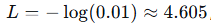调用示例
python
loss_fun = F.cross_entropy()
loss = loss_fun(y_pred, labels)一句话描述
交叉熵损失函数是描述:预测的概率分布 和真实概率分布之间差异的损失函数。差异越大,损失值越高;差异越小,损失值越低。
举例说明
假设有一只猫的图片,我们采用一个三分类(猫,狗,鸟)的模型进行预测
真实标签(one-hot 编码):1, 0, 0
表示 100% 是猫。
模型预测概率(经过 softmax 后):
0.7, 0.2, 0.1
模型认为 70% 可能是猫,20% 狗,10% 鸟。
公式
对于二分类任务
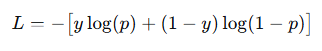
对于多分类任务
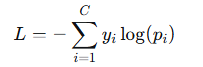
带入例子
真实标签:y=1,0,0
预测概率:p=0.7,0.2,0.1
则有:
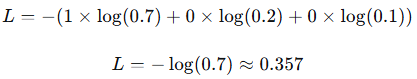
总结
假设预测概率特别低(比如 0.01),那么根据log函数的特性,可以知道,越接近0其损失值会越大。越接近1损失越小。