博主介绍:✌全网粉丝50W+,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业项目实战8年之久,选择我们就是选择放心、选择安心毕业✌
> 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、毕业设计:2026年计算机专业毕业设计选题汇总(建议收藏)✅
2、大数据毕业设计:2026年选题大全 深度学习 python语言 JAVA语言 hadoop和spark(建议收藏)✅
1、项目介绍
技术栈:
Python语言、Flask框架、MySQL数据库、Echarts可视化、requests爬虫、HTML、高德地图、数据分析
技术栈:
Python语言、Flask框架、MySQL数据库、Echarts可视化、requests爬虫、HTML、高德地图、数据分析
项目介绍
- 数据采集层:基于Python的requests库构建爬虫模块,定向爬取各城市地铁线路、站点名称、站点坐标等核心数据,同时补充城市大学数量等关联数据,爬取结果清洗后存入MySQL数据库,保障数据的完整性与时效性。
- 后端服务层:采用Flask框架搭建Web服务,封装数据查询、用户验证等接口,实现前端请求与数据库的高效交互,支撑多维度数据的快速提取与分析计算。
- 数据分析层:借助Pandas等工具完成文本分析(站点名称高频字统计、"门"字站点分析)、相关性分析(大学数量与地铁站点数量关联)等,挖掘地铁数据背后的规律与特征。
- 可视化展示层:整合Echarts可视化库与高德地图API,以柱状图、词云图、地图标记、散点图等形式,直观呈现地铁线路/站点数量分布、站点命名特征、城市分布等10类核心分析结果;同时设计登录界面,保障系统访问权限。
- 功能拓展层:支持手动触发数据采集任务,可定期更新数据源,满足地铁数据动态分析的需求。
2、项目界面
1 、地铁线路数量分布
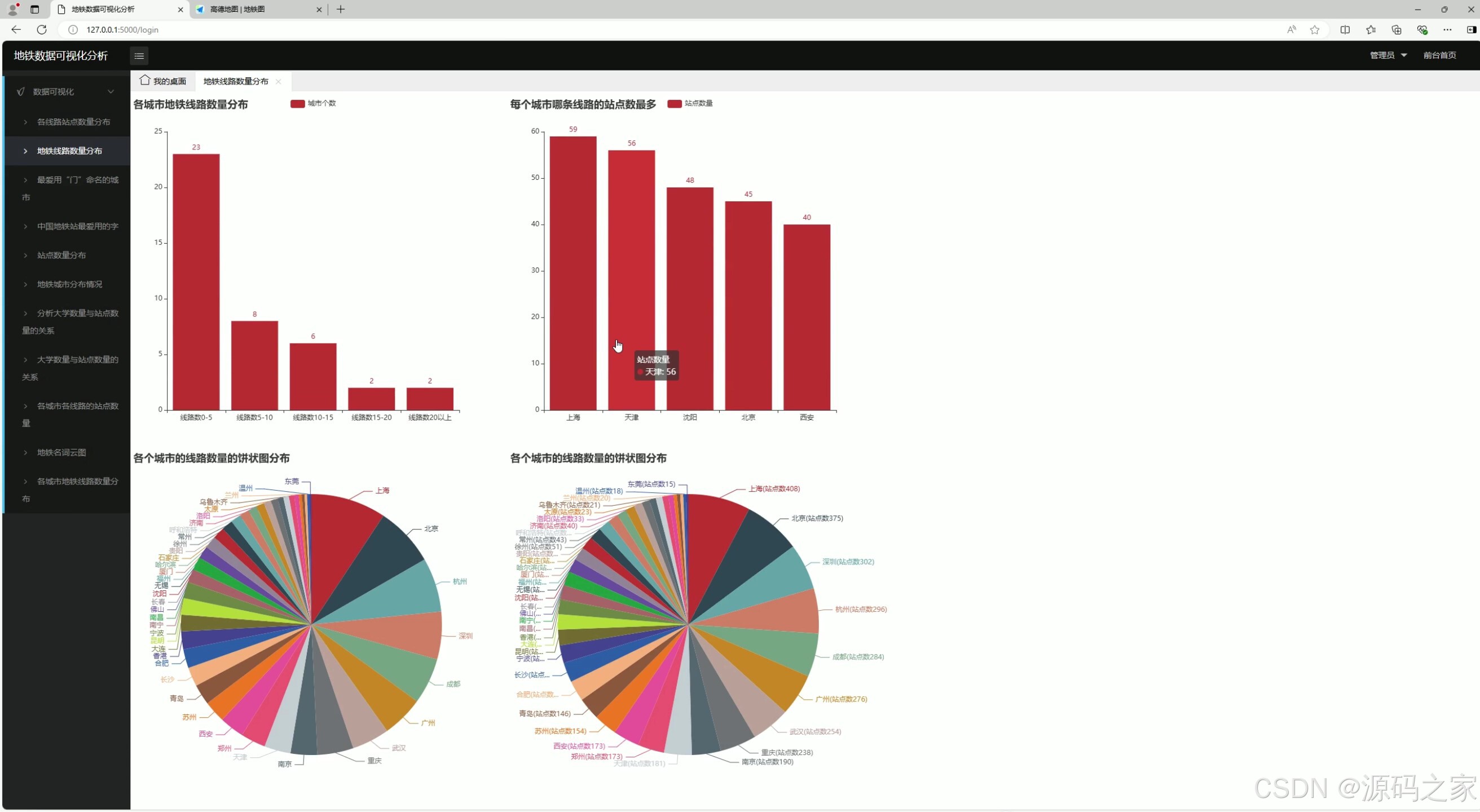
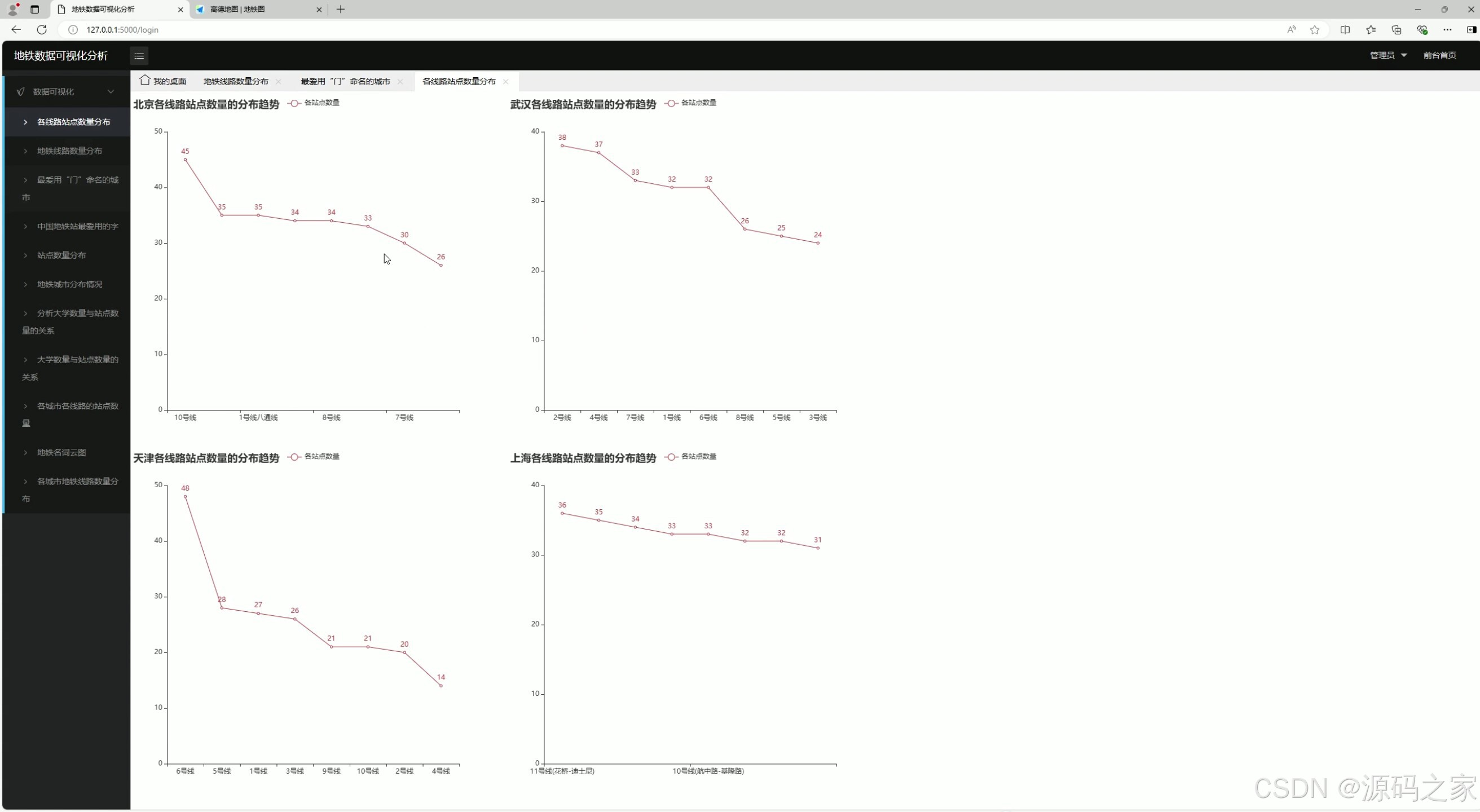
2、各线路站点数量分布
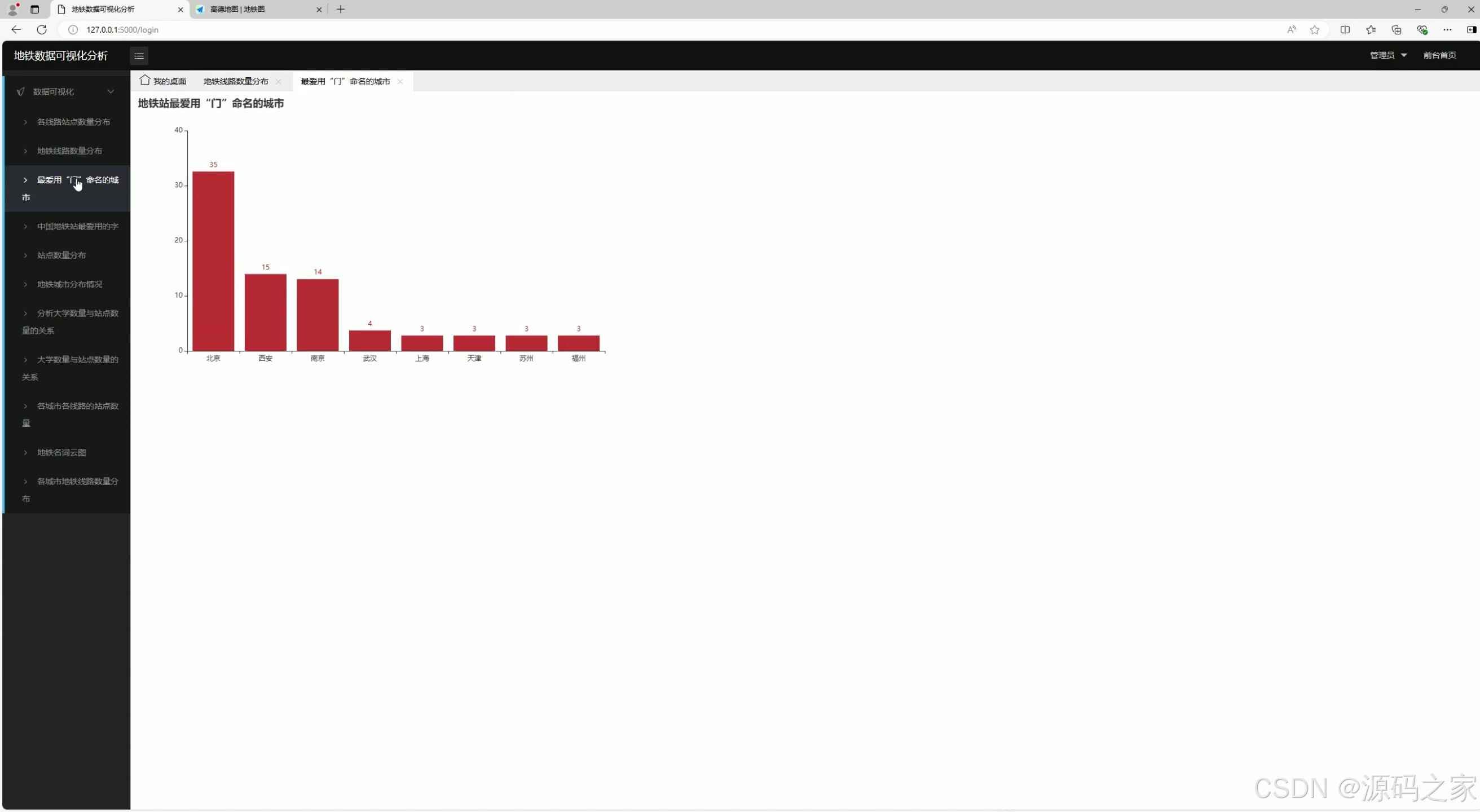
3、最爱用【门】命名的城市
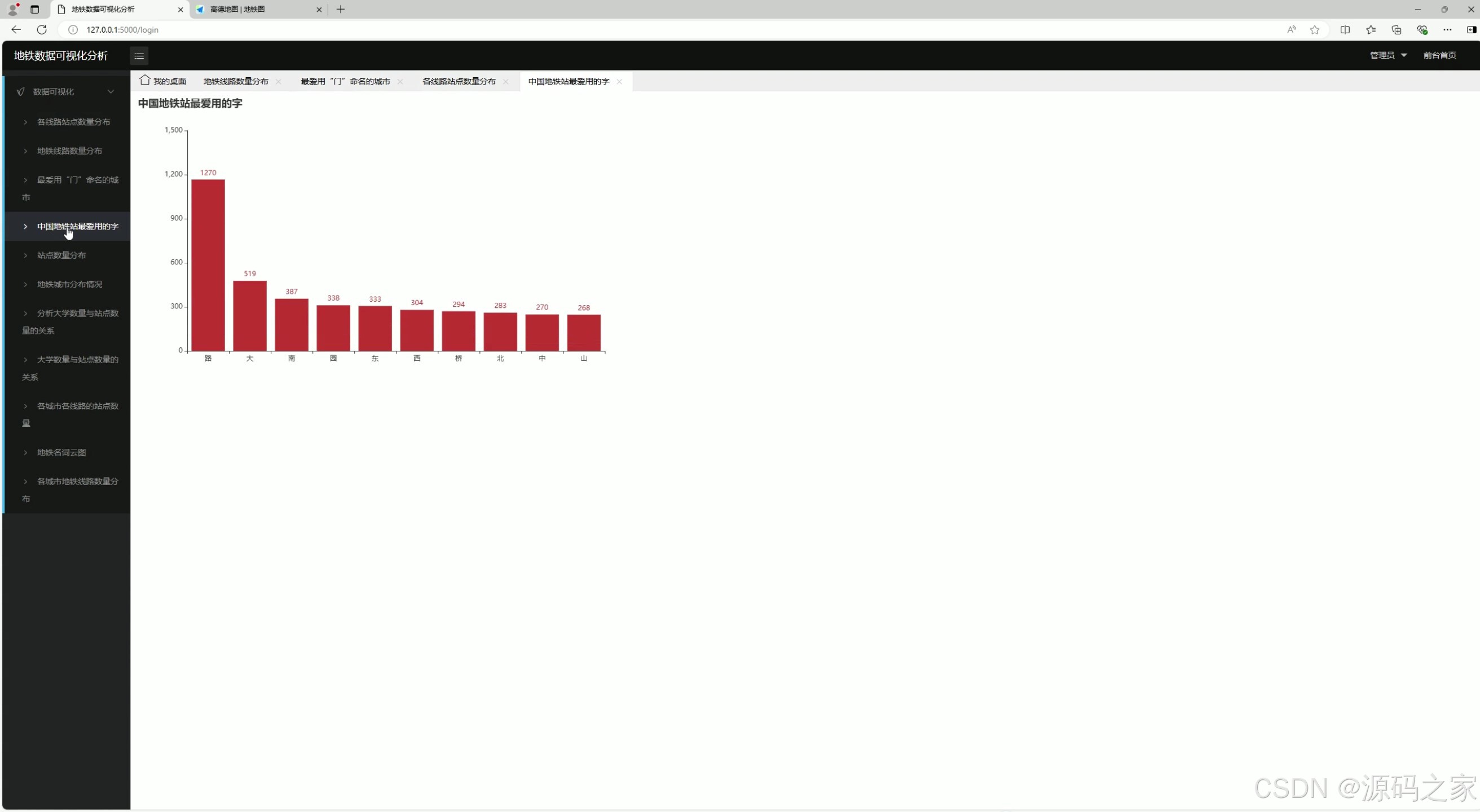
4、地铁站最爱用的字排行
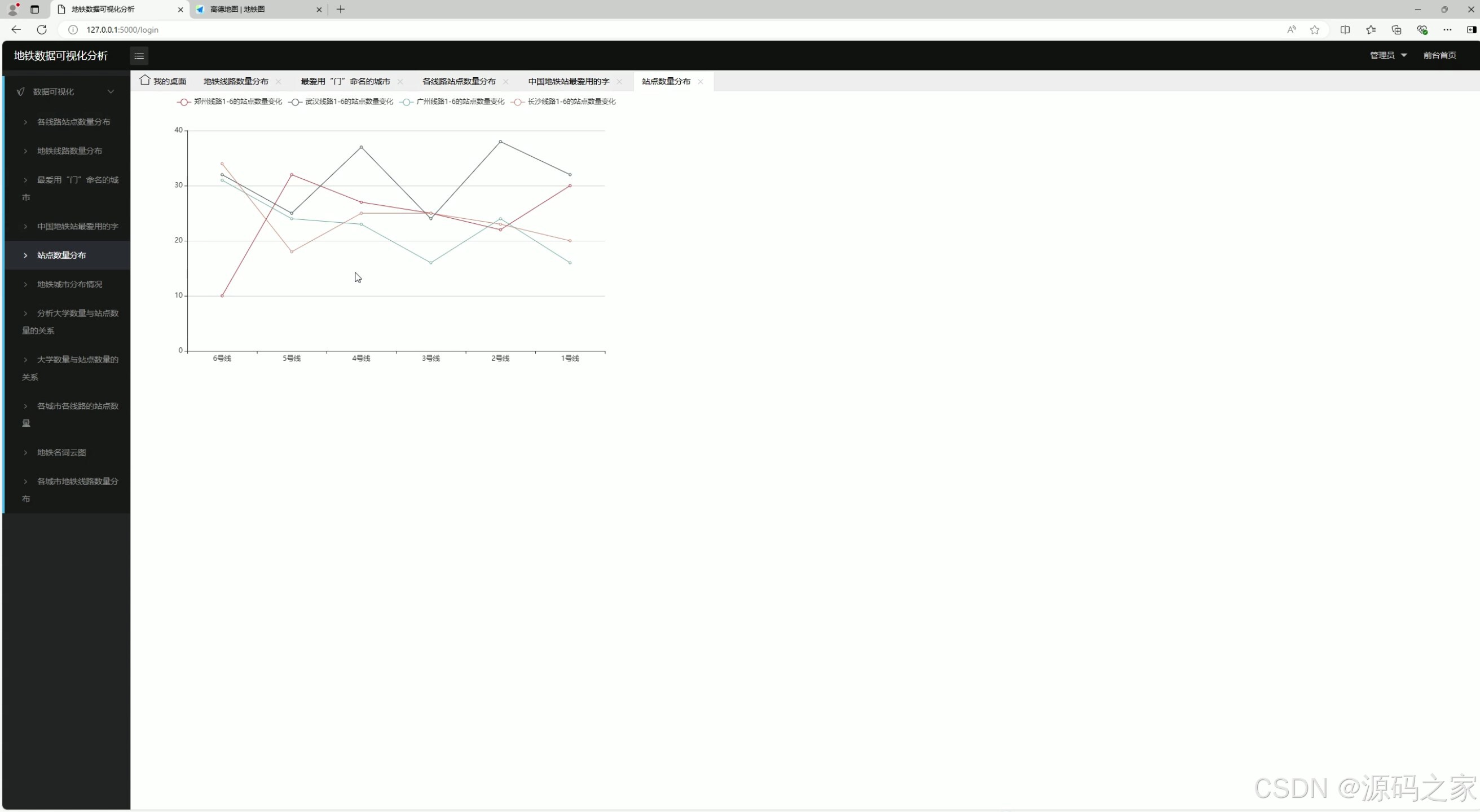
5、站点数量分布
6、各城市分布地图
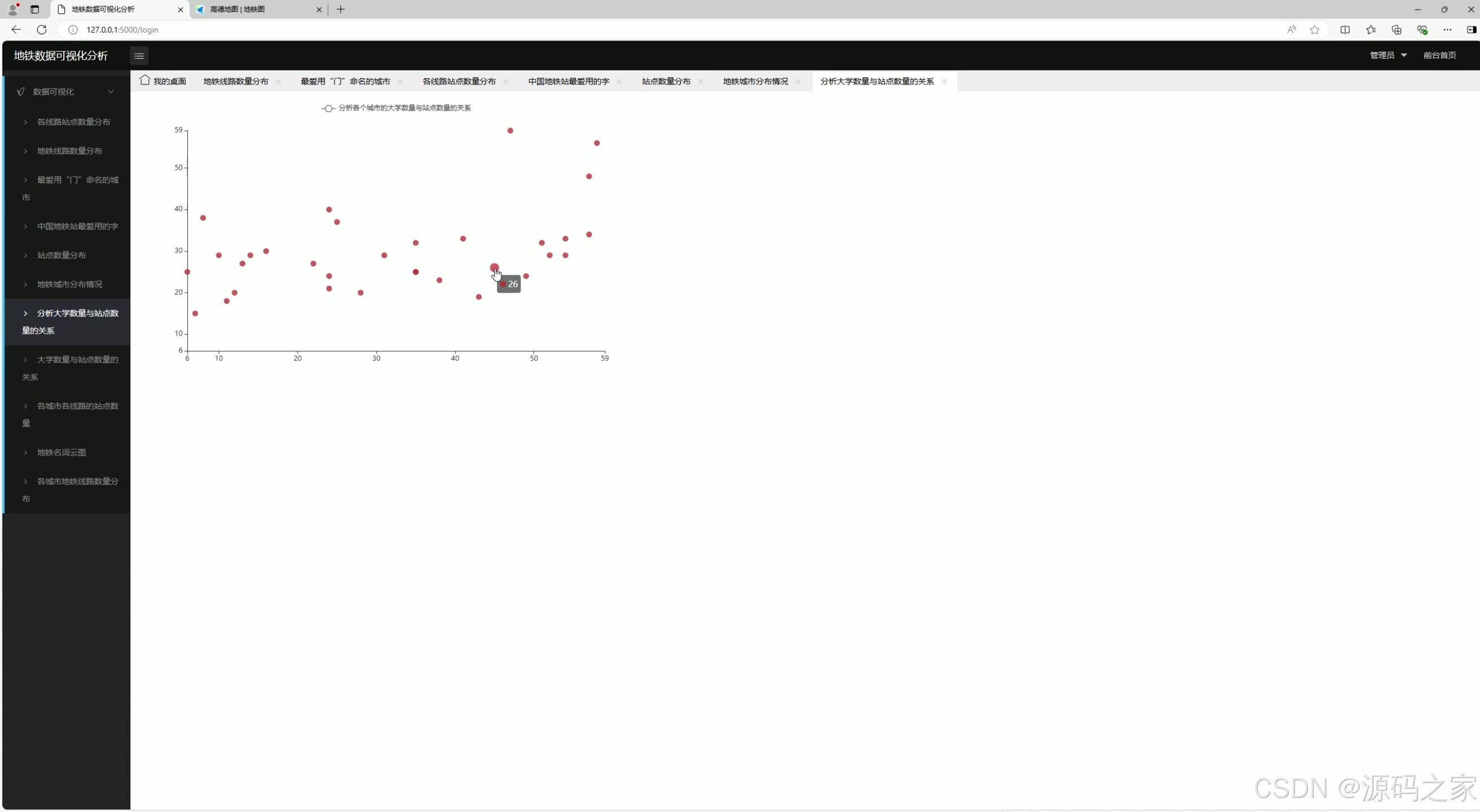
7、大学数量与站点数量的关系
8、各城市各站点数量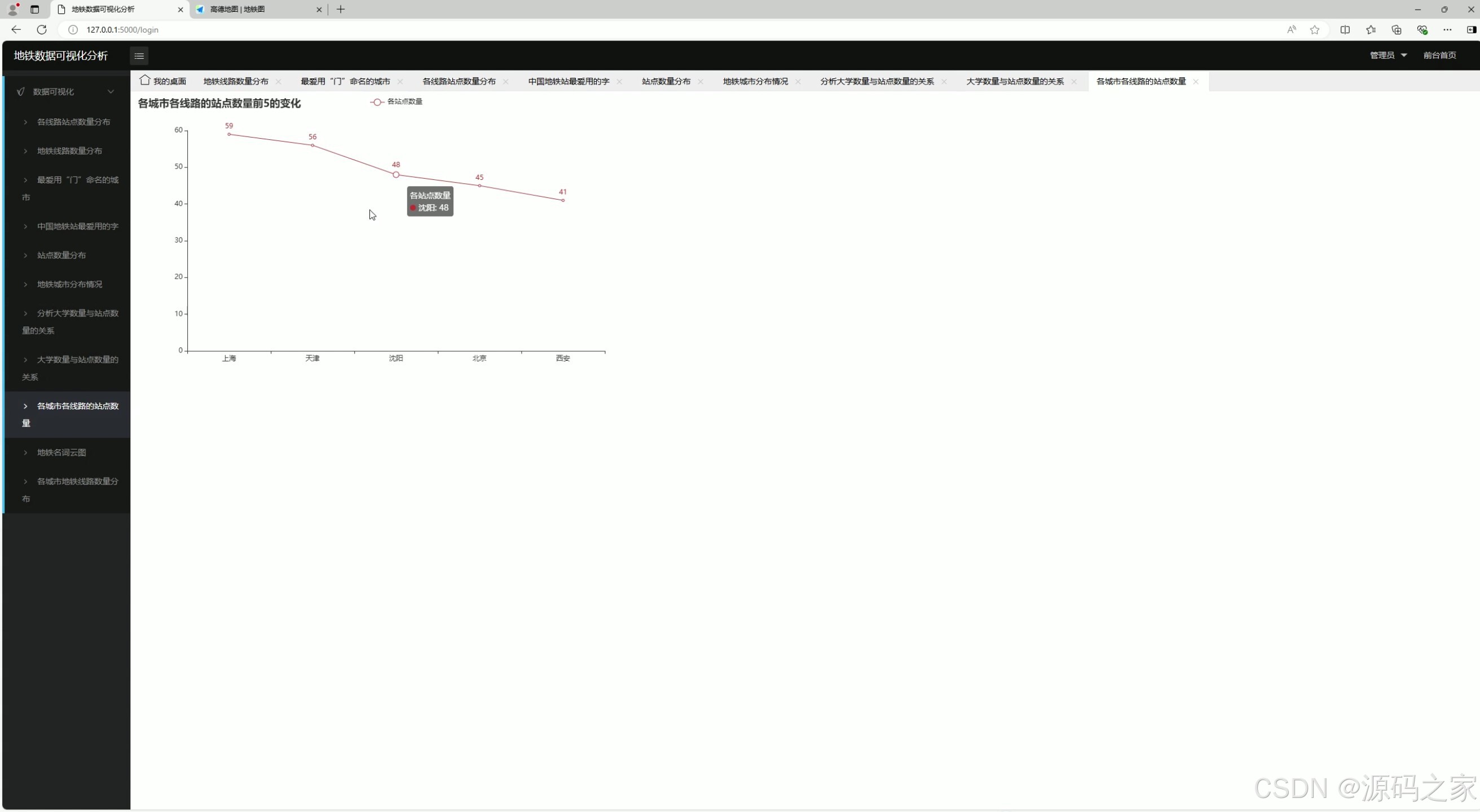
9、地图名词云图分析
10、地铁数据分布
11、登录界面

12、数据采集
3、项目说明
项目功能模块介绍
1. 地铁线路数量分布
- 功能:展示不同城市地铁线路的数量分布情况。
- 实现方式 :
- 使用
requests爬虫从相关数据源(如地铁官网、开放数据平台)获取地铁线路数据。 - 数据存储到 MySQL 数据库中。
- 前端使用 Echarts 可视化库生成柱状图或饼图,展示各城市的地铁线路数量分布。
- 使用
2. 各线路站点数量分布
- 功能:展示每个地铁线路的站点数量分布。
- 实现方式 :
- 数据通过爬虫获取并存储到 MySQL 数据库。
- 使用 Flask 后端从数据库中提取数据。
- 前端通过 Echarts 生成图表,展示站点数量分布。
3. 最爱用【门】命名的城市
- 功能:分析并展示哪些城市最喜欢用"门"字命名地铁站点。
- 实现方式 :
- 对地铁站点名称进行文本分析,统计包含"门"字的站点数量。
- 数据存储到 MySQL 数据库。
- 前端通过 Echarts 生成地图或柱状图,展示结果。
4. 地铁站最爱用的字排行
- 功能:统计并展示地铁站名称中最常用的汉字。
- 实现方式 :
- 对地铁站点名称进行文本分析,提取汉字并统计频率。
- 数据存储到 MySQL 数据库。
- 前端通过 Echarts 生成柱状图或词云图,展示常用汉字排行。
5. 站点数量分布
- 功能:展示不同城市地铁站点的数量分布。
- 实现方式 :
- 数据通过爬虫获取并存储到 MySQL 数据库。
- 使用 Flask 后端从数据库中提取数据。
- 前端通过 Echarts 生成地图或柱状图,展示站点数量分布。
6. 各城市分布地图
- 功能:在地图上展示各城市的地铁站点分布。
- 实现方式 :
- 使用高德地图 API 获取地图数据。
- 数据通过爬虫获取并存储到 MySQL 数据库。
- 前端通过高德地图 API 在地图上标记地铁站点位置。
7. 大学数量与站点数量的关系
- 功能:分析大学数量与地铁站点数量之间的关系。
- 实现方式 :
- 爬取大学数量和地铁站点数量数据。
- 数据存储到 MySQL 数据库。
- 使用数据分析工具(如 Pandas)进行相关性分析。
- 前端通过 Echarts 生成散点图或折线图,展示分析结果。
8. 各城市各站点数量
- 功能:展示每个城市中每个地铁站点的数量。
- 实现方式 :
- 数据通过爬虫获取并存储到 MySQL 数据库。
- 使用 Flask 后端从数据库中提取数据。
- 前端通过 Echarts 生成图表,展示站点数量分布。
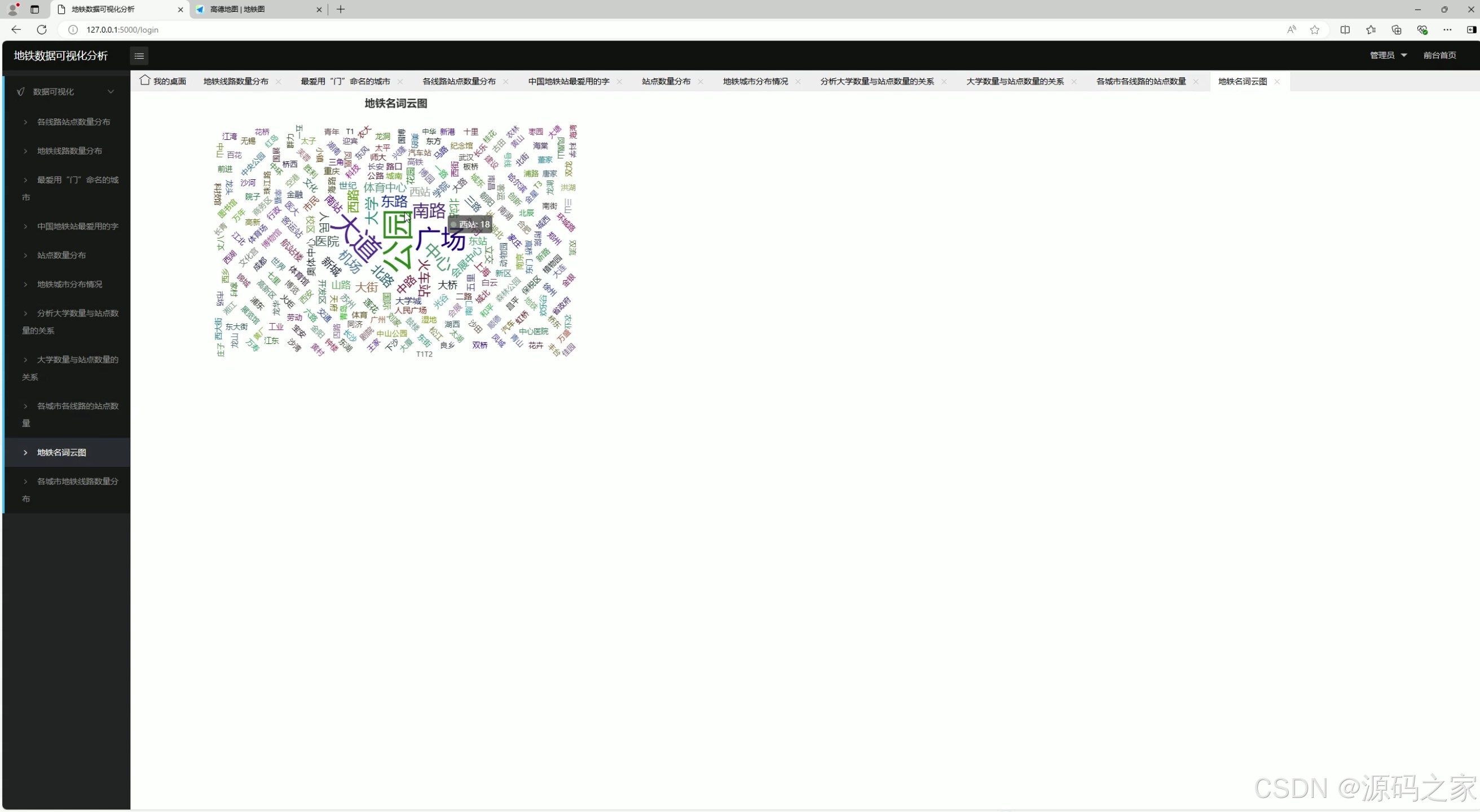
9. 地图名词云图分析
- 功能:生成地铁站点名称的词云图,展示常用词汇。
- 实现方式 :
- 对地铁站点名称进行文本分析,提取高频词汇。
- 数据存储到 MySQL 数据库。
- 前端通过 Echarts 生成词云图,展示结果。
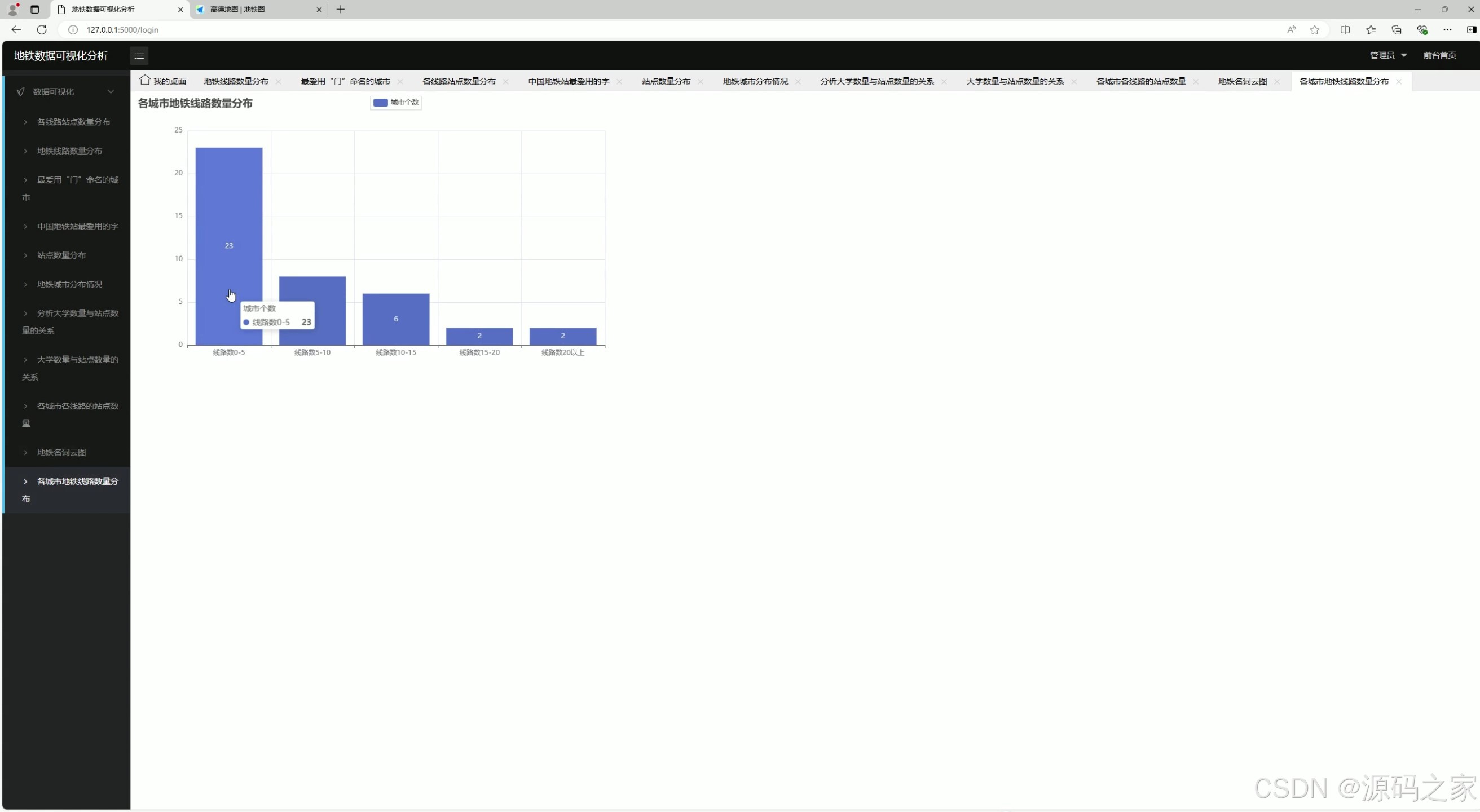
10. 地铁数据分布
- 功能:展示地铁数据的整体分布情况,可能包括线路、站点、客流量等。
- 实现方式 :
- 数据通过爬虫获取并存储到 MySQL 数据库。
- 使用 Flask 后端从数据库中提取数据。
- 前端通过 Echarts 生成多种图表,展示数据分布。
11. 登录界面
- 功能:用户可以通过此界面登录系统。
- 实现方式 :
- 使用 Flask 提供用户登录接口。
- 前端使用 HTML 和 CSS 设计登录页面,用户输入用户名和密码后通过表单提交到后端进行验证。
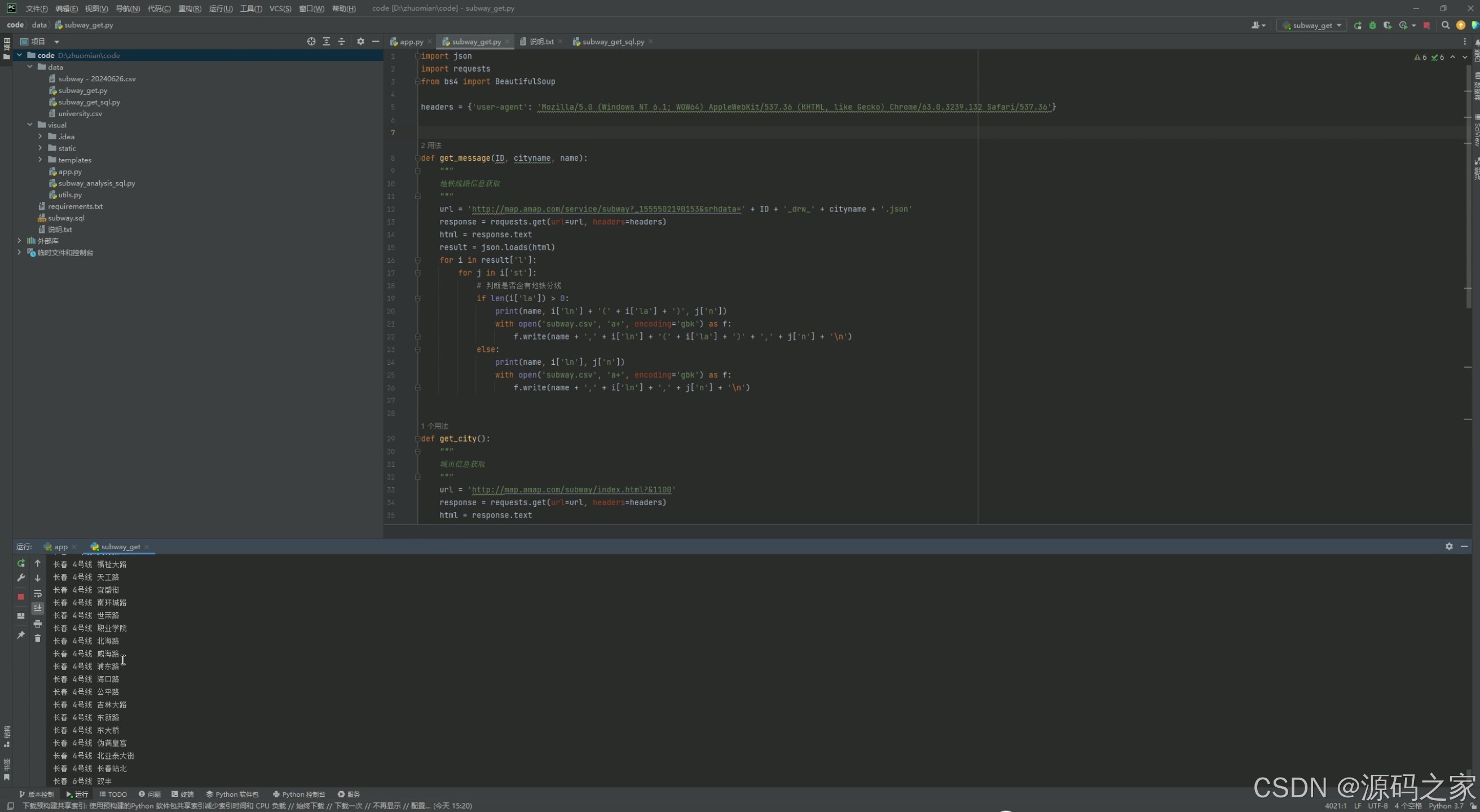
12. 数据采集
- 功能:提供数据采集功能,定期从外部数据源获取地铁数据。
- 实现方式 :
- 使用 Python 的
requests库编写爬虫脚本。 - 数据采集脚本定期运行,将数据存储到 MySQL 数据库。
- 可以通过后台管理界面手动触发数据采集任务。
- 使用 Python 的
4、核心代码
python
import json
import requests
from bs4 import BeautifulSoup
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}
def get_message(ID, cityname, name):
"""
地铁线路信息获取
"""
url = 'http://map.amap.com/service/subway?_1555502190153&srhdata=' + ID + '_drw_' + cityname + '.json'
response = requests.get(url=url, headers=headers)
html = response.text
result = json.loads(html)
for i in result['l']:
for j in i['st']:
# 判断是否含有地铁分线
if len(i['la']) > 0:
print(name, i['ln'] + '(' + i['la'] + ')', j['n'])
with open('subway.csv', 'a+', encoding='gbk') as f:
f.write(name + ',' + i['ln'] + '(' + i['la'] + ')' + ',' + j['n'] + '\n')
else:
print(name, i['ln'], j['n'])
with open('subway.csv', 'a+', encoding='gbk') as f:
f.write(name + ',' + i['ln'] + ',' + j['n'] + '\n')
def get_city():
"""
城市信息获取
"""
url = 'http://map.amap.com/subway/index.html?&1100'
response = requests.get(url=url, headers=headers)
html = response.text
# 编码
html = html.encode('ISO-8859-1')
html = html.decode('utf-8')
soup = BeautifulSoup(html, 'lxml')
# 城市列表
res1 = soup.find_all(class_="city-list fl")[0]
res2 = soup.find_all(class_="more-city-list")[0]
for i in res1.find_all('a'):
# 城市ID值
ID = i['id']
# 城市拼音名
cityname = i['cityname']
# 城市名
name = i.get_text()
get_message(ID, cityname, name)
for i in res2.find_all('a'):
# 城市ID值
ID = i['id']
# 城市拼音名
cityname = i['cityname']
# 城市名
name = i.get_text()
get_message(ID, cityname, name)
if __name__ == '__main__':
get_city()5、源码获取方式
html
biyesheji0005 或 biyesheji0001 绿泡泡🍅由于篇幅限制,获取完整文章或源码、代做项目的,查看我的【用户名】、【专栏名称】、【顶部选题链接】就可以找到我啦🍅
感兴趣的可以先收藏起来,点赞、关注不迷路,下方查看 👇🏻获取联系方式👇🏻