论文地址:思维链
摘要
我们探讨了生成思维链------一系列中间推理步骤------如何显著提升大型语言模型执行复杂推理的能力。具体而言,我们展示了这种推理能力如何通过一种称为"思维链提示"的简单方法在足够大规模的语言模型中自然涌现。该方法在提示中提供少量思维链示例作为示范。
在三个大型语言模型上的实验表明,思维链提示在一系列算术推理、常识推理和符号推理任务上均能提升模型性能。实证结果提升显著。例如,仅用八个思维链示例提示 PaLM 540B 模型,便在数学应用题基准 GSM8K 上达到了最先进的准确率,甚至超过了带有验证器的精调 GPT-3 模型。
简要总结
这篇摘要的核心是提出并验证了 "思维链提示" 方法的有效性:
- 核心理念 :通过要求语言模型在给出最终答案前,先一步步地展示其推理过程(即"思维链"),可以大幅提升其在复杂任务上的表现。
- 关键方法 :这是一种简单的提示工程方法,只需在给模型的提问示例中,包含几个展示完整推理步骤的范例即可。
- 主要发现 :
- 这种方法能让足够大的模型**"涌现"**出强大的推理能力。
- 它在算术、常识和符号推理等多种任务上都有效。
- 效果非常突出,举例来说,用此方法提示一个超大规模模型(PaLM 540B),在数学解题任务上达到了当时的最优水平,甚至击败了经过专门精调的模型。
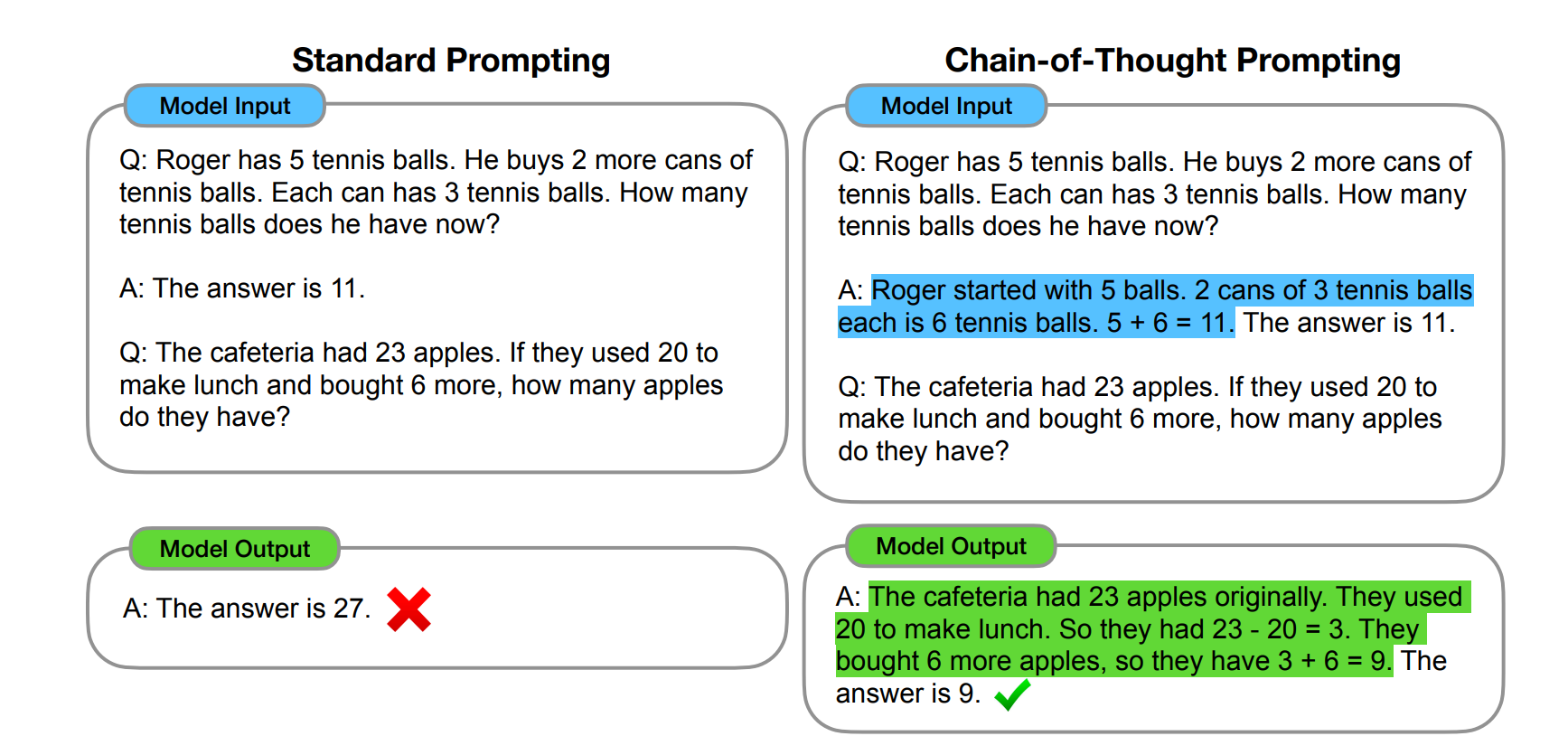
思维链提示让大模型能一步步解决复杂问题,并把推理过程高亮出来,方便你检查。
1 引言
近年来,语言模型(Peters 等人,2018;Devlin 等人,2019;Brown 等人,2020 等)彻底革新了自然语言处理(NLP)领域的格局。研究表明,扩大语言模型的规模能够带来诸多优势,例如提升任务性能和样本效率(Kaplan 等人,2020;Brown 等人,2020 等)。然而,仅靠增大模型规模,并不足以在算术推理、常识推理和符号推理等挑战性任务上实现高性能(Rae 等人,2021)。
本研究基于两个核心思路,探索如何通过一种简单方法解锁大语言模型的推理能力:
- 算术推理的理据生成价值:生成导向最终答案的自然语言推理理据(rationale),能够显著提升算术推理任务的表现。此前的研究中,研究者要么通过从头训练(Ling 等人,2017)或微调预训练模型(Cobbe 等人,2021),让模型具备生成自然语言中间推理步骤的能力;要么采用神经符号方法,使用形式化语言而非自然语言完成推理(Roy & Roth,2015;Chiang & Chen,2019;Amini 等人,2019;Chen 等人,2019)。
- 大模型的上下文少样本学习潜力:大语言模型可通过提示(prompting)实现上下文少样本学习------无需为每个新任务微调独立的模型 checkpoint,只需向模型提供少量展示任务范式的"输入-输出"样例即可。值得注意的是,该方法已在一系列简单问答任务中取得成功(Brown 等人,2020)。
但上述两种思路均存在显著局限:
- 对于理据增强的训练/微调方法,构建大规模高质量推理理据的成本极高,其复杂度远高于普通机器学习任务中使用的简单"输入-输出"样本对;
- 对于 Brown 等人(2020)提出的传统少样本提示方法,其在需要推理能力的任务上表现较差,且往往无法通过增大模型规模实现性能的显著提升(Rae 等人,2021)。
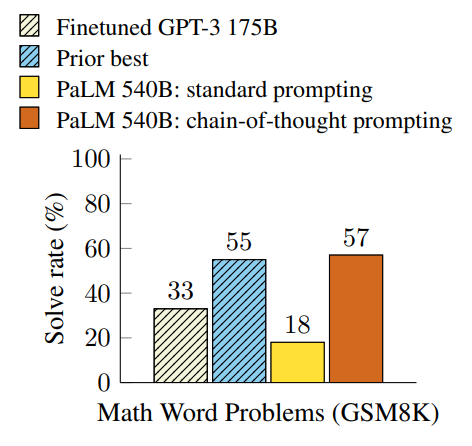
Figure 2: PaLM 540B uses chain-ofthought prompting to achieve new stateof-the-art performance on the GSM8K
benchmark of math word problems.
Finetuned GPT-3 and prior best are from
Cobbe et al. (2021).
为此,本文结合两种思路的优势并规避其缺陷,提出了一种新方法:在推理任务的少样本提示中,使用**〈输入,思维链,输出〉三元组构建提示词。其中,思维链是一系列导向最终输出的自然语言中间推理步骤,我们将这种提示方法称为思维链提示(chain-of-thought prompting)**,图1展示了该方法的一个提示词示例。
我们在算术、常识和符号推理三类基准任务上开展了实证评估,结果表明思维链提示的性能显著优于标准提示,部分任务的性能提升幅度十分惊人。图2呈现了其中一项关键结果:在小学数学应用题基准 GSM8K(Cobbe 等人,2021)上,5400亿参数的 PaLM 模型结合思维链提示,不仅大幅超越标准提示的性能,还刷新了该任务的最先进(SOTA)成绩。纯提示方法的核心优势在于无需大规模训练数据集 ,且单个模型 checkpoint 可通用执行多种任务,不会损失泛化能力。本研究也进一步凸显了大语言模型的独特学习模式------可通过少量包含任务信息的自然语言样例完成学习(区别于通过大规模训练数据集自动学习输入输出底层模式的传统方式)。
核心要点拆解
1. 研究背景与核心痛点
| 领域现状 | 核心优势 | 关键局限 |
|---|---|---|
| 大模型规模扩张 | 提升通用任务性能、样本效率 | 无法突破算术/常识/符号推理等复杂任务的性能瓶颈 |
| 理据增强的推理方法 | 提升推理任务的可解释性与准确性 | 构建高质量理据成本高,需专门训练/微调 |
| 传统少样本提示 | 无需微调、任务泛化性强 | 推理任务表现差,模型规模扩大也难见效 |
2. 思维链提示的核心设计
- 提示词范式:摒弃传统"输入-输出"二元组,采用**〈输入,思维链,输出〉三元组**,通过中间推理步骤引导模型模拟人类思考过程;
- 核心本质:将"理据生成"与"上下文少样本学习"结合,既保留提示方法的零微调优势,又引入推理步骤提升复杂任务性能;
- 典型示例:例如解答数学题时,提示词不仅给出题目和答案,还附带"先算XX,再算XX,最终得到XX"的完整推理流程。
3. 实验核心结论与方法价值
- 性能突破:在算术、常识、符号推理任务上全面超越标准提示,PaLM-540B 结合该方法在 GSM8K 任务上达成 SOTA;
- 工程优势:零微调、零额外训练数据,单模型可适配多类推理任务,大幅降低落地成本;
- 学术意义:证明大语言模型可通过自然语言推理样例实现"认知层面的任务学习",而非仅学习输入输出的表面关联。
2 思维链提示
试想人类解决复杂推理任务(如多步骤数学应用题)时的思考过程:通常会先将问题拆解为若干中间步骤,逐一解决后再得出最终答案。例如"简送给妈妈2朵花后还剩10朵......再送给爸爸3朵后就只剩7朵了......所以答案是7"。本文的研究目标是赋予语言模型生成类似思维链的能力------即生成连贯的中间推理步骤序列,从而推导出问题的最终答案。我们将证明:只要在少样本提示的样例中提供思维链推理的示范,规模足够大的语言模型就能自主生成思维链。
图1展示了一个典型案例:某模型在生成思维链后成功解答了一道原本会答错的数学应用题。该案例中的思维链虽可被解读为解题过程,但我们仍将其称为"思维链",这是为了更精准地体现其核心特质------模拟人类逐步推导答案的思考流程(此外,传统的解题步骤/解释通常会置于最终答案之后(Narang 等人,2020;Wiegreffe 等人,2022;Lampinen 等人,2022 等),与思维链的前置推理逻辑不同)。
作为一种提升语言模型推理能力的方法,思维链提示具备以下多项突出优势:
- 分步拆解问题:理论上,思维链可让模型将多步骤问题分解为若干中间子任务,从而为需要更多推理步骤的问题分配更多计算资源,适配复杂任务的推理需求。
- 增强模型可解释性:思维链为观察模型行为提供了可解释的窗口,既能清晰呈现模型推导特定答案的路径,也能为定位推理过程中的错误提供调试依据(不过,要完全刻画支撑答案的模型内部计算逻辑,仍是一个待解的开放性问题)。
- 任务普适性强 :思维链推理可用于数学应用题、常识推理、符号操作等任务,且理论上至少可适配人类能通过语言完成的所有任务。
- 零成本触发:对于规模足够大的现成语言模型,无需额外训练或微调,只需在少样本提示的样例中加入思维链序列示例,即可轻松激发其思维链推理能力。
在后续实证实验中,我们将分别验证思维链提示在算术推理 (第3节)、常识推理 (第4节)和符号推理(第5节)任务中的实用价值。
核心要点拆解
1. 思维链的本质定义
- 核心形态:连贯的自然语言中间推理步骤序列,而非直接输出答案;
- 设计灵感:复刻人类"分步拆解、逐步推导"的认知逻辑;
- 触发条件:仅需在少样本提示样例中提供思维链示范,无需模型微调。
2. 思维链提示的四大核心优势(按价值维度分类)
| 优势维度 | 具体内涵 | 实际价值 |
|---|---|---|
| 任务适配性 | 可拆解多步骤问题,按需分配计算资源 | 突破简单提示无法处理复杂推理任务的瓶颈 |
| 可解释性 | 可视化推理路径,支持错误溯源 | 解决大模型"黑箱推理"的信任度问题,便于调试优化 |
| 场景泛化性 | 适配算术、常识、符号等多类任务,兼容人类语言可解的所有场景 | 实现单模型跨推理任务的通用适配,降低任务专用模型的研发成本 |
| 工程易用性 | 零训练/微调成本,现成大模型可直接触发 | 大幅降低推理能力落地的技术门槛,无需额外标注或算力投入 |
3. 方法的关键边界
- 仅对规模足够大的语言模型有效(小模型难以学习到思维链的推理逻辑);
- 思维链的"可解释性"是路径层面的可视化,而非模型内部计算逻辑的完全透明化。
3 算术推理
我们首先针对图1所示类型的数学应用题展开研究,这类任务用于衡量语言模型的算术推理能力。尽管此类任务对人类而言较为简单,但语言模型在算术推理上却常常表现不佳(Hendrycks 等人,2021;Patel 等人,2021 等)。值得注意的是,当5400亿参数的语言模型结合思维链提示后,其在多个任务上的性能可与任务专属微调模型 相媲美,甚至在高难度的GSM8K基准(Cobbe 等人,2021)上刷新了最先进(SOTA)成绩。

Figure 3: Examples of hinput, chain of thought, outputi triples for arithmetic, commonsense, and
symbolic reasoning benchmarks. Chains of thought are highlighted. Full prompts in Appendix G.
3.1 实验设置
我们在多个基准任务上,针对不同语言模型验证思维链提示的效果。
-
基准数据集
选取以下5个数学应用题基准:
(1)GSM8K数学应用题基准(Cobbe 等人,2021);
(2)题型结构多样的SVAMP数学应用题数据集(Patel 等人,2021);
(3)题型丰富的ASDiv数学应用题数据集(Miao 等人,2020);
(4)代数应用题数据集AQuA;
(5)MAWPS基准(Koncel-Kedziorski 等人,2016)。
任务样例详见附录表12。
-
标准提示基线
基线采用Brown 等人(2020)提出的经典少样本提示方法:在测试样本预测前,向模型输入若干"输入-输出"上下文样例,样例仅包含问题与答案,模型需直接输出答案(如图1左侧所示)。
-
思维链提示方案
我们的方法是在少样本提示的每个样例中,为对应答案补充一条思维链(如图1右侧所示)。由于多数数据集仅含测试集,我们人工构建了8个带思维链的少样本提示样例(图1右侧为其中1例,完整样例见附录表20),且未对这些样例进行提示词工程优化(鲁棒性验证见3.4节及附录A.2)。除AQuA(选择题形式,非自由作答)外,所有基准任务均复用这8个思维链样例;针对AQuA,我们从训练集中选取4个带解题步骤的样例(见附录表21)。
-
语言模型
评估5类大语言模型:
(1)GPT-3(Brown 等人,2020):包含text-ada-001(3.5亿参数)、text-babbage-001(13亿参数)、text-curie-001(67亿参数)、text-davinci-002(1750亿参数),对应InstructGPT系列模型(Ouyang 等人,2022);
(2)LaMDA(Thoppilan 等人,2022):参数规模涵盖4.22亿、20亿、80亿、680亿、1370亿;
(3)PaLM:参数规模为80亿、620亿、5400亿;
(4)UL2 20B(Tay 等人,2022);
(5)Codex(Chen 等人,2021,OpenAI API中的code-davinci-002)。
所有模型均采用贪心解码采样(后续研究表明,对多轮采样结果的最终答案进行多数投票可进一步提升思维链提示性能(Wang 等人,2022a))。LaMDA模型结果为5个随机种子(样例顺序随机打乱)的平均值(不同种子间方差较小);为节省算力,其他模型仅采用单一固定样例顺序。
3.2 实验结果
思维链提示的核心结果汇总于图4,各模型、各参数规模、各基准的完整实验数据见附录表2。主要结论有三点:
- 思维链是模型规模的涌现能力 (Wei 等人,2022b):小模型使用思维链提示无法提升性能,仅当模型参数规模达到约1000亿时,才能获得性能增益。定性分析发现,小模型会生成流畅但逻辑错误的思维链,导致性能低于标准提示。
- 任务复杂度越高,性能增益越显著:例如,在基线性能最低的GSM8K数据集上,最大规模的GPT和PaLM模型性能翻倍;而在MAWPS中最简单的SingleOp子集(仅需单步计算),思维链提示的性能提升为负或微乎其微(见附录表3)。
- 性能媲美任务专属微调模型:GPT-3 1750亿和PaLM 5400亿结合思维链提示,可匹敌此前依赖标注训练集的任务专属微调SOTA模型。其中PaLM 5400亿在GSM8K、SVAMP、MAWPS上刷新SOTA(标准提示已在SVAMP上超越此前最优),在AQuA和ASDiv上也达到了与SOTA仅2%的差距(见附录表2)。
为探究思维链提示的起效机制,我们人工分析了LaMDA 1370亿在GSM8K上生成的思维链:
- 50个答案正确的样本中,仅2个是"巧合得出正确答案",其余48个的思维链在逻辑和数学层面均完全正确(见附录D.1及表8的正确样例);
- 50个答案错误的样本中,46%的思维链仅存在微小失误(计算错误、符号映射错误、缺失单步推理),54%则存在语义理解或逻辑连贯性的重大错误(见附录D.2)。
进一步对比PaLM 620亿与5400亿的错误类型发现,模型规模提升至5400亿后,可修复620亿模型中大部分"缺失单步推理"和"语义理解错误"(见附录A.1)。
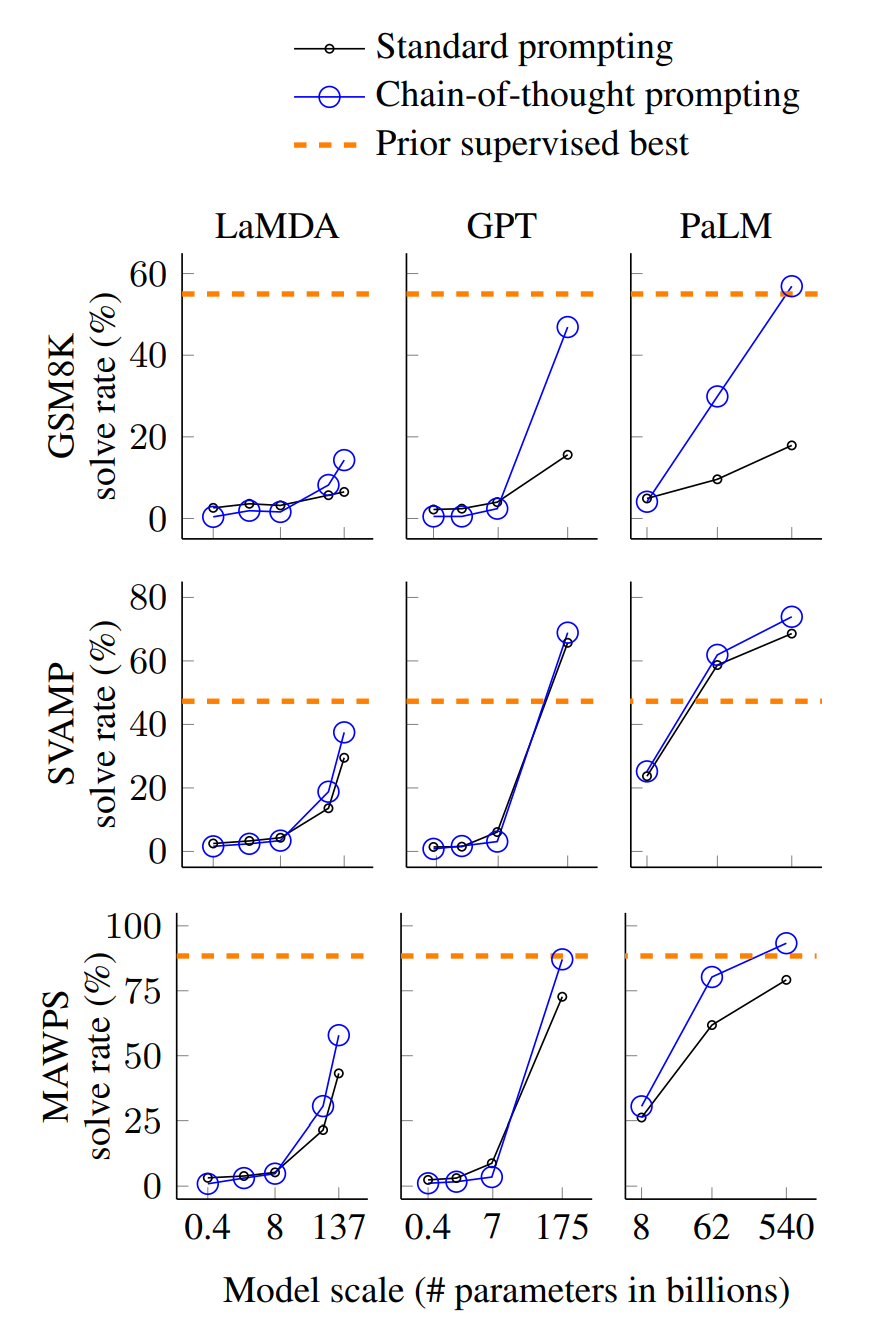
Figure 4: Chain-of-thought prompting enables
large language models to solve challenging math
problems. Notably, chain-of-thought reasoning
is an emergent ability of increasing model scale.
Prior best numbers are from Cobbe et al. (2021)
for GSM8K, Jie et al. (2022) for SVAMP, and Lan
et al. (2021) for MAWPS.
3.3 消融实验
思维链提示的显著增益引出一个问题:其他提示变体能否实现同等性能提升?图5展示了三类思维链变体的消融实验结果:
-
仅输出公式
思维链提示的增益可能源于生成待计算的数学公式,因此我们测试"仅输出公式再给答案"的变体。结果显示,该变体在GSM8K上几乎无增益------这说明GSM8K的题目语义复杂度高,无自然语言推理步骤则无法直接转化为公式;而在单/双步应用题数据集上,仅公式提示可提升性能(见附录表6),因这类题目可直接从题干推导公式。
-
仅增加计算量
另一种假设是思维链通过"生成中间token增加计算量"提升性能。为剥离推理逻辑的影响,我们测试"输出与解题公式字符数相等的点序列(......)"的变体。该变体性能与基线持平,说明仅增加计算量无法带来增益,自然语言中间步骤的推理表达才是核心价值。
-
答案后置思维链
思维链的增益也可能仅为激活预训练知识,因此我们测试"先给答案、再补思维链"的变体。该变体性能与基线相当,证明思维链的顺序推理逻辑 是关键,而非单纯的知识激活。
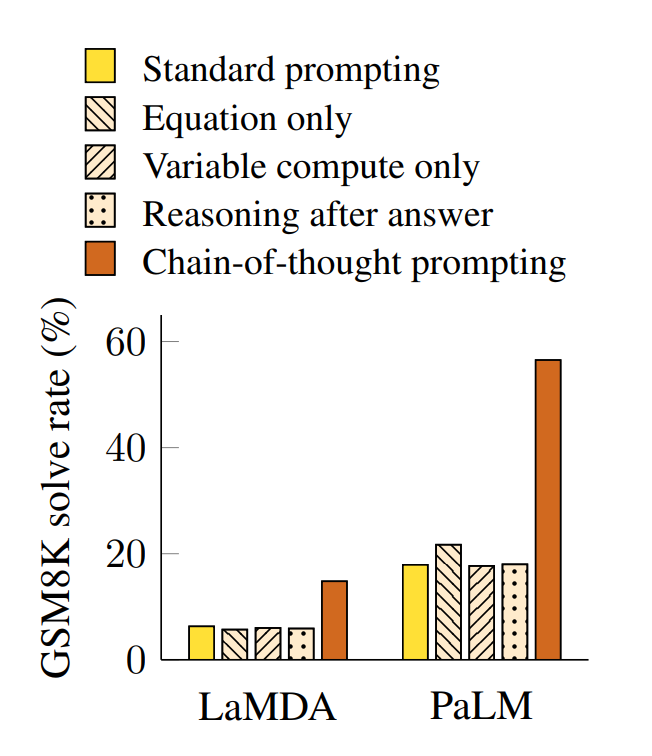
Figure 5: Ablation study for different variations of prompting using LaMDA 137B and PaLM 540B.
Results for other datasets are given
in Appendix Table 6 and Table 7.
3.4 思维链的鲁棒性
提示方法的核心痛点是对样例的敏感性(例如GPT-3在SST-2上的准确率会随样例顺序变化,从接近随机的54.3%波动至接近SOTA的93.4%(Zhao 等人,2021))。本小节验证思维链对不同标注者、不同样例的鲁棒性:
-
不同标注者的思维链
除标注者A编写的思维链外,另两位合著者(标注者B、C)为相同样例独立编写了思维链(见附录H);标注者A还按Cobbe 等人(2021)的解题风格编写了更简洁的版本。图6显示,尽管不同标注的思维链存在性能波动(符合样例提示的固有特性(Le Scao & Rush,2021;Reynolds & McDonell,2021;Zhao 等人,2021)),但所有思维链提示均大幅优于标准基线,说明其有效性不依赖特定语言风格。
-
不同来源的提示样例
从GSM8K训练集中随机选取3组各8个自带推理步骤的样例(独立于人工编写样例)进行实验,结果显示其性能与人工样例相当,且显著优于标准提示。
此外,实验还验证了思维链提示对样例顺序、样例数量 的鲁棒性(见附录A.2)。
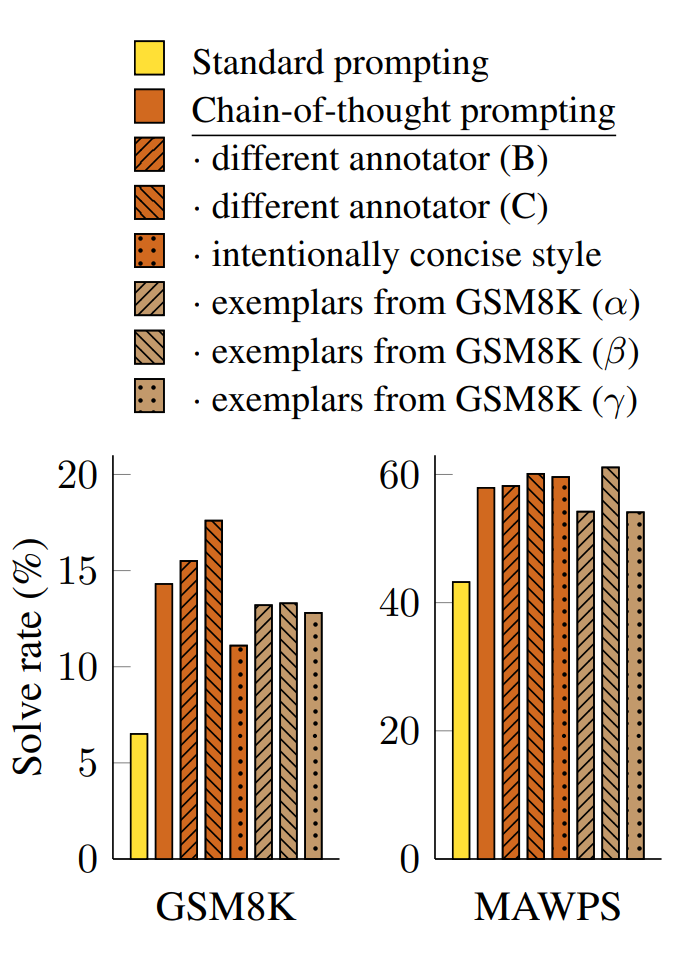
Figure 6: Chain-of-thought prompting
has variance for different prompt examples (as expected) but outperforms standard prompting for various annotators as
well as for different exemplars
核心要点拆解(聚焦实验逻辑与结论)
1. 实验核心结论(按优先级排序)
- 规模门槛 :思维链推理是千亿级模型的涌现能力,小模型无法有效生成逻辑正确的思维链;
- 任务适配性:任务复杂度与性能增益正相关,多步骤/高语义复杂度任务(如GSM8K)增益最显著;
- 性能天花板:零微调的思维链提示可媲美任务专属微调模型,部分任务刷新SOTA;
- 起效本质 :自然语言推理步骤的逻辑连贯性是核心,而非公式生成或计算量增加;
- 鲁棒性:不依赖特定标注风格或样例来源,具备工程落地的稳定性。
2. 消融实验的关键价值
通过控制变量验证了思维链提示的核心价值点,排除了"公式""计算量""知识激活"等非核心因素的干扰,证明顺序化自然语言推理是性能提升的根本原因。
3. 误差分析的启示
- 小失误(计算/符号错误)可通过模型规模提升缓解;
- 重大失误(语义理解/逻辑连贯)是千亿级模型仍需突破的瓶颈。
4 常识推理
尽管思维链提示特别适用于数学应用题,但思维链的自然语言属性使其可广泛应用于各类常识推理任务------这类任务需要基于通用背景知识,对物理世界交互和人类社会行为进行推理。常识推理是智能体与现实世界交互的核心能力,目前仍未被现有自然语言理解系统完全掌握(Talmor 等人,2021)。
-
基准数据集
我们选取5个覆盖多类型常识推理的数据集:
- CSQA(Talmor 等人,2019):主流常识问答数据集,题目包含复杂语义,往往需要调用先验知识才能解答;
- StrategyQA(Geva 等人,2021):要求模型通过多跳推理策略推导问题答案;
- BIG-bench 专项任务 (大基准协作项目,2021):选取两个子任务,一是日期理解 (从给定上下文推断具体日期),二是体育理解(判断体育相关语句是否合理);
- SayCan (Ahn 等人,2022):需将自然语言指令映射为离散集合中的机器人动作序列。
所有数据集的思维链标注样例见图3。
-
提示词设置
沿用前一节的实验框架:
- 针对CSQA和StrategyQA,从训练集中随机选取样本并人工编写思维链,作为少样本提示样例;
- 两个BIG-bench任务无独立训练集,因此选取测试集中前10个样本作为少样本提示样例,剩余样本用于性能评估;
- 针对SayCan,采用Ahn 等人(2022)使用的6个训练集样本,并为其人工补充思维链。
-
实验结果
图7展示了PaLM模型的核心结果(LaMDA、GPT-3及不同规模模型的完整结果见表4),关键结论如下:
- 所有任务中,模型规模扩大均能提升标准提示的性能,而思维链提示可在此基础上实现进一步增益,且PaLM 540B的提升幅度最为显著;
- 结合思维链提示后,PaLM 540B的性能远超基线:在StrategyQA上刷新SOTA(准确率75.6% vs 此前最优69.4%),在体育理解任务上的表现超过未借助工具的体育爱好者(95.4% vs 84%);
- 上述结果证明,思维链提示同样能提升各类常识推理任务的性能(需注意,CSQA任务上的增益相对有限)。
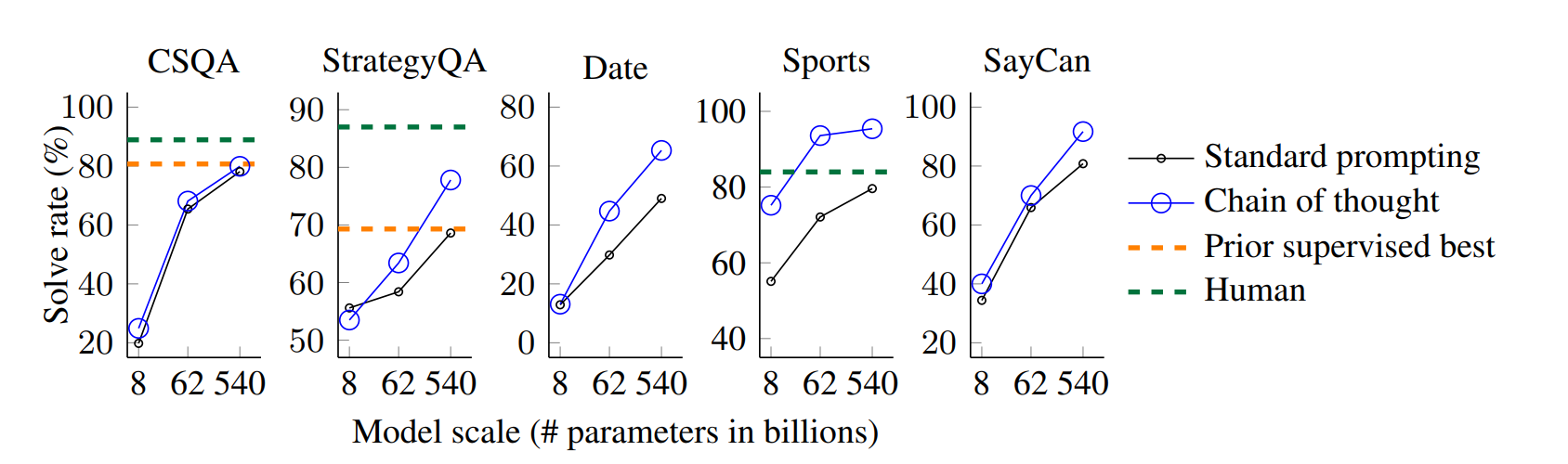
Figure 7: Chain-of-thought prompting also improves the commonsense reasoning abilities of
language models. The language model shown here is PaLM. Prior best numbers are from the
leaderboards of CSQA (Talmor et al., 2019) and StrategyQA (Geva et al., 2021) (single-model only,
as of May 5, 2022). Additional results using various sizes of LaMDA, GPT-3, and PaLM are shown
in Table 4.
核心要点拆解(聚焦任务适配性与实验结论)
1. 常识推理任务的核心特性
常识推理区别于算术推理的关键在于知识依赖性 和多模态/多场景关联性,需结合物理规律、社会规则等通用知识,而非仅依赖逻辑或数学计算。
2. 思维链提示在常识推理中的表现规律
| 任务类型 | 性能增益幅度 | 核心原因分析 |
|---|---|---|
| StrategyQA(多跳推理) | 显著(+6.2%) | 多跳任务需分步拆解推理逻辑,思维链的"步骤化推导"可明确多阶段的知识关联 |
| 体育理解 | 大幅领先(超人类基线) | 思维链可将体育领域的专业规则转化为自然语言推理步骤,弥补模型的领域知识缺口 |
| 日期理解 | 稳步提升 | 日期计算的逻辑链条可通过思维链显性化,减少时间关系的混淆 |
| CSQA(通用常识) | 增益有限 | CSQA题目多为单步常识判断,无需复杂推理链,思维链的"分步拆解"优势难以体现 |
| SayCan(机器人动作映射) | 有效提升 | 思维链可将自然语言指令拆解为动作子任务,建立语言与离散动作的对应逻辑 |
3. 方法迁移价值
思维链提示从算术推理迁移到常识推理,验证了其跨任务适配性------只要任务可通过"自然语言分步推理"解决,无论任务类型是计算还是知识关联,思维链均能发挥作用。
5 符号推理
我们最后的实验评估聚焦符号推理任务 ------这类任务对人类而言十分简单,但对语言模型却颇具挑战性。实验将证明,思维链提示不仅能让语言模型完成标准提示下难以胜任的符号推理任务,还能实现长度泛化,即处理推理步骤数超过少样本样例的测试输入。
-
任务设计
我们选取以下两个构造化玩具任务:
- 最后字母拼接:要求模型将姓名中各单词的最后一个字母拼接(例如输入"Amy Brown",输出"yn")。该任务是"首字母拼接"的进阶版本,而语言模型无需思维链即可完成首字母拼接任务。我们基于姓名统计数据中排名前1000的名和姓(数据来源:https://namecensus.com/),随机组合生成完整姓名作为任务输入。
- 硬币翻转:要求模型判断硬币经过多次翻转/不翻转操作后是否仍为正面朝上(例如输入"硬币初始为正面。菲比翻转了硬币。奥斯瓦尔多未翻转硬币。硬币是否仍为正面?",输出"否")。
由于这两类符号推理任务的构造逻辑明确,我们为每个任务同时设计了域内测试集 和域外(OOD)测试集:
- 域内测试集的样本步骤数与训练/少样本样例一致;
- 域外测试集的样本步骤数多于样例(例如最后字母拼接任务中,样例仅包含双词姓名,测试则涵盖3词、4词姓名;硬币翻转任务也按此逻辑设置步骤数差异)。
实验沿用前两节的模型与方法框架,同时为每个任务的少样本样例人工编写了思维链(样例见附图3)。
-
实验结果
PaLM模型的域内及域外评估结果见图8(LaMDA模型结果见附录表5),核心结论如下:
- 域内任务 :PaLM 540B结合思维链提示后,两类任务的解决率接近100%(需注意,PaLM 540B在标准提示下已能完成硬币翻转任务,但LaMDA 137B无法做到)。尽管域内任务属于"玩具级任务"(少样本样例的思维链已提供完整解题范式,模型仅需将测试样本的新符号代入重复步骤即可),但小模型仍会失效------只有参数规模达到千亿级的模型,才具备对未见符号执行抽象操作的能力。
- 域外任务 :标准提示在两类任务中均完全失效;而思维链提示下,语言模型的性能随规模扩大呈上升趋势(尽管性能低于域内任务)。这表明,对于规模足够的语言模型,思维链提示可实现超越所见样例长度的泛化能力 。
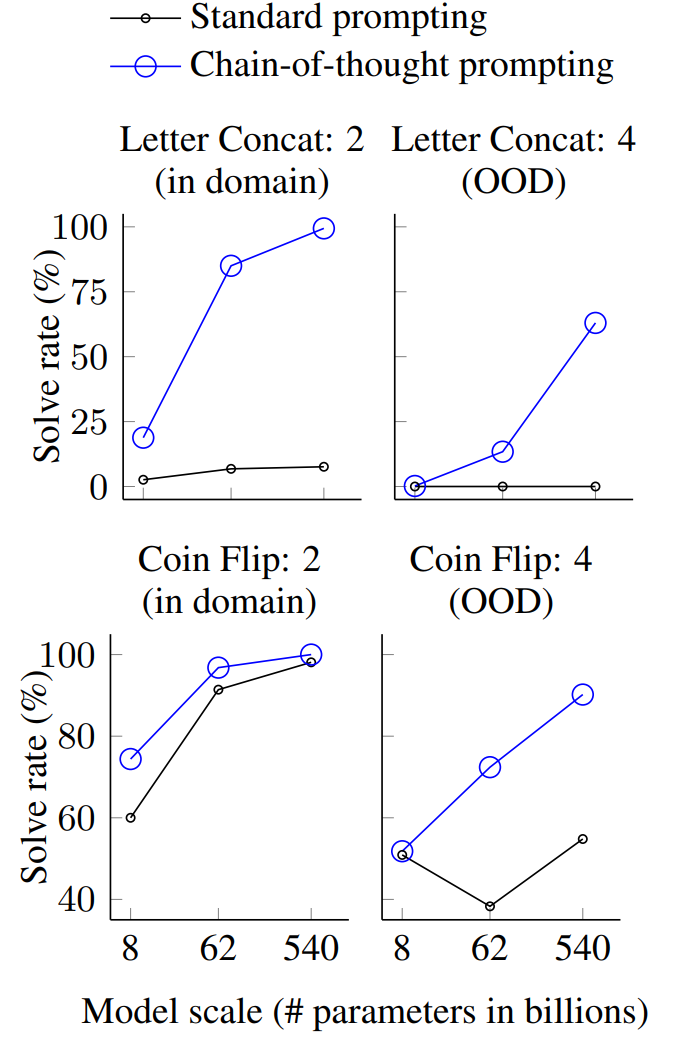
Figure 8: Using chain-of-thought
prompting facilitates generalization to
longer sequences in two symbolic reasoning tasks.
核心要点拆解(聚焦符号推理的关键特性与实验结论)
1. 符号推理任务的核心挑战
符号推理的核心是抽象符号的规则化操作,要求模型理解"符号映射逻辑"并严格遵循步骤执行,而非依赖语义或知识,这对模型的逻辑泛化能力是关键考验。
2. 思维链提示的核心价值(符号推理场景)
| 价值维度 | 具体表现 | 原理分析 |
|---|---|---|
| 基础符号操作能力 | 千亿级模型结合思维链可实现域内任务接近100%准确率 | 思维链将符号操作拆解为显性步骤(如"先取第一个词最后字母,再取第二个词最后字母,最后拼接"),为模型提供明确的操作范式 |
| 长度泛化能力 | 支持步骤数超过样例的域外任务,性能随模型规模提升 | 思维链的"分步执行"逻辑可被模型归纳为通用规则,从而扩展到更长的符号序列,突破样例的长度限制 |
| 规模依赖特性 | 仅千亿级模型可实现有效符号推理,小模型完全失效 | 符号抽象操作是模型规模的涌现能力,小模型无法理解思维链中的规则逻辑,仅能模仿表面形式 |
3. 跨任务一致性结论
从算术、常识到符号推理,思维链提示的有效性均依赖千亿级模型规模 ,且核心价值均源于"将隐性推理逻辑转化为显性自然语言步骤",印证了该方法的通用适配性。
6 讨论
本文探索了思维链提示技术 ,将其作为一种可激发大语言模型多步推理行为的简易机制。首先,在算术推理任务中,思维链提示实现了显著的性能提升,其效果远超各类消融实验变体,且对不同标注者、不同提示样例、不同语言模型均具备鲁棒性(见第3节)。其次,常识推理任务的实验进一步印证了思维链推理的自然语言属性 使其具备普适性(见第4节)。最后,在符号推理任务中,我们证明思维链提示可助力模型实现域外泛化 ,处理长度超过训练样例的序列(见第5节)。在所有实验中,思维链推理的激发仅需对现成预训练语言模型施加提示即可实现,本文全程未对任何语言模型进行微调。
模型规模催生思维链推理能力 是贯穿全文的核心结论(Wei 等人,2022b)。对于许多"标准提示下性能随模型规模增长趋于平缓"的推理任务,思维链提示能让模型性能随规模扩大呈现出陡峭的上升曲线 。思维链提示拓展了大语言模型可胜任的任务边界------换言之,本研究揭示了一个关键事实:标准提示仅能触及大语言模型能力的下限。这一发现引发的问题或许比它解决的问题更多,例如:随着模型规模进一步扩大,推理能力的提升空间还有多大?还有哪些提示方法能够拓展语言模型的可解任务范围?
本文研究也存在若干局限性:
- 推理的本质界定模糊:尽管思维链模仿了人类推理者的思考过程,但这并不能回答"神经网络是否在真正意义上'推理'"这一问题,我们将其列为开放性问题;
- 标注成本的规模化瓶颈 :在少样本设置下,为样例人工补充思维链的成本较低,但这种标注成本在微调场景下可能高到难以承受(不过,这一问题或可通过合成数据生成 或零样本泛化技术解决);
- 推理路径的正确性无法保证:模型生成的思维链可能导向正确答案,也可能导向错误答案。如何提升语言模型生成内容的事实准确性,是未来研究的重要方向(Rashkin 等人,2021;Ye & Durrett,2022;Wiegreffe 等人,2022 等);
- 规模依赖导致落地成本高昂 :思维链推理能力仅在大模型尺度下才会涌现,这使得该技术在实际应用中的部署成本较高。未来研究可探索如何在小模型上诱导出推理能力。
核心要点拆解(聚焦结论升华与局限性)
1. 全文核心结论总结
| 维度 | 关键结论 |
|---|---|
| 方法有效性 | 思维链提示是零微调、高鲁棒性的推理能力激发手段,在算术、常识、符号三类推理任务中均显著优于标准提示 |
| 规模依赖性 | 思维链推理是千亿级模型的涌现能力,小模型无法生成有效逻辑链,大模型的性能增益随规模扩大而显著提升 |
| 能力边界拓展 | 标准提示仅展示了大模型的"基础能力",思维链提示可解锁模型的"高阶推理能力",大幅拓展可解任务范围 |
| 方法普适性 | 思维链的自然语言属性使其可跨任务迁移,无需针对不同任务设计专属提示逻辑 |
2. 研究局限性的深层分析
| 局限性 | 本质问题 | 潜在解决方向 |
|---|---|---|
| 无法界定"真推理"还是"伪模仿" | 大模型的思维链可能是对人类推理步骤的表面模仿,而非基于逻辑的自主推导 | 从神经机制层面解析模型生成思维链时的内部表征,建立"推理有效性"的量化评估标准 |
| 少样本标注成本易规模化失控 | 人工编写思维链的效率低,难以支撑大规模微调数据需求 | 利用大模型自生成思维链(self-generation)构建合成数据集;采用 Zero-shot-CoT 规避人工标注 |
| 推理路径正确性无保障 | 模型可能出现"推理步骤错误但答案巧合正确"或"步骤合理但结论错误"的情况 | 引入外部验证器(verifier)校验思维链逻辑;结合检索增强生成(RAG)提升事实准确性 |
| 大模型部署成本高 | 小模型无法涌现思维链能力,限制了边缘端等低成本场景的应用 | 探索知识蒸馏技术,将大模型的推理能力迁移到小模型;设计轻量化的专用推理架构 |
3. 未来研究方向的核心启发
- 模型侧:小模型推理能力的诱导方法、大模型推理的神经机制解释;
- 数据侧:合成思维链数据的生成技术、低成本标注方案;
- 提示侧:更高效的推理提示模板设计、多模态思维链的拓展;
- 评估侧:推理路径的逻辑性评估指标、模型"真推理"能力的验证方法。