向量内存(VMEM)指令将每个工作项的数据分别读取或写入VGPR中。这与标量内存指令形成对比,标量内存指令移动的是波前中所有线程共享的单个数据块。所有向量内存(VM)操作都由纹理缓存系统(一级和二级缓存)处理。
软件通过以下三种类型的VMEM指令之一,通过纹理缓存启动加载、存储或原子操作:
-
MTBUF:内存类型化缓冲区操作
-
MUBUF:内存非类型化缓冲区操作
-
MIMG:内存图像操作
指令定义了哪些VGPR为操作提供地址,哪些VGPR从操作接收或提供数据,以及一系列包含内存缓冲区描述符(V#或T#)的SGPR。此外,MIMG操作从四个SGPR系列提供纹理采样器;该采样器定义了对从图像读取的数据执行的纹素过滤操作。
8.1 向量内存缓冲区指令
向量内存(VM)操作通过纹理缓存(TC)在VGPR和内存中的缓冲区对象之间传输数据。"向量"意味着为波前中的每个线程唯一传输一个或多个数据块,这与标量内存读取形成对比,标量内存读取仅传输波前中所有线程共享的一个值。
缓冲区读取可以选择将数据返回到VGPR或直接返回到LDS。
缓冲区对象的示例包括顶点缓冲区、原始缓冲区、流输出缓冲区和结构化缓冲区。
缓冲区对象支持同质和异质数据,但不支持读取数据的过滤(无采样器)。缓冲区指令分为两组:
-
MUBUF:非类型化缓冲区对象
-
数据格式在资源常量中指定
-
加载、存储、原子操作,带或不带数据格式转换
-
-
MTBUF:类型化缓冲区对象
-
数据格式在指令中指定
-
唯一操作是加载和存储,两者都带数据格式转换
-
原子操作从VGPR获取数据,并与内存中已有的数据进行算术组合。可选地,操作发生前内存中的值可以返回到着色器。
所有VM操作都使用缓冲区资源常量(V#),它是SGPR中的128位值。执行指令时,此常量被发送到纹理缓存。此常量定义了内存中缓冲区的地址和特性。通常,这些常量在执行VM指令之前使用标量内存读取从内存获取,但这些常量也可以在着色器内生成。
8.1.1 简化缓冲区寻址
下面的方程显示了硬件如何计算缓冲区访问的内存地址。
8.1.2 缓冲区指令
缓冲区指令(MTBUF和MUBUF)允许着色器程序读取和写入内存中的线性缓冲区。这些操作可以对小至一个字节,大到每个工作项四个双字的数据进行操作。提供了原子算术操作,可以对内存中的数据值进行操作,并可选择返回执行算术操作前内存中的值。
D16指令变体将结果转换为打包的16位值。例如,BUFFER_LOAD_FORMAT_D16_XYZW 将写入两个VGPR。
表25. 缓冲区指令
| 指令 | 描述 |
|---|---|
| MTBUF指令 | |
TBUFFER_LOAD_FORMAT_{x,xy,xyz,xyzw} TBUFFER_STORE_FORMAT_{x,xy,xyz,xyzw} |
从类型化缓冲区对象读取或写入。也用于顶点获取。 |
| MUBUF指令 | |
BUFFER_LOAD_FORMAT_{x,xy,xyz,xyzw} BUFFER_STORE_FORMAT_{x,xy,xyz,xyzw} BUFFER_LOAD_<size> BUFFER_STORE_<size> <size> = byte, ubyte, short, ushort, Dword, Dwordx2, Dwordx3, Dwordx4 BUFFER_ATOMIC_<op> BUFFER_ATOMIC_<op>_x2 |
从非类型化缓冲区对象读取或写入。 |
表26. 微码格式
| 字段 | 位大小 | 描述 |
|---|---|---|
| OP | 4/7 | MTBUF:类型化缓冲区指令的操作码。 MUBUF:非类型化缓冲区指令的操作码。 |
| VADDR | 8 | 提供地址第一个组件的VGPR地址(偏移量或索引)。当同时使用索引和偏移量时,索引在第一个VGPR中,偏移量在第二个VGPR中。 |
| VDATA | 8 | 提供写入数据第一个组件或接收读取数据第一个组件的VGPR地址。 |
| SOFFSET | 8 | 提供无符号字节偏移量的SGPR。必须是SGPR、M0或内联常量。 |
| SRSRC | 5 | 指定哪个SGPR在四个或八个连续SGPR中提供T#(资源常量)。此字段缺少SGPR地址的最低两位,因为该地址必须对齐到四个SGPR的倍数。 |
| DFMT | 4 | 内存缓冲区中数据的格式:0无效,1 8,2 16,3 8_8,4 32,5 16_16,6 10_11_11,7 11_11_10,8 10_10_10_2,9 2_10_10_10,10 8_8_8_8,11 32_32,12 16_16_16_16,13 32_32_32,14 32_32_32_32,15保留 |
| NFMT | 3 | 内存中数据的数值格式:0 unorm,1 snorm,2 uscaled,3 sscaled,4 uint,5 sint,6保留,7 float |
| OFFSET | 12 | 无符号字节偏移量。 |
| OFFEN | 1 | 1 = 从VGPR(VADDR)提供偏移量。0 = 不提供(偏移量=0)。 |
| IDXEN | 1 | 1 = 从VGPR(VADDR)提供索引。0 = 不提供(索引=0)。 |
| GLC | 1 | 全局一致性。控制L1纹理缓存如何处理读取和写入。 读取 :GLC=0:读取可以命中L1并在波前之间保持。 GLC=1:读取错过L1并强制获取到L2。波之间没有L1持久性。 写入 :GLC=0:写入错过L1,写入到L2,并在波前之间在L1中保持。 GLC=1:写入错过L1,写入到L2。波前之间没有持久性。 原子操作 :GLC=0:不返回先前数据值。波前之间没有L1持久性。 GLC=1:返回先前数据值。波前之间没有L1持久性。 注意:对于原子操作,GLC表示"返回操作前值"。 |
| SLC | 1 | 系统级一致性。设置时,访问强制在二级纹理缓存中错过,并与系统内存一致。 |
| TFE | 1 | PRT(部分驻留纹理)的纹素失败启用。设置为1时,获取可以返回NACK,导致VGPR写入到DST+1(所有获取目标GPR之后的第一个GPR)。 |
| LDS | 1 | 仅限MUBUF:0 = 将读取数据返回到VGPR。1 = 将读取数据返回到LDS而不是VGPR。 |
8.1.3 VGPR使用
VGPR提供地址和写入数据;此外,它们可以是返回数据的目标(另一个选项是LDS)。
地址
根据指令字中的偏移启用(OFFEN)和索引启用(IDXEN),使用零个、一个或两个VGPR,如下表所示:
表27. 地址VGPR
| IDXEN | OFFEN | VGPRn | VGPRn+1 |
|---|---|---|---|
| 0 | 0 | 无 | |
| 0 | 1 | uint偏移量 | |
| 1 | 0 | uint索引 | |
| 1 | 1 | uint索引 | uint偏移量 |
写入数据:从VDATA开始的N个连续VGPR。指令字中指定的数据格式(MTBUF的NFMT、DFMT,或MUBUF操作码字段中编码的)决定了要写入多少双字。
读取数据:与写入相同。数据返回到连续的GPR。
读取数据格式:读取数据为32位,基于指令或资源中的数据格式。浮点或规范化数据作为浮点数返回;整数格式作为整数返回(有符号或无符号,与内存存储格式类型相同)。内存中32或64位数据的读取不进行任何格式转换。
带返回的原子操作:数据从VDATA开始的VGPR中读取,提供给原子操作。如果原子操作返回值到VGPR,则该数据返回到从VDATA开始的相同VGPR。
8.1.4 缓冲区数据
读取或写入的数据量和类型由以下控制:数据格式(dfmt)、数值格式(nfmt)、目标组件选择(dst_sel)和操作码。Dfmt和nfmt可以来自资源、指令字段或操作码本身。Dst_sel来自资源,但对于许多操作被忽略。
表28. 缓冲区指令
| 指令 | 数据格式 | 数值格式 | DST_SEL |
|---|---|---|---|
TBUFFER_LOAD_FORMAT_* |
指令 | 指令 | identity |
TBUFFER_STORE_FORMAT_* |
指令 | 指令 | identity |
BUFFER_LOAD_<type> |
派生 | 派生 | identity |
BUFFER_STORE_<type> |
派生 | 派生 | identity |
BUFFER_LOAD_FORMAT_* |
资源 | 资源 | 资源 |
BUFFER_STORE_FORMAT_* |
资源 | 资源 | 资源 |
BUFFER_ATOMIC_* |
派生 | 派生 | identity |
指令 :使用指令的dfmt和nfmt字段而不是资源的字段。
数据格式派生 :数据格式从操作码派生,忽略资源定义。例如,buffer_load_ubyte 将数据格式设置为8,数值格式设置为uint。
资源的数据格式不能为INVALID ;该格式具有特定含义(未绑定资源),对于这种情况,数据格式不会被指令的隐含数据格式替换。
DST_SEL identity:根据数据格式中的组件数量,这是:X000、XY00、XYZ0或XYZW。
MTBUF从指令派生数据格式。MUBUF BUFFER_LOAD_FORMAT 和 BUFFER_STORE_FORMAT 指令使用资源中的dst_sel;其他MUBUF指令从指令本身派生数据格式。
D16指令:加载格式和存储格式指令也有"d16"变体。对于存储,每个32位VGPR保存两个16位数据元素,传递给纹理单元。纹理单元在写入内存之前将它们转换为纹理格式。对于加载,从纹理单元返回的数据转换为16位,一对数据存储在每个32位VGPR中(先LSB,然后MSB)。int与float的控制由NFMT控制。
8.1.5 缓冲区寻址
缓冲区是内存中的数据结构,使用索引和偏移量进行寻址。索引指向大小为stride字节的特定记录,偏移量是记录内的字节偏移量。stride来自资源,索引来自VGPR(或零),偏移量来自SGPR或VGPR以及指令本身。
表29. 用于寻址的BUFFER指令字段
| 字段 | 大小 | 描述 |
|---|---|---|
| inst_offset | 12 | 指令的字面字节偏移量。 |
| inst_idxen | 1 | 布尔值:为true时从VGPR获取索引,为false时无索引。 |
| inst_offen | 1 | 布尔值:为true时从VGPR获取偏移量,为false时无偏移量。注意,无论此位如何,inst_offset都存在。 |
缓冲区指令的"元素大小"是指令传输的数据量。对于MTBUF指令,由DFMT字段确定;对于MUBUF指令,从操作码确定。可以是1、2、4、8或16字节。
表30. 用于寻址的V#缓冲区资源常量字段
| 字段 | 大小 | 描述 |
|---|---|---|
| const_base | 48 | 缓冲区资源的基地址(字节)。 |
| const_stride | 14或18 | 记录的跨度(字节)(0到16,383字节,或0到262,143字节)。通常为14位,但当以下情况时扩展到18位:const_add_tid_enable = true与非格式类型(或缓存无效/WB)的MUBUF指令一起使用。此扩展旨在用于暂存(私有)缓冲区。 如果(const_add_tid_enable && MUBUF-non-format instr.),则 const_stride17:0 = { V#.DFMT3:0, V#.const_stride13:0 } const_stride为14位:{4'b0, V#.const_stride13:0} |
| const_num_records | 32 | 缓冲区中的记录数。 对于原始缓冲区,单位为字节;对于结构化缓冲区,单位为跨度;对于私有(暂存)缓冲区,忽略。 单位为:(inst_idxen == 1) ? 字节 : 跨度 |
| const_add_tid_enable | 1 | 布尔值。为true时,将波前内的thread_ID添加到索引中。 |
| const_swizzle_enable | 1 | 布尔值。为true时,表示表面被重排。 |
| const_element_size | 2 | 仅当const_swizzle_en = true时使用。给定索引的记录的连续字节数(2、4、8或16字节)。必须>=结构中的最大元素大小。const_stride必须是const_element_size的整数倍。 |
| const_index_stride | 2 | 仅当const_swizzle_en = true时使用。在切换到下一个元素之前,单个元素(大小为const_element_size)的连续索引数。有8、16、32或64个索引。 |
表31. 来自GPR的地址组件
| 字段 | 大小 | 描述 |
|---|---|---|
| SGPR_offset | 32 | 地址的无符号字节偏移量。来自SGPR或M0。 |
| VGPR_offset | 32 | 可选的每线程无符号字节偏移量。来自VGPR。 |
| VGPR_index | 32 | 可选的每线程索引值。来自VGPR。 |
最终的缓冲区内存地址由三部分组成:
-
来自缓冲区资源(V#)的基地址
-
来自SGPR的偏移量
-
根据缓冲区是线性寻址(简单的结构数组计算)还是重排,以不同方式计算的缓冲区偏移量
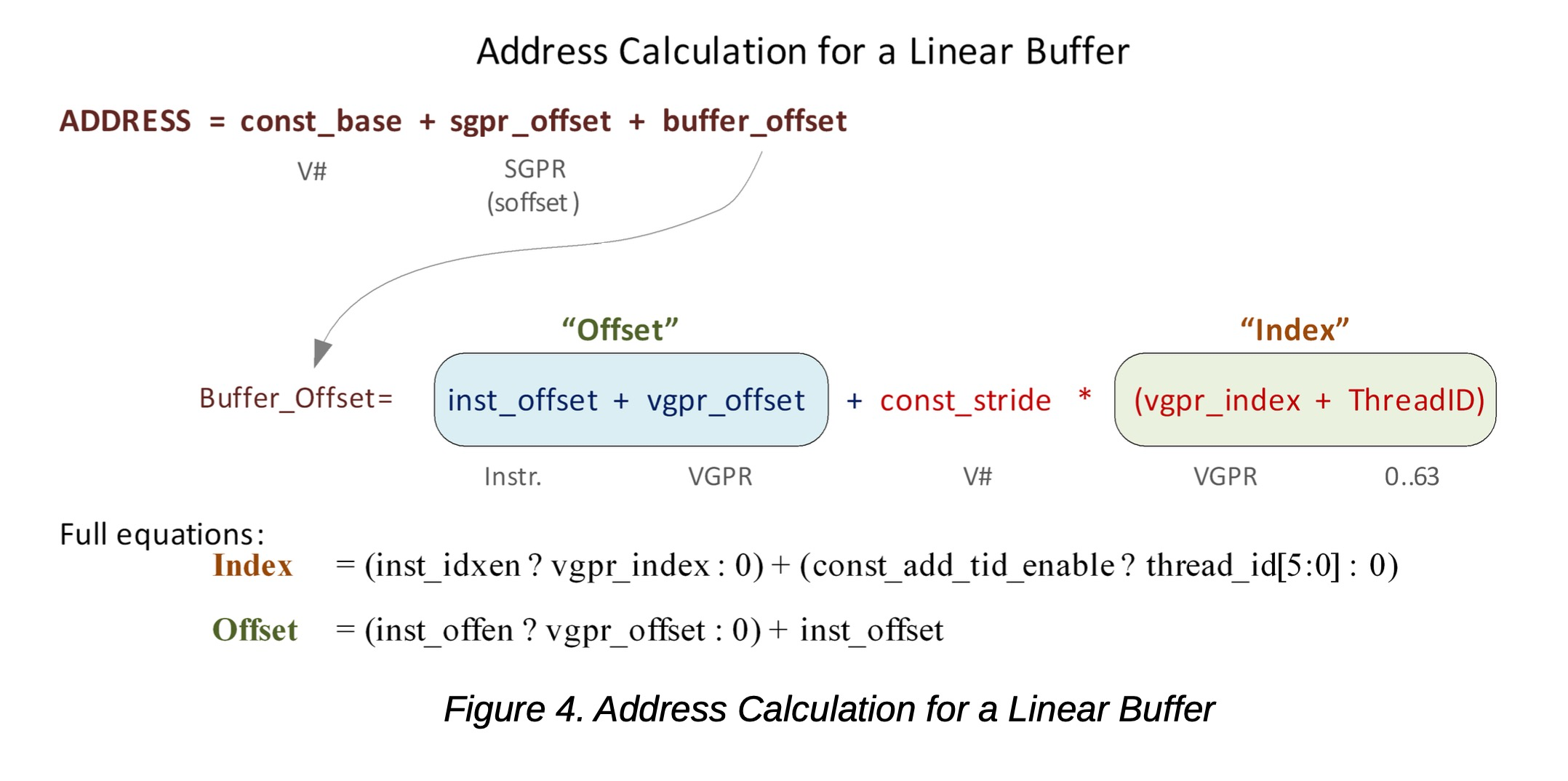
图4. 线性缓冲区的地址计算
范围检查
可以检查地址是否在范围内。当地址超出范围时,读取将返回零,写入和原子操作将被丢弃。地址范围检查算法取决于缓冲区类型。
私有(暂存)缓冲区
使用条件:AddTID==1 && IdxEn==0
对于此缓冲区,没有范围检查。
原始缓冲区
使用条件:AddTID==0 && SWizzleEn==0 && IdxEn==0
超出范围条件:(InstOffset + (OffEN ? vgpr_offset : 0)) >= NumRecords
结构化缓冲区
使用条件:AddTID==0 && Stride!=0 && IdxEn==1
超出范围条件:Index(vgpr) >= NumRecords
注意:
-
超出范围的读取返回零(V#.dst_sel = SEL_1的组件返回1除外)
-
超出范围的写入不写入任何内容
-
加载/存储格式*指令和原子操作进行"全有或全无"范围检查-要么完全在范围内,要么完全在范围外
-
加载/存储双字-x{2,3,4}按组件进行范围检查
重排缓冲区寻址
重排寻址重新排列缓冲区中的数据,可以帮助提高结构数组的缓存局部性。重排寻址还需要双字对齐的访问。单个获取指令不能尝试获取大于const-element-size的单位。缓冲区的STRIDE必须是element_size的倍数。
重排缓冲区地址计算:
cpp
Index = (inst_idxen ? vgpr_index : 0) +
(const_add_tid_enable ? thread_id[5:0] : 0)
Offset = (inst_offen ? vgpr_offset : 0) + inst_offset
index_msb = index / const_index_stride
index_lsb = index % const_index_stride
offset_msb = offset / const_element_size
offset_lsb = offset % const_element_size
buffer_offset = (index_msb * const_stride + offset_msb *
const_element_size) * const_index_stride + index_lsb *
const_element_size + offset_lsb
Final Address = const_base + sgpr_offset + buffer_offset请记住,"sgpr_offset"不是上述方程中"offset"项的一部分。

图5. 缓冲区重排示例
重排寻址的拟议用例
以下是重排寻址在常见图形缓冲区中的一些拟议用途。
表32. 重排缓冲区用例
| DX11原始UAV | OpenCL缓冲区对象 | Dx11结构化(字面偏移) | Dx11结构化(GPR偏移) | 暂存 | 环/流输出 | 常量缓冲区 | |
|---|---|---|---|---|---|---|---|
| inst_vgpr_offset_en | T | F | T | T | T | T | |
| inst_vgpr_index_en | F | T | T | F | F | F | |
| const_stride | na | <api> | <api> | scratchSize | na | na | |
| const_add_tid_enable | F | F | F | T | T | F | |
| const_buffer_swizzle | F | T | T | T | F | F | |
| const_elem_size | na | 4 | 4 | 4或16 | na | 4 | |
| const_index_stride | na | 16 | 16 | 64 |
8.1.6 16位内存操作
D16缓冲区指令允许内核在每个工作项的VGPR和内存之间仅加载或存储16位数据。这些指令有两个变体:
-
D16:将数据加载到VGPR的低16位或从VGPR的低16位存储数据
-
D16_HI:将数据加载到VGPR的高16位或从VGPR的高16位存储数据
例如,BUFFER_LOAD_UBYTE_D16 从内存为每个工作项读取一个字节,将其转换为16位整数,然后将其加载到数据VGPR的低16位中。
8.1.7 对齐
对于双字或更大尺寸的读写操作,字节地址的最低两位(LSB)被忽略,从而强制进行双字对齐。
8.1.8 缓冲区资源
缓冲区资源描述了缓冲区在内存中的位置以及缓冲区中数据的格式。它在四个连续的SGPR(四个对齐的SGPR)中指定,并在每个缓冲区指令执行时发送到纹理缓存。
下表详细说明了构成缓冲区资源描述符的字段:
表33. 缓冲区资源描述符
| 位范围 | 大小 | 名称 | 描述 |
|---|---|---|---|
| 47:0 | 48 | 基地址 | 字节地址 |
| 61:48 | 14 | 跨度 | 字节0到16383 |
| 62 | 1 | 缓存重排 | 缓冲区访问。可选地,重排纹理缓存TC L1缓存bank |
| 63 | 1 | 重排启用 | 根据跨度、索引跨度和元素大小重排AOS,否则为线性(跨度 × 索引 + 偏移量) |
| 95:64 | 32 | 记录数 | 以跨度或字节为单位 |
| 98:96 | 3 | 目标选择_x | 目标通道选择:0=0, 1=1, 4=R, 5=G, 6=B, 7=A |
| 101:99 | 3 | 目标选择_y | |
| 104:102 | 3 | 目标选择_z | |
| 107:105 | 3 | 目标选择_w | |
| 110:108 | 3 | 数值格式 | 数值数据类型(浮点、整型等)。参见指令编码的值 |
| 114:111 | 4 | 数据格式 | 字段数和每个字段的大小。参见指令编码的值。对于ADD_TID_EN=1的MUBUF指令,此字段保存跨度17:14 |
| 115 | 1 | 用户VM启用 | 资源通过平铺池/堆映射 |
| 116 | 1 | 用户VM模式 | 未映射行为:0:空(返回0/丢弃写入);1:无效(导致错误) |
| 118:117 | 2 | 索引跨度 | 8、16、32或64。用于重排缓冲区寻址 |
| 119 | 1 | 添加线程ID启用 | 将线程ID添加到索引中以计算地址 |
| 122:120 | 3 | RSVD | 保留。必须设置为零 |
| 123 | 1 | NV | 非易失性(0=易失性) |
| 125:124 | 2 | RSVD | 保留。必须设置为零 |
| 127:126 | 2 | 类型 | 值==0表示缓冲区。与128位T#资源中的四位类型字段的高两位重叠 |
全部设置为零的资源充当未绑定的纹理或缓冲区(返回0,0,0,0)。
8.1.9 内存缓冲区加载到LDS
MUBUF指令格式允许从内存缓冲区直接读取数据到LDS,而不经过VGPR。这支持以下MUBUF指令子集:
-
BUFFER_LOAD_{ubyte, sbyte, ushort, sshort, dword, format_x} -
对于加载到LDS,设置指令的TFE位是非法的
地址计算:
-
LDS_offset= 来自M015:0的16位无符号字节偏移量 -
Mem_offset= 来自SGPR(SOFFSET SGPR)的32位无符号字节偏移量 -
idx_vgpr= 来自VGPR的索引值(位于VADDR)(如果idxen=0则为零) -
off_vgpr= 来自VGPR的偏移量值(位于VADDR或VADDR+1)(如果offen=0则为零)
下图显示了LDS和内存地址计算的组件:

仅当资源(T#)的ADD_TID_ENABLE字段设置为1时,才会添加TIDinWave,而LDS会添加它。MEM_ADDR M#在VDATA字段中;它指定M0。
钳位规则
内存地址钳位遵循与任何其他缓冲区获取相同的规则。
LDS地址钳位:返回的数据不能写入分配给此wave的LDS空间之外。
-
设置活动掩码以限制缓冲区读取,仅允许那些将数据返回到合法LDS位置的线程
-
LDSbase(分配)以32个双字为单位,LDSsize也是如此
-
M015:0以字节为单位
8.1.10 GLC位解释
GLC位对于加载、存储和原子操作具有不同的含义。
GLC对于加载的含义
-
当GLC==0时:
-
加载可以从GPU L1读取数据
-
通常,所有加载(除了加载获取)使用GLC==0
-
-
当GLC==1时:
-
加载故意错过GPU L1并从L2读取。如果GPU L1中有匹配的行,它将被无效;L2被重新读取
-
注意:对于单个加载指令,不会为同一wavefront中的每个工作项重新读取L2。例如:
b=uav[N+tid]// 假设这是一个字节读取,glc==1且N对齐到64B。在上述操作中,wavefront的第一个Tid从L2或更远处引入行,其他63个Tid从L1中的相同64B缓存行读取
-
GLC对于存储的含义
-
当GLC==0时:
-
这会导致跨wavefront存储操作的工作项进行写合并;脏行会自动写入L2
-
如果存储操作弄脏了64B行的所有字节,它在L1中保持干净和有效;允许后续访问命中此缓存行
-
否则,不留写合并行在L1中
-
-
当GLC==1时:
- 与GLC==0相同,只是写合并行不留在线中,即使所有字节都被弄脏
原子操作
-
当GLC==0时:
- 不返回数据(这是"只写"原子操作)
-
当GLC==1时:
- 返回操作前内存中的值
8.2 向量内存(VM)图像指令
向量内存(VM)操作通过纹理缓存(TC)在VGPR和内存之间传输数据。"向量"意味着为wavefront中的每个工作项唯一传输一个或多个数据块。这与标量内存读取形成对比,标量内存读取仅传输wavefront中所有工作项共享的一个值。
图像对象的示例包括纹理贴图和类型化表面。
图像对象使用一到四维地址访问;它们由一到四个元素的同质数据组成。这些图像对象使用IMAGE_*或SAMPLE_*指令读取或写入,所有这些指令都使用MIMG指令格式。IMAGE_LOAD指令直接从图像缓冲区读取元素到VGPR,而SAMPLE指令使用采样器常量(S#)并在读取数据后应用过滤。IMAGE_ATOMIC指令将VGPR中的数据与内存中已有的数据组合,并可选择返回操作前内存中的值。
所有VM操作都使用图像资源常量(T#),它是SGPR中的256位值。执行指令时,此常量被发送到纹理缓存。此常量定义了内存中表面的地址、数据格式和特性。一些图像指令还使用采样器常量,它是SGPR中的128位常量。通常,这些常量在执行VM指令之前使用标量内存读取从内存获取,但这些常量也可以在着色器内生成。
纹理获取指令有一个数据掩码(DMASK)字段。DMASK指定接收多少个数据组件。如果DMASK小于纹理中的组件数,纹理单元只发送DMASK组件,从R开始,然后是G、B和A。如果DMASK指定的组件多于纹理格式指定的,着色器接收缺失组件的零。
8.2.1 图像指令
本节描述图像指令集,以及这些指令可用的微码字段。
表34. 图像指令
| MIMG | 描述 |
|---|---|
SAMPLE_* |
从图像对象读取和过滤数据 |
IMAGE_LOAD_<op> |
从图像对象读取数据,使用以下之一:image_load、image_load_mip、image_load_{pck, pck_sgn, mip_pck, mip_pck_sgn} |
IMAGE_STORE IMAGE_STORE_MIP |
将数据存储到图像对象。存储数据到特定的mipmap级别 |
IMAGE_ATOMIC_<op> |
图像原子操作,包括以下之一:swap、cmpswap、add、sub、rsub、{u,s}{min,max}、and、or、xor、inc、dec、fcmpswap、fmin、fmax |
表35. 指令字段
| 字段 | 位大小 | 描述 |
|---|---|---|
| OP | 7 | 操作码 |
| VADDR | 8 | 提供地址第一个组件的VGPR地址 |
| VDATA | 8 | 提供写入数据第一个组件或接收读取数据第一个组件的VGPR地址 |
| SSAMP | 5 | 在四个连续SGPR中提供S#(采样器常量)的SGPR。缺少SGPR地址的最低两位,因为必须对齐到四个SGPR的倍数 |
| SRSRC | 5 | 在四个或八个连续SGPR中提供T#(资源常量)的SGPR。缺少SGPR地址的最低两位,因为必须对齐到四个SGPR的倍数 |
| UNRM | 1 | 强制地址为非规范化,无论T#如何。对于图像存储和原子操作,必须设置为1 |
| DA | 1 | 着色器声明要与此获取一起使用的数组资源。当为1时,着色器提供带指令的数组索引。当为0时,不提供数组索引 |
| DMASK | 4 | 数据VGPR启用掩码:一到四个连续VGPR。读取:定义返回哪些组件。0=红,1=绿,2=蓝,3=阿尔法。写入:定义哪些组件用VGPR的数据写入(缺失组件得到0)。启用的组件来自连续VGPR。例如:DMASK=1001:红在VGPRn中,阿尔法在VGPRn+1中。对于D16写入,DMASK仅用作字数计数:每个位代表要写入的16位数据,从VADDR的LSB开始,然后是MSB、VADDR+1等。忽略位位置 |
| GLC | 1 | 全局一致性。控制L1纹理缓存如何处理读取和写入。读取:GLC=0:读取可以命中L1并在wave间持久。GLC=1:读取错过L1并强制获取到L2。wave间没有L1持久性。写入:GLC=0:写入错过L1,写入到L2,并在wavefront间在L1中持久。GLC=1:写入错过L1,写入到L2。wavefront间没有持久性。原子操作:GLC=0:不返回先前数据值。wavefront间没有L1持久性。GLC=1:返回先前数据值。wavefront间没有L1持久性 |
| SLC | 1 | 系统级一致性。设置时,访问强制在二级纹理缓存中错过,并与系统内存一致 |
| TFE | 1 | PRT(部分驻留纹理)的纹素失败启用。设置时,获取可以返回NACK,导致VGPR写入到DST+1(所有获取目标GPR之后的第一个GPR) |
| LWE | 1 | LOD警告启用。设置为1时,纹理获取可能返回"LOD_CLAMPED = 1" |
| A16 | 1 | 地址组件为16位(而不是通常的32位)。设置时,所有地址组件为16位(每双字打包两个),除了:纹素偏移(三个6位无符号整数打包到一个双字中)。PCF参考(对于_C指令)。地址组件:对于无采样器的图像操作,为16位无符号整数;有采样器时,为16位浮点数 |
| D16 | 1 | VGPR数据16位。在加载时,将内存中的数据转换为16位格式,然后存储到VGPR中。对于存储,将VGPR中的16位数据转换为32位,然后写入内存。数据被视为浮点还是整数由NFMT决定。仅允许以下操作码使用:IMAGE_SAMPLE*、IMAGE_GATHER4*(但不包括GATHER4H_PCK)、IMAGE_LOAD、IMAGE_LOAD_MIP、IMAGE_STORE、IMAGE_STORE_MIP |
8.3 无采样器的图像操作码
对于无采样器的图像操作码,所有VGPR地址值都视为无符号整数。对于立方体贴图,face_id = slice * 6 + face。
下表显示了各种图像操作码的地址VGPR内容:
表36. 无采样器的图像操作码
| 图像操作码(无采样器的资源) | Acnt | 维度 | VGPRn | VGPRn+1 | VGPRn+2 | VGPRn+3 |
|---|---|---|---|---|---|---|
| get_resinfo | 0 | 任意 | mipid | |||
| load / store / atomics | 0 | 1D | x | |||
| load / store / atomics | 1 | 1D数组 | x | slice | ||
| load / store / atomics | 1 | 2D | x | y | ||
| load / store / atomics | 2 | 2D MSAA | x | y | fragid | |
| load / store / atomics | 2 | 2D数组 | x | y | slice | |
| load / store / atomics | 3 | 2D数组MSAA | x | y | slice | fragid |
| load / store / atomics | 2 | 3D | x | y | z | |
| load / store / atomics | 2 | 立方体 | x | y | face_id | |
| load_mip / store_mip | 1 | 1D | x | mipid | ||
| load_mip / store_mip | 2 | 1D数组 | x | slice | mipid | |
| load_mip / store_mip | 2 | 2D | x | y | mipid | |
| load_mip / store_mip | 3 | 2D数组 | x | y | slice | mipid |
| load_mip / store_mip | 3 | 3D | x | y | z | mipid |
| load_mip / store_mip | 3 | 立方体 | x | y | face_id | mipid |
8.4 有采样器的图像操作码
对于有采样器的图像操作码,所有VGPR地址值都视为浮点数。对于立方体贴图,face_id = slice * 8 + face。
某些采样和聚集操作码需要VGPR中显示的之外的额外值。这些值是:偏移、偏置、z比较和梯度。
表37. 有采样器的图像操作码
| 图像操作码(有采样器) | Acnt | 维度 | VGPRn | VGPRn+1 | VGPRn+2 | VGPRn+3 |
|---|---|---|---|---|---|---|
| sample | 0 | 1D | x | |||
| sample | 1 | 1D数组 | x | slice | ||
| sample | 1 | 2D | x | y | ||
| sample | 2 | 2D隔行扫描 | x | y | field | |
| sample | 2 | 2D数组 | x | y | slice | |
| sample | 2 | 3D | x | y | z | |
| sample | 2 | 立方体 | x | y | face_id | |
| sample_l | 1 | 1D | x | lod | ||
| sample_l | 2 | 1D数组 | x | slice | lod | |
| sample_l | 2 | 2D | x | y | lod | |
| sample_l | 3 | 2D隔行扫描 | x | y | field | lod |
| sample_l | 3 | 2D数组 | x | y | slice | lod |
| sample_l | 3 | 3D | x | y | z | lod |
| sample_l | 3 | 立方体 | x | y | face_id | lod |
| sample_cl | 1 | 1D | x | clamp | ||
| sample_cl | 2 | 1D数组 | x | slice | clamp | |
| sample_cl | 2 | 2D | x | y | clamp | |
| sample_cl | 3 | 2D隔行扫描 | x | y | field | clamp |
| sample_cl | 3 | 2D数组 | x | y | slice | clamp |
| sample_cl | 3 | 3D | x | y | z | clamp |
| sample_cl | 3 | 立方体 | x | y | face_id | clamp |
| gather4 | 1 | 2D | x | y | ||
| gather4 | 2 | 2D隔行扫描 | x | y | field | |
| gather4 | 2 | 2D数组 | x | y | slice | |
| gather4 | 2 | 立方体 | x | y | face_id | |
| gather4_l | 2 | 2D | x | y | lod | |
| gather4_l | 3 | 2D隔行扫描 | x | y | field | lod |
| gather4_l | 3 | 2D数组 | x | y | slice | lod |
| gather4_l | 3 | 立方体 | x | y | face_id | lod |
| gather4_cl | 2 | 2D | x | y | clamp | |
| gather4_cl | 3 | 2D隔行扫描 | x | y | field | clamp |
| gather4_cl | 3 | 2D数组 | x | y | slice | clamp |
| gather4_cl | 3 | 立方体 | x | y | face_id | clamp |
注意:
-
Sample包括sample、sample_d、sample_b、sample_lz、sample_c、sample_c_d、sample_c_b、sample_c_lz和getlod
-
Sample_l包括sample_l和sample_c_l
-
Sample_cl包括sample_cl、sample_d_cl、sample_b_cl、sample_c_cl、sample_c_d_cl和sample_c_b_cl
-
Gather4包括gather4、gather4_lz、gather4_c和gather4_c_lz
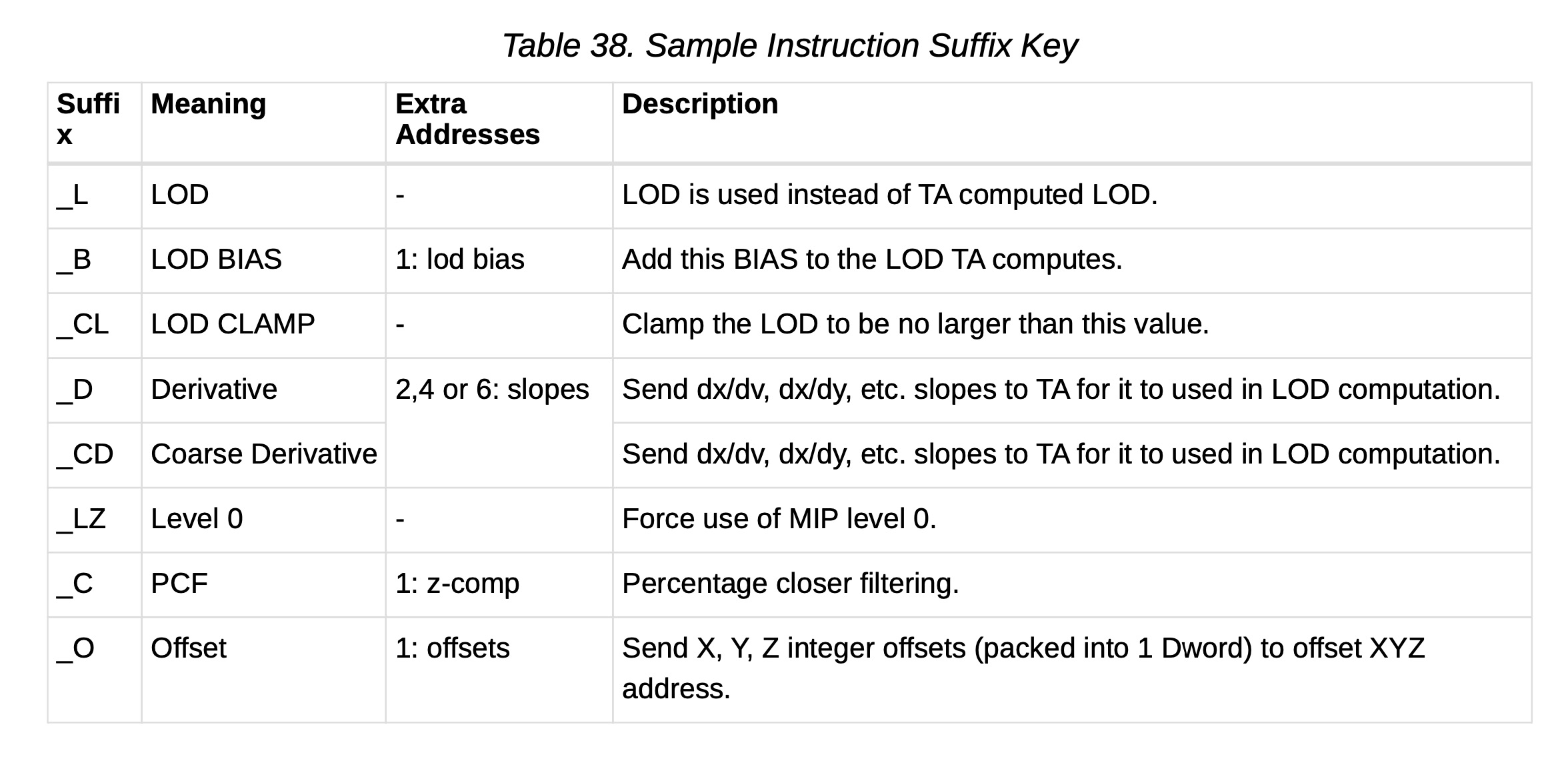
下表列出并简要描述了图像指令的合法后缀:
表38. 采样指令后缀键
8.4.1 VGPR使用
地址:地址由最多四个部分组成:
bash
{ offset } { bias } { z-compare } { derivative } { body }这些都打包到连续的VGPR中。
-
偏移 :
SAMPLE*O*、GATHER*O*一个双字的offset_xyz。偏移是六位有符号整数:X=5:0、Y=13:8、Z=21:16
-
偏置 :
SAMPLE*B*、GATHER*B*。一个双字浮点数 -
z比较 :
SAMPLE*C*、GATHER*C*。一个双字 -
导数(sample_d、sample_cd):2、4或6个双字,每个导数打包为一个双字,如下:
图像维度 VGPR N N+1 N+2 N+3 N+4 N+5 1D DX/DH DX/DV - - - - 2D DX/DH DY/DH DX/DV DY/DV - - 3D DX/DH DY/DH DZ/DH DX/DV DY/DV DZ/DV -
主体:一到四个双字,如表中定义:带采样器的图像操作码。地址组件为X、Y、Z、W,X在VGPR_M中,Y在VGPR_M+1中,依此类推。"主体"中的组件数是表中ACNT字段的值加一
-
数据:从一到四个连续VGPR写入或返回到。读取或写入的数据量由指令的DMASK字段确定
-
读取:DMASK指定资源的哪些元素返回到连续VGPR。纹理系统从内存读取数据,根据数据格式将其扩展为规范RGBA形式,为缺失组件填充零或一。然后应用DMASK,只有选定的组件返回到着色器
-
写入:写入图像对象时,只能写入整个元素(所有组件),而不仅仅是单个组件。组件来自连续VGPR,纹理系统为图像数据格式的任何缺失组件填充零值;忽略不属于存储数据格式的任何值。例如,如果DMASK=1001,着色器发送红从VGPR_N,阿尔法从VGPR_N+1到纹理单元。如果图像对象是RGB,纹素被VGPR_N的红覆盖,绿和蓝设置为零,着色器的阿尔法被忽略
-
原子操作:图像原子操作仅在32位和64位每像素表面上支持。表面数据格式在资源常量中指定。原子操作将元素视为32位或64位的单个组件。对于原子操作,DMASK设置为发送到纹理单元的VGPR(双字)数。图像原子操作的DMASK合法值:不允许其他DMASK值
-
0x1 = 32位原子操作(除了cmpswap)
-
0x3 = 32位原子cmpswap
-
0x3 = 64位原子操作(除了cmpswap)
-
0xf = 64位原子cmpswap
-
-
带返回的原子操作:数据从VDATA开始的VGPR中读取,提供给原子操作。如果原子返回值到VGPR,则该数据返回到从VDATA开始的相同VGPR
-
D16指令:加载格式和存储格式指令也有"d16"变体。对于存储,每个32位VGPR保存两个16位数据元素,传递给纹理单元。纹理单元在写入内存之前将它们转换为纹理格式。对于加载,从纹理单元返回的数据转换为16位,一对数据存储在每个32位VGPR中(先LSB,然后MSB)。DMASK位代表单个16位元素;因此,当DMASK=0011用于图像加载时,两个16位组件加载到单个32位VGPR中
-
8.4.2 图像资源
图像资源(也称为T#)定义图像缓冲区在内存中的位置、其维度、平铺方式和数据格式。这些资源存储在四个或八个连续SGPR中,并由MIMG指令读取。
表39. 图像资源定义
| 位范围 | 大小 | 名称 | 注释 |
|---|---|---|---|
| 128位资源:1D纹理、2D纹理、2D MSAA(多重采样抗锯齿) | |||
| 39:0 | 40 | 基地址 | 256字节对齐。也用于fmask指针 |
| 51:40 | 12 | 最小LOD | 4.8格式(四位无符号整数位,八位小数位) |
| 57:52 | 6 | 数据格式 | 组件数和每个组件的位数 |
| 61:58 | 4 | 数值格式 | 数值格式 |
| 62 | 1 | NV | 非易失性(0=易失性) |
| 77:64 | 14 | 宽度 | mip0的宽度-1(以纹素为单位) |
| 91:78 | 14 | 高度 | mip0的高度-1(以纹素为单位) |
| 94:92 | 3 | 性能调制 | 缩放采样器的perf_z、perf_mip、aniso_bias、lod_bias_sec |
| 98:96 | 3 | 目标选择_x | 0=0, 1=1, 4=R, 5=G, 6=B, 7=A |
| 101:99 | 3 | 目标选择_y | |
| 104:102 | 3 | 目标选择_z | |
| 107:105 | 3 | 目标选择_w | |
| 111:108 | 4 | 基础级别 | 资源视图中的最大mip级别。对于MSAA,设置为零 |
| 115:112 | 4 | 最后级别 | 对于MSAA,保存样本数 |
| 120:116 | 5 | 平铺索引 | 查找表:32×16 bank_width2、bank_height2、num_banks2、tile_split2、macro_tile_aspect2、micro_tile_mode2、array_mode4 |
| 127:124 | 4 | 类型 | 0=buf, 8=1d, 9=2d, 10=3d, 11=cube, 12=1d-array, 13=2d-array, 14=2d-msaa, 15=2d-msaa-array。1-7保留 |
| 256位资源:1D数组、2D数组、3D、立方体贴图、MSAA | |||
| 140:128 | 13 | 深度 | 3D贴图的mip0深度-1 |
| 156:141 | 16 | 间距 | 以纹素为单位 |
| 159:157 | 3 | 边框颜色重排 | 指定边框颜色的通道排序,独立于T# dst_sel字段。0=xyzw, 1=xwyz, 2=wqyx, 3=wxyz, 4=zyxw, 5=yxwz |
| 176:173 | 4 | 数组间距 | 被子的数组间距,编码为:trunc(log2(array_pitch))+1 |
| 184:177 | 8 | 元数据地址 | 位47:40 |
| 185 | 1 | 元数据线性 | 强制元数据表面为线性 |
| 186 | 1 | 元数据管道对齐 | 在元数据寻址中保持管道对齐 |
| 187 | 1 | 元数据RB对齐 | 在元数据寻址中保持RB对齐 |
| 191:188 | 4 | 最大MIP | 资源mipLevel-1。描述资源,与描述资源视图的base_level和last_level相反。对于MSAA,保存log2(样本数) |
| 203:192 | 12 | 最小LOD警告 | LOD的反馈触发器,U4.8格式 |
| 211:204 | 8 | 计数器bank ID | PRT计数器ID |
| 212 | 1 | LOD硬件计数启用 | PRT硬件计数器启用 |
| 213 | 1 | 压缩启用 | 启用增量颜色压缩 |
| 214 | 1 | 阿尔法在MSB上 | 如果表面的组件交换未反转,则设置为1(DCC) |
| 215 | 1 | 颜色变换 | 自动=0,无=1(DCC) |
| 255:216 | 40 | 元数据地址 | 元数据地址的高位(DCC)47:8 |
所有图像资源视图描述符(T#)都由驱动程序写为256位。
MIMG格式指令有一个DeclareArray(DA)位,反映着色器期望绑定的是数组纹理还是简单纹理。当DA为零时,硬件不向纹理缓存发送数组索引。如果纹理贴图被索引,硬件提供零索引值。为非索引纹理贴图发送的索引被忽略。
8.4.3 图像采样器
采样器资源(也称为S#)定义对采样指令读取的纹理贴图数据执行的操作。这些主要是地址钳位和过滤选项。采样器资源在四个连续SGPR中定义,并在每个采样指令执行时提供给纹理缓存。
表40. 图像采样器定义
| 位范围 | 大小 | 名称 | 描述 |
|---|---|---|---|
| 2:0 | 3 | 钳位x | 钳位/环绕模式 |
| 5:3 | 3 | 钳位y | |
| 8:6 | 3 | 钳位z | |
| 11:9 | 3 | 最大各向异性比率 | |
| 14:12 | 3 | 深度比较函数 | |
| 15 | 1 | 强制非规范化 | 强制地址坐标为非规范化 |
| 18:16 | 3 | 各向异性阈值 | |
| 19 | 1 | mc坐标截断 | |
| 20 | 1 | 强制去伽马 | |
| 26:21 | 6 | 各向异性偏置 | u1.5格式 |
| 27 | 1 | 截断坐标 | |
| 28 | 1 | 禁用立方体贴图环绕 | |
| 30:29 | 2 | 过滤模式 | 正常线性插值、最小或最大过滤 |
| 31 | 1 | 兼容模式 | 1=新模式;0=传统模式 |
| 43:32 | 12 | 最小LOD | u4.8格式 |
| 55:44 | 12 | 最大LOD | u4.8格式 |
| 59:56 | 4 | 性能MIP | |
| 63:60 | 4 | 性能Z | |
| 77:64 | 14 | LOD偏置 | s5.8格式 |
| 83:78 | 6 | LOD偏置秒 | s1.4格式 |
| 85:84 | 2 | xy放大过滤 | 放大过滤 |
| 87:86 | 2 | xy缩小过滤 | 缩小过滤 |
| 89:88 | 2 | z过滤 | |
| 91:90 | 2 | MIP过滤 | |
| 92 | 1 | MIP点预钳位 | 当MIP过滤器=点时,钳位前添加0.5 |
| 93 | 1 | 禁用LSB上取整 | 禁用过滤器中的上取整逻辑(向上舍入) |
| 94 | 1 | 过滤器精度修复 | |
| 95 | 1 | 各向异性覆盖 | 如果base_level = last_level,禁用各向异性过滤 |
| 107:96 | 12 | 边框颜色指针 | |
| 125:108 | 18 | 未使用 | |
| 127:126 | 2 | 边框颜色类型 | 不透明黑色、透明黑色、白色、使用边框颜色指针 |
8.4.4 数据格式
数据格式0-15可用于缓冲区资源,所有格式可用于图像格式。下表详细说明了图像和缓冲区资源可以使用的所有数据格式。
8.4.5 向量内存指令数据依赖性
当发出VM指令时,地址立即从VGPR中读取并发送到纹理缓存。任何纹理或缓冲区资源和采样器也立即发送。然而,写入数据不会立即发送到纹理缓存。
着色器开发人员负责避免与VMEM指令相关的数据危害,包括在读取从纹理缓存获取的数据之前等待VMEM读取指令完成(VMCNT)。这在"数据依赖性解析"部分中解释。