,11,12],'name':['tim', 'tom', 'rose'], 'income':[100,200,300]},
index=['person1', 'person2', 'person3'])
print(df)
# 修改列名
a= df.columns
df.columns = range(0, len(df.columns))
print(df.columns)
# 修改行名
print(df.index)
df.index = range(0,len(df.index))
print(df.index)
#在最后添加一列
df['pay'] = [20, 30, 40]
print(df)
# 增加一行
df.loc['person4', ['age', 'name', 'income']] = [20, 'kitty', 200]
print(df)
"""
访问DataFrame
"""
#访问某列
print(df.name)
a = df.name
b = df['name']
#访问某些列
print(df[['age', 'name']]) #
#访问行
print(df[0:2])
# #使用loc访问
print(df.loc[['person1', 'person3']])
#访问某个值
print(df.loc['person1', 'name'])
#直接在原数据上删除
del df['age']
print(df)
#删除列
data = df.drop('name', axis=1, inplace=False)
print(data)
#删除行
df.drop('person3', axis=0, inplace=True)4、数据框查询的2种方法
python
"""
loc()
iloc()
"""
import pandas as pd
import numpy as np
#生成指定日期
df = pd.DataFrame(
np.arange(30).reshape(5,6),index=['20180101','20180102','20180103','20180104','20180105'],
columns=['A','B','C','D','E','F'])
"""
loc()方法
df.loc[x, y]
【标签索引】
"""
#打印某个值
print(df.loc['20180103', 'B'])
#打印某列值
print(df.loc[:,'B'])
print(df.loc['20180103':,'B'])
print(df.loc['20180103':,['B', 'D']])
#打印某行值
print(df.loc['20180101', :])
#打印某些行
print(df.loc['20180103':,:])
"""
iloc()方法
位置索引
"""
#获取某个数据
print(df.iloc[1,2])
#获取某列
print(df.iloc[:,2])
#获取某几列
print(df.iloc[:,[1,3]])
#获取某行
print(df.iloc[1,:])
#获取某些行
print(df.iloc[[1,2,4],:])5、数据导入与导出
1)pandas.read_2csv('文件名')
功能:读取csv文件
列名为文件中第一行的数据,行名从0开始,依次递增
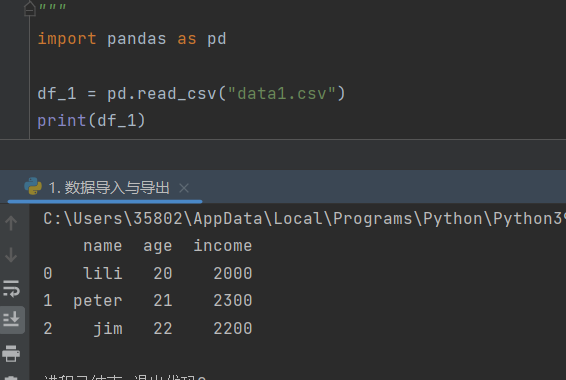

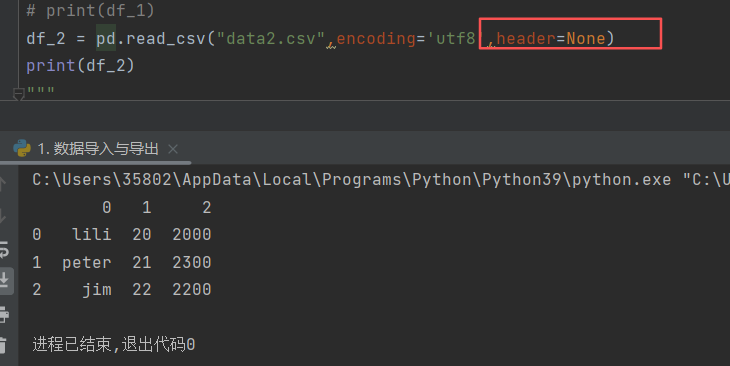
若所要读取的文件没有列名,则需要在括号中文件名的后面在加一个header=None
但不使用时默认header=True,代表文件中第一行的数据作为列名
当header=None时,列名输出和行名一样的数
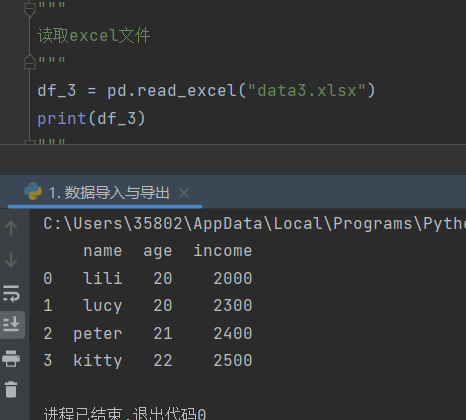
2)pandas.read_excel('文件名')
功能:读取excel文件
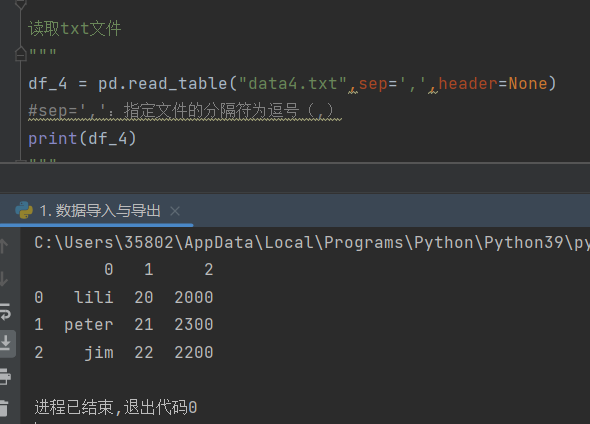
3)pandas.read_txt('文件名',sep=',',header=None)
功能:读取txt文件
sep=',',代表指定文件中的分隔符为逗号
4)导出文件
to_csv:导出csv文件
导出.csv:导出文件的文件名
index=True:导出时 包含DataFrame的索引(即行标签),默认值为True,若为False,则不导出行标签
导出excel文件也是类似的方法

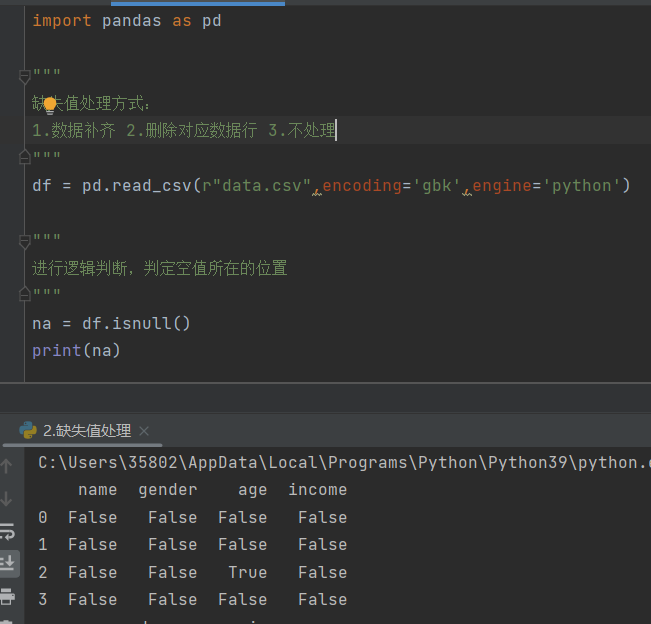
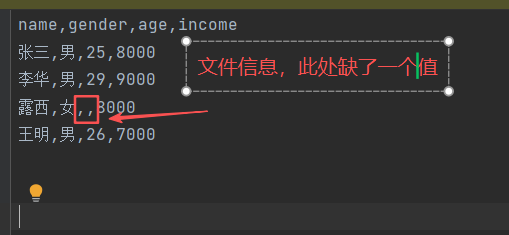
6、缺失值处理
1)isnull()
功能:判断读取文件中空值的位置,若是空值输出True,否则输出False
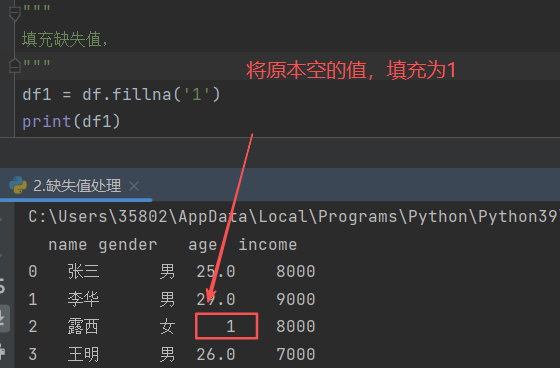
2)fillna()
功能:进行缺失值的填充(只能将所有的缺失值都填充为同一个数)
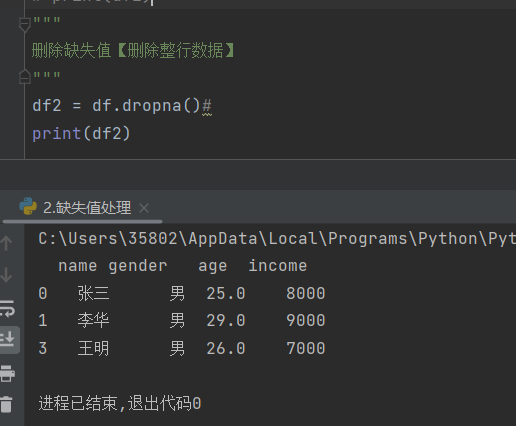
3)dropna()
功能:删除缺失值所在的整行数据
7、重复值处理
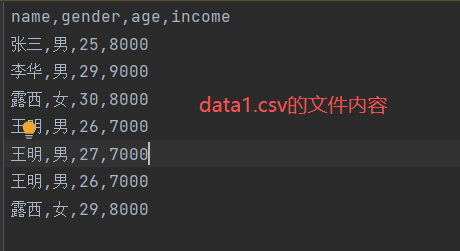
1)duplicated()
功能:找到重复的位置
若重复输出True,否则输出False
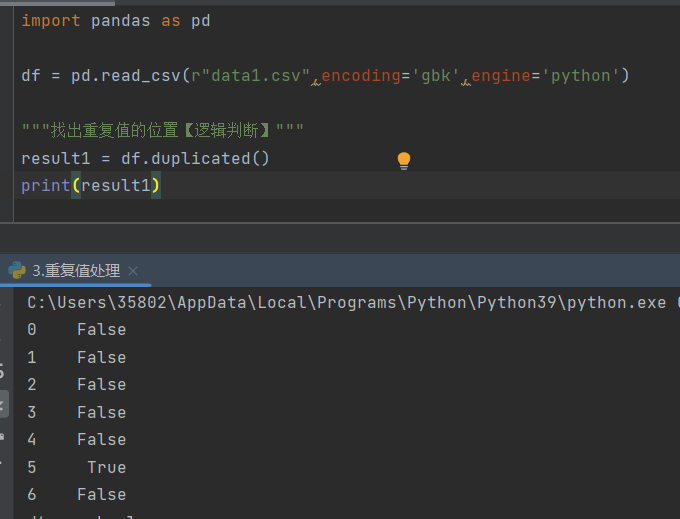
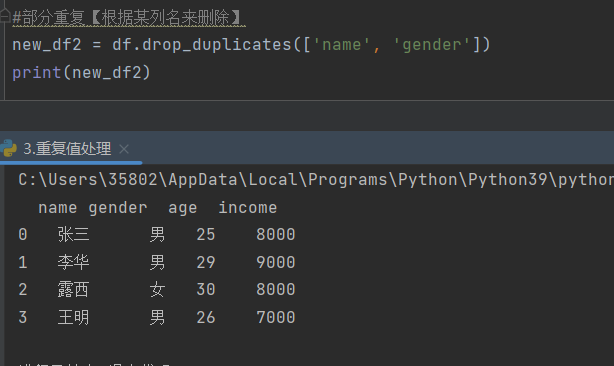
2)duplicated('参数1','参数2',......)
功能:根据文件中的列名来判断是否重复
参数:文件中所存在的列名
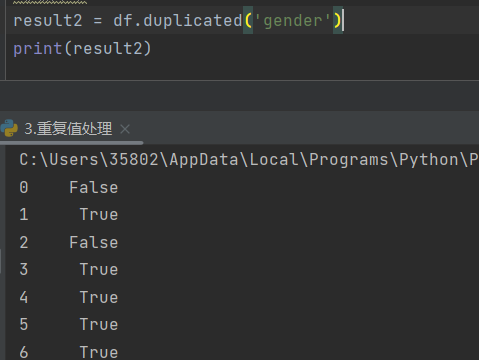
3)提取重复行的信息
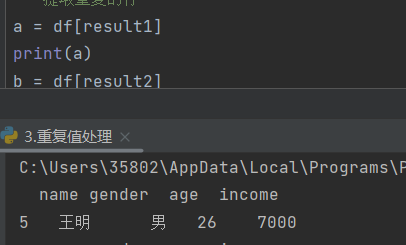
通过bool提取内容(提取输入为True的整行数据)
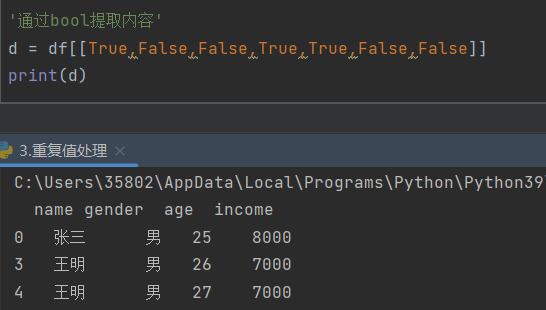
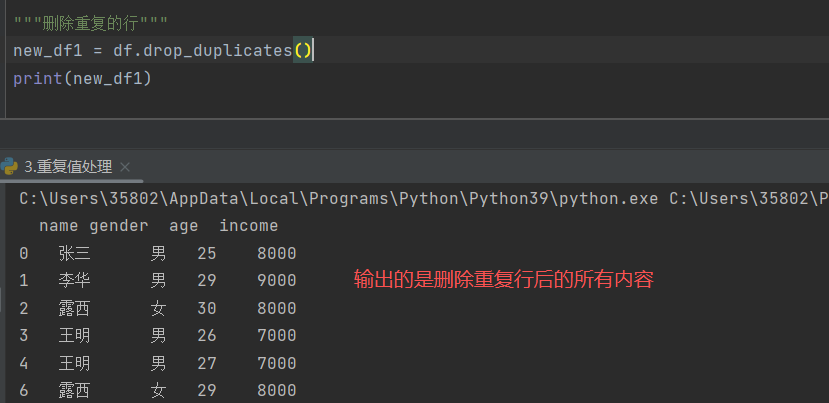
4)删除重复的行
8、数据抽取
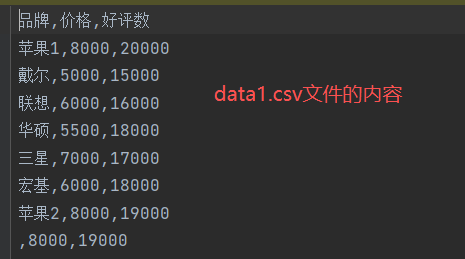
1)df'列名'
df:读取文件后将文件存放到的地方
列名:所读取文件中所存在的列名,即第一行的信息
想要选取一定范围内的可以在后面加上一定条件,如df'好评数' > 17000,则选取df中好评数大于17000的信息
**注:**选取后输出的结果是布尔值,只有True和False,若为True则是要选取的数据,为False则不是
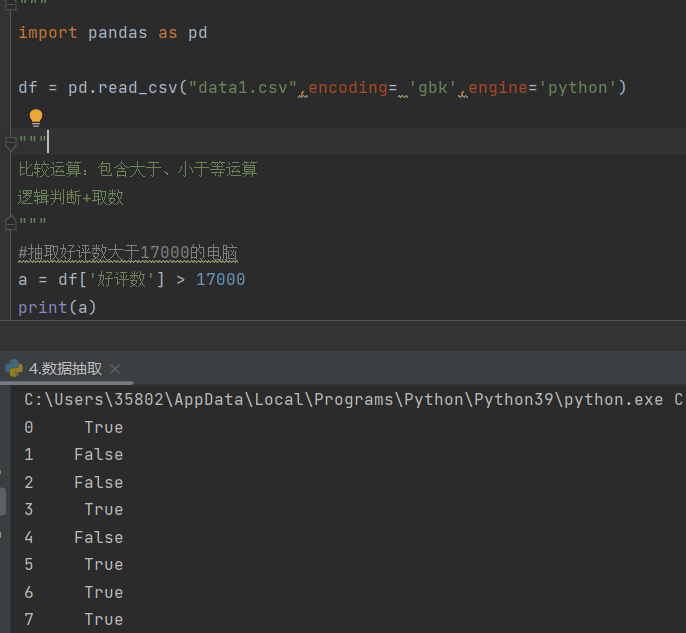
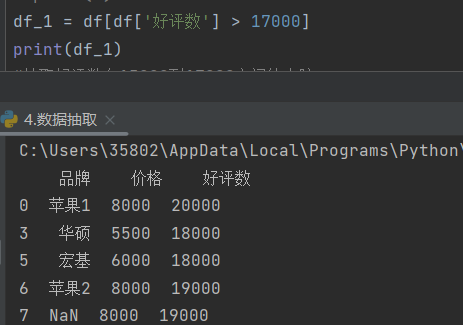
df_1 = dfdf\['好评数' > 17000]
若在df 中选取数据,则直接输出符合条件的所有信息,而不是输出布尔值
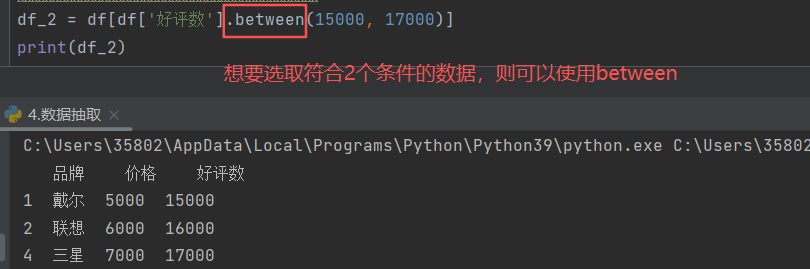
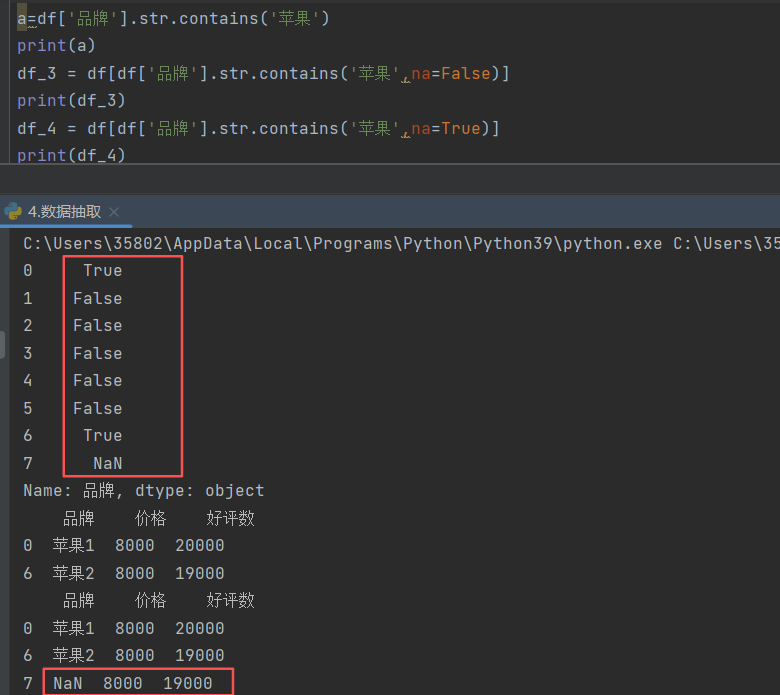
2)str.contains('参数',na=False)
df'第一行列名'.str.contains('参数'):对第一列每一个元素进行匹配,若存在输出True,不存在输出False,若此处为确实值,输出NaN
na=False,若存在na,且等于False,输出具体的内容,但不输出缺失项的信息,若等于True,则连缺失行内容一起输出
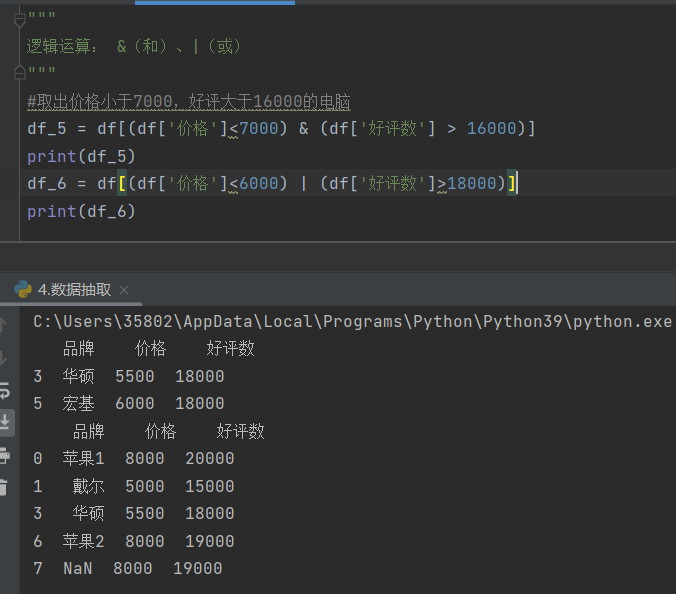
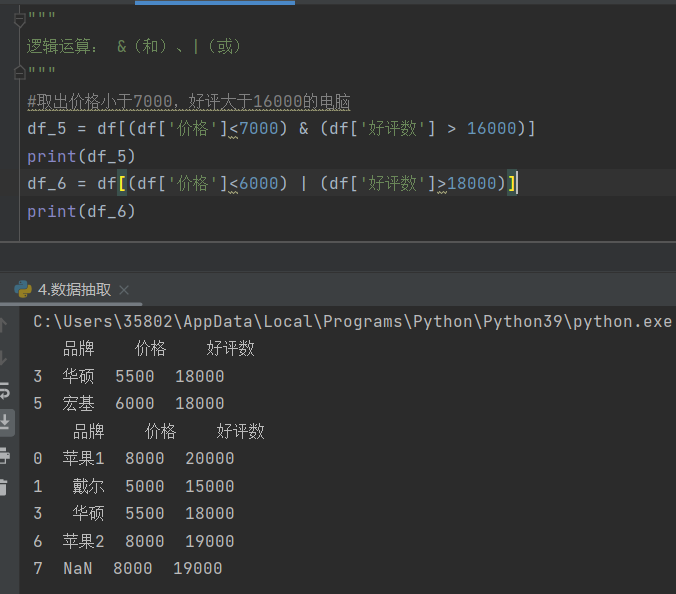
3)逻辑运算:&(和)、|(或)
9、数据框的合并
concat()函数:
使用方式:concat(df1,df2,df3...)
python
import pandas as pd
import numpy as np
df_1 = pd.DataFrame(np.arange(12).reshape(3,4))
df_2 = 2*df_1
#竖向合并
new_df1 = pd.concat([df_2, df_1])
#横向合并
new_df2 = pd.concat([df_1, df_2], axis=1)
"""
join参数 inner:表示交集 outer:表示并集
"""
df_3 = pd.DataFrame(np.arange(12).reshape(3,4),
index=['A', 'B', 2])
new_df3 = pd.concat([df_1, df_3], axis=1, join='inner')
new_df4 = pd.concat([df_1, df_3], axis=1, join='outer')