目录
[2.1 性能评估](#2.1 性能评估)
[2.2 增强型MLRM的显著性分数分析](#2.2 增强型MLRM的显著性分数分析)
[2.3 超参数分析](#2.3 超参数分析)
[2.4 效率分析](#2.4 效率分析)
[2.5 在线服务与实验](#2.5 在线服务与实验)
上一篇论文:推荐大模型系列-NoteLLM-2: Multimodal Large Representation Models for Recommendation(一)
一、方法论
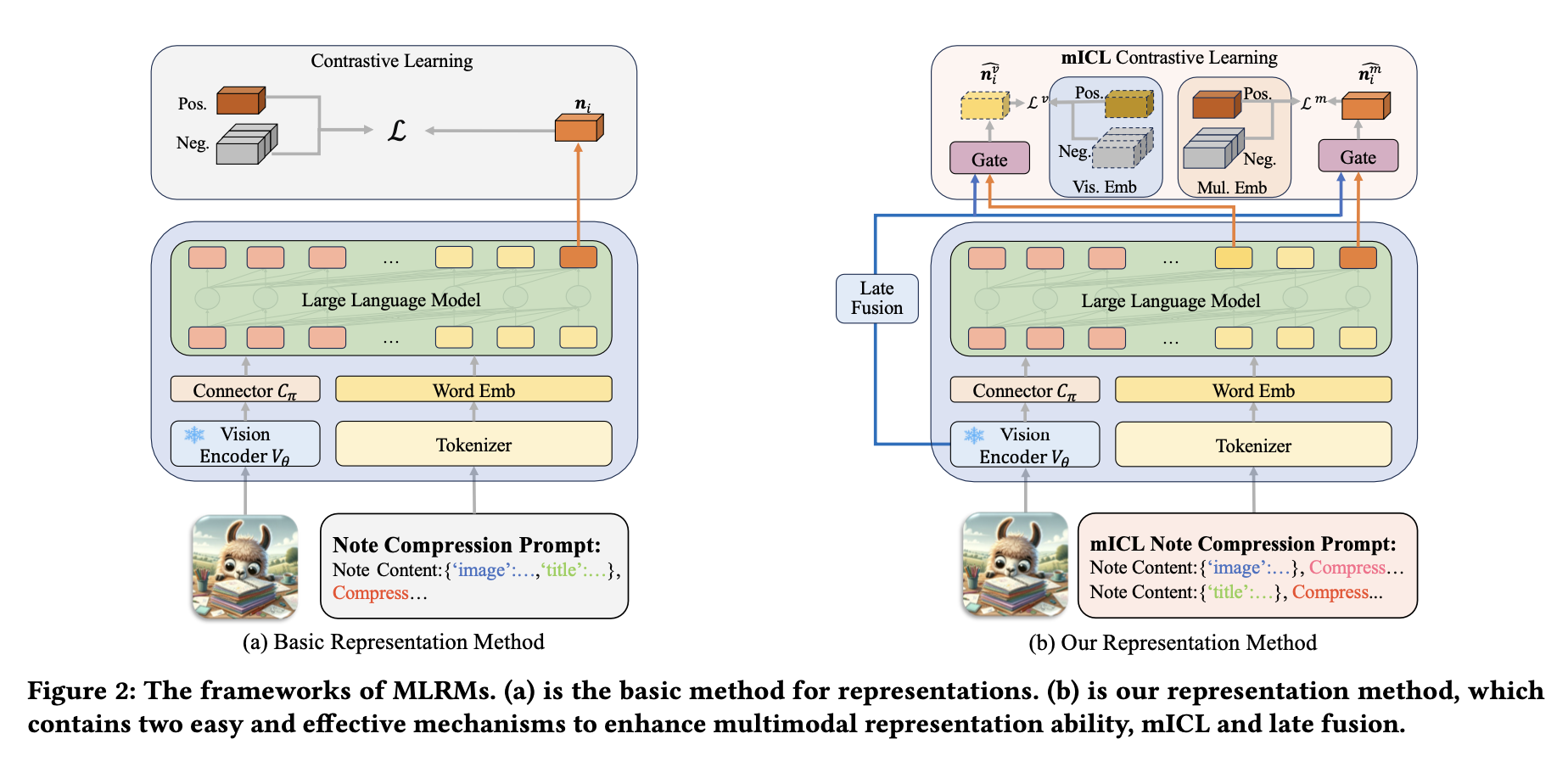
研究表明,未经预训练端到端训练的多模态大语言模型(MLRMs)效果欠佳,主要原因是大型语言模型(LLM)处理视觉信息后未充分利用其价值。因此,需设计更聚焦视觉信号的机制。
提出新型训练框架 NoteLLM-2,包含两种不同视角的改进方法:
- 基于提示的改进(mICL):通过调整提示模板,改变模型对视觉信息的注意力分布。
- 基于架构的改进:结合延迟融合与视觉提示,推迟视觉信息融合时机,增强视觉信息流对最终表征的影响。改进框架如图2(b)所示。
具体实现上,给定笔记 ( n_i ),mICL 不再将多模态信息压缩为单一词汇,而是拆分为单模态笔记,并采用类似上下文学习(ICL)的方式聚合多模态信息。笔记压缩提示模板重构如下:

模板说明
在模板中,<IMG_EMB>是一个特殊标记。通过大语言模型(LLMs)处理多模态嵌入后,选择相关的隐藏状态来表示笔记内容。
视觉笔记表示
采用<IMG_EMB>标记前一个隐藏状态作为视觉笔记表示,记为𝒏𝑖𝑣。由于因果注意力机制,𝒏𝑖𝑣仅包含笔记图像信息。
多模态笔记表示
将最后一个隐藏状态作为多模态笔记表示,记为𝒏𝑚𝑖,该表示融合了视觉和文本信息。此方法将原始单一嵌入分解为两个模态的笔记嵌入。多模态笔记表示𝒏𝑚𝑖通过类似ICL(In-Context Learning)的方式聚合有用的视觉信息。
后期融合
采用原始视觉嵌入增强笔记嵌入。此举避免了因大语言模型空间特性导致的文本偏差,同时保留了更多原始视觉信息。具体步骤如下:
- 通过视觉编码器𝑉𝜃提取图像特征,例如CLIP ViT-B中的CLS标记,该特征包含完整图像信息。
- 使用线性层将这些特征转换至大语言模型的维度,记为𝒗 ∈ ℝℎ𝑡。
- 采用门控机制将原始视觉信息融合到笔记嵌入中。
关键点
- 视觉与文本分离:通过𝒏𝑖𝑣和𝒏𝑚𝑖实现模态解耦。
- 特征增强:后期融合通过门控机制平衡视觉与文本信息。
- 维度对齐:线性层确保视觉特征与LLMs的隐藏层维度匹配。
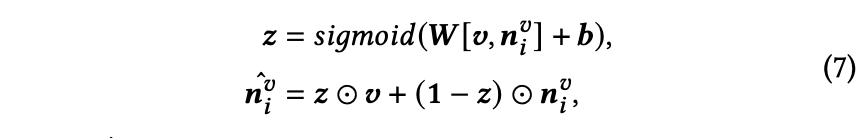
其中, 表示融合后的视觉笔记嵌入。·,· 表示拼接操作,𝑾 和 𝒃 是可学习参数。⊙ 表示逐元素乘积。类似地,通过相同的门控操作可以得到融合后的多模态笔记嵌入
。
随后,采用融合后的笔记嵌入进行对比学习,如下所示:
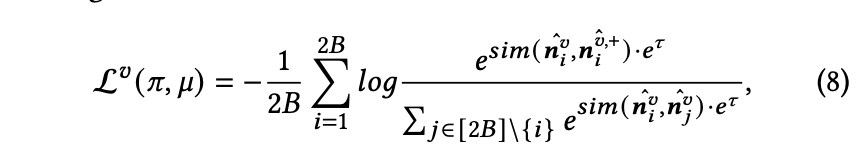
L𝑣 (𝜋, 𝜇) 表示视觉笔记嵌入的损失。类似地,可以得出 L𝑚 (𝜋, 𝜇),即多模态笔记嵌入的损失。最终损失的计算方式如下:
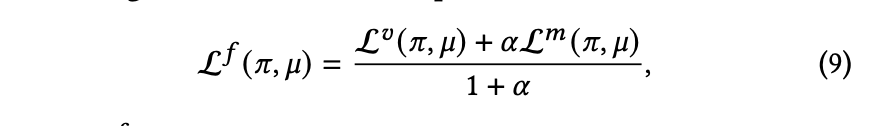
最终损失函数表示为 L𝑓 (𝜋, 𝜇),其中 𝛼 是一个超参数。在评估阶段,使用包含多模态信息的音符嵌入 作为输入。
二、实验
2.1 性能评估
基于三种多模态语言检索模型(ML-RM),通过以下基线实验验证NoteLLM-2的有效性:
- 基础方法:ML-RM的朴素表示方法。
- mICL:在基础方法上增加mICL机制。
- 晚融合:将晚融合机制集成至基础方法。
- NoteLLM-2:同时结合mICL与晚融合。
- 仅晚融合:仅通过晚融合整合图像与文本信息,不向大语言模型(LLM)输入图像嵌入。
- Omni-Retrieval58:采用跨模态对比学习对齐多种嵌入(仅图像、仅文本、多模态)。
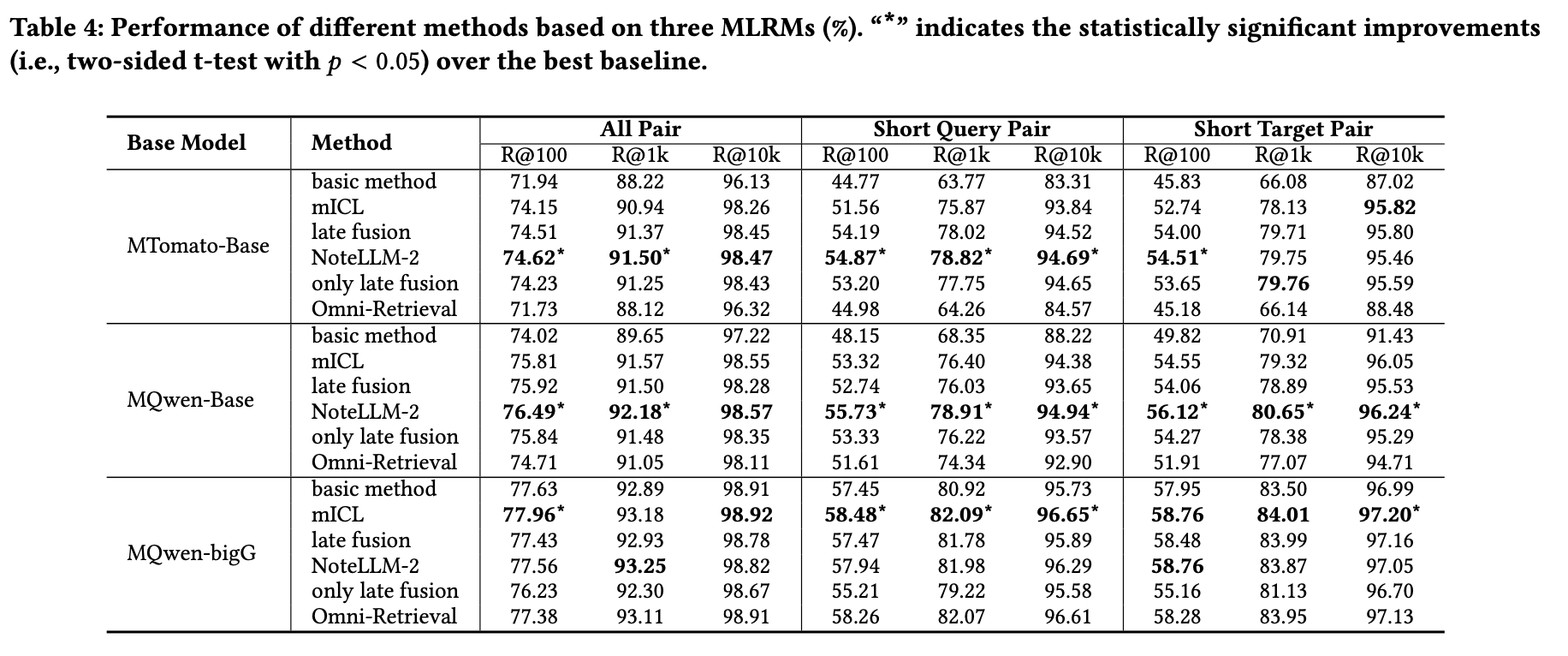
实验结果如表4所示。NoteLLM-2显著提升了视觉编码器较小的模型(MTomato-Base和MQwen-Base)的整体性能,同时对MQwen-bigG的短文本配对任务表现亦有提升。
mICL对所有模型均有增强效果,而晚融合对小视觉编码器模型更有效。当视觉编码器较强时(如MQwen-bigG+晚融合),晚融合通过侧重图像信息提升短文本配对性能,但过度依赖图像可能损害文本理解能力,导致整体性能下降并削弱mICL的提示词效果。未来将设计更均衡的晚融合机制。
仅晚融合虽简单高效,但在视觉编码器较强时可能因与LLM交互不足导致性能损失。Omni-Retrieval对视觉信息的增强效果弱于NoteLLM-2,因其未考虑LLM的独特机制,且其他跨模态损失可能干扰多模态嵌入对齐。
MQwen-bigG+NoteLLM-2表现不及Qwen-VL-Chat(尤其在短文本配对任务),主因是两者视觉标记长度差异(MQwen-bigG为16,Qwen-VL-Chat为256)。
2.2 增强型MLRM的显著性分数分析
为深入理解NoteLLM-2对多模态语言表示模型(MLRM)的影响,对比了原始微调方法与增强微调方法的显著性分数差异。原始方法的显著性分数为𝑆𝑣(视觉)、𝑆𝑡(文本)和ˆ 𝑆𝑜(其他模态),而增强方法的分数为𝑆^𝑣、𝑆ˆ𝑡和𝑆ˆ𝑜。其中,视觉笔记压缩词被纳入视觉嵌入𝐸𝑣的一部分。
实验结果与发现
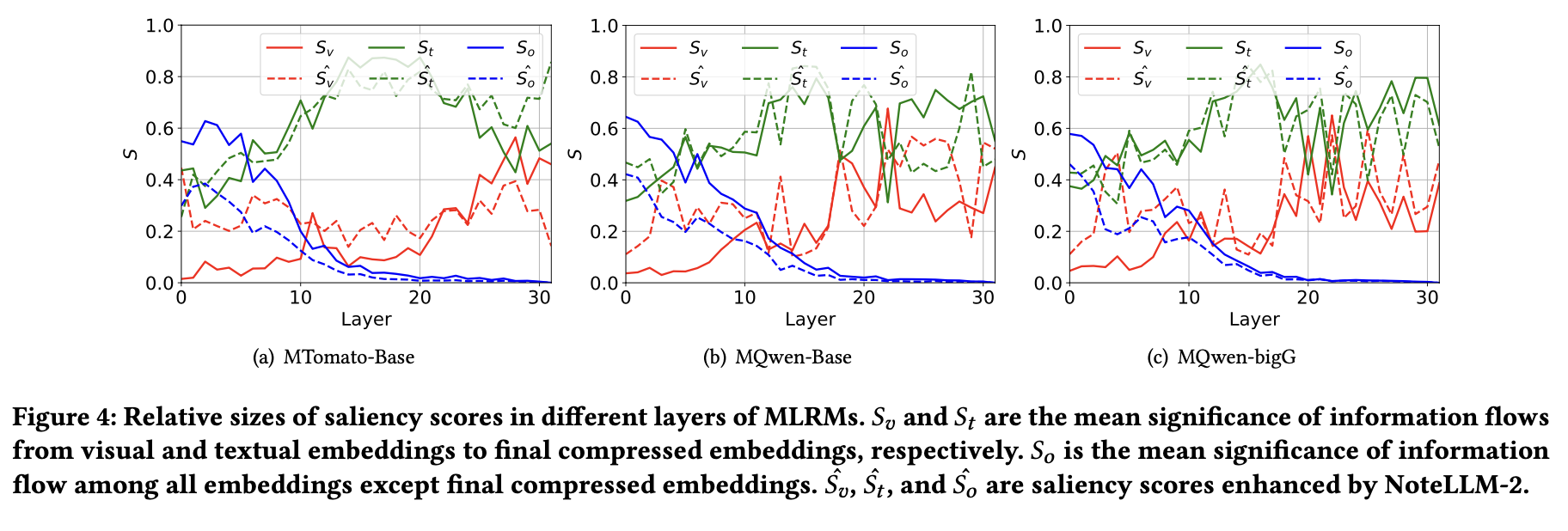
图4显示,所有增强型MLRM的表示均放大了对图像的直接关注(𝑆𝑣),同时降低了浅层中对𝑆𝑜的依赖。文本模态的显著性分数(𝑆𝑡)基本保持不变。𝑆𝑣与𝑆𝑜的平衡表明,引入图像带来的信息流增益不仅凸显了相关多模态嵌入,还能通过最终压缩嵌入直接聚合。这一特性有助于最终嵌入捕获图像中与文本完全不同的关键模式。
机制解释
该结果归因于mICL采用统一的压缩提示(compressed prompt)处理多模态输入。通过识别图像中的相似压缩模式,mICL能像ICL48一样,强化多模态表示对图像的聚焦能力。
2.3 超参数分析
本节使用MTomato-Base+NoteLLM-2进行超参数分析实验。
视觉标记长度的影响
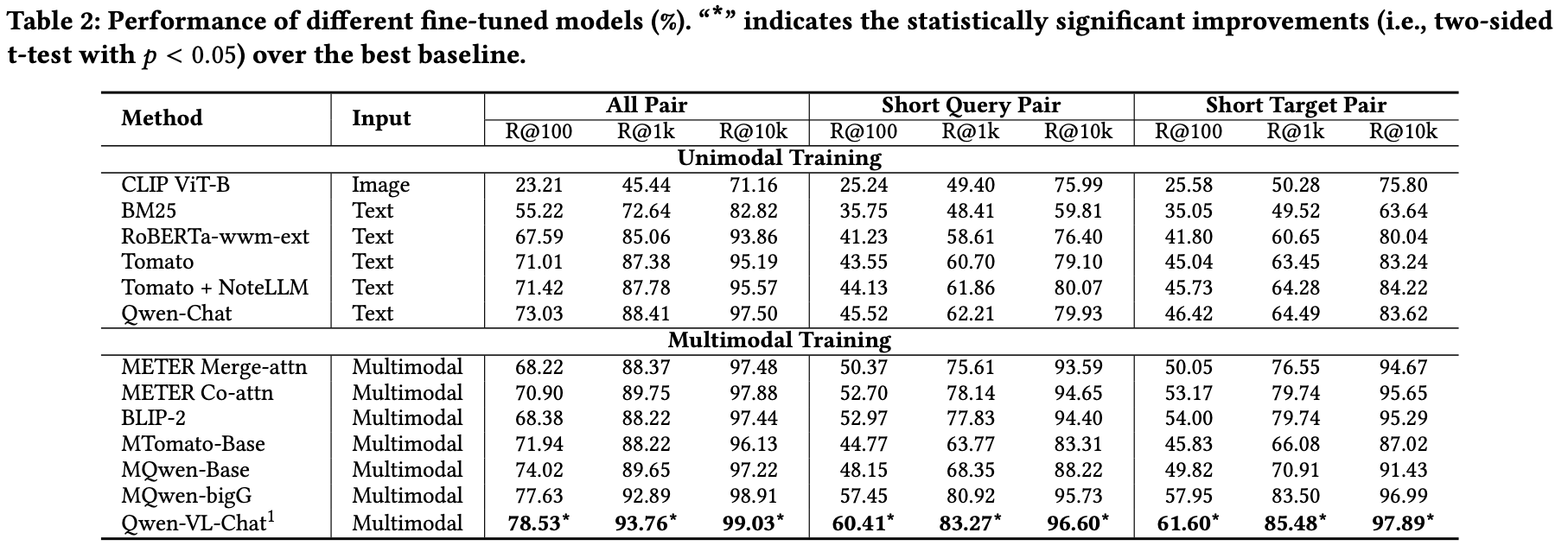
通过调整视觉标记长度探究其影响,结果如表5所示。将长度从16降至8会导致性能下降,但推理效率更高。视觉标记长度在性能与推理速度之间存在权衡。此外,表2数据显示,**即使仅使用8个视觉标记,MTomato-Base+NoteLLM-2的性能仍优于使用16个视觉标记的MTomato-Base。**这表明本方法通过改进注意力模式与融合机制增强了视觉注意力,而非单纯扩展图像标记空间。
文本与视觉损失比例的影响
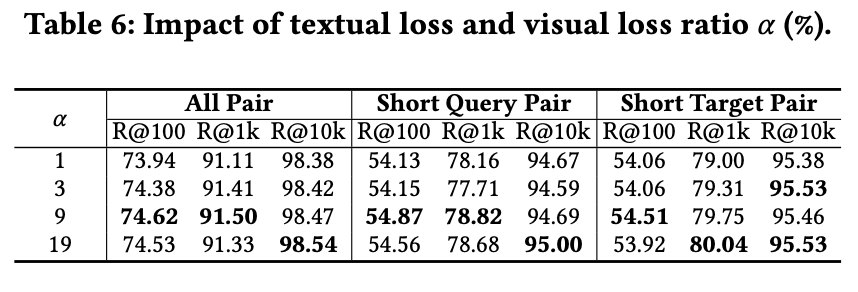
调整文本与视觉损失比例𝛼的结果如表6所示。当比例较小时,性能略差;但随着比例增加,本方法对文本与视觉损失比例的变化表现出较强的鲁棒性。
2.4 效率分析
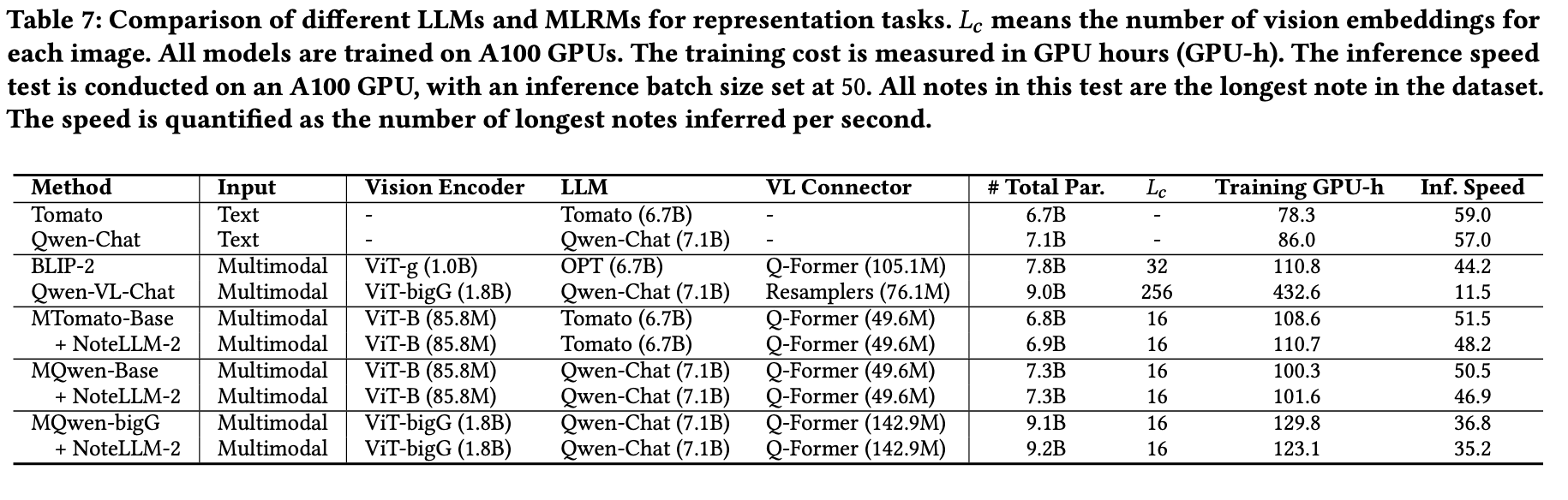
在表7中对比了不同大语言模型的参数量、训练成本和推理速度。当前最先进的多模态大模型(如Qwen-VL-Chat)专为多模态理解与问答设计,其适配训练成本高且推理速度慢,难以适应快速推荐的场景。而面向表征任务设计的MLRMs在训练和推理上均更高效。
由于NoteLLM-2采用了更长的提示模板,其集成通常会轻微降低训练和推理速度,但能带来更好的性能表现。
在线服务与实验
图5展示了在线服务流程,分为离线与在线两个阶段。离线阶段中,经NoteLLM-2训练的多模态关系模型(MLRM)会实时生成用户新发布笔记的多模态嵌入向量,这些向量存入嵌入表以供复用。同时,基于物品相似度的近似最近邻(I2I ANN)索引会动态更新新笔记的嵌入向量。
在线阶段,系统根据用户交互历史笔记从现有嵌入表中选取历史嵌入向量,通过多次ANN搜索在I2I索引中检索相关笔记。召回的前k个相关笔记会推送至下一推荐阶段。目前该模型已替代原有I2I召回流程,成为平台核心召回通道之一。
平台通过分配10%流量进行为期一周的A/B测试。在线基线方法采用相同LLM进行I2I训练(基于NoteLLM61的训练方式),而经NoteLLM-2训练的MLRM将首千次曝光点击量提升6.35%,笔记发布后24小时内互动量提升8.08%。此外,发布24小时内获得首次互动且曝光达100次的笔记数量增长9.83%。
2.5 在线服务与实验
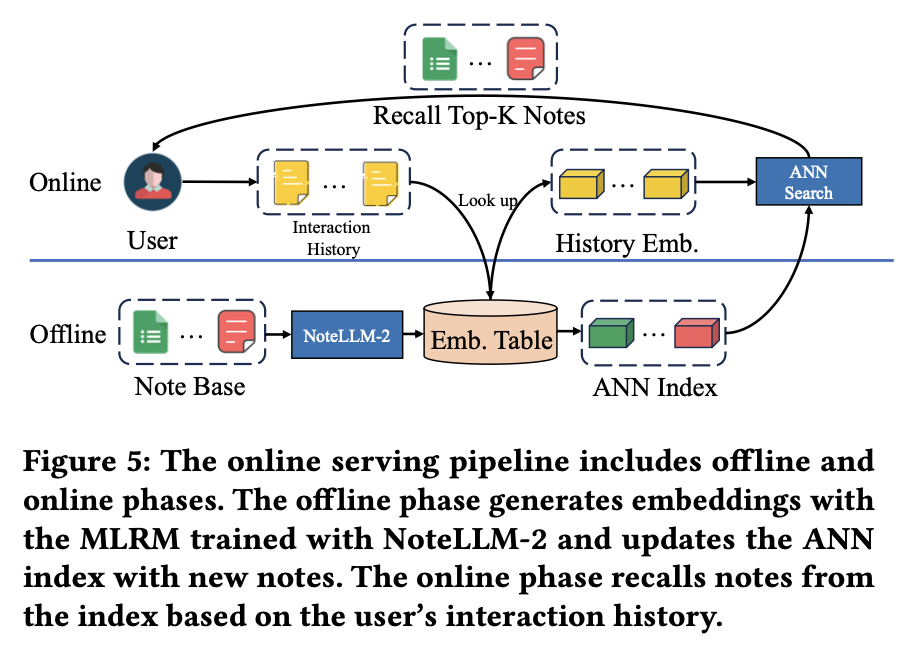
图5展示了在线服务流程,分为离线与在线两个阶段。离线阶段中,经NoteLLM-2训练的多模态关系模型(MLRM)会实时生成用户新发布笔记的多模态嵌入向量,这些向量存入嵌入表以供复用。同时,基于物品相似度的近似最近邻(I2I ANN)索引会动态更新新笔记的嵌入向量。
在线阶段,系统根据用户交互历史笔记从现有嵌入表中选取历史嵌入向量,通过多次ANN搜索在I2I索引中检索相关笔记。召回的前k个相关笔记会推送至下一推荐阶段。目前该模型已替代原有I2I召回流程,成为平台核心召回通道之一。
平台通过分配10%流量进行为期一周的A/B测试。在线基线方法采用相同LLM进行I2I训练(基于NoteLLM61的训练方式),而经NoteLLM-2训练的MLRM将首千次曝光点击量提升6.35%,笔记发布后24小时内互动量提升8.08%。此外,发布24小时内获得首次互动且曝光达100次的笔记数量增长9.83%。
三、相关工作
多模态表征
随着预训练技术的发展,大量研究利用网络规模的图文数据预训练模型,以实现对多模态信息的基础理解。现有预训练技术主要分为两类:一类采用生成式预训练目标,如掩码语言/图像建模或图像描述生成;另一类采用对比式预训练目标,如对比学习和图文匹配任务。这些模型在下游任务中展现出强大的零样本能力,但其文本理解能力(尤其在大型语言模型时代)仍显不足。本研究探索利用大型语言模型的强大理解能力来增强多模态表征。
大型语言模型
大型语言模型因其卓越的文本理解与生成能力受到广泛关注,催生了大量基于此类模型的文本应用。为处理多模态信息,大型语言模型被扩展为多模态大语言模型。多数多模态大语言模型通过专用模态编码器捕获非文本信息,将其映射到文本空间后由语言模型处理,从而实现多模态输入下的答案生成。现有研究主要关注语言模型的生成能力,少数探索了其文本表征能力,但尚未涉及基于语言模型的多模态表征。因此,本研究在推荐场景中探索语言模型增强的多模态表征能力。
多模态物品到物品推荐
物品到物品推荐基于物品相似性从海量池中生成排序列表,是推荐系统召回阶段的重要技术。此类推荐通常通过预构建的索引,采用近似k近邻方法检索相关物品。部分研究探索了基于多模态内容的物品到物品推荐,但这些工作采用小规模预训练视觉-语言模型作为主干,存在显著的扩展潜力。本研究尝试在物品到物品推荐中利用大型语言模型强化多模态表征。
四、结论与未来工作
本文探讨了在图像到图像(I2I)推荐场景下,利用大语言模型(LLMs)提升多模态表征任务中的文本理解能力。研究设计了一种端到端微调方法,能够灵活集成现有的大语言模型与视觉编码器,减少对需昂贵多模态预训练的开源多模态大模型(MLLMs)的依赖。
为避免端到端微调中忽视视觉信息的问题,提出了NoteLLM-2框架,包含多模态上下文学习(mICL)和延迟融合策略。大量实验验证了该方法的有效性。未来工作将扩展至更复杂的模态(如视频)以及更广泛的场景与推荐任务。
本篇论文理论和实验部分分享就到这里了,下一篇会继续分享附录,实验详细细节~
下一篇传送门(尽快更新ing):推荐大模型系列-NoteLLM-2: Multimodal Large Representation Models for Recommendation(三)