比起君子讷于言而敏于行,我更喜欢君子善于言且敏于行。
目录
[一、为什么选 Rook?](#一、为什么选 Rook?)
[二、Rook 低层原理(必须理解的组件)](#二、Rook 低层原理(必须理解的组件))
[1. CRD(CustomResourceDefinition)------抽象出"Ceph 资源"](#1. CRD(CustomResourceDefinition)——抽象出“Ceph 资源”)
[2. Rook Operator(核心自动化大脑)](#2. Rook Operator(核心自动化大脑))
[3. Ceph Daemons(真正干活的)](#3. Ceph Daemons(真正干活的))
[三、Rook 架构图](#三、Rook 架构图)
[四、 Rook 需要哪些 YAML(这是最重要的部分)](#四、 Rook 需要哪些 YAML(这是最重要的部分))
[1. 部署 Rook 控制面(CRD + Operator)](#1. 部署 Rook 控制面(CRD + Operator))
[2. 部署 Ceph 集群(跟硬盘有关)](#2. 部署 Ceph 集群(跟硬盘有关))
[3. 可选的(按需创建)](#3. 可选的(按需创建))
前言
想在k8s集群中使用ceph,应该怎么做呢?使用Rook
**一、**为什么选 Rook?
裸 Ceph 是给 2010 年代裸机/虚拟机环境设计的,Rook 是给 2020 年代 Kubernetes 时代而生的 Ceph。Rook 不是存储系统,它只是 Ceph 的自动化运维系统(Operator)。
Rook 只需要你:写 yaml 、 Apply、 让 Operator 自动 reconcile。然后所有组件自动出现、自动扩容、自动修复。
它的唯一作用:让 Ceph 能以 Kubernetes 原生方式运行、扩容、自愈,硬盘自动接管
Ceph = 真正存储
Rook = Ceph 的大脑 + 自动驾驶仪
K8s = 环境 + 编排
二、Rook 低层原理(必须理解的组件)
1. CRD(CustomResourceDefinition)------抽象出"Ceph 资源"
Rook 把 Ceph 的东西全部抽象成 Kubernetes API 对象:
| Ceph 组件 | Rook 的 CRD |
|---|---|
| 整个 Ceph 集群 | CephCluster |
| 存储池 | CephBlockPool |
| 文件系统 CephFS | CephFilesystem |
| OSD 存储设备 | CephCluster.storage.devices |
| Mgr / Mon | CephCluster.mgr / mon |
| RBD StorageClass | StorageClass |
| RGW/对象存储 | CephObjectStore |
Rook 让 Kubernetes 本身能够理解"Ceph 这个东西"。
2. Rook Operator(核心自动化大脑)
Operator 是一个永远处于 "observing → reconciling → fixing" 的控制回路:
CRD YAML 变化 → Operator 看到了
↓
Operator 生成 Ceph 配置 / 命令
↓
Operator 创建相应的 Pod、OSD、mon、mgr
↓
确保状态达到你 YAML 要的样子它会 一直监控:
-
Ceph 守护进程是否运行
-
MON quorum 是否健康
-
OSD 是否 down / out
-
新硬盘是否出现
-
节点是否加入/退出集群
你只写 YAML → 其它全部 Operator 负责。这就是 Kubernetes 的 operator 模式。
3. Ceph Daemons(真正干活的)
在容器里跑真正的 Ceph 服务:
| 组件 | 作用 |
|---|---|
| ceph-mon | 整个集群的脑,维护 map |
| ceph-mgr | Dashboard、Prometheus、Orchestrator 模块 |
| ceph-osd | 管 HDD/SSD(你的 8T/2T) |
| ceph-mds | CephFS 的 namespace server |
| ceph-rgw | S3 网关(可选) |
Rook 帮你管理它们,但它们本身就是原生 Ceph。
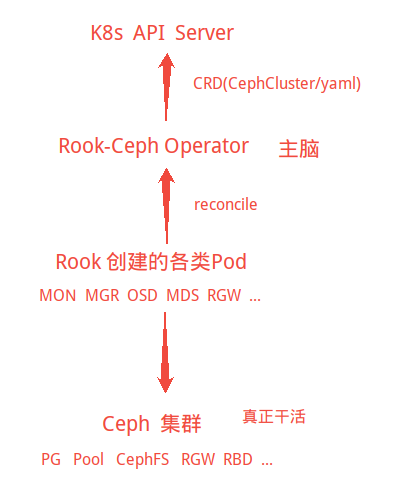
三、Rook 架构图
**CRD:**让 Kubernetes"知道"什么是 Ceph(像提供新 API)
**Operator:**看 YAML → 生成 Pod → 控制 Ceph(自动化运维系统)
**Ceph 容器:**真正的存储系统
四、 Rook 需要哪些 YAML(这是最重要的部分)
1. 部署 Rook 控制面(CRD + Operator)
这一步是所有集群通用的,不涉及磁盘。
通常有三个文件(只需 apply 一次):
| 文件 | 作用 |
|---|---|
crds.yaml |
定义 CephCluster / CephBlockPool / CephFilesystem 等 CRD |
common.yaml |
RBAC、namespace、service accounts |
operator.yaml |
Operator 主体,负责启动大脑 |
📌 执行这 3 个文件后,集群不包含任何 Ceph,只是"准备好 Ceph 的大脑"
**2.**部署 Ceph 集群(跟硬盘有关)
这是最核心的 cluster.yaml。这个文件明确告诉 Rook:
-
Ceph 要在哪里跑
-
要启用哪些模块
-
如何使用你的硬盘
-
有几个 MON
-
是否开启 dashboard
-
是否使用 SSD 作为 WAL/DB
📌 这个 YAML = 整个 Ceph 的定义
OSD 出现与否、设备如何使用,都在这里。
3. 可选的(按需创建)
| YAML | 作用 |
|---|---|
CephFilesystem |
创建 CephFS,自动部署 MDS |
CephBlockPool |
创建 RBD 池 |
StorageClass |
给 K8s PVC 提供 Ceph RBD/FS 卷 |
CephObjectStore |
S3 服务 |
CephObjectStoreUser |
创建 S3 用户 |
未来最常用的是:
-
CephFS(共享文件存储)
-
RBD(持久化块存储)
五、各个yaml的作用
| YAML | 属于 Rook 哪一层? | 它控制什么? | 什么时候 apply? |
|---|---|---|---|
crds.yaml |
k8s API | 定义 Ceph 的所有资源类型 | 第一次部署 Rook 时 |
common.yaml |
RBAC | 权限、ServiceAccount、Namespace | 第一次部署 Rook 时 |
operator.yaml |
Rook 大脑 | Operator 的 Pod & Controller | 第一次部署 Rook 时 |
cluster.yaml |
你的集群定义 | MON/OSD/MGR、磁盘分配、网络 | 有 HDD 时执行 |
filesystem.yaml |
CephFS | 创建 MDS + Pool + FS | Ceph 集群 ready 后 |
block-pool.yaml |
RBD | RBD 池(给 PVC 用) | 需要块存储时 |
storageclass.yaml |
K8s SC | PVC 自动绑定 Ceph | 做持久化卷时 |
objectstore.yaml |
RGW | Swift/S3 接口 | 做 S3 时 |
**注意:cluster.yaml优先级最高。**crds.yaml、common.yaml、operator.yaml只负责"让 Rook 自己跑起来"。Ceph 集群的实际配置永远以cluster.yaml 为准。所以首次run的时候可以直接用官方的模板
六、操作命令
bash
# 安装调试工具(非必须但推荐)
sudo apt install -y lvm2 ceph-common jq
#下载适合k8s1.21的版本,主要是用examples
cd /home/ubuntu
git clone --single-branch --branch v1.11.9 https://github.com/rook/rook.git
cd rook/deploy/examples
# 部署 CRDs + common + operator(上一步已cd,这一步用的是需要用examples里面的yaml)
kubectl create namespace rook-ceph
kubectl apply -f crds.yaml -f common.yaml -f operator.yaml
# 验证,有点儿耐心,等一下,拉取镜像需要时间。这一步之后,集群里已经"认识 Ceph 这个东西"了。
kubectl -n rook-ceph get pods
#准备好适合自己的cluster.yaml
kubectl apply -f cluster.yaml
#这个镜像总是无法自动拉取,不清楚为什么,可以先手动拉一下
sudo docker pull rook/ceph:v1.11.9
#这次应该能看到:rook-ceph-mon-* rook-ceph-mgr-* ,耐心等一等
kubectl -n rook-ceph get pods
# 验证
kubectl -n rook-ceph get pods -o wide
# 看看dashboard,UI页面
kubectl -n rook-ceph get svc | grep dashboard
kubectl -n rook-ceph get pod -l app=rook-ceph-mgr -o wide
#让系统自动分配一个 30000-32767 端口
kubectl -n rook-ceph patch svc rook-ceph-mgr-dashboard -p '{"spec":{"type":"NodePort"}}'
#查看一下分到了哪个端口,进行ip+端口访问即可
kubectl -n rook-ceph get svc rook-ceph-mgr-dashboard总结
重点还是搞清楚yaml,基本上就不会有什么问题。后续我会再整理cluster.yaml的详细内容分析,彻底吃透它。