最近在开发过程中遇到了一个的挺有意思的验签问题。我们的项目采用了前后端签名验证机制来保证数据安全:
- 前端:请求时对 body 进行签名
- 后端:接收后对 body 进行验签
正常情况下都没啥问题,但这次比较奇怪:
- 后端接口 A 返回了一个对象,其中某个字段是 JSON 字符串(String 类型)
- 前端拿到这个对象后,会把这个json字符串原模原样的作为参数传给后端接口 B
- 然后就。。。验签失败了
我们就陷入了互相甩锅的局面:
- 后端认为:前端验签时做了特殊处理
- 前端很无辜:用的是公共库,从没改过
- 折中共识:可能是 HTTP 传输过程中对 JSON 做了转义
经过一番调试发现:
- 前端验签时,JSON 字符串字段有一次转义字符 (如
") - 后端收到的 body 中,JSON 字符串字段有二次转义字符 (如
\")
双方验签的数据不一致,自然验证失败。
临时方案:对这个字段做 Base64 编码,绕过转义问题。
但事实真的是 HTTP 传输导致的转义吗?当然不是
HTTP 请求本身不会对数据进行转义。那转义字符是从哪里来的?
问题根源
整个流程是这样的:
第一步:后端接口 A 返回数据(第一次序列化)
kotlin
// 后端返回的对象
public class Response {
private String data; // 这里存储的是 JSON 字符串
}
// 接口 A 返回数据
return new Response("{"name":"张三","age":25}");Spring Boot 在响应时会自动进行 JSON 序列化,由于 data 字段本身是字符串,会对其中的特殊字符进行转义:
json
{
"data": "{"name":"张三","age":25}"
}第二步:前端验签(基于一次转义的数据)
前端拿到响应后,对整个对象进行验签:
javascript
// 前端收到的数据
const response = {
data: "{"name":"张三","age":25}" // 带有一次转义
};
// 对这个对象做验签
const signature = sign(JSON.stringify(response));此时验签的原始数据包含一次转义字符。
第三步:前端请求接口 B(第二次序列化)
前端将这个对象作为 body 请求接口 B:
arduino
// 将对象发送给接口 B
axios.post('/api/b', response);浏览器或 HTTP 库会再次对 body 进行 JSON 序列化,JSON 字符串又会被转义一次:
swift
{
"data": "{\"name\":\"张三\",\"age\":25}"
}注意:" 变成了 \"(二次转义)
第四步:后端接口 B 验签(基于二次转义的数据)
后端收到请求后,拿到的是经过二次转义的数据进行验签:
swift
// 后端收到的 body(二次转义)
String body = "{\"name\":\"张三\",\"age\":25}";
// 验签失败!因为转义字符数量不一致为什么验签会失败?
- 前端验签 :基于一次转义的数据
{"name":...} - 后端验签 :基于二次转义的数据
{\"name\":...}
两边计算签名的原始数据不一致,自然就验签失败了
最快的方案
不要在对象中嵌套 JSON 字符串,直接返回 JSON 对象
kotlin
// 错误做法
public class Response {
private String data; // JSON 字符串
}
// 正确做法
public class Response {
private UserInfo data; // JSON 对象
}
public class UserInfo {
private String name;
private Integer age;
}这样 Spring Boot 只会进行一次序列化,不会产生转义字符,前后端处理的数据格式完全一致。
知己知彼
既然找到了问题根源,正好就深入源码看看 Jackson 是如何对字符串进行序列化的。Spring Boot 默认使用 Jackson 作为 JSON 序列化框架。
序列化调用链路
1. BeanSerializerBase - 对象序列化入口
序列化一般会调用 BeanSerializer,其核心实现在 BeanSerializerBase 中:
ini
protected void serializeFields(Object bean, JsonGenerator gen, SerializerProvider provider)
throws IOException {
final BeanPropertyWriter[] props; // 对象的所有字段属性
if (_filteredProps != null && provider.getActiveView() != null) {
props = _filteredProps;
} else {
props = _props;
}
int i = 0;
try {
// 遍历所有字段进行序列化
for (final int len = props.length; i < len; ++i) {
BeanPropertyWriter prop = props[i];
if (prop != null) {
prop.serializeAsField(bean, gen, provider); // 关键调用
}
}
// ... 省略其他代码
}
}2. BeanPropertyWriter - 字段序列化处理
每个字段会调用 serializeAsField 方法,根据字段类型选择对应的序列化器:
ini
public void serializeAsField(Object bean, JsonGenerator gen, SerializerProvider prov)
throws Exception {
// 获取字段值
final Object value = (_accessorMethod == null)
? _field.get(bean)
: _accessorMethod.invoke(bean, (Object[]) null);
// 处理 null 值
if (value == null) {
if (_nullSerializer != null) {
gen.writeFieldName(_name);
_nullSerializer.serialize(null, gen, prov);
}
return;
}
// 获取序列化器(关键:根据字段类型选择不同的序列化器)
JsonSerializer<Object> ser = _serializer;
if (ser == null) {
Class<?> cls = value.getClass();
PropertySerializerMap m = _dynamicSerializers;
ser = m.serializerFor(cls); // String 类型会返回 StringSerializer
if (ser == null) {
ser = _findAndAddDynamic(m, cls, prov);
}
}
// 写入字段名和值
gen.writeFieldName(_name);
ser.serialize(value, gen, prov); // 调用具体的序列化器
}核心要点:
- 如果字段是对象,会递归调用
BeanSerializer - 如果字段是字符串,会调用
StringSerializer
3. StringSerializer
当字段类型是 String 时,使用 StringSerializer 进行序列化:
java
@Override
public void serialize(Object value, JsonGenerator gen, SerializerProvider provider)
throws IOException {
gen.writeString((String) value); // 调用 JsonGenerator 写入字符串
}4. UTF8JsonGenerator
由于默认使用 UTF-8 编码,最终会调用 UTF8JsonGenerator.writeString 方法:
kotlin
public void writeString(String text) throws IOException {
this._verifyValueWrite("write a string");
if (text == null) {
this._writeNull();
} else {
int len = text.length();
if (len > this._outputMaxContiguous) {
this._writeStringSegments(text, true);
} else {
if (this._outputTail + len >= this._outputEnd) {
this._flushBuffer();
}
// 添加开始引号
this._outputBuffer[this._outputTail++] = this._quoteChar;
// 写入字符串内容(这里会对特殊字符进行转义!)
this._writeStringSegment((String)text, 0, len);
if (this._outputTail >= this._outputEnd) {
this._flushBuffer();
}
// 添加结束引号
this._outputBuffer[this._outputTail++] = this._quoteChar;
}
}
}关键点 :_writeStringSegment 方法会对字符串中的特殊字符(如 "、``、换行符等)进行转义处理。
转义示例对比
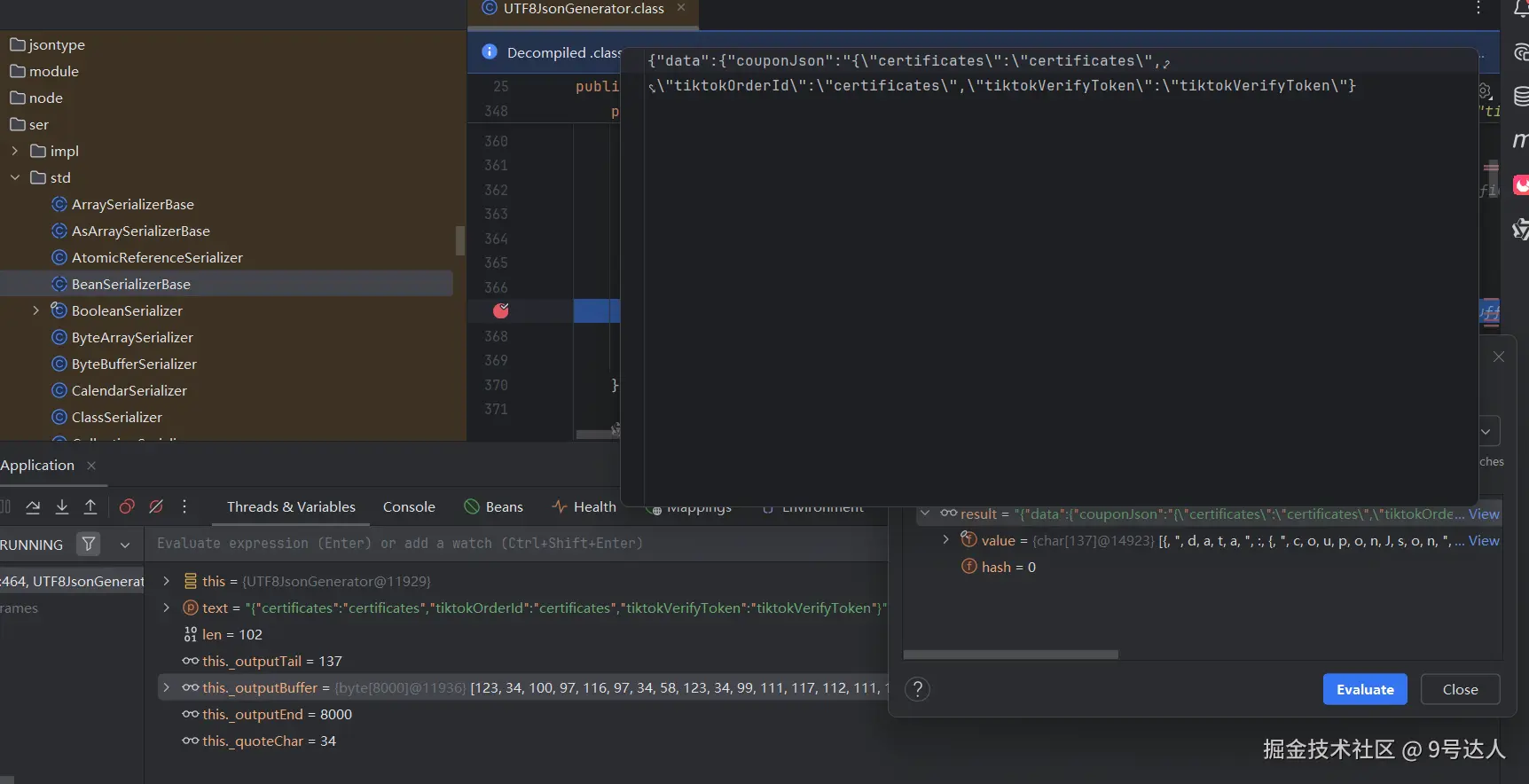 序列化之后就多了一层转义符号
序列化之后就多了一层转义符号
主要的调用链路
scss
对象序列化
↓
BeanSerializerBase.serializeFields() // 遍历对象字段
↓
BeanPropertyWriter.serializeAsField() // 处理单个字段
↓
StringSerializer.serialize() // String 类型走这里
↓
UTF8JsonGenerator.writeString() // 执行转义
↓
_writeStringSegment() // 转义特殊字符(" → ")理解了这个调用链路,就能明白为什么 JSON 字符串在序列化时会产生转义字符,以及为什么多次序列化会导致多层转义。
总结
- 尽量避免在对象中嵌套 JSON 字符串,应该使用强类型对象,避免多次序列化带来的转义问题
- HTTP 传输不会篡改数据,问题往往出在序列化/反序列化环节
- 理解序列化的本质:每序列化一次,JSON 字符串就会多一层转义
- 遇到验签问题,优先检查双方处理数据时经历了几次序列化
验签虽然好,但有时候也挺麻烦的。所以理解数据在前后端之间的流转过程和序列化时机,可以更好避免这样的验签问题。