CoT思维链
思维链(Chain of Thought,CoT)是提升大语言模型(LLM)处理复杂推理任务的核心技术。
它的核心逻辑是引导大模型在输出最终答案前,先生成一连串结构化的中间推理步骤,就像模拟人类解决问题时一步步思考的过程。
通过这种方式,LLM能更透彻地理解问题结构,把复杂任务拆解开来,逐步推导解决方案。
这些清晰可见的思考步骤,让大模型的决策过程更透明、更易解释,方便用户理解和调试。
不过,这种方法也有代价------较长的思考链条会增加计算资源消耗和处理时间。
在实际应用中,CoT特别适合处理需要多步逻辑推导的任务,比如数学解题(如复杂方程求解)、逻辑推理题(如三段论推理)等。以数学题为例,大模型借助CoT会先分析题目中的已知条件,明确求什么,再一步步列出公式、代入数据,最终得出结果,整个过程就像学生解题时写的演算步骤。
虽然CoT增强了大模型的推理能力,但它的推理过程主要依赖大模型内部的知识库,缺乏与外部世界的实时互动,这可能导致知识滞后、产生错误信息或让错误不断传递。
ReAct(Reasoning and Action)框架则通过结合"推理"(Reasoning)与"行动"(Action),解决了这一问题。
它让大模型在推理时能与外部工具或环境互动,获取最新信息、执行具体操作,并根据反馈调整后续步骤。
这种动态交互让大模型具备了"边思考边行动、边观察边调整"的能力,核心运作机制可总结为"思考(Thought)→行动(Action)→观察(Observation)"的循环。
一、Plan-Act(规划 - 执行)模式
Plan-Act 是一种线性的 "先规划后执行" 模式 ,核心是 "先制定完整计划,再按计划逐步执行",无中间反馈调整环节:
- 流程:接收目标→拆解为固定子任务序列→按顺序执行所有步骤→输出结果;
- 特点:规划阶段一次性确定所有行动路径,执行过程中不根据实际结果修改计划;
- 示例 :若规划 "查询京东 iPhone 17 价格→计算优惠→推荐购买",即使执行时发现京东无货,仍会继续按原计划完成步骤(如强行计算优惠),最终输出无效结果。
Plan-and-Execute 框架:结构化规划与顺序执行
与 ReAct 的迭代试错不同,Plan-and-Execute (P-a-E) 采取了一种更结构化、更线性的方法。
这种"先规划后执行"的模式是 AI Agent 领域中另一种常见的架构范式 。顾名思义,它包含两个截然不同的阶段:
工作原理详解
- Planning (规划) 阶段: 首先,Agent(通常通过一次或少数几次 LLM 调用)基于用户给定的初始目标,生成一个完整的、通常是分步骤的执行计划。这个计划列出了为达成目标所需执行的所有步骤及其顺序。
- Execution (执行) 阶段: 然后,Agent 严格按照预先制定的计划,一步一步地顺序执行。通常每一步会涉及调用一个或多个工具。只有当前步骤成功完成后,才会进入下一步。
实现模式与关键点
构建 P-a-E Agent 通常涉及两个核心组件:
- 规划器 (Planner): 负责理解初始目标并生成结构化的执行计划。这通常是一个专门的 LLM 调用,其 Prompt 旨在输出一个清晰的步骤列表或带有依赖关系的计划。计划的质量直接决定了 Agent 的最终表现。
- 执行器 (Executor): 负责解析计划,并按顺序调度工具执行每个步骤。它需要管理步骤间的状态传递(如上一步的输出作为下一步的输入),但不负责重新规划(除非设计了非常复杂的错误处理逻辑)。
二、ReAct(推理 - 行动)模式
ReAct 是一种循环的 "边推理边行动" 模式 ,核心是 "每一步都根据当前状态推理下一步动作,执行后观察结果,再调整后续策略":
- 流程:接收目标→推理第一步行动→执行→观察结果→基于结果推理第二步行动→循环直至完成目标;
- 特点 :无预先完整规划,依赖实时反馈动态决策,强调 "思考 - 行动 - 反馈" 的闭环;
- 示例 :目标是 "购买性价比最高的 iPhone 17",第一步推理 "查询京东价格"→执行后发现无货→观察结果→下一步推理 "切换至拼多多查询"→执行后获取价格→继续推理 "计算返利"→最终输出推荐方案。
ReAct (其名称是 Reasoning + Acting 的结合)是一种极具影响力的 Agent 执行框架,由 Yao 等人明确提出。它的核心思想是模仿人类解决问题时边想边做、边观察边调整的模式。
ReAct 让 LLM 在解决任务时模拟人类的思考过程:想一步,做一步,再根据结果调整思考,再行动......如此循环,直到得出最终答案。
工作原理详解:迭代循环机制
ReAct Agent 在一个紧密的迭代循环中运行,这个循环通常包含以下步骤:
- Thought (思考): Agent 首先基于当前目标和之前的观察进行内部"思考"。这通常是利用 LLM 生成一段描述当前状态、分析问题、制定下一步行动策略或分解任务的文本。
- Action (行动): 基于思考的结果,Agent 决定执行一个具体的行动。这通常是调用一个工具(如搜索引擎、计算器、API)并附带必要的参数,或者是向用户请求更多信息,甚至是判断任务已经完成并生成最终答案。
- Observation (观察): 执行行动后,Agent 会从环境或工具那里获得一个结果或反馈,这就是"观察"。例如,搜索引擎返回的搜索结果、API 调用的输出、代码执行的错误信息等。
- 回到 Thought: Agent 将这个观察结果纳入考量,开始新一轮的思考,评估上一步行动的效果,判断是否需要调整策略,并规划下一步的行动。这个循环不断重复,直到 Agent 判断任务目标已经达成。
Thought → Action → Observation 循环,思考 行动 观察 思考...... 最终答案
关键 Prompt 设计技巧
ReAct 的效果在很大程度上依赖于精心设计的 Prompt。
这个 Prompt 需要引导 LLM 在每一步:
- 有效思考 (Thought): 指示 LLM 分析当前状况、回顾目标、评估已有信息、识别知识差距、制定行动计划。常常包含 "Think step-by-step" 或类似的指令。
- 做出行动决策 (Action): 指示 LLM 以特定格式(如 JSON)输出要调用的工具名称和参数,或者输出最终答案。
- 解读观察结果 (Observation): 帮助 LLM 理解工具返回的信息,并将其融入下一步的思考中。
- Prompt 还需要包含可用工具的描述以及一些示例(Few-shot examples),来帮助 LLM 更好地理解如何在这个循环中工作。
优点分析
- 灵活性高: ReAct 能够根据每一步的观察结果动态调整策略,对预料之外的情况或工具执行失败具有较强的适应性。
- 处理知识密集型任务: 通过迭代地使用工具(如搜索)获取信息,ReAct 能较好地处理需要外部知识的任务。
- 透明度: "Thought"步骤提供了 Agent 决策过程的中间记录,便于理解和调试。
缺点分析
- 可能陷入无效循环: 如果 Agent 的思考或工具使用出现偏差,可能会导致在几个步骤之间重复循环而无法取得进展。
- 效率较低: 每一步都需要 LLM 进行思考和决策,对于长流程任务,LLM 调用次数多,可能导致较高的延迟和成本。
- 错误累积: 前一步的错误(如错误的思考或工具调用失败)可能会影响后续步骤,导致最终结果偏差。
代码实现分析 (以 LangChain/LlamaIndex 为例)
主流的 Agent 开发框架如 LangChain 和 LlamaIndex 都对 ReAct 提供了良好的支持,极大地简化了其实现。它们通常会提供一个核心的执行器模块,例如 LangChain 中的 AgentExecutor,负责管理整个 ReAct 循环。
开发者可以通过简单的配置来快速启用 ReAct 逻辑。
例如,在 LangChain 中,开发者常常可以通过 initialize_agent 函数并选用特定的 agent_type(如 zero-shot-react-description、react-docstore 等预置类型)来便捷地构建 ReAct Agent。
类似地,LlamaIndex 也通过其 AgentRunner 或相关类(如 ReActAgent)提供了对 ReAct 模式的支持,允许开发者将 LLM、工具集和 ReAct 的循环机制方便地组合起来。
这些框架的执行器(Executor/Runner)内部封装了 ReAct 的核心流程:
- 格式化并发送包含思考、行动指令的 Prompt 给 LLM。
- 解析 LLM 输出的 Thought 和 Action。
- 根据 Action 查找并调用相应的工具。
- 将工具返回的 Observation 格式化并反馈给 LLM,开始下一轮循环。
- 处理循环的终止条件(如达到最大迭代次数、Agent 判断任务完成并输出 Final Answer 等)。
这意味着开发者通常只需要定义好 LLM 实例、准备好工具列表(Tool)以及可能定制化的基础 Prompt,就可以利用这些框架快速搭建并运行一个 ReAct Agent,而无需手动编写复杂的循环控制和解析逻辑。
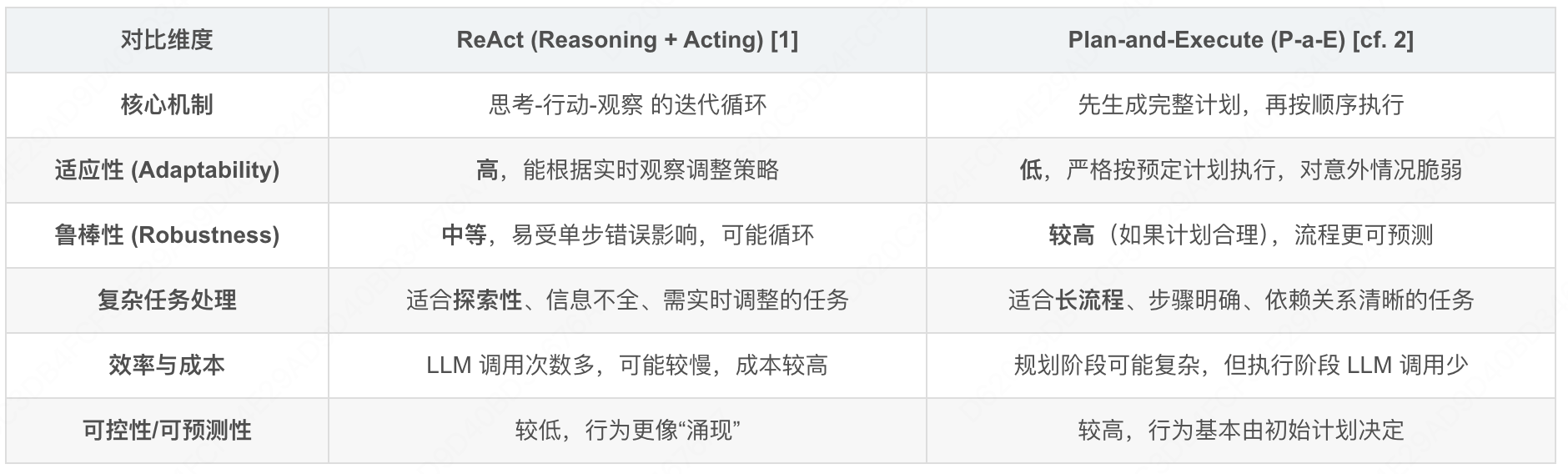
三、核心区别对比
| 维度 | Plan-Act 模式 | ReAct 模式 |
|---|---|---|
| 规划方式 | 预先制定完整、固定的计划 | 无预先计划,每步动态推理 |
| 反馈机制 | 无执行中反馈,计划一旦确定不修改 | 每步执行后均根据结果反馈调整策略 |
| 灵活性 | 低,无法应对计划外的异常情况 | 高,可适配环境变化或意外结果 |
| 适用场景 | 简单、确定性高的任务(如固定流程自动化) | 复杂、不确定性高的任务(如多平台比价、故障排查) |
| 决策逻辑 | 静态的 "计划驱动" | 动态的 "反馈驱动" |
1) ReAct(Reason + Act)
"边思考边行动":思考 → 选工具 → 执行 → 观察 → 再思考 循环。
- 优势:对动态/不确定信息更稳,路径可随观察自我修正
- 代价:步数和成本不易控,易陷入"想太多"的循环
2) Plan-and-Execute(先计划、后执行)
先产出全局计划(可带里程碑/验收标准),再由执行器按计划推进,必要时触发再规划。
- 优势:可控、可审计、可展示进度
- 代价:初始信息不足时易偏航,必须设计好再规划触发器
经验法则 :探索/信息不足→先 ReAct;流程固化/要可视化进度→Plan-and-Execute,并保留再规划"逃生门"。
如何选择?
-
用 ReAct:
-
任务简单、无需长期规划(如单轮问答、API 调用)。
-
希望快速部署,避免训练成本。
-
-
用 Plan-and-Act:
-
任务复杂、多步骤(如订票、数据爬取)。
-
环境动态性强(如网页内容变化)。
-
需高鲁棒性,容忍较高计算开销。
-
四、延伸:Plan-ReAct 模式(结合两者优势)
Plan-ReAct 是 Plan-Act 与 ReAct 的融合模式,兼具前瞻性规划和动态调整能力:
- 流程:先制定初步的任务框架(Plan)→执行时按 ReAct 模式循环(每步推理→行动→反馈→调整计划);
- 示例:先规划 "查询多平台价格→对比优惠→推荐购买" 的框架→执行第一步 "京东查询" 发现无货→反馈后调整计划,跳过京东直接查询拼多多→继续后续步骤。
简言之,Plan-Act 是 "按剧本演戏",ReAct 是 "即兴发挥",而 Plan-ReAct 是 "有大纲但可临场改剧本"------ 三者的核心差异在于是否依赖预先规划 和是否支持动态反馈调整。
常见坑与规避
- 过度规划 :步骤太细 → 设"最少信息可完成"粒度
- 无限循环:ReAct 无硬阈值 → 必配步数/时长上限
- 工具误用:描述不清 → 工具卡片写清"何时用/不用"+反例
- 幻觉入参:强制参数校验 + 必要时二次确认
- 计划偏航 :设置"验收标准 "与"再规划门"
总结
ReAct 通过迭代的"思考-行动-观察"循环赋予了 Agent 灵活性和适应性,而 Plan-and-Execute 则通过"先规划后执行"的模式提供了更高的结构性和可预测性。
Prompt 控制 / 模块化设计、规划策略、工具调度 / 使用、记忆机制、控制流与反馈、Agent 协同架构、以及工具库可扩展性 / 安全性,这些共同决定了一个 agent 表现的好坏,也诞生了现在各种各样的 agent 应用。
一些可直接复用的 Prompt 片段
System(基线)
你是一个严谨的 Agent Planner。目标:将复杂任务拆成可验证的小步骤,
并在成本、时延与成功率之间平衡。
要求每步包含:step_name, intent, tool, inputs, expected_output, success_criteria。
计划需给出:overall_acceptance, 预算上限与风险项。
仅能使用提供的工具目录与参数 schema.
ReAct 循环
思考 当前子目标:{sub_goal}
计划 候选工具与原因:{tool_ranking}
行动 调用:{tool_name} 参数:{params}
观察 得到:{observation}
评估 是否满足 success_criteria?若否,更新子目标/工具并继续。
Plan 阶段(一次性计划)
为任务"{user_goal}"生成不超过 {max_steps} 步的执行计划。
每步输出:step_name, intent, tool, inputs, expected_output, success_criteria。
计划末尾输出:overall_acceptance, risk_list, fallback 策略。
Execute 阶段
按第 {i} 步执行,必要时调用工具。
输出:observation, achieved?, next_step_suggestion。
若连续失败≥{k}次或验证不通过→请求再规划。