目录
-
- 一、算力管理的行业痛点与openFuyao的技术定位
-
- [1.1 行业核心痛点解析](#1.1 行业核心痛点解析)
- [1.2 openFuyao的技术定位与核心价值](#1.2 openFuyao的技术定位与核心价值)
- 二、openFuyao多样化算力资源池化技术
-
- [2.1 资源池化架构:分层设计,弹性伸缩](#2.1 资源池化架构:分层设计,弹性伸缩)
- [2.2 资源监控与可视化:全链路可观测](#2.2 资源监控与可视化:全链路可观测)
- 三、openFuyao算力调度总体方案:智能协同,极致释放
-
- [3.1 调度架构设计:三级调度协同体系](#3.1 调度架构设计:三级调度协同体系)
- [3.2 核心调度策略:多场景智能适配](#3.2 核心调度策略:多场景智能适配)
- [3.3 调度执行流程:全链路自动化](#3.3 调度执行流程:全链路自动化)
- 四、技术优势与产业实践:数据见证价值
-
- [4.1 核心技术优势量化](#4.1 核心技术优势量化)
- [4.2 典型产业实践案例](#4.2 典型产业实践案例)
- 五、总结与展望:共建多样化算力生态
在" 云原生+AI原生 "双轮驱动的技术时代,算力已成为数字经济的核心生产要素。硬件厂商不断推出CPU、GPU、NPU、DPU等多样化算力硬件,互联网算力平台持续扩容集群规模,但异构算力协同困难、资源利用率低下、调度响应滞后等问题始终制约着算力价值的充分释放。

openFuyao作为面向通算和智算集群的开源社区,以"多样化算力极致释放"为核心目标,构建了完善的算力池化共管与智能调度体系,为硬件厂商、互联网算力平台等团队开发者提供了一站式算力使能解决方案,重新定义了异构环境下的算力管理范式。

下面我将深度解析openFuyao的多样化算力 资源池化技术、全场景调度总体方案,结合架构设计与代码示例,全面展现其在算力释放领域的技术突破与产业价值,为开发者提供可落地的技术参考与实践指南。
一、算力管理的行业痛点与openFuyao的技术定位
随着AI大模型训练、大数据分析、金融交易等场景的爆发式增长,算力需求呈现出"异构化、规模化、动态化"三大特征。但当前算力管理体系面临着多重行业痛点,严重制约了硬件性能的有效释放。
1.1 行业核心痛点解析
- 异构算力协同壁垒:CPU、GPU、NPU、DPU等xPU硬件架构差异显著,缺乏统一的资源抽象与管理标准,导致"硬件孤岛"现象普遍,多类型算力难以协同调度。
- 资源利用率两极分化:在线业务为保障稳定性预留大量冗余资源,峰值利用率不足30%;离线业务却面临资源短缺,而传统静态分配模式无法实现资源动态流转。
- 调度机制适配不足:众核高密(256核及以上)场景下锁竞争激增,同类业务集中部署导致节点过热;时延敏感型业务与吞吐量优先型业务混部时,缺乏细粒度的优先级保障机制。
- 集群运维复杂度高:超大规模集群(万节点级)的部署、升级、监控难度呈指数级增长,传统方案难以兼顾调度性能与运维效率。
1.2 openFuyao的技术定位与核心价值
openFuyao基于Kubernetes深度优化,采用"核心平台+可插拔组件"架构,聚焦多样化算力的池化管理与智能调度,构建了"硬件抽象-资源池化-智能调度-性能加速"的全链路技术体系。其核心价值体现在三个维度:
- 对硬件厂商:提供标准化的硬件适配框架,通过Operator机制实现xPU资源秒级可用,降低硬件生态适配成本,提升硬件产品的场景化竞争力。
- 对互联网算力平台:支持万节点级集群的高性能调度与在离线混部,资源利用率提升40%以上,同时保障在线业务QPS下降不超过5%,实现算力成本与服务质量的最优平衡。
- 对开发者:提供模块化、轻量化的技术方案,支持分钟级一键部署与小时级版本迭代,将传统"月级"开发周期大幅压缩,降低算力管理系统的开发与运维门槛。
openFuyao的技术演进始终围绕"算力极致释放"展开,从异构资源池化到智能调度优化,从单机性能调优到超大规模集群协同,形成了覆盖全场景、全链路的算力使能能力。
二、openFuyao多样化算力资源池化技术
2.1 资源池化架构:分层设计,弹性伸缩
openFuyao采用"全局资源池+局部资源池"的分层池化架构,既保障了跨节点、跨集群的算力协同,又实现了单机内资源的精细化管理。
池化架构总体设计
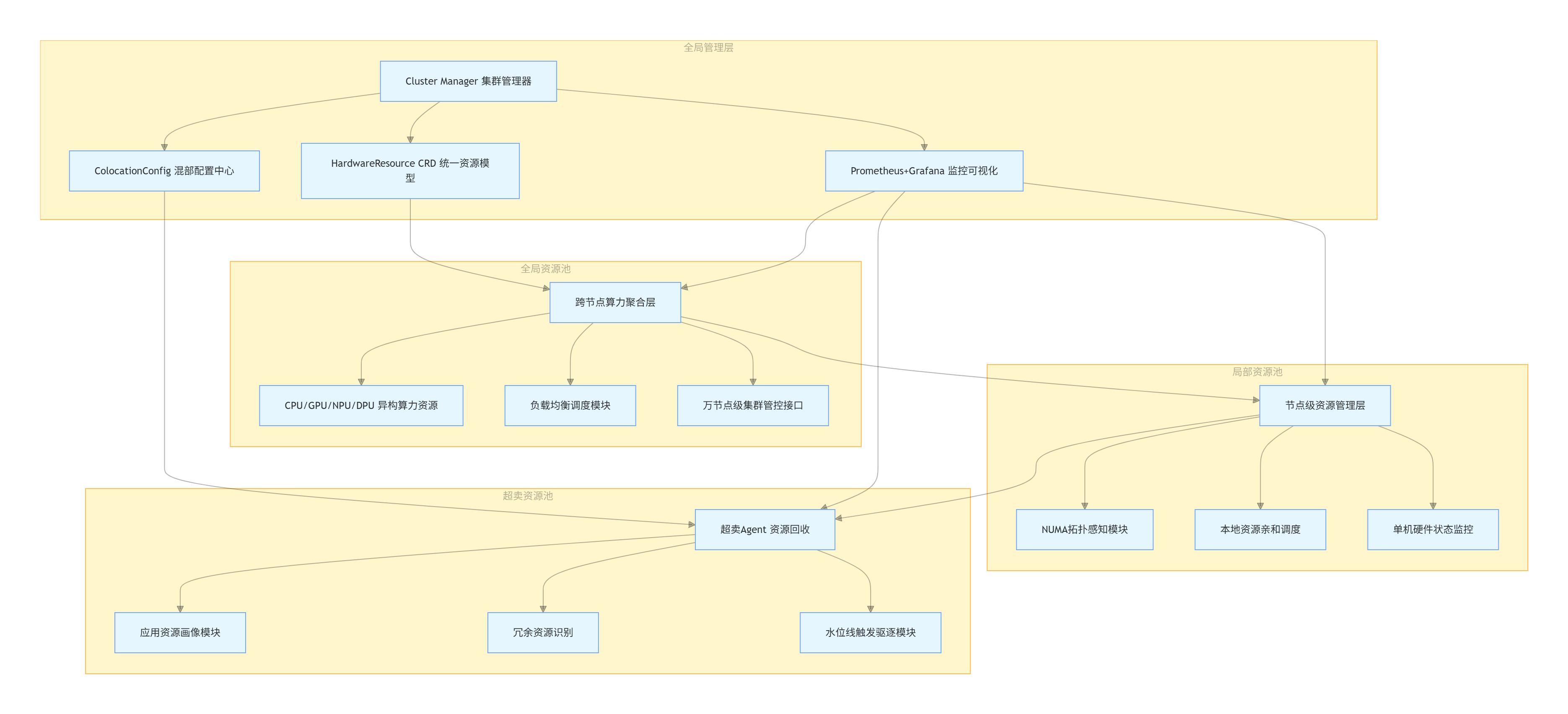
- 全局资源池:以集群为单位,聚合所有节点的异构算力资源,提供跨节点的资源调度与负载均衡能力,支持万节点级集群的统一管控。
- 局部资源池:以节点为单位,基于NUMA拓扑构建本地资源池,实现CPU、内存、xPU资源的本地化亲和调度,降低跨NUMA节点的数据传输时延。
- 超卖资源池:通过资源画像技术识别已分配但未使用的冗余资源,构建超卖资源池,供离线业务在空闲时段使用,提升整体资源利用率。
超卖资源池化实现原理
超卖资源池是openFuyao提升资源利用率的核心创新,其实现依赖于精准的资源画像与动态回收机制:
- 超卖Agent以DaemonSet形式部署在每个节点,通过histograms统计工作负载的CPU、内存使用情况,构建应用资源画像;
- 基于资源画像预测Pod的实际资源需求,识别出"分配过量"的冗余资源(如Pod请求8核CPU但实际平均使用率仅30%);
- 超卖Agent将冗余资源回收并上报至全局管理面,更新超卖资源池的可分配容量;
- 当在线业务出现流量峰值时,通过水位线监测触发离线业务驱逐,将超卖资源快速归还给在线业务,保障服务质量。
以下是超卖资源池配置的核心代码示例,通过全局配置面定义超卖策略:
plain
apiVersion: fuyao.io/v1alpha1
kind: ColocationConfig
metadata:
name: overcommit-config
namespace: kube-system
spec:
overcommit:
enabled: true
cpuOvercommitRatio: 1.8 # CPU超卖比例
memoryOvercommitRatio: 1.5 # 内存超卖比例
evictionThresholds: # 驱逐水位线
cpuUsage: 85% # CPU使用率达到85%触发驱逐
memoryUsage: 90% # 内存使用率达到90%触发驱逐
psiStall: 50ms # PSI干扰检测阈值
nodeSelector:
fuyao.io/colocation-node: "true" # 仅在混部节点启用超卖通过这一机制,openFuyao在保障在线业务稳定性的前提下,将集群CPU与内存利用率提升40%以上,实现了算力资源的"物尽其用"。
2.2 资源监控与可视化:全链路可观测
算力池化的高效运行离不开实时、全面的资源监控。openFuyao构建了"节点-硬件-容器-任务"四级监控体系,通过Prometheus+Grafana实现监控数据的采集、存储与可视化。
监控指标体系
openFuyao扩展了Kubernetes的监控指标,新增了异构硬件专属指标与池化资源调度指标,核心指标包括:
- 硬件层指标:CPU/GPU/NPU的使用率、温度、功耗、访存带宽、设备健康状态;
- 资源池指标:全局/局部资源池的总容量、已分配容量、空闲容量、超卖资源量;
- 调度层指标:调度延迟、调度成功率、任务抢占次数、离线业务驱逐次数;
- 业务层指标:在线业务的时延、QPS、错误率,离线业务的吞吐量、完成率。
可视化管理界面
openFuyao提供了colocation-website可视化管理组件,支持混部统计、节点管理、调度配置等功能的可视化操作。开发者可通过界面实时查看算力资源池的运行状态,调整超卖比例、驱逐水位线等关键参数,实现资源池的精细化管控。
三、openFuyao算力调度总体方案:智能协同,极致释放
如果说算力池化是"聚沙成塔",那么算力调度就是"分沙筑楼"。openFuyao构建了"多级调度协同、多策略智能适配、多场景深度优化"的调度体系,实现了多样化算力的动态分配与高效利用,满足不同业务的差异化需求。
3.1 调度架构设计:三级调度协同体系
openFuyao采用"集群层调度-节点层调度-硬件层调度"的三级协同架构,每层调度各司其职又相互配合,实现了从全局负载均衡到本地资源优化的全链路调度能力。
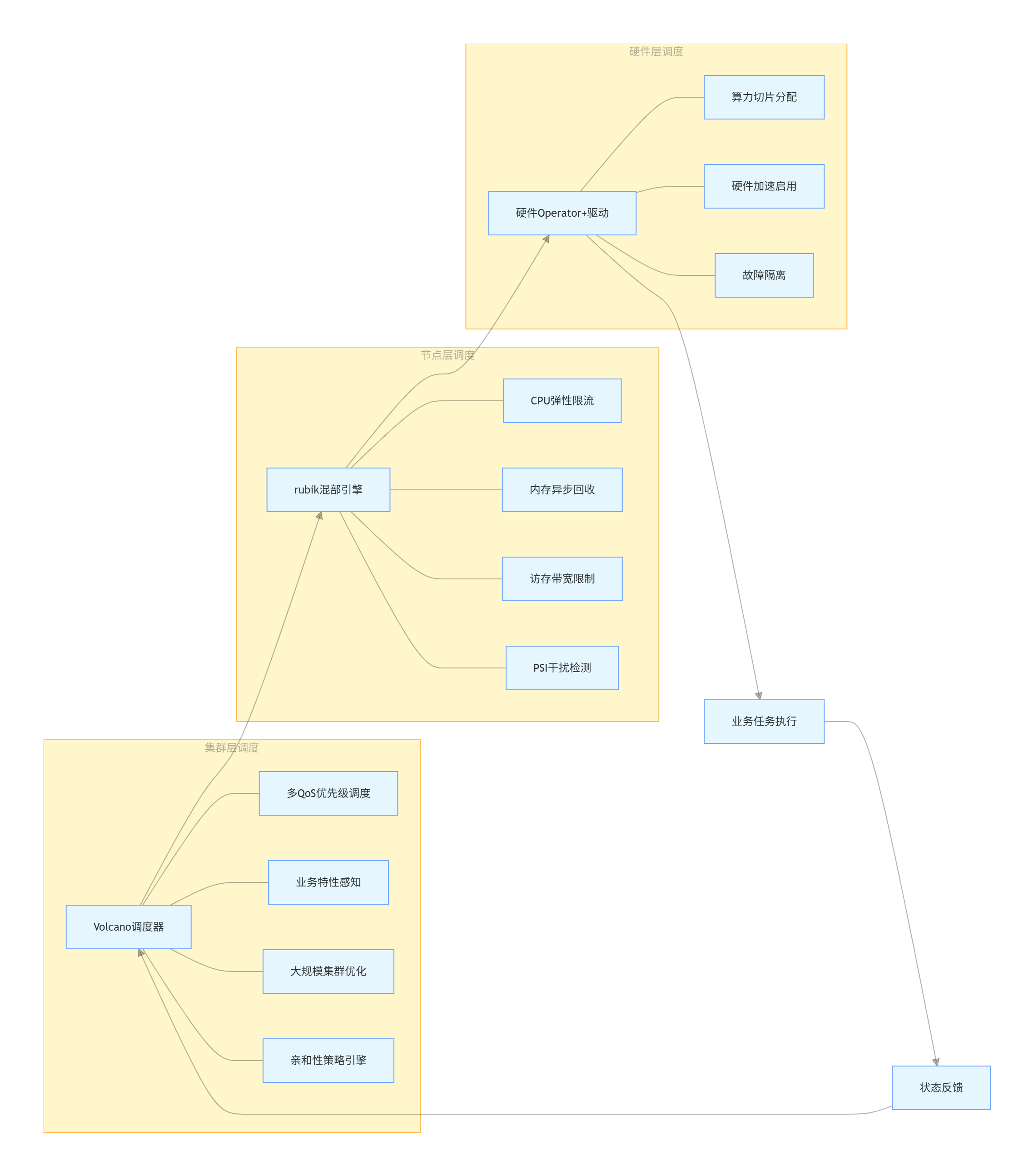
集群层调度 :全局负载均衡
集群层调度基于Volcano调度器深度优化,负责跨节点的任务分配与负载均衡,核心能力包括:
- 多QoS优先级调度:支持HLS(高时延敏感)、LS(时延敏感)、BE(尽力而为)三级QoS分级,高优先级任务可抢占低优先级资源,保障核心业务稳定性;
- 业务特性感知调度:感知任务类型(IO密集型、内存敏感型、算力敏感型),避免同类业务集中部署在同一节点,降低资源竞争;
- 大规模集群调度优化:支持万节点级集群的实时调度,通过调度队列优化与并行计算,将调度延迟控制在微秒级;
- 亲和性调度:支持NUMA亲和、硬件亲和、节点亲和等多种亲和性策略,提升任务与硬件的匹配度。
节点层调度:本地资源精细化管理
节点层调度通过rubik混部引擎实现,负责单机内资源的动态调整与隔离,核心能力包括:
- CPU弹性限流:基于cgroup技术实现CPU资源的动态分配,限制离线业务对在线业务的CPU抢占;
- 内存异步回收:针对内存敏感型业务,实现空闲内存的异步回收与再分配,避免内存溢出;
- 访存带宽限制:通过内核接口限制离线业务的访存带宽,保障在线业务的访存性能;
- PSI干扰检测:实时监测业务间的资源干扰,当干扰超过阈值时触发资源调整。
硬件层调度:异构算力专属优化
硬件层调度通过Operator与硬件驱动协同,实现异构算力的高效利用,核心能力包括:
- 算力切片:支持GPU/NPU等算力硬件的切片分配,将单卡算力拆分为多个逻辑算力单元,满足小规模任务的资源需求;
- 硬件加速特性启用:根据任务类型自动启用硬件的专属加速特性(如GPU的Tensor Core、NPU的AI加速指令);
- 硬件故障隔离:当硬件出现故障时,快速隔离故障资源,将任务调度至其他可用硬件,保障业务连续性。
3.2 核心调度策略:多场景智能适配
openFuyao针对不同业务场景设计了差异化的调度策略,通过策略动态选择机制,实现"业务类型-调度策略-硬件能力"的最优匹配。
三级QoS调度策略
openFuyao定义了HLS、LS、BE三级QoS模型,覆盖高要求在线业务、普通在线业务、离线业务三大场景,其核心特性与调度规则如下表所示:
| QoS级别 | 核心特点 | 适用场景 | 调度规则 | 对应K8s QoS |
|---|---|---|---|---|
| HLS(高时延敏感) | 时延、稳定性严格要求,不超卖,预留资源 | 金融交易、核心微服务 | 绑核部署,优先级最高,可抢占其他级别资源 | Guaranteed |
| LS(时延敏感) | 共享资源,支持突发流量弹性 | 普通微服务、API网关 | NUMA亲和调度,优先级中等,可被HLS抢占 | Guaranteed/Burstable |
| BE(尽力而为) | 共享超卖资源,允许被驱逐 | 大数据分析、模型训练 | 仅使用超卖资源,优先级最低,触发水位线时被驱逐 | BestEffort |
三级QoS调度的核心实现逻辑是通过PriorityClass绑定不同QoS级别的任务,在调度队列层按照优先级排序,同时通过准入控制校验资源请求的合理性。以下是QoS级别配置的代码示例:
plain
# HLS级任务配置
apiVersion: v1
kind: Pod
metadata:
name: financial-transaction-pod
annotations:
fuyao.io/qos-level: "HLS" # 标记QoS级别
spec:
containers:
- name: transaction-service
image: financial/transaction:v1.0
resources:
requests:
cpu: 4
memory: 8Gi
limits:
cpu: 4 # requests与limits相等,确保Guaranteed类型
memory: 8Gi
schedulerName: volcano-scheduler # 使用混部调度器
---
# BE级任务配置
apiVersion: v1
kind: Pod
metadata:
name: data-analysis-pod
annotations:
fuyao.io/qos-level: "BE" # 标记QoS级别
spec:
containers:
- name: analysis-worker
image: data/analysis:v1.0
resources:
requests:
cpu: 2
memory: 4Gi
schedulerName: volcano-scheduler
tolerations:
- key: "fuyao.io/overcommit"
operator: "Exists"
effect: "NoSchedule" # 容忍超卖资源调度通过这一配置,HLS级的金融交易任务将获得CPU绑核部署和最高优先级调度,而BE级的数据分析任务仅使用超卖资源,在在线业务峰值时会被自动驱逐,保障核心业务的稳定性。
众核高密调度策略
针对256核及以上的众核高密场景,openFuyao推出了集群层众核调度策略,解决了传统调度方案中锁竞争激增、部署密度不足的问题。其核心优化点包括:
- 众核拓扑感知:通过节点Agent采集CPU拓扑信息(核心数、NUMA节点、缓存层级),构建全局拓扑视图;
- 业务类型分散部署:识别IO密集、内存敏感、算力敏感等业务类型,通过调度算法将不同类型业务分散部署在不同NUMA节点,降低资源竞争;
- 部署密度优化:优化Pod资源调配策略,减少锁竞争和资源碎片,提升容器部署密度10%。
众核高密调度的实现依赖于Volcano调度器的自定义调度插件,以下是插件配置的核心代码示例:
plain
// 众核高密调度插件核心逻辑
func (p *ManyCoreSchedulerPlugin) Score(node *v1.Node, pod *v1.Pod) (int32, error) {
// 1. 获取节点众核拓扑信息
nodeTopology, err := p.getNodeManyCoreTopology(node.Name)
if err != nil {
return 0, err
}
// 2. 识别Pod业务类型
podType := getPodBusinessType(pod) // IO/内存/算力敏感型
// 3. 计算节点上同类型业务的部署密度
sameTypePodCount := p.countSameTypePods(node.Name, podType)
// 4. 基于拓扑信息和业务密度打分,同类型业务越少得分越高
score := calculateScore(nodeTopology, sameTypePodCount, pod.Resources.Requests)
return score, nil
}通过这一插件,调度器在选择节点时会优先考虑同类型业务部署较少的节点,同时结合NUMA拓扑优化资源分配,实现众核高密场景下的高效调度。
NUMA亲和调度策略
针对金融、AI等对时延敏感的场景,openFuyao提供了NUMA亲和调度策略,通过优化CPU、内存、xPU的本地化部署,降低跨NUMA节点的数据传输时延。其核心实现逻辑是:
- 节点Agent采集NUMA拓扑信息,包括每个NUMA节点的CPU核心、内存、PCIe设备分布;
- 调度器根据Pod的资源请求和NUMA拓扑信息,选择最优NUMA节点;
- 通过cgroup配置CPU亲和性和内存绑定,确保Pod的CPU核心、内存、xPU设备位于同一NUMA节点。
中国工商银行基于openFuyao的NUMA亲和调度策略,打造了金融级高性能容器引擎,通过集群级+节点级的双重优化,显著降低了金融交易的响应时延,满足了"极致稳定、时延敏感"的业务需求。
3.3 调度执行流程:全链路自动化
openFuyao的算力调度流程涵盖任务提交、调度决策、资源分配、运行时调整、任务完成五大阶段,全链路自动化执行,无需人工干预。其详细流程如下:
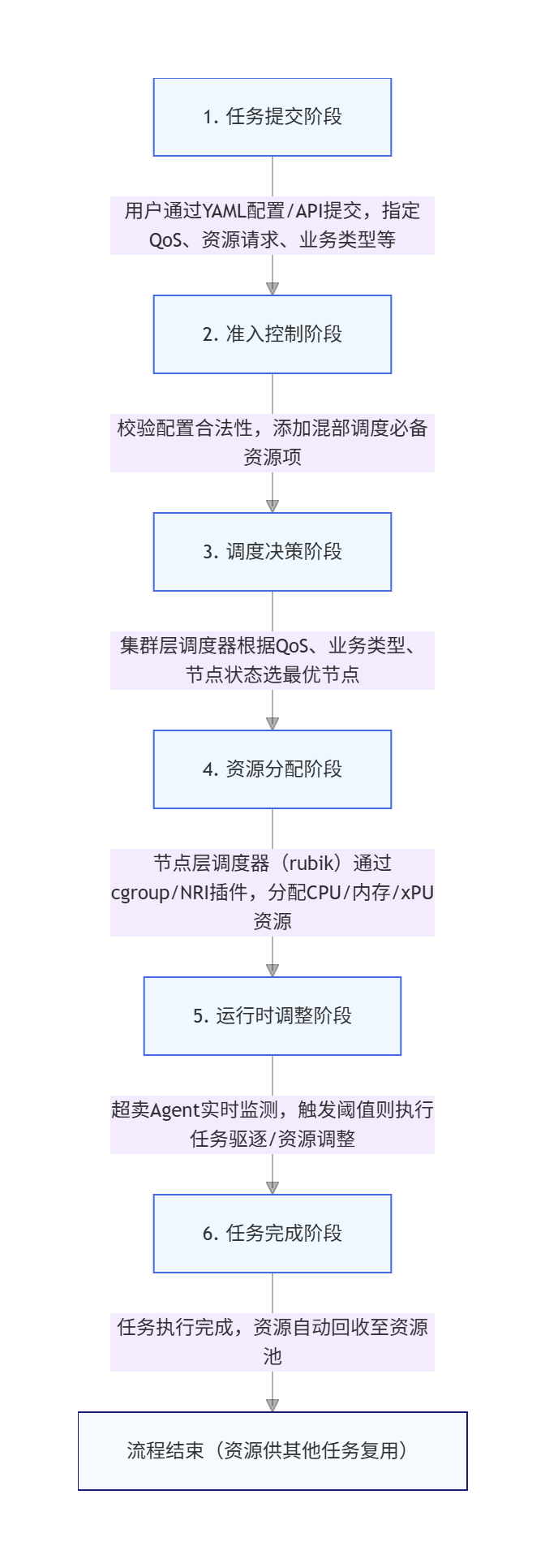
这一全链路自动化流程,确保了调度决策的实时性、准确性和执行效率,实现了算力资源的动态流转与高效利用。
四、技术优势与产业实践:数据见证价值
openFuyao的多样化算力使能技术已在金融、互联网、AI等多个行业落地应用,其技术优势通过实测数据和产业实践得到了充分验证。
4.1 核心技术优势量化
openFuyao通过池化技术与调度优化的深度融合,实现了多项关键指标的突破:
- 资源利用率:在离线混部场景下,CPU与内存利用率提升40%以上,超卖资源池贡献了30%的额外算力;
- 调度性能:支持万节点级集群调度,调度延迟低至微秒级,任务调度成功率达99.99%;
- 业务稳定性:在线业务QPS下降不超过5%,时延波动控制在10%以内,满足高敏感业务需求;
- 部署效率:Cluster-API优化后,集群安装部署耗时缩减40%,支持分钟级一键部署;
- 硬件适配:兼容CPU、GPU、NPU、DPU等多种异构硬件,支持openEuler系列操作系统,适配范围广泛。
这些量化指标充分证明了openFuyao在算力释放、调度性能、部署效率等方面的技术优势,为企业级生产环境提供了可靠的技术支撑。
4.2 典型产业实践案例
金融行业:高性能交易系统
某国有大行基于openFuyao构建了金融级高性能容器引擎,针对核心交易系统的"极致稳定、时延敏感"需求,采用NUMA亲和调度与HLS级QoS保障策略,实现了以下价值:
- 交易时延降低20%:通过NUMA拓扑优化,跨NUMA节点数据传输减少,核心交易平均时延从15ms降至12ms;
- 资源利用率提升35%:在保障交易稳定性的前提下,通过在离线混部将集群CPU利用率从45%提升至61%;
- 故障恢复时间缩短80%:借助openFuyao的故障隔离与自动调度能力,硬件故障导致的业务中断时间从分钟级降至秒级。
互联网行业:云原生算力平台
联通云基于openFuyao社区发行版,打造了新一代CSKTurbo云原生加速引擎,面向互联网客户提供弹性算力服务,实现了以下突破:
- 算力成本降低30%:通过超卖资源池与智能调度,将闲置资源转化为可用算力,降低了云平台的硬件采购成本;
- 业务部署效率提升5倍:支持分钟级集群部署与弹性伸缩,满足互联网业务"潮汐式"算力需求;
- 多租户隔离性保障:通过精细化资源隔离与QoS控制,确保不同租户的业务互不干扰,服务质量达标率99.9%。
AI行业:大模型训练平台
华鲲振宇基于openFuyao构建了天巡CubeX智擎平台,面向AI大模型训练与推理场景,实现了异构算力的高效协同:
- 模型训练效率提升40%:通过GPU/NPU异构调度与算力切片技术,充分利用各类硬件的加速能力;
- 百模管理标准化:统一的算力池化管理实现了多种大模型的标准化部署与调度,降低了模型运营复杂度;
- 资源弹性伸缩:根据训练任务的算力需求,自动扩缩容集群资源,避免资源浪费。
这些产业实践案例覆盖了不同行业的核心场景,充分验证了openFuyao在多样化算力使能方面的通用性与可靠性,为更多企业的算力管理升级提供了参考范式。
五、总结与展望:共建多样化算力生态
openFuyao是"云原生+AI原生"时代的多样化算力集群开源社区,核心优势在于统一抽象的池化架构与多场景适配的调度策略,为硬件厂商、互联网算力平台提供标准化接入、高效可靠的算力管理方案,打破异构算力壁垒,释放算力价值。

未来,openFuyao将聚焦三大方向:提升超大规模集群调度性能、深化AI原生调度能力、完善硬件生态适配。依托开源特性,华为、工行等核心成员共建技术标准与创新平台,开发者接入可降低研发成本、提升算力释放效率,在数字经济竞争中抢占先机。诚邀更多开发者加入社区,共推算力技术创新。