在弱光、夜间监控和安防场景中,目标检测面临极大挑战:可见光图像噪声强、细节丢失、目标模糊,而红外图像在结构边缘保持得更好,但语义信息不足。如果能将红外(IR)与可见光(VIS)两种模态有效融合,通常可以大幅提升夜间检测表现。
一种常见且高效的解决方案是 ------ 基于 YOLO 架构,构建"双 Backbone + 双模态输入"的融合检测器 。本文以 LLVIP(Low-Light Visible-Infrared Person) 双模态数据集为例,介绍整个双模态 YOLO 的构建过程,包括:
-
数据准备
-
双 Backbone 结构设计
-
模态融合方式
-
训练流程
-
模型可视化推理示例
1. LLVIP 数据集简介
LLVIP(2021)是一个专门用于弱光下行人检测的双模态数据集,包含:
| 项目 | 数值 |
|---|---|
| 图像对数(VIS + IR) | 15488 对 |
| 图像分辨率 | 约 1080P |
| 标注类别 | Person |
| 场景 | 室外/弱光/夜间 |
| 是否配准 | ✔ 完全像素级配准 |
可见光样例(噪声大):
红外样例(结构清晰):
双模态检测的关键优势就在于:
-
VIS 提供纹理、颜色信息
-
IR 提供结构、轮廓与稳定亮度
因此构建双 Backbone 模型能让两种特征互补。
2. 为什么要"双 Backbone + 双模态"?
1. 单模态检测的局限性
可见光模态:白天表现优异,但夜间 / 雾霾场景下易受噪声、低对比度影响,目标易漏检。
红外模态:不受光照影响,能清晰捕捉目标轮廓,但缺乏颜色、纹理等细节,小目标检测精度低。
双模态融合的核心是互补信息聚合:用红外模态提供目标 "位置锚点",用可见光模态补充 "细节特征",提升复杂场景的鲁棒性。
2. 双 Backbone 架构设计思路
VIS 与 IR 的分布差异极大,如果直接拼接输入:
-
模态差异太大:卷积难以同时学习
-
低光噪声干扰特征
-
IR 热特征稀疏,不适合早期拼接
为每个模态单独设计一个 Backbone 分支,在 Neck 阶段进行高层语义融合, 在 Head 阶段共享检测器。
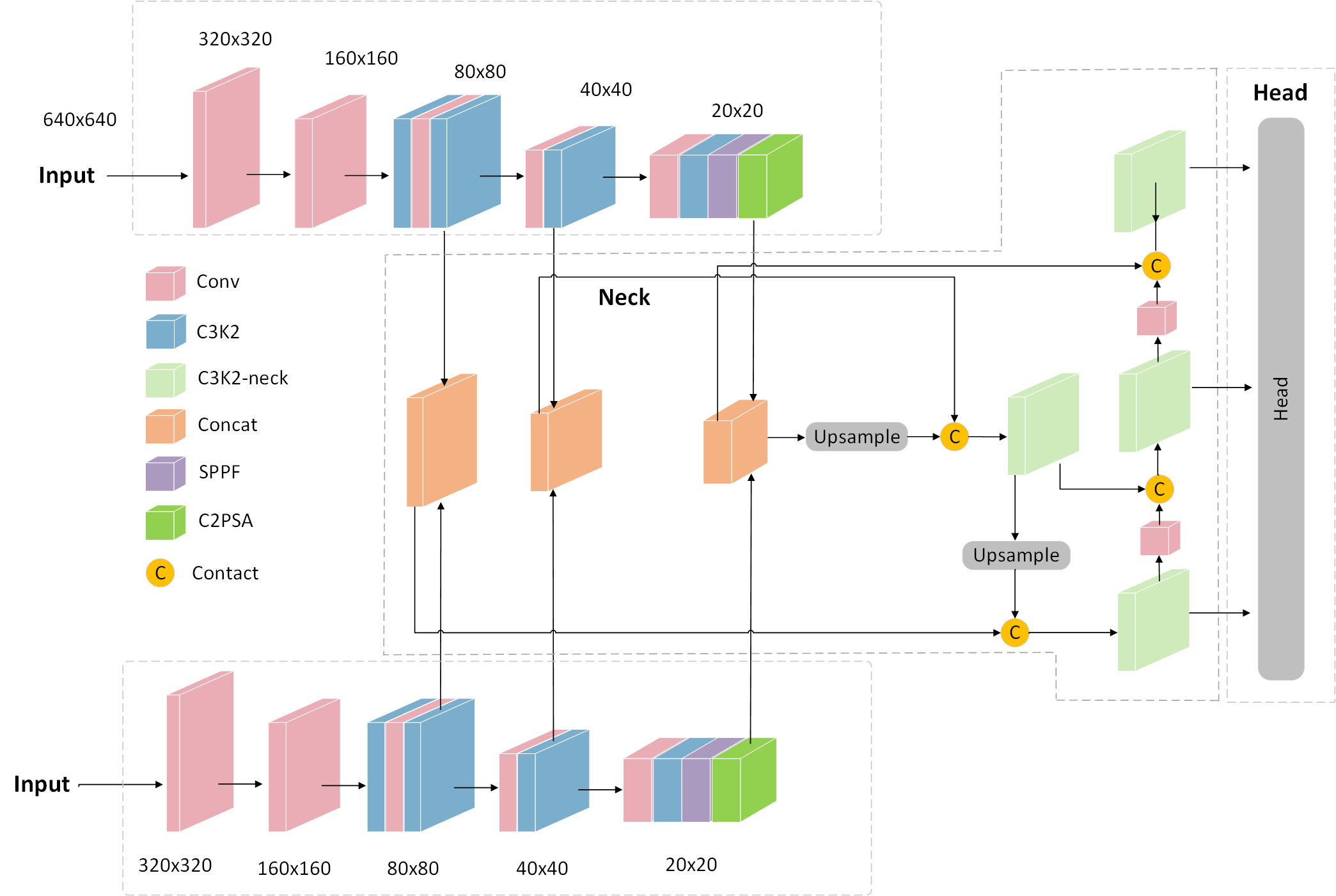
3. YOLO 双 Backbone 结构设计
我们以 YOLOv8/YOLOv11 为基础,对主干部分进行双模态改造。
(1) 融合方式1:Concat + 1×1 Conv(最常用)
python
fusion = Conv1x1( concat([feat_vis, feat_ir], dim=1) )(2) 融合方式2:加权融合(效果更好)
W 模态权重可学习:
python
fusion = w1 * feat_vis + w2 * feat_ir(3) 融合方式3:Cross Attention(效果最好)
对 VIS → IR、IR → VIS 分别建立注意力:
python
att_vis2ir = Softmax(Q_vis · K_ir^T)
att_ir2vis = Softmax(Q_ir · K_vis^T)
feat_fused = feat_vis + att_vis2ir · V_ir + feat_ir + att_ir2vis · V_vis4. 训练流程(基于 LLVIP)
代码获取:
https://github.com/tgf123/YOLOv8_improve
YOLO 双 Backbone 双模态融合:以 LLVIP 数据集为例的红外 - 可见光目标检测实践_哔哩哔哩_bilibili
YOLOv11模型改进讲解,教您如何使用双backbone提升YOLO11检测精度_哔哩哔哩_bilibili
YOLO双backbone讲,使用Mambaout替换YOLO backbone,可用于单模态和双模态检测,提高精度_哔哩哔哩_bilibili
4.1数据准备
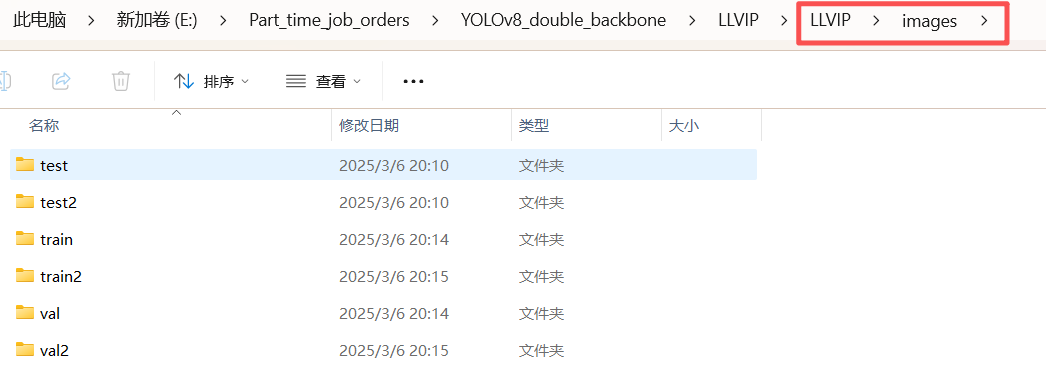
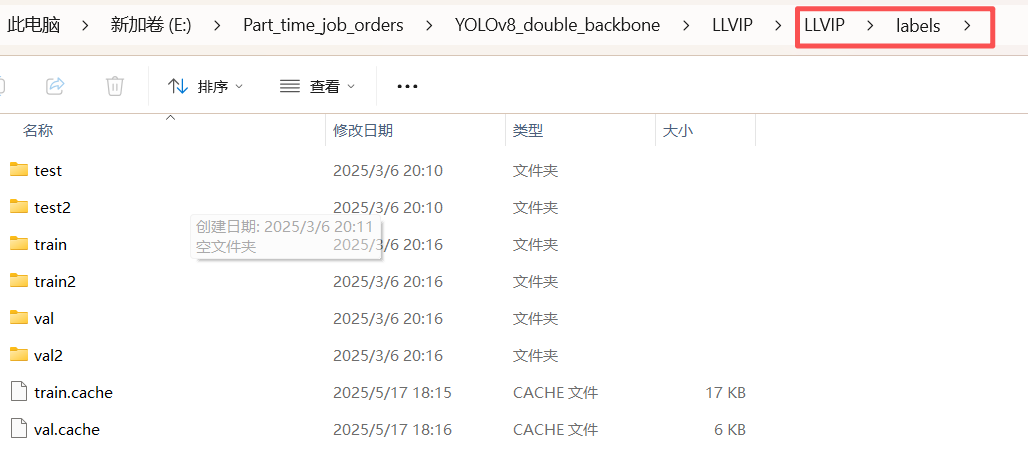
从下面的数据截屏可以看到,图像和标签都是两份
LLVIP/
├── images/
│ ├── train/
│ ├── train2/ # IR
│ ├── val/
│ ├── val2/ # IR
├── labels/
│ ├── train/
│ ├── train2/
│ ├── val/
│ ├── val2/
python
path: E:/Part_time_job_orders/YOLOv8_double_backbone/LLVIP/LLVIP
train: images/train # VIS
train2: images/train2 # IR
val: images/val # VIS
val2: images/val2 # IR
nc: 1
names:
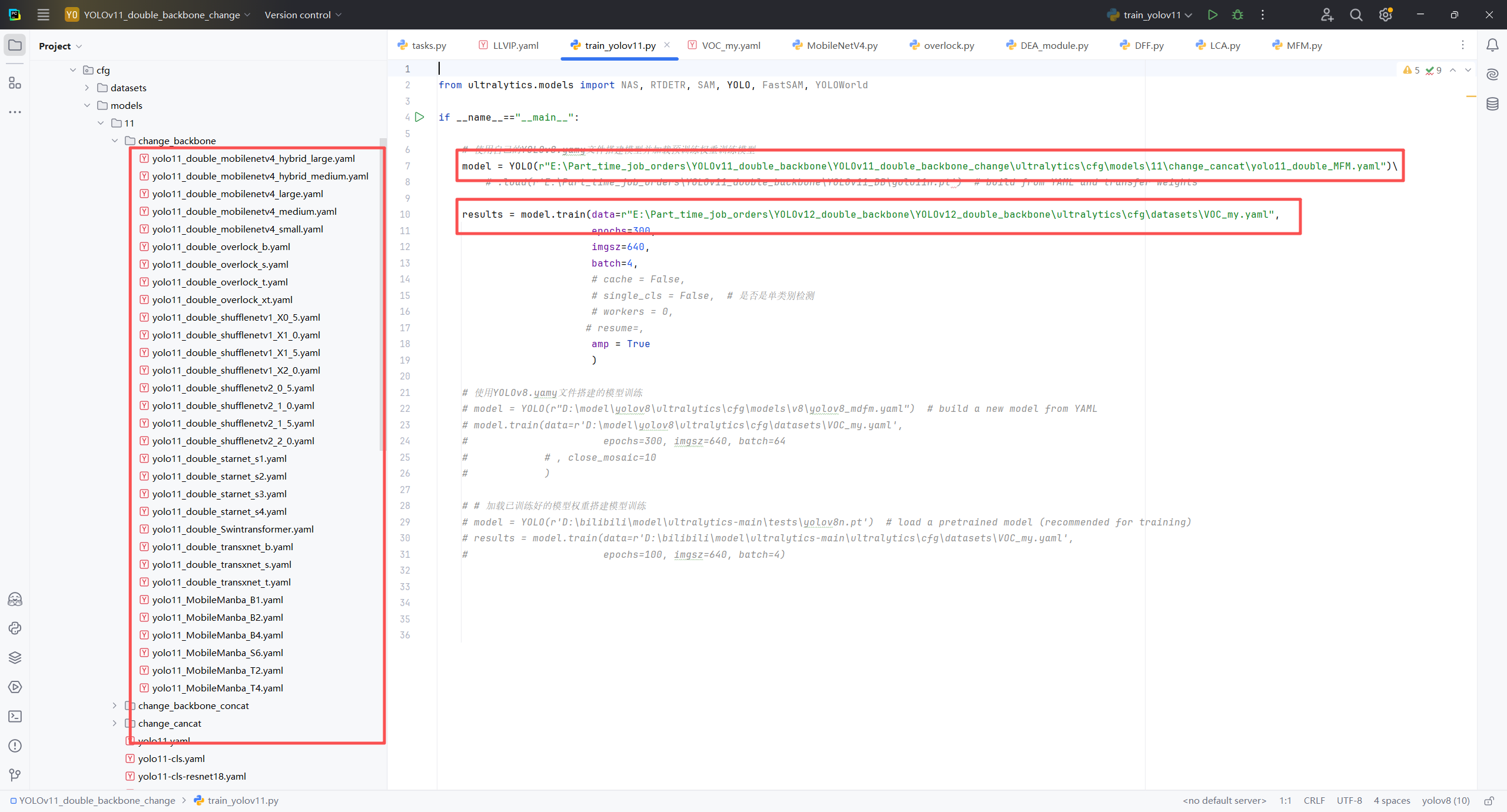
0: Person4.2模型的训练
从下面的的图中可以看出,和平常的yolo训练时一样的,也是将yaml文件的路径和数据的yaml路径复制一下,然后直接运行就可以。
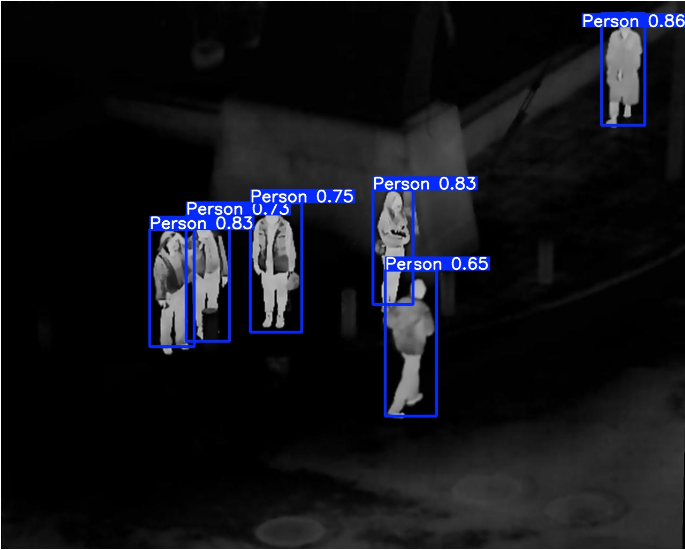
4.3模型的可视化
python
from ultralytics import YOLO
if __name__ == "__main__":
pth_path = r"E:\Part_time_job_orders\YOLOv11_double_backbone\YOLOv11_double_backbone\runs\detect\train5\weights\best.pt"
test_path = [r"E:\Part_time_job_orders\YOLOv8_double_backbone\LLVIP\LLVIP\images\train\010001.jpg",r"E:\Part_time_job_orders\YOLOv8_double_backbone\LLVIP\LLVIP\images\train2\010001.jpg"]
# ["/home/shengtuo/tangfan/Crack_detection/data/RDD2022_China/images/val/China_MotorBike_001974.jpg","/home/shengtuo/tangfan/Crack_detection/data/RDD2022_China/images/val/China_MotorBike_001974.jpg"]]
# Load a model
# model = YOLO('yolov8n.pt') # load an official model
model = YOLO(pth_path) # load a custom model
# Predict with the model
results = model(test_path ,imgsz=640, save=True, conf=0.5) # predict on an image
| 数据集名称 | 参考论文 | 下载链接 |
|---|---|---|
| MSRS 数据集 | PIAFusion: A progressive infrared and visible image fusion network based on illumination aware | https://github.com/Linfeng-Tang/MSRS |
| RoadScene 数据集 | U2Fusion: A Unified Unsupervised Image Fusion Network | https://github.com/hanna-xu/RoadScene |
| M3FD 数据集 | Target-aware Dual Adversarial Learning and a Multi-scenario Multi-Modality Benchmark to Fuse Infrared and Visible for Object Detection | https://github.com/JinyuanLiu-CV/TarDAL |
| TNO 数据集 | The TNO Multiband Image Data Collection | https://figshare.com/articles/dataset/TNO_Image_Fusion_Dataset/1008029 |
| LLVIP 数据集 | LLVIP: A Visible-infrared Paired Dataset for Low-light Vision | https://github.com/bupt-ai-cz/LLVIP |
| FMB 数据集 | Multi-interactive Feature Learning and a Full-time Multi-modality Benchmark for Image Fusion and Segmentation | https://github.com/JinyuanLiu-CV/SegMiF |
| FLIR 数据集 | FREE Teledyne FLIR Thermal Dataset for Algorithm Training(参考博客) | https://www.flir.com/oem/adas/adas-dataset-form/ |
| MFNet 数据集 | MFNet: Towards real-time semantic segmentation for autonomous vehicles with multi-spectral scenes | https://www.mi.t.u-tokyo.ac.jp/static/projects/mil_multispectral/ |
| KAIST 数据集 | Multispectral Pedestrian Detection: Benchmark Dataset and Baseline(KAIST Multispectral Pedestrian Detection Benchmark) | https://github.com/SoonminHwang/rgbt-ped-detection |
| PST900 数据集 | PST900: RGB-Thermal Calibration, Dataset and Segmentation Network | https://github.com/ShreyasSkandanS/pst900_thermal_rgb |
| HDO 数据集 | RCVS: Round-the-Clock Video Stream registration and fusion scheme | https://github.com/xiehousheng/HDO |
| MMVS 数据集 | VRFF: Video Registration and Fusion Framework | https://github.com/Meng-Sang/VRFF;https://github.com/Meng-Sang/MMVS |
| DVTOD 数据集 | Misaligned Visible-Thermal Object Detection: A Drone-based Benchmark and Baseline | https://github.com/VDT-2048/DVTOD |
| AWMM-100k 数据集 | All-weather Multi-Modality Image Fusion: Unified Framework and 100k Benchmark | https://github.com/ixilai/AWFusion |
| EMS 数据集 | Text-IF: Leveraging Semantic Text Guidance for Degradation-Aware and Interactive Image Fusion | https://github.com/XunpengYi/Text-IF |
| INO 数据集 | Video Analytics Dataset(参考博客) | https://www.ino.ca/en/technologies/video-analytics-dataset/videos/ |
| M3SVD 数据集 | VideoFusion: A Spatio-Temporal Collaborative Network for Mutli-modal Video Fusion and Restoration | https://github.com/Linfeng-Tang/M2VD |
| VF-Bench 数据集 | A Unified Solution to Video Fusion: From Multi-Frame Learning to Benchmarking (NeurIPS 25) | https://github.com/Zhaozixiang1228/VF-Bench |
| Airsim-VID 数据集 | VIFNet: An End-to-end Visible-Infrared Fusion Network for Image Dehazing | https://github.com/mengyu212/VIFNet_dehazing |
| DeMMI-RF 数据集 | Task-Gated Multi-Expert Collaboration Network for Degraded Multi-Modal Image Fusion | https://github.com/LeeX54946/TG-ECNet |
| AVMS 数据集 | FS-Diff: Semantic guidance and clarity-aware simultaneous multimodal image fusion and super-resolution | https://github.com/XylonXu01/FS-Diff |
| RGBT550K 数据集 | M-SpecGene: Generalized Foundation Model for RGBT Multispectral Vision | https://github.com/CalayZhou/M-SpecGene |
| RGBT-Tiny 数据集 | Visible-Thermal Tiny Object Detection: A Benchmark Dataset and Baselines | https://github.com/XinyiYing/RGBT-Tiny |
| IVT 数据集 | TextFusion: Unveiling the power of textual semantics for controllable image fusion | https://github.com/AWCXV/TextFusion |
| RGB-NIR Scene Dataset 数据集 | Multi-spectral SIFT for Scene Category Recognition (CVPR2011) | https://www.epfl.ch/labs/ivrl/research/downloads/rgb-nir-scene-dataset/ |
| RGBD1K 数据集 | RGBD1K: A Large-Scale Dataset and Benchmark for RGB-D Object Tracking (AAAI 23) | https://github.com/xuefeng-zhu5/RGBD1K |
| UniMod1K 数据集 | UniMod1K: Towards a More Universal Large-Scale Dataset and Benchmark for Multi-modal Learning (IJCV 24) | https://github.com/xuefeng-zhu5/UniMod1K |
| IVSD 数据集 | Multispectral Image Stitching via Global-Aware Quadrature Pyramid Regression (TIP 24) | https://github.com/Jzy2017/MSGA |
| Havard 多模态医学图像数据集 | 无明确对应论文(The Whole Brain Atlas) | https://www.med.harvard.edu/aanlib/home.html;https://github.com/yidamyth/Havard-Medical-Image-Fusion-Datasets |
| VIFB 数据集基准 | VIFB: A Visible and Infrared Image Fusion Benchmark (2020 CVPR Workshops) | https://github.com/xingchenzhang/VIFB |
| GTPLD 电力线数据集 | Ground Truth of Power Line Dataset (Infrared-IR and Visible Light-VL) | https://www.selectdataset.com/dataset/4371a791b8e4090388449273a001dab8 |