服务器存储数据恢复环境&故障:
某存储设备中一共有40块磁盘组建存储池,其中4块磁盘作为全局热备盘使用。存储池内划分出若干空间映射到服务器使用。
服务器存储设备在没有断电、进水、异常操作、供电不稳定等外部因素的情况下突然崩溃。管理员重启服务器后无法进入操作系统,数据丢失。
服务器存储数据恢复过程:
1、将故障存储中所有硬盘做好标记后取出,以只读方式进行完整硬盘镜像。镜像完后把所有磁盘按照编号还原到原存储设备中,后续的数据分析和数据恢复操作都基于镜像文件进行,避免对原始磁盘数据造成二次破坏。
2、基于镜像文件分析所有磁盘的底层数据,北亚企安数据恢复工程师发现所有磁盘是通过ZFS进行管理,磁盘内记录系统元信息的NVLIST较为混乱。需要恢复数据的磁盘分为三组,每组12块;单个组使用ZFS特有的RAIDZ管理所有磁盘;RAIDZ级别为2,即每个组内可缺失磁盘个数最大为2;全局热备盘全部启用。
Tips:在ZFS文件系统中,池被称为ZPOOL。ZPOOL的子设备可以有很多种类:块设备、文件、磁盘等。本案例中的子设备为三组RAIDZ。
经过分析发现,三组RAIDZ中的两组RAIDZ启用热备盘个数分别为1和3。启用热备盘后,第一组RAIDZ又有一块离线盘,第二组RAIDZ内则又有两块盘离线。
故障模拟:三组RAIDZ内第一和二组RAIDZ中有磁盘离线,热备盘自动上线进行替换;热备盘无冗余情况下第一组RAIDZ中有一块盘离线,第二组RAIDZ中有两块盘离线,ZPOOL进入高负荷状态(每次读取数据都需要进行校验得到正确数据);由于第二组RAIDZ内有三块盘离线,该组RAIDZ崩溃、ZPOOL下线、服务崩溃。
3、ZFS管理的存储池与常规存储不同。ZFS管理的存储池中所有磁盘都由ZFS进行管理。常规RAID在存储数据时,只按照特定的规则组建池,不关心文件在子设备上的位置;而ZFS在存储数据时会为每次写入的数据分配适当大小的空间,并通过计算得到指向子设备的数据指针。这种特性决定了RAIDZ缺盘时无法直接通过校验得到数据,必须将整个ZPOOL作为一个整体进行解析。
北亚企安数据恢复工程师手工截取事务块数据,并编写程序获取最大事务号入口。
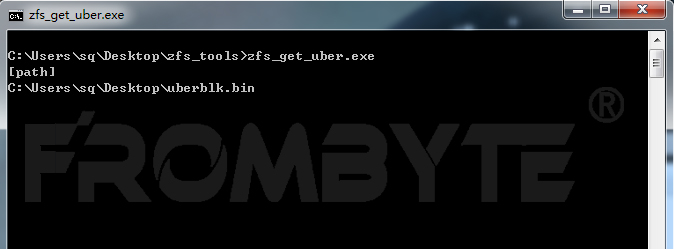
4、获取到文件系统入口后,北亚企安数据恢复工程师编写数据指针解析程序进行地址解析。
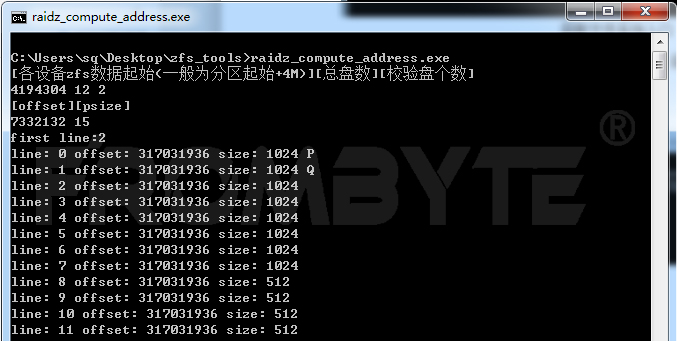
5、获取到文件系统入口点在各磁盘分布情况后,北亚企安数据恢复工程师手工截取并分析文件系统内部结构。入口分布所在的磁盘组无缺失盘,可直接提取信息。数据恢复工程师根据ZFS文件系统的数据存储结构找到映射的LUN名称,从而找到其节点。
6、经过分析,数据恢复工程师发现在此存储中的ZFS版本与开源版本有较大差别,无法使用以前开发的解析程序解析,所以北亚企安数据恢复工程师重新编写了数据提取程序提取数据。
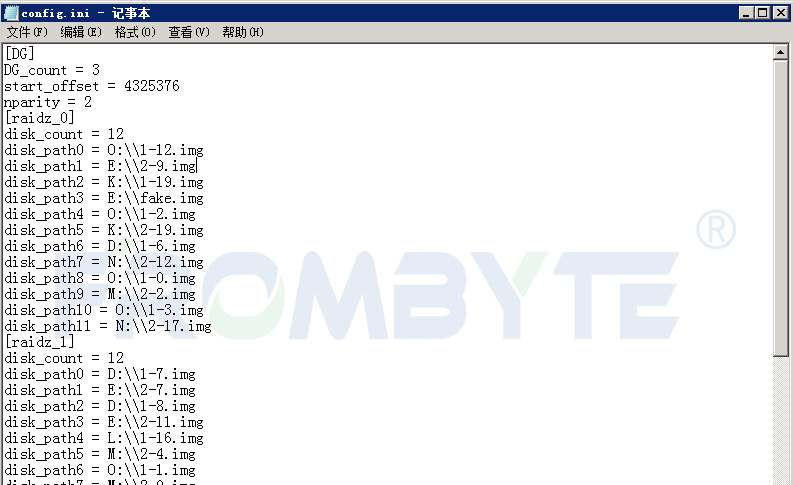
由于磁盘组内缺盘个数较多,每个IO流都需要通过校验得到,提取进度极为缓慢。与用户方沟通后得知,此ZVOL卷映射到XenServer作为存储设备,需要恢复的文件在其中一个vhd内。提取ZVOL卷头部信息,按照XenStore卷存储结构进行分析,发现该vhd在整个卷的尾部,计算得到其起始位置后从此位置开始提取数据。
7、Vhd提取完毕后,验证其内部的压缩包及图片、视频等文件,均可正常打开。
8、用户方验证数据后,确定恢复出来的文件数量与系统自动记录的文件个数基本一致,文件全部可正常打开。本次数据恢复工作完成。