本文的主要目的是从模型轻量化、推理优化、硬件优化三个核心维度系统性提升 YOLO 模型的推理速度,同时尽可能平衡精度损失(速度和精度的权衡是核心)。以下是分层次、可落地的优化方案(以 YOLOv8 为例,v5 通用)。
核心优化逻辑
速度优化需遵循 "先软件、后硬件" 的顺序(软件优化成本低、收益高),且每一步优化后都要验证精度损失是否在可接受范围内(通常允许精度下降≤3%):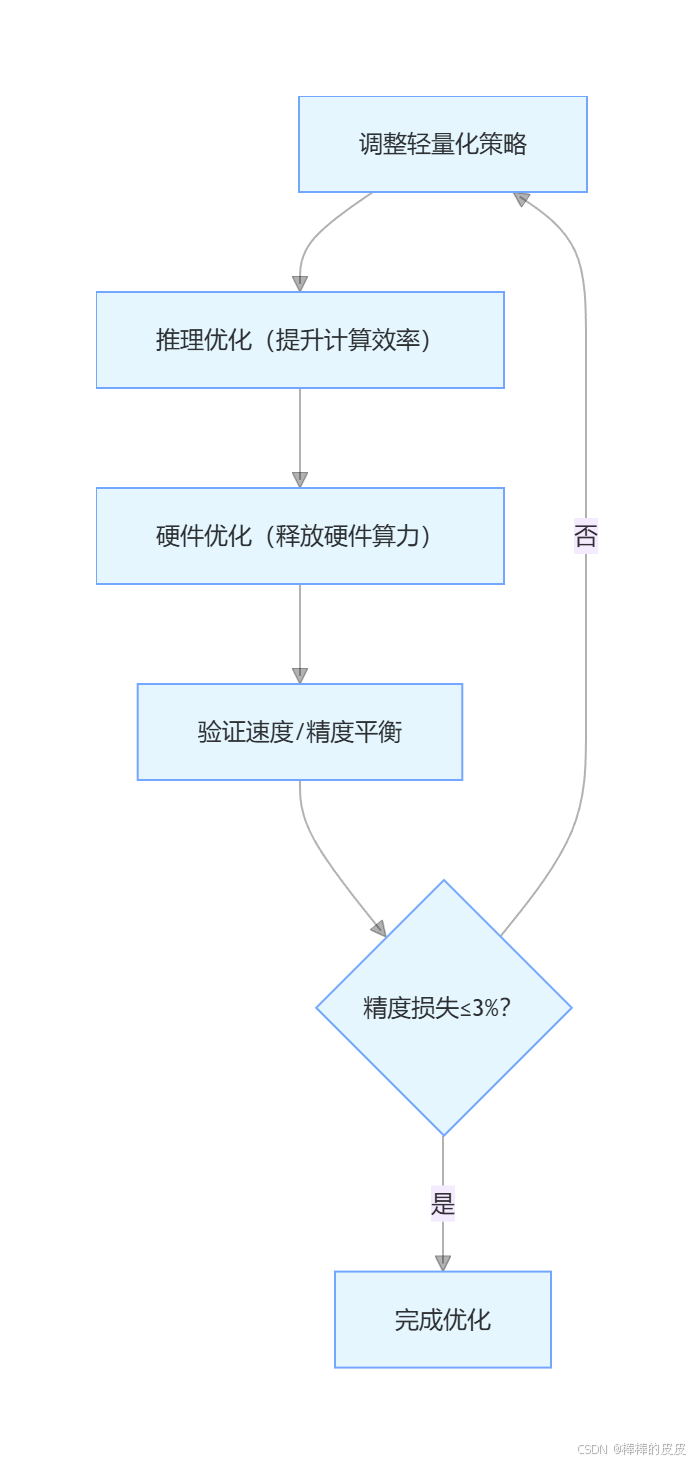
一、模型轻量化(基础层,降低计算量)
模型轻量化是从 "源头" 减少推理时的计算量,核心是精简网络结构、减少参数量 / 计算量,是速度优化的第一步。
1. 选择轻量化模型(最简单、收益最高)
优先选择官方提供的轻量化版本,无需修改代码,直接替换模型即可:
| 模型版本 | 参数量 | 计算量(GFLOPs) | 速度提升 | 精度损失 | 适用场景 |
|---|---|---|---|---|---|
| YOLOv8n(nano) | 3.2M | 8.7 | ↑80%-100% | ≈5%-8% | 移动端 / 边缘设备(Jetson Nano / 手机) |
| YOLOv8s(small) | 11.2M | 28.6 | ↑30%-50% | ≈2%-3% | 通用场景(平衡速度 / 精度) |
| YOLOv8m(medium) | 25.9M | 78.9 | ↑10%-20% | ≈1%-2% | 精度要求稍高的场景 |
实操命令:
python
# 直接加载轻量化模型训练/推理
yolo detect train model=yolov8n.pt data=data.yaml # 训练
yolo detect predict model=yolov8n.pt source=test.jpg # 推理2. 模型剪枝(进阶,精简冗余参数)
剪枝是移除模型中 "贡献小" 的卷积核 / 神经元,减少计算量,YOLOv8 支持一键剪枝:
python
# 剪枝YOLOv8s模型(保留70%的参数,可调整prune参数)
yolo detect train \
model=yolov8s.pt \
data=data.yaml \
epochs=30 \
prune=0.3 # 剪枝比例(0.3=移除30%冗余参数)关键注意:
- 剪枝后需重新微调(finetune)10-20 轮,恢复部分精度;
- 剪枝比例建议≤0.4(比例过高会导致精度大幅下降)。
3. 模型量化(核心,降低计算精度)
量化是将模型的 32 位浮点数(FP32)转换为 8 位整数(INT8)或 16 位浮点数(FP16),减少内存占用和计算时间,是工业界最常用的轻量化手段。
方式 1:训练后量化(简单,精度损失稍大)
python
# 将FP32模型量化为INT8(YOLOv8一键量化)
yolo export \
model=runs/detect/train/weights/best.pt \
format=onnx \ # 先导出为ONNX格式
int8=True \ # 量化为INT8
data=data.yaml # 提供数据集用于校准方式 2:量化感知训练(QAT,复杂,精度损失小)
适合对精度要求高的场景,训练时模拟量化误差,量化后精度损失≤2%:
python
from ultralytics import YOLO
from ultralytics.utils.quantization import quantize_model
# 加载模型
model = YOLO("yolov8s.pt")
# 量化感知训练
model.train(data="data.yaml", epochs=20, quantize=True)
# 导出量化模型
model.export(format="onnx", int8=True)4. 知识蒸馏(平衡速度 / 精度)
用高精度大模型(教师模型)"教" 轻量化小模型(学生模型),让小模型在速度接近原生的前提下,精度提升 5%-10%:
python
# 用YOLOv8l(教师)蒸馏YOLOv8n(学生)
yolo detect train \
model=yolov8n.pt \
data=data.yaml \
epochs=50 \
distill=yolov8l.pt \ # 教师模型权重
imgsz=640二、推理优化(中间层,提升计算效率)
模型轻量化后,需优化推理流程,让模型在推理时 "跑的更快",核心是减少数据预处理 / 后处理耗时、提升计算并行度。
1. 导出为高效推理格式(核心操作)
YOLO 默认的.pt 格式适合训练,推理时需导出为更高效的格式,不同格式的速度对比:
| 推理格式 | 速度提升 | 支持框架 | 适用硬件 | 实操命令 |
|---|---|---|---|---|
| ONNX | ↑20%-30% | ONNX Runtime/TensorRT | 通用(CPU/GPU) | yolo export model=best.pt format=onnx |
| TensorRT | ↑50%-100%(GPU) | TensorRT | NVIDIA GPU | yolo export model=best.pt format=engine device=0 |
| OpenVINO | ↑30%-50%(CPU) | OpenVINO | Intel CPU / 集成显卡 | yolo export model=best.pt format=openvino |
| TensorFlow Lite | ↑40%-60%(移动端) | TFLite | 手机 / 边缘设备 | yolo export model=best.pt format=tflite int8=True |
关键说明:
- 导出 TensorRT 时需指定 GPU(
device=0),且需安装对应版本的 TensorRT; - 导出 OpenVINO 需安装
openvino-dev:pip install openvino-dev。
2. 推理参数优化(细节提升,无精度损失)
调整推理时的参数,减少不必要的计算:
| 优化参数 | 操作内容 | 速度提升 | 实操命令 / 代码 |
|---|---|---|---|
| 减小输入尺寸 | 将 imgsz 从 640→480/320(需是 32 的倍数) | ↑20%-40% | yolo predict model=best.pt source=test.jpg imgsz=480 |
| 调高置信度阈值 | 过滤低置信度预测框,减少 NMS 计算 | ↑5%-10% | yolo predict model=best.pt source=test.jpg conf=0.4 |
| 关闭不必要的后处理 | 如关闭可视化、只输出检测框坐标 | ↑3%-5% | yolo predict model=best.pt source=test.jpg save=False |
| 批处理推理 | 多张图片批量推理(而非单张) | ↑30%-50% | yolo predict model=best.pt source=test_dir/ batch=16 |
3. 推理框架优化(选择高效框架)
不同推理框架的效率差异显著,优先选择以下框架:
| 硬件类型 | 推荐推理框架 | 提速效果 | 实操代码(以 ONNX 模型为例) |
|---|---|---|---|
| NVIDIA GPU | TensorRT | ↑50%-100% | python<br>import tensorrt as trt<br>from ultralytics.utils import ops<br># 加载TensorRT引擎<br>engine = ops.load_engine("best.engine")<br># 推理<br>results = engine.infer(img)<br> |
| Intel CPU | OpenVINO | ↑30%-50% | python<br>from openvino.runtime import Core<br>core = Core()<br>model = core.read_model("best_openvino_model.xml")<br>compiled_model = core.compile_model(model, "CPU")<br># 推理<br>results = compiled_model([img])<br> |
| 通用硬件 | ONNX Runtime | ↑20%-30% | python<br>import onnxruntime as ort<br>sess = ort.InferenceSession("best.onnx")<br># 推理<br>results = sess.run(None, {"images": img})<br> |
三、硬件优化(底层,释放硬件算力)
硬件优化是在 "软件优化到位" 后,进一步释放硬件的算力潜力,适合对速度有极致要求的场景。
1. GPU 优化(NVIDIA 显卡)
| 优化手段 | 操作内容 | 提速效果 | 实操命令 |
|---|---|---|---|
| 开启 CUDA 推理 | 确保模型推理使用 GPU 而非 CPU | ↑100%-200% | 推理时指定device=0:yolo predict model=best.pt source=test.jpg device=0 |
| 开启 TensorRT 加速 | 结合模型导出为 engine 格式,最大化 GPU 算力 | ↑50%-100% | 见 "推理优化 - 导出为高效格式" |
| 调整 GPU 批量大小 | 适配 GPU 显存,最大化并行计算 | ↑10%-20% | 批量推理时设置batch=32/64(根据显存调整) |
| 开启 FP16 推理 | GPU 对 FP16 的计算效率远高于 FP32 | ↑20%-30% | 导出模型时指定half=True:yolo export model=best.pt format=onnx half=True |
2. 边缘设备优化(Jetson / 手机)
| 硬件类型 | 优化手段 | 提速效果 | 实操方法 |
|---|---|---|---|
| NVIDIA Jetson(Nano/Xavier) | 1. 导出为 TensorRT 格式;2. 开启 JetPack 加速;3. 使用 INT8 量化 | ↑50%-80% | 1. 安装 JetPack 对应版本;2. yolo export model=best.pt format=engine device=0 int8=True |
| 手机(Android/iOS) | 1. 导出为 TFLite 格式(INT8);2. 使用 NNAPI/CORE ML 加速 | ↑40%-60% | 1. 导出 TFLite:yolo export model=best.pt format=tflite int8=True;2. 集成到手机 APP 时调用 NNAPI 接口 |
| 嵌入式 CPU(如树莓派) | 1. 使用 YOLOv8n 模型;2. 导出为 OpenVINO 格式;3. 开启多线程推理 | ↑30%-50% | 1. yolo export model=best.pt format=openvino;2. 推理时设置threads=4(根据 CPU 核心数) |
3. 通用硬件优化
| 优化手段 | 操作内容 | 提速效果 | 实操方法 |
|---|---|---|---|
| 开启多线程推理 | 利用 CPU 多核并行计算 | ↑20%-30% | 推理时设置threads参数:yolo predict model=best.pt source=test.jpg threads=8 |
| 关闭硬件节能模式 | 避免 CPU/GPU 降频 | ↑5%-10% | 1. CPU:关闭 intel_pstate 节能;2. GPU:NVIDIA 显卡设置 "高性能模式" |
| 使用 SSD 硬盘 | 减少图片 / 模型加载耗时 | ↑3%-5% | 将数据集、模型文件放在 SSD 上,而非 HDD |
四、速度优化实操流程(按优先级)
- 基线测试:先测试原始模型的推理速度(FPS)和精度(mAP@0.5),记录基线数据;
- 模型轻量化 :
- 第一步:替换为 YOLOv8n/YOLOv8s(最简单,优先做);
- 第二步:对模型进行 INT8 量化(训练后量化);
- 推理优化 :
- 第一步:导出为 ONNX/TensorRT/OpenVINO 格式;
- 第二步:调整推理参数(减小 imgsz、调高 conf 阈值);
- 硬件优化 :
- 第一步:确保使用 GPU 推理(指定 device=0);
- 第二步:开启 TensorRT/OpenVINO 加速;
- 验证平衡:每一步优化后,验证精度损失是否≤3%,若超标则调整轻量化策略(如降低剪枝比例、改用 FP16 量化)。
速度 / 精度平衡示例(YOLOv8s→YOLOv8n + 量化)
| 优化阶段 | FPS(RTX3060) | mAP@0.5 | 速度提升 | 精度损失 |
|---|---|---|---|---|
| 原始 YOLOv8s(FP32) | 60 | 0.88 | - | - |
| 替换为 YOLOv8n(FP32) | 110 | 0.81 | ↑83% | 7% |
| YOLOv8n + INT8 量化 | 140 | 0.79 | ↑133% | 9% |
| YOLOv8n + INT8 + TensorRT | 180 | 0.78 | ↑200% | 10% |
| 蒸馏后 YOLOv8n + INT8 + TensorRT | 175 | 0.82 | ↑192% | 6% |
五、常见速度问题与对应优化方案(速查表)
| 问题现象 | 核心原因 | 优先优化维度 | 具体方案 |
|---|---|---|---|
| 推理速度慢,CPU 占用高 | 未使用 GPU 推理 | 硬件层 → 推理层 | 1. 指定device=0使用 GPU;2. 导出为 TensorRT 格式。 |
| 移动端推理卡顿 | 模型过大 / 精度过高 | 模型层 → 推理层 | 1. 换 YOLOv8n 模型;2. 导出为 TFLite INT8 格式;3. 减小 imgsz 到 320。 |
| GPU 推理速度未达预期 | 未开启 TensorRT 加速 | 推理层 → 硬件层 | 1. 导出为 engine 格式;2. 开启 FP16 推理;3. 调整 batch 大小。 |
| 批量推理速度慢 | batch 大小适配不当 | 推理层 → 硬件层 | 1. 根据 GPU 显存调整 batch(8G 显存→batch=16);2. 开启梯度累加(仅训练)。 |
| 精度损失过高(>5%) | 轻量化过度 | 模型层 | 1. 降低剪枝 / 量化比例;2. 改用知识蒸馏恢复精度;3. 换稍大的模型(如 YOLOv8n→YOLOv8s)。 |
总结
核心优化要点
- 模型层:优先选官方轻量化模型(YOLOv8n/s),其次用 INT8 量化(训练后量化简单易操作),剪枝需配合微调;
- 推理层:导出为高效格式(TensorRT/GPU、OpenVINO/Intel CPU、TFLite / 移动端),调整推理参数(imgsz/conf);
- 硬件层:确保使用 GPU 推理,边缘设备适配专属加速框架(TensorRT/NNAPI)。
优化原则
- 小步迭代:每一步优化后验证速度 / 精度,避免过度优化导致精度不达标;
- 成本优先:先做软件优化(模型 / 推理),再做硬件优化(硬件升级成本高);
- 场景适配:移动端优先 YOLOv8n+TFLite INT8,服务器端优先 YOLOv8s+TensorRT FP16。