在MySQL数据库中,InnoDB存储引擎的锁机制是保障并发事务安全的核心组件,直接影响系统的并发性能与数据一致性。本文将从两阶段锁原则 、InnoDB行锁模式 、行锁算法三个核心理论出发,结合实际实验验证,帮助大家彻底掌握InnoDB锁机制的工作原理与实践要点。
1 两阶段锁:锁操作的"黄金法则"
传统关系型数据库(包括InnoDB)遵循两阶段锁原则(Two-Phase Locking, 2PL),该原则将事务中的锁操作明确划分为两个不相交的阶段,确保锁的安全性与并发控制的有效性。
1.1 两阶段锁的核心流程
| 步骤 | MySQL操作 | 解释 | 锁阶段 |
|---|---|---|---|
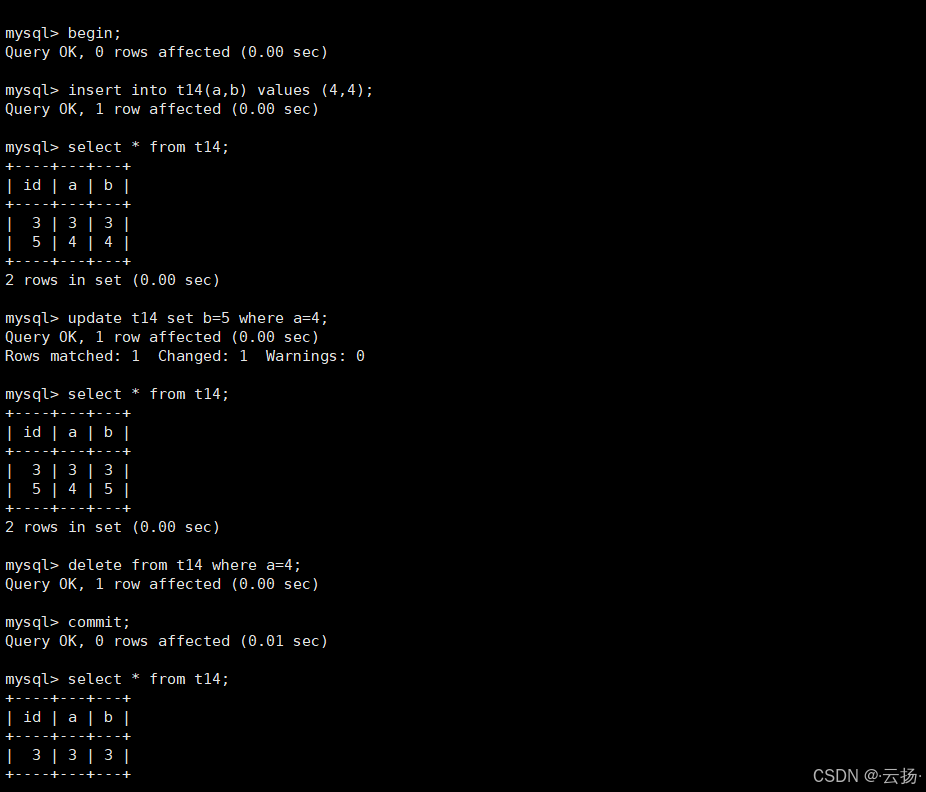
| 1 | begin; |
事务正式启动,进入事务上下文 | - |
| 2 | insert into t14(a,b) values(4,4); |
执行插入操作,为目标记录加insert对应的排他锁 |
加锁阶段 |
| 3 | update t14 set b=5 where a=4; |
执行更新操作,为目标记录加update对应的排他锁 |
加锁阶段 |
| 4 | delete from t14 where a=4; |
执行删除操作,为目标记录加delete对应的排他锁 |
加锁阶段 |
| 5 | commit; |
事务提交,释放步骤2-4中所有已加的锁 | 解锁阶段 |
1.2 关键特性
- 加锁阶段 :事务在执行过程中,根据操作需求(增删改查)逐步获取所需的锁,只加锁、不解锁;
- 解锁阶段 :事务提交(
commit)或回滚(rollback)时,一次性释放所有已获取的锁 ,只解锁、不加锁; - 核心目的:通过"先聚锁、后释放"的逻辑,避免事务执行过程中因锁提前释放导致的数据不一致问题(如脏读、不可重复读)。
2 InnoDB行锁模式:控制并发访问的"权限开关"
InnoDB支持两种核心行锁模式:共享锁(Shared Lock, S锁) 和排他锁(Exclusive Lock, X锁),不同锁模式决定了事务对数据的访问权限,以及与其他事务的兼容性。
2.1 共享锁(S锁):"只读不写"的协作锁
-
作用 :事务获取某记录的S锁后,仅拥有读取数据的权限,无修改权限;
-
兼容性 :多个事务可同时对同一记录加S锁("共享读"),但禁止其他事务加X锁(避免"读-写冲突");
-
适用场景:需要确保数据读取期间不被修改的场景(如统计报表生成);
-
加锁SQL :
sql-- 为查询结果集的记录加共享锁 select * from t14 where a=1 lock in share mode;
2.2 排他锁(X锁):"独占读写"的互斥锁
-
作用 :事务获取某记录的X锁后,拥有该记录的独占读写权限;
-
兼容性 :同一记录只能被一个事务加X锁,禁止其他事务加S锁或X锁(避免"写-读""写-写"冲突);
-
适用场景:需要修改数据的场景(如更新订单状态、删除无效数据);
-
默认行为 :InnoDB执行
insert/update/delete操作时,会自动为目标记录加X锁,无需手动指定; -
手动加锁SQL :
sql-- 为查询结果集的记录加排他锁 select * from t14 where a=1 for update;
2.3 锁兼容性矩阵
| 现有锁\请求锁 | 共享锁(S) | 排他锁(X) |
|---|---|---|
| 共享锁(S) | 兼容 | 冲突 |
| 排他锁(X) | 冲突 | 冲突 |
3 InnoDB行锁算法:精准锁定数据的"工具集"
InnoDB通过三种行锁算法实现对"记录"和"范围"的锁定,确保在不同查询条件下的锁粒度可控,平衡并发性能与数据安全性。
3.1 Record Lock:锁定单个记录的"精准锁"
- 定义 :对索引树上的单个具体记录加锁,仅锁定目标记录本身,不影响其他记录;
- 适用场景 :通过唯一索引(如主键、唯一键) 精准定位单条记录时(如
where id=1,id为主键); - 示例 :执行
update t14 set b=10 where id=1;(id为主键),仅锁定id=1的记录。
3.2 Gap Lock:锁定索引间隙的"范围锁"
- 定义 :对索引树中两个记录之间的间隙 加锁,不包含记录本身,仅阻止其他事务在该间隙插入新记录;
- 适用场景 :通过非唯一索引 查询范围数据时(如
where a between 1 and 3,a为普通索引),避免"幻读"; - 示例 :若表中
a的值为1、2、3(普通索引),执行select * from t14 where a between 1 and 3 for update;,会锁定(负无穷,1)、(1,2)、(2,3)、(3,正无穷)四个间隙,阻止插入a=0、a=1.5等数据。
3.3 Next-Key Lock:Record Lock + Gap Lock的"组合锁"
- 定义 :InnoDB的默认行锁算法,同时锁定"记录本身"和"该记录之前的间隙",形成一个"左开右闭"的锁定范围;
- 核心目的:解决"幻读"问题(事务两次查询同一范围,结果集行数不一致);
- 示例 :表中
a的值为1、2、3(普通索引),执行select * from t14 where a=2 for update;,会锁定(1,2]范围(即a=2的记录 +(1,2)的间隙),阻止插入a=1.5,同时锁定a=2本身。
3.4 关键注意事项:索引是行锁的"前提"
InnoDB行锁的实现依赖索引:若查询条件未通过索引检索数据(如where b=1,b无索引),InnoDB会对表中所有记录加锁,等价于"表锁" ,严重降低并发性能。因此,必须为查询条件中的过滤字段建立合适的索引,这是避免行锁升级为表锁的核心要点。
4 行锁实验:通过实践验证锁机制
理论需要实践验证,下面通过一个完整实验,直观感受InnoDB行锁的作用过程。
4.1 实验环境准备
-
创建测试表 (
a为普通索引,id为主键):sqluse martin; -- 切换到目标数据库 drop table if exists t14; -- 若表存在则删除 CREATE TABLE `t14` ( `id` int NOT NULL AUTO_INCREMENT, `a` int NOT NULL, `b` int NOT NULL, PRIMARY KEY (`id`), -- 主键索引 KEY `idx_a` (`a`) -- 普通索引 ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4; -
插入测试数据:
sqlinsert into t14(a,b) values(1,1),(2,2),(3,3);
4.2 实验过程与现象
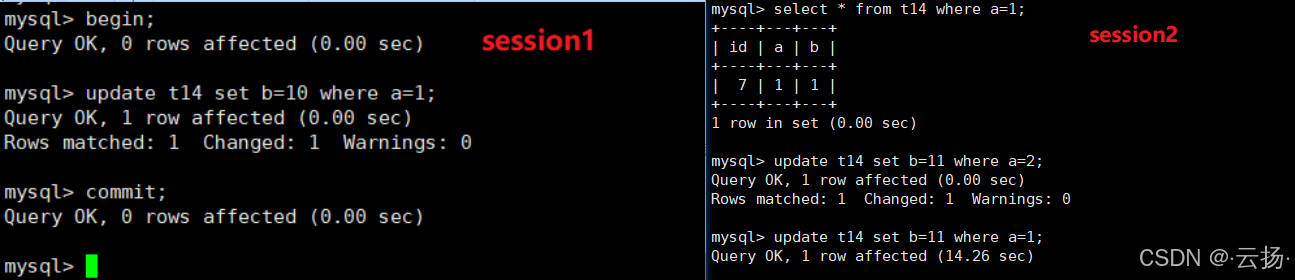
实验采用两个会话(session1、session2)模拟并发事务,操作步骤与结果如下:
| 步骤 | session1(会话1) | session2(会话2) | 现象分析 |
|---|---|---|---|
| 1 | begin;(启动事务) |
- | session1进入事务上下文,未加锁 |
| 2 | update t14 set b=10 where a=1; |
- | session1通过a索引(普通索引)定位记录,加Next-Key Lock(锁定(负无穷,1]) |
| 3 | - | select * from t14 where a=1;(查询) |
查询成功,因select默认不加锁(快照读),不与session1的X锁冲突 |
| 4 | - | update t14 set b=11 where a=2;(更新) |
更新成功,a=2不在session1的锁定范围((负无穷,1]),无锁冲突 |
| 5 | - | update t14 set b=11 where a=1;(更新) |
阻塞等待 ,a=1被session1加X锁,session2请求X锁冲突 |
| 6 | commit;(提交事务) |
- | session1释放所有锁 |
| 7 | - | 步骤5的更新自动执行成功 | 锁释放后,session2的X锁请求被允许 |
4.3 实验结论
- InnoDB行锁的锁定范围由索引类型和查询条件决定,普通索引下默认使用Next-Key Lock;
- 快照读(如默认
select)不请求锁,不会与其他事务的锁冲突; - 事务提交后才释放所有锁,符合两阶段锁原则;
- 仅锁定必要的记录和间隙,避免过度锁定导致的并发性能下降。
总结
InnoDB锁机制是MySQL并发控制的核心,掌握以下要点可帮助开发者设计更高效、更安全的事务:
- 两阶段锁:事务内"先加锁、后解锁",提交/回滚时一次性释放所有锁;
- 行锁模式:S锁支持共享读,X锁支持独占读写,根据业务场景选择合适的锁模式;
- 行锁算法:Record Lock锁单条记录,Gap Lock锁间隙,Next-Key Lock锁范围+记录,默认使用Next-Key Lock防幻读;
- 索引依赖:务必为查询条件字段建立索引,避免行锁升级为表锁。
通过理论学习与实验验证,可更深入理解InnoDB锁机制的底层逻辑,在实际开发中规避锁冲突、死锁等问题,提升数据库的并发性能与稳定性。