CorrCLIP
动机
作者提出了类间相关性的概念,并发现类间相关性就是CLIP分割性能下降的关键原因 。
类间相关性:狗的patch和猫的patch不应该交互,或者不应该相关。
验证实验
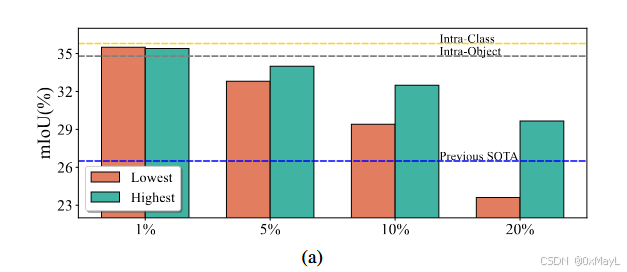
只保留 类内 / 物体内部 的 patch 相关性,分割性能显著提升;
逐渐加入类间相关性,性能持续下降,哪怕是"最相似的类间 patch 互动"也会伤害分割。
图2 (a)中,作者往相似度矩阵(来自DINO的特征 )逐步增加了类间相关性。具体来说,完美的注意力矩阵,类间patch之间不会有任何互动,作者对分别加入与某一个patch最高和最低相似度的另外一个patch
(例如对于狗的patch,加入猫的patch,加入公路的patch,一个高相似度,一个低相似度。)以实现增加类间相关性。
作者得出结论,即使是高相似度的类间patch,例如狗和猫的patch相似度较高,这种类间相关性仍然会大幅度影响分割性能。

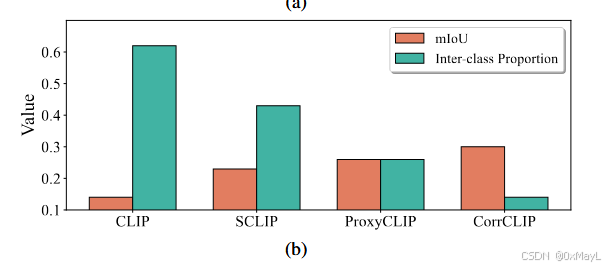
先前的方法本质上可以理解为降低类间相似度来提高分割性能。
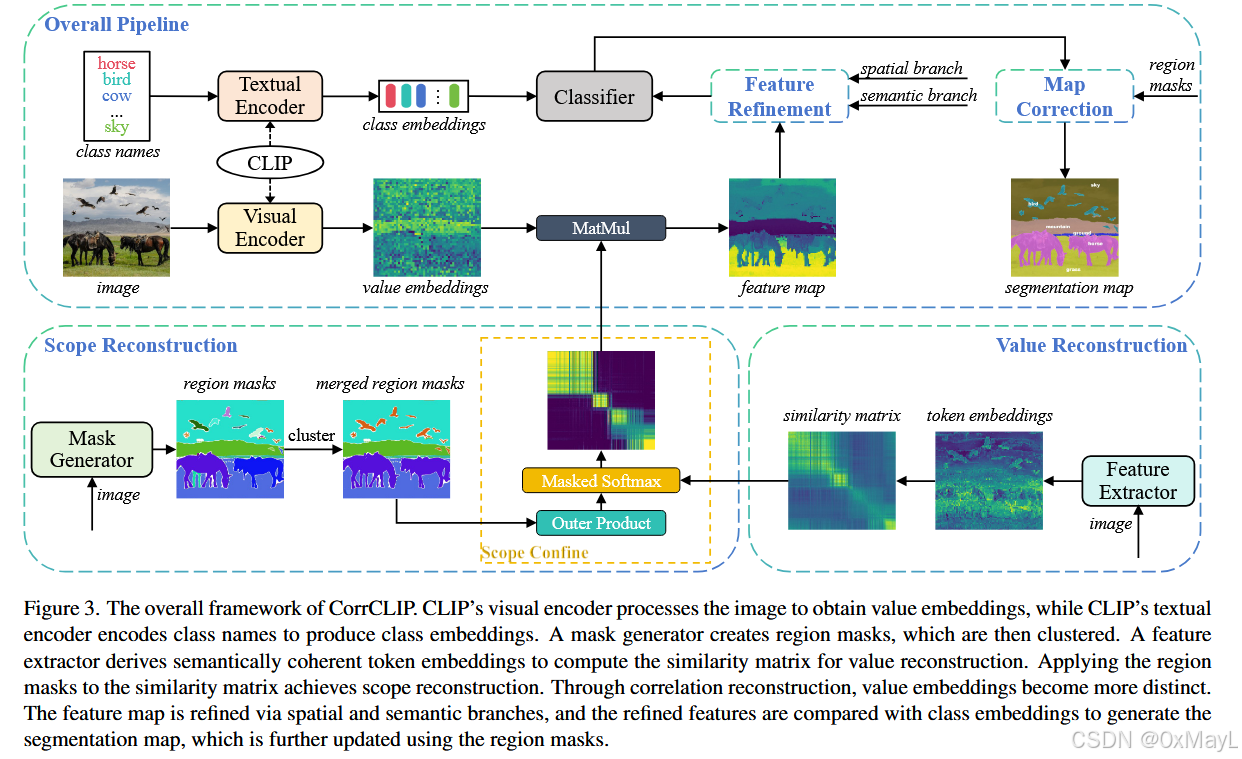
方法
Scope Reconstruction
作者使用SAM2生成多个类别的掩码,实际上是一个与图像大小相同的矩阵,但是里面有多种标签 (就类似分割掩膜)。
尽管self-self注意力可以增加性能,但仍然受限于CLIP的类间相关性。作者使用SAM来显示构造这种注意力掩码。
注意:FSF_SFS是DINO中提取的特征。SAM2生成的分割掩码与FSF_SFS进行交互,得到二分类掩码。这些二分类掩码将会被用于聚类,得到多个聚类中心。

Z个掩码经过聚类后只剩下z个掩码,这z个掩码中分为背景类和非背景类。
然后设计一种注意力掩码 ,其中背景类只允许与自己交互 ,非背景类还需要确保置信度达标。

Value Reconstruction
与ProxyCLIP差不多,利用DINO的特征制作注意力矩阵。
通过插值确保S和E维度一致。

Feature Refinement
简单来说就是CLIP的特征+多个低层特征的平均值(空间特征 )+MCT掩码嵌入(语义特征 )。
MCT的数量和融合后的掩码数量一致,经过ViT编码后,将与自己的对应的掩膜进行直接相乘(相当于论文中与自己的掩膜交互)
假设z个MCT,维度为(z,D),共有(z,HW)个掩膜,相乘后维度恰好为(H W,D),然后就可以与前面的特征进行融合。


Map Correction
前面融合后的掩码将用于用于同一某一区域的类别 。
作者说是为了保持空间一致性,抑制区域内单个patch的噪声。

缺点和不足
计算开销大
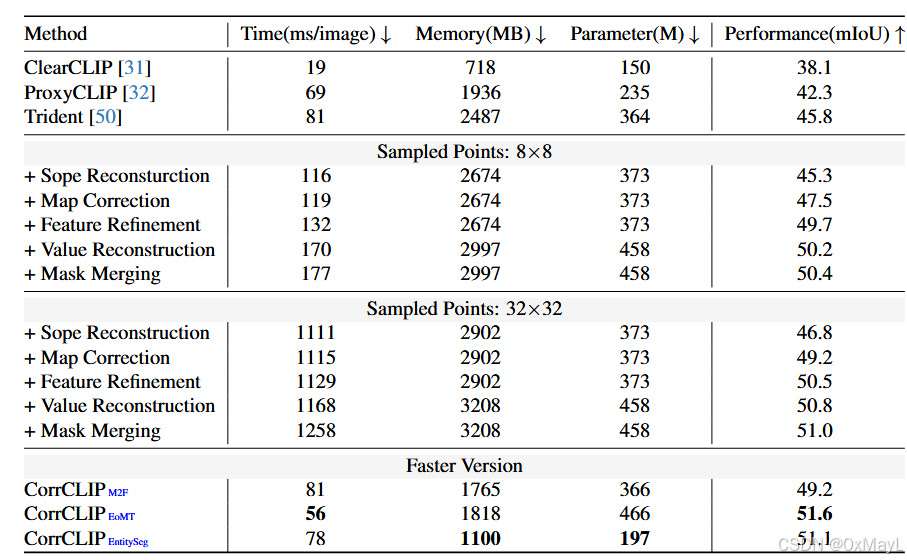
同时运行 CLIP、DINO、SAM2,且 SAM 要 32×32 网格点采样;
掩码生成、相似度重算、DBSCAN 聚类都比较耗时/显存;
单图延时显著高于 ClearCLIP 等轻量方法,需要专门的加速策略。
强依赖掩码生成质量 & 下采样分辨率
掩码要下采样到 CLIP patch 尺度,会引入量化误差;
掩码越精细,SR 效果越好,但计算开销急剧上升;
仍有残余类间相关
即便在一个区域内,大概率是物体一致,但仍可能混有多个类,VR 只是在权重层面减弱,而不是完全消除;
对极度细粒度类别(very fine-grained)仍可能混淆。
实现复杂度较高
管理多模型(CLIP + DINO + SAM)、多阶段(SR/VR/FR/MC)、多 Hyper-parameter(τ、mask size、聚类 eps 等)需要较多工程工作。
GPT总结
- 摘要翻译(意译,便于理解)
开放词汇语义分割(OVSS)的目标是在没有预先固定类别集合的情况下,为每个像素赋予语义标签。CLIP 在零样本分类上很强,但因为 patch 之间的相关性"不成体系",在把图像 patch 对齐到类别 embedding 时表现不好。本工作发现:类间相关性(inter-class correlations)是破坏 CLIP 分割性能的主要原因 。
因此作者提出 CorrCLIP,通过"重构 patch 相关性"来提升分割能力:
- 利用 SAM 限制 patch 交互的范围,减少类间相关;
- 再用自监督模型计算语义更连贯的相似度,压低类间相关的权重;
- 另外引入两条分支增强 patch 特征的空间细节与语义信息;
- 最后用 SAM 掩码后处理分割图,提高空间一致性。
在 patch 相关性、特征表达和分割图三方面一起改进后,CorrCLIP 在 8 个基准上取得了更优的表现,并开源了代码。
1. 方法动机
1.a 为什么要提出 CorrCLIP?
-
CLIP 视觉编码器是为整体图像分类训练的,只追求"整张图 → 文本"的对齐,而不是"局部 patch → 文本"的精细对齐。
-
把 CLIP 直接拿来做 OVSS,需要把每个 patch 的特征对齐到类别文本 embedding,这时 patch 之间的注意力/相关性质量就非常关键。
-
作者系统分析后发现:
- 只保留 类内 / 物体内部 的 patch 相关性,分割性能显著提升;
- 逐渐加入类间相关性,性能持续下降,哪怕是"最相似的类间 patch 互动"也会伤害分割。
⇒ 类间相关性是主要"毒点"。
-
现有改进 CLIP 的方法(ClearCLIP、SCLIP、ProxyCLIP 等)确实有提升,但:
- 没有显式回答"哪些相关性在伤害性能";
- 也没有从"交互范围"和"相似度数值"两层面,系统地重构相关性。
所以,CorrCLIP 的核心动机:
显式削弱/控制类间相关性,让 CLIP 的注意力更多发生在"同一物体/同一类别区域内部",从而让 patch 特征更可分,更容易对齐文本。
1.b 现有方法的痛点 / 不足
作者主要对比三类 training-free OVSS 方法:
-
只改注意力形式但仍困在 CLIP 内部
-
MaskCLIP、ClearCLIP、SCLIP、ResCLIP 等:
-
改成 self-self attention,或使用低层特征来修补注意力。
-
这些操作间接地减少了一些类间相关,但:
- 仍完全依赖 CLIP 自身的 patch 表达,语义连贯性有限;
- 没有显式限制哪些 patch 可以互相注意。
-
-
-
引入其他基础模型,但只做"阈值/加权"
-
ProxyCLIP、Trident、CLIPer、CASS、FreeDA 等:
- 从 DINO、SAM 或 diffusion 模型提特征/原型,辅助 CLIP;
- 常用"相似度阈值"来删掉低相似的边。
-
问题:
- 高相似的类间相关仍大量存在,对分割依旧有负面影响;
- 没有 region 级的、结构化的"谁能和谁对话"的约束。
-
-
训练-based 方法(TCL、CLIP-DINOiser、CAT-Seg 等)
-
依赖像素级或图像级监督,效果强,但:
- 可能破坏 CLIP 原有的开放词汇能力;
- 泛化到分布外数据集时性能下降明显。
-
1.c 研究假设 / 直觉(用几句话概括)
可以浓缩成三条直觉:
-
好用的 patch 相关性 = 类内/物体内为主
- 只在同一物体/同一类中强交互,会让 patch 更"干净可分"。
-
类间相关绝大多数是有害的
- 聚合到"别的类"的信息,会模糊边界,降低像素判别性。
-
现成的大模型可以帮我们"修正" CLIP 的 patch 相关
- SAM 提供"区域范围"(scope);
- DINO 提供"更语义一致的相似度值"(value)。
⇒ 在 scope 和 value 两个层面重构相关性,就能显著提高 OVSS 性能。
2. 方法设计(重点:完整 pipeline + 细节)
先从"CLIP 做 OVSS 的基础流程"说起,再插入 CorrCLIP 的四个模块:
Scope Reconstruction(SR)
Value Reconstruction(VR)
Feature Refinement(FR)
Map Correction(MC)
2.1 基础:CLIP 适配 OVSS 的标准流程
-
图像 → patch token
-
输入图像被切成 N 个 patch,经线性层变成 token:
- 记为 (X_C \in \mathbb{R}^{N \times d})(d 是通道维)。
-
加上位置编码,送入 CLIP 的 ViT 视觉编码器。
-
-
最后一层 self-attention
-
在最后一层,把 token 映射成 Q、K、V:
- (Q_C, K_C, V_C \in \mathbb{R}^{N \times d})。
-
ClearCLIP 的做法:用 Q·Qᵀ 来构造相似度矩阵 S:
S = Q_C Q_C\^\\top \\in \\mathbb{R}\^{N \\times N}
-
这是 patch 与 patch 之间的相关性。
-
-
注意力 & 图像特征
- 注意力图:
\\text{Attn}=\\text{Softmax}(S/\\sqrt{d})
- 用注意力加权 V 得到聚合后的图像 patch 特征:
F_\\text{img} = \\text{Proj}(\\text{Attn}, V_C)
- 此处 ClearCLIP 会把最后一层的 FFN、残差都去掉,只保留这一步。
- 注意力图:
-
文本侧:类别描述 → 文本 embedding
- K 个类别名称 + ImageNet prompt 模板,输入 CLIP 文本编码器,得到:
F_\\text{text} \\in \\mathbb{R}\^{K \\times d}
- K 个类别名称 + ImageNet prompt 模板,输入 CLIP 文本编码器,得到:
-
分类:patch 特征 × 文本向量
- 把 (F_\text{img}) 投影到与文本相同空间,然后做点积,取 argmax:
\\text{pred} = \\arg\\max_K\\big(\\text{Proj}(F_\\text{img}) F_\\text{text}\^\\top\\big)
- 得到每个 patch 的类别预测,reshape 为分割图。
- 把 (F_\text{img}) 投影到与文本相同空间,然后做点积,取 argmax:
CorrCLIP 就是在"如何构造 S 和 Attn、如何得到更好的 F_img 和 pred"这几步上,插入 4 个模块。
2.2 Scope Reconstruction(SR):用 SAM 限制"谁能和谁注意"
目标:
让 patch 只在"合理的区域内部"彼此交互,大幅减少类间相关。
2.2.1 用 SAM 生成区域掩码
-
使用 SAM2 + Hiera-L 作为掩码生成器:
- 在输入图像上均匀采样 32×32 个点作为提示;
- 对每个点,SAM 生成一组候选掩码;
- 用 "pred_iou_thresh = 0.7" 和 "stability_score_thresh = 0.7" 做筛选,剔除低质掩码。
-
下采样掩码到与 CLIP 最后一层 feature map 同大小(N 个 patch):
- 得到 Z 个互不重叠 的区域掩码:
M={m_1,\\dots,m_Z},\\quad m_i \\in {0,1}\^{N}
- 未被任何 SAM 掩码覆盖的 patch 合并成一个"背景区域" (m_0)。
- 得到 Z 个互不重叠 的区域掩码:
2.2.2 区域特征 & 掩码聚类(mask merging)
-
先从某个"语义更连贯"的特征序列 (F_S) 上做 mask average pooling:
- (f_i = \text{Mean}(m_i \odot F_S)),得到每个区域的特征 (f_i \in \mathbb{R}^d)。
-
对 ({f_i}) 用 DBSCAN 聚类(eps=0.2,min_samples=1),把语义相似的区域合并:
- 得到合并后的区域掩码集合 (\hat{M}={\hat{m}_1,\dots,\hat{m}_z})。
注意:合并之后的掩码里可能包含多个类别的像素,但它们在特征空间应该"很像",类间相关的负面影响较小。消除更多噪声和伪分割区域带来的收益更大。实验表明"开聚类"比"不聚类"在所有数据集上都有提升。
2.2.3 构造交互矩阵 E:定义"允许交互的 patch 对"
现在,我们用 (\hat{M}) 来定义一个二值矩阵 (E \in {0,1}^{N\times N}):
-
对每个合并区域 (\hat{m}_i):
-
外积 (\hat{m}_i \otimes \hat{m}_i) 生成一个区域内部的"完全连通图":
- 行列为 1 的位置表示"这两个 patch 在同一 region,可以互相注意"。
-
把这些区域的外积累加起来:
\\sum_{i=1}\^{z} \\hat{m}_i \\otimes \\hat{m}_i
-
-
对未分割区域 (m_0):
- 不能简单地让所有背景 patch 互相连通,否则类间相关会太多。
- 作者做法:
(m_0 \\otimes m_0) \\odot (S \> \\text{Mean}(S))
只允许相似度高于全局平均值的 pairs 在背景内部交互。
-
最终交互矩阵:
E = \\sum_{i=1}\^{z} \\hat{m}_i \\otimes \\hat{m}_i + (m_0 \\otimes m_0) \\odot (S \> \\text{Mean}(S))
2.2.4 用 Masked Softmax 限制注意力范围
-
把 E 当作 attention mask,只对 E=1 的位置做 softmax:
\\text{Attn} = \\text{MaskedSoftmax}\\big(S/\\sqrt{d}, E\\big)
-
直观理解:
- 每个 patch 只能在同一 SAM 区域内(或背景里极少数高相似 patch)聚合信息;
- 大量不相关的类间交互被硬剪掉。
实验表明,仅仅插入 SR 这一件事,就能在多个数据集上带来 5~15 mIoU 的提升,而且可以"外挂"到 SCLIP / ProxyCLIP / SC-CLIP 等方法上继续提分。
2.3 Value Reconstruction(VR):用 DINO 重新计算"相关性数值"
动机:
SAM 区域可能依然包含多个类别,即使我们把交互限制在区域内部,区域内仍有类间相关。
⇒ 需要一个语义更可靠的相似度矩阵 S,拉低类间相关的权重。
2.3.1 用 DINO 的 Q、K 输出来计算 S
-
在 DINO 的 ViT 上,得到 token 序列,在最后一层映射成:
- (Q_D, K_D, V_D \in \mathbb{R}^{N \times d})(长度和 patch 大小通过插值对齐 CLIP)。
-
构造"语义特征" (F_S = Q_D + K_D),然后用它做 cosine 相似:
S = \\frac{F_S F_S^\\top}{\|F_S\|^2}
-
与 SR 中的 E 结合,用温度系数 τ 调节"尖锐程度":
\\text{Attn} = \\text{MaskedSoftmax}(S / \\tau, E), \\quad \\tau \< 1
- τ=0.25,使得"高相似 patch 的权重更大,低相似更小"。
作者比较了多种构造相似度的方式:CLIP 自己的 QK、只用 DINO 输出特征 X-X、用小 DINO-S 等,发现"QK-QK + DINO-B"平均表现最好。
关键点:
- SR 决定"谁能互相注意"(拓扑结构);
- VR 决定"注意力权重是多少"(边权重),并通过 DINO 的语义布局把类间相关进一步压低。
2.4 Feature Refinement(FR):补空间细节 & 区域语义
目标:
在相关性重构之后,再从特征表达层面补两块短板:
- patch 的空间细节(边界/小物体);
- patch 的区域级语义(每个掩码的全局语义)。
CorrCLIP 定义当前 F_img 的"主干分支"为:
F_\\text{main} = \\text{Proj}(\\text{Attn} V_C)
然后加两个分支:
2.4.1 空间分支(Spatial branch)
-
利用 CLIP 较低层的 patch 特征 (V'_C):
- 低层特征含有更细致的纹理和位置信息。
-
先用最后一层的 value-projection 把 (V'_C) 映射到同一空间,再用同一 Attn 聚合:
- 得到增强空间维度的特征分支。
2.4.2 语义分支(Semantic branch:Mask Class Tokens)
这块设计挺有意思:
-
在 ViT 输入时,新增 z 个 "mask class tokens":
- 每个 token 对应一个 SAM 合并掩码。
- 它们放在 patch token 前面。
-
在每一层 self-attention 中:
- 每个 mask class token 只与自己区域内的 patch 交互;
- 其他区域的 patch 被 mask 掉。
-
在 ViT 最后一层:
-
对每个在区域 i 内的 patch,把对应的 mask class token 向量加到它身上:
- 相当于每个 patch 获得一个"区域全局语义总结"。
-
记这 z 个 mask class token 的输出为 MCT,最后整体 F_img 变为:
F_\\text{img} = \\text{Proj}(\\text{Attn} V_C) + \\alpha \\cdot \\text{Proj}(\\text{Attn} V'_C) + \\beta \\cdot \\text{MCT}
其中 α=1, β=0.5。
Ablation 里可以看到:单独用空间分支或语义分支,在一些数据集(尤其 City & Object)上会有轻微负增益,但两个一起用时,在所有数据集上都是正增益,说明"空间+语义"是互补的。
2.5 Map Correction(MC):用区域多数投票修正分割图
动机:
-
CLIP 没有从像素级监督中学习"空间一致性",即:
- 一个连贯的物体区域内部,预测类别可能跳来跳去。
-
SR/VR/FR 已经缓和了这个问题,但仍不如全监督方法。
做法:
-
利用前面得到的区域掩码((\hat{m}_i),i>0),对初始预测 pred 做后处理:
\\text{pred}\[\\hat{m}_i\] = \\text{Mode}(\\text{pred}\[\\hat{m}_i\])\\quad (i\>0)
- 即:每个区域内取"出现最多的类别",把整个区域统一成这个类别。
效果:
- 显著提升物体内部的连贯性;
- 抑制"单个噪声 patch 异常预测"的现象。
3. 与其他方法对比
3.a 与主流 OVSS 方法的本质区别
核心差异:CorrCLIP 把"patch 相关性"拆成两层------范围(scope)和数值(value),并且用外部 VFM(SAM、DINO)显式重构。
-
ClearCLIP / SCLIP / NACLIP / ResCLIP / SC-CLIP:
- 只在 CLIP 内部改注意力形式(self-self、更低层)和残差结构;
- 仍没控制"谁可以和谁交互",也没借助外部"语义布局先验"。
-
ProxyCLIP / Trident / CLIPer / CASS / FreeDA:
-
已经引入 DINO、SAM 等信息,但主要做:
- 阈值剪枝、加权融合、构造额外原型等;
-
没有一个统一的、从"范围+数值+后处理"三层设计的"相关性重构"框架。
-
-
训练-based 方法(TCL、OVSeg、CAT-Seg 等):
-
通过额外训练在特定数据集上做得更好,但:
- 需要标注或精心设计的文本 supervision;
- 有损 CLIP 的真正开放词汇能力,跨分布泛化有限。
-
3.b 创新点 & 贡献度
可归纳为三大类贡献(也是论文自述的三条):
-
发现问题:提出"类间相关是主要毒点"的证据链
-
系统实验证明:
- 只用类内/物体内相关 → 性能显著提升;
- 加入更多类间相关 → 性能单调下降。
-
-
方法创新:多层次重构 patch 相关性
-
Scope Reconstruction:
- 用 SAM 区域掩码明确限制 patch 交互范围;
-
Value Reconstruction:
- 用 DINO 的语义相似度重新赋值相关性,配合温度系数进一步区分强/弱相关;
-
二者配合,直接对"相关性的拓扑结构 + 数值"进行重构。
-
-
整体系统设计:从相关性 → 特征 → 分割图的链式优化
-
Feature Refinement:
- 新的"mask class tokens"设计 + 低层特征融合;
-
Map Correction:
- 区域多数投票保证空间一致性;
-
整体无训练、端到端使用 CLIP + VFM,实现大幅超越之前所有 training-free 方法,并在部分 OoD 数据集上超过训练-based 方法。
-
3.c 更适用的场景 / 适用范围
更适合的场景:
-
重视"训练-free + 强泛化"的 OVSS 应用
- 不想再额外训练一个大模型;
- 又希望在 VOC、COCO、Cityscapes、ADE 等标准数据集上达到当前最高水平。
-
可以接受额外计算开销的离线/近实时场景
- 需要同时跑 CLIP + DINO + SAM,计算和显存开销较大;
- 更适合 offline 标注、分析系统,或有高算力服务器的应用。
-
希望在"分布外场景"有稳健表现
- 在 MESS 中的 FoodSeg、ATLANTIS、CUB、SUIM 等 OoD 数据集上, CorrCLIP 比基于 COCO 训练的全监督方法更强,说明对 domain shift 有优势。
不太适合的场景:
- 移动端、实时应用,对延时和显存有严格约束时,原版 CorrCLIP 太重,需要使用作者在附录中提到的"精简版 + 更轻量掩码生成器"。
3.d 方法对比表(简化版)
| 方法 | 是否训练 | 主要思路 | 优点 | 缺点 / 改进点 |
|---|---|---|---|---|
| ClearCLIP | 否 | 改最后一层结构+QQ 相似度 | 简单,提升明显,开销小 | 仍存在大量类间相关;不利用外部 VFM |
| SCLIP | 否 | self-self attention,patch 关注自己 | 减少了一部分类间相关 | 仍在 CLIP 内部打转,相关性范围不可控 |
| ProxyCLIP | 否 | 用 DINO 构造 proxy attention + 阈值 | 利用更好语义特征辅助 CLIP | 仍有高相似类间相关;缺少区域级约束 |
| Trident | 否 | 融合多种 VFM 提示和特征 | 综合性能强,是 CorrCLIP 之前 SOTA | 没有从"相关性结构"统一建模 |
| Training-based (TCL/OVSeg/CAT-Seg 等) | 是 | 在特定数据集上再训练或适配 CLIP | 某些数据集上性能很高 | 破坏开放词汇泛化能力;需要标注 |
| CorrCLIP | 否 | SAM 限制范围 + DINO 重构数值 + FR + MC | 训练-free,高 mIoU、强 OoD 泛化 | 计算代价大,依赖高质量掩码生成器 |
4. 实验表现与优势
4.a 如何验证方法有效性?
数据集与指标:
- Pascal VOC:VOC21(含背景 21 类)、VOC20(无背景 20 类);
- Pascal Context:PC60、PC59;
- COCO Stuff:Stuff(171 类)、Object(81 类);
- ADE20K:ADE(150 类);
- Cityscapes:City(19 类);
- 共 8 个 benchmark,统一用 mIoU 评价。
模型配置:
- CLIP backbone:ViT-B/16、ViT-L/14、ViT-H/14 三种;
- DINO:ViT-B/8;
- 掩码生成:SAM2 + Hiera-L。
对比方法:
- Training-free:CLIP, MaskCLIP, ClearCLIP, SCLIP, ProxyCLIP, LaVG, CLIPtrase, NACLIP, Trident, ResCLIP, SC-CLIP, CLIPer, CASS, FreeDA 等;
- Training-based:TCL, CLIP-DINOiser, CoDe, CAT-Seg, ESC-Net 等。
消融实验:
- 逐步加入 SR、VR、MC、FR 四个模块,观察 mIoU 变化;
- 分析不同 mask 分辨率、不同相似度构造方式、是否做 mask merging;
- 不同类型 CLIP(CLIP/OpenCLIP/MetaCLIP/DFNCLIP)的影响;
- 空间分支和语义分支单独/联合使用的效果;
- 计算开销(时间、显存、参数量)分析及加速版。
4.b 代表性结果与关键数据
只列几个关键点(以 ViT-L/14 为例):
- 在 8 个 benchmark 上,CorrCLIP-L 的平均 mIoU = 53.6%;
- 前一个 training-free 最好方法(Trident/CLIPer/SC-CLIP 等组合)平均在 ~45% 左右;
- CorrCLIP-L 相当于平均提升 +8.4 mIoU。
分数据集看(ViT-L/14):
- VOC21:76.7(比次优方法 69~70 提升约 6~7);
- PC60 / PC59:44.9 / 50.8(相比 38~44 提升 6~7+);
- Object / Stuff:49.4 / 34.0(相比 43~29 提升 5~6);
- ADE / City:30.7 / 51.1(相比 24~41 提升 6~10,City 提升特别明显)。
在 ViT-B/16 / ViT-H/14 上,CorrCLIP 同样在 8 个 benchmark 上 全面压过所有 training-free 方法,平均提升 5.2 mIoU(B)和 3.7 mIoU(H)。
与 training-based 方法对比:
- 在 VOC/PC/COCO 等内分布数据集上,CorrCLIP 能接近甚至超过弱监督方法;
- 在 MESS 中四个 OoD 数据集上,CorrCLIP-L 在所有数据集上都明显优于 OVSeg-L 与 CAT-Seg-L,说明其跨分布泛化能力更强。
4.c 哪些场景 / 数据集优势最明显?
-
城市场景(Cityscapes)
- ViT-L:CorrCLIP = 51.1,前 SOTA ~41 左右,提升近 10 mIoU;
- 空间一致性与边界质量提升效果最显著。
-
复杂多类场景(PC60 / PC59 / Stuff)
- 这类数据中,图像中同时包含许多物体与 stuff,类间相关非常多;
- CorrCLIP 的 SR+VR 特别适合这种环境,带来 5~7 的提升。
-
分布外数据集(FoodSeg、ATLANTIS、CUB、SUIM)
- CorrCLIP-L 全面超过在 COCO 上训练的全监督方法;
- 说明"训练-free + 强 prior"比"在单一数据集上再训练"更适合跨域应用。
4.d 局限性与不足
论文中明说或隐含的局限,可以归纳为:
-
计算开销较大(作者在附录里专门做了表):
- 同时运行 CLIP、DINO、SAM2,且 SAM 要 32×32 网格点采样;
- 掩码生成、相似度重算、DBSCAN 聚类都比较耗时/显存;
- 单图延时显著高于 ClearCLIP 等轻量方法,需要专门的加速策略。
-
强依赖掩码生成质量 & 下采样分辨率
- 掩码要下采样到 CLIP patch 尺度,会引入量化误差;
- 掩码越精细,SR 效果越好,但计算开销急剧上升;
- 若 SAM 对某些 domain(如医学、特殊工业场景)表现不佳,则 CorrCLIP 也会受影响。
-
仍有残余类间相关
- 即便在一个区域内,大概率是物体一致,但仍可能混有多个类,VR 只是在权重层面减弱,而不是完全消除;
- 对极度细粒度类别(very fine-grained)仍可能混淆。
-
实现复杂度较高
- 管理多模型(CLIP + DINO + SAM)、多阶段(SR/VR/FR/MC)、多 Hyper-parameter(τ、mask size、聚类 eps 等)需要较多工程工作。
5. 学习与应用建议
5.a 是否开源?复现关键步骤
论文给出了 GitHub 链接(CorrCLIP),代码已开源。
复现关键步骤(按模块分):
-
准备模型与输入
- 加载 CLIP(ViT-B/L/H)、DINO-B/8、SAM2+Hiera-L;
- 对输入图像按数据集规范 resize(短边 336 或 448),使用滑窗推理(336×336 窗,步长 112)。
-
掩码生成 & 合并(Scope Reconstruction)
- 对每张图,网格采样 32×32 点;
- 调 SAM 的 inference,设置 threshold=0.7,得到一系列掩码;
- 下采样到 patch 分辨率,构造 m_i 与 m_0;
- 用 DINO 的某层特征做 mask average pooling 得到 f_i;
- 用 DBSCAN 聚类 f_i,得到合并掩码 (\hat{m}_i)。
-
构造交互矩阵 E
- 对每个 (\hat{m}_i) 做外积并累加;
- 对 m_0 做外积乘 (S>mean(S));
- 得到 E,并在注意力 softmax 中用作 mask。
-
相似度重构(Value Reconstruction)
- 从 DINO 最后一层获得 Q_D、K_D;
- 对齐 token 长度后,构造 F_S=Q_D+K_D;
- 归一化后做内积得到 S(cosine 相似);
- 用 τ=0.25 缩放并配合 E 做 MaskedSoftmax。
-
特征重构(Feature Refinement)
- 选取 CLIP 某一低层的 V_C',用最后一层的 value-proj 映射,和 Attn 聚合;
- 在 ViT 输入添加 z 个 mask class tokens,并在每层中限制其交互范围;
- 在最后一层把对应 mask class token 加回每个 patch;
- 用 α=1, β=0.5 融合三条分支得 F_img。
-
文本匹配与后处理(Map Correction)
- 用 CLIP 文本编码器算 F_text;
- F_img 与 F_text 做点积分类,得到粗分割 map;
- 对每个 (\hat{m}_i) 做多数投票更新 pred。
5.b 实现细节与超参数注意事项
根据论文描述,总结几个容易踩坑的点:
-
图像预处理
- 牢记不同数据集的短边尺度:VOC/PC/COCO 用 336,City/ADE 用 448;
- 滑窗推理参数(336 窗 + 112 步长)直接影响速度与边界质量。
-
SAM 超参数
- pred_iou_thresh 和 stability_score_thresh 统一设为 0.7;
- 网格点密度是开销大头,如果算力有限,可以从 32×32 改成 8×8,略微损失性能换大幅加速。
-
聚类与 mask merging
- DBSCAN:eps=0.2, min_samples=1;
- 实现在 CPU 上,注意效率;
- 可以先复现论文默认设置,再尝试只保留较大 region 或改用 K-Means 等。
-
相似度构造与 τ
- 推荐直接用 DINO-B + (Q+K) 方案与 τ=0.25;
- 若内存吃紧,可以换成 DINO-S,论文中实验显示性能接近。
-
空间/语义分支
- 默认 α=1, β=0.5;
- 若显存不够,可先关掉语义分支(mask class tokens),只保留空间分支,性能仍有提升。
-
加速版实现
- 作者尝试用更轻量的掩码生成器(Mask2Former / EoMT / EntitySeg),并去掉 VR 与 mask merging,得到"CorrCLIP Faster";
- 性能略降,但速度已接近或优于 ProxyCLIP / Trident,可参考其设置做工程折中。
5.c 能否迁移到其他任务?怎么迁移?
虽然论文只做了 OVSS,但从方法形态上看,它实际上提供了一个"重构自注意力相关性"的通用框架,可以考虑迁移到:
-
开放词汇实例/全景分割
- 把 mask 改为实例级/全景级区域;
- 在检测器或全景分割头的 decoder 中引入 SR/VR,使 query 只在对应 region 内交互。
-
开放词汇目标检测 / referring segmentation
- 用 SAM/DINO 先生成候选区域(proposal),再把 CorrCLIP 的相关性重构思想应用到候选内部的特征聚合和文本对齐上。
-
一般 ViT-based dense task(深度估计、人体解析等)
-
如果任务存在"类间/区域间相关性污染"的问题,可以类似地:
- 用外部模型提供区域划分(scope);
- 用自监督模型提供更可靠的相似度(value);
- 在 decoder 注意力里嵌入 SR/VR 的思想。
-
迁移时需要注意:
- 替换"类别文本 embedding 匹配"这一终端步骤为对应任务的 head;
- 重新选择合适的 region 生成器(不一定要 SAM,task-specific proposal network 也可)。
6. 总结与速记版 pipeline
6.a 一句话概括核心思想(不超过 20 字)
用外部区域与相似度重构 CLIP 相关性
6.b 速记版 pipeline(3--5 步,去掉论文术语)
- 用一个强大的分割模型先把图像切成很多区域,并把相似的区域合并在一起。
- 在每个区域内部,用另一个视觉模型来衡量像素之间的相似度,只允许同一区域、相似度足够高的像素彼此交流信息。
- 在汇聚图像信息时,同时利用高层特征、低层细节特征和区域级的"全局特征",得到更细致又语义清晰的像素表示。
- 把这些像素表示与类别文字向量做匹配,得到初始分割结果。
- 最后,对每个区域内部进行多数投票,把整块区域统一成最可能的类别,修正空间上的小噪声。
如果你之后想把 CorrCLIP 融入你的一阶段 ZSSEG / ZEGCLIP 体系,我们也可以专门讨论"哪些模块可以裁剪、哪些可以和 proposal head 结合"。