引言
在Python编程中,字符串是最基础也是最常用的数据类型之一。1然而,许多开发者对于字符串的不可变性(immutability)特性理解不足,这导致了各种难以察觉的错误和性能问题。字符串的不可变性看似简单,实则影响着Python程序的方方面面------从内存管理到性能优化,从API设计到并发安全。本文将深入探讨字符串不可变性的本质、它带来的优势与挑战,以及如何避免由此引发的常见错误,帮助读者编写更高效、更安全的Python代码。2
字符串不可变性的本质
什么是字符串不可变性?
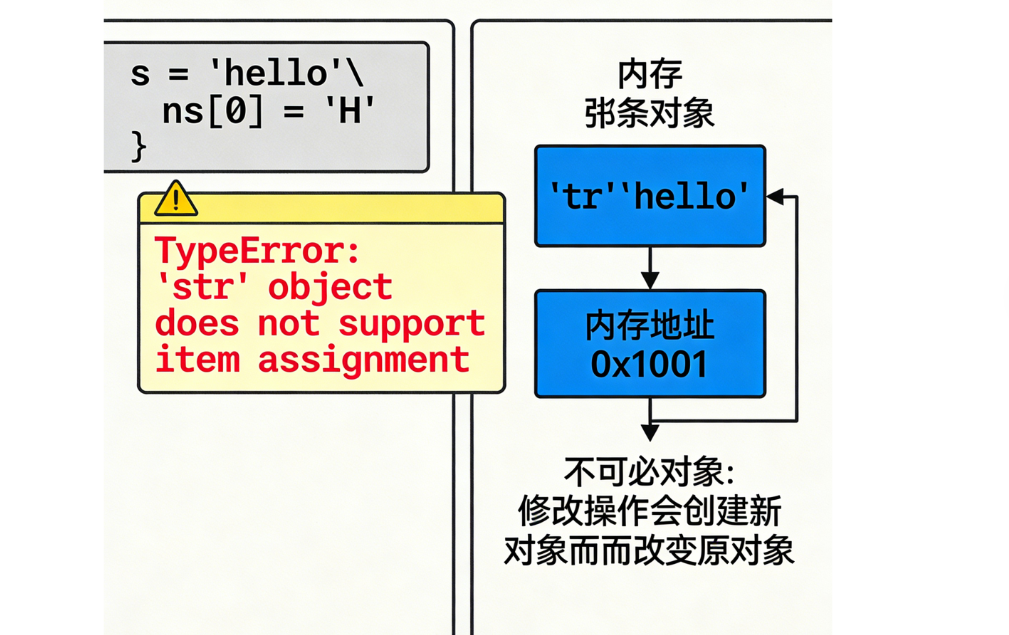
在Python中,字符串是不可变对象(immutable object),这意味着一旦创建,字符串的内容就不能被修改。任何看似"修改"字符串的操作,实际上都是创建了一个新的字符串对象。
python
# 演示字符串的不可变性
original = "Hello, World!"
print(f"原始字符串: {original}")
print(f"原始字符串ID: {id(original)}")
# 尝试"修改"字符串
modified = original.replace("Hello", "Hi")
print(f"\n修改后字符串: {modified}")
print(f"修改后字符串ID: {id(modified)}")
print(f"两个字符串是同一个对象吗? {original is modified}")
# 另一个例子:拼接字符串
concatenated = original + " How are you?"
print(f"\n拼接后字符串: {concatenated}")
print(f"拼接后字符串ID: {id(concatenated)}")
print(f"原始字符串被修改了吗? {original}")
# 直接索引赋值会报错
try:
original[0] = 'h' # 这会引发TypeError
except TypeError as e:
print(f"\n尝试修改字符串字符时出错: {e}")Python字符串的内存表示
理解Python如何在内存中表示字符串,有助于理解其不可变性的设计原理:
python
import sys
def examine_string_memory():
"""检查字符串的内存表示"""
# 创建字符串
str1 = "Hello"
str2 = "Hello"
str3 = "Hello!"
print("=== 字符串内存分析 ===")
# 显示字符串对象信息
print(f"str1: '{str1}', id: {id(str1)}, size: {sys.getsizeof(str1)} bytes")
print(f"str2: '{str2}', id: {id(str2)}, size: {sys.getsizeof(str2)} bytes")
print(f"str3: '{str3}', id: {id(str3)}, size: {sys.getsizeof(str3)} bytes")
# Python的字符串驻留(interning)
print(f"\n字符串驻留现象:")
print(f"str1 is str2: {str1 is str2}") # 短字符串可能被驻留
# 长字符串通常不会被驻留
long_str1 = "这是一个较长的字符串" * 5
long_str2 = "这是一个较长的字符串" * 5
print(f"long_str1 is long_str2: {long_str1 is long_str2}")
# 显式驻留字符串
import sys
a = sys.intern("special_string")
b = sys.intern("special_string")
print(f"\n显式驻留后: a is b = {a is b}")
# 检查字符编码
print(f"\n字符串编码:")
ascii_str = "Hello"
unicode_str = "你好,世界"
print(f"ASCII字符串 '{ascii_str}' 长度: {len(ascii_str)}, 字节数: {len(ascii_str.encode('utf-8'))}")
print(f"Unicode字符串 '{unicode_str}' 长度: {len(unicode_str)}, 字节数: {len(unicode_str.encode('utf-8'))}")
return str1, str2, str3
str1, str2, str3 = examine_string_memory()不可变性的设计哲学
Python选择将字符串设计为不可变类型,主要基于以下几个原因:
python
def demonstrate_immutability_benefits():
"""演示字符串不可变性的优势"""
print("=== 字符串不可变性的优势 ===")
# 1. 哈希能力:不可变对象可以作为字典键
print("\n1. 可作为字典键:")
user_data = {
"Alice": {"age": 30, "city": "New York"},
"Bob": {"age": 25, "city": "London"}
}
# 尝试使用可变对象作为键(会失败)
try:
mutable_key = ["list_key"]
bad_dict = {mutable_key: "value"}
except TypeError as e:
print(f" 列表作为字典键时出错: {e}")
print(f" 字符串作为字典键正常: {user_data['Alice']}")
# 2. 线程安全:不可变对象可以在线程间安全共享
print("\n2. 线程安全:")
import threading
shared_string = "Initial Value"
def modify_string():
# 线程中"修改"字符串实际上是创建新对象
global shared_string
new_string = shared_string + " modified by thread"
# 注意:这里修改的是局部变量,不是真的修改共享字符串
return new_string
threads = []
results = []
for i in range(3):
t = threading.Thread(target=lambda: results.append(modify_string()))
threads.append(t)
t.start()
for t in threads:
t.join()
print(f" 原始字符串: {shared_string}")
print(f" 线程结果: {results}")
# 3. 缓存和重用:字符串驻留优化
print("\n3. 缓存优化(字符串驻留):")
# 自动驻留的字符串
a = "hello"
b = "hello"
print(f" a = 'hello', b = 'hello'")
print(f" a is b: {a is b}")
# 表达式结果通常不会被驻留
c = "hel"
d = "lo"
e = c + d # 动态创建的字符串
print(f" e = c + d = '{e}'")
print(f" a is e: {a is e}") # 通常为False
# 4. 简化代码:不需要担心字符串被意外修改
print("\n4. 简化API设计:")
def process_text(text):
"""处理文本的函数,不需要担心text被修改"""
# 因为字符串不可变,我们可以安全地使用它
processed = text.upper().replace(" ", "_")
# 原始text不会被改变
return processed
original = "Hello World"
result = process_text(original)
print(f" 原始: '{original}'")
print(f" 结果: '{result}'")
print(f" 原始未被修改: '{original}'")
return user_data, results, original, result
user_data, thread_results, original_text, processed_text = demonstrate_immutability_benefits()由不可变性引发的常见错误
错误1:误以为字符串操作是原地修改
python
def common_error_1():
"""常见错误1:误以为字符串操作是原地修改"""
print("=== 错误1:误以为字符串操作是原地修改 ===")
# 错误的做法
print("\n错误的做法:")
text = "Hello, World!"
print(f"原始文本: {text}")
# 开发者可能错误地认为这些操作会修改原字符串
text.upper() # 这不会修改text!
text.replace("World", "Python") # 这也不会修改text!
print(f"执行操作后: {text}") # 仍然是"Hello, World!"
print("问题:开发者忘记了字符串方法返回新字符串")
# 正确的做法
print("\n正确的做法:")
text = "Hello, World!"
print(f"原始文本: {text}")
# 需要接收返回值
text = text.upper()
text = text.replace("WORLD", "Python")
print(f"执行操作后: {text}")
# 或者使用链式调用
text = "Hello, World!"
result = text.upper().replace("WORLD", "Python")
print(f"链式调用结果: {result}")
return text, result
original, corrected = common_error_1()错误2:在循环中频繁拼接字符串
python
import time
import sys
def common_error_2():
"""常见错误2:在循环中频繁拼接字符串"""
print("=== 错误2:在循环中频繁拼接字符串 ===")
# 性能测试:错误的拼接方式
print("\n1. 使用 + 操作符在循环中拼接(错误方式):")
start_time = time.perf_counter()
result = ""
for i in range(10000):
result += str(i) # 每次循环都创建新字符串!
end_time = time.perf_counter()
print(f" 拼接10000次耗时: {(end_time - start_time)*1000:.2f}ms")
print(f" 结果长度: {len(result)}")
print(f" 内存使用峰值: 较高(每次循环都分配新内存)")
# 性能测试:正确的拼接方式
print("\n2. 使用列表和join方法(正确方式):")
start_time = time.perf_counter()
parts = []
for i in range(10000):
parts.append(str(i))
result = "".join(parts)
end_time = time.perf_counter()
print(f" 拼接10000次耗时: {(end_time - start_time)*1000:.2f}ms")
print(f" 结果长度: {len(result)}")
print(f" 内存使用: 更高效(只分配一次内存)")
# 性能测试:使用生成器表达式
print("\n3. 使用生成器表达式和join(更高效):")
start_time = time.perf_counter()
result = "".join(str(i) for i in range(10000))
end_time = time.perf_counter()
print(f" 拼接10000次耗时: {(end_time - start_time)*1000:.2f}ms")
print(f" 结果长度: {len(result)}")
# 可视化内存分配差异
print("\n4. 内存分配可视化:")
def demonstrate_memory_allocation():
"""演示不同拼接方式的内存分配"""
# 错误方式的内存分配模式
print(" 错误方式 (+= 在循环中):")
print(" 循环1: 分配字符串 '0'")
print(" 循环2: 分配字符串 '01' (复制'0',添加'1')")
print(" 循环3: 分配字符串 '012' (复制'01',添加'2')")
print(" ... 每次循环都复制整个字符串!")
print(" 时间复杂度: O(n²)")
# 正确方式的内存分配模式
print("\n 正确方式 (列表+join):")
print(" 循环1-10000: 分配10000个小字符串")
print(" join操作: 分配一个大字符串,一次复制所有内容")
print(" 时间复杂度: O(n)")
demonstrate_memory_allocation()
# 实际场景示例
print("\n5. 实际场景示例:")
# 构建SQL查询的错误方式
def build_query_bad(table, columns, conditions):
"""构建SQL查询的错误方式"""
query = "SELECT "
# 错误:循环中使用 +=
for i, col in enumerate(columns):
if i > 0:
query += ", "
query += col
query += " FROM " + table
if conditions:
query += " WHERE "
for i, (key, value) in enumerate(conditions.items()):
if i > 0:
query += " AND "
query += f"{key} = '{value}'"
return query
# 构建SQL查询的正确方式
def build_query_good(table, columns, conditions):
"""构建SQL查询的正确方式"""
# 使用列表收集各部分
query_parts = ["SELECT "]
# 列部分
query_parts.append(", ".join(columns))
query_parts.append(" FROM ")
query_parts.append(table)
# 条件部分
if conditions:
query_parts.append(" WHERE ")
condition_strs = []
for key, value in conditions.items():
condition_strs.append(f"{key} = '{value}'")
query_parts.append(" AND ".join(condition_strs))
# 一次性拼接
return "".join(query_parts)
# 测试
table = "users"
columns = ["id", "name", "email"]
conditions = {"status": "active", "age": ">18"}
print(f" 表: {table}")
print(f" 列: {columns}")
print(f" 条件: {conditions}")
print(f" 错误方式构建的查询: {build_query_bad(table, columns, conditions)[:50]}...")
print(f" 正确方式构建的查询: {build_query_good(table, columns, conditions)}")
return result
loop_result = common_error_2()错误3:忽略字符串方法的返回值
python
def common_error_3():
"""常见错误3:忽略字符串方法的返回值"""
print("=== 错误3:忽略字符串方法的返回值 ===")
# 场景1:数据清洗中的错误
print("\n1. 数据清洗场景:")
def clean_data_bad(data_list):
"""错误的数据清洗函数"""
for item in data_list:
# 错误:字符串方法返回新字符串,但这里忽略了返回值
item.strip() # 不会修改item!
item.lower() # 不会修改item!
return data_list # 返回的是未清洗的数据!
def clean_data_good(data_list):
"""正确的数据清洗函数"""
cleaned = []
for item in data_list:
# 正确:接收返回值
cleaned_item = item.strip().lower()
cleaned.append(cleaned_item)
return cleaned
# 测试
dirty_data = [" Hello ", " WORLD ", " Python "]
print(f" 原始数据: {dirty_data}")
print(f" 错误清洗结果: {clean_data_bad(dirty_data)}")
print(f" 正确清洗结果: {clean_data_good(dirty_data)}")
# 场景2:字符串替换中的错误
print("\n2. 字符串替换场景:")
def replace_text_bad(text, old, new):
"""错误的文本替换函数"""
# 错误:直接调用replace而不保存结果
text.replace(old, new)
return text # 返回的是未替换的文本!
def replace_text_good(text, old, new):
"""正确的文本替换函数"""
# 正确:保存replace的结果
return text.replace(old, new)
# 测试
text = "I like apples. Apples are tasty."
print(f" 原始文本: {text}")
print(f" 错误替换('apples'->'oranges'): {replace_text_bad(text, 'apples', 'oranges')}")
print(f" 正确替换('apples'->'oranges'): {replace_text_good(text, 'apples', 'oranges')}")
# 场景3:忘记字符串是不可变的
print("\n3. 尝试直接修改字符串:")
def process_name_bad(name):
"""错误的名称处理函数"""
# 错误:尝试直接修改字符串
if name.startswith("Mr. "):
# 不能这样做!
# name[4:] = name[4:].upper() # 这会报错
# 所以开发者可能会用错误的方式
name = name[4:] # 这不会修改传入的name!
return name
def process_name_good(name):
"""正确的名称处理函数"""
# 正确:创建新字符串
if name.startswith("Mr. "):
return name[4:].upper()
return name
# 测试
names = ["Mr. Smith", "Ms. Johnson", "Dr. Brown"]
print(f" 原始名称: {names}")
print(f" 错误处理: {[process_name_bad(name) for name in names]}")
print(f" 正确处理: {[process_name_good(name) for name in names]}")
return dirty_data, text, names
dirty_data, sample_text, name_list = common_error_3()错误4:字符串与字节串混淆
python
def common_error_4():
"""常见错误4:字符串与字节串混淆"""
print("=== 错误4:字符串与字节串混淆 ===")
# Python 3中字符串和字节串的区别
print("\n1. 字符串(str) vs 字节串(bytes):")
# 字符串(Unicode)
text_str = "Hello, 世界!"
print(f" 字符串: {text_str}")
print(f" 类型: {type(text_str)}")
print(f" 长度(字符数): {len(text_str)}")
print(f" 编码为UTF-8字节: {text_str.encode('utf-8')}")
# 字节串
text_bytes = b"Hello, World!"
print(f"\n 字节串: {text_bytes}")
print(f" 类型: {type(text_bytes)}")
print(f" 长度(字节数): {len(text_bytes)}")
# 常见错误:混合使用str和bytes
print("\n2. 常见错误:混合使用str和bytes:")
def concatenate_bad(part1, part2):
"""错误的拼接函数"""
try:
return part1 + part2
except TypeError as e:
return f"错误: {e}"
# 测试混合类型拼接
str_part = "字符串部分"
bytes_part = b"bytes part"
print(f" 尝试拼接 str + bytes: {concatenate_bad(str_part, bytes_part)}")
print(f" 尝试拼接 bytes + str: {concatenate_bad(bytes_part, str_part)}")
# 正确的方式:统一类型
print("\n3. 正确处理字符串和字节串:")
def process_text_correctly(text, encoding='utf-8'):
"""正确处理文本(支持str和bytes输入)"""
if isinstance(text, bytes):
# 如果是字节串,解码为字符串
return text.decode(encoding)
elif isinstance(text, str):
# 如果是字符串,直接返回
return text
else:
raise TypeError(f"Expected str or bytes, got {type(text)}")
# 测试
test_inputs = [
"Hello, 世界!", # 字符串
b"Hello, World!", # 字节串
"正常字符串",
b"\xe4\xb8\x96\xe7\x95\x8c" # "世界"的UTF-8编码
]
for i, inp in enumerate(test_inputs):
try:
result = process_text_correctly(inp)
print(f" 输入{i+1} ({type(inp).__name__}): {inp!r} -> {result}")
except Exception as e:
print(f" 输入{i+1} 错误: {e}")
# 文件操作中的常见错误
print("\n4. 文件操作中的编码问题:")
def read_file_bad(filename):
"""错误的文件读取方式(可能引发编码错误)"""
try:
with open(filename, 'r') as f: # 默认文本模式,使用系统编码
return f.read()
except UnicodeDecodeError as e:
return f"解码错误: {e}"
def read_file_good(filename, encoding='utf-8'):
"""正确的文件读取方式(指定编码)"""
try:
with open(filename, 'r', encoding=encoding) as f:
return f.read()
except UnicodeDecodeError as e:
return f"解码错误: {e}"
# 创建测试文件
test_content = "Hello, 世界!\nThis is a test file."
# 用不同编码写入文件
encodings = ['utf-8', 'gbk', 'latin-1']
for encoding in encodings:
filename = f"test_{encoding}.txt"
try:
with open(filename, 'w', encoding=encoding) as f:
f.write(test_content)
print(f" 已创建 {filename} ({encoding})")
except Exception as e:
print(f" 创建 {filename} 时出错: {e}")
# 尝试读取(可能出错)
print("\n 读取测试:")
for encoding in encodings:
filename = f"test_{encoding}.txt"
result = read_file_bad(filename) # 不指定编码
if "解码错误" in str(result):
print(f" {filename}: 默认编码读取失败")
else:
print(f" {filename}: 默认编码读取成功")
# 清理测试文件
import os
for encoding in encodings:
filename = f"test_{encoding}.txt"
if os.path.exists(filename):
os.remove(filename)
return text_str, text_bytes
text_str, text_bytes = common_error_4()高级话题与性能优化
字符串驻留(Interning)机制
python
import sys
def explore_string_interning():
"""探索字符串驻留机制"""
print("=== 字符串驻留机制 ===")
# 自动驻留的字符串
print("\n1. 自动驻留(短字符串和标识符):")
# 短字符串通常会被驻留
a = "hello"
b = "hello"
print(f" a = 'hello', b = 'hello'")
print(f" a is b: {a is b} (ID: {id(a)} == {id(b)})")
# 包含空格的字符串通常不会被驻留
c = "hello world"
d = "hello world"
print(f" c = 'hello world', d = 'hello world'")
print(f" c is d: {c is d} (通常为False)")
# 标识符会被驻留
e = "variable_name"
f = "variable_name"
print(f" e = 'variable_name', f = 'variable_name'")
print(f" e is f: {e is f}")
# 显式驻留
print("\n2. 显式驻留(sys.intern):")
str1 = "a long string that won't be interned automatically" * 2
str2 = "a long string that won't be interned automatically" * 2
print(f" 长字符串自动驻留: str1 is str2 = {str1 is str2}")
# 显式驻留
str3 = sys.intern(str1)
str4 = sys.intern(str2)
print(f" 显式驻留后: str3 is str4 = {str3 is str4}")
# 驻留的优势:比较速度
print("\n3. 驻留的性能优势:")
def compare_strings_non_interned():
"""比较非驻留字符串"""
list1 = ["string_" + str(i) for i in range(1000)]
list2 = ["string_" + str(i) for i in range(1000)]
count = 0
for s1 in list1:
for s2 in list2:
if s1 == s2: # 需要比较内容
count += 1
return count
def compare_strings_interned():
"""比较驻留字符串"""
list1 = [sys.intern("string_" + str(i)) for i in range(1000)]
list2 = [sys.intern("string_" + str(i)) for i in range(1000)]
count = 0
for s1 in list1:
for s2 in list2:
if s1 is s2: # 只需要比较ID
count += 1
return count
# 性能比较
import time
start = time.perf_counter()
count1 = compare_strings_non_interned()
time1 = time.perf_counter() - start
start = time.perf_counter()
count2 = compare_strings_interned()
time2 = time.perf_counter() - start
print(f" 非驻留比较耗时: {time1:.4f}秒")
print(f" 驻留比较耗时: {time2:.4f}秒")
print(f" 性能提升: {time1/time2:.1f}倍")
# 驻留的实际应用场景
print("\n4. 实际应用场景:")
# 场景:大量重复字符串的处理
def process_data_without_intern(data):
"""处理数据,不使用驻留"""
processed = []
for item in data:
# 可能创建大量重复字符串
processed.append(item.strip().lower())
return processed
def process_data_with_intern(data):
"""处理数据,使用驻留"""
processed = []
for item in data:
# 使用驻留避免重复字符串
processed.append(sys.intern(item.strip().lower()))
return processed
# 模拟大量重复数据
import random
words = ["apple", "banana", "cherry", "date", "elderberry"]
data = [random.choice(words) for _ in range(10000)]
# 分析内存使用
result1 = process_data_without_intern(data)
result2 = process_data_with_intern(data)
# 计算唯一字符串数量
unique1 = len(set(result1))
unique2 = len(set(id(s) for s in result2)) # 基于ID计算
print(f" 数据量: {len(data)}")
print(f" 不使用驻留 - 唯一字符串对象数: {unique1}")
print(f" 使用驻留 - 唯一字符串对象数: {unique2}")
print(f" 内存节省: {(1 - unique2/unique1)*100:.1f}% (理论上)")
return a, b, str3, str4
interned_examples = explore_string_interning()字符串格式化性能比较
python
import time
import sys
def compare_string_formatting():
"""比较不同字符串格式化方法的性能"""
print("=== 字符串格式化性能比较 ===")
# 测试数据
name = "Alice"
age = 30
salary = 50000.50
iterations = 100000
# 方法1:百分号格式化(旧式)
def percent_format():
result = "Name: %s, Age: %d, Salary: $%.2f" % (name, age, salary)
return result
# 方法2:str.format()
def format_method():
result = "Name: {}, Age: {}, Salary: ${:.2f}".format(name, age, salary)
return result
# 方法3:f-string(Python 3.6+)
def f_string():
result = f"Name: {name}, Age: {age}, Salary: ${salary:.2f}"
return result
# 方法4:字符串拼接
def concatenation():
result = "Name: " + name + ", Age: " + str(age) + ", Salary: $" + f"{salary:.2f}"
return result
# 方法5:使用join
def join_method():
parts = [
"Name: ", name,
", Age: ", str(age),
", Salary: $", f"{salary:.2f}"
]
result = "".join(parts)
return result
# 性能测试函数
def benchmark(func, iterations):
"""基准测试函数"""
start = time.perf_counter()
for _ in range(iterations):
func()
end = time.perf_counter()
return end - start
# 运行基准测试
methods = [
("% 格式化", percent_format),
("str.format()", format_method),
("f-string", f_string),
("字符串拼接", concatenation),
("join方法", join_method)
]
print(f"\n迭代次数: {iterations}")
print("-" * 50)
results = {}
for method_name, method_func in methods:
# 预热
for _ in range(1000):
method_func()
# 正式测试
time_taken = benchmark(method_func, iterations)
results[method_name] = time_taken
print(f"{method_name:15} {time_taken*1000:8.2f} ms")
# 找出最快的方法
fastest = min(results, key=results.get)
fastest_time = results[fastest]
print("-" * 50)
print(f"\n最快方法: {fastest} ({fastest_time*1000:.2f} ms)")
# 相对性能比较
print("\n相对性能(倍数,越小越好):")
for method_name, time_taken in results.items():
ratio = time_taken / fastest_time
print(f" {method_name:15} {ratio:6.2f}x")
# 内存使用比较
print("\n=== 内存使用比较 ===")
def memory_usage(func, iterations):
"""估算内存使用"""
import tracemalloc
tracemalloc.start()
# 执行多次以获取稳定测量
results = []
for _ in range(iterations // 100): # 减少迭代次数避免内存爆炸
results.append(func())
current, peak = tracemalloc.get_traced_memory()
tracemalloc.stop()
return current / 1024, peak / 1024 # 转换为KB
print(f"\n内存使用({iterations//100}次迭代):")
for method_name, method_func in methods:
current, peak = memory_usage(method_func, iterations)
print(f"{method_name:15} 当前: {current:6.2f} KB, 峰值: {peak:6.2f} KB")
# 不同场景下的推荐
print("\n=== 不同场景推荐 ===")
recommendations = [
{
"场景": "Python 3.6+ 新代码",
"推荐": "f-string",
"理由": "性能最好,语法最简洁,可读性最强"
},
{
"场景": "需要向后兼容",
"推荐": "str.format()",
"理由": "兼容Python 2.7和3.x,性能良好"
},
{
"场景": "大量简单拼接",
"推荐": "join()方法",
"理由": "性能稳定,内存效率高"
},
{
"场景": "国际化/本地化",
"推荐": "str.format()",
"理由": "更好地支持多语言和格式控制"
},
{
"场景": "复杂表达式",
"推荐": "f-string",
"理由": "支持内联表达式,代码更清晰"
}
]
for rec in recommendations:
print(f" {rec['场景']:20} → {rec['推荐']:15} ({rec['理由']})")
return results
formatting_results = compare_string_formatting()字符串视图与内存视图
python
def explore_string_views():
"""探索字符串视图和内存高效操作"""
print("=== 字符串视图与内存高效操作 ===")
# 字符串切片并不复制数据(Python 3中)
print("\n1. 字符串切片的内存行为:")
large_string = "a" * 100 + "b" * 100 + "c" * 100
print(f" 原始字符串长度: {len(large_string)}")
print(f" 原始字符串ID: {id(large_string)}")
# 切片创建新字符串对象
slice1 = large_string[50:150]
print(f" 切片[50:150]长度: {len(slice1)}")
print(f" 切片ID: {id(slice1)}")
print(f" 切片是独立对象: {large_string[50] is slice1[0]}")
# 但对于短字符串,Python可能重用对象
short_string = "hello"
slice2 = short_string[1:4]
print(f"\n 短字符串切片可能被优化:")
print(f" 短字符串: '{short_string}', ID: {id(short_string)}")
print(f" 切片[1:4]: '{slice2}', ID: {id(slice2)}")
# 内存视图(memoryview)用于字节串
print("\n2. 内存视图(memoryview):")
# 创建字节串
data = b"Hello, World! This is a test byte string."
print(f" 原始字节串: {data[:20]}...")
print(f" 原始字节串ID: {id(data)}")
# 创建内存视图(不复制数据)
mv = memoryview(data)
print(f" 内存视图ID: {id(mv)}")
print(f" 内存视图长度: {len(mv)}")
# 通过内存视图切片(不复制数据)
slice_mv = mv[7:12]
print(f" 内存视图切片[7:12]: {slice_mv.tobytes()}")
print(f" 内存视图切片是原始数据的视图: {slice_mv.obj is data}")
# 修改原始数据(如果是可变的)
print("\n3. 可变数据的视图:")
# 创建字节数组(可变)
byte_arr = bytearray(b"Hello, World!")
print(f" 字节数组: {byte_arr}")
# 创建内存视图
mv_arr = memoryview(byte_arr)
# 通过视图修改数据
mv_arr[7:12] = b"Python"
print(f" 通过内存视图修改后: {byte_arr}")
# 字符串不可变,所以没有类似的可变视图
print("\n4. 字符串没有可变视图(因为不可变):")
text = "Hello, World!"
try:
# 尝试创建字符串的内存视图会失败
mv_text = memoryview(text)
except TypeError as e:
print(f" 错误: {e}")
print(f" 原因: 字符串不可变,不需要/不支持内存视图")
# 实际应用:处理大型文本文件
print("\n5. 实际应用:处理大型文本文件")
def process_large_file_efficiently(filename):
"""高效处理大型文本文件"""
print(f" 处理文件: {filename}")
# 方法1:一次性读取(内存消耗大)
with open(filename, 'r', encoding='utf-8') as f:
content = f.read() # 整个文件加载到内存
print(f" 方法1(一次性读取): {len(content)} 字符")
# 方法2:逐行读取(内存效率高)
line_count = 0
char_count = 0
with open(filename, 'r', encoding='utf-8') as f:
for line in f:
line_count += 1
char_count += len(line)
print(f" 方法2(逐行读取): {line_count} 行, {char_count} 字符")
# 方法3:使用内存映射文件(最大内存效率)
import mmap
with open(filename, 'r+b') as f:
# 内存映射文件
mmapped = mmap.mmap(f.fileno(), 0, access=mmap.ACCESS_READ)
# 可以直接在内存映射上搜索(不加载到Python内存)
position = mmapped.find(b"search_term")
if position != -1:
print(f" 找到 'search_term' 在位置 {position}")
mmapped.close()
return len(content), line_count, char_count
# 创建测试文件
test_filename = "large_test_file.txt"
with open(test_filename, 'w', encoding='utf-8') as f:
# 写入大量数据
for i in range(10000):
f.write(f"这是第 {i} 行,包含一些测试文本。\n")
print(f" 创建测试文件: {test_filename}")
# 处理文件(注释掉实际处理以减少输出)
# process_large_file_efficiently(test_filename)
# 清理
import os
os.remove(test_filename)
return large_string, data, byte_arr
view_examples = explore_string_views()最佳实践与模式
字符串处理最佳实践
python
def string_best_practices():
"""字符串处理最佳实践"""
print("=== 字符串处理最佳实践 ===")
practices = [
{
"实践": "1. 使用f-string进行格式化",
"示例": "f'Name: {name}, Age: {age}'",
"理由": "性能最好,可读性最强"
},
{
"实践": "2. 大量拼接使用join()",
"示例": "''.join(list_of_strings)",
"理由": "避免O(n²)时间复杂度"
},
{
"实践": "3. 明确处理字符串编码",
"示例": "text.encode('utf-8') / data.decode('utf-8')",
"理由": "避免编码错误,特别是处理文件或网络数据时"
},
{
"实践": "4. 使用str.strip()清理用户输入",
"示例": "clean_input = user_input.strip()",
"理由": "移除意外空格和换行符"
},
{
"实践": "5. 使用str.startswith()和str.endswith()",
"示例": "if filename.endswith('.txt'):",
"理由": "比切片更清晰,更安全"
},
{
"实践": "6. 避免频繁修改字符串",
"示例": "使用列表收集,最后join()",
"理由": "字符串不可变,每次修改都创建新对象"
},
{
"实践": "7. 使用三引号处理多行字符串",
"示例": 'long_text = """第一行\n第二行"""',
"理由": "更清晰,避免大量的\\n转义"
},
{
"实践": "8. 使用str.split()和str.rsplit()控制分割",
"示例": "parts = text.rsplit('.', 1) # 从右边分割一次",
"理由": "更精确地控制分割行为"
},
{
"实践": "9. 使用str.partition()获取分隔符",
"示例": "left, sep, right = text.partition('=')",
"理由": "同时获取分隔符和两侧内容"
},
{
"实践": "10. 使用str.translate()进行高效字符替换",
"示例": "trans_table = str.maketrans('aeiou', '12345')\ntext.translate(trans_table)",
"理由": "批量字符替换时性能最好"
}
]
for practice in practices:
print(f"{practice['实践']}")
print(f" 示例: {practice['示例']}")
print(f" 理由: {practice['实践']}")
print()
# 实际示例展示
print("\n=== 实际示例 ===")
# 示例1:高效字符替换
print("1. 高效字符替换(str.translate):")
# 创建替换表
translate_table = str.maketrans({
'a': '4',
'e': '3',
'i': '1',
'o': '0',
's': '5'
})
text = "Hello, this is a test string with some vowels."
leet_text = text.translate(translate_table)
print(f" 原始: {text}")
print(f" 转换后: {leet_text}")
# 对比普通替换
def replace_multiple_slow(text, replacements):
"""缓慢的多次替换"""
for old, new in replacements.items():
text = text.replace(old, new)
return text
replacements = {'a': '4', 'e': '3', 'i': '1', 'o': '0', 's': '5'}
import time
# 性能对比
start = time.perf_counter()
for _ in range(10000):
replace_multiple_slow(text, replacements)
slow_time = time.perf_counter() - start
start = time.perf_counter()
for _ in range(10000):
text.translate(translate_table)
fast_time = time.perf_counter() - start
print(f" 性能对比: translate() 比多次replace()快 {slow_time/fast_time:.1f}倍")
# 示例2:处理多行文本
print("\n2. 处理多行文本:")
multi_line_text = """第一行:这是开始
第二行:继续内容
第三行:最后一行"""
print(f" 原始多行文本:\n{multi_line_text}")
# 逐行处理
lines = multi_line_text.splitlines()
processed_lines = []
for i, line in enumerate(lines, 1):
cleaned = line.strip()
if cleaned: # 跳过空行
processed_lines.append(f"{i}: {cleaned}")
result = "\n".join(processed_lines)
print(f" 处理后:\n{result}")
# 示例3:安全处理用户输入
print("\n3. 安全处理用户输入:")
def sanitize_user_input(user_input, max_length=100):
"""清理用户输入"""
if not isinstance(user_input, str):
user_input = str(user_input)
# 移除首尾空白
cleaned = user_input.strip()
# 限制长度
if len(cleaned) > max_length:
cleaned = cleaned[:max_length]
# 替换危险字符(简单示例)
cleaned = cleaned.replace('<', '<').replace('>', '>')
return cleaned
# 测试
test_inputs = [
" Hello World! ",
"Script: <script>alert('xss')</script>",
"A" * 200, # 超长输入
12345, # 非字符串输入
None
]
print(" 输入 -> 清理后:")
for inp in test_inputs:
try:
cleaned = sanitize_user_input(inp)
print(f" '{inp}' -> '{cleaned}'")
except Exception as e:
print(f" 错误处理 '{inp}': {e}")
return practices, leet_text, result
best_practices, leet_example, processed_text = string_best_practices()总结与结论
字符串不可变性的核心要点
字符串的不可变性是Python语言设计的基石之一,它带来了以下关键影响:19
- 安全性:不可变对象是线程安全的,可以作为字典键,不会在传递时被意外修改
- 性能优化:允许字符串驻留、缓存哈希值等优化
- 简化语义:明确的操作语义,不会有意外的副作用
- 内存效率:对于相同内容的字符串可以安全地共享内存
常见错误的避免策略
通过本文的分析,我们可以总结出避免字符串相关错误的策略:
- 永远记住字符串不可变:任何"修改"操作都返回新字符串
- 大量拼接用join :避免在循环中使用
+=拼接字符串 - 明确编码解码:在处理I/O时总是明确指定编码
- 使用现代格式化 :优先使用f-string,其次是
str.format() - 选择合适的方法 :根据场景选择
split()、partition()、translate()等最合适的方法
性能优化建议
对于高性能字符串处理:
- 使用f-string进行格式化:性能最佳
- 批量操作使用translate:替换多个字符时效率最高
- 考虑使用内存视图:处理大型二进制数据时
- 避免不必要的转换:在字节串和字符串间频繁转换
面向未来的字符串处理
随着Python的发展,字符串处理也在不断进化:20
- Python 3.6+的f-string:提供了更简洁高效的格式化
- 类型注解支持 :
str类型注解提高了代码可读性 - 更好的Unicode支持:全面拥抱Unicode,简化国际化开发
- 性能持续优化:每个Python版本都在改进字符串处理性能
掌握字符串的不可变性不仅是理解Python的基础,更是编写高效、安全、可维护代码的关键。21通过深入理解这一特性,开发者可以避免常见的陷阱,充分利用Python字符串处理的优势,构建更健壮的应用程序。