一、存储概念解析
分布式存储
概念
- 是一种独特的系统架构
- 由一组能够通过网络连通,为了完成共同任务而协调任务的计算机节点组成
- 分布式是为了使用廉价的普通的计算机完成复杂的计算和存储任务
- 目的就是利用更多的机器处理更多的数据或任务
特性
-
可扩展:分布式存储系统可以扩展到几百台甚至几千台的集群规模,而且随着集群规模的增长,系统整体性能表现为线性增长
-
低成本:分布式存储系统的自动容错、自动负载均衡机制使其可以构建在普通的PC机之上。另外,线性扩展能力也使得增加、减少机器非常方便,可以实现自动运维
-
高性能:无论是针对整个集群还是单台服务器,都要求分布式存储系统具备高性能
-
易用:分布式存储系统需要能够提供易用的对外接口,另外,也要求具备完善的监控、运维工具,并与其他系统集成
-
分布式算法
- 哈希分布
- 顺序分布
-
常用分布式存储方案
- Lustre
- Hadoop
- FastDFS
- GlusterFS
- Ceph
二、Ceph概述
Ceph概念
什么是Ceph
- Ceph是一个分布式存储系统,具有高扩展、高可用、高性能等特点
- Ceph可以提供块存储、文件存储、对象存储
- Ceph支持EB级别的存储空间
- 作为软件定义存储(Software Define Storage)的优秀解决方案在行业中已得到广泛应用
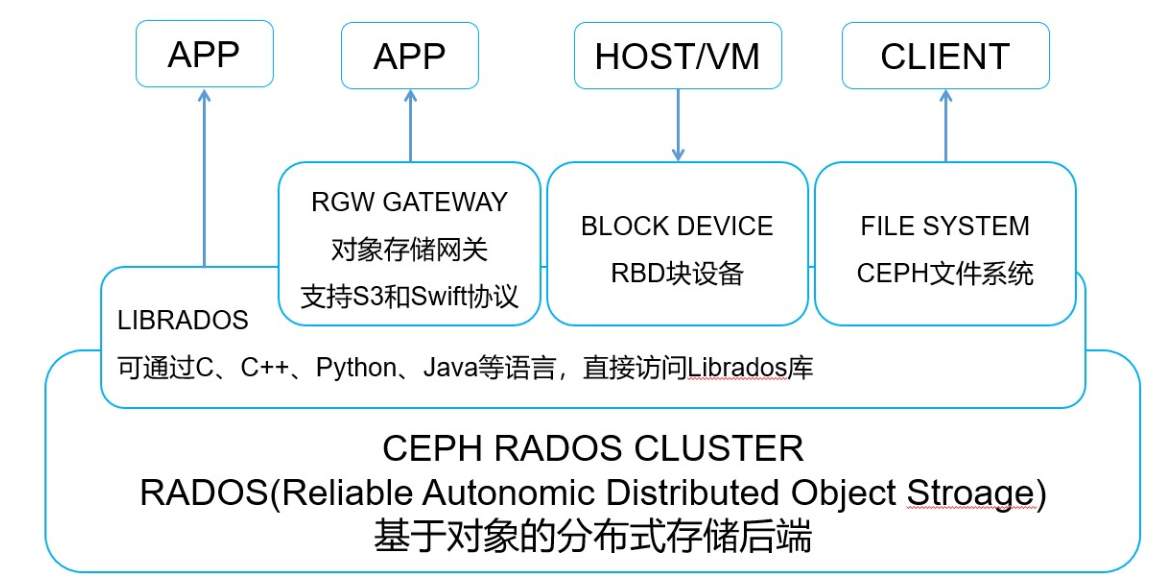
Ceph架构图

Ceph组件及协同工作
核心组件
-
监视器:MON(Monitor)
- Monitor负责管理Ceph集群的整体状态、配置信息和监控数据
- 维护集群状态图和管理守护程序和客户端之间的身份验证
- 它们定期选举一个Leader来协调集群中的其他节点,并接收和处理客户端和OSD的请求
- 为了冗余和高可用性,通常至少需要三台Monitor
-
管理器:MGR(Manager)
- Manager提供集群管理功能,包括集群状态监控、元数据管理、REST API接口等
- 托管基于python的模块来管理和公开Ceph集群信息,包括基于web的Ceph仪表板和REST API
- 以便管理员和用户可视化地管理和操作Ceph集群
- 高可用性通常需要至少两台Manager
-
OSD(Object Storage Daemon)
- OSD是Ceph存储集群的核心组件
- 负责存储数据和处理数据的复制、恢复和再平衡
- 通过检查其他Ceph OSD守护进程的心跳来为Ceph监视器和管理器提供一些监视信息
- 每个OSD节点都有一个或多个OSD进程来管理对应的存储设备
- 为了实现冗余和高可用性,通常至少需要三个Ceph OSD
-
MDS(Metadata Server)
- MDS用于支持Ceph文件系统 (CephFS)
- 负责维护文件系统的元数据
- 回答客户端的访问请求,负责文件名到inode的映射,以及跟踪文件锁
-
RGW(RADOS Gateway)
- RGW是Ceph提供的对象存储网关,兼容S3和Swift协议
- 它为用户提供了通过RESTful API与Ceph存储集群进行交互的能力
辅助工具
-
Rados
- RADOS(可靠、自适应分布式对象存储)是底层的分布式对象存储系统
- 作为Ceph存储引擎的一部分,提供高性能、可扩展的对象存储服务
-
CephFS
- CephFS是Ceph的分布式文件系统
- 通过将文件存储在RADOS中实现了文件级别的访问
-
Librados
- librados是Ceph提供的客户端库,允许开发人员编写基于Ceph的应用程序
Ceph工作图
Ceph数据存储
-
名词解释
-
Object:对象
- Ceph最底层的存储单元
- 每个Object包含元数据和数据
-
Pool:存储池
- 是存储对象的逻辑区分
- 规定了数据冗余的类型和对应的副本分布策略
- 支持两种类型:副本和纠删码,目前基本上使用的都是3副本类型
-
PG(Placement Groups):数据放置组
- 是一个逻辑概念
- 引入这一层是为了更好的分配和定位数据
-
CRUSH:算法
- 是Ceph使用的数据分布算法
- 确保数据分配到预期的地方
- 是容灾级别的控制策略
- 支持Ceph存储集群动态扩展、重新平衡和恢复
-
三、ceph搭建
实验环境准备
关闭防火墙和SELinux
| 主机名 | IP地址 | 角色 | 内存/硬盘 |
|---|---|---|---|
| pubserver(已存在) | eth0:192.168.88.240 | ansible主机 | 无须更改 |
| client(已存在) | eth0:192.168.88.10 | 客户端 | 无须更改 |
| ceph1 | eth0:192.168.88.11 | ceph集群 | 4G / 额外加3块20G硬盘 |
| ceph2 | eth0:192.168.88.12 | ceph集群 | 4G / 额外加3块20G硬盘 |
| ceph3 | eth0:192.168.88.13 | ceph集群 | 4G / 额外加3块20G硬盘 |
Ansible配置
配置Ansible
编写Ansible相关配置
root@pubserver \~# mkdir ceph
root@pubserver \~# cd ceph/
root@pubserver ceph# vim ansible.cfg
defaults
inventory = inventory
module_name = shell
host_key_checking = false
roles_path = roles #将当前目录下的
roles文件夹设置为 Ansible 查找角色的路径。
root@pubserver ceph# mkdir roles
root@pubserver ceph# vim inventory
ceph
ceph1 ansible_ssh_host=192.168.88.11
ceph2 ansible_ssh_host=192.168.88.12
ceph3 ansible_ssh_host=192.168.88.13
clients
client ansible_ssh_host=192.168.88.10
all:vars
ansible_ssh_user=root #登录用户
ansible_ssh_pass=a #自定义用户密码
# 验证Ansible配置,确认CEPH节点内存和硬盘信息
root@pubserver ceph# ansible all -m ping
root@pubserver ceph# ansible ceph -a "free -h"
ceph3 | CHANGED | rc=0 >>
total used free shared buff/cache available
Mem: 3.7Gi 125Mi 3.5Gi 16Mi 111Mi 3.4Gi
Swap: 0B 0B 0B
ceph2 | CHANGED | rc=0 >>
total used free shared buff/cache available
Mem: 3.7Gi 125Mi 3.5Gi 16Mi 111Mi 3.4Gi
Swap: 0B 0B 0B
ceph1 | CHANGED | rc=0 >>
total used free shared buff/cache available
Mem: 3.7Gi 125Mi 3.5Gi 16Mi 111Mi 3.4Gi
Swap: 0B 0B 0B
root@pubserver ceph# ansible ceph -a "lsblk"
ceph1 | CHANGED | rc=0 >>
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
vda 253:0 0 20G 0 disk
└─vda1 253:1 0 20G 0 part /
vdb 253:16 0 20G 0 disk
vdc 253:32 0 20G 0 disk
vdd 253:48 0 20G 0 disk
ceph3 | CHANGED | rc=0 >>
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
vda 253:0 0 20G 0 disk
└─vda1 253:1 0 20G 0 part /
vdb 253:16 0 20G 0 disk
vdc 253:32 0 20G 0 disk
vdd 253:48 0 20G 0 disk
ceph2 | CHANGED | rc=0 >>
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
vda 253:0 0 20G 0 disk
└─vda1 253:1 0 20G 0 part /
vdb 253:16 0 20G 0 disk
vdc 253:32 0 20G 0 disk
vdd 253:48 0 20G 0 disk
基础准备工作
- 更新自定义yum源,加入Ceph相关软件
更新自定义yum源
root@server1 \~# scp /linux-soft/s2/zzg/ceph_soft/cephclient-rpm/* root@192.168.88.240:/var/ftp/rpms/
root@pubserver \~# createrepo --update /var/ftp/rpms/ #更新yum源repodata信息
## 更新所有节点yum源
root@pubserver ceph# mkdir files
root@pubserver ceph# vim files/local88.repo
BaseOS
name=RockyLinux BaseOS
baseurl="ftp://192.168.88.240/dvd/BaseOS/"
enabled=1
gpgcheck=0
AppStream
name=RockyLinux AppStream
baseurl="ftp://192.168.88.240/dvd/AppStream/"
enabled=1
gpgcheck=0
rpms
name=local rpms
baseurl="ftp://192.168.88.240/rpms/"
enabled=1
gpgcheck=0
root@pubserver ceph# vim 02_update_yum.yml
- name: update yum
hosts: all
tasks:
- name: remove dir #删除目录
file:
path: /etc/yum.repos.d/
state: absent
- name: create dir #创建目录
file:
path: /etc/yum.repos.d/
state: directory
- name: upload file #发送repo文件
copy:
src: files/local88.repo
dest: /etc/yum.repos.d/local88.repo
root@pubserver ceph# ansible-playbook 02_update_yum.yml
- 配置所有节点主机名解析
添加所有节点主机名解析配置
blockinfile模块跟lineinfile基本一样,向指定文件内加入一段内容
192.168.88.240必须解析为quay.io!!!
root@pubserver ceph# vim 01_update_hosts.yml
- name: update hosts
hosts: all
tasks:
- name: add host resolv #修改/etc/hosts文件添加主机名映射
blockinfile:
path: /etc/hosts
block: |
192.168.88.10 client
192.168.88.11 ceph1
192.168.88.12 ceph2
192.168.88.13 ceph3
192.168.88.240 quay.io
root@pubserver ceph# ansible-playbook 01_update_hosts.yml
root@pubserver ceph# ansible all -a "tail -7 /etc/hosts"
- 配置时间同步服务
配置时间同步服务Chronyd
配置服务端
root@pubserver \~# timedatectl #查看系统时间配置
root@pubserver \~# timedatectl set-timezone Asia/Shanghai #设置时区为上海
root@pubserver \~# date
root@pubserver \~# date -s "年-月-日 时:分:秒" #如果日期时间不对则修改
root@pubserver \~# yum -y install chrony #已经安装
root@pubserver \~# vim /etc/chrony.conf
...
25 allow 192.168.88.0/24 #允许88网段主机同步时间
26
27 # Serve time even if not synchronized to a time source.
28 local stratum 10 #向下10层同步时间
...
root@pubserver \~# systemctl enable chronyd #设置服务开机自启动
root@pubserver \~# systemctl restart chronyd #重启chronyd服务
root@pubserver \~# ss -antlpu | grep chronyd
udp UNCONN 0 0 127.0.0.1:323 0.0.0.0:* users:(("chronyd",pid=9225,fd=5))
udp UNCONN 0 0 0.0.0.0:123 0.0.0.0:* users:(("chronyd",pid=9225,fd=6))
root@pubserver \~#
# 配置客户端(使用系统角色)
root@pubserver \~# yum -y install rhel-system-roles
root@pubserver ceph#cp -r /usr/share/ansible/roles/rhel-system-roles.timesync/ ./roles/timesync # 将 RHEL 系统自带的 timesync 角色复制到你当前 Ansible 项目
root@pubserver ceph# ansible-galaxy list #快速查看当前环境中已安装的 Ansible 角色
/root/ceph/roles
- timesync, (unknown version)
root@pubserver ceph# vim 03_timesync.yml
- name: config ntp #利用timesync角色配置时间服务
hosts: all
vars:
timesync_ntp_servers:
- hostname: 192.168.88.240
iburst: yes
roles:
- timesync
root@pubserver ceph# ansible-playbook 03_timesync.yml
root@pubserver ceph# ansible all -a "chronyc sources"
chronyc sources #列出所有配置的时间源(NTP 服务器)及其同步状态
ceph1 | CHANGED | rc=0 >>
MS Name/IP address Stratum Poll Reach LastRx Last sample
===============================================================================
^* quay.io 4 6 177 10 +12us +20us +/- 39ms
ceph3 | CHANGED | rc=0 >>
MS Name/IP address Stratum Poll Reach LastRx Last sample
===============================================================================
^* quay.io 4 6 177 11 -29us -31us +/- 38ms
ceph2 | CHANGED | rc=0 >>
MS Name/IP address Stratum Poll Reach LastRx Last sample
===============================================================================
^* quay.io 4 6 177 11 +17us +37us +/- 38ms
client | CHANGED | rc=0 >>
MS Name/IP address Stratum Poll Reach LastRx Last sample
===============================================================================
^* quay.io 4 6 177 10 -10us -21us +/- 38ms
- Ceph节点安装必要软件
Ceph节点安装必要软件
Ceph-Quincy版本采用容器化方式部署
要求Ceph节点有Python3环境,容器管理工具podman或docker,lvm2软件
root@pubserver ceph# vim 04_inst_pkgs.yml
- name: install pkgs
hosts: ceph
tasks:
- name: install pkgs #安装必备软件
yum:
name: python39,podman,lvm2
state: present
root@pubserver ceph# ansible-playbook 04_inst_pkgs.yml
- 搭建私有Ceph镜像仓库
搭建私有容器镜像仓库
部署Ceph-Quincy集群需要使用cephadm工具,该工具为一个Python脚本
部署过程中需要连接到公网quay.io站点下载Ceph相关镜像
为规避无法连接外网或同一时间大量下载造成网络卡顿,故需自己部署一个私有站点quay.io欺骗cephadm工具
上传Ceph集群相关文件(cephadm脚本和Ceph镜像)
root@server1 \~# scp -r /linux-soft/s2/zzg/ceph_soft/ceph-server/ root@192.168.88.240:/root
搭建私有镜像仓库
root@pubserver ceph# cd /root/ceph-server/
root@pubserver ceph-server# yum -y install docker-distribution-2.6.2-2.git48294d9.el7.x86_64.rpm
root@pubserver ceph-server# vim /etc/docker-distribution/registry/config.yml
Docker 私有镜像仓库(Docker Registry)的核心文件。这个 config.yml 文件决定了仓库的存储位置、监听端口、访问日志等关键行为。
version: 0.1
log:
fields:
service: registry
storage:
cache:
layerinfo: inmemory
filesystem:
rootdirectory: /var/lib/registry
http:
addr: :80 #端口由5000调整为80,必须调整,否则后续下载镜像时会有报错
root@pubserver ceph-server# systemctl enable --now docker-distribution.service
root@pubserver ceph-server# ss -antpul | grep :80 #确认80端口被registry进程占用
tcp LISTEN 0 128 *:80 *:* users:(("registry",pid=11002,fd=3))
root@pubserver ceph-server# curl http://localhost/v2/_catalog
{"repositories":\[\]} #此时仓库为空
导入Ceph镜像
root@pubserver ceph-server# vim /etc/hosts
192.168.88.240 quay.io
root@pubserver ceph-server# yum -y install podman
root@pubserver ceph-server# vim /etc/containers/registries.conf #配置私有仓库,文件最后追加
...
\[registry\]
location = "quay.io" #私有仓库地址
insecure = true #可以使用http协议
#导入Ceph相关镜像到本地
root@pubserver ceph-server# for i in *.tar
do
podman load -i $i
done
root@pubserver ceph-server# podman images
REPOSITORY TAG IMAGE ID CREATED SIZE
quay.io/ceph/ceph v17 cc65afd6173a 17 months ago 1.4 GB
quay.io/ceph/ceph-grafana 8.3.5 dad864ee21e9 24 months ago 571 MB
quay.io/prometheus/prometheus v2.33.4 514e6a882f6e 2 years ago 205 MB
quay.io/prometheus/node-exporter v1.3.1 1dbe0e931976 2 years ago 22.3 MB
quay.io/prometheus/alertmanager v0.23.0 ba2b418f427c 2 years ago 58.9 MB
推送镜像到私有仓库
root@pubserver ceph-server# podman push quay.io/ceph/ceph:v17
root@pubserver ceph-server# podman push quay.io/ceph/ceph-grafana:8.3.5
root@pubserver ceph-server# podman push quay.io/prometheus/prometheus:v2.33.4
root@pubserver ceph-server# podman push quay.io/prometheus/node-exporter:v1.3.1
root@pubserver ceph-server# podman push quay.io/prometheus/alertmanager:v0.23.0
验证私有仓库中Ceph镜像保存情况
root@pubserver ceph-server# curl http://quay.io/v2/_catalog
{"repositories":"ceph/ceph","ceph/ceph-grafana","prometheus/alertmanager","prometheus/node-exporter","prometheus/prometheus"}
配置Ceph节点使用私有镜像仓库
root@pubserver \~# cd /root/ceph
root@pubserver ceph# vim 05_config_priv_registry.yml
- name: config private registry
hosts: ceph
tasks:
- name: add quay.io #配置私有registry仓库
blockinfile:
path: /etc/containers/registries.conf
block: |
\[registry\]
location = "quay.io"
insecure = true
root@pubserver ceph# ansible-playbook 05_config_priv_registry.yml
root@pubserver ceph# ansible ceph -a 'tail -5 /etc/containers/registries.conf'
ceph1 | CHANGED | rc=0 >>
BEGIN ANSIBLE MANAGED BLOCK
\[registry\]
location = "quay.io"
insecure = true
END ANSIBLE MANAGED BLOCK
ceph2 | CHANGED | rc=0 >>
BEGIN ANSIBLE MANAGED BLOCK
\[registry\]
location = "quay.io"
insecure = true
END ANSIBLE MANAGED BLOCK
ceph3 | CHANGED | rc=0 >>
BEGIN ANSIBLE MANAGED BLOCK
\[registry\]
location = "quay.io"
insecure = true
END ANSIBLE MANAGED BLOCK
# 建议搭建Ceph集群前临时撤掉Ceph节点网关,禁止Ceph节点连接公网
# 目的是防止因准备步骤有误造成去公网拉取镜像造成网络阻塞甚至导致集群初始化或扩容失败
root@pubserver ceph# ansible ceph -a "route del default gw 192.168.88.254"
Ceph搭建
-
Cephadm工具
-
Cephadm使用容器和systemd安装和管理Ceph集群,并与CLI(命令行)和dashboard GUI紧密 集成
-
cephadm与新的编排API完全集成,并完全支持新的CLI和仪表板功能来管理集群部署
-
cephadm需要容器支持(podman或docker)和Python 3
-
cephadm是一个用于管理Ceph集群的实用程序。可以使用它:
- 将Ceph容器添加到集群中
- 从群集中删除一个Ceph容器
- 更新Ceph容器
-
创建ceph集群
搭建Ceph集群
Ceph1节点作为初始化节点
Ceph在使用过程中是无中心化结构,但搭建过程中选择集群某一个节点作为初始化管理节点,然后扩容其他节点
上传cephadm脚本
root@server1 \~# scp /linux-soft/s2/zzg/ceph_soft/ceph-server/cephadm root@192.168.88.11:/root
# 使用cephadm初始化Ceph集群
root@ceph1 \~# ls -l cephadm
-rwxr-xr-x 1 root root 357805 May 21 18:04 cephadm
root@ceph1 \~# chmod +x cephadm #如果没有x权限则执行本命令赋予脚本x权限
root@ceph1 \~# sed -i '/5000/s/:5000//' cephadm #必须操作,调整镜像地址!!
root@ceph1 \~# sed -rn '46,60p' cephadm #确认cephadm脚本中:5000被去掉
Default container images -----------------------------------------------------
DEFAULT_IMAGE = 'quay.io/ceph/ceph:v17'
DEFAULT_IMAGE_IS_MASTER = False
DEFAULT_IMAGE_RELEASE = 'quincy'
DEFAULT_PROMETHEUS_IMAGE = 'quay.io/prometheus/prometheus:v2.33.4'
DEFAULT_LOKI_IMAGE = 'docker.io/grafana/loki:2.4.0'
DEFAULT_PROMTAIL_IMAGE = 'docker.io/grafana/promtail:2.4.0'
DEFAULT_NODE_EXPORTER_IMAGE = 'quay.io/prometheus/node-exporter:v1.3.1'
DEFAULT_ALERT_MANAGER_IMAGE = 'quay.io/prometheus/alertmanager:v0.23.0'
DEFAULT_GRAFANA_IMAGE = 'quay.io/ceph/ceph-grafana:8.3.5'
DEFAULT_HAPROXY_IMAGE = 'quay.io/ceph/haproxy:2.3'
DEFAULT_KEEPALIVED_IMAGE = 'quay.io/ceph/keepalived:2.1.5'
DEFAULT_SNMP_GATEWAY_IMAGE = 'docker.io/maxwo/snmp-notifier:v1.2.1'
DEFAULT_REGISTRY = 'docker.io' # normalize unqualified digests to this
------------------------------------------------------------------------------
root@ceph1 \~# ./cephadm bootstrap --mon-ip 192.168.88.11 --initial-dashboard-password=123456 --dashboard-password-noupdate #指定初始化节点IP地址,指定dashboard面板密码,不更新dashboard面板密码
等待三分钟左右,确认初始化结果(Ceph1节点下载5个镜像,启动7个容器)
root@ceph1 \~# podman images #列出本地存储中的容器镜像
REPOSITORY TAG IMAGE ID CREATED SIZE
quay.io/ceph/ceph v17 cc65afd6173a 17 months ago 1.4 GB
quay.io/ceph/ceph-grafana 8.3.5 dad864ee21e9 24 months ago 571 MB
quay.io/prometheus/prometheus v2.33.4 514e6a882f6e 2 years ago 205 MB
quay.io/prometheus/node-exporter v1.3.1 1dbe0e931976 2 years ago 22.3 MB
quay.io/prometheus/alertmanager v0.23.0 ba2b418f427c 2 years ago 58.9 MB
root@ceph1 \~#podman ps #查看正在启用的容器
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
bba0d99ea82d quay.io/ceph/ceph:v17 -n mon.ceph1 -f -... 3 minutes ago Up 3 minutes ago ceph-25abe31e-f0a1-11ee-865f-52540064d52b-mon-ceph1
6941cbfb4cd8 quay.io/ceph/ceph:v17 -n mgr.ceph1.zmgy... 3 minutes ago Up 3 minutes ago ceph-25abe31e-f0a1-11ee-865f-52540064d52b-mgr-ceph1-zmgyyq
a83997481c89 quay.io/ceph/ceph@sha256:acdebfa95714d289fe1491195d0a88d9f0d518d2e4b3eaab4dac0ce276c4c568 -n client.crash.c... About a minute ago Up About a minute ago ceph-25abe31e-f0a1-11ee-865f-52540064d52b-crash-ceph1
48a02cec3420 quay.io/prometheus/node-exporter:v1.3.1 --no-collector.ti... About a minute ago Up About a minute ago ceph-25abe31e-f0a1-11ee-865f-52540064d52b-node-exporter-ceph1
0ca222a96e34 quay.io/prometheus/prometheus:v2.33.4 --config.file=/et... 48 seconds ago Up 48 seconds ago ceph-25abe31e-f0a1-11ee-865f-52540064d52b-prometheus-ceph1
b983a78a9e02 quay.io/prometheus/alertmanager:v0.23.0 --cluster.listen-... 33 seconds ago Up 33 seconds ago ceph-25abe31e-f0a1-11ee-865f-52540064d52b-alertmanager-ceph1
9b946f0ea966 quay.io/ceph/ceph-grafana:8.3.5 /bin/bash 29 seconds ago Up 29 seconds ago ceph-25abe31e-f0a1-11ee-865f-52540064d52b-grafana-ceph1
## 管理Ceph集群
# 方法一:./cephadm shell进入管理容器,无需额外装包但命令行无法补全
# 方法二:安装ceph-common包,额外装包但命令行可以补全
root@ceph1 \~# yum -y install ceph-common.x86_64 #装完包后重新登录终端刷新bash环境
root@ceph1 \~# ceph -s #查看Ceph集群状态
cluster:
id: 2ca9f32a-f0a3-11ee-83c6-52540081f933
health: HEALTH_WARN #此时状态为WARN,因为还没部署osd组件
OSD count 0 < osd_pool_default_size 3
services:
mon: 1 daemons, quorum ceph1 (age 2h)
mgr: ceph1.qgermx(active, since 2h)
osd: 0 osds: 0 up, 0 in
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 0 B used, 0 B / 0 B avail
pgs:
root@ceph1 \~# ceph orch ls #查看Ceph集群容器信息,n/m的含义是"正在运行/预期运行"
NAME PORTS RUNNING REFRESHED AGE PLACEMENT
alertmanager ?:9093,9094 1/1 8m ago 2h count:1
crash 1/1 8m ago 2h *
grafana ?:3000 1/1 8m ago 2h count:1
mgr 1/2 8m ago 2h count:2
mon 1/5 8m ago 2h count:5
node-exporter ?:9100 1/1 8m ago 2h *
prometheus ?:9095 1/1 8m ago 2h count:1
# 同步ceph公钥(Quincy版本的Ceph使用自己的ssh秘钥,用于后续操作扩容进集群的节点)
root@ceph1 \~# ssh-copy-id -f -i /etc/ceph/ceph.pub root@ceph1
root@ceph1 \~# ssh-copy-id -f -i /etc/ceph/ceph.pub root@ceph2
root@ceph1 \~# ssh-copy-id -f -i /etc/ceph/ceph.pub root@ceph3
# Ceph集群扩容
root@ceph1 \~# ceph orch host ls
HOST ADDR LABELS STATUS
ceph1 192.168.88.11 _admin
1 hosts in cluster
root@ceph1 \~# ceph orch host add ceph2 192.168.88.12 #将ceph2加入集群
root@ceph1 \~# ceph orch host add ceph3 192.168.88.13 #将ceph3加入集群
root@ceph1 \~# ceph orch host ls #确认Ceph集群扩容情况
HOST ADDR LABELS STATUS
ceph1 192.168.88.11 _admin
ceph2 192.168.88.12
ceph3 192.168.88.13
3 hosts in cluster
# 注:删除错误的主机命令为:ceph orch host rm 主机名 --force
确认扩容结果,扩容后等待一会儿,新节点要下载镜像启动容器
root@ceph1 \~# ceph orch ls #crash为3/3则集群扩容成功
NAME PORTS RUNNING REFRESHED AGE PLACEMENT
alertmanager ?:9093,9094 1/1 3m ago 2h count:1
crash 3/3 3m ago 2h *
grafana ?:3000 1/1 3m ago 2h count:1
mgr 2/2 3m ago 2h count:2
mon 3/5 3m ago 2h count:5
node-exporter ?:9100 3/3 3m ago 2h *
prometheus ?:9095 1/1 3m ago 2h count:1
# 调整mon和mgr数量
root@ceph1 \~# ceph orch apply mon --placement="3 ceph1 ceph2 ceph3"
root@ceph1 \~# ceph orch apply mgr --placement="3 ceph1 ceph2 ceph3"
等待一会儿确认调整结果,集群需要重新调度容器,mon和mgr均为3/3则调整成功
root@ceph1 \~# ceph orch ls
NAME PORTS RUNNING REFRESHED AGE PLACEMENT
alertmanager ?:9093,9094 1/1 26s ago 2h count:1
crash 3/3 30s ago 2h *
grafana ?:3000 1/1 26s ago 2h count:1
mgr 3/3 30s ago 19s ceph1;ceph2;ceph3;count:3
mon 3/3 30s ago 36s ceph1;ceph2;ceph3;count:3
node-exporter ?:9100 3/3 30s ago 2h *
prometheus ?:9095 1/1 26s ago 2h count:1
root@ceph1 \~# ceph -s
cluster:
id: 2ca9f32a-f0a3-11ee-83c6-52540081f933
health: HEALTH_WARN #尚未启动OSD造成WARN状态
OSD count 0 < osd_pool_default_size 3
services:
mon: 3 daemons, quorum ceph1,ceph2,ceph3 (age 2m)
mgr: ceph1.qgermx(active, since 2h), standbys: ceph2.itkjyd, ceph3.asqmxz
osd: 0 osds: 0 up, 0 in
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 0 B used, 0 B / 0 B avail
pgs:
# 启动OSD,绑定Ceph节点上的硬盘设备(每个硬盘设备对应一个OSD守护进程)
root@ceph1 \~# ceph orch daemon add osd ceph1:/dev/vdb
root@ceph1 \~# ceph orch daemon add osd ceph1:/dev/vdc
root@ceph1 \~# ceph orch daemon add osd ceph1:/dev/vdd
root@ceph1 \~# ceph orch daemon add osd ceph2:/dev/vdb
root@ceph1 \~# ceph orch daemon add osd ceph2:/dev/vdc
root@ceph1 \~# ceph orch daemon add osd ceph2:/dev/vdd
root@ceph1 \~# ceph orch daemon add osd ceph3:/dev/vdb
root@ceph1 \~# ceph orch daemon add osd ceph3:/dev/vdc
root@ceph1 \~# ceph orch daemon add osd ceph3:/dev/vdd
#以上9条命令可以直接使用这条命令添加
root@ceph1 \~# ceph orch apply osd --all-available-devices
检查Ceph相关进程状态和数量
root@ceph1 \~# ceph orch ls
NAME PORTS RUNNING REFRESHED AGE PLACEMENT
alertmanager ?:9093,9094 1/1 75s ago 3h count:1
crash 3/3 6m ago 3h *
grafana ?:3000 1/1 75s ago 3h count:1
mgr 3/3 6m ago 18m ceph1;ceph2;ceph3;count:3
mon 3/3 6m ago 19m ceph1;ceph2;ceph3;count:3
node-exporter ?:9100 3/3 6m ago 3h *
osd 9 6m ago - <unmanaged>
prometheus ?:9095 1/1 75s ago 3h count:1
root@ceph1 \~# ceph orch ps #查看Ceph集群所有的容器
root@ceph1 \~# ceph orch ps --daemon-type=mon #3个容器
root@ceph1 \~# ceph orch ps --daemon-type=mgr #3个容器
root@ceph1 \~# ceph orch ps --daemon-type=osd #9个容器
确认Ceph集群状态,至此Ceph集群已搭建完成
root@ceph1 \~# ceph -s
cluster:
id: 2ca9f32a-f0a3-11ee-83c6-52540081f933
health: HEALTH_OK #此时Ceph集群状态已经是OK
services:
mon: 3 daemons, quorum ceph1,ceph2,ceph3 (age 20m)
mgr: ceph1.qgermx(active, since 3h), standbys: ceph2.itkjyd, ceph3.asqmxz
osd: 9 osds: 9 up (since 45s), 9 in (since 90s)
data:
pools: 1 pools, 1 pgs
objects: 2 objects, 449 KiB
usage: 167 MiB used, 160 GiB / 160 GiB avail
pgs: 1 active+clean
## 故障排查
查看服务状态:
ceph: root@ceph1 /# ceph orch ps
如果有error(比如node-exporter.ceph2),则把相应的服务删除:
ceph: root@ceph1 /# ceph orch daemon rm node-expoter.ceph2
然后重新配置:
ceph: root@ceph1 /# ceph orch daemon reconfig node-exporter.ceph2
或
ceph: root@ceph1 /# ceph orch daemon redeploy node-exporter.ceph2
如果是mgr这样的服务出故障,删除后,部署的命令是:
ceph: root@ceph1 /# ceph orch daemon reconfig mgr ceph2
或
ceph: root@ceph1 /# ceph orch daemon redeploy mgr ceph2
四、Ceph块存储
块存储相关概念
-
块存储
- 就是可以提供像硬盘一样的设备
- 使用块存储的节点,第一次连接块设备,需要对块设备进行分区、格式化,然后挂载使用
块设备与字符设备
root@ceph1 \~# ll /dev/vda #b表示block,块设备
brw-rw---- 1 root disk 253, 0 Apr 2 11:38 /dev/vda
root@ceph1 \~# ll /dev/tty #c表示character,字符设备
crw-rw-rw- 1 root tty 5, 0 Apr 2 14:26 /dev/tty
-
Ceph块存储
-
Ceph中的块设备叫做rbd,是rados block device的简写,表示ceph的块设备
-
rados是Reliable, Autonomic Distributed Object Store的简写,意思是可靠、自主的分布式对象存储
-
Ceph块设备采用精简配置,可调整大小,并将数据存储在多个OSD上
-
RBD驱动已经很好的集成在了Linux内核中
-
RBD提供了企业功能,如快照、COW克隆等,RBD还支持内存缓存,从而能够大大提高性能
-
Ceph提供块存储
-
管理存储池
-
存储池是Ceph存储数据的逻辑区分,关联于OSD设备
-
支持数据校验,有副本和纠删码两种策略,默认3副本
-
Ceph中的存储池
查看Ceph存储空间:共180G空间,默认3副本,最大存储60G数据
root@ceph1 \~# ceph df #查看Ceph集群存储情况
--- RAW STORAGE ---
CLASS SIZE AVAIL USED RAW USED %RAW USED
hdd 180 GiB 180 GiB 187 MiB 187 MiB 0.10
TOTAL 180 GiB 180 GiB 187 MiB 187 MiB 0.10
--- POOLS ---
POOL ID PGS STORED OBJECTS USED %USED MAX AVAIL
.mgr 1 1 449 KiB 2 449 KiB 0 57 GiB
root@ceph1 \~#ceph osd pool get .mgr size #获取存储池副本数
size: 3
# 创建存储池
root@ceph1 \~# ceph osd pool ls #获取当前存储池
.mgr
root@ceph1 \~# ceph osd pool create rbd 64 #创建名为rbd的存储池
pool 'rbd' created
root@ceph1 \~# ceph osd pool application enable rbd rbd #设置存储池类型为rbd
enabled application 'rbd' on pool 'rbd'
root@ceph1 \~# ceph osd pool ls
.mgr
rbd
root@ceph1 \~# ceph df
--- RAW STORAGE ---
CLASS SIZE AVAIL USED RAW USED %RAW USED
hdd 180 GiB 180 GiB 190 MiB 190 MiB 0.10
TOTAL 180 GiB 180 GiB 190 MiB 190 MiB 0.10
--- POOLS ---
POOL ID PGS STORED OBJECTS USED %USED MAX AVAIL
.mgr 1 1 897 KiB 2 2.6 MiB 0 57 GiB
rbd 2 64 0 B 0 0 B 0 57 GiB
-
管理镜像
-
在存储池中划分空间提供给客户端作为硬盘使用
-
划分出来的空间,术语叫做镜像
-
Ceph中的镜像管理
# 镜像管理命令rbd
该命令默认操作名为rbd的存储池,如果自定义存储池名称,操作时需带上--pool poolname
查看镜像
root@ceph1 \~# rbd ls #返回空结果
root@ceph1 \~# rbd ls --pool rbd #列出 Ceph 存储集群中 rbd 池内的所有块设备镜像
# 创建镜像
root@ceph1 \~# rbd create img1 --size 10G
root@ceph1 \~# rbd ls
img1
root@ceph1 \~# rbd ls --pool rbd #如果操作的存储池名称不是rbd则需要使用--pool指定名称
img1
查看镜像详情
root@ceph1 \~# rbd info img1 ## 查看镜像详情
rbd image 'img1':
size 10 GiB in 2560 objects
order 22 (4 MiB objects)
snapshot_count: 0
id: 39f34b1da603
block_name_prefix: rbd_data.39f34b1da603
format: 2
features: layering, exclusive-lock, object-map, fast-diff, deep-flatten
op_features:
flags:
create_timestamp: Tue Apr 2 15:15:32 2024
access_timestamp: Tue Apr 2 15:15:32 2024
modify_timestamp: Tue Apr 2 15:15:32 2024
# 镜像扩容/缩容
root@ceph1 \~# rbd resize img1 --size 200G #扩容,并不会立即分配所有空间
root@ceph1 \~# rbd info img1
rbd image 'img1':
size 200 GiB in 51200 objects
...
root@ceph1 \~# rbd resize img1 --size 20G --allow-shrink #缩容,基本用不到
root@ceph1 \~# rbd info img1
rbd image 'img1':
size 20 GiB in 5120 objects
...
删除镜像
root@ceph1 \~# rbd remove img1 #删除指定镜像
root@ceph1 \~# rbd ls #返回空
- 客户端使用Ceph块设备
客户端配置
装包
root@client \~# yum -y install ceph-common
获取集群配置文件和用户认证文件
root@client \~# scp root@192.168.88.11:/etc/ceph/ceph.conf /etc/ceph/
root@client \~# scp root@192.168.88.11:/etc/ceph/ceph.client.admin.keyring /etc/ceph/
root@client \~# ceph -s #客户端已经可以操作Ceph集群
cluster:
id: 2ca9f32a-f0a3-11ee-83c6-52540081f933
health: HEALTH_OK
...
客户端使用Ceph块设备
root@client \~# rbd create img1 --size 10G #创建块设备
root@client \~# rbd ls #查看块设备
img1
root@client \~# rbd info img1 #查看img1设备信息
rbd image 'img1':
size 10 GiB in 2560 objects
...
root@client \~# rbd status img1 #查看img1状态
Watchers: none
root@client \~# rbd map img1 #映射Ceph镜像到本地
/dev/rbd0
root@client \~# lsblk #本地多出rbd类型硬盘
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
rbd0 252:0 0 10G 0 disk
vda 253:0 0 20G 0 disk
└─vda1 253:1 0 20G 0 part /
root@client \~# rbd showmapped #查看映射关系
id pool namespace image snap device
0 rbd img1 - /dev/rbd0
root@client \~# rbd status img1 #查看img1状态
Watchers:
watcher=192.168.88.10:0/2491123928 client.14922 cookie=18446462598732840961
root@client \~# mkdir /data #创建挂载测试目录
root@client \~# mkfs.xfs /dev/rbd0 #格式化硬盘
root@client \~# mount /dev/rbd0 /data/ #挂载硬盘
root@client \~# df -hT | grep rbd
/dev/rbd0 xfs 10G 105M 9.9G 2% /data
root@client \~# cp /etc/hosts /data/ #测试使用
root@client \~# ls /data/
hosts
root@client \~# umount /dev/rbd0 #卸载块设备
root@client \~# ls /data/
root@client \~# rbd showmapped #查看映射关系
id pool namespace image snap device
0 rbd img1 - /dev/rbd0
root@client \~# rbd unmap img1 #取消映射关系
root@client \~# rbd showmapped #确认取消映射关系
root@client \~# rbd remove img1 #删除镜像