本大纲按认知规律 + 技能进阶设计,分为 4 个核心阶段,每个阶段明确「学习目标、核心知识点、实践任务、验收标准」,兼顾理论理解与工程落地,适配零基础到工业级应用的学习路径。
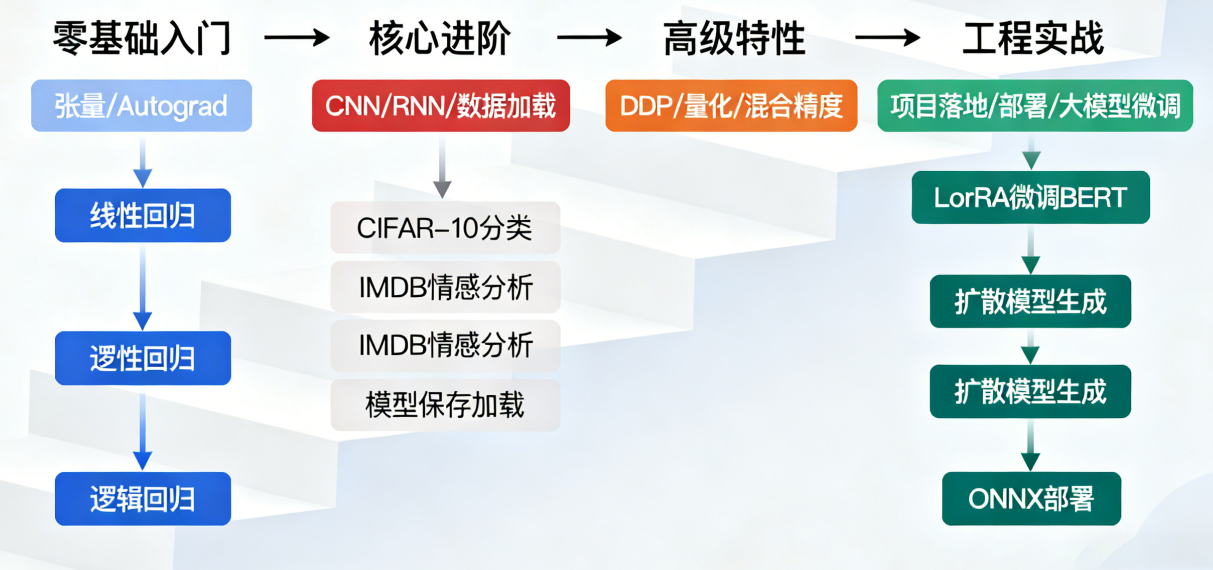
阶段一:零基础入门(1-2 周)
核心目标
掌握 PyTorch 基础语法,理解张量与自动求导核心逻辑,能实现简单数值计算与基础神经网络。
细分知识点
| 模块 | 具体内容 |
|---|---|
| 环境搭建 | 1. Anaconda/Pip 安装 PyTorch(CPU/GPU 版)2. 验证安装与 CUDA 环境配置3. PyTorch 版本兼容问题排查 |
| 张量核心 | 1. 张量创建(空 / 零 / 一 / 随机 / 从数组 / 列表创建)2. 张量属性(形状 / 数据类型 / 设备 / 维度)3. 张量变形(reshape/view/unsqueeze/squeeze/flatten)4. 张量运算(算术 / 矩阵乘 / 索引切片 / 广播 / 拼接拆分)5. 张量与 Numpy 互转、设备迁移(CPU↔GPU) |
| 自动求导 | 1. 梯度追踪(requires_grad=True)2. 反向传播(backward ())与梯度清零(zero_())3. 多变量求导、梯度禁用(no_grad ()/detach ())4. 计算图基础概念 |
| 基础网络 | 1. nn.Module 基类使用(init/forward)2. 简单层(nn.Linear)、损失函数(MSELoss)3. 优化器(SGD)与基础训练循环4. 手动实现线性回归 / 逻辑回归 |
实践任务
- 实现张量的各类操作(创建、变形、运算),输出可视化结果;
- 手动推导并实现单变量 / 多变量函数的梯度计算(验证 Autograd 结果);
- 用 PyTorch 实现线性回归(模拟带噪声的线性数据,训练并可视化拟合结果)。
验收标准
- 能独立解决张量操作的常见问题(如形状不匹配、设备不兼容);
- 理解「梯度追踪 - 反向传播 - 参数更新」的完整流程;
- 线性回归模型训练后,损失收敛至 0.1 以下,权重 / 偏置接近真实值。
阶段二:核心进阶(2-3 周)
核心目标
掌握神经网络模块化构建、数据加载、经典网络结构,能实现 CNN/RNN 等基础模型并完成经典数据集训练。
细分知识点
| 模块 | 具体内容 |
|---|---|
| 网络层与模块化 | 1. 常用层:卷积层(Conv2d)、池化层(MaxPool2d)、循环层(LSTM/GRU)、激活层(ReLU/Sigmoid)2. 网络模块化设计(子模块封装、Sequential)3. 批量归一化(BatchNorm)、Dropout 正则化 |
| 数据加载 | 1. Dataset 抽象类(自定义数据集:len /getitem)2. DataLoader 核心参数(batch_size/shuffle/num_workers/pin_memory)3. 数据预处理(torchvision.transforms)4. 经典数据集加载(MNIST/CIFAR-10/IMDB) |
| 训练体系 | 1. 损失函数:CrossEntropyLoss(分类)、BCEWithLogitsLoss(二分类)2. 优化器:Adam/AdamW(参数配置、学习率)3. 训练循环规范(前向→损失→反向→优化)4. 评估模式(eval ())与无梯度推理(no_grad ())5. 学习率调度(StepLR/ReduceLROnPlateau) |
| 经典模型 | 1. CNN:LeNet-5 / 简单 ResNet(MNIST/CIFAR-10 分类)2. RNN/LSTM:文本序列分类(IMDB 情感分析)3. 模型保存 / 加载(参数保存 / 完整模型 / 检查点) |
实践任务
- 基于 Dataset/DataLoader 自定义图像数据集(按类别分文件夹),实现数据增强;
- 搭建 CNN 模型完成 MNIST 手写数字分类,测试精度≥98%;
- 搭建 LSTM 模型完成 IMDB 情感分类,测试精度≥85%;
- 实现模型的保存、加载与断点续训。
验收标准
- 能独立处理数据加载的常见问题(如多线程报错、数据格式不兼容);
- 经典模型训练过程中,能通过调整学习率 / 批次 / 正则化解决过拟合 / 欠拟合;
- 能解释 CNN 卷积 / 池化的作用、LSTM 解决的核心问题(梯度消失)。
阶段三:高级特性(3-4 周)
核心目标
掌握 PyTorch 高级功能,理解底层原理,能解决训练效率、模型性能优化问题。
细分知识点
| 模块 | 具体内容 |
|---|---|
| 自定义扩展 | 1. 自定义层(nn.Parameter/forward 实现)2. 自定义损失函数(如 Focal Loss 解决类别不平衡)3. 自定义优化器(基础优化器扩展) |
| 训练优化 | 1. 梯度裁剪(clip_grad_norm_,解决梯度爆炸)2. 早停(Early Stopping)避免过拟合3. 混合精度训练(AMP/Autocast/GradScaler)4. 梯度累积(模拟大批次训练)5. 模型剪枝 / 量化(torch.nn.utils.prune/quantization) |
| 分布式训练 | 1. 多 GPU 训练基础(DataParallel)2. 分布式数据并行(DDP)核心流程3. 分布式采样器(DistributedSampler)4. 多机器训练入门(可选) |
| 计算图与性能 | 1. 计算图优化(避免不必要的梯度追踪)2. PyTorch 2.0 + 编译优化(torch.compile)3. 显存优化(清空缓存 / 减少中间变量)4. 训练速度调优(num_workers/pin_memory/ 数据预加载) |
实践任务
- 实现自定义 Focal Loss,解决 CIFAR-10 数据集类别不平衡问题;
- 基于 AMP 实现混合精度训练,对比显存占用与训练速度;
- 用 DDP 实现多 GPU 训练(2 卡),验证训练加速比;
- 对训练好的 CNN 模型进行剪枝 / 量化,对比精度与模型大小。
验收标准
- 能独立排查显存不足、训练速度慢的核心问题并给出优化方案;
- 混合精度训练显存占用降低≥30%,训练速度提升≥20%;
- 模型量化后精度下降≤2%,模型体积缩小≥75%;
- 理解 DDP 与 DataParallel 的核心区别,能解决分布式训练的常见报错。
阶段四:工程实战与前沿应用(2-3 周)
核心目标
掌握工业级项目规范,能落地完整项目,适配前沿技术(大模型微调 / 扩散模型),实现模型部署。
细分知识点
| 模块 | 具体内容 |
|---|---|
| 工程化规范 | 1. 标准项目结构(config/models/scripts/utils/logs)2. 配置管理(YAML/JSON)3. 日志系统(logging+TensorBoard)4. 超参数调优(Optuna/GridSearch)5. 代码版本管理(Git)、依赖清单(requirements.txt) |
| 前沿技术 | 1. 大模型微调(LoRA/QLoRA,基于 PEFT 库)2. 扩散模型基础(前向加噪 / 反向去噪 / UNet)3. Transformer 基础(自注意力 / 位置编码) |
| 模型部署 | 1. TorchScript 导出与推理2. ONNX 格式转换与验证3. ONNX Runtime 推理加速4. 简单 API 部署(FastAPI) |
| 项目落地 | 1. 需求分析与数据预处理2. 模型选型与迭代3. 评估指标(Acc/Precision/Recall/F1/MAE)4. 结果可视化与报告输出 |
实践任务
- 搭建工业级图像分类项目(ResNet + 数据增强 + 早停 + 日志 + TensorBoard);
- 用 Optuna 调优超参数,对比调优前后模型性能;
- 基于 LoRA 微调 BERT/ViT 模型(文本分类 / 图像分类);
- 实现模型的 TorchScript/ONNX 导出,并用 FastAPI 编写推理接口。
验收标准
- 项目代码符合工程规范(模块化、注释清晰、配置解耦);
- 超参数调优后模型性能提升≥5%;
- 部署后的模型推理延迟≤100ms(单张 224×224 图像);
- 能独立编写项目文档(环境搭建、训练流程、部署说明)。
阶段五:拓展进阶(可选,按需学习)
核心目标
适配特定方向的深度应用,形成技术专长。
细分方向与知识点
| 方向 | 核心内容 |
|---|---|
| 计算机视觉 | 1. 目标检测(YOLO/SSD 的 PyTorch 实现)2. 图像分割(U-Net)3. 迁移学习与预训练模型(torchvision.models)4. 数据增强库(Albumentations) |
| 自然语言处理 | 1. HuggingFace Transformers 库使用2. 文本生成(GPT/LLaMA 微调)3. 词嵌入(Word2Vec/GloVe)4. 文本预处理(Tokenizers) |
| 强化学习 | 1. 强化学习基础(DQN/PPO)2. PyTorch 实现强化学习模型3. Gym 环境交互与训练 |
| 大模型工程 | 1. DeepSpeed/FairScale 分布式训练2. 模型量化(GPTQ/AWQ)3. 大模型推理优化(vLLM) |
配套学习资源与工具
核心资源
- 官方文档:PyTorch 官网教程(https://pytorch.org/tutorials/);
- 书籍:《Deep Learning with PyTorch》《PyTorch 深度学习实战》;
- 实战平台:Kaggle(MNIST/CIFAR-10/IMDB 数据集)、HuggingFace Hub(预训练模型);
- 开源项目:PyTorch 官方 Examples、HuggingFace Transformers、PEFT。
必备工具
- 开发环境:PyCharm/VS Code + Jupyter Notebook;
- 监控工具:TensorBoard、Weights & Biases(W&B);
- 部署工具:ONNX Runtime、FastAPI、TorchServe;
- 调优工具:Optuna、PyTorch Profiler。
学习节奏与建议
- 基础优先:阶段一 / 二是核心,务必吃透张量、自动求导、训练循环,避免跳过基础直接学高级特性;
- 实践驱动:每个知识点必须配套代码实现,比如学 "卷积层" 就动手搭 CNN,学 "DDP" 就跑多 GPU 训练;
- 问题导向:遇到报错先查官方文档 / Stack Overflow/PyTorch Issues,培养独立排障能力;
- 迭代优化:同一个任务(如 MNIST 分类)反复优化(从简单 CNN→ResNet→混合精度→量化),加深理解;
- 阶段验收:完成每个阶段的 "验收标准" 后再进入下阶段,避免 "似懂非懂"。
下一篇具体以代码示例开展具体学习。当然,功夫在课外。。。