让机器人像人一样推理,能更像人一样行动。
从走路、跳舞到后空翻,动作模仿教会了机器人「怎么动」,到端盘子、分拣水果、热食物等复杂操作时,机器人不能只模仿,更要深度决策------识别复杂环境,理解「为什么做」的任务意图,再转化为「动手这么做」的连贯操作。
从类人操作到类人智能,具身智能逐渐迈入「心手合一」的推理-行动时代。
星尘智能 Astribot Lumo-1 模型应运而生!
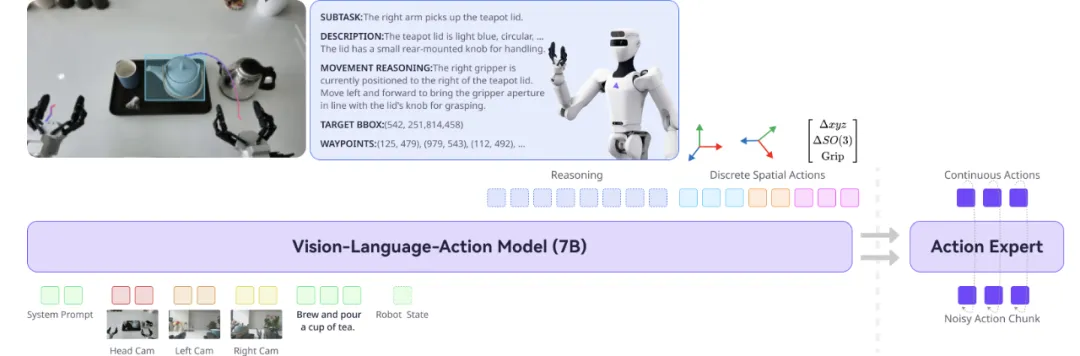
这是一个自研端到端视觉-语言-动作的全身VLA模型,借助具身化VLM、跨本体联合训练、推理-动作真机训练,以及强化学习校准对齐等方式,配合绳驱机器人S1的高质量真机训练,将大模型「深度心智」转化成全身丝滑操作。
Lumo 在拉丁语中意为光亮和启发,希望它能成为一束照进具身智能的光:让机器人能「懂你说什么」,还能「知道为什么」,然后「自己决定怎么做」。
项目主页:www.astribot.com/research/Lumo1
技术报告:https://arxiv.org/pdf/2512.08580
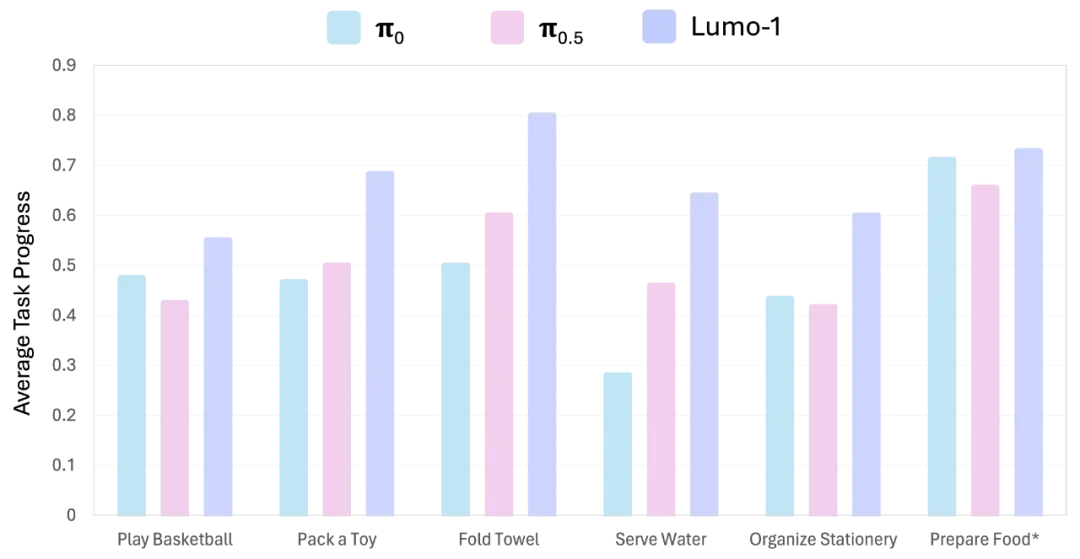
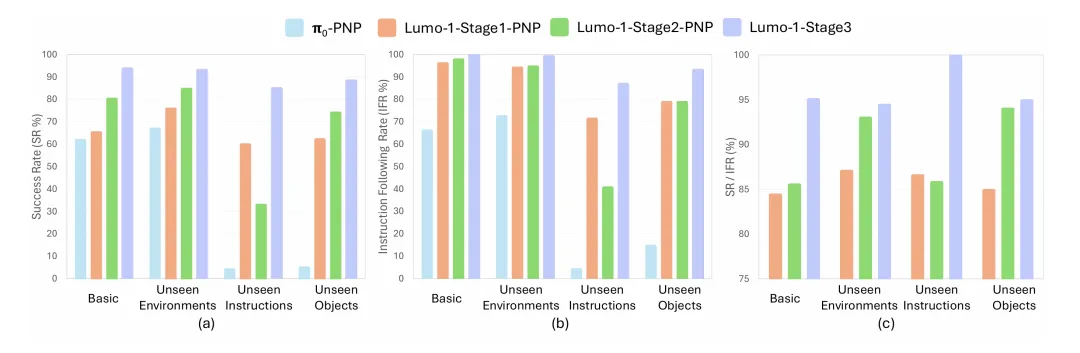
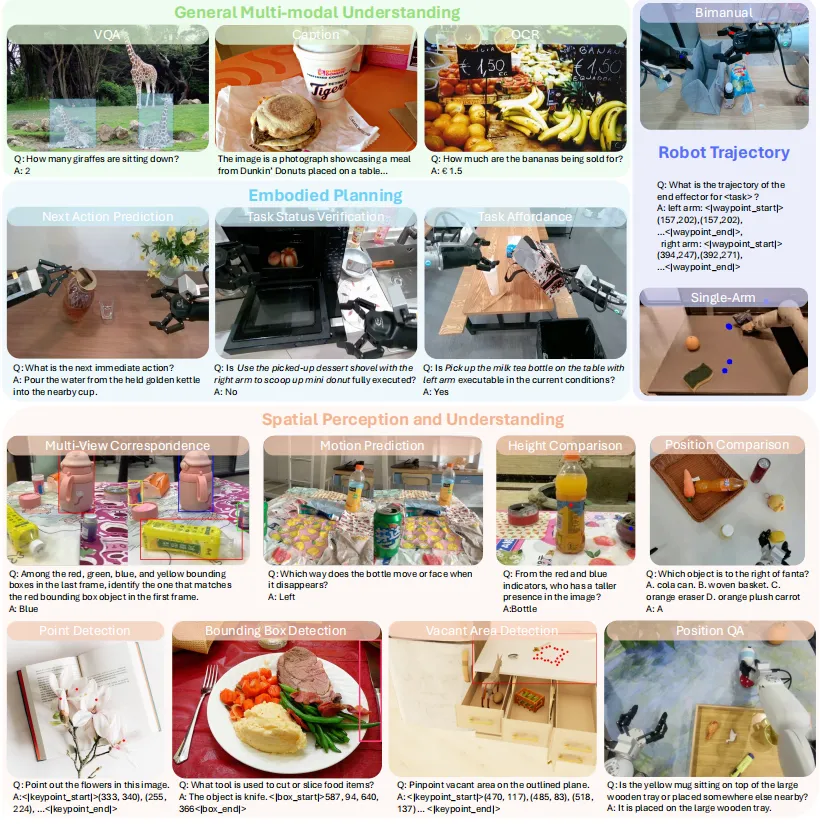
Lumo-1展现了强大的操作智能与泛化能力,在多步骤长时序、精细灵巧操作、可泛化抓放等三类核心任务中,全部超越π0、π0.5等先进模型,尤其在未见过的物体、场景和指令等分布外情况(Out of Distribution,简称OOD),以及抽象、模糊、需扩展推理的指令中,优势更为明显。
通用抓取放置任务效果远超π0
长时序、精细操作类核心任务效果超越 π0 和 π0.5
三大特点 推动「心手合一」
在 Lumo-1 里,通过1) 动作空间建模SAT(Spatial Action Tokenizer),机器人将动作轨迹转化为可复用、组合的「动作单词库」,能像写句子一样组合动作,或者复用、解释和预测动作。技术上,SAT将连续动作轨迹压缩成最短路径点,并把旋转/平移的增量动作聚类成紧凑token等,在保持动作空间意义时,减少数据收集引入的无关噪音,比FAST与分桶方法等更紧凑和稳定。
通过2) 结构化推理(Structured Reasoning),机器人大脑不再死记轨迹,而是形成解释动作的结构化推理链,从执行动作到「执行想法」。模型围绕目标进行抽象推理、子任务拆解、视觉要素识别与空间动作推断,使「为什么这样做」先于「怎么做」。最终,它把视觉理解映射为路径点预测,让 2D 预测自然落到 3D 控制上,实现更有目的性、情境化的动作生成。
把可以画海洋的物品放入绿盘子
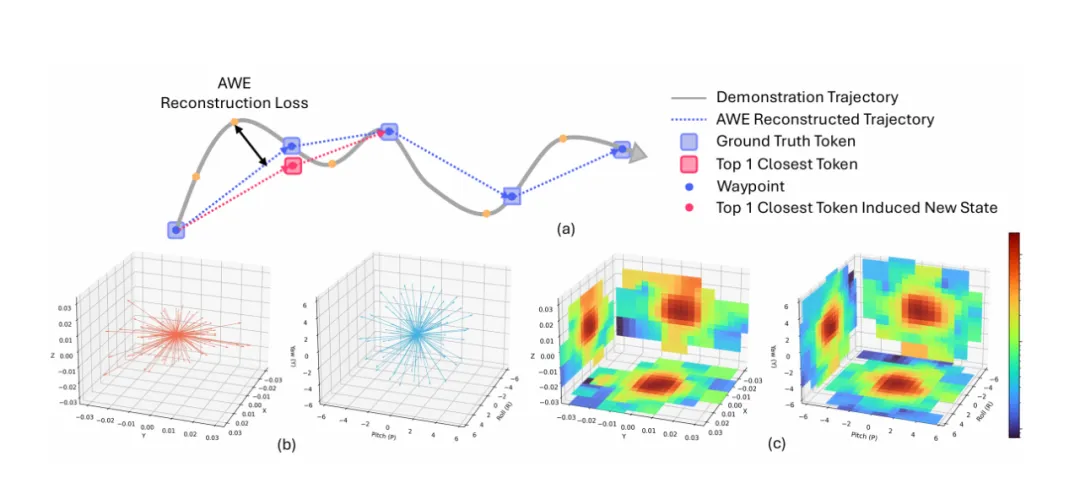
推理很强 ≠ 执行一定成功。Lumo-1 在最后加入3) 强化学习推理-行动对齐(RL Alignment),校准对齐高级推理与低级动作之间的误差,设计了视觉、动作与推理一致、动作执行、推理格式等多维度的奖励信号,通过基于GRPO的学习方案鼓励模型选择更准确、连贯、符合物理规则的动作。实验表明,该方案使模型在任务成功率、动作合理性与泛化能力上显著超越模仿专家示范的原始表现。
三阶训练 VLM认知转化为VLA智能
Lumo-1 的训练不是堆规模,而是精心设计的「智力迁移」过程。
阶段 1:具身化 VLM(Embodied VLM)。在精选的视觉-语言数据上持续预训练,让模型具备空间理解、规划、轨迹推断等「具身语义」。在 7 个经典具身推理基准中大部分超过 RoboBrain-7B、Robix-7B 等专用模型。
精选数据集旨在不损伤预训练VLM的通用多模态理解与推理能力前提下,强化核心具身推理能力。

阶段 2:跨本体联合训练。融合跨机器人、多视角轨迹、VLM数据上联合训练,强化了指令跟随、物体定位与空间推理能力,使模型开始理解「动作是什么,与指令和观测是什么关系」。
阶段 3:真机推理-动作训练(S1轨迹)。利用绳驱机器人 Astribot S1 高度仿人的示教轨迹,进行带推理过程的动作训练,让模型习得真实世界可执行的动作模式,比如:怎么用双手协同处理物体、如何执行长序列操作、如何将推理一步步落实为轨迹等。
Astribot S1机器人上收集的样本任务。这些任务涵盖了广泛的日常活动,采集自不同的物体、光照条件及环境场景。每项任务均涉及复杂、长时序行为,可自然分解为多个子任务,包含多样化的基础动作单元,例如清扫、削皮、倾倒、刷洗、折叠、按压和旋转等
最后加入 RL 校准对齐,闭合整个推理-行动链路,让平均奖励上升,错误率降低,在真实环境中泛化能力更强。
Lumo-1 训练结果验证 Scaling Law
多样化数据是关键变量,缺乏增强的数据会导致执行在现实中迅速失效;多样提示、图像增强、跨场景训练大幅提升鲁棒性。具身智能除了数据堆叠,也对数据「更像世界」提出了更高要求。
Lumo-1 的训练结果验证了 Scaling Law ,在数据受限下,模型 loss 走势与扩展定律高度一致,Lumo-1 是「可继续放大」的。
我们将推动这束「微光」,向可大规模部署的通用具身智能迈进。