前言
本文记录使用Trae SOLO模式开发一个视频提取文字并总结归纳的工具
线上地址:ashuai.site:24680/
需求场景表述
-
笔者是前端开发,但是对产品经理的知识了解不多,所以想学习产品经理的知识,问之前的产品同事要了一份视频课程,无奈课程时长起步一个多小时,如果一点点开,或者快进看,也是效率略低。
-
因此,笔者想开发一个工具,能够一键提取视频中的内容文字,并把内容文字交给大模型,由大模型总结摘要
-
这样我就可以快速学习产品经理的知识,而不是浪费时间在看视频上
首先,我需要做技术框架选型,限定为react+vite+ts+antd+tailwindcss
篇幅原因,把内容文字交给大模型,由大模型总结摘要这一步,笔者没有再solo
同质化调用大模型api的文章,可以参考笔者先前的文章:《效能工具(十)之接入deepseek实现AI学习PDF文档读后感文件批量生成功能》
Trae的SOLO模式开发
1. 基于用户需求,生成对应文档
笔者把上述需求,告知Trae 以后,Trae自动帮我生成一个文档,规划好,它需要做的事情,并且允许我调整这个规划文档,如下:
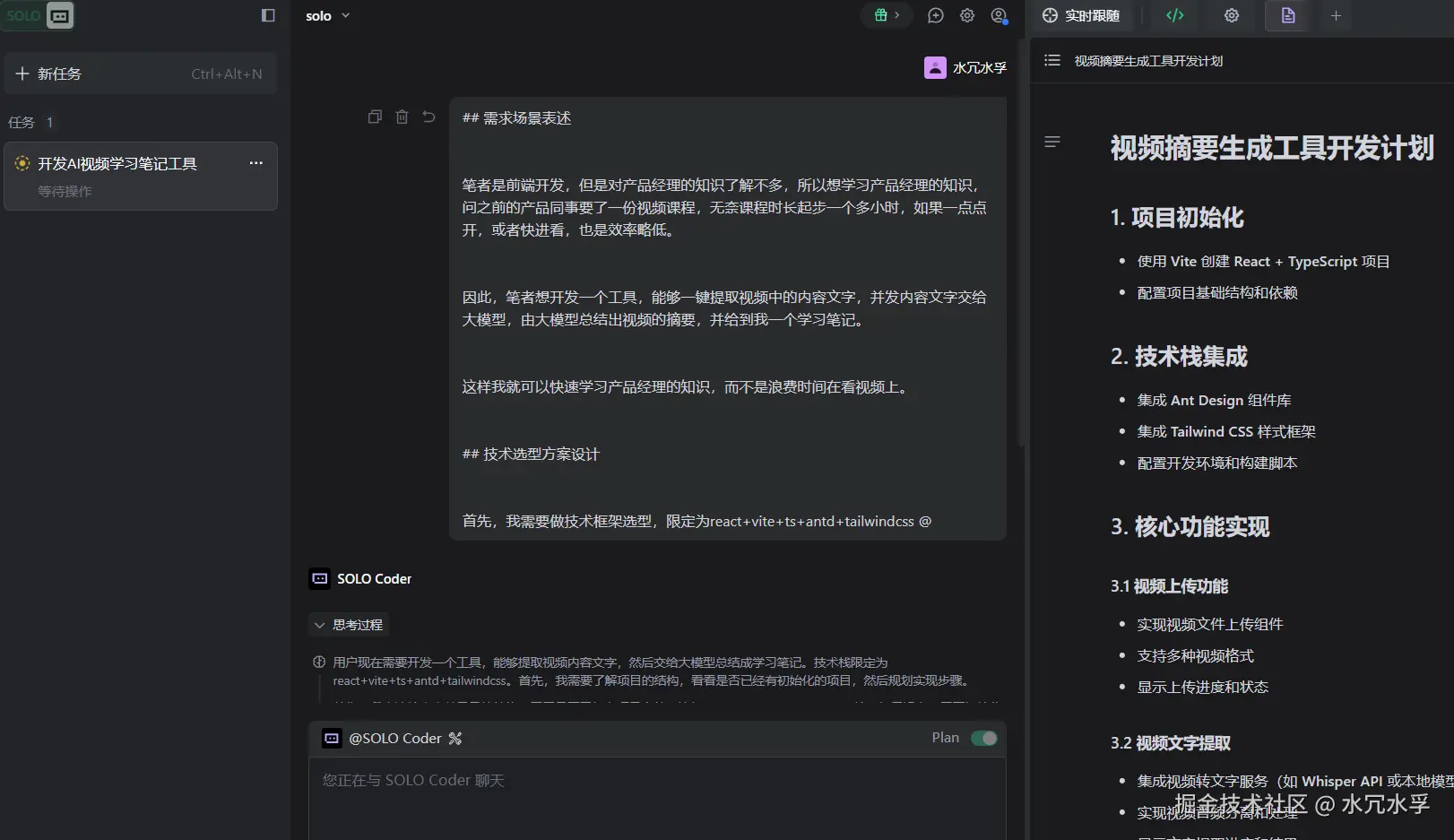
- 如果我觉得规划文档冗余,或者缺少东西,可以修修改改
- 这一步,很像项目经理提出需求后,产品提供的需求拆解文档(包含技术开发要点)
2. 让其按照文档,进行开工
让其按照文档,进行开工,Trae SOLO会自动在命令行执行相关命令,然后在右侧生成对应代码
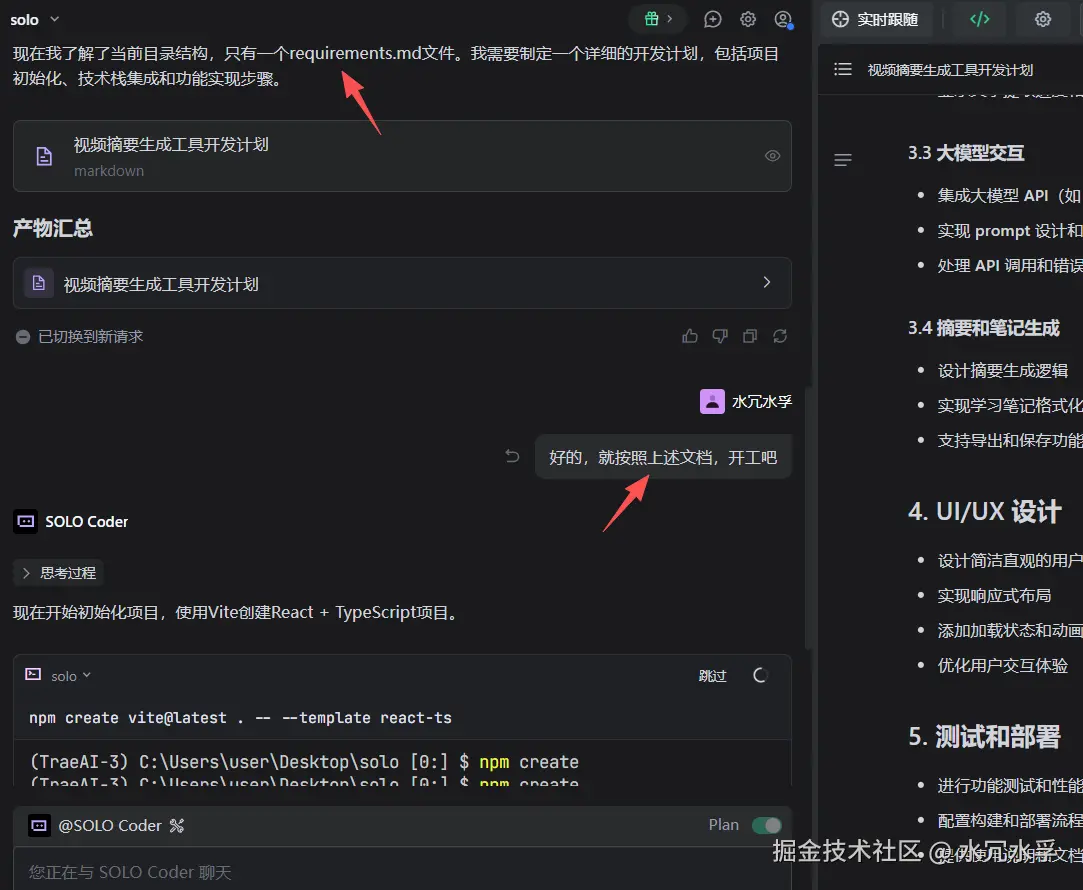
然后,安装各种依赖
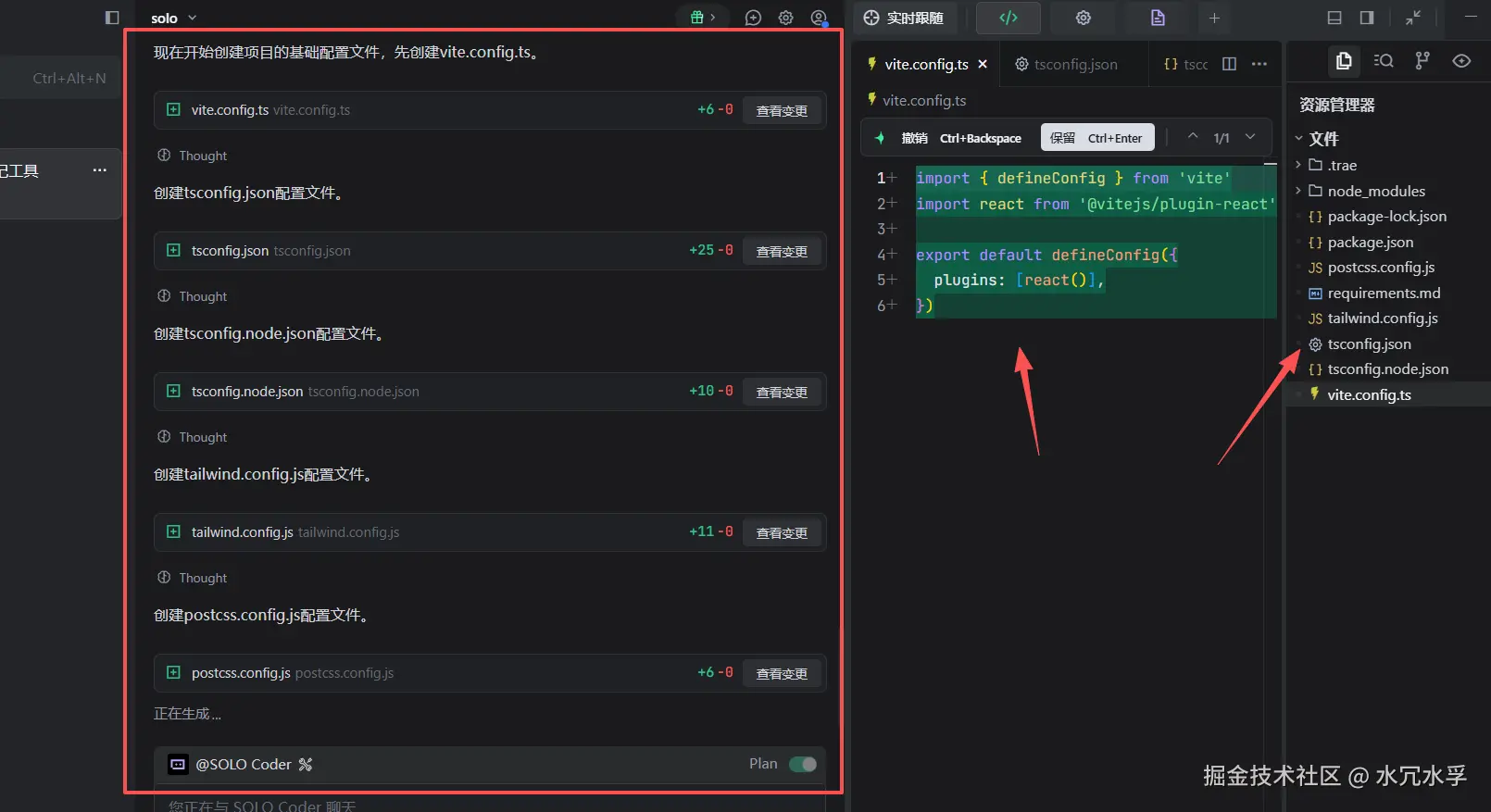
3. 产物变更
当Trae SOLO完毕以后,会提供一个产物汇总,我们可以查看变更,这样能够具体看出来,Trae帮我们写了那些代码
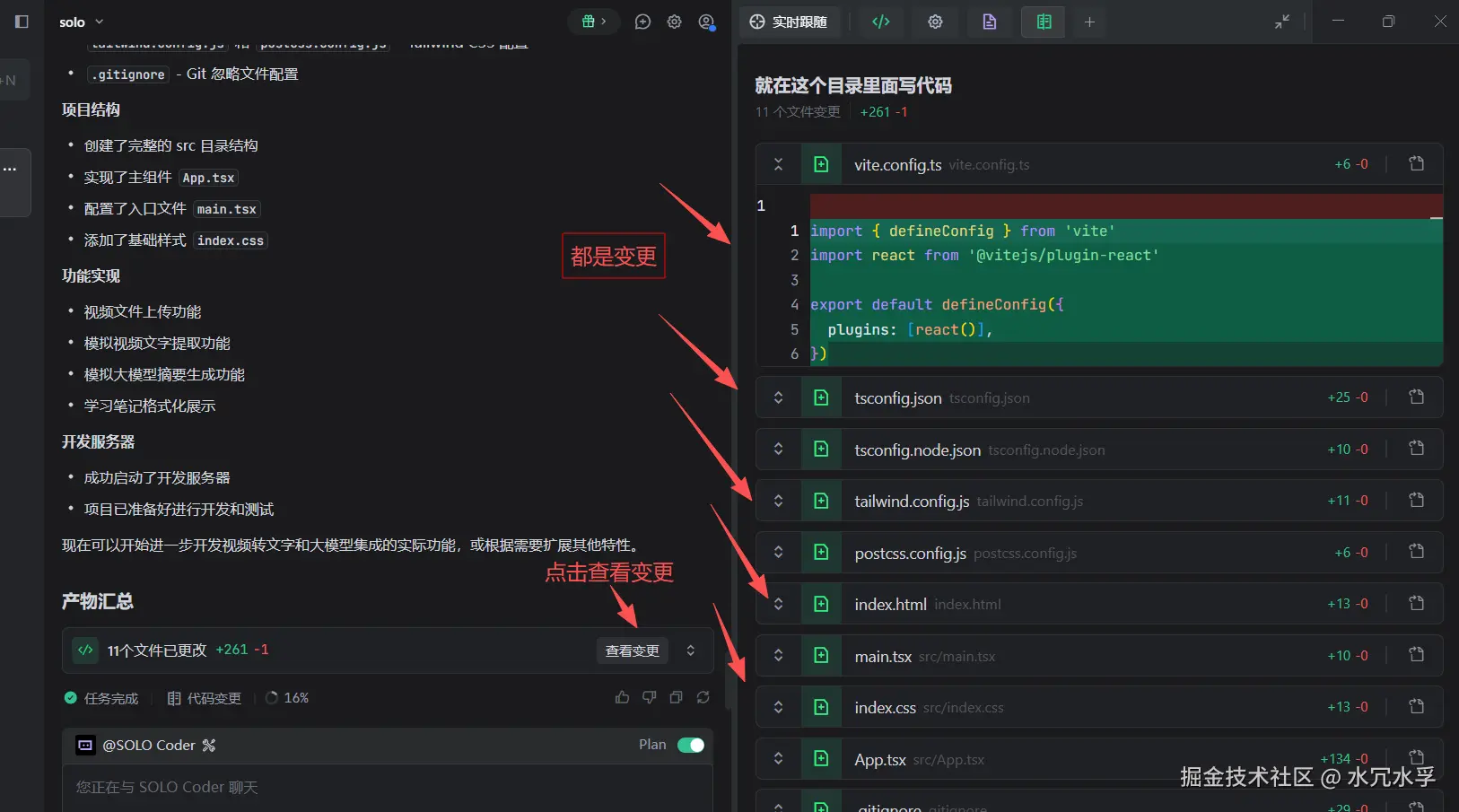
然后,我们查看一下终端
4. 启动项目跑起来,浏览器看效果
默认运行在5173端口上
看看浏览器的效果,发现了一个小bug
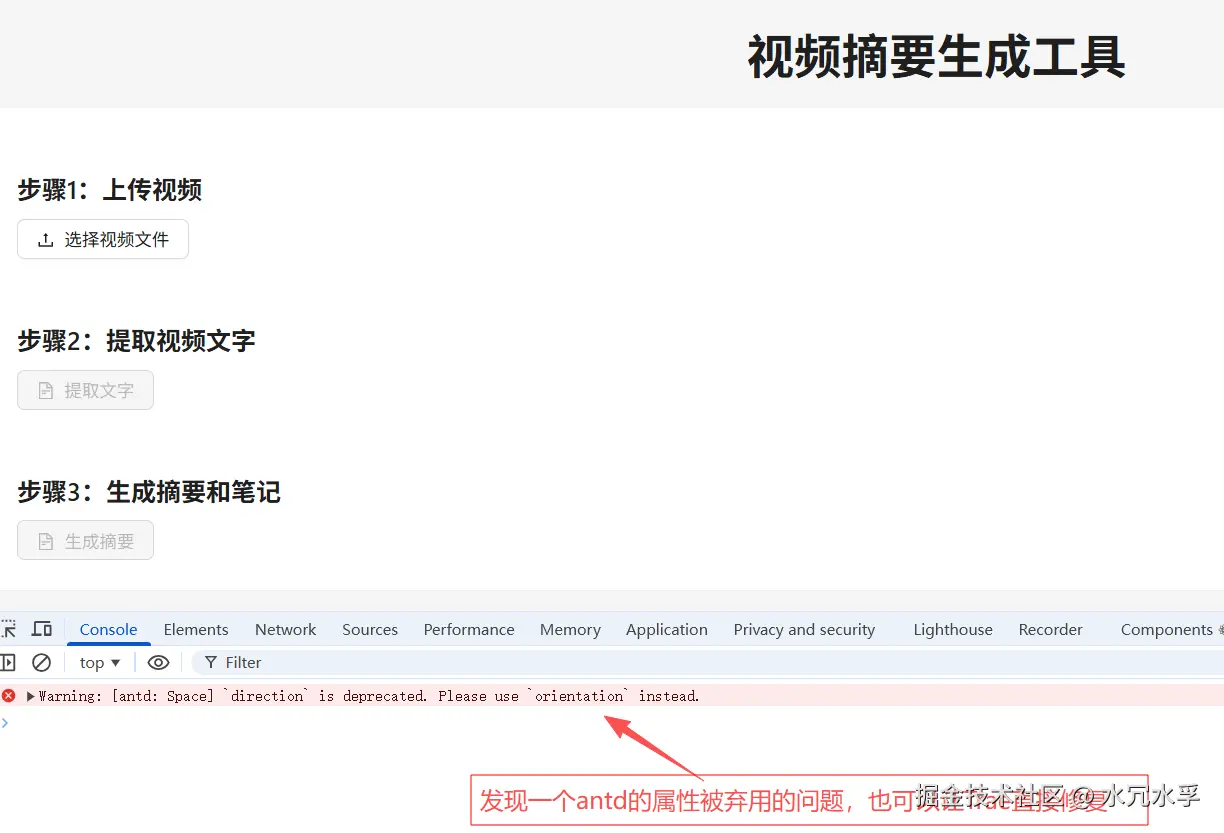
5. 告知修复antd的属性弃用的bug
这里可以截图,或者文字输入,把浏览器的bug粘贴,告知Trae,如下
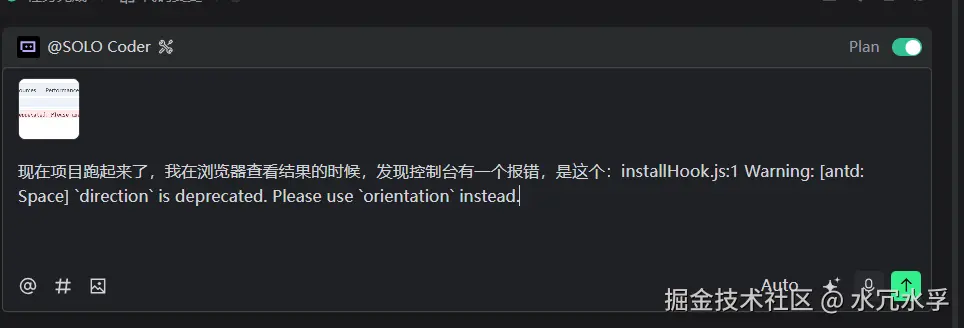
然后,Trae会进行思考,并定位到问题代码,自动修复

这样的话,基本的样子就出来了,接下来,需要我进行人工介入
6. 视频提取文字,技术拆解
视频提取文字,分为这几个步骤
- 把视频中的音频剥离出来------使用fluent-ffmpeg这个包
- 把音频转成文字------使用whisper-node这个包
fluent-ffmpeg需要下载ffmepg这个工具的本地
whisper-node下载tiny微小版模型就行了
接下来,我需要 Windows 平台,下载ffmepg
参考这篇文章:blog.csdn.net/Natsuago/ar...
最终,笔者把ffmpeg安装好了,如下
7. 发现还得写后端
fluent-ffmpeg和whisper-node需要后端服务,才方便运行,所以,我和Trae沟通后,它又帮我继续创建后端代码
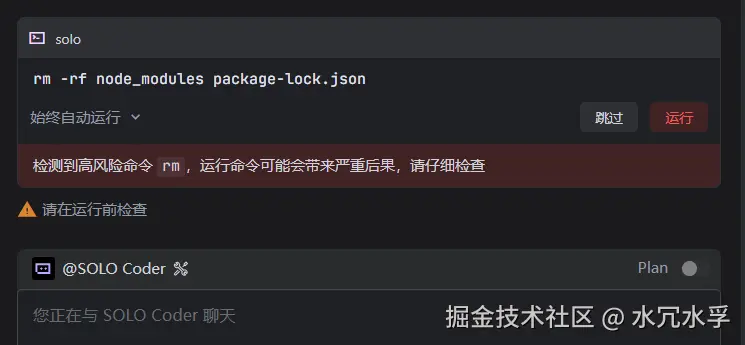
8. 针对于高风险的命令会暂停并提示用户
比如删除文件操作,Trae会停下来solo,然后询问用户是否这样操作,这样还是不错的,防止AI编程误删一些重要的文件
9. 若是方向错误,告知可纠正
- 实际上,涉及到视频转文本的功能,还是python生态更加合适
- 笔者一开始,让其使用nodejs生态写后端,而后,solo也发现了并推荐改成python生态
- 笔者点击同意,选择让其把后端代码改成python生态
- 然后trae也很清晰地理解了需求
- 进行了重构
- 重构过程中,可能也会出现一些报错,也需要人工介入,但是这并不Trae的问题,而是所有AI编程的问题
和人沟通,有什么问题,和AI沟通也会有
有时候,锅不在AI,而在我们,因为我们没有清晰地表达明白需求
10. 来回solo最终得到结果成品
在来回的solo交流中,最终,实现了笔者想要的效果
工具成品
技术栈介绍
注意,以下这总结文档,也是solo出来,我再修改的

效果图
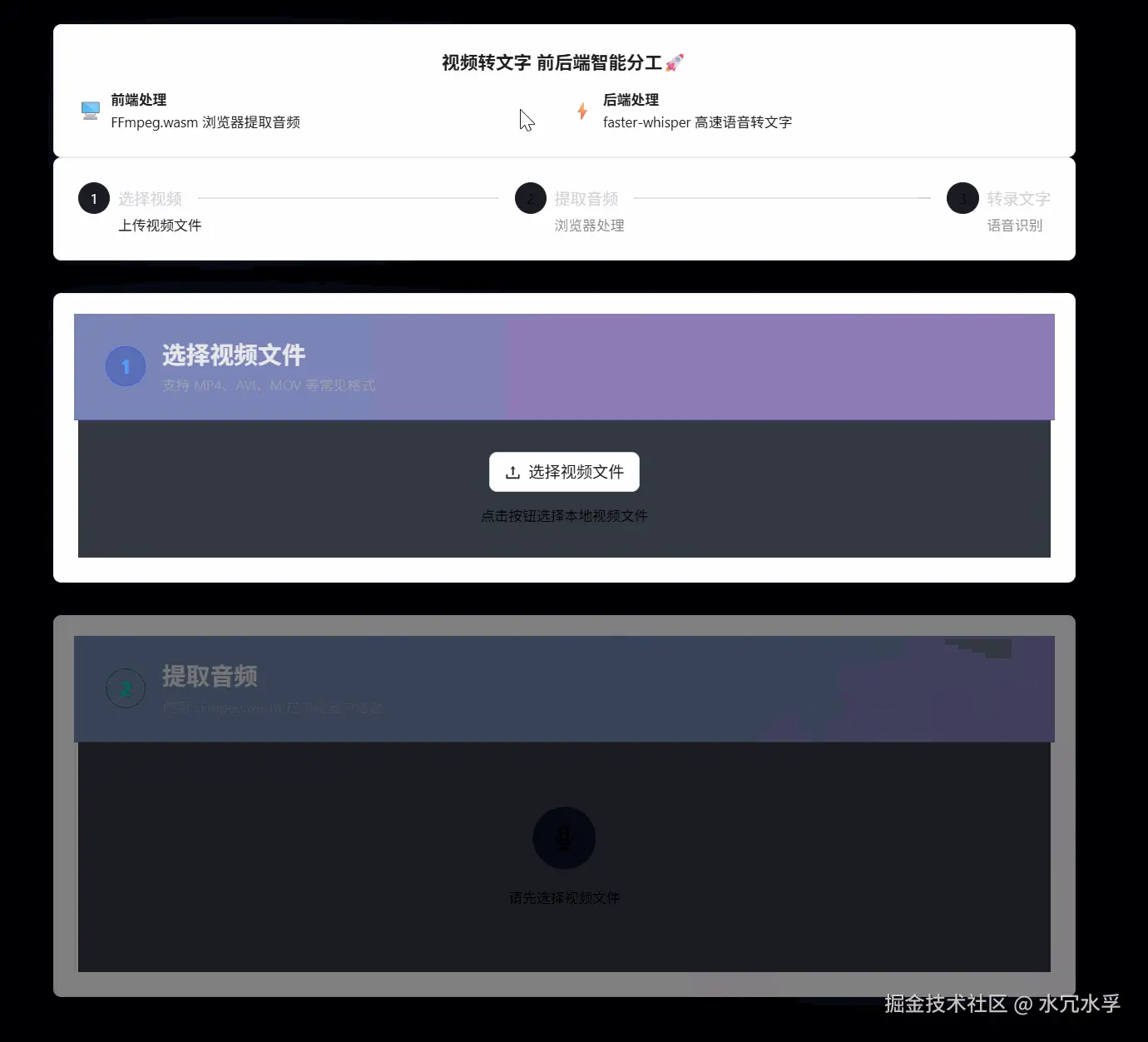
线上地址(不包含后端)
服务器内存容量吃紧,就不部署后端了,大家可以自己拉取代码,自己本机跑起来
github仓库代码
注意,若是生产环境,高可用,笔者还是建议,使用云服务商的付费接口
原因主要有两点:
1.开源模型的识别准确率、2.服务器维护成本
总结Trae SOLO模式
- Trae SOLO模式就是我们开发者化身项目经理角色
- Trea SOLO化身产品经理写文档、加程序员写代码角色
- 我们开发者,主要是进行把控、管控、调整
- 从而让开发出来的项目,符合预期
整体用下来,还是能够提升很大的开发效率的