社交网络不仅塑造着我们与现实世界的连接方式,更隐藏着复杂的关系结构与传播规律。
从寻找"你可能认识的人 "到引导热门话题,这些看似简单的功能背后,是"社交网络挖掘"这一学科的精妙理论体系。
它不仅关心谁与谁相连,更关注这些连接如何随时间演变、如何形成社区 ,以及信息与影响力如何在网络中共振。
本文将从网络的动态特性出发,解析中心性与声望 如何衡量节点的关键性,探讨社区检测如何揭示内部紧密的群体,
并深入介绍链接预测 与影响力最大化的算法逻辑,为你揭开社交网络海量数据背后的运行机理。
目录
[1. 特性](#1. 特性)
[2. 中心性与声望 centrality & prestige](#2. 中心性与声望 centrality & prestige)
[3. Community Detection 找社区](#3. Community Detection 找社区)
[3.1 Kernighan-Lin 迭代改进式分两团](#3.1 Kernighan-Lin 迭代改进式分两团)
[3.2 Girvan-Newman 自顶向下](#3.2 Girvan-Newman 自顶向下)
[3.3 Multi-Level Gragh Partitioning 多层划分](#3.3 Multi-Level Gragh Partitioning 多层划分)
[4. 分类 & 标签传播](#4. 分类 & 标签传播)
[4.1 Spectral Clustering 谱聚类 - 拉普拉斯特征分解](#4.1 Spectral Clustering 谱聚类 - 拉普拉斯特征分解)
[4.2 迭代分类算法(ICA)-- 解决初始标签稀疏](#4.2 迭代分类算法(ICA)-- 解决初始标签稀疏)
[4.3 Label Propagation with Random Walks 随机游走标签传播](#4.3 Label Propagation with Random Walks 随机游走标签传播)
[5. Link Prediction 预测未来新的连边生成 - 你可能认识的人](#5. Link Prediction 预测未来新的连边生成 - 你可能认识的人)
[6. Social Influence Analysis 社交影响力分析 - 贪心](#6. Social Influence Analysis 社交影响力分析 - 贪心)
[6.1 Linear Threshold Model 线性阈值模型 定义种子点集的影响力](#6.1 Linear Threshold Model 线性阈值模型 定义种子点集的影响力)
1. 特性
-
Tradic Closure 三元闭包: 有共友的两个人,未来成为朋友的可能性会更高。
-
社交网络动态性 :Degree 度越高 ,未来被其他点连到的概率更大。
-
边数随节点数的增长幅度 超线性 1~2次;
-
任意两个节点平均距离很小(通过六个人连接某某)小世界效应
-
随着网络逐渐密集化 ,节点之间的平均距离会随时间缩小 ,出现一个 "巨型连通分量"。
互联网社交、信息传播 数据的发展:
(推荐系统抖音小红书,刚注册就推一堆人,这些人很多都是粉丝量已经很大的 很火的人)
20年前邮件通讯为主的时候,关注垃圾邮件问题;
搜索引擎火的时候 创建假网站链接,提高 PageRank 分数;
现在 创账号涨粉 ,粉丝量高之后虹吸效应。
2. 中心性与声望 centrality & prestige
无向图 (QQ 微信 互相认识)有向图(小红书 抖音 关注、粉丝)

无向图 Centrality 中心性;值高的对整个社交网络影响大。
有向图 Prestige 权威性 (被很多点指向)粉丝很多;
gregariousness 群居性(指向了很多点)关注了很多;
中心 不止看单个点性质,要看对整个网络的作用 。有的可能粉丝多,但信息传播上作用不大。
(传播作用 比如一个大V说的话,它的粉丝传出去,媒体再传)
1. 物理中心 :到其他点平均距离越低,越在中心。
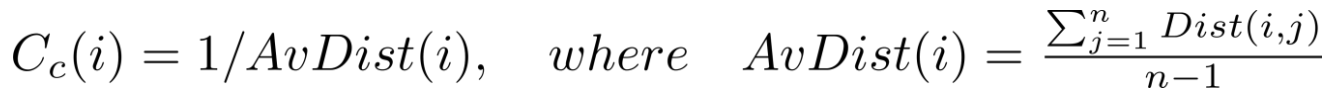
- Proximity Prestige 近距声望:能传播到的人
Influence(i) 可通过指向到达 i的点的个数(指向代表关注 说明是直接/间接粉丝)
代表 i 发出的信息,能通过粉丝关系 传播出去覆盖的用户数。
- 刻画影响信息流动的点(对网络连通性影响)
betweenness centralnality 两两最短路通过这个点的比例。
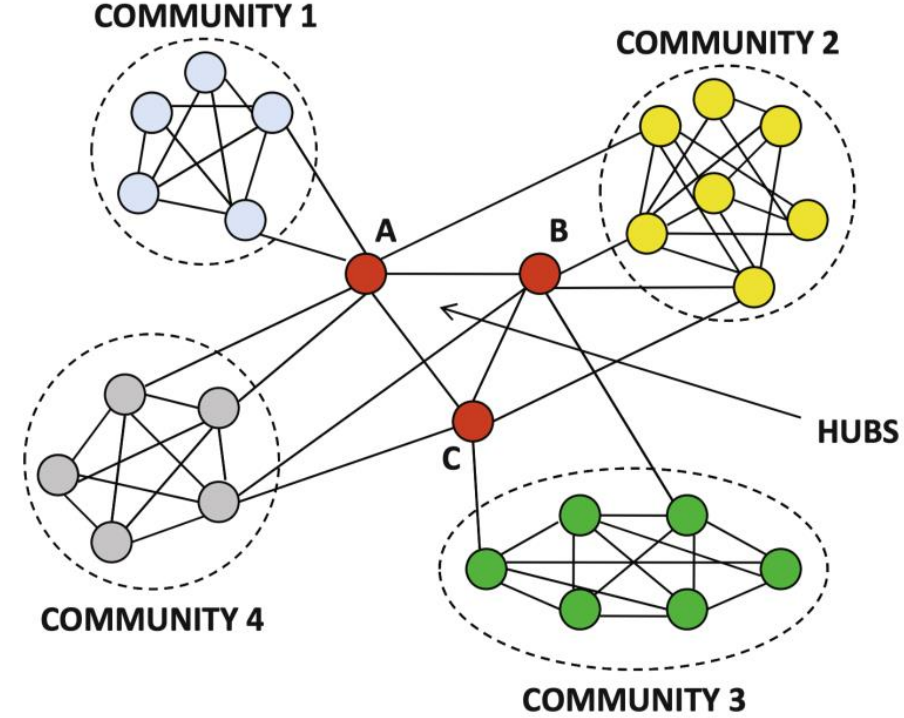
3. Community Detection 找社区
有高度数的 hub 中心 连接不同 community。
3.1 Kernighan-Lin 迭代改进式分两团
最大化社区内部的边数 (等价地,最小化社区之间的边数)
先初始化 分两团,再不断贪心地 从两端挑两个对调,来提高目标函数。
我们定义一个节点 x 的 外部代价 和 内部代价:衡量 x 在哪一端合适。
-
E_x:节点 x 与另一个社区相连的边数。 -
I_x:节点 x 与自己所在社区相连的边数。 D_x = E_x - I_x D_x 越大越该对调。 -
g_xy = D_x + D_y - 2 * w_{x,y} 对调 x,y 的收益
-
(减去 2*(x,y)是否连接 因为 x,y 都还在对方对面没变)
3.2 Girvan-Newman 自顶向下
high betweenness 的关键边 ,连接不同 cluster 的概率大。
(断掉之后很多路通不了 ,分成了小块)不断把 最关键的边打断。
edge betweenness 计算过程:
-
每次指定一个起始点 s ,算单源最短路,到每个点最短路径长度SP 和数目 N。
-
从最远的节点回退,每条边贡献 = 子节点的 "流量" × 父节点的最短路径数 / 子节点的所有父节点的最短路径数之和。
每次重复 1. 删掉 betweenness 最高的那条边 2. 整体重算一下 edge betweenness。
3.3 Multi-Level Gragh Partitioning 多层划分
METIS 快速获得高质量解:
- compress 相邻节点合并(粗化)为一个节点;
(合并配对 方法:未匹配的和未匹配 任意 邻居,权重最大 的邻居,边密度最高的邻居)
- 再对小图进行划分 (简单);3. 再映射回去(反粗化)。
4. 分类 & 标签传播
4.1 Spectral Clustering 谱聚类 - 拉普拉斯特征分解
把节点映射到多维空间 中,同时保留网络的 "局部聚类结构"(之前相近 映射后也相近)。
给定边权矩阵W,为每个节点学习一个嵌入 y ,边权大的距离要小。
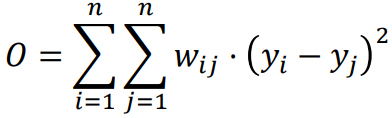 展开为对角阵的 和 两两的。
展开为对角阵的 和 两两的。
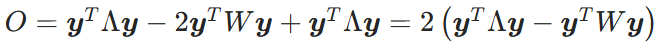
拉普拉斯矩阵 L = 对角度矩阵 - 邻接矩阵 W,可改写为如下的约束问题:
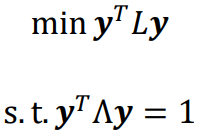 其中 对角阵
其中 对角阵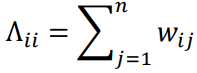 拉普拉斯
拉普拉斯 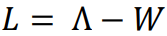
对拉格朗日乘子求导得,y为矩阵 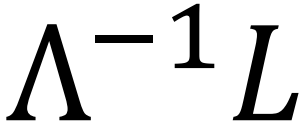 的特征向量:
的特征向量:
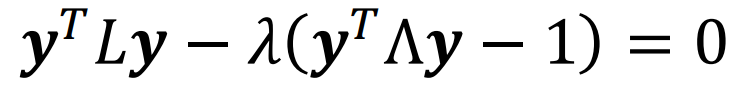
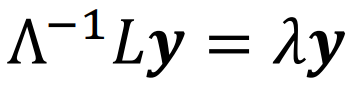
4.2 迭代分类算法(ICA)-- 解决初始标签稀疏
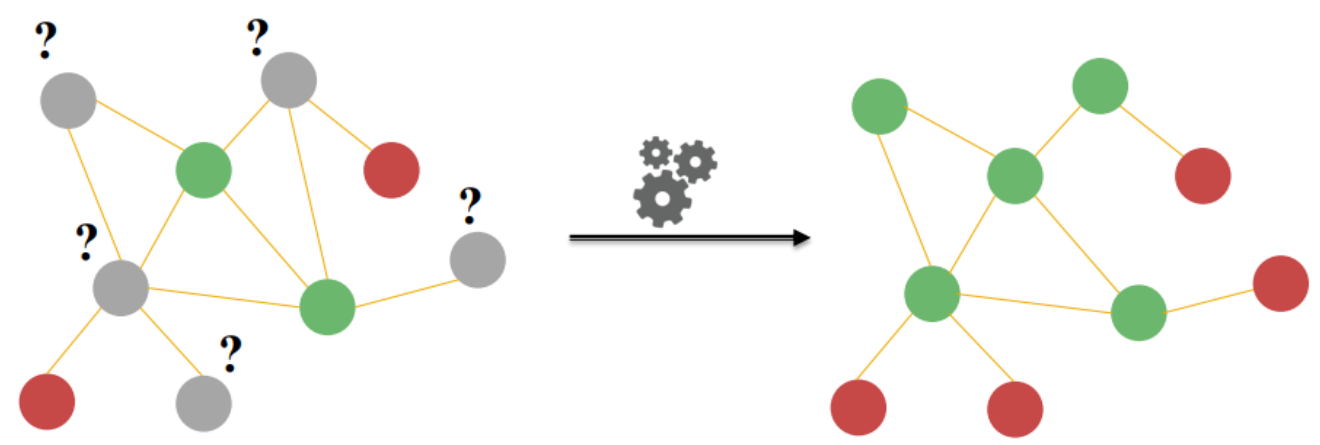
只有少量节点的标签已知 ,需要用这些已知标签,给未知标签的节点做分类。
(难点:初始标签稀疏)
思路:属性相似 的节点通常是相连 的(社交网络中的 "同质性 ",比如兴趣相同的用户会互相关注)
迭代自训练框架 ------ 通过不断把 "高置信度 的预测结果" 加入训练集 ,缓解 "标签稀疏" 的问题。
利用节点特征以外 额外构造 link feature 链接特征:
邻居的 "类别分布"、节点的度、PageRank 值、连通性等等。

优点 : 1. 能同时利用 "节点内容 特征" 和 "图结构特征" 进行分类;
- 不强烈依赖 "同质性" 假设,因此可用于社交网络之外的领域。
缺点 : 早期迭代中预测错误 的标签,会被加入训练集,导致后续错误不断传播、放大。
4.3 Label Propagation with Random Walks 随机游走标签传播
让随机游走从无标签节点出发 ,最终停在有标签节点 ,用停留概率给无标签节点分配标签。
"最可能终止 " 的标签,就是节点 i 的预测标签。
关键假设:图必须是标签连通的 ------ 每个无标签节点都能通过随机游走到达至少一个有标签节点。
转移矩阵 P 的构建:
- 移除有标签 节点的出边,替换为自环。
- 无标签节点按所有出边的权重比例 ,作为游走概率。
π 作为走 t 步之后在某点的概率:初始是自己概率为1 其他概率为 0。
乘以P进行转移 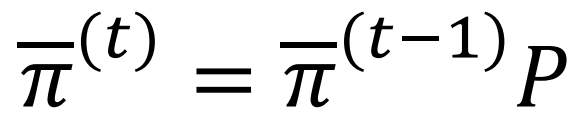
无穷次后收敛 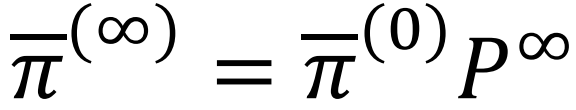
求解收敛的 P ∞ 用特征值分解。
性质:△ 的特征值绝对值都不超过 1 ,无穷次方则 只有λ=1 的位置是1,其余都是0。
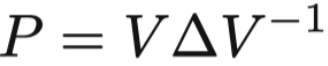
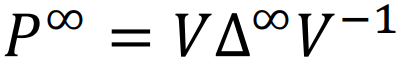
5. Link Prediction 预测未来新的连边生成 - 你可能认识的人
- 结构型 :两个节点若在邻居中共享相似节点,则更可能建立连接;
指标:共友数 ,朋友交集 除以并集 ,共友权重求和(朋友少的权重高)
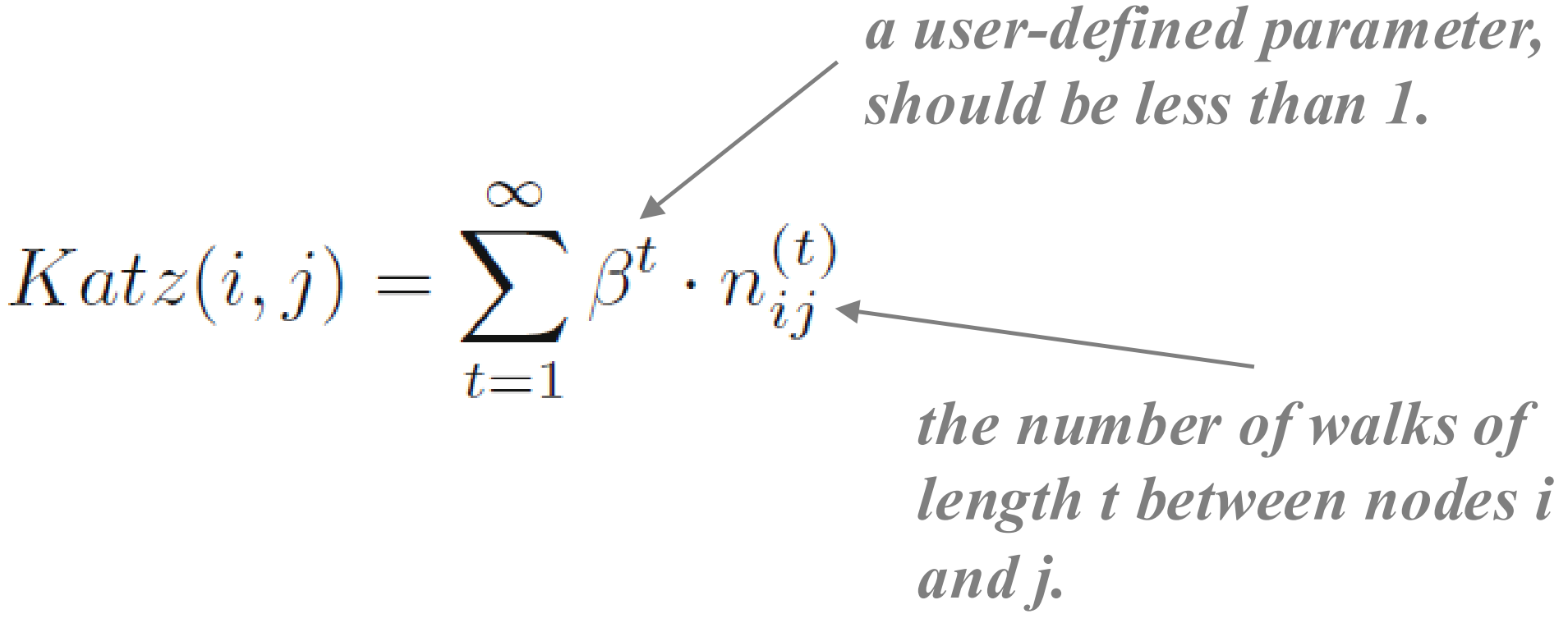
路径:i 到 j 长度为 t 的路径数,乘以系数的 t 次方。
- 内容型 :节点若有相似的内容,则更可能形成链接。
建模为二分类问题(有链接 还是没链接)作为正负样本。
建模为缺失值估计 问题,对于邻接矩阵 为 0 的位置还没链接;当作一个缺失值,算未来链接概率。
6. Social Influence Analysis 社交影响力分析 - 贪心
在社交网络中选 k 个"种子节点",通过在这些节点上传播信息,实现影响力的最大化。
(做广告的 如何选用户推广 信息)k 是预算范围内 能推广的用户数。
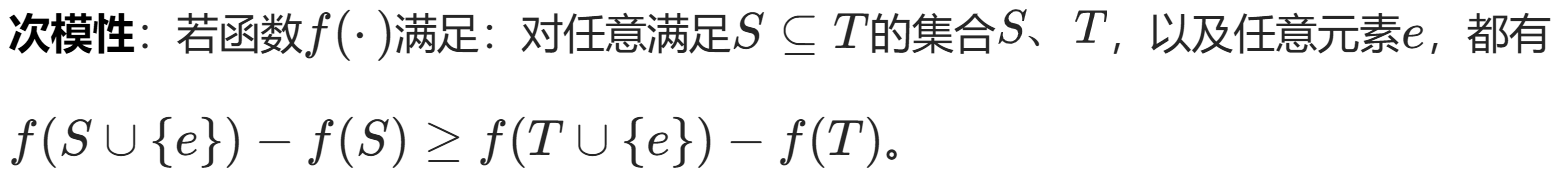
边际效益递减:前 k-1 个点集基础上 加第 k 个点的边际效益;大于前 k 个点集基础上 加第 k+1 个点。
用贪心 ,每次取增加影响力最大的;由于次模性 ,保证结果不低于最优解的 e-1 / e ≈ 0.632
6.1 Linear Threshold Model 线性阈值模型 定义种子点集的影响力
是否接受到影响 -> 激活与非激活;被激活将一直保持 并会传播给未激活的。
定义活跃邻居影响力 :被激活 的邻居 边权和
预先定义了每个节点的 激活阈值 (可用一个均匀分布 活跃邻居影响力超过阈值则被激活)
种子节点都设定激活后,不断循环激活;直至没有新点能被激活了。