基于深度学习的文物图像修复系统
1. 项目背景与意义
文物是人类文明的瑰宝,但随着时间的推移,许多文物(如壁画、古画、照片等)不可避免地遭受了自然风化、虫蛀、霉变或人为损坏,导致出现了裂缝、污渍、缺失等问题。传统的人工修复往往需要耗费大量的时间和人力成本,且对修复师的技艺要求极高。
本项目旨在利用计算机视觉 和深度学习技术,构建一个自动化的文物图像修复系统。通过学习大量文物图像的纹理和结构特征,算法能够智能地推断并填补缺失区域,不仅能提高修复效率,还能为文物保护工作提供有力的辅助工具。
2. 核心算法原理 (Core Algorithms)
本系统集成了从基础到前沿的三代图像修复算法,分别适用于不同的修复场景。
2.1 数据预处理:自监督学习范式
深度学习模型需要大量的"成对数据"进行训练(即:受损图像 -> 完整图像)。在现实中,我们很难找到同一文物受损前后的完美对应照片。因此,我们采用自监督学习 (Self-Supervised Learning) 的策略:
- 数据源:收集完整的高质量文物图像或老照片作为"真值" (Ground Truth)。
- 模拟损坏 :在训练过程中,动态地在完整图像上覆盖随机生成的掩码 (Mask) 。
- 掩码区域像素被置为 0(黑色)或噪音,模拟文物缺失。
- 掩码形状包括:随机矩形(模拟大块缺失)、随机线条(模拟划痕裂缝)。
- 输入与输出:模型的输入是"受损图像"和"掩码",目标是输出与"完整图像"尽可能一致的结果。

图解 :数据集样本可视化
- 第一行 (Masked Image):输入模型的受损图像。黑色块代表缺失区域,这些区域的信息对于模型是完全未知的。
- 第二行 (Ground Truth):对应的原始完整图像。模型需要学习如何从第一行的残缺信息中,"猜"出第二行的完整内容。
2.2 第一代模型:改进型 CNN-UNet
原理 :
U-Net 是一种经典的编码器-解码器 (Encoder-Decoder) 结构,最初用于医学图像分割,后被证明在图像生成任务中表现优异。
- 编码器 (Encoder):通过一系列卷积层 (Convolution) 和下采样层 (Downsampling),逐步提取图像的抽象特征(如轮廓、形状、语义),同时降低图像分辨率。
- 解码器 (Decoder):通过上采样 (Upsampling) 逐步恢复图像分辨率,将抽象特征还原为像素细节。
- 跳跃连接 (Skip Connections):这是 U-Net 的灵魂。它将编码器每一层的特征图直接"复制拼贴"到解码器的对应层。这解决了深层网络容易丢失纹理细节的问题,使得修复结果既有准确的结构,又有清晰的边缘。
改进点:消除"棋盘格伪影" (Checkerboard Artifacts)
- 问题 :传统的 U-Net 使用转置卷积 (Transposed Convolution) 进行上采样。由于卷积核重叠不均匀,生成的图像往往带有明显的网格状伪影(看起来像棋盘格)。
- 解决方案 :我们在本项目中将转置卷积替换为 "双线性插值上采样 (Bilinear Upsample) + 卷积 (Convolution)" 的组合。先通过数学插值平滑放大图片,再通过卷积层细化特征,从而彻底消除了伪影,使修复区域更加平滑自然。
2.3 第二代模型:生成对抗网络 (GAN-UNet)
原理 :
虽然 CNN-UNet 能恢复结构,但它使用的 L1/L2 损失函数倾向于生成"模糊的平均值"。为了解决这个问题,我们引入了 GAN (Generative Adversarial Networks) 。
GAN 包含两个相互博弈的网络:
- 生成器 (Generator):即上述的 U-Net,负责"伪造"修复图像,试图骗过判别器。
- 判别器 (Discriminator):负责"找茬",判断输入的图像是真实的文物照片,还是生成器修复的假照片。
博弈过程:
- 判别器努力学习区分真假,迫使生成器生成的图像必须具备真实图像的高频细节(如笔触、颗粒感)。
- 最终,生成器生成的图像在纹理上会极其逼真,不再模糊。
2.4 第三代模型:Stable Diffusion XL (SDXL) Inpainting
模型简介 :
本项目集成了 Hugging Face 发布的 diffusers/stable-diffusion-xl-1.0-inpainting-0.1 模型。这是一个基于潜在扩散 (Latent Diffusion) 的文本到图像生成模型,专为图像修复 (Inpainting) 任务进行了微调。它不仅能修复纹理,还能根据 Prompt(提示词)"脑补"出缺失的语义内容(如补全断裂的物体、复原缺失的图案)。
核心技术细节:
- 基础架构 :该模型初始化自
stable-diffusion-xl-base-1.0权重,继承了 SDXL 强大的图像生成能力。 - 高分辨率训练 :模型在 1024x1024 的高分辨率下进行了 40,000 步的微调训练,这使其在处理大幅面文物图像时具有显著优势。
- 9通道输入结构 (9-Channel Input) :为了适应修复任务,SDXL Inpainting 修改了 UNet 的输入层,共有 9 个通道 (普通 SDXL 只有 4 个):
- 4 通道:原图的潜在空间编码 (Encoded Masked-Image)。
- 1 通道:Mask 掩码本身 (Mask)。
- 4 通道 :待去噪的潜在向量 (Noisy Latents)。
这种设计让模型能明确区分"哪些是背景"、"哪些需要修复",从而实现精确的局部重绘。
- 无分类器引导 (Classifier-Free Guidance):训练时使用了 5% 的文本条件丢弃 (Dropout),以提高推理时的引导效果。
部署与使用说明 (Deployment) :
本系统后端基于 Python diffusers 库部署该模型。针对显存资源,我们采用了 fp16 半精度推理和 CPU Offload 技术。
python
from diffusers import AutoPipelineForInpainting
from diffusers.utils import load_image
import torch
# 1. 加载模型
# 使用 torch.float16 精度可将显存占用降低约 50%
pipe = AutoPipelineForInpainting.from_pretrained(
"diffusers/stable-diffusion-xl-1.0-inpainting-0.1",
torch_dtype=torch.float16,
variant="fp16"
).to("cuda")
# 2. 显存优化 (关键步骤)
# 如果显存小于 12GB,建议开启 CPU Offload,将暂时不用的模型层卸载到内存
pipe.enable_model_cpu_offload()
# 3. 执行修复
# image: 原始图片 (PIL Image, resize to 1024x1024)
# mask_image: 掩码图片 (PIL Image, resize to 1024x1024)
# prompt: 提示词
output = pipe(
prompt="restore the ancient mural, high details",
image=image,
mask_image=mask_image,
guidance_scale=8.0,
num_inference_steps=20, # 迭代步数,20-30 步效果最佳
strength=0.99 # 重绘强度,接近 1.0 表示完全重新生成 Mask 区域
).images[0]效果展示:

图解 :SDXL Inpainting 实际修复案例
- 左图 (原图):原始壁画,存在色彩剥落和划痕。
- 中图 (涂抹残缺区域):用户交互涂抹的 Mask 区域(白色高亮部分),覆盖了需要修复的接缝和破损处。
- 右图 (修复后):SDXL 模型生成的修复结果。可以看到,模型不仅填补了颜色,还智能地生成了与周围风格一致的纹理细节(如红色横梁的斑驳感、绿色地面的笔触),实现了"无痕修复"。
2.5 评估指标 (Evaluation Metrics)
为了客观评价模型的好坏,我们使用两个核心指标:
- PSNR (Peak Signal-to-Noise Ratio,峰值信噪比) :
- 衡量修复图像与原图在像素数值上的差异。
- 单位为 dB,数值越高代表失真越小,修复越准确。
- SSIM (Structural Similarity,结构相似性) :
- 衡量修复图像与原图在亮度、对比度、结构上的相似度。
- 范围 0, 1,数值越接近 1 代表人眼看起来越像原图。
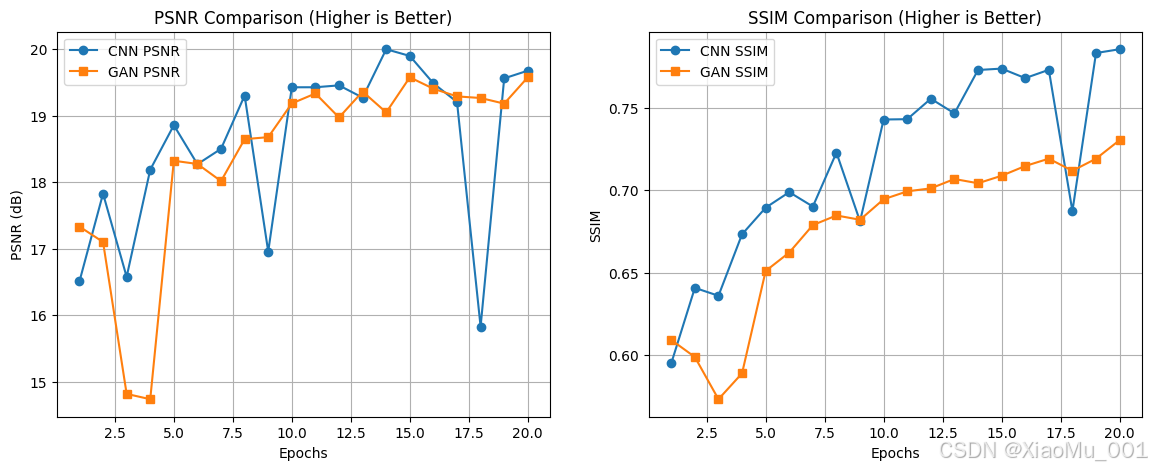
图解 :训练指标变化曲线
- 左图 (Loss):随着训练轮数 (Epoch) 增加,损失函数值迅速下降并趋于平稳,说明模型正在有效学习。
- 右图 (PSNR/SSIM):PSNR 和 SSIM 均呈上升趋势。注意在训练后期,曲线波动变小,意味着模型收敛。如果测试集指标开始下降而训练集继续上升,则提示过拟合,需停止训练。
2.6 后处理技术:泊松融合 (Poisson Blending)
原理 :
即使深度学习模型生成的修复区域内容很完美,直接将其"贴"回原图时,边缘处往往会有光照或色调的突变(Seams)。
泊松融合 不是简单地复制像素值,而是求解泊松方程 (Poisson Equation)。
- 它保留修复区域的梯度(即纹理变化趋势)。
- 强制修复区域的边界像素值与原图背景完全一致。
- 结果:修复区域的颜色会自动调整以适应背景的光照,从而实现"无缝拼接"。

图解 :泊松融合效果
- 左侧 (Before Blending):直接粘贴修复结果,可以看到明显的方形边界,颜色与背景不融合。
- 右侧 (After Poisson Blending):应用泊松融合后,边界完全消失,修复区域的色调与周围环境完美统一。
2.7 综合修复效果对比

图解 :不同模型修复效果对比
- Masked:受损输入。
- CNN Result:修复了结构,但细节较模糊平滑。
- GAN Result:纹理更清晰,颗粒感更强,更接近真实文物质感。
- Ground Truth:原始图像。
- 结论:GAN 模型在视觉观感上优于纯 CNN 模型。
3. 数据库设计详解 (Database Design)
系统采用关系型数据库管理数据,核心设计包含三个实体表。
3.1 用户表 (User)
基于 Django 认证系统,存储用户信息。
| 字段名 | 类型 | 约束 | 描述 |
|---|---|---|---|
id |
Integer | PK, Auto | 用户唯一标识 |
username |
Varchar(150) | Unique, Not Null | 登录账号 |
password |
Varchar(128) | Not Null | PBKDF2 算法加密存储的密码 |
email |
Varchar(254) | - | 用户邮箱,用于找回密码等 |
is_staff |
Boolean | Default False | 权限标识,True 则可进入后台管理 |
date_joined |
DateTime | Auto Now | 账号注册时间 |
3.2 修复任务表 (RestorationTask)
这是系统的核心业务表,记录每一次修复操作的完整生命周期。
| 字段名 | 类型 | 约束 | 描述 |
|---|---|---|---|
id |
UUID | PK, Unique | 使用 UUID 作为主键,防止遍历爬取,确保任务ID全局唯一 |
user_id |
Integer | FK (User) | 外键关联用户表,支持级联删除 (CASCADE) |
original_image |
ImageField | Not Null | 用户上传的原始受损图片路径 |
mask_image |
ImageField | Nullable | 用户绘制的涂抹掩码图片路径 |
restored_image |
ImageField | Nullable | 算法生成的修复结果图片路径 |
model_name |
Varchar(50) | Default 'CNN-UNet' | 记录该次任务使用的算法模型 |
status |
Varchar(20) | Choices | 任务状态机:pending -> processing -> completed / failed |
prompt |
TextField | Nullable | 仅 SDXL 模型使用,存储用户输入的文本提示词 |
psnr / ssim |
Float | Nullable | 任务完成后自动计算并回填的质量评分 |
created_at |
DateTime | Auto Now Add | 任务提交时间 |
3.3 AI 模型配置表 (AIModel)
用于系统管理员动态管理算法模型,无需修改代码即可上下线模型。
| 字段名 | 类型 | 约束 | 描述 |
|---|---|---|---|
id |
Integer | PK | 模型ID |
name |
Varchar(100) | Unique | 模型名称,前端显示给用户选择 |
path |
Varchar(255) | - | 模型权重文件的本地绝对路径或 HuggingFace ID |
is_active |
Boolean | Default True | 开关,False 时前端不可见该模型 |
description |
TextField | - | 模型的技术特点介绍 |
4. 系统功能与界面详解 (System Walkthrough)
系统采用 Vue 3 + Element Plus 构建响应式前端,Django REST Framework 提供高性能 API 后端。
4.1 用户认证 (Authentication)
安全的第一道防线。采用 Token 认证机制。
- 注册:校验用户名唯一性、密码复杂度。
- 登录:获取 API Token,后续请求自动携带 Token 鉴权。
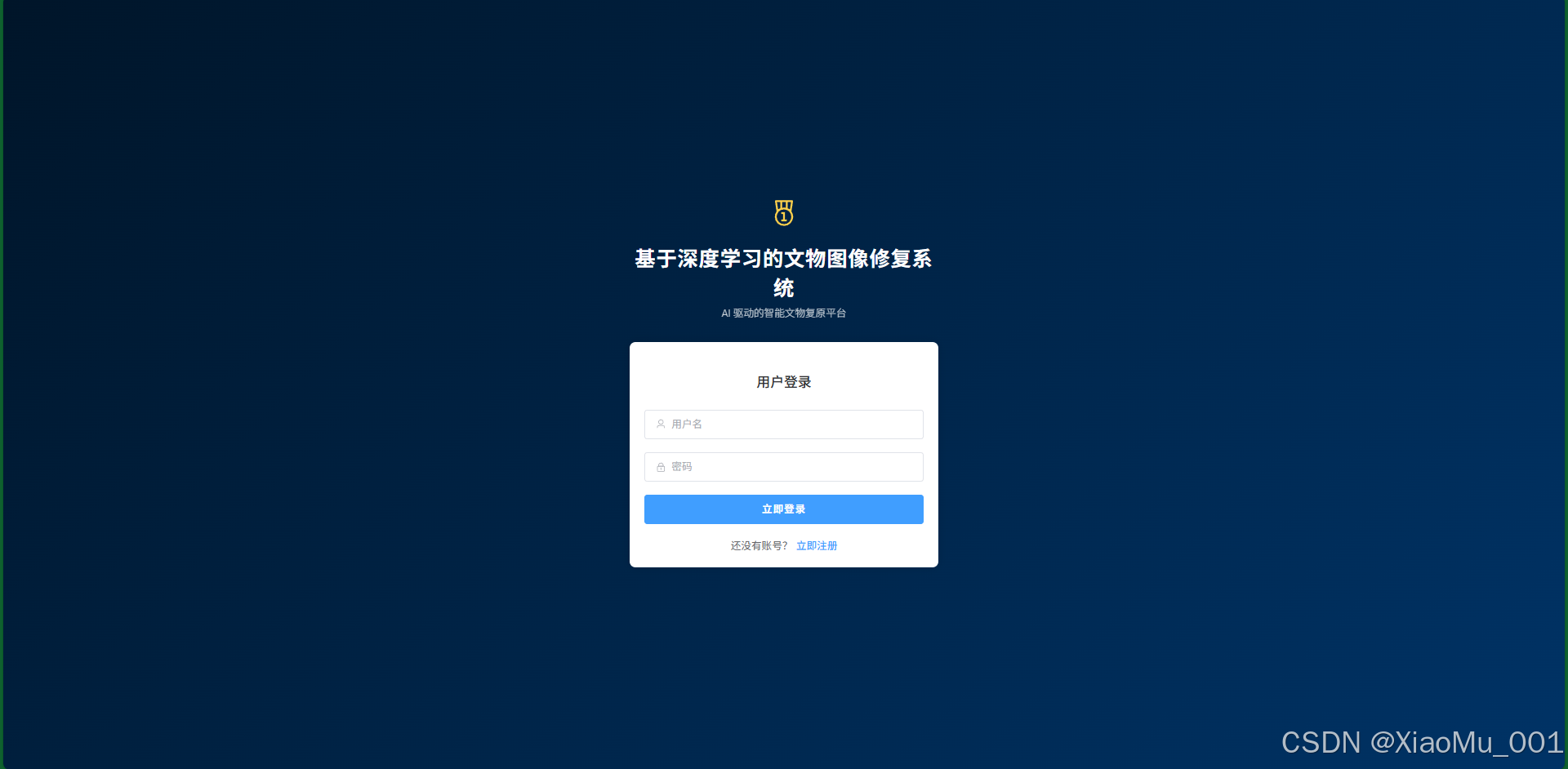
界面说明:采用左右分栏布局,左侧展示系统主题海报,右侧为交互表单。设计简洁大气,提供清晰的错误提示。
4.2 首页概览 (Dashboard)
登录后的着陆页,提供系统导航和功能入口。
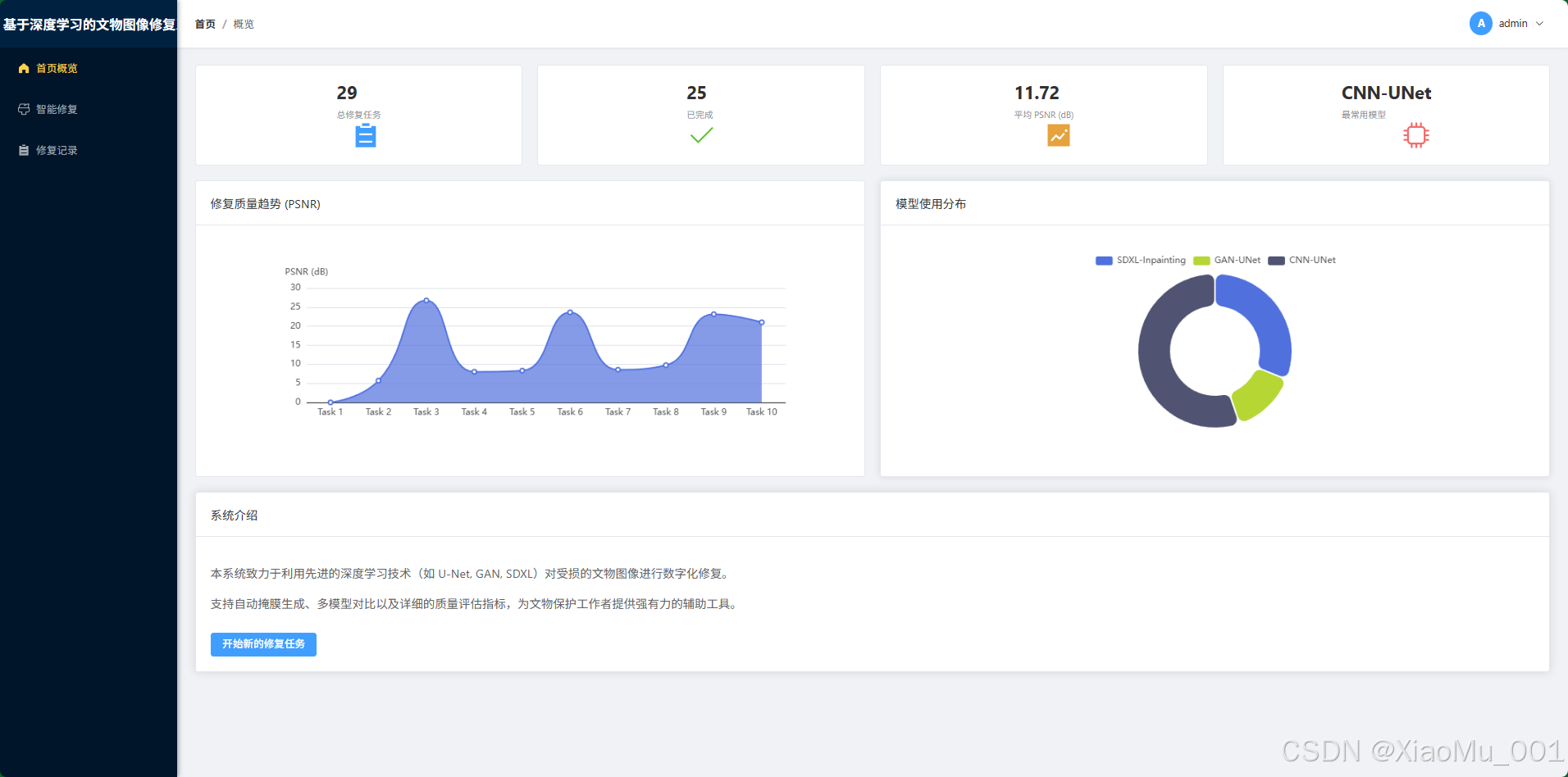
界面说明:
- 顶部导航栏:常驻显示,包含"智能修复"、"修复记录"、"个人中心"等入口。
- Feature Cards:卡片式展示系统核心能力,引导用户快速开始。
4.3 智能修复工作台 (Smart Restoration Workspace)
这是系统的核心交互界面,集成了 Canvas 绘图引擎。
操作流程:
- 上传:拖拽或点击上传受损文物图片。
- 涂抹 (Masking) :
- 系统内置画笔工具,用户在图片上涂抹需要修复的区域。
- 支持缩放 (Zoom) 和 平移 (Pan),方便处理高分辨率图片细节。
- 支持调节笔刷大小,适应不同粗细的裂缝。
- 配置:侧边栏选择模型(如 SDXL),可选输入 Prompt(如"修复为唐代风格花纹")。
- 执行:点击"开始修复",后端异步处理任务。
- 结果:右侧实时弹出修复结果,并显示 PSNR/SSIM 评分。支持一键导出 ZIP 包。
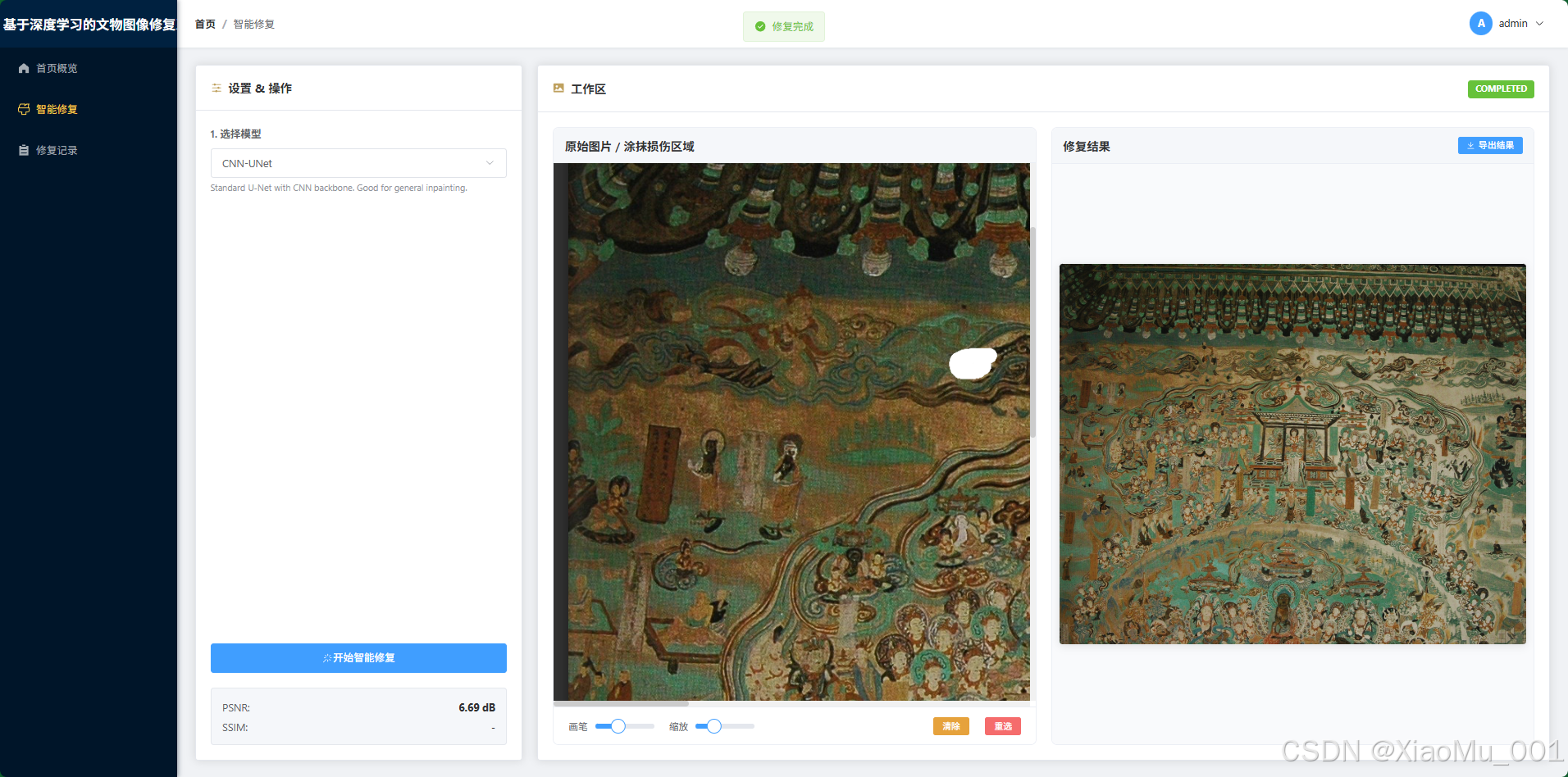
界面说明:
- 左侧画布:交互式绘图区,红色半透明涂抹显示 Mask 区域。
- 右侧画布:结果展示区,支持与原图并排对比。
- 工具栏:包含画笔、橡皮擦、撤销、重置等工具。
4.4 修复记录管理 (History Archive)
数据持久化模块,用户的每一次操作都会被云端保存。
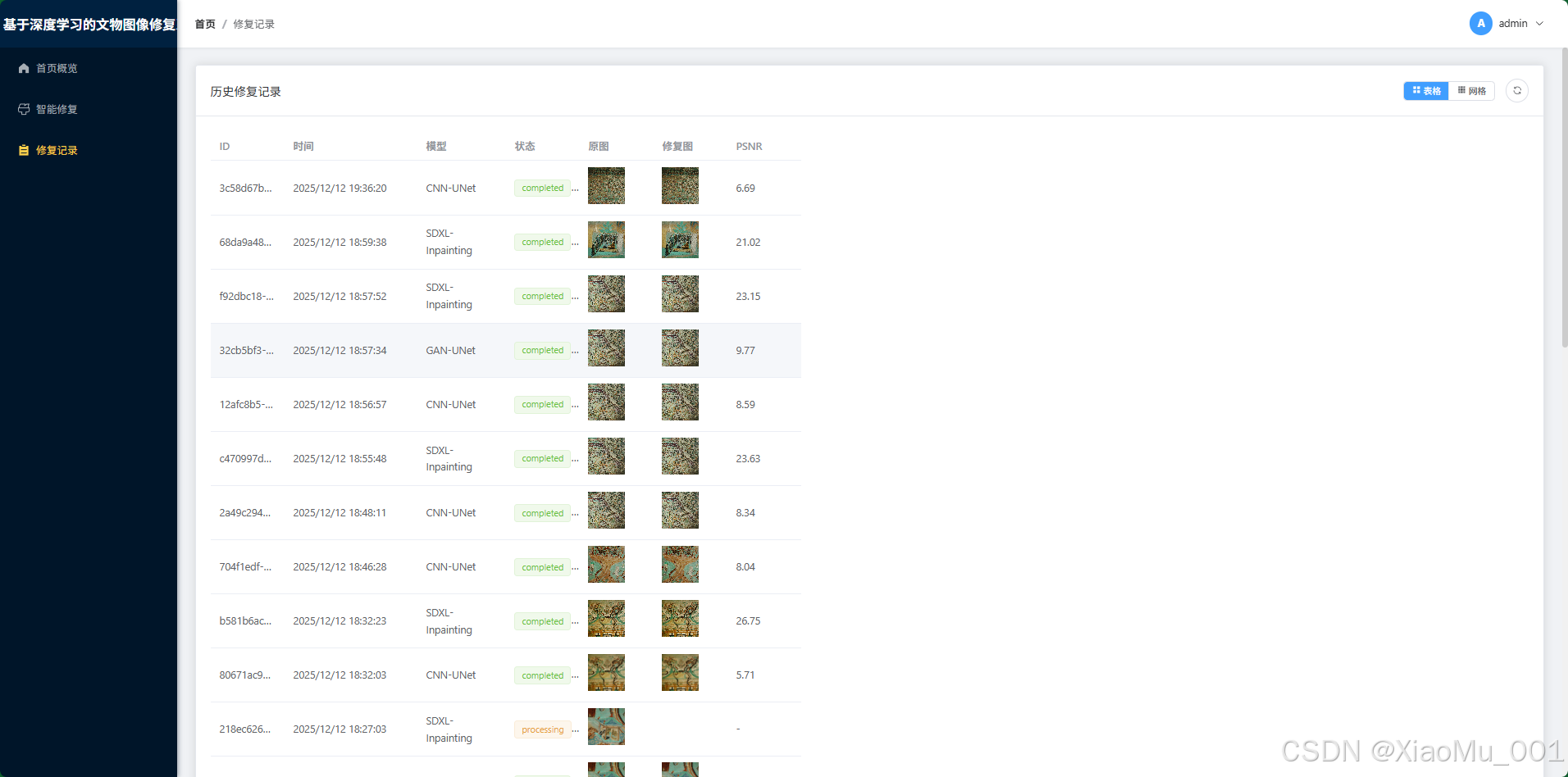
界面说明:
- 采用瀑布流或卡片列表展示历史任务。
- 每张卡片显示原图缩略图、使用的模型、任务状态标签(成功/失败)。
- 点击卡片可查看详情或重新下载结果。
4.5 个人中心 (User Profile)
用户自我管理模块。
界面说明:支持修改昵称、邮箱及登录密码。
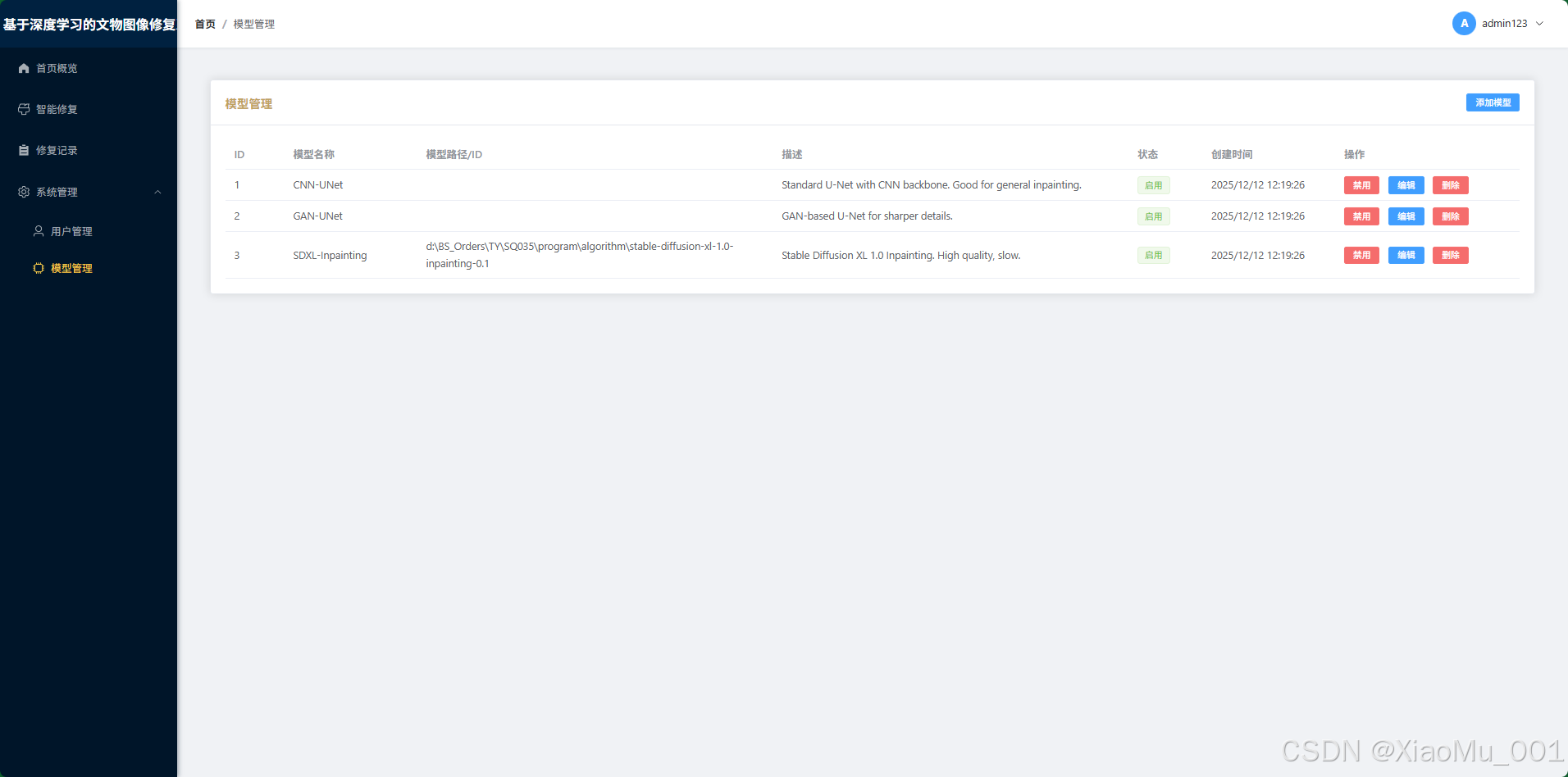
4.6 后台管理系统 (Admin Portal)
仅限超级管理员访问,用于系统运维。
-
用户管理 :监控系统用户数量,封禁违规账号。
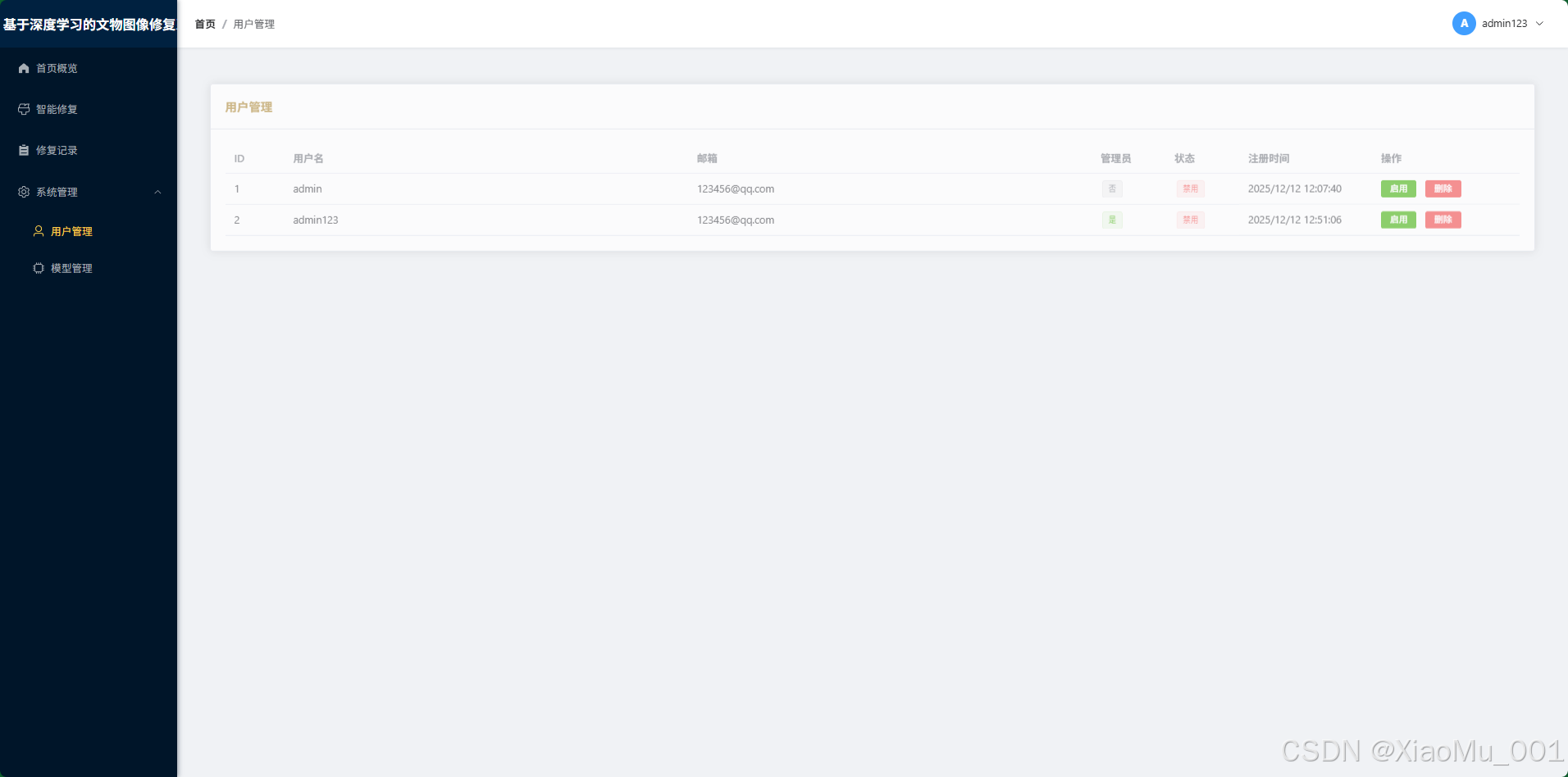
-
模型管理 :无需重启服务器,在线添加新的算法模型权重路径,即刻生效。