
作者:罗一鑫 StarRocks Committer
导读:在存算分离架构下,"一次性导入海量历史数据"正成为被放大的隐形风险。本文介绍 StarRocks 如何从写入源头重构大导入路径:通过"内存→本地磁盘 spill→集中 merge→对象存储",减少远程写入和重复开销,降低 S3 写入次数并放大文件粒度,释放本地 I/O 能力,从源头缓解小文件问题,帮助用户以更低投入获得更高效、更稳定的使用体验。
大规模导入,在存算分离架构下变成"放大问题"
在越来越多用户将历史数据整体迁移至 StarRocks 的过程中,"一次性导入海量历史数据"逐渐成为常见操作场景。表面上看,这只是一次离线灌库任务;但在存算分离 + 对象存储的架构下,如果处理不当,很容易引发导入效率下降、底层小文件激增、查询性能受损等一连串连锁反应。
StarRocks 作为一款分布式列式数据库,底层采用类似 LSM-Tree 的存储结构:新写入的数据首先进入内存中的 memtable,经排序等处理后再由后台线程刷盘至持久化存储,并通过后续的 Compaction 将多个小文件合并为更大的有序文件。在常规规模的增量写入下,这套机制可以很好地兼顾写入性能与查询性能;但在大批量导入历史数据时,问题会被显著放大:
-
历史数据量巨大、涉及 Tablet 数量多。每个 Tablet 维护独立的 memtable,在高并发导入的压力下,系统会频繁将 memtable 刷盘,短时间内生成大量的小文件。
-
在存算分离架构下,计算与存储解耦,用户往往会从较少数量、较小规格的 CN 节点开始使用集群(甚至仅有 1 个 CN 节点),有限的 CPU 和内存进一步加剧了"小 memtable、频繁刷盘、小文件堆积"的问题。
-
存算分离让用户可以在完成批量导入后快速缩容或释放计算节点,仅保留对象存储中的数据以节约成本。但这也意味着导入阶段产生的大量小文件没有得到及时、充分的合并整理,底层存储中会长期残留数量众多的小文件。
-
当用户再次拉起集群对这些历史数据进行查询时,需要扫描和处理的大量小文件会显著拉低查询性能。
可以看到,这些问题在存算分离架构中更为突出,本质原因在于:用户更倾向于使用少量、小规格的计算节点来完成大规模历史数据导入,这一选择会导致小文件泛滥、进而导致查询性能受损等问题。
从写入源头下手,重构大导入路径
要想真正解决"大导入引发的小文件问题",仅依靠后续的 Compaction 合并文件远远不够。通过对整个写入链路的分析可以发现,问题的根源主要集中在以下几个方面:
-
受限于内存,CN 节点往往在 memtable 尚未写满时就被迫刷盘,单次刷盘生成的文件体积偏小;
-
在存算分离架构下,每次刷盘都需要直接写入对象存储,高延迟的远程 I/O 叠加频繁写入,使导入效率大幅下降;
-
每一次落盘都伴随数据排序、编码、压缩以及索引构建等完整写入流程,频繁重复这些工作会消耗大量 CPU 资源;
-
最终,这些过多、过小的文件还需要再次被读取参与 Compaction 合并,前期投入的排序、编码等工作在一定程度上变成了"无用功",进一步浪费系统资源。
基于上述分析,StarRocks 在存算分离场景下重新设计了大导入的写路径,从源头对写入流程进行优化:
-
写入阶段:优先 Spill 到本地磁盘当 memtable 写满时,不再直接将数据写入对象存储,而是通过 spill 能力将中间数据缓存在 CN 本地磁盘。这样既避免了高延迟的对象存储写入,也避免了在尚未稳定成型之前就反复进行排序、编码等"重工作"。在本地磁盘空间不足时,中间数据也可以有选择地溢写到 S3 等对象存储中,保证整体流程的稳定性。
-
收敛阶段:集中 Merge 后再写入对象存储 当本次大导入任务的数据全部写入完成后,系统再对上述 spill 生成的临时文件进行集中 merge,将其整理为结构合理、粒度适中的目标数据文件,最终写入对象存储。
整体来看,新的大导入路径可以概括为:"内存 → 本地磁盘 Spill → 集中 Merge → 写入对象存储"。
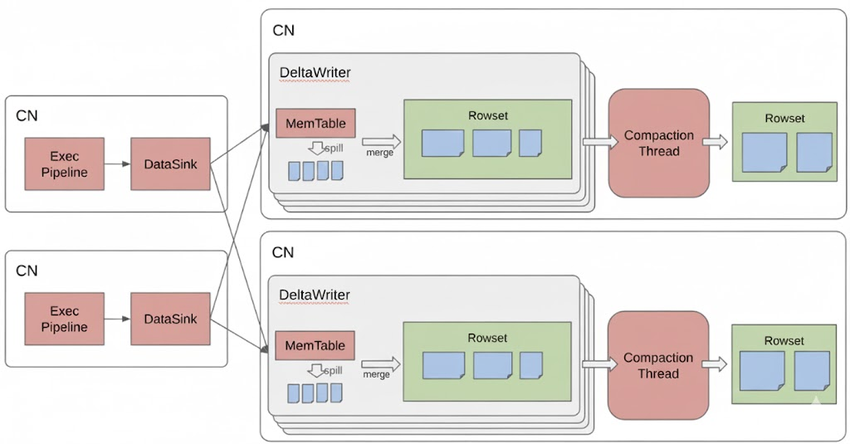
这种大导入路径的优化,主要在三个方面带来了显著收益:
-
当 memtable 写满时,系统仅将中间结果 spill 到本地磁盘,而不直接写入后端对象存储,从而显著提升了这一阶段的写入性能。
-
同时在 spill 阶段,只需将 memtable 中的数据快速落盘,无需执行完整的数据排序、编码、索引构建等操作带来的额外资源开销。
-
中间阶段产生的临时文件会在最终落盘前统一 merge,整合成数量更少、粒度更大的目标文件写入对象存储。这样一方面显著减少了底层小文件数量,几乎不再依赖额外的后台 Compaction 来来进行合并;另一方面,即使在导入完成后立即发起查询,也能获得稳定的性能表现。
效果对比
为了评估上述大导入优化在真实场景下的收益,我们在存算分离集群上设计了两组对比测试:
-
单并发场景:单个导入任务,导入 1 TB 数据,对比优化前后的导入耗时及导入完成后的查询性能;
-
多并发压力场景:10 个并发导入任务,每个导入 100 GB(总量同样为 1 TB),对比优化前后的导入性能以及导入完成后的查询表现。
测试一:单并发大数据集导入
在这一测试中,我们使用 Broker Load 以单并发方式一次性导入 1 TB 数据集(约 2.7 亿行)。在优化前,导入阶段耗时约 2 小时 15 分钟,此后系统又花费约 34 分钟完成后台 Compaction。从用户视角看,从提交导入任务到系统恢复为稳定可查询状态,总耗时约 2 小时 50 分钟。
*************************** 3. row ***************************
JobId: 10409
State: FINISHED
Type: BROKER
SinkRows: 270000000
LoadStartTime: 2024-12-27 10:59:12
LoadFinishTime: 2024-12-27 13:14:04导入完成后,该分区的 compaction score:
AvgCS: 358.06 P50CS: 299.00 MaxCS: 1056.00当导入完成后立即发起如下查询:
sql
mysql> select count(*) from duplicate_21_0;
+-----------+
| count(*) |
+-----------+
| 270000000 |
+-----------+
1 row in set (56.25 sec)优化后,导入总计耗时约 2h 42min
sql
*************************** 2. row ***************************
JobId: 10642
State: FINISHED
Type: BROKER
SinkRows: 270000000
LoadStartTime: 2024-12-27 16:14:08
LoadFinishTime: 2024-12-27 18:56:00导入完成后,compaction score 已经是最佳值,无需后台合并:
AvgCS: 2.39 P50CS: 2.00 MaxCS: 5.00导入完成后立刻发起查询:
sql
mysql> select count(*) from duplicate_21_0;
+-----------+
| count(*) |
+-----------+
| 270000000 |
+-----------+
1 row in set (0.72 sec)测试二:多并发大数据集压力测试
在这一测试中,对总量 1 TB 的数据进行多并发导入压力测试,目标表共包含 28 个 partition,每个 partition 下有 256 个 tablet。在优化前,受限于单个集群节点的 CPU 和内存资源,导入始终无法在 4 小时的超时时间内完成,最终被系统自动取消,任务状态如图所示:
sql
*************************** 10. row ***************************
JobId: 11458
State: CANCELLED
Type: BROKER
Priority: NORMAL
ScanRows: 21905408
LoadStartTime: 2025-01-06 17:11:46
LoadFinishTime: 2025-01-06 21:11:44而在优化后:
sql
*************************** 20. row ***************************
JobId: 28336
State: FINISHED
Type: BROKER
Priority: NORMAL
ScanRows: 30000000
LoadStartTime: 2025-01-06 20:10:49
LoadFinishTime: 2025-01-06 20:27:59在相同场景下,10 个并发导入任务从 2025-01-06 20:10:49 开始,到 2025-01-06 20:36:10 全部完成,总耗时约 25 分钟。
这 10 个导入任务刚好触发了 Compact 阈值,但导入结束时系统的 compaction score 始终保持在较为理想的区间:
AvgCS: 10.00 P50CS: 10.00 MaxCS: 10.00另外,可以观察后端对象存储在优化前后的一些关键指标:
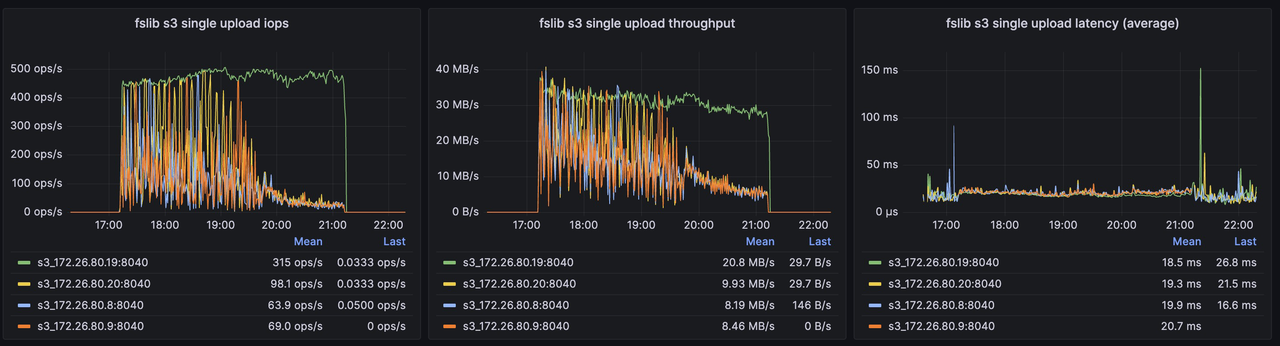
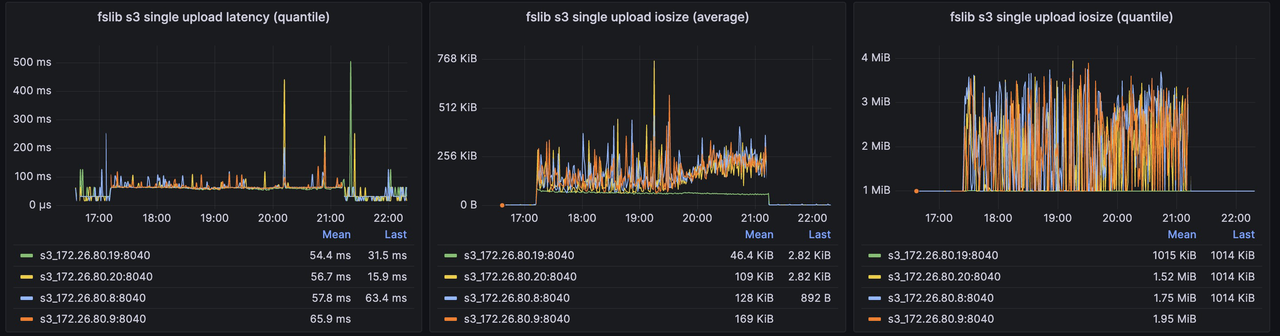
优化前 S3 关键指标
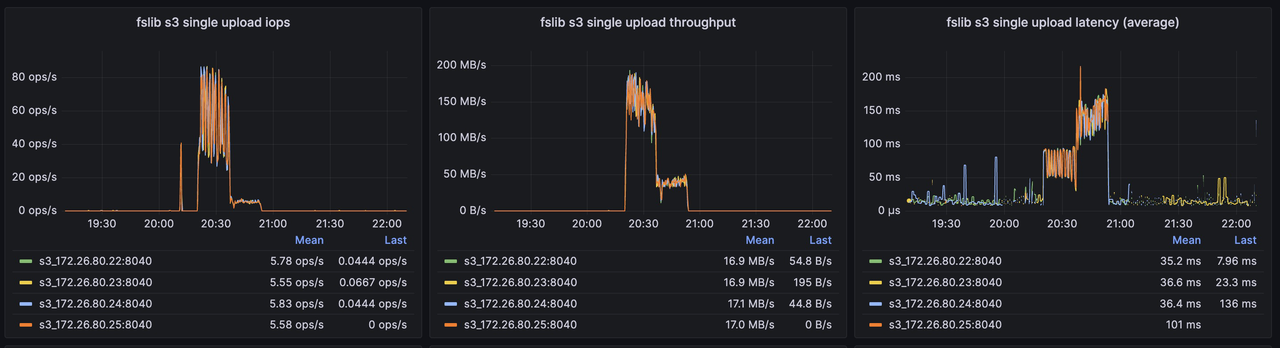
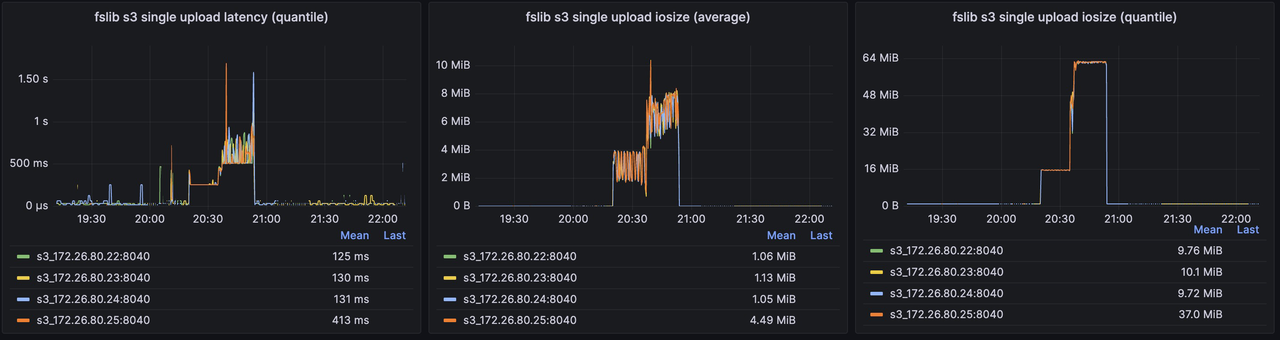
优化后 S3 关键指标
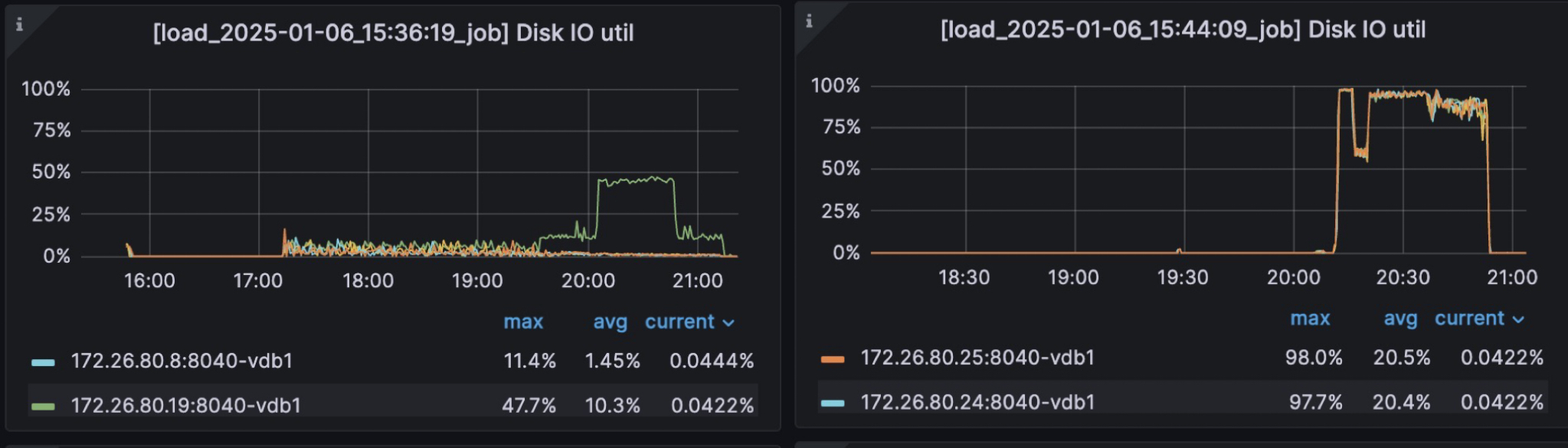
优化前后 Local Disk IO Util 对比
可以看到,在开启该优化后:
-
对 S3 的写入次数显著减少,写吞吐显著提高,单个对象的平均大小大幅提升,有利于降低存储成本并提升整体读写性能;
-
导入过程能够更加充分地利用本地磁盘的 I/O 能力,从而带来明显的导入性能提升。
总结
通过在内核层面优化批量数据导入能力,StarRocks 在历史数据回灌场景下有效避免了资源(尤其是内存)受限时产生的大量小文件问题,也让用户能够在存算分离架构下以更低的投入,获得更高效、更稳定的使用体验。