1. 引言
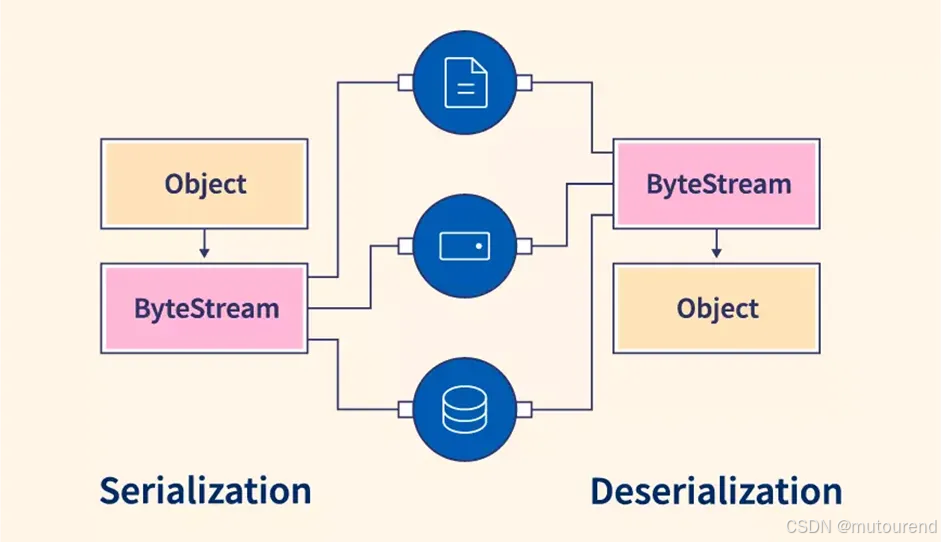
在现代嵌入式系统中,微控制器常常需要与 PC、智能手机或云服务交换结构化数据。这可能是遥测数据、配置参数或传感器读数。挑战在于,这些平台使用不同的编程语言和环境,而微控制器的 RAM 和闪存非常有限。为了使通信可靠且可移植,原始数据必须转换为结构化、与机器无关的格式------这个过程称为序列化。
2. 何为序列化?
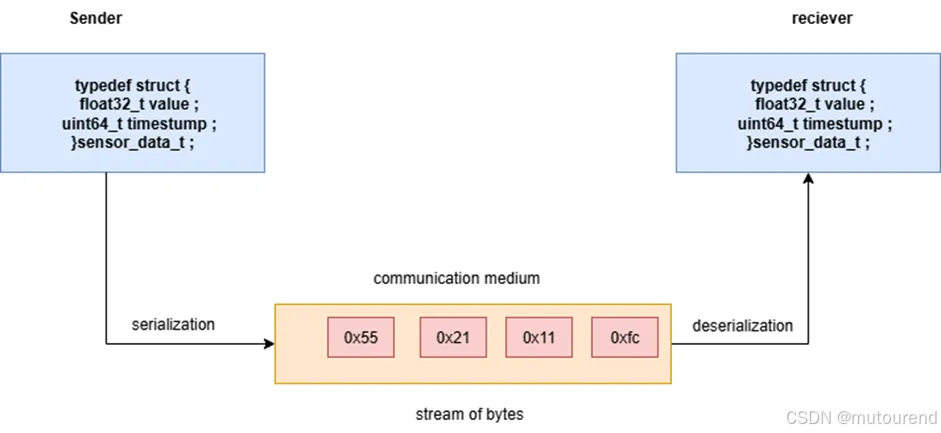
序列化是将结构化数据(如带有时间戳和值的传感器读数)转换为可移植字节流的过程,这些字节流可以通过串行连接、网络套接字或无线信道发送。在接收端,数据会被反序列化回原始结构。
简单方法,比如直接发送原始字节,在不同处理器、字节序或编程语言环境下往往会失败。标准化的序列化方法可以确保设备间兼容性和长期可维护性。
以下为序列化/反序列化示例:
3. Protobuf 与嵌入式困境
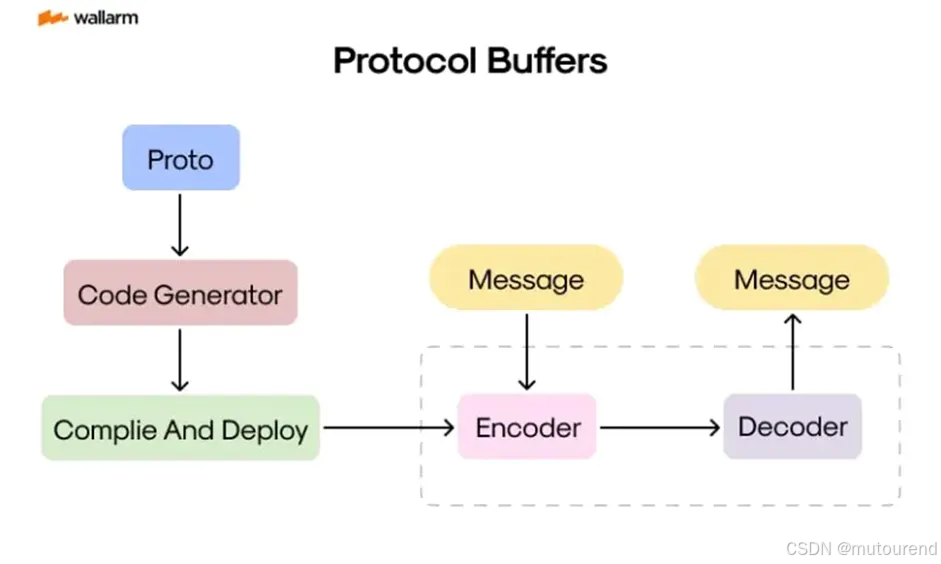
Protocol Buffers(简称 Protobuf)是现代软件中最广泛使用的序列化格式之一。它与语言无关、平台独立,并提供成熟的工具链:
- 在
.proto文件中定义消息,运行编译器,即可得到可直接使用的 C++、Java、Python 或 Go 代码。
这使得Protobuf非常适合需要跨平台交换结构化数据的系统。
以下为protobuf工作流示意图:
问题出现在试图将标准 Protobuf 引入深度嵌入式系统时。官方实现是针对服务器和移动设备设计的,这些平台可以接受动态内存分配和相对较大的代码体积。在只有几十 KB RAM 和闪存的小型 MCU 上,庞大的运行时、动态分配以及对 C++ 的依赖成为了显著障碍。即使设法适配,性能也可能下降,因为在实时环境中内存分配和解析开销很高。
这种不匹配通常被称为"嵌入式困境"。Protobuf 优雅地解决了数据交换问题,但其默认实现对于许多微控制器而言资源消耗过大。因此,开发者需要更轻量的替代方案,在兼容 Protobuf 生态的同时,满足嵌入式硬件的约束条件。
4. 嵌入式友好选项:Nanopb
将 Protobuf 引入小型设备的最流行方案之一是 Nanopb(https://github.com/nanopb/nanopb)。它是一个微型 C 库,可以直接从 .proto 文件生成代码,同时避免了标准 Protobuf 实现中的庞大运行时。与完整版不同:
- Nanopb 不使用动态内存,而是通过静态缓冲区处理所有内容。
- 这使得内存使用可预测且安全,对于资源紧张的 MCU 至关重要。
使用流程非常简单。在 .proto 文件中定义好数据结构,运行 Nanopb 的生成器,然后将生成的 C 代码包含到固件中。在微控制器端,填充结构体,调用编码器生成字节流,并通过选定的通信方式发送。在主机端,相同的字节流可以通过任何标准 Protobuf 库解码,从而确保跨平台兼容性。
Nanopb 被广泛采用,因为其实现了恰当的平衡:
- 对于只有几 KB RAM 的 32 位 MCU 足够轻量,同时仍保持与 Protobuf 生态系统的兼容。
如,假设希望发送包含时间戳和传感器读数的遥测数据。首先在 .proto 文件中描述结构,如:
proto
message Telemetry {
uint32 timestamp = 1;
float value = 2;
}运行 Nanopb 生成器后,会产生两个文件(telemetry.pb.c 和 telemetry.pb.h),定义了 C 结构体和编码/解码函数。在 MCU 代码中,包含这些文件,填充 Telemetry 结构体,并使用 Nanopb 的 API 进行消息序列化和反序列化:
c
/** Encode Telemetry message */
Telemetry msg = Telemetry_init_zero;
msg.timestamp = get_time();
msg.value = read_sensor();
uint8_t buffer[64];
pb_ostream_t stream = pb_ostream_from_buffer(buffer, sizeof(buffer));
if (pb_encode(&stream, Telemetry_fields, &msg)) {
send_uart(buffer, stream.bytes_written);
}
/** Decode Telemetry message */
Telemetry recv_msg = Telemetry_init_zero;
pb_istream_t istream = pb_istream_from_buffer(buffer, stream.bytes_written);
if (pb_decode(&istream, Telemetry_fields, &recv_msg)) {
printf("Time: %u, Value: %f\n", recv_msg.timestamp, recv_msg.value);
}以上这个小示例展示了完整的工作流程:
- 填充结构体,
- 将其编码为字节,
- 传输,
- 然后在另一端将其解码回相同的结构。
Nanopb在 MCU 上保持通信高效,同时在更大系统上仍然完全兼容 Protobuf。
另一个值得注意的选项是 upb(https://github.com/protocolbuffers/protobuf/tree/main/upb),这是一个轻量级的 C 实现,现在已成为官方 Protobuf 项目的一部分。它提供高效的解析和编码,内存使用比完整的 C++ 运行时更低,非常适合资源比最小 MCU 多但仍需要精简代码的中端设备。对于希望在保持嵌入式友好的同时,实现与上游 Protobuf 更接近的功能特性的项目,upb 提供了一个可靠的替代方案。
5. 结论
序列化是让嵌入式设备与 PC、手机和云系统"讲同一种语言"的关键。虽然完整的 Protobuf 对小型 MCU 来说过于庞大,但像 Nanopb 这样的轻量级库以最小的开销带来了相同的好处。通过在 .proto 文件中一次性定义消息并跨平台共享,开发者可以获得可靠、可维护的通信,而无需重新发明协议。
参考资料
1 Wadix Technologies 2025年9月博客 From MCU to Cloud: Lightweight Serialization with Nanopb