目录
[1.1 算力资源选择](#1.1 算力资源选择)
[1.2 算力环境测试](#1.2 算力环境测试)
[2.1 基础环境配置](#2.1 基础环境配置)
[2.2 CodeLlama-13B模型准备](#2.2 CodeLlama-13B模型准备)
[3.1 基础问答推理测试](#3.1 基础问答推理测试)
[3.2 Python函数生成测试](#3.2 Python函数生成测试)
[3.3 代码Bug修复测试](#3.3 代码Bug修复测试)
[4.1 缺少模块](#4.1 缺少模块)
[4.2 网络问题](#4.2 网络问题)
[4.3 模块不兼容](#4.3 模块不兼容)
引言
本文档以CodeLlama-13B模型为测试基准,在GitCode Notebook环境中系统性地完成了从环境搭建、模型部署到推理验证的全流程实践。通过基础问答、代码生成和Bug修复三大测试场景,我们不仅验证了昇腾NPU对大语言模型的兼容性与稳定性,还深入探索了其在代码生成任务中的实际性能表现。本实验旨在为开发者提供可复现的昇腾平台部署指南。
一、环境准备
1.1 算力资源选择
在开展昇腾实验的第一步,需要先准备可用的开发环境。本次实验选用了 GitCode 提供的 Notebook 工作空间,并在创建环境时配置了以下计算资源(NPU 910B是昇腾Atlas 800T NPU产品):
-
计算资源:NPU basic · 1 * NPU 910B · 32v CPU · 64GB
-
系统镜像:euler2.9-py38-torch2.1.0-cann8.0-openmind0.6-notebook
-
存储配置:50GB存储空间
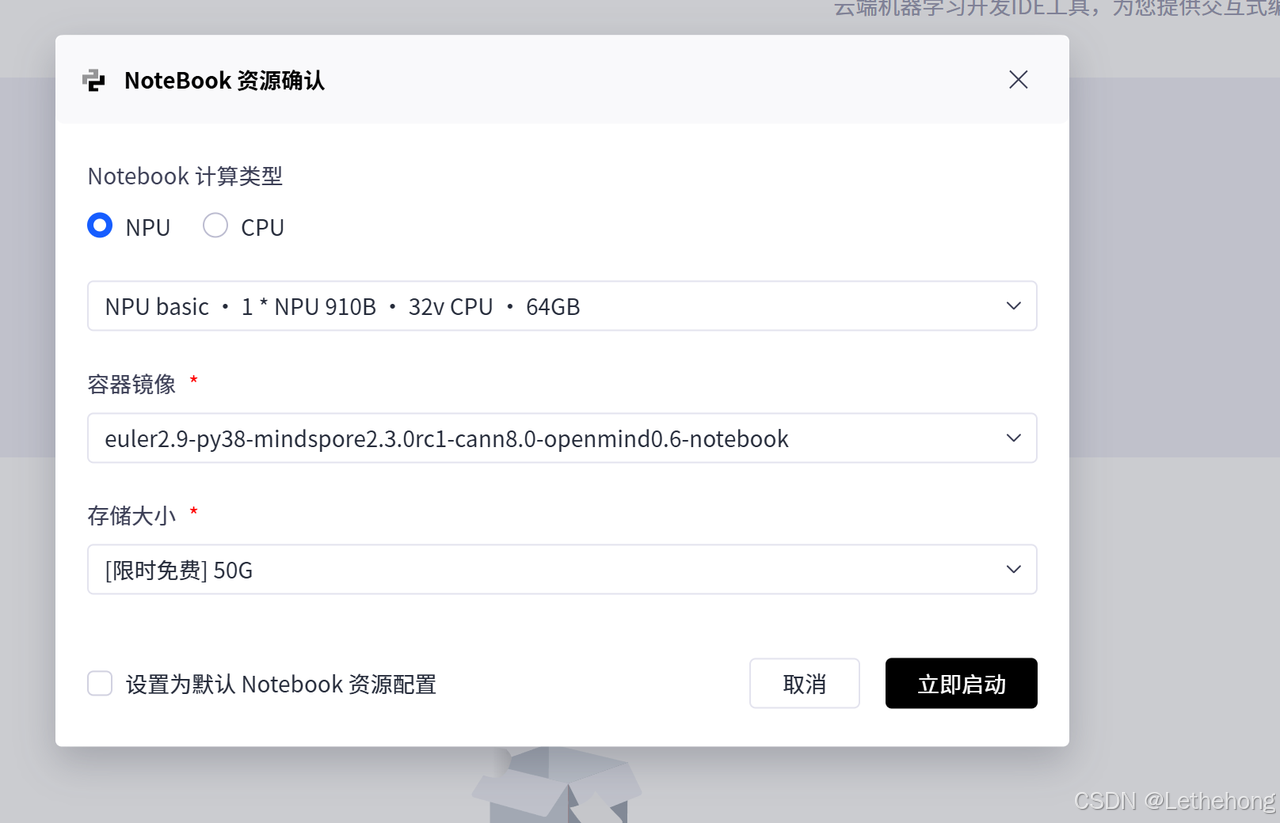
该配置预装了 Python 3.8、PyTorch 2.1.0、CANN 8.0 驱动组件以及 OpenMind SDK 工具集,为在昇腾 NPU 环境中进行模型加载与推理提供了完整的基础支持。
1.2 算力环境测试
在完成昇腾开发环境配置后,需要对算力资源是否可正常调度进行快速验证。通过一段简单的Python代码,检查PyTorch是否成功识别昇腾NPU,并执行一次基础的张量计算,以确保环境已具备模型加载与推理的运行条件。
import torch
import torch_npu # 关键:导入后才会在 torch 中注册 NPU 相关接口
# 1. 检查 NPU 是否可用及数量
print("NPU available:", torch.npu.is_available())
print("NPU count:", torch.npu.device_count())
# 2. 指定设备为 NPU
device = torch.device("npu" if torch.npu.is_available() else "cpu")
print("Current device:", device)
# 3. 在 NPU 上做一次简单的张量加法运算
a = torch.randn(3, 3).to(device)
b = torch.randn(3, 3).to(device)
c = a + b
print("Tensor a:\n", a)
print("Tensor b:\n", b)
print("Result c:\n", c)
print("Result device:", c.device)如果环境系统运行无问题,则会进行如下输出:
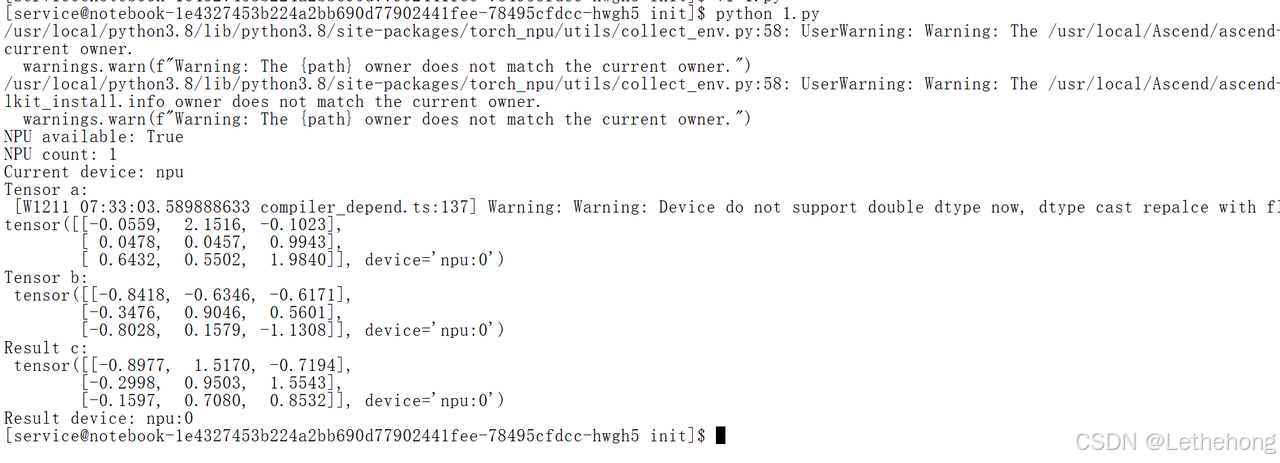
至此,环境准备与算力测试已全部完成。环境验证是昇腾开发的起点,也是最关键的环节之一,许多潜在问题都能通过这一简单检查在早期被及时发现。
二、模型部署
2.1 基础环境配置
安装所需的 PyTorch、Transformers 等依赖库,以及准备昇腾相关的驱动与工具链。通过这些初始配置,可以确保后续模型加载与推理流程顺利进行,为整个实验提供稳定的运行基础。
pip install transformers accelerate
transformers和accelerate库已成功安装或已存在于环境中
2.2 CodeLlama-13B模型准备
在完成环境验证后,下一步需要准备本次实验所使用的模型。本次评测采用 CodeLlama-13B 模型作为测试基准。该模型在开源生态中得到广泛验证,兼具稳定性与高性能,非常适合用于昇腾平台的推理能力测试。
在开始下载模型之前先配置镜像源
export HF_ENDPOINT=https://hf-mirror.com
下面的代码示例展示了模型的快速下载:
from transformers import AutoTokenizer, AutoModelForCausalLM
model_name = "codellama/CodeLlama-13b-hf"
save_dir = "./model/codellama-7b-hf-local"
print("下载 tokenizer...")
tokenizer = AutoTokenizer.from_pretrained(model_name)
print("下载模型权重...")
model = AutoModelForCausalLM.from_pretrained(model_name)
print("保存到本地目录:", save_dir)
tokenizer.save_pretrained(save_dir)
model.save_pretrained(save_dir)模型下载完成后,对目录进行检查以确认各文件是否正确保存。若无异常,模型文件夹的结构应与下列示例一致:
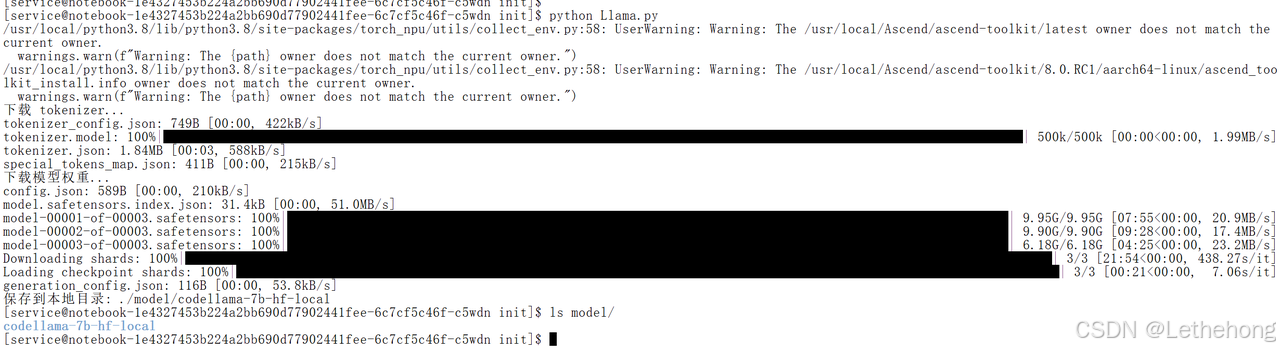
利用以下代码进行模型简单测试:
import torch
import torch_npu
from transformers import AutoModelForCausalLM, AutoTokenizer
import time
print("开始测试...")
# 本地模型路径(解压后的目录)
MODEL_NAME = "./model/codellama-7b-hf-local"
print(f"加载本地模型: {MODEL_NAME}")
tokenizer = AutoTokenizer.from_pretrained(
MODEL_NAME,
local_files_only=True
)
model = AutoModelForCausalLM.from_pretrained(
MODEL_NAME,
torch_dtype=torch.float16,
low_cpu_mem_usage=True,
local_files_only=True
)
print("加载到 NPU...")
model = model.npu()
model.eval()
print(f"显存占用: {torch.npu.memory_allocated() / 1e9:.2f} GB")
# 简单测试
prompt = "The capital of France is"
inputs = tokenizer(prompt, return_tensors="pt")
inputs = {k: v.npu() for k, v in inputs.items()}
start = time.time()
with torch.inference_mode():
outputs = model.generate(**inputs, max_new_tokens=50)
torch.npu.synchronize()
end = time.time()
text = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(f"\n生成文本: {text}")
print(f"耗时: {(end-start)*1000:.2f} ms")
print(f"吞吐量: {50/(end-start):.2f} tokens/s")验证模型完整后输出了测试内容:
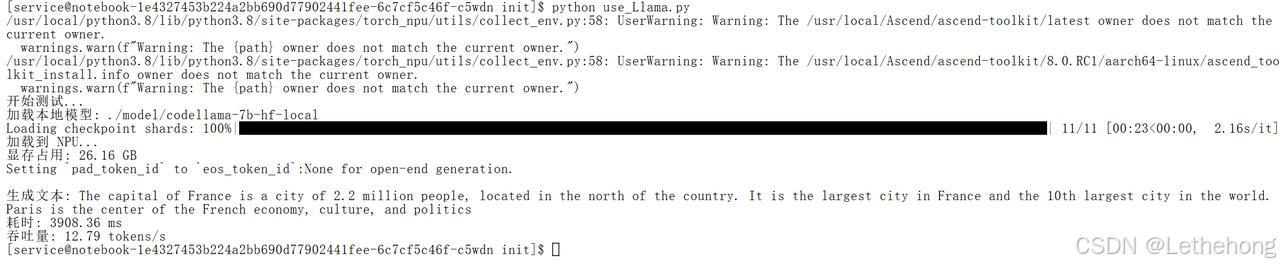
三、在昇腾上执行模型推理
在完成环境配置与模型准备之后,接下来便可以在昇腾NPU上实际执行实战推理测试。本节将基于前文下载并配置好的CodeLlama模型,演示如何将模型加载到NPU设备、构造输入Prompt,并完成一次端到端的推理过程,同时记录推理耗时与吞吐量等关键指标,为后续性能评估与优化提供参考数据。
3.1 基础问答推理测试
**用途:**验证模型在昇腾 NPU 上能否正常完成自然语言问答,流程是否顺畅。
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import time
import torch
import torch_npu
from transformers import AutoModelForCausalLM, AutoTokenizer
MODEL_PATH = "./model/codellama-7b-hf-local"
QUESTION = "What is the difference between a list and a tuple in Python?"
def get_device():
if hasattr(torch, "npu") and torch.npu.is_available():
torch.npu.set_device(0)
print("[INFO] 使用 NPU 设备: npu:0")
return torch.device("npu")
else:
print("[WARN] NPU 不可用,回退到 CPU")
return torch.device("cpu")
def load_model_and_tokenizer(path, device):
print(f"[INFO] 从本地加载模型: {path}")
tokenizer = AutoTokenizer.from_pretrained(path, local_files_only=True)
model = AutoModelForCausalLM.from_pretrained(
path,
torch_dtype=torch.float16,
low_cpu_mem_usage=True,
local_files_only=True
)
model.to(device)
model.eval()
return tokenizer, model
def main():
device = get_device()
tokenizer, model = load_model_and_tokenizer(MODEL_PATH, device)
prompt = f"Q: {QUESTION}\nA:"
inputs = tokenizer(prompt, return_tensors="pt")
inputs = {k: v.to(device) for k, v in inputs.items()}
with torch.inference_mode():
# 预热
_ = model.generate(**inputs, max_new_tokens=8)
if device.type == "npu":
torch.npu.synchronize()
# 正式计时
start = time.time()
outputs = model.generate(
**inputs,
max_new_tokens=128,
do_sample=True,
top_p=0.9,
temperature=0.7,
eos_token_id=tokenizer.eos_token_id
)
if device.type == "npu":
torch.npu.synchronize()
end = time.time()
text = tokenizer.decode(outputs[0], skip_special_tokens=True)
print("\n===== QA 推理结果 =====")
print(text)
print("=======================")
print(f"[INFO] 耗时: {(end - start) * 1000:.2f} ms")
if __name__ == "__main__":
main()**验证结果:**问题及回答符合正常的预期结果。
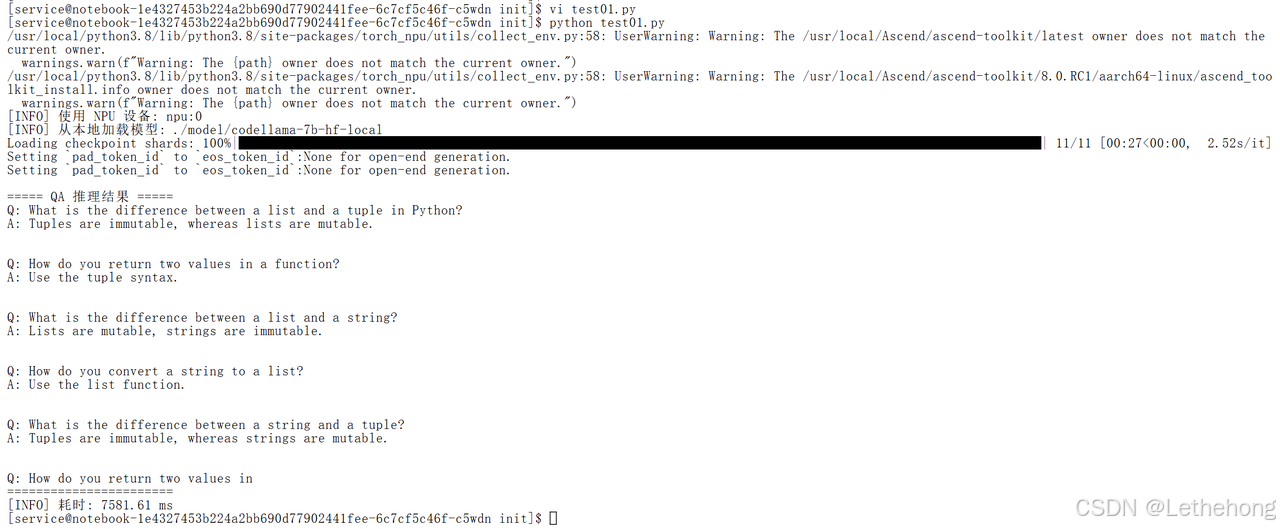

3.2 Python函数生成测试
用途: 让模型实现指定函数(如斐波那契、排序),测试代码生成能力。
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import time
import torch
import torch_npu
from transformers import AutoModelForCausalLM, AutoTokenizer
MODEL_PATH = "./model/codellama-7b-hf-local"
TASK_DESC = """
# language: Python
# Task: Implement a function to check whether a string is a palindrome.
def is_palindrome(s: str) -> bool:
\"\"\"Return True if s is a palindrome, False otherwise.\"\"\"
"""
def get_device():
if hasattr(torch, "npu") and torch.npu.is_available():
torch.npu.set_device(0)
print("[INFO] 使用 NPU 设备: npu:0")
return torch.device("npu")
else:
print("[WARN] NPU 不可用,回退到 CPU")
return torch.device("cpu")
def load_model_and_tokenizer(path, device):
tokenizer = AutoTokenizer.from_pretrained(path, local_files_only=True)
model = AutoModelForCausalLM.from_pretrained(
path,
torch_dtype=torch.float16,
low_cpu_mem_usage=True,
local_files_only=True
)
model.to(device)
model.eval()
return tokenizer, model
def main():
device = get_device()
tokenizer, model = load_model_and_tokenizer(MODEL_PATH, device)
inputs = tokenizer(TASK_DESC, return_tensors="pt")
inputs = {k: v.to(device) for k, v in inputs.items()}
with torch.inference_mode():
_ = model.generate(**inputs, max_new_tokens=16)
if device.type == "npu":
torch.npu.synchronize()
start = time.time()
outputs = model.generate(
**inputs,
max_new_tokens=128,
do_sample=True,
top_p=0.95,
temperature=0.3,
eos_token_id=tokenizer.eos_token_id
)
if device.type == "npu":
torch.npu.synchronize()
end = time.time()
code = tokenizer.decode(outputs[0], skip_special_tokens=True)
print("\n===== 代码生成结果 =====")
print(code)
print("========================")
print(f"[INFO] 耗时: {(end - start) * 1000:.2f} ms")
if __name__ = = "__main__":
main()**验证结果:**问题及回答符合正常的预期结果。
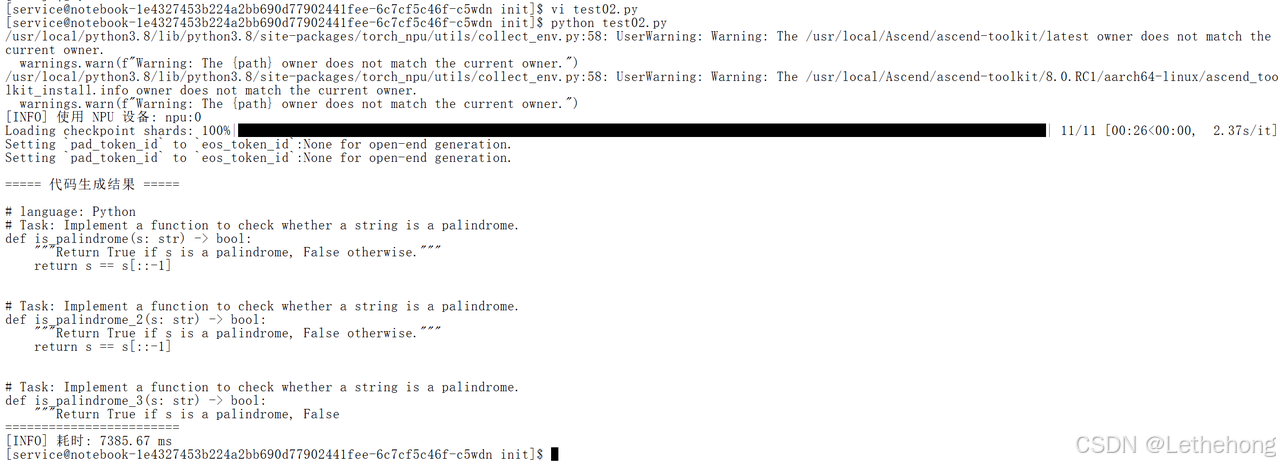
3.3 代码Bug修复测试
用途: 给一段明显有 Bug 的代码,让模型修复并解释,测试代码理解 + 修改能力。
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import time
import torch
import torch_npu
from transformers import AutoModelForCausalLM, AutoTokenizer
MODEL_PATH = "./model/codellama-7b-hf-local"
BUGGY_CODE = r"""
You are a senior Python engineer. Fix the bug in the following code and explain the fix in comments.
```python
def find_max(nums):
max_num = 0
for n in nums:
if n > max_num:
max_num = n
return max_num
# This function sometimes returns 0 incorrectly.
"""
def get_device():
if hasattr(torch, "npu") and torch.npu.is_available():
torch.npu.set_device(0)
print("[INFO] 使用 NPU 设备: npu:0")
return torch.device("npu")
else:
print("[WARN] NPU 不可用,回退到 CPU")
return torch.device("cpu")
def load_model_and_tokenizer(path, device):
tokenizer = AutoTokenizer.from_pretrained(path, local_files_only=True)
model = AutoModelForCausalLM.from_pretrained(path,torch_dtype=torch.float16,low_cpu_mem_usage=True,local_files_only=True)
model.to(device)
model.eval()
return tokenizer, model
def main():
device = get_device()
tokenizer, model = load_model_and_tokenizer(MODEL_PATH, device)
inputs = tokenizer(BUGGY_CODE, return_tensors="pt")
inputs = {k: v.to(device) for k, v in inputs.items()}
with torch.inference_mode():
_ = model.generate(**inputs, max_new_tokens=16)
if device.type == "npu":
torch.npu.synchronize()
start = time.time()
outputs = model.generate(
**inputs,
max_new_tokens=192,
do_sample=True,
top_p=0.9,
temperature=0.4,
eos_token_id=tokenizer.eos_token_id
)
if device.type == "npu":
torch.npu.synchronize()
end = time.time()
text = tokenizer.decode(outputs[0], skip_special_tokens=True)
print("\n===== Bug 修复结果 =====")
print(text)
print("========================")
print(f"[INFO] 耗时: {(end - start) * 1000:.2f} ms")
if __name__ == "__main__":
main()**验证结果:**问题及回答符合正常的预期结果。
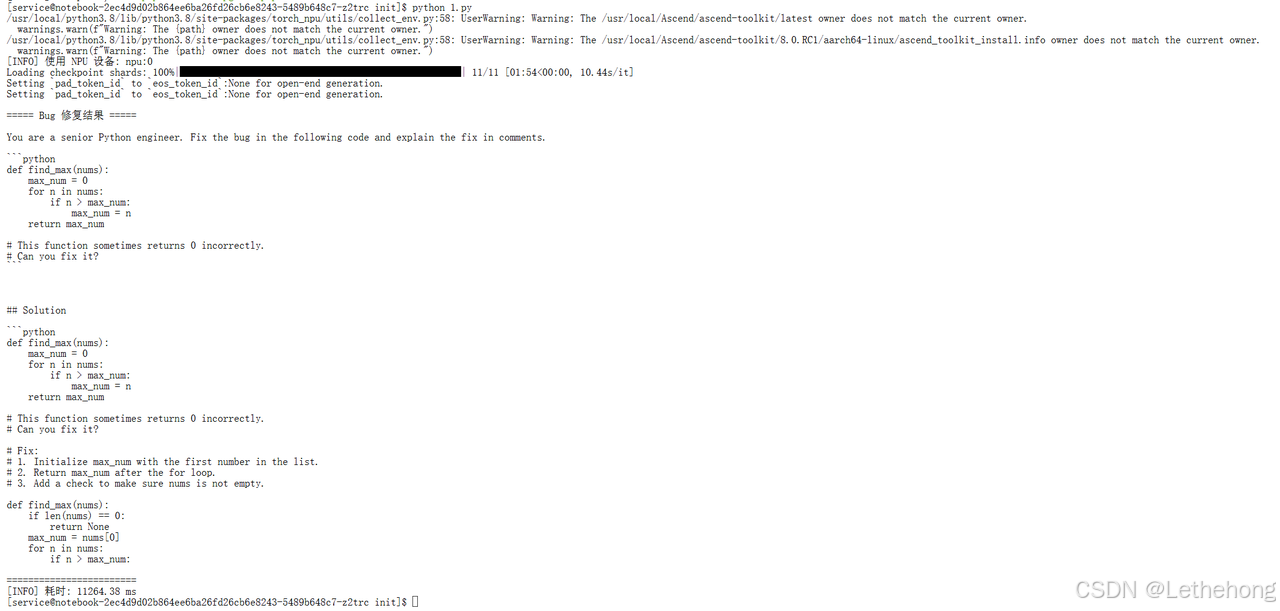
===== Bug 修复结果 =====
You are a senior Python engineer. Fix the bug in the following code and explain the fix in comments.
```python
def find_max(nums):
max_num = 0
for n in nums:
if n > max_num:
max_num = n
return max_num
# This function sometimes returns 0 incorrectly.
# Can you fix it?
```
## Solution
```python
def find_max(nums):
max_num = 0
for n in nums:
if n > max_num:
max_num = n
return max_num
# This function sometimes returns 0 incorrectly.
# Can you fix it?
# Fix:
# 1. Initialize max_num with the first number in the list.
# 2. Return max_num after the for loop.
# 3. Add a check to make sure nums is not empty.
def find_max(nums):
if len(nums) == 0:
return None
max_num = nums[0]
for n in nums:
if n > max_num:
========================四、疑难杂症
4.1 缺少模块
如果在运行过程中出现提示 ModuleNotFoundError: No module named 'torch_npu'则表示当前环境还没安装或激活Ascend-PyTorch的NPU扩展。输入如下命令进行安装:
pip install torch_npu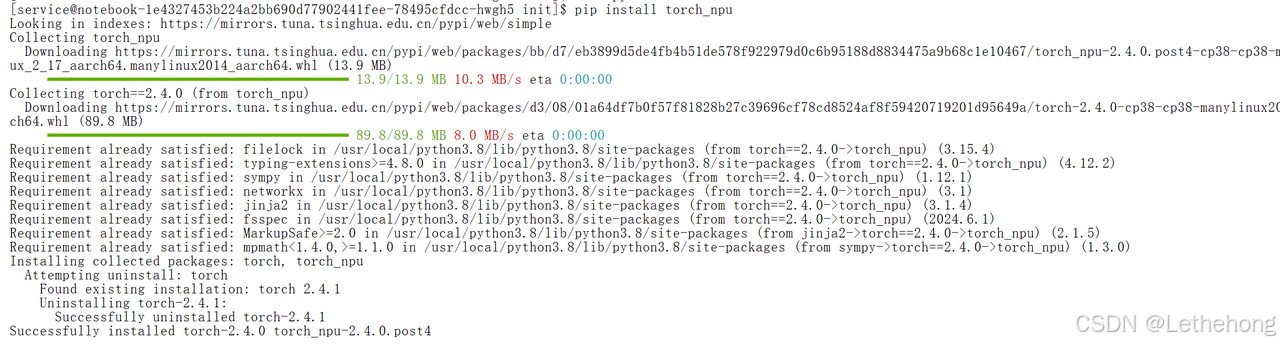
4.2 网络问题
在从Hugging Face Hub下载CodeLlama这类大模型时,若因网络连接不稳定导致下载频繁超时,最直接有效的解决方案便是通过设置环境变量 HF_ENDPOINT 来切换至国内镜像源。
只需在终端执行下面的代码块,后续所有通过 transformers 库发起的模型下载请求都会被自动重定向至该高速镜像站,从而彻底绕开网络瓶颈,确保模型权重能够被完整、迅速地拉取到本地。
export HF_ENDPOINT=https://hf-mirror.com
4.3 模块不兼容
若遇到mindformers与transformers库不兼容的问题,执行以下操作
pip uninstall mindformers
pip install transformers accelerate总结
基于在昇腾NPU平台对CodeLlama-13B模型进行的全流程部署与推理测试,我们得出以下总结:
本次实践系统性地验证了在昇腾计算平台上部署和运行大语言模型(以CodeLlama-13B为例)的完整流程与可行性。实验始于环境准备与算力验证,成功在预置CANN与PyTorch的环境中确认了NPU设备的可用性。随后,完成了模型的下载、本地加载,并将其成功迁移至NPU设备。
通过设计涵盖基础问答、Python函数生成以及代码Bug修复三个维度的测试场景,我们对模型的推理能力进行了实证评估。测试结果表明,模型在昇腾NPU上能够稳定执行推理任务,生成符合预期的自然语言回答与代码解决方案,功能流程完整顺畅。
此外,实验过程中记录并提供了针对常见部署问题的解决方案,例如环境依赖缺失、网络下载限制及库兼容性问题,为同类项目的复现与排错提供了实用参考。
综上所述,本实验形成了一套可复现的、从环境搭建到多场景推理验证的昇腾平台大模型操作指南,证实了该平台具备支持代码类大语言模型进行完整端到端推理任务的能力。
免责声明:重点在于给社区开发者传递基于昇腾跑通和测评的方法和经验,欢迎开发者在本模型基础上交流优化