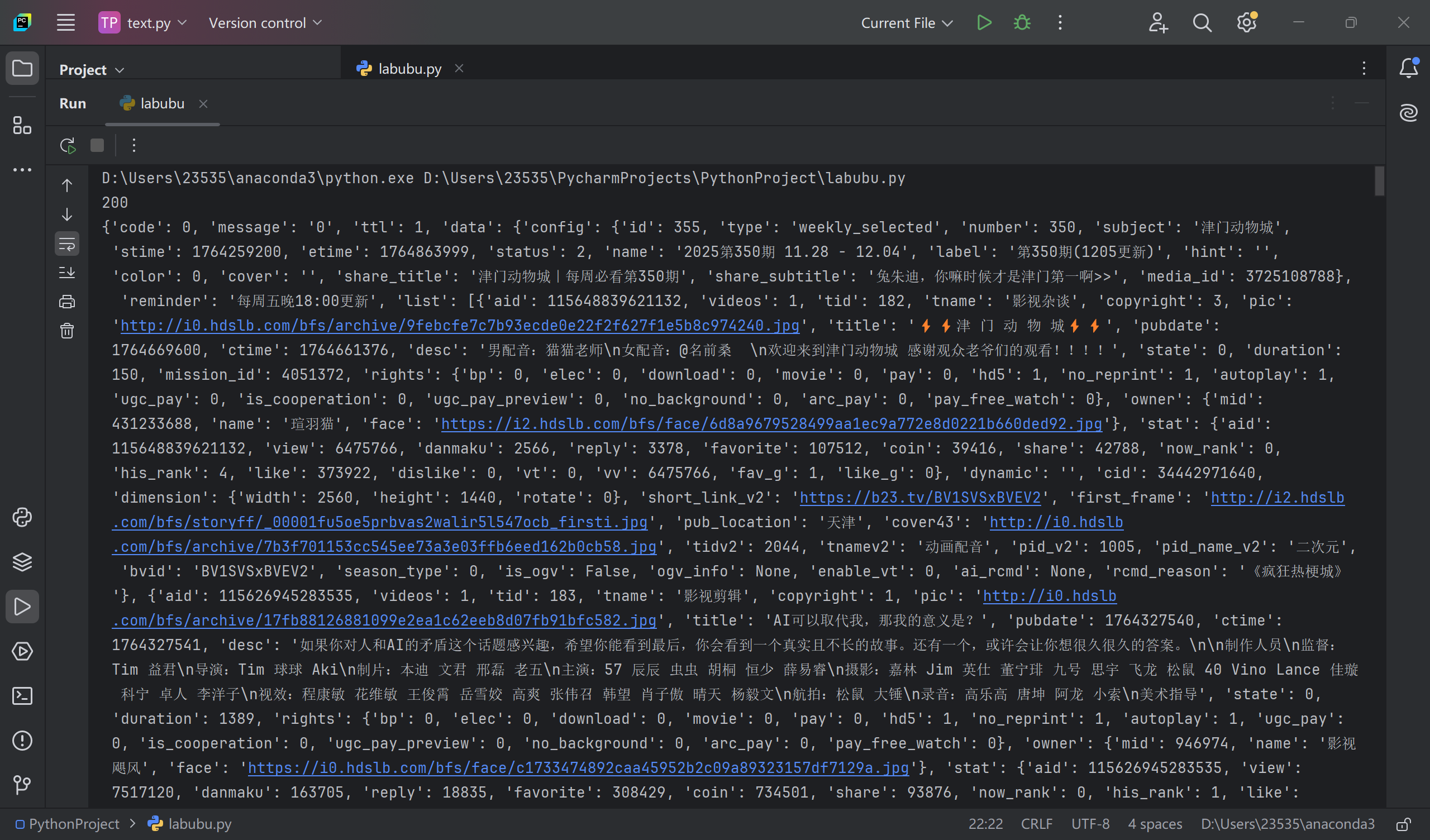
问题一:只能爬取到第一页的内容
对响应输出,不管怎么改url后面的内容的内容都是一样的
python
import requests
headersvalue={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/143.0.0.0 Safari/537.36 Edg/143.0.0.0'
}
url='https://search.bilibili.com/all?keyword=labubu&from_source=webtop_search&spm_id_from=333.1007&search_source=3&page=3&o=48'
r=requests.get(url,headers=headersvalue)
print(r.request.headers)
print(r.url)
print(r.status_code)
print(r.text)可能性分析:
1.核心数据是前端通过 Ajax 动态加载的,直接请求我写的 URL,返回的是 "空壳 HTML"(只包含页面框架,数据靠 JS 渲染)
尝试定位api接口的位置:
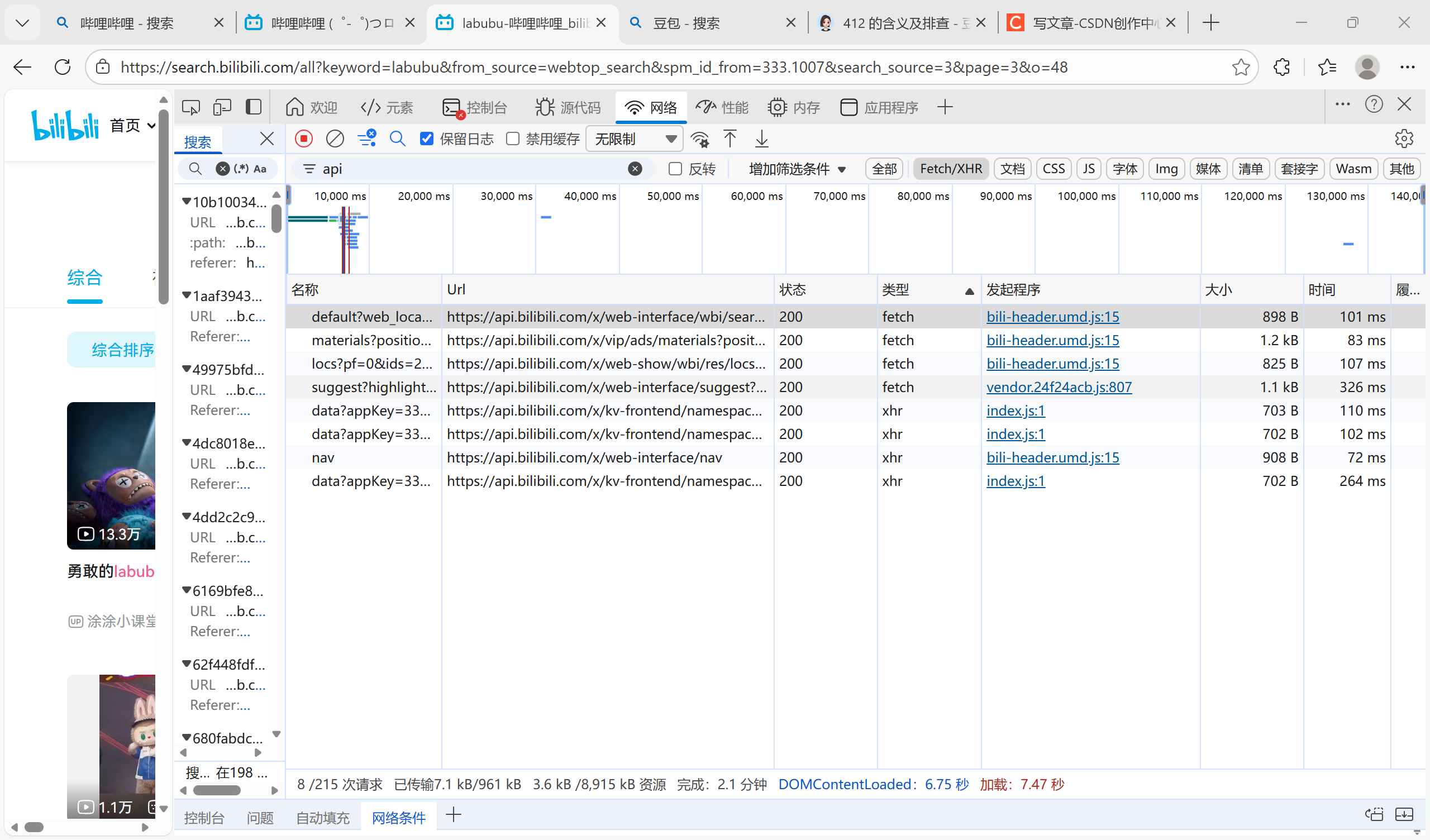
直接搜search更方便
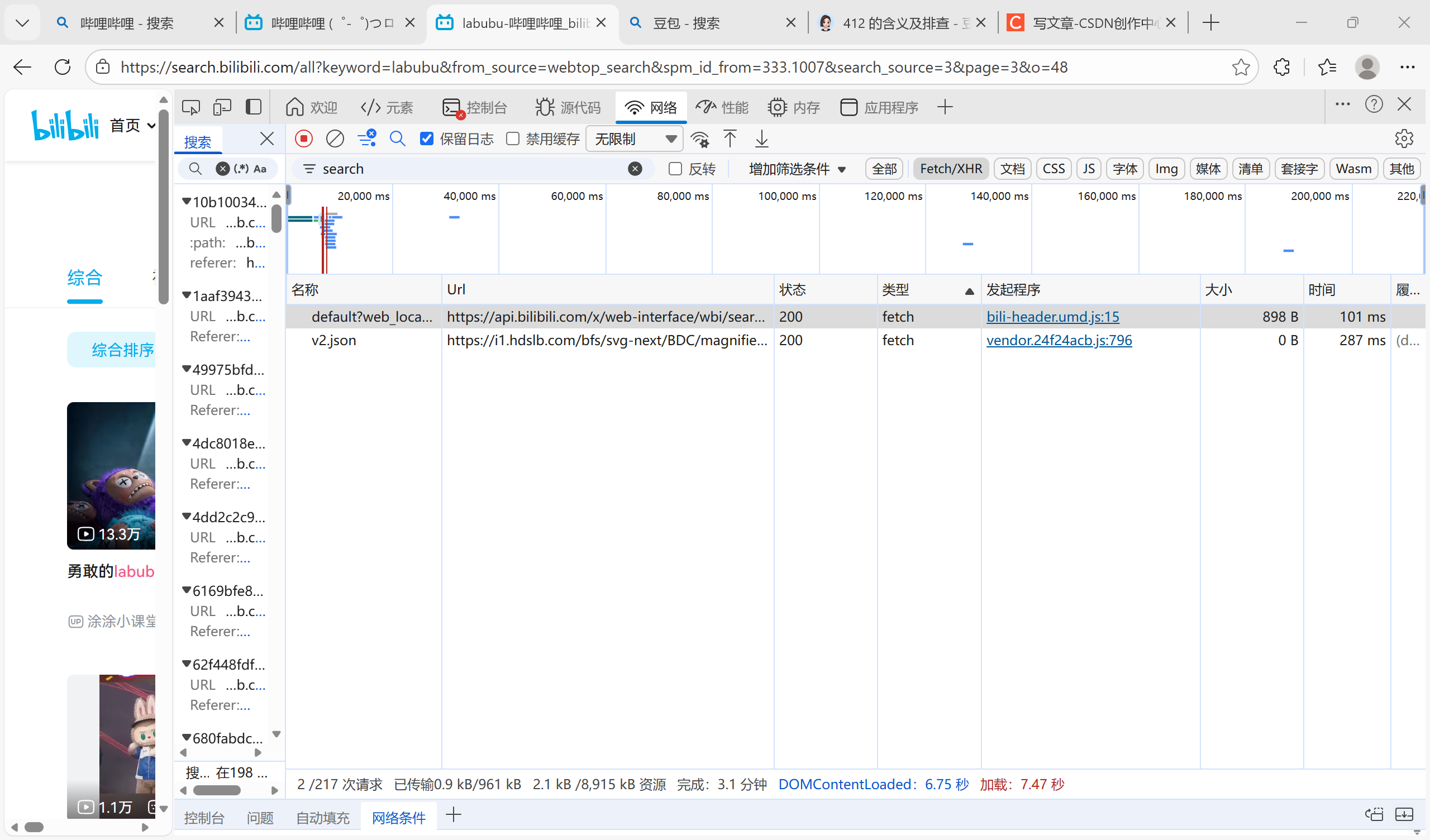
点进去看响应,没有发现我们想要的title什么的
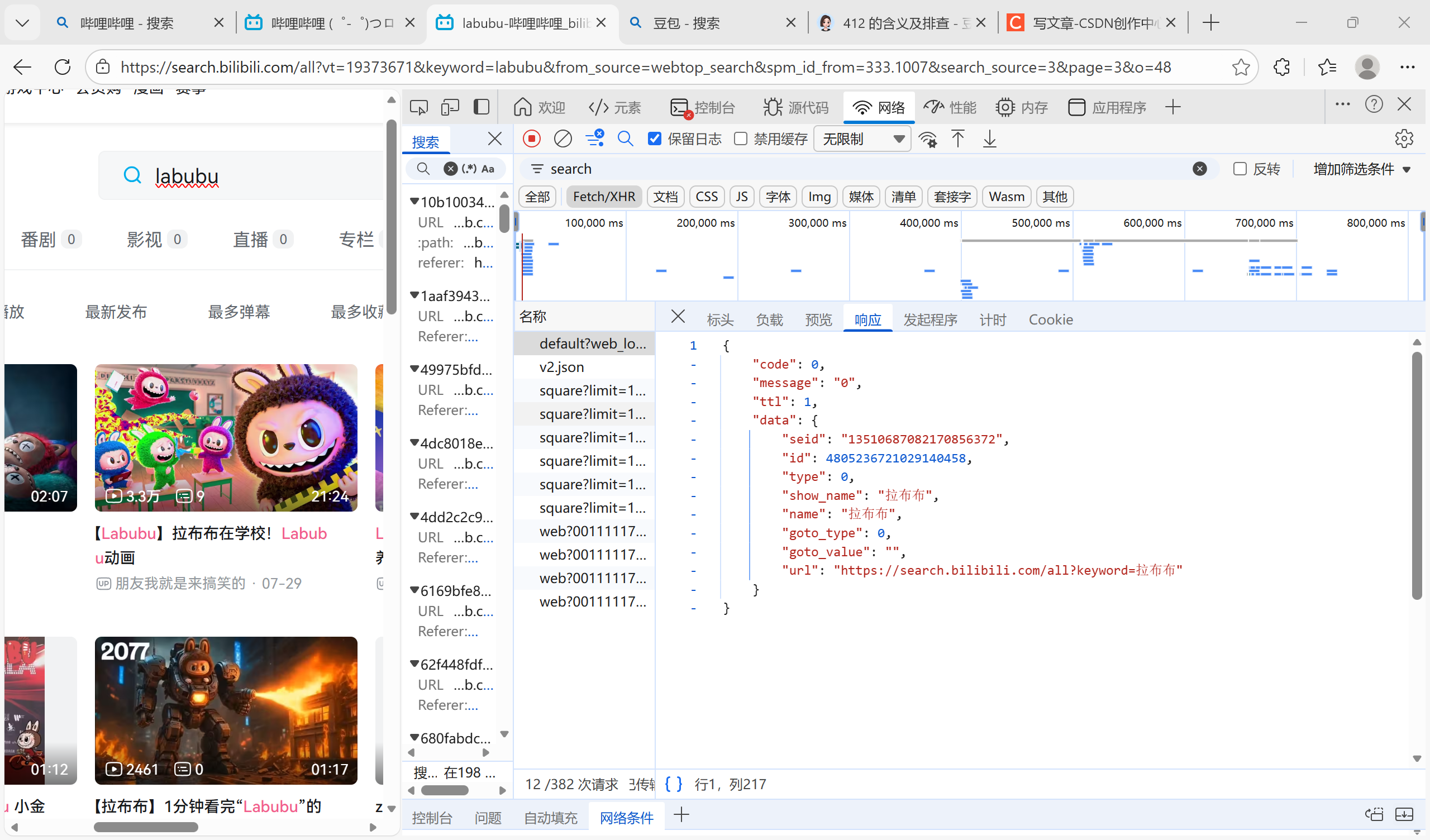
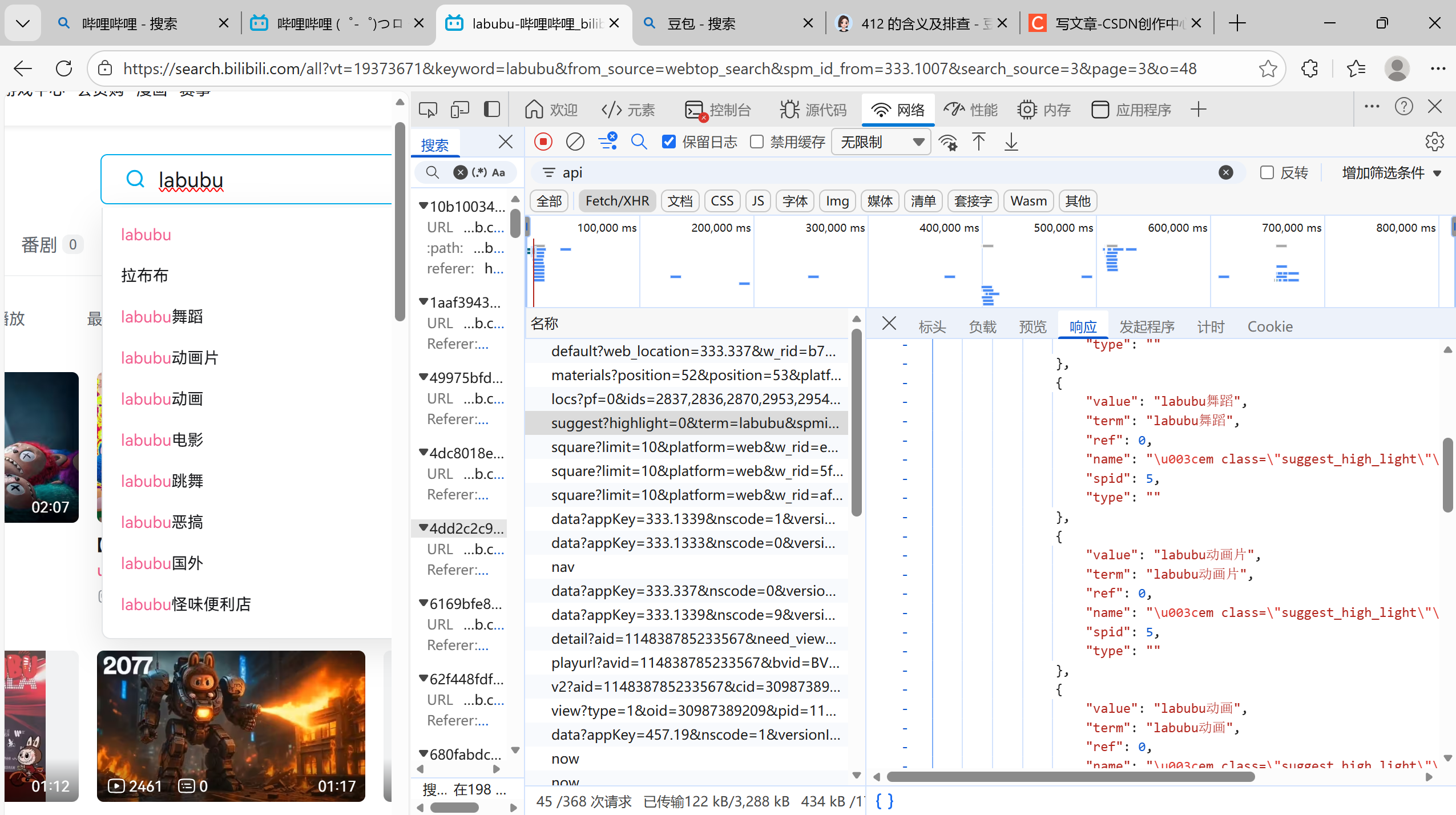
退回去一个一个api看,找到了两个有点像的
第一个就是suggest,根据翻译猜测是推荐框
第二个是detail,仔细翻阅有我想要的标题,up主等信息
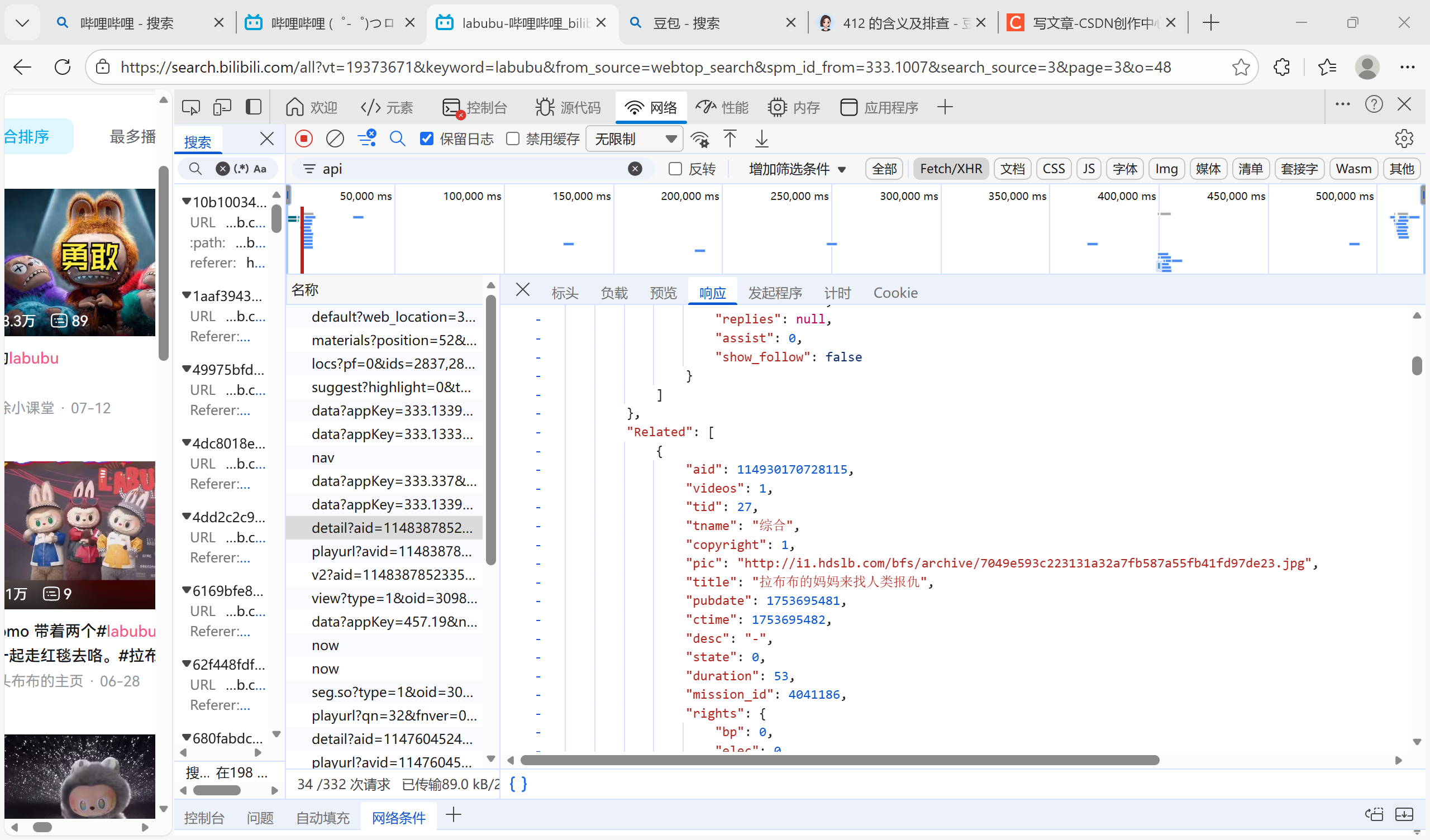
写到这里,我试了很久,决定暂时放弃,下面学到的内容很有用
问题二:爬取b站的入站必刷、综合热门的信息
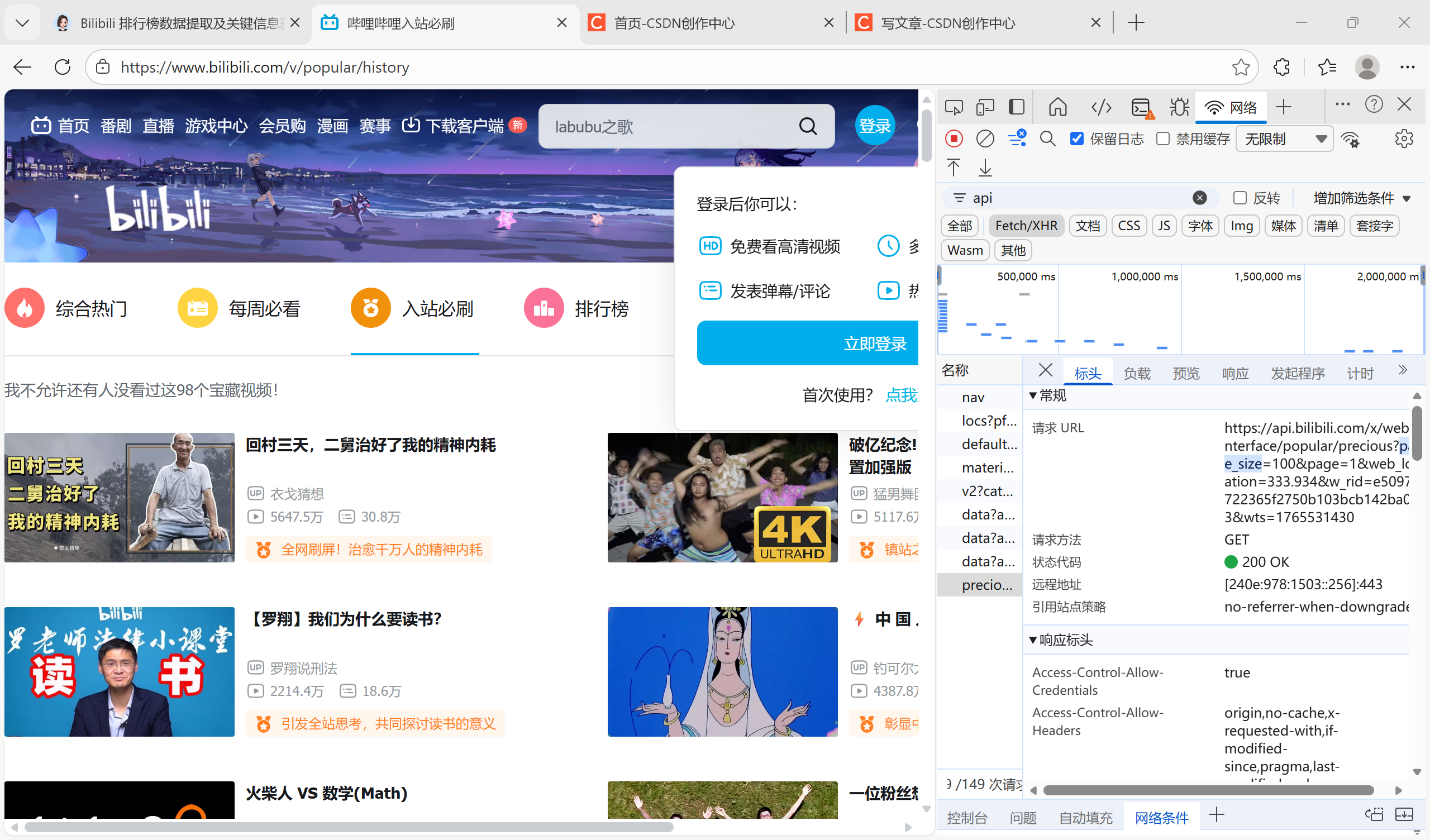
首先,有一点很重要的,我之前一直以为爬取的内容是响应的text文本里的内容,其实不是的,text里的内容是服务器返回的原始内容,是没有经过处理的,我们要对text进行json解析,解析成字典或者是列表
明确这点的话,那我们找到合适的响应内容,能够解析成json格式的链接
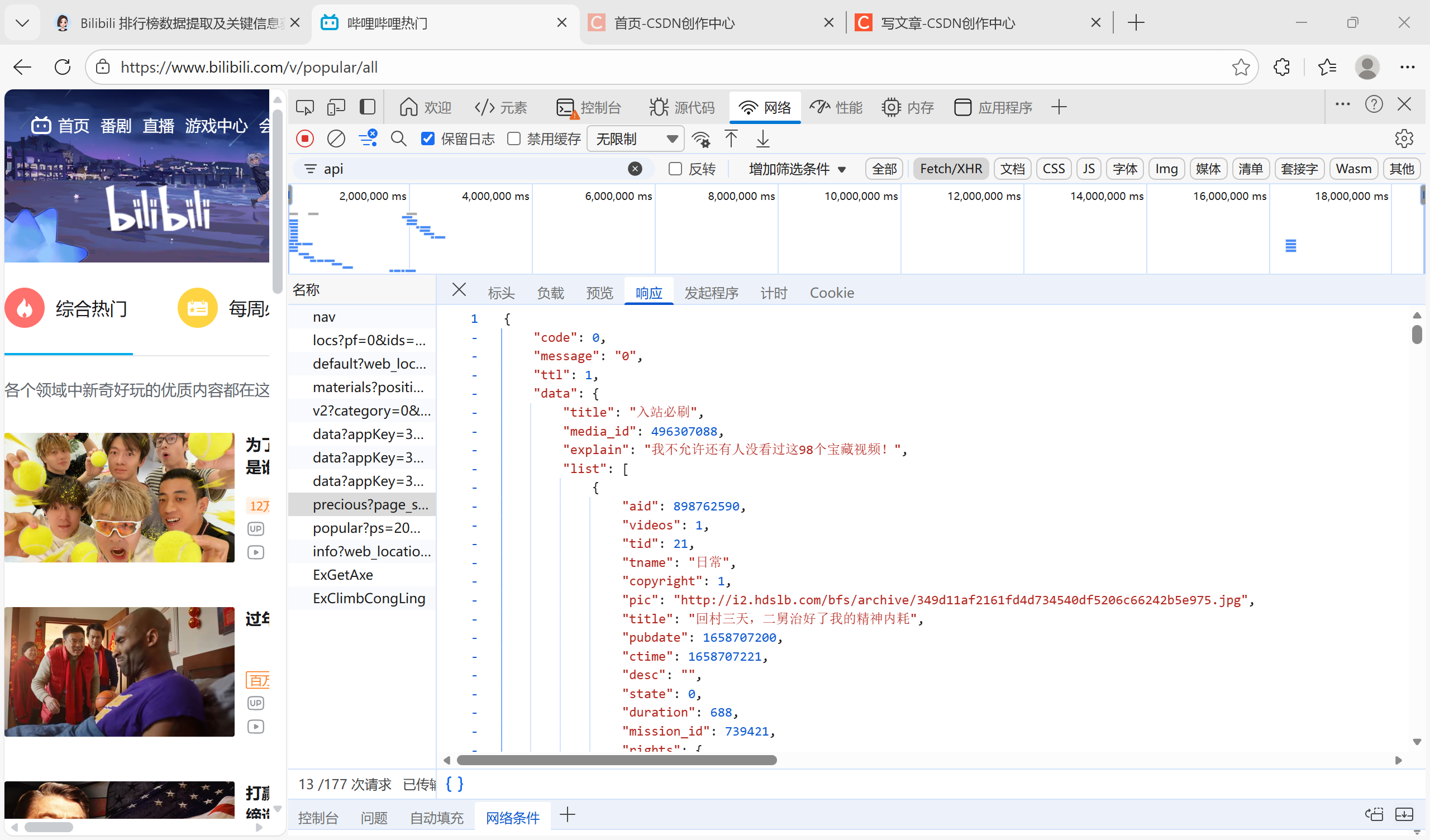
像上面那样的,是我们需要的,找到以后就可以拿到网址(在标头里的请求url)
python
import requests
headersvalue1= {
'User-Agent': '自己的',
'Referer': '自己的',
'Cookie':"自己的"
}
params1={'number':350}
url1='https://api.bilibili.com/x/web-interface/popular/series/one'
r1= requests.get(url1, headers=headersvalue1,params=params1)
print(r1.status_code)
print(r1.json() )
print("\n")
headersvalue2={
"user-agent":"自己的",
"Referer":"自己的",
"Cookie":"自己的"
}
params2={'page_size':100,'page':1}
url2='https://api.bilibili.com/x/web-interface/popular/precious'
r2= requests.get(url2, headers=headersvalue2,params=params2)
print(r2.status_code)
print(r2.json() )