对于任何需要维护超大表(更新旧数据、分批删除、数据迁移)的 DBA 或开发者来说,使用 ctid(元组物理位置)将大表切分为多个小块进行处理是标准操作。然而,直到现在,这种操作都有一个巨大的痛点:它严格依赖单进程。
随着最近的一个 Commit (0ca3b169) 合并入 PostgreSQL 19 (master 分支),TID 范围扫描(TID Range Scans)终于支持并行了。
该功能由瀚高的 Cary Huang 提出并主导开发,由微软的 David Rowley 协助测试及审阅,并最终提交。他们密切合作以完善并行安全逻辑,确保工作进程正确处理扫描限制------最终促成了这个落地到 master 分支的健壮实现。
瀚高以"用开源链接世界"为使命,强调开源技术在数据库基础软件领域的核心作用,致力于通过共享和合作,推动行业发展,同时链接和赋能全球用户。开源技术是中国软件技术发展的必由之路,瀚高作为亚太地区 PostgreSQL 国际社区顶级贡献者之一,长期深度参与 PostgreSQL 国际社区发展与建设。自 2025 年 7 月以来,瀚高被 PostgreSQL 社区采纳的贡献就已超过 2000 行代码。
根据基准测试,新特性的速度提升高达 3 倍。
1. 核心痛点:规划器(Planner)的权衡
Postgres 自版本 14 起就支持了 TID Range Scans。这允许你基于物理块号扫描表的特定切片:
SELECT * FROM my_large_table WHERE ctid >= '(0,0)' AND ctid < '(10000,0)';
这是像 AWS DMS 这样的工具或逻辑复制初始化器拆分海量表的标准方式。问题在于,直到现在这种扫描节点严格来说都是单工作进程(single worker) 的。
这迫使 Postgres 查询规划器陷入了两难境地。当你在大数据集上运行查询时,规划器必须在以下两者之间做出选择:
-
TID Range Scan: I/O 高效(只读取你请求的块),但是单工作进程。
-
Parallel Seq Scan(并行顺序扫描): CPU 高效(占用所有 CPU 内核),但 I/O 浪费(可能会为了过滤而读取超出你范围的块)。
规划器经常会错误地选择并行顺序扫描,CPU 收益似乎超过了 I/O 损耗带来的负面影响。这导致数据库为了利用可用的工作进程,读取了比必要多得多的数据。
2. 修复方案:并行性与可变分块
由 Cary Huang 开发并由 David Rowley 提交的代码,引入了允许 Tid Range Scan 参与并行查询计划的基础架构。该逻辑有效地将块范围分配给可用的并行工作进程。不再是一个进程从块 0 扫描到 N,多个工作进程可以并发地获取数据块。
实现(约 500 行代码)重用了并行顺序扫描中的"块分块(block chunking)"逻辑。但它不仅仅是将块范围平均分配给工作进程,因为如果表的某个部分数据密度更高,这种简单分配可能导致负载不均衡。
相反,它使用了衰减块大小策略 (decaying chunk size strategy):
- 大块开始 (Large Start): 工作进程开始时领取大块的块,以最大限度地减少共享状态上的锁定开销。
- 逐渐减小 (Tapering Down): 随着扫描的进行,分块大小会缩小。
- 颗粒化结束 (Granular Finish): 到扫描结束时,工作进程每次只领取 1 个块。
这种"缓慢减少"确保了我们不会最后只剩下一个工作进程在处理一个巨大的最终块,而其他工作进程却闲置着。它强制所有进程大致在同一时间跨过终点线。
3. 基准测试数据
为了看到实际效果,我创建了一个包含 1000 万行的表 bench_tid_range,并使用 ctid 范围条件对表的前 50% 运行了 count(*) 查询。
测试环境:
- 数据量:1000 万行
- 查询:
SELECT count(*) FROM bench_tid_range WHERE ctid >= '(0,0)' AND ctid < '(41667,0)'
| 环境 | 工作进程数 (Workers) | 执行时间 (中位数) | 加速比 |
|---|---|---|---|
| Before (Pg 18) | 0 | 448 ms | 1.00x |
| After (Pg 19) | 0 | 435 ms | 1.03x |
| After (Pg 19) | 1 | 238 ms | 1.88x |
| After (Pg 19) | 2 | 174 ms | 2.58x |
| After (Pg 19) | 3 | 151 ms | 2.97x |
| After (Pg 19) | 4 | 150 ms | 2.98x |
| After (Pg 19) | 5 | 147 ms | 3.05x |
| After (Pg 19) | 6 | 143 ms | 3.14x |
| After (Pg 19) | 7 | 147 ms | 3.04x |
| After (Pg 19) | 8 | 147 ms | 3.04x |
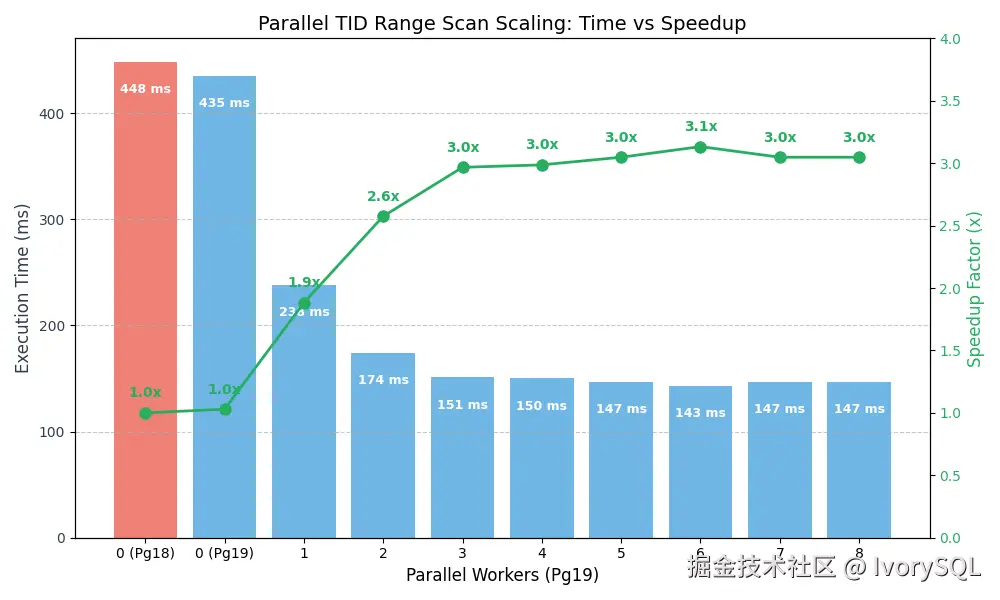
我们可以看到,仅仅启用 1 个工作进程(这实际上给了我们 2 个扫描进程:Leader + 1 个 Worker),执行时间就大幅下降。对于这个特定的工作负载,"最佳平衡点"似乎在 2-3 个工作进程左右。
4. 为什么不直接用"并行顺序扫描"?
你可能会问:"为什么 Postgres v18 不直接选择并行顺序扫描?用 4 个工作进程扫描整个表难道不比用 1 个进程扫描半个表快吗?"
我通过强制设置 enable_tidscan = off 并使用 4 个工作进程测试了这一点:
- 执行时间: ~230 ms。
- I/O: 访问了所有 ~83k 个页面。
新的并行 TID 范围扫描(~150 ms)仍然比暴力/强制的并行顺序扫描快 35%,而且它产生的 I/O 负载只有后者的一半(只访问了 ~41k 个页面)。这可谓两全其美:快速的执行时间(并行)和高效的资源使用(类似索引的范围界定)。
5. 这对工具意味着什么
如果你维护在 Postgres 实例之间移动数据的内部脚本,你可能编写了手动计算块范围并将巨大的表划分为块、然后生成进程来运行它们的代码。
随着 PostgreSQL 19 的推出,这种复杂性可能可以被删除了。你可以发出更广泛的 TID 范围查询,并相信规划器会有效地在集群的 I/O 和 CPU 资源之间分配工作。
6. 如何复现测试
这是设置测试表和运行基准测试的 SQL:
sql
-- 1. 创建表
DROP TABLE IF EXISTS bench_tid_range;
CREATE TABLE bench_tid_range (id int, payload text);
-- 2. 插入 10M 行以生成 ~41k 个页面
INSERT INTO bench_tid_range
SELECT x, 'payload_' || x
FROM generate_series(1, 10000000) x;
-- 3. Vacuum 以设置可见性映射并冻结(对于稳定的基准测试很重要)
VACUUM (ANALYZE, FREEZE) bench_tid_range;
-- 4. 为会话启用并行
SET max_parallel_workers_per_gather = 4; -- 尝试 2, 4, 8
SET min_parallel_table_scan_size = 0; -- 即使对于较小的表也强制并行扫描
-- 5. 运行查询
EXPLAIN (ANALYZE, BUFFERS)
SELECT count(*)
FROM bench_tid_range
WHERE ctid >= '(0,0)' AND ctid < '(41667,0)';7. 结论
这是一项令人欣喜的"底层"改进。它或许不会改变您日常的临时查询,但对于构建自定义数据维护脚本的数据库管理员和开发人员而言,并行执行基于 TID 的扫描功能是优化工具包中一项强大的新工具。
8. 参考
本文部分内容是来自 Grant Zhou 和 Robins Tharakan 撰写的英文博客。