在 Linux 系统中,文件操作是编程与运维的核心基础,无论是磁盘文件、键盘显示器等外设,还是网络套接字,都遵循 "一切皆文件" 的设计理念。本文将结合 C 语言文件接口、系统调用、文件描述符与重定向等核心知识点,带你全面掌握基础 IO 操作。
1. 理解 "文件"
在深入操作之前,我们首先要明确 "文件" 的本质 ------ 它不仅是磁盘上的一串字节,更是属性与内容的集合体,且在 Linux 中有着极为广泛的定义。
1.1 文件的双重定义
狭义理解: 存储在磁盘等永久性存储介质上的实体,由文件内容(实际数据)和文件属性(元数据,如文件名、大小、权限、创建时间等)组成。哪怕是 0KB 的空文件,也会占用磁盘空间存储其属性信息。
**广义理解:**Linux 系统中 "一切皆文件",键盘、显示器、网卡、管道、套接字等设备或通信组件,都被抽象为文件。这种设计让开发者可以通过统一的 API 操作各类系统资源,无需关注底层硬件差异。
1.2 文件操作的核心逻辑
我们来讲解一下关于文件的一些共识性内容
在Linux下一切皆文件。
文件 = 内容 + 属性
所有文件操作本质上分为两类:对文件内容的读写(如修改文本、传输数据)和对文件属性的修改(如更改权限、重命名)。
而操作系统中文件分两类:
• 未打开的文件: 存在磁盘 中,核心是 "存储与分类"(方便快速查找);
• 打开的文件: 由进程操作,存在内存中 ------ 这也是本篇文章的研究重点。
一个进程可以打开多个文件,因此进程:打开文件 = 1:N。
操作系统如何管理打开的文件?
核心思路是**"先描述,再组织":**
描述: 每个打开的文件对应一个 "文件打开对象"(结构体),包含文件属性、操作信息等;
**组织:**这些对象会通过链表(如双向链表)串联,把 "文件管理" 转化为对链表的增删查改 ------ 这是操作系统管理大量打开文件的经典方式。
从系统角度看,文件操作的主体是进程 ------ 进程通过操作系统提供的接口访问文件,而非直接操作硬件。磁盘等外设由操作系统统一管理,进程只需通过标准化接口发起请求即可。
2. C语言文件接口
语言标准库提供了一套封装完好的文件操作接口,基于系统调用实现,简化了开发者的使用流程。这些接口围绕FILE结构体展开,支持文本文件与二进制文件的读写。
2.1 文件的打开与关闭
FILE *fopen(const char *path, const char *mode): 打开文件,成功返回指向FILE结构体的指针(文件指针),失败则返回NULL。
**int fclose(FILE *fp):**关闭文件,释放相关资源,若未关闭可能导致资源泄漏或数据丢失。
关键参数mode(打开模式)的常用取值:
r: 只读打开,文件不存在则报错;
w: 只写打开,文件不存在则创建,存在则清空内容;
a: 追加写打开,文件不存在则创建,写入数据追加在文件末尾;
**r+/w+/a+:**读写模式,分别对应只读、只写、追加模式的扩展。
示例:以只写模式创建并打开文件
cpp
#include <stdio.h>
int main()
{
// 打开当前进程工作目录下的myfile文件,不存在则创建
FILE* fp = fopen("myfile", "w");
if (!fp)
{ // 打开失败时fp为NULL
printf("fopen error!\n");
return 1;
}
// 文件操作...
fclose(fp); // 必须关闭文件
return 0;
}运行结果:
注意:这里用fopen打开文件时,如果文件不存在会创建新文件,这我们从图中是可以看到的,那么这个文件会存放在哪个路径下呢?其实不一定是载进程所处的路径下(code1文件所处路径),而是在我们运行code1时所处的路径下。比如code1文件存放在lesson18目录下,而我们在lesson19目录下运行code1文件(使用绝对路径),此时myfile就会在lesson19目录下生成。
2.2 文件的读写操作
字符 / 字符串读写: fputc(写字符)、fgetc(读字符)、fputs(写字符串)、fgets(读字符串);
格式化读写: fprintf(格式化写入,如fprintf(fp, "name: %s, age: %d", name, age))、fscanf(格式化读取);
**二进制读写:**fwrite(二进制写入)、fread(二进制读取),适用于存储结构体、图像等非文本数据。
示例:使用fwrite向文件写入数据
cpp
#include <stdio.h>
#include <string.h>
int main()
{
FILE* fp = fopen("myfile", "w");
if (!fp)
{
printf("fopen error!\n");
return 1;
}
const char* msg = "hello linux!\n";
int count = 5;
// 循环写入5次字符串,参数:数据地址、单次写入大小、写入次数、文件指针
while (count--)
{
fwrite(msg, strlen(msg), 1, fp);
}
fclose(fp);
return 0;
}运行结果:
示例:使用fread读取文件数据
cpp
#include <stdio.h>
#include <string.h>
int main()
{
FILE* fp = fopen("myfile", "r");
if (!fp)
{
printf("fopen error!\n");
return 1;
}
char buf[1024];
const char* msg = "hello bit!\n";
while (1)
{
// 读取数据到buf,参数:缓冲区地址、单次读取字节数、读取次数、文件指针
size_t s = fread(buf, 1, strlen(msg), fp);
if (s > 0)
{
buf[s] = '\0'; // 手动添加字符串结束符
printf("%s", buf);
}
if (feof(fp)) // 判断是否读取到文件末尾
{
break;
}
}
fclose(fp);
return 0;
}运行结果:
3. 三个默认打开流
我们在之前就说了在Linux中一切皆文件,那么我们的键盘、显示器当然也是文件了。其实我们用键盘输入,其实就是操作系统往键盘文件中读取数据。打印数据,本质上就是操作系统往显示器文件上写入数据。但我们一般没有启动这几个文件为什么能正常输入输出数据呢?答案是这几个文件都是操作系统默认帮我们打开的。
为了方便我们操作,操作系统会在我们启动进程时默认帮我们打开三个输入输出流:标准输入流、标准输出流、标准错误流。
对于C语言这几个就是stdin、stdout、stderr。对于C++则分别是cin、cout、cerr。对于其他语言如JAVA、Python也有类似的概念,这是自然的,因为这不是某个语言独有的,而是操作系统为我们提供的,所有的语言自会实现对应的语法。
输入输出流我们自然是了解的,那么何为错误流呢?我们可以简单的解释一下:我们程序员平常在运行程序时,一般打印数据的目的是什么呢?答案是要么是程序内所要求的,要么是我们要调试程序,找出错误信息,这错误流则可以帮助我们打印错误信息,帮助我们找到程序出bug的地方。
示例: C 语言的默认文件流
C 程序启动时,操作系统会默认打开三个标准文件流,供进程直接使用,其类型均为FILE*:
stdin: 标准输入流,对应键盘(文件描述符 0);
stdout: 标准输出流,对应显示器(文件描述符 1);
**stderr:**标准错误流,对应显示器(文件描述符 2)。
示例:向标准输出流写入数据
cpp
#include <stdio.h>
#include <string.h>
int main()
{
const char* msg = "hello fwrite\n";
fwrite(msg, strlen(msg), 1, stdout); // 直接写入stdout
printf("hello printf\n"); // printf默认输出到stdout
fprintf(stdout, "hello fprintf\n"); // 显式指定stdout
return 0;
}运行结果:

4. 系统文件IO
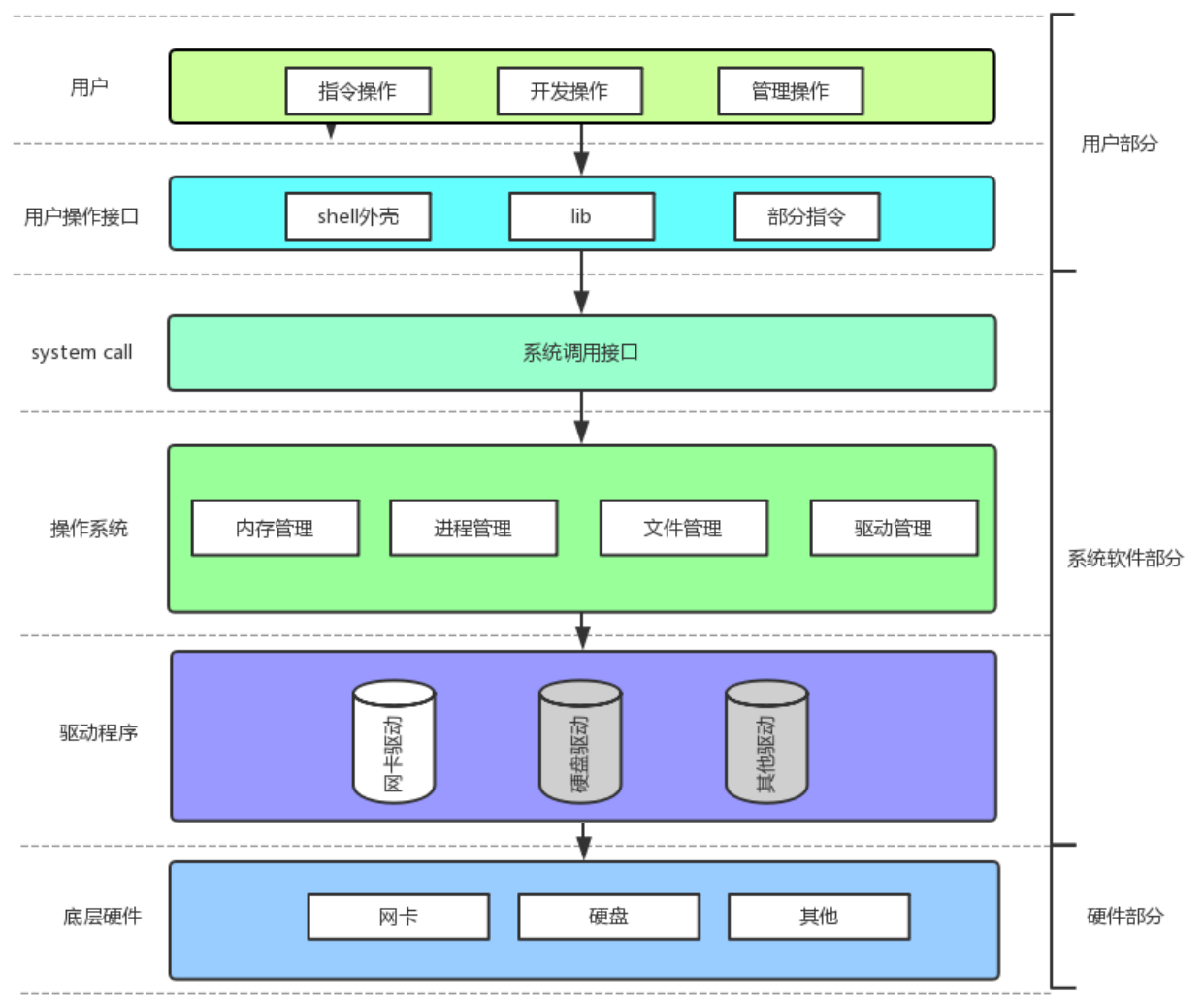
C 语言文件接口是对系统调用的封装,而系统调用是操作系统提供的底层接口,是所有文件操作的基础。掌握系统调用,能更深入理解文件操作的本质。
4.1 系统调用与库函数的关系
库函数: 如fopen、fwrite,属于 C 标准库(libc),封装了系统调用,提供更友好的接口和缓冲区机制,降低开发难度。
**系统调用:**如open、write、read、close,是操作系统内核提供的接口,直接与硬件或内核数据结构交互,是文件操作的 "最终执行者"。
关系链:用户程序 → 库函数(封装) → 系统调用 → 操作系统 → 硬件设备。
4.2 核心系统调用接口
使用系统调用前需包含头文件:#include <sys/types.h>、#include <sys/stat.h>、#include <fcntl.h>、#include <unistd.h>。
(1)open:打开或创建文件
cpp
int open(const char *pathname, int flags);
int open(const char *pathname, int flags, mode_t mode);pathname: 文件路径(绝对路径或相对路径,相对路径基于进程当前工作目录);
flags: 打开标志,通过 "按位或"(|)组合,核心取值:访问模式(必选其一):O_RDONLY(只读)、O_WRONLY(只写)、O_RDWR(读写);
扩展标志(可选): O_CREAT(文件不存在则创建)、O_TRUNC(文件存在则清空)、O_APPEND(追加写);
mode: 文件权限(八进制数),仅当flags包含O_CREAT时有效,如0644(所有者读写、其他只读);
**返回值:**成功返回文件描述符(非负整数),失败返回-1。(文件描述符我们会在下面进行详细讲解)
这里注意上下两种open的差别我们可以看到其实就是在mode上,我们如果确定要打开一个已存在的文件,那么使用上面的open即可。如果我们要打开一个可能不存在的文件,就需要下面的open了,此时我们要传入O_CREAT(文件不存在则创建),我们知道对文件的操作是需要权限的,我们创建一个文件后就需要赋予其权限了,就是mode。当然实际权限的生效还要看系统的权限掩码umask ,最终文件权限 = mode & (~umask)。
如果想详细了解请移步:Linux权限_linux账户从括号改成冒号-CSDN博客
我们如果想排除umask的影响,除了可以在命令行中直接更改,也可以在程序中直接调用umask函数,将其设为0(只在该进程设计的文件操作生效):
cpp
umask(0); // 程序中修改umask为0(不限制任何权限)如果想同时以多个选项打开文件,可以用按位或(|)链接数个选项,如:
cpp
//以只写方式打开文件,且文件不存在时创建文件
O_WRONLY | O_CREAT按位或(|)的作用是把多个标志的二进制位 "合并",比如O_WRONLY(实际宏定义值为01,对应二进制0001)和O_CREAT(宏定义值为0100,对应二进制1000000)按位或后是1000001,表示同时启用 "只写" 和 "文件不存在则创建" 这两个标志;
其实我们从这里也能看出来,这些标志位的本质就是宏定义的整数,其中flags是一个整型,如果将一个比特位作为一个标志位,那么理论上flags可以传递32种不同的标志位,但在这里我们只需要了解如何使用即可。
(2)write:向文件写入数据
cpp
ssize_t write(int fd, const void *buf, size_t count);fd: 文件描述符(open的返回值);
buf: 存储待写入数据的缓冲区地址;
count: 期望写入的字节数;
**返回值:**成功返回实际写入的字节数,失败返回-1。
ssize_t其实就是有符号整型,在 32 位系统中,ssize_t通常是typedef int ssize_t
示例:使用系统调用实现文件写入
cpp
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <string.h>
int main()
{
umask(0); // 设置文件掩码为0,不影响权限设置
// 打开文件,不存在则创建,只写模式,有内容则清空,权限0644
int fd = open("myfile", O_WRONLY | O_CREAT | O_TRUNC, 0644);
if (fd < 0) // 失败时fd为-1
{
perror("open"); // 打印错误信息
return 1;
}
const char* msg = "hello bit!\n";
int len = strlen(msg);
int count = 5;
while (count--)
{
// 向fd对应的文件写入数据
write(fd, msg, len);
}
close(fd); // 关闭文件
return 0;
}运行结果:
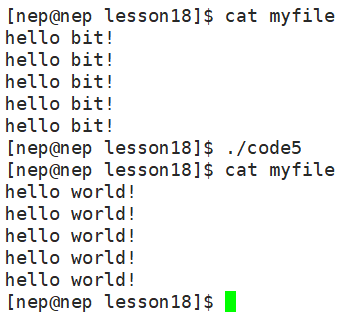
注:当文件已经存在时,open的mode参数(这里的0644)不会生效。
(3)read:从文件读取数据
cpp
ssize_t read(int fd, void *buf, size_t count);fd: 文件描述符;
buf: 存储读取数据的缓冲区地址;
count: 期望读取的字节数;
**返回值:**成功返回实际读取的字节数(到达文件末尾时返回 0),失败返回-1。
示例:使用系统调用实现文件读取
cpp
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <string.h>
int main()
{
// 只读模式打开文件
int fd = open("myfile", O_RDONLY);
if (fd < 0)
{
perror("open");
return 1;
}
const char* msg = "hello world!\n";
char buf[1024];
while (1)
{
// 从fd对应的文件读取数据
ssize_t s = read(fd, buf, strlen(msg));
if (s > 0)
{
buf[s] = '\0'; // 手动添加字符串结束符
printf("%s", buf);
}
else
{
break; // 读取失败或到达末尾
}
}
close(fd);
return 0;
}运行结果:
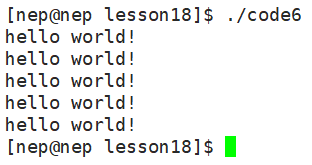
(4)close:关闭文件
cpp
int close(int fd);fd: 文件描述符;
**返回值:**成功返回 0,失败返回-1。
5. 文件描述符(fd)
5.1 文件描述符的本质
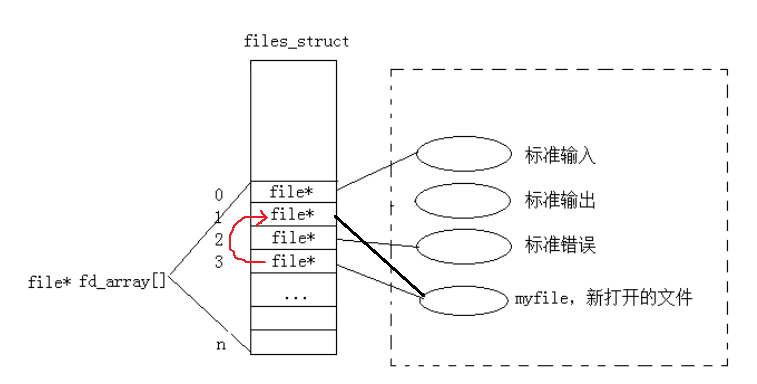
文件描述符是open系统调用的返回值,是一个非负整数,本质是进程文件描述符表(fd_array)的数组下标。进程通过task_struct(PCB)中的指针指向files_struct结构体,该结构体包含fd_array数组,数组元素是指向打开文件的file结构体指针。
当然我这么说一堆结论,大家肯定还是一头雾水,接下来请听我细细道来。
一个进程可以打开多个文件,而一个文件又可以被多个进程打开。那么操作系统是如何管理这些文件的呢?答案很简单,又是我们前面学到的六字真言:"先描述再组织"。
这里的先描述,落实到操作系统中,就是每个文件都会有一个struct file的结构体,里面包含了该文件的许多信息,如文件存放位置、打开时间、文件大小等属性。
那么再组织呢?通过前面的学习,我们了解到了命令行参数表和环境变量表,本质上它们就是一个指针数组,其实操作系统管理文件的方式和它们类似,每个进程会创建一个结构体指针数组fd_array ,其中记录了所有该进程打开文件的 struct file 的地址(指针),这就是文件描述符表。
如下图:
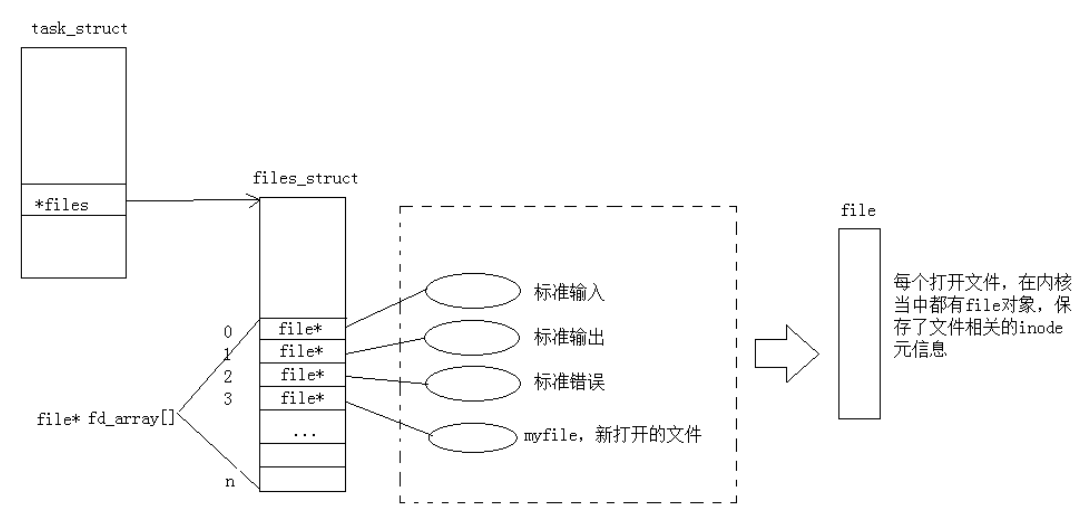
我们可以看到 fd_array 数组就保存在我们的进程的 task_struct 中,而文件描述符 fd 其实就是每个文件在 fd_array 数组中的下标,我们通过文件描述符就可以找到对应文件的 file 结构体,进而找到对应文件了。
Linux 进程默认打开 3 个文件:
0: stdin(标准输入),对应键盘;
1: stdout(标准输出),对应显示器;
**2:**stderr(标准错误),对应显示器。
我们可以看到,这三个文件分别占据了 fd_array 数组的前三个位置,对应下标0、1、2,因此,新打开的文件会从 3 开始分配文件描述符,如下验证:
cpp
#include<stdio.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <string.h>
int main()
{
int fd = open("myfile", O_WRONLY | O_CREAT, 0644);
if (fd < 0) // 失败时fd为-1
{
perror("open"); // 打印错误信息
return 1;
}
printf("%d\n", fd);
return 0;
}运行结果:

5.2 文件描述符的分配规则
操作系统会从文件描述符表中找到当前未被使用的最小下标值,作为新文件的文件描述符。
示例:验证分配规则
cpp
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
int main()
{
close(0); // 关闭标准输入(fd=0)
// 新打开的文件会占用最小未使用的fd=0
int fd = open("myfile", O_RDONLY);
if (fd < 0)
{
perror("open");
return 1;
}
printf("fd: %d\n", fd); // 输出fd: 0
close(fd);
return 0;
}运行结果:

6. 重定向
重定向是通过修改文件描述符表中fd对应的file结构体指针,让原本指向某个文件(如显示器)的fd指向另一个文件(如磁盘文件),从而改变数据的输入输出方向。
6.1 重定向的本质
以输出重定向(>)为例:关闭标准输出(fd=1),再打开一个新文件,此时新文件的fd会分配为 1(因为 1 是最小未使用下标)。之后所有向fd=1写入的数据,都会写入新文件而非显示器。
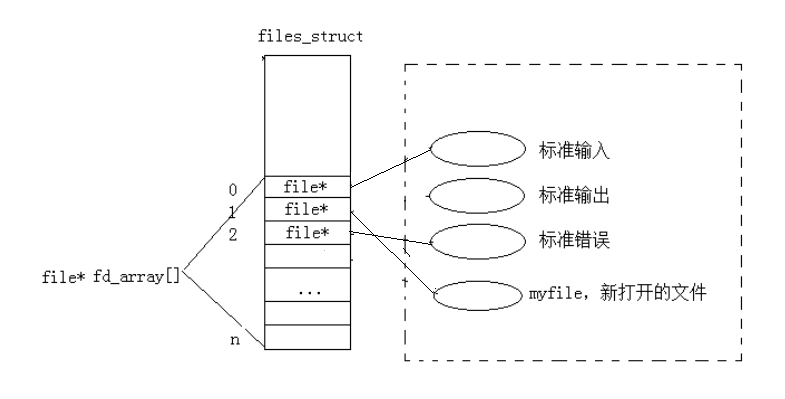
示例:实现输出重定向
cpp
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
int main()
{
close(1); // 关闭标准输出(fd=1)
// 打开文件,fd分配为1
int fd = open("myfile", O_WRONLY | O_CREAT, 0644);
if (fd < 0)
{
perror("open");
return 1;
}
printf("fd: %d\n", fd); // 本应输出到显示器,实际写入myfile
fflush(stdout); // 刷新缓冲区,确保数据写入文件
close(fd);
return 0;
}运行结果:
6.2 常用重定向符号
>: 输出重定向,覆盖文件原有内容;
>>: 追加重定向,在文件末尾追加内容;
**<:**输入重定向,从文件读取数据而非键盘。
输出重定向我们已经在上面说过了,下面说说输入重定向:
cpp
#include <stdio.h>
#include <sys/stat.h>
#include <sys/types.h>
#include <fcntl.h>
#include <unistd.h>
#include <string.h>
int main()
{
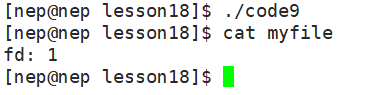
// 1. 关闭默认的标准输入(fd=0,对应键盘)
close(0);
// 2. 打开myfile(只读模式),此时fd会分配为0(因为0是当前最小未使用的文件描述符)
// 相当于把原本指向键盘的fd=0,改成指向myfile
int fd = open("myfile", O_RDONLY);
if (fd < 0)
{
perror("open fail:");
return 1;
}
// 3. 从标准输入(此时已重定向到myfile)读取数据并打印
char buf[128] = { 0 };
// scanf默认从fd=0读取,现在fd=0指向myfile,所以会读取myfile的内容
while (scanf("%s", buf) != EOF)
{
printf("%s\n", buf); // 打印到屏幕(stdout,fd=1)
}
// 4. 关闭文件
close(fd);
return 0;
}**代码逻辑:**原本scanf从键盘(fd=0)读取数据,现在通过close(0)+open("myfile"),让 fd=0 指向myfile;运行程序后,scanf会直接读取myfile里的内容,而不是等待键盘输入。
运行结果:
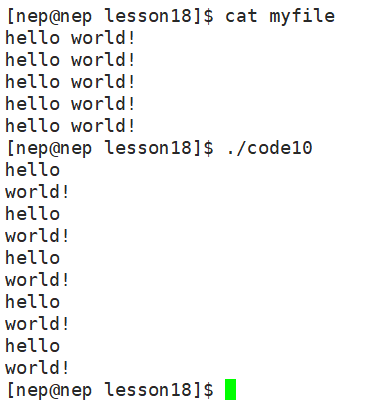
至于追加重定向 就简单多了,相比输出重定向的区别就是覆盖变成了追加,格式如下,只需加入O_APPEND即可:
cpp
int fd = open("myfile", O_WRONLY | O_APPEND | O_CREAT, 0664);6.3 补充
stdout(标准输出)与 stderr(标准错误):看似相同,实则不同
虽然 stdout 和 stderr 默认都输出到显示器,但二者的文件描述符、重定向行为、缓冲区策略都有本质区别 ------ 这也是我们能单独捕获错误信息的关键。
核心区别:文件描述符与重定向行为
stdout 对应的文件描述符是1,stderr 对应的是2;
输出重定向(>)默认只作用于 stdout(fd=1),不会影响 stderr(fd=2)。
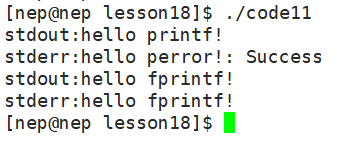
示例,先写一段同时输出 stdout 和 stderr 的代码:
cpp
#include<stdio.h>
int main()
{
// stdout输出(printf默认输出到stdout)
printf("stdout:hello printf!\n");
// stderr输出(perror默认输出到stderr)
perror("stderr:hello perror!");
// 显式指定stdout/stderr输出
fprintf(stdout, "stdout:hello fprintf!\n");
fprintf(stderr, "stderr:hello fprintf!\n");
return 0;
}运行结果:
如果我们直接输出,显而易见的会全部输出:
但是如果重定向的话就会有所不同了:
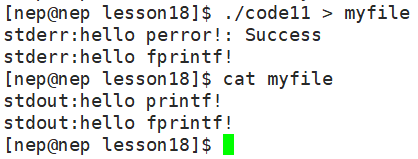
我们可以发现,只有标准输出信息成功重定向到了myfile中,而标准错误信息仍输出到显示器中了。这是为什么呢?其实是因为输出重定向符号(>)只会作用于 stdout(fd=1),不会影响 stderr(fd=2),./code11 > myfile 其实等同于 ./code11 1 > myfile
如果我们想要把错误信息单独存放到文件中,可以用如下指令,把2单独进行重定向:
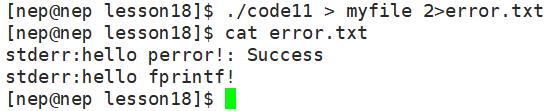
而如果我们实在想要把所有信息输入到一个文件中,也可以用如下指令,把2中存放的地址改为1中指向的地址:
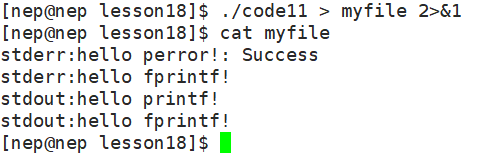
6.4 dup2 系统调用
dup2系统调用可直接复制文件描述符的指向,简化重定向实现:
cpp
int dup2(int oldfd, int newfd);**功能:**将oldfd对应的文件指针复制到newfd,若newfd已打开则先关闭;
调用成功:返回newfd(此时newfd和oldfd指向同一个文件);
调用失败:返回-1,同时设置errno记录错误原因(比如oldfd无效)。
如 dup(3,1),其实就是把3中存储的地址拷贝覆盖到1中:
示例:使用dup2实现输出重定向
cpp
#include <stdio.h>
#include <unistd.h>
#include <fcntl.h>
int main()
{
// 打开文件,获取oldfd
int oldfd = open("log.txt", O_CREAT | O_RDWR, 0644);
if (oldfd < 0)
{
perror("open");
return 1;
}
// 将oldfd复制到newfd=1(标准输出),实现重定向
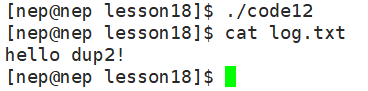
dup2(oldfd, 1);
// 后续写入stdout的数据都会写入log.txt文件
printf("hello dup2!\n");
fflush(stdout);
close(oldfd);
return 0;
}运行结果:
dup2的作用是让newfd和oldfd指向同一个文件,使用时要注意两点:
1. 若oldfd无效,dup2会失败,且newfd不会被关闭
比如oldfd是一个未打开的文件描述符(比如-1),调用dup2(oldfd, newfd)会直接失败;
此时newfd原本指向的文件不会有任何变化(不会被关闭)。
2. 若newfd和oldfd的值相同,dup2啥也不做,直接返回newfd比如oldfd=1、newfd=1,调用dup2(1, 1)时,因为两个文件描述符已经是同一个,所以dup2不会执行任何操作,直接返回1。
结语
好好学习,天天向上!有任何问题请指正,谢谢观看!