本文共 1906 字,阅读预计需要 4 分钟。
Hi,你好,我是Carl,一个本科进大厂做了2年+AI研发后,裸辞的AI创业者。
今早,一个月内第三个号称"地表最强" 的模型发布了,OpenAI的GPT-5.2 ,官方定位是"最强大的专业知识工作模型"。
看腻了那些复杂的跑分和论文,我此刻更想在一个最朴素的场景下,试试这些"王炸"们的成色。
提示词非常简单,
"你是一个资深全栈游戏开发工程师。请在当前目录下创建一个新文件夹,写一个火柴人第一人称射击游戏,并直接帮我完成所有构建工作。"
三分钟,代码生成完毕。我启动服务,打开浏览器,屏幕上确实出现了一个火柴人,手里也确实拿着枪,也确实能攻击周围的敌人。
但我晃动鼠标,发现它开始在屏幕上左右射击,像一个比魂斗罗还要古早的横屏射击游戏。
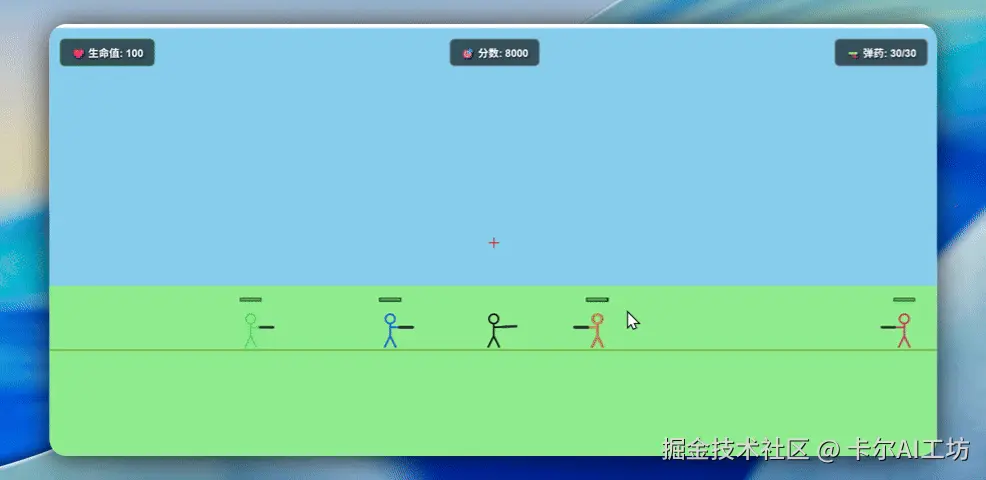
说好的第一人称射击呢?这明明是个横版第三人称游戏啊!
那一刻我意识到一个被由于过度营销而掩盖的真相,参数量再大,听不懂人话也是白搭。
于是我准备不看跑分,不看论文,试试各个模型,就看谁能真正帮我把这个游戏做出来。
亲历:当"全能神"听不懂人话
这次规则非常简单粗暴,还原最真实的"懒人开发"场景:
-
环境:VS Code + Copilot 插件。
-
提示词:统一使用上文中,与GPT 5.2相同的一段 Prompt。
-
干涉:零干涉。不解释,不修 Bug,生成什么跑什么。
尝试的模型除了刚才翻车的 GPT 5.2,还有 Google 的 Gemini 3,Anthropic 的 Opus 4.5,以及 OpenAI 自家的两个偏科生:GPT 5.1 Codex 和 GPT 5.1 Codex Max。
战况:谁才是真正的程序员?
如果把这几个模型比作你的同事,他们的画风是这样的:
Gemini 3:稳重的老干部
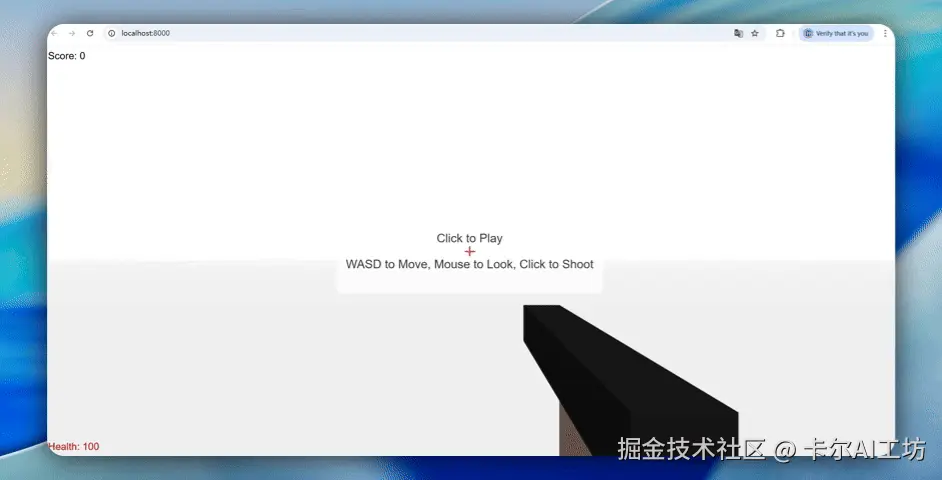
Gemini 3 是那个让你最放心的老员工。
它写得最慢,磨蹭了 5 分钟。生成的项目结构也最简单:game.js,index.html,style.css,外加一个内容很简单的 README,只讲如何启动。
但是,它跑起来了。
没有花哨的特效,界面简陋得像 90 年代的 Flash 游戏,颜色也是最基础的黑白灰。但它稳稳当当地执行了"第一人称射击"的指令,没有报错,没有崩溃。
这个简单的界面倒是与它多模态之神的标签不符,不过也是因为在copilot的环境里它获取上下文和渲染的能力受限,并不能释放Google AI Studio的原生环境里的能力。
在文章末尾,我加上了Gemini3在Google AI Studio中的表现。"主场作战"形态的Gemini3,依然是最均衡、最稳定的那个。
Opus 4.5:偏科的设计师
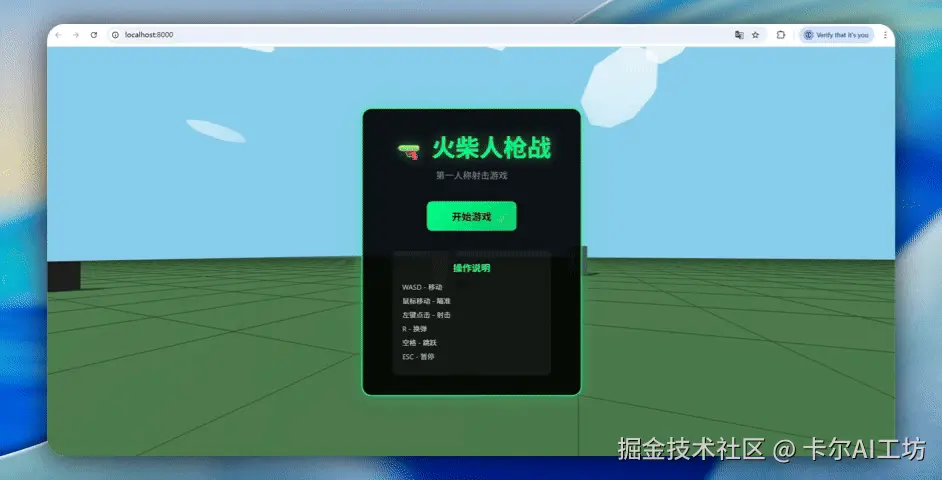
Opus 4.5 则是那个很前卫的设计师。
它速度很快,也是3分钟完成构建,也是简单的三个游戏文件。
打开游戏的一瞬间,我也确实被惊艳到了:丰富的配色,细腻的 UI 风格,甚至启动界面是动态的。
但当我按下鼠标左键开火时,每次开火,屏幕都会疯狂闪烁。也许这是它独到的设计?
GPT 5.1 Codex:不修边幅的后端程序员

这才是真正的"扫地僧"。
GPT 5.1 Codex 交出的作业,让我看到了专业程序员的影子。看看这个文件结构:
enemies.jsgame.jsstickman.jsutils.jsweapons.js- ...
它是唯一一个知道要把"敌人"、"武器"、"工具函数"拆分成独立模块的模型。生成的 README 文档也最长、最详细。
甚至每次开枪射击也是有音效的,即使很难听。
运行游戏,典型的程序员审美,界面丑得令人发指,但打击感是最好的。子弹的弹道、敌人的反馈,都像模像样。
它不修边幅,不善言辞,但它是唯一一个真正懂"软件工程"的家伙,构建的项目也是最完整的。
GPT 5.1 Codex Max:走火入魔、急于证明自己的____
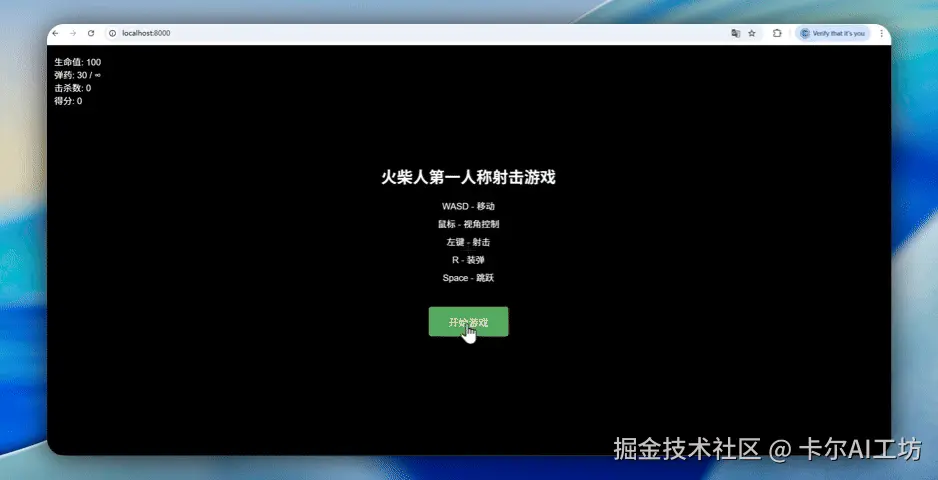
它没能交出一个能正常运行的项目。画面错乱,鼠标控制也是反的(鼠标左移,视角右转)
它想得太多了。它试图引入更复杂的物理引擎和交互逻辑,结果导致了灾难性的后果,甚至连敌人模型都加载不出来。
这就是典型的"过度工程"。为了炫技,把最基础的可用性搞丢了。
盲区与反思:Copilot 的"中间商差价"
这里必须帮 Gemini 3 说句公道话。
我在 VS Code 的 Copilot 里调用它,效果肯定远不如它在自家主场 Google AI Studio 里表现得好。
IDE 插件往往会对 Prompt 进行一层包装,或者受限于上下文窗口的截断,导致模型发挥受限。
所以,我又在Google AI Studio里构建了一次,呈现的效果完全不同:
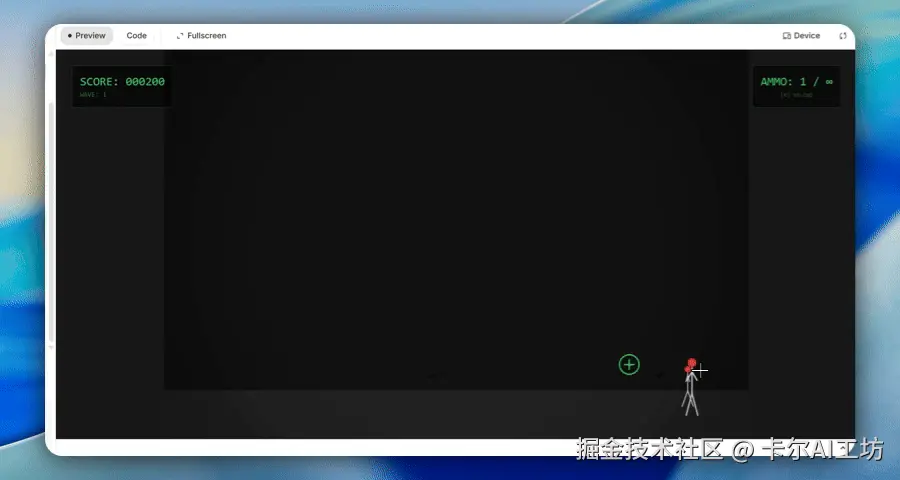
震动效果、音效,交互感,远胜于copilot下的Gemini3,也比其它的模型的完成度高得多。
风险:迷信"最新版"的代价
这次测试倒是给了我一个不一样的审视最新模型的视角,也许,在 AI 编程领域,最新 ≠ 最好,Max ≠ 最强。
很多团队在做技术选型时,习惯性地把所有业务都切到最新模型上,结果往往是成本飙升,效果却不升反降。
也许,当下模型的能力正在逐步靠近瓶颈期,"更新换代"所带来的提升正在逐步减少,上下文工程的重要性越来越大。
结语:几个落地建议
1. 过度推理的陷阱:
像 GPT 5.1 Codex Max 这种"聪明过头"的模型,很容易在简单任务上加戏。
对策:对于 CRUD 或基础逻辑代码,强制指定使用参数量较小、针对代码微调过的版本(如 Codex 基础版)。
2. 指令遵循的随机性:
强如 GPT 5.2 也会把 FPS 做成横版游戏。
对策:不要过度迷信"一句话生成",将复杂需求拆解为 Step-by-Step 的原子指令。先让它写大纲,确认理解无误后,再让它写代码。
3. "各取所长":
尝试"组合拳"。用 Codex 写后端逻辑和核心算法与任务规划,让Gemini3来干活或者做前端的设计。
总之,无论 AI 多强,永远保留人工 Review 的环节。毕竟,它可能连左右都分不清。
我是Carl,我们下期再见。