会跟随整个项目进行更新,缺啥找啥就行了,如果这里面也没有说明是非常常见的问题咯。
conda创建
bash
conda create -n learn python=3.10在终端输入,learn可以改为你要创建的环境名称,python根据自己电脑下载的python进行选择。
torch与cuda载入
你需要先考虑自己应该下什么版本的torch和cuda,去问ai或者查资料。比如我的5070ti就是支持torch2.9.0,cuda12.8。
找好版本后进入网址选好版本https://pytorch.org/get-started/locally/?spm=a2ty_o01.29997173.0.0.2d395171K7OSyy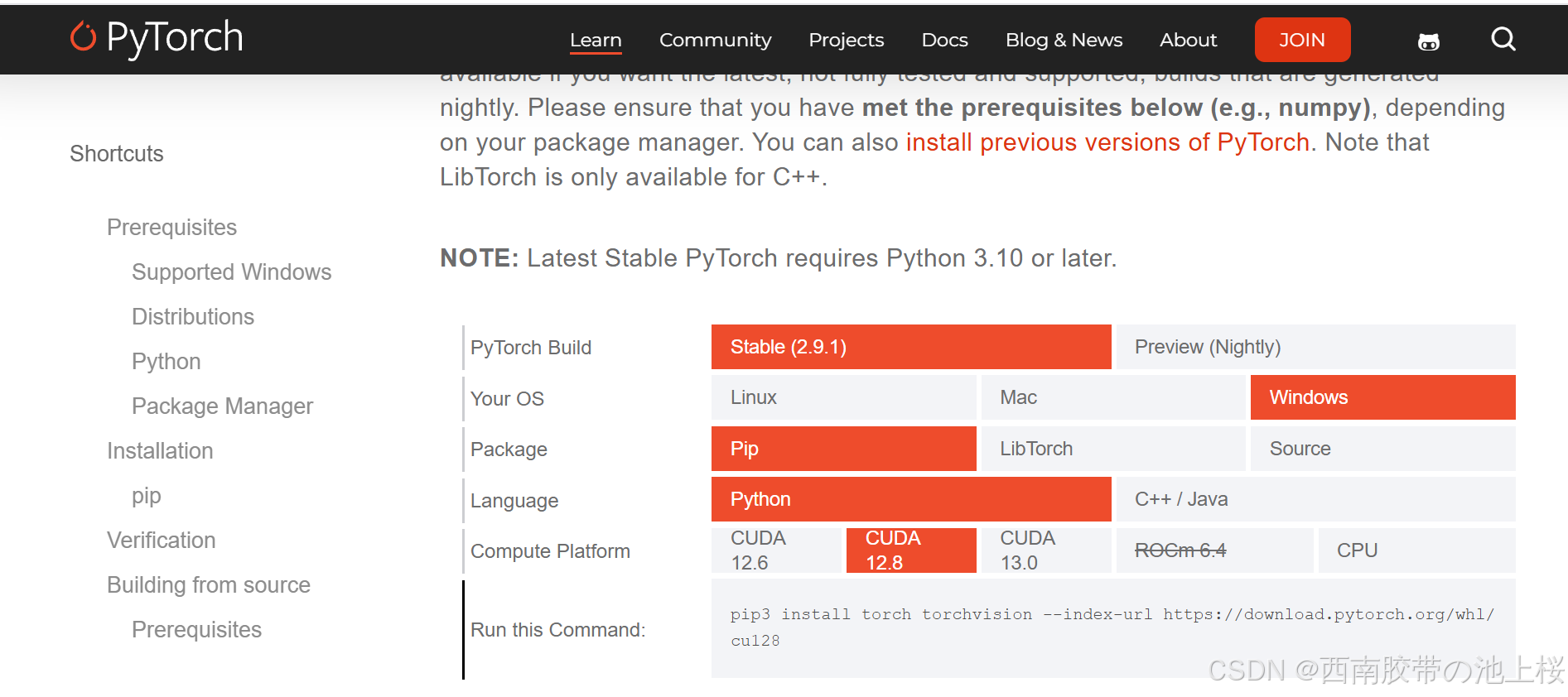
bash
pip3 install torch torchvision --index-url https://download.pytorch.org/whl/cu128cuda版本(GPU),版本可自己通过网站寻找。
bash
python -c "import torch; print(torch.__version__); print(torch.cuda.is_available())"查看下载的pytorch版本和cuda版本确定是否正确。
下载其它pip依赖
其实到这里已经差不多了,接下来运行你的代码,缺什么依赖就pip什么
modelscope
bash
ModuleNotFoundError: No module named 'modelscope'要用魔搭社区就得pip1.10.0的版本
addict
bash
ModuleNotFoundError: No module named 'addict'addict是一个轻量级 Python 库,允许你像访问属性一样操作字典(dict),常用于配置管理、模型参数组织等场景。一些开源项目(如 MMDetection、MMEngine、某些 ModelScope 模型)会依赖它。
pip就能解决
datasets
bash
ModuleNotFoundError: No module named 'datasets'datasets 是 Hugging Face 提供的一个高效、易用的库,用于:
- 加载和处理公开数据集(如 GLUE、SQuAD、中文 CLUE 等)
- 创建、保存和共享自定义数据集
- 与
transformers无缝集成,常用于模型训练/评估流程
很多 Hugging Face 官方示例、微调脚本都依赖它。
bash
pip install datasets==2.21.0推荐用2.21.0不然和魔塔不兼容
simplejson
bash
pip install simplejsonjson格式处理的库,学习模型几乎必备。
transformers
python
pip install transformers==4.31.0学习模型必备