目录
[2.1、单 GPU 和 CPU 训练示例](#2.1、单 GPU 和 CPU 训练示例)
[2.2、多 GPU 训练](#2.2、多 GPU 训练)
[2.3、空闲 GPU 训练](#2.3、空闲 GPU 训练)
[2.6.5.2、混淆矩阵 (confusion_matrix.png )](#2.6.5.2、混淆矩阵 (confusion_matrix.png ))
2.6.5.3、精确率-置信度曲线(BoxP_curve.png)
{kind=link}
2.6.5.4、召回率-置信度曲线(BoxR_curve.png)
{kind=link}
2.6.5.5、精确率-召回率曲线(BoxPR_curve.png)
{kind=link}
2.6.5.6、F1-置信度曲线(BoxF1_curve.png)
{kind=link}
{kind=link}
{kind=link}
[2.6.5.11、weights 文件夹](#2.6.5.11、weights 文件夹)
一、数据集
训练一个强大而准确的对象检测模型需要一个全面的数据集。
YOLO官方支持两种结构的数据集格式
1.1、第一种结构(YOLOv5风格)
dataset/
├── train/
│ ├── images/
│ │ ├── 0001.jpg
│ │ └── ...
│ └── labels/
│ ├── 0001.txt
│ └── ...
├── valid/
│ ├── images/
│ └── labels/
└── test/
├── images/
└── labels/配置文件(data.yaml)
train: ../train/images
val: ../valid/images
test: ../test/images
nc: 2
names: ['fire', 'smoke']1.2、第二种结构(YOLOv8风格)
dataset/
├── images/
│ ├── train/
│ │ ├── 0001.jpg
│ │ └── ...
│ ├── val/
│ │ ├── 0002.jpg
│ │ └── ...
│ └── test/
│ ├── 0003.jpg
│ └── ...
└── labels/
├── train/
│ ├── 0001.txt
│ └── ...
├── val/
│ ├── 0002.txt
│ └── ...
└── test/
├── 0003.txt
└── ...配置文件(data.yaml):
path: ../dataset # 数据集根目录
train: images/train
val: images/val
test: images/test
names:
0: fire
1: smoke1.3、两种结构的本质区别
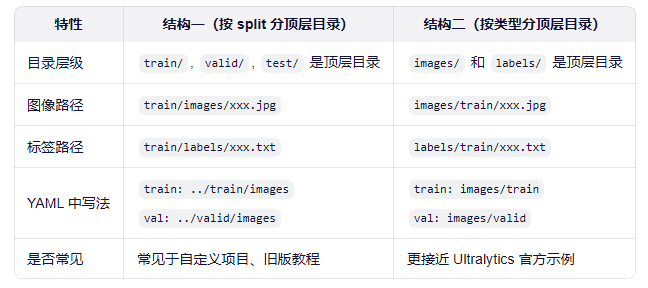
1.4、为什么两种都能用
因为 YOLO 加载数据时的逻辑是:
- 读取 YAML 中的 train: xxx 路径 → 得到图像列表;
- 对每个图像路径(如 images/train/001.jpg),将 images 替换为 labels,.jpg 替换为 .txt,得到标签路径;
- 所以只要你的目录满足这个映射关系,就能工作。
因此:
- 结构一:图像在 train/images/001.jpg → 标签必须在 train/labels/001.txt
→ 但此时 YAML 写 train: train/images,YOLO 会去找 train/labels,也能匹配上。
- 结构二:图像在 images/train/001.jpg → 标签在 labels/train/001.txt
→ YAML 写 train: images/train,YOLO 自动找 labels/train,符合官方默认逻辑。
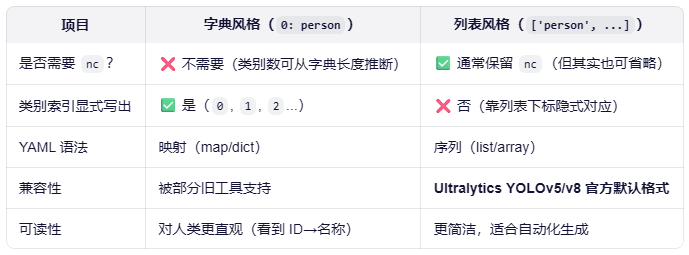
1.5、配置文件要不要写nc
写法一(字典风格,常见于 COCO 风格或旧版 YOLO):
names:
0: person
1: bicycle
2: car写法二(列表风格,Ultralytics YOLOv5/v8 官方推荐):
nc: 3
names: ['person', 'bicycle', 'car']它们有什么不同?
1.6、标签文件txt格式
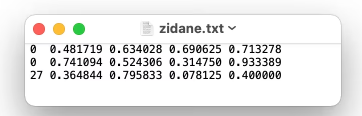
每张图片配一个同名的 .txt 文件,里面每一行描述一个目标物体,格式是:
"类别编号 中心x 中心y 宽度 高度",所有数字都要变成 0 到 1 之间的小数(框坐标必须在 归一化 xywh 格式从 0 到 1)。
举个例子:
假设你有一张图片叫 fire_001.jpg,尺寸是 800 像素宽 × 600 像素高。
图中有一个火焰,它的矩形框在图像上的位置如下(单位:像素):
- 左上角:(200, 150)
- 右下角:(400, 300)
那么这个框的:
- 宽度 = 400 - 200 = 200 像素
- 高度 = 300 - 150 = 150 像素
- 中心点 x = (200 + 400) / 2 = 300 像素
- 中心点 y = (150 + 300) / 2 = 225 像素
现在,把它们归一化(变成 0~1 的小数):
- 归一化 x_center = 300 / 800 = 0.375
- 归一化 y_center = 225 / 600 = 0.375
- 归一化 width = 200 / 800 = 0.25
- 归一化 height = 150 / 600 = 0.25
再假设你的类别定义是:
- 0 = 火焰(fire)
- 1 = 烟雾(smoke)
因为这是火焰,所以类别编号是 0。
那么 fire_001.txt 文件内容就只有一行:
0 0.375 0.375 0.25 0.25重要规则(记住这几点就行)
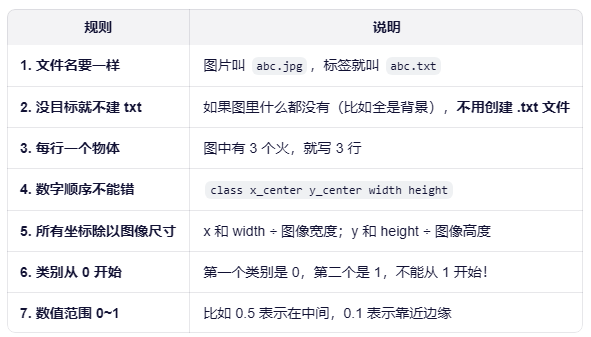
再举个"多目标"例子
图片:scene.jpg(1000×800 像素)
里面有:
- 个火焰(类别 0),框归一化后:0 0.2 0.3 0.1 0.15
- 个烟雾(类别 1),框归一化后:1 0.6 0.5 0.2 0.25
那么 scene.txt 内容就是:
0 0.2 0.3 0.1 0.15
1 0.6 0.5 0.2 0.25官方示例:对象检测数据集概述 - Ultralytics YOLO 文档
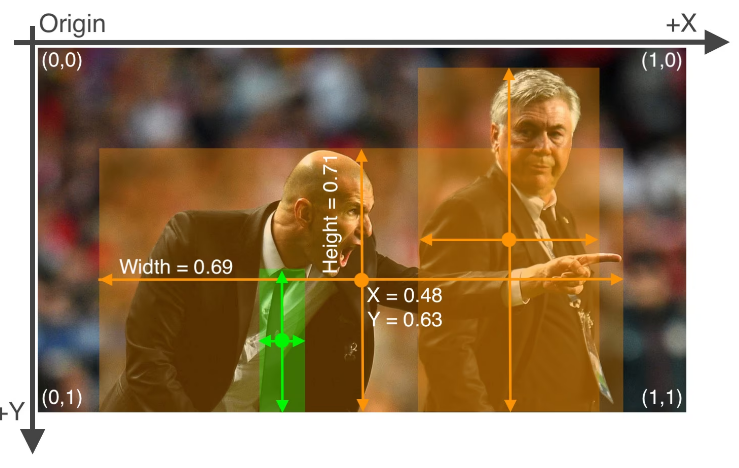
与上述图像对应的标签文件包含 2 个人(类别 0)和一条领带(类别 27):
根据上面规则,自开发了一个标注工具
【标注工具 01】labelfast标注工具使用指南(支持YOLO\COCO\VOC格式)-CSDN博客
二、训练
Ultralytics 提供了两种命令python与CLI,本文使用python,详细文档请看使用 Ultralytics YOLO 进行模型训练 - Ultralytics YOLO 文档
2.1、单 GPU 和 CPU 训练示例
设备自动确定。如果GPU可用,将使用GPU(默认CUDA设备0);否则训练将在CPU上开始。
示例代码:
python
from ultralytics import YOLO # 导入YOLO模型类
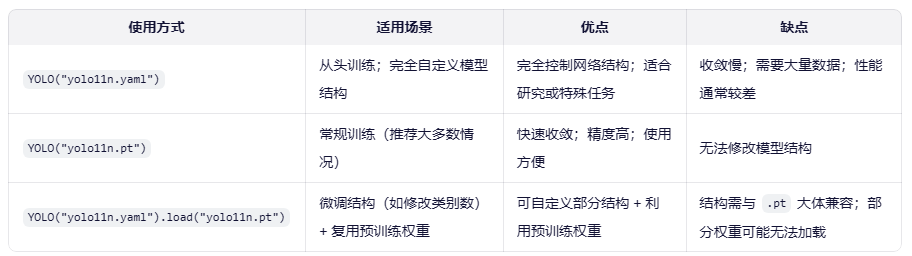
# 加载模型的三种方式
model = YOLO("yolo11n.yaml") # 从YAML配置文件构建新模型
model = YOLO("yolo11n.pt") # 加载预训练模型(推荐用于训练)
model = YOLO("yolo11n.yaml").load("yolo11n.pt") # 从YAML构建模型并加载预训练权重
# 训练模型
results = model.train(data="coco8.yaml", epochs=100, imgsz=640) # 使用coco8数据集训练100轮,图像尺寸640YOLO 模型训练使用的三种初始化的对比
2.2、多 GPU 训练
通过将训练负载分配到多个 GPU 上,多 GPU 训练可以更有效地利用可用的硬件资源。此功能可通过 python API 和命令行界面使用。要启用多 GPU 训练,请指定您希望使用的 GPU 设备 ID。
示例代码:
python
from ultralytics import YOLO # 导入YOLO模型类
# 加载模型
model = YOLO("yolo11n.pt") # 加载预训练模型(推荐用于训练)
# 使用2个GPU训练模型
results = model.train(data="coco8.yaml", epochs=100, imgsz=640, device=[0, 1]) # 指定使用GPU 0和GPU 1进行训练
# 使用两个最空闲的GPU训练模型
results = model.train(data="coco8.yaml", epochs=100, imgsz=640, device=[-1, -1]) # 自动选择两个最空闲的GPU进行训练2.3、空闲 GPU 训练
空闲 GPU 训练支持自动选择多 GPU 系统中利用率最低的 GPU,从而优化资源使用,而无需手动选择 GPU。此功能根据利用率指标和 VRAM 可用性识别可用的 GPU。
示例代码:
python
from ultralytics import YOLO # 导入YOLO模型类
# 加载模型
model = YOLO("yolo11n.pt") # 加载预训练模型(推荐用于训练)
# 使用单个最空闲的GPU进行训练
results = model.train(data="coco8.yaml", epochs=100, imgsz=640, device=-1) # 自动选择最空闲的单个GPU进行训练
# 使用两个最空闲的GPU进行训练
results = model.train(data="coco8.yaml", epochs=100, imgsz=640, device=[-1, -1]) # 自动选择两个最空闲的GPU进行训练2.4、恢复中断的训练
例如当训练过程意外中断时,或者当您希望使用新数据或更多 epoch 继续训练模型时。
当训练恢复时,Ultralytics YOLO 会从上次保存的模型加载权重,还会恢复优化器状态、学习率调度器和 epoch 编号。这使您可以从中断的地方无缝地继续训练过程。
以下是如何使用 python 和通过命令行恢复中断训练的示例:
python
from ultralytics import YOLO
# Load a model
model = YOLO("path/to/last.pt")
# Resume training
results = model.train(resume=True)通过设置 resume=True, train 函数将从上次停止的地方继续训练,使用存储在 'path\/to\/last.pt' 文件中的状态。如果省略 resume 参数或将其设置为 False, train ,该函数将启动新的训练会话。
请记住,默认情况下,检查点会在每个 epoch 结束时保存,或者使用 save_period 参数按固定间隔保存,因此您必须至少完成 1 个 epoch 才能恢复训练运行。
2.5、训练参数设置
YOLO 模型的训练设置包括训练过程中使用的各种超参数和配置。这些设置会影响模型的性能、速度和准确性。关键训练设置包括批量大小、学习率、动量和权重衰减。此外,优化器的选择、损失函数和训练数据集组成会影响训练过程。
基本参数:
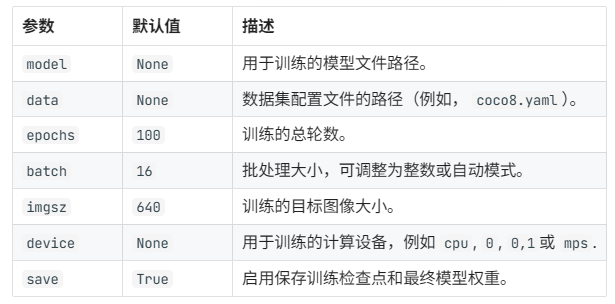
主要参数:
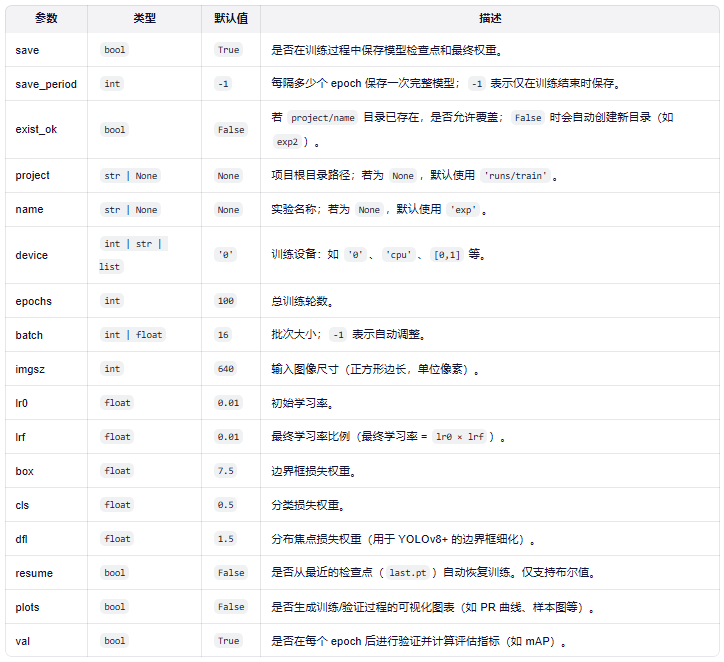
详细参数:使用 Ultralytics YOLO 进行模型训练 - Ultralytics YOLO 文档
2.6、训练实例(烟火)
2.6.1、训练代码
python
from ultralytics import YOLO
import torch
if __name__ == "__main__":
# 定义模型路径
model_path="model/yolo11s.pt" # 预训练模型权重文件路径
model_yaml_path="yolo11s.yaml" # 模型配置文件路径(备用)
# 初始化YOLO模型
model = YOLO(model_path) # 加载预训练模型
# model = YOLO(model_yaml_path) # 可选:从YAML配置文件构建新模型
# model = YOLO(model_yaml_path).load(model_path) # 可选:从YAML构建并加载预训练权重
# 设置训练参数
data_path = 'D:/datasets/FireSmoke/data.yaml' # 数据集配置文件路径
project="runs/train" # 训练结果保存的项目目录
name = "train_fire" # 训练任务名称
# 执行模型训练
results = model.train(
data=data_path, # 数据集配置文件
epochs=100, # 训练轮数
imgsz=640, # 图像尺寸
batch=16, # 批次大小
device=0 if torch.cuda.is_available() else 'cpu', # 使用GPU或CPU
project=project, # 项目保存路径
name=name, # 项目名称
patience=50, # 早停轮数
plots=True, # 生成训练图表
exist_ok=False, # 是否覆盖现有项目
profile= True, # 是否进行性能测试
lr0=0.01, # 初始学习率
lrf=0.01, # 学习率衰减率
box=7.5, # 框损失权重
nbs=64, # 损失归一化的标称批量大小
)
print("模型训练完成!") # 训练完成提示2.6.2、数据集配置
数据集类型采用YOLOV5风格
python
dataset/
├── train/
│ ├── images/
│ │ ├── fire_smoke__00001.jpg
│ │ └── ...
│ └── labels/
│ ├── fire_smoke__00001.txt
│ └── ...
├── valid/
│ ├── images/
│ └── labels/
└── test/
├── images/
└── labels/data.yaml
python
train: D:/work/my/datasets/FireSmoke/train/images
val: D:/work/my/datasets/FireSmoke/valid/images
test: D:/work/my/datasets/FireSmoke/test/images
nc: 2
names: ['fire', 'smoke']
labelfast:
version: 1.32.6.3、虚拟环境配置
打开 PyCharm IDE ,下载最新的Ultralytics 代码,拷贝到工程里
ultralytics/ultralytics: Ultralytics YOLO 🚀
虚拟环境创建python 解析器
安装依赖库
python
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple/
python
torch torchvision torchaudio onnxruntime 安装
CPU 版本
pip install torch==2.5.1 torchvision==0.20.1 torchaudio==2.5.1 --index-url https://pypi.tuna.tsinghua.edu.cn/simple
pip install onnxruntime==1.19.0 -i https://pypi.tuna.tsinghua.edu.cn/simple/
GPU 版本 根据自己的gpu 选择对应的CUDA
pip install torch==2.5.1+cu121 torchvision==0.20.1+cu121 torchaudio==2.5.1+cu121 --extra-index-url https://download.pytorch.org/whl/cu121
pip install onnxruntime-gpu==1.19.0 -i https://pypi.tuna.tsinghua.edu.cn/simple/2.6.4、开始训练
出现Epoch,则表示开始进行训练,此处演示,只使用1一个轮次。
2.6.5、训练结果

2.6.5.1、训练参数存档(args.yaml)
记录本次训练的所有参数,包括:训练轮数(epochs)、学习率(lr0)、图像尺寸(imgsz)、数据路径等关键设置
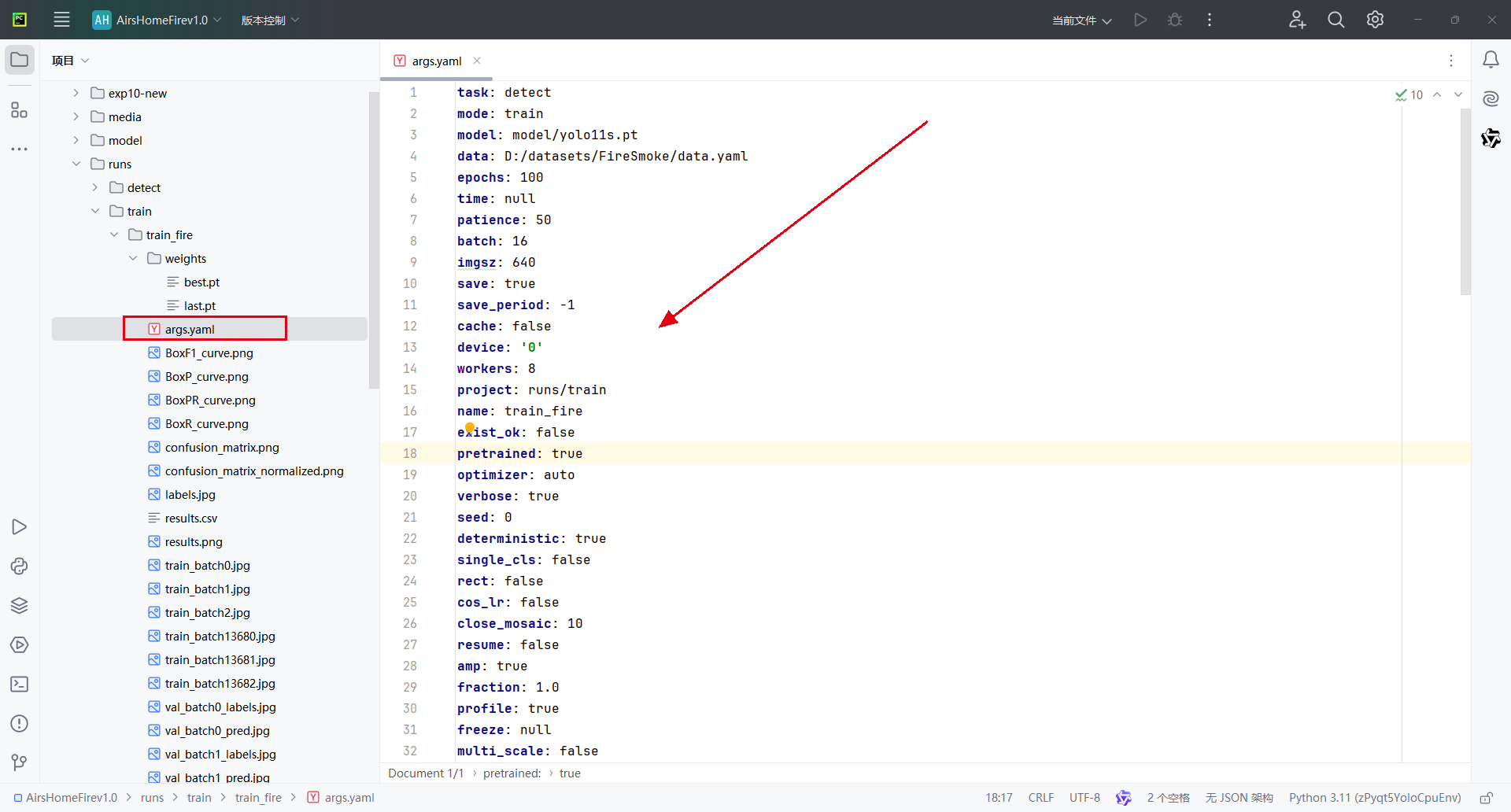
作用:验证实验是否按预期配置;便于复现或调参。
2.6.5.2、混淆矩阵 (confusion_matrix.png )
混淆矩阵详解:confusion_matrix.png 与 confusion_matrix_normalized.png
1、什么是混淆矩阵?它有什么用?
在目标检测任务中,混淆矩阵(Confusion Matrix)是一种用于评估模型分类准确性的核心可视化工具。
它统计的是:在整个验证集上,每个真实目标(ground truth)被模型预测成什么类别。
虽然目标检测同时涉及定位(bounding box)和分类,但混淆矩阵只关注分类部分(前提是预测框与真实框的 IoU ≥ 0.5(默认值,训练可以设置),即定位基本正确)。
通过混淆矩阵,我们可以:
- 看出哪些类别容易被正确识别;
- 发现哪些类别经常被互相混淆;
- 分析模型对正常样本的误报或漏检情况。
2、TP、FP、TN、FN 定义(通俗易懂的描述)
在二分类或多分类评估中,针对某一特定类别(如 "fire"),定义四个基本指标:
TP(True Positive,真阳性):
真实是该类,模型也预测为该类 → 正确识别。
例如:真实是火,预测也是火。
FP(False Positive,假阳性):
真实不是该类,但模型错误预测为该类 → 误报。
例如:真实是背景,却被预测为火。
FN(False Negative,假阴性):
真实是该类,但模型没有预测为该类(预测为其他类或未检出)→ 漏检。
例如:真实是烟,但模型没检测到(归为 background)。
TN(True Negative,真阴性):
真实不是该类,模型也没有预测为该类 → 正确拒绝。
例如:真实是背景,模型也没说它是火。
注意:在目标检测中,TN 难以准确定义(因背景区域无限),通常不用于实际评估。
3、精确率与召回率的计算公式
召回率(Recall):
衡量"所有真实目标中,有多少被找出来了?"
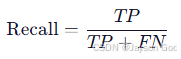
反映漏检程度,越高越好。
精确率(Precision):
衡量"所有预测为目标的结果中,有多少是真的?"
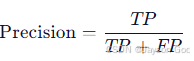
反映误报程度,越高越好。
在目标检测中,mAP(mean Average Precision)等核心指标正是基于 Precision 和 Recall 构建的。
4、混淆矩阵的结构:行 vs 列
以实际例子烟火训练的混淆矩阵:左边图是原始计数,右边图是归一化比例
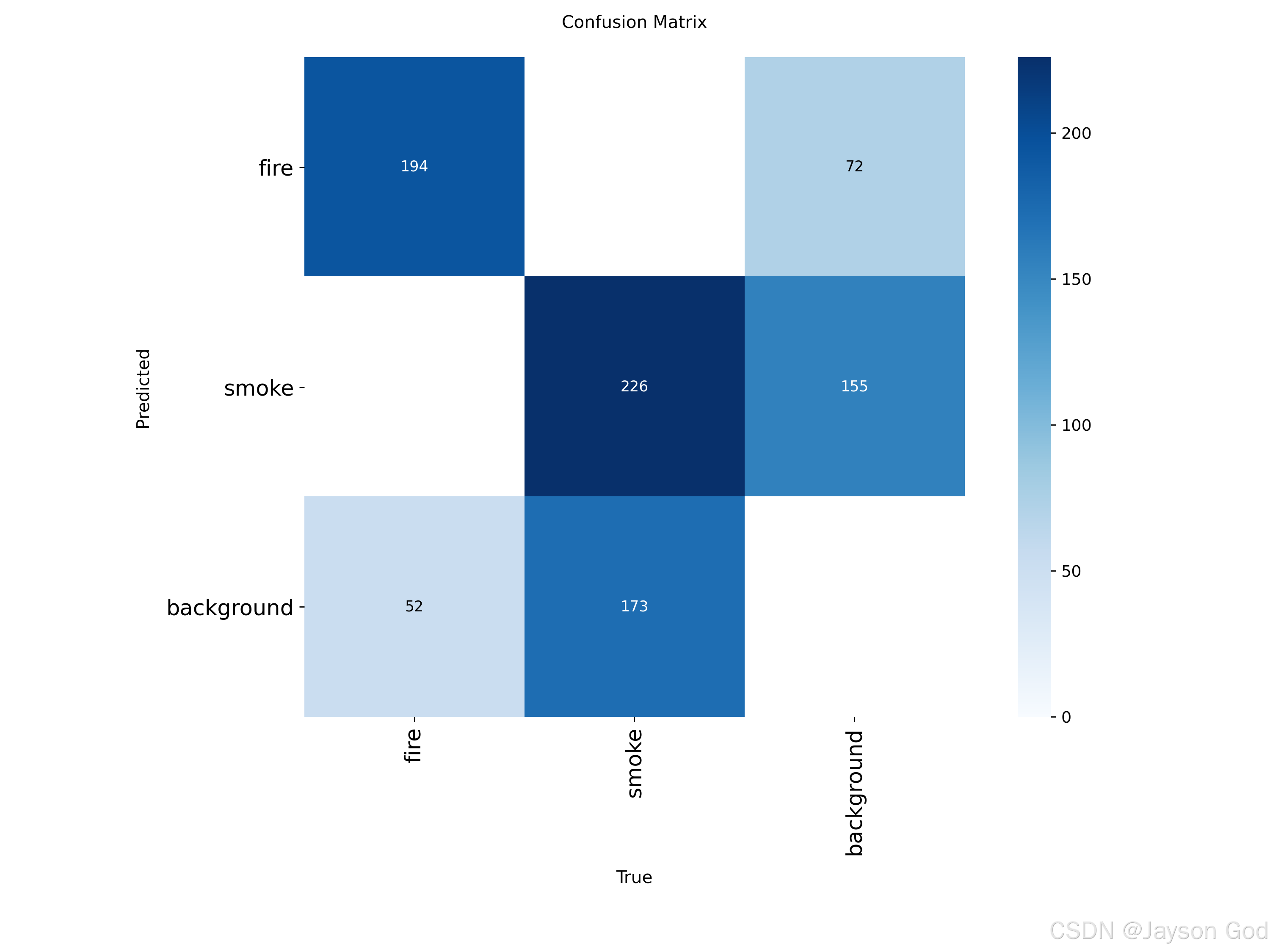
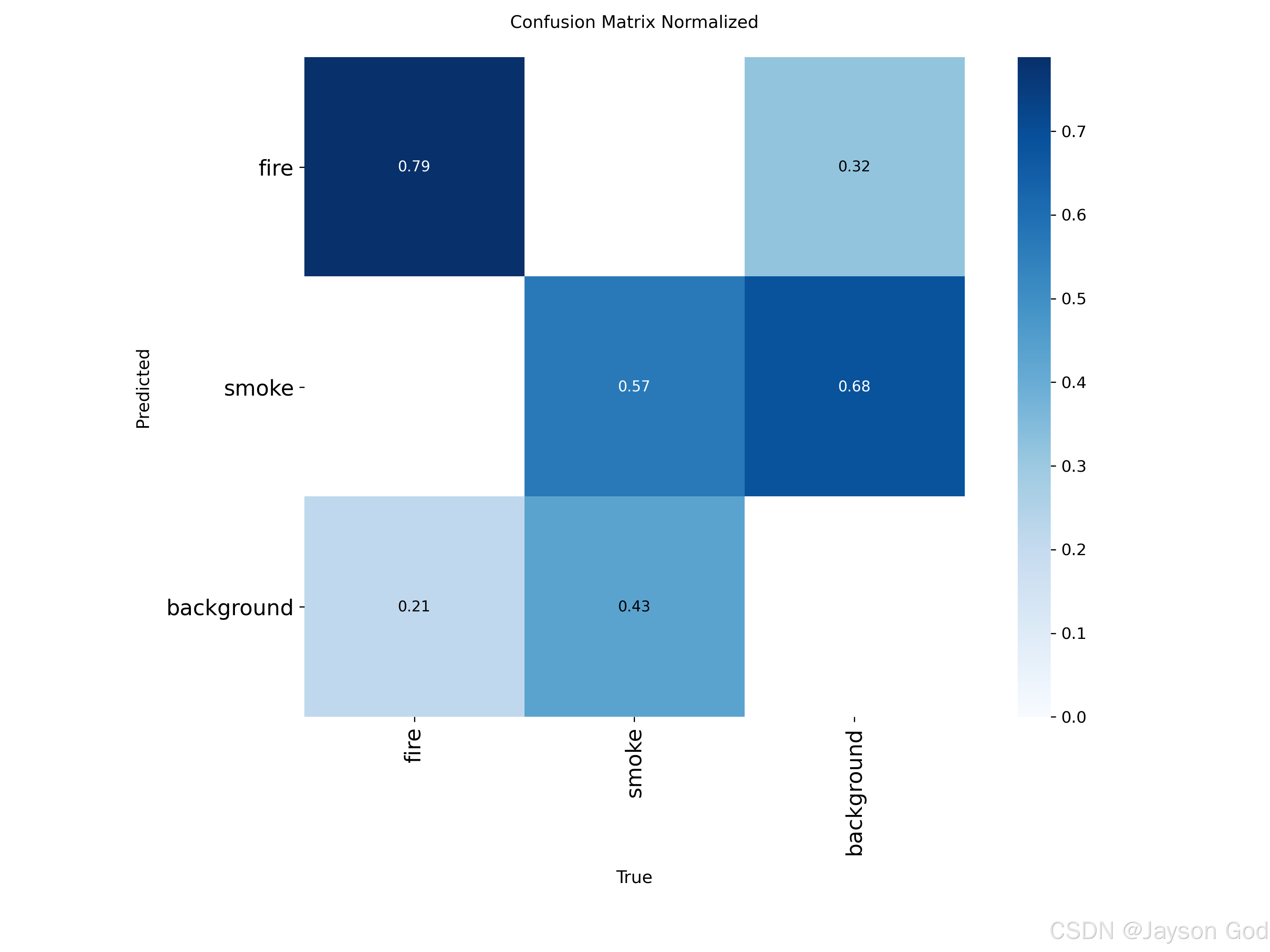
转成表格
|-------|------------|------|-------|------------|
| 预测类别↓ | fire | 194 | 0 | 72 |
| 预测类别↓ | smoke | 0 | 226 | 155 |
| 预测类别↓ | background | 52 | 173 | 0 |
| || fire | smoke | background |
| || 真实类别 → |||
关键规则:
列 (黄色)= 真实类别(Ground Truth)
行 (绿色)= 预测类别(Prediction)
单元格 (i, j) = 被预测为第 i 类,真实为第 j 类的目标数量
具体单元格含义
| 单元格(行, 列) | 数值 | 正确含义 |
|---|---|---|
| (fire, fire) | 194 | 真实是 fire,预测为 fire → TP_fire(正确识别火) |
| (fire, smoke) | 0 | 真实是 smoke,预测为 fire → smoke 被错判为 fire 的数量 = 0 |
| (fire, background) | 72 | 真实是 background,预测为 fire → FP_fire(在正常图像上误报火) |
| (smoke, fire) | 0 | 真实是 fire,预测为 smoke → fire 被错判为 smoke 的数量 = 0 |
| (smoke, smoke) | 226 | 真实是 smoke,预测为 smoke → TP_smoke(正确识别烟) |
| (smoke, background) | 155 | 真实是 background,预测为 smoke → FP_smoke(在正常图像上误报烟) |
| (background, fire) | 52 | 真实是 fire,未被检出 → FN_fire(火漏检) |
| (background, smoke) | 173 | 真实是 smoke,未被检出 → FN_smoke(烟漏检) |
| (background, background) | 0 | 真实是 background,预测为 background → 理论上应为"正确识别正常场景",但在目标检测中: • 模型不会主动预测 background; • 所有无目标区域默认不产生预测框; • 因此该值恒为 0 或空白,不参与评估 |
5、两张图的区别
confusion_matrix.png(原始计数)
- 显示绝对数量(整数)
- 适合了解各类别预测的实际分布
- 颜色深浅反映数量多少
confusion_matrix_normalized.png(归一化比例)
- 显示比例(0~1),按列归一化(column-wise)
- 即:每一列(真实类别)之和 = 1
- 公式:
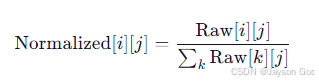
示例:归一化 smoke 列(真实=smoke)
原始列值:
- fire 行:0
- smoke 行:226
- background 行:173
总和 = 0 + 226 + 173 = 399
归一化后:
- smoke 行:226 / 399 ≈ 0.566(56.6% 正确识别)
- background 行:173 / 399 ≈ 0.434(43.4% 漏检)
- fire 行:0 → 无错分为火
说明:烟雾漏检率高达 43.4%,但几乎不会被错认为火。
6、如何从混淆矩阵计算 TP / FP / FN / TN?(按类别)
所有指标均针对单个类别,采用 "one-vs-rest" 方式定义。
以 fire 类为例:
| 指标 | 含义 | 计算方式 | 数值 |
|---|---|---|---|
| TP(True Positive,真阳性) | 真实是 fire,预测也是 fire | 对角线 = 第1行第1列 | 194 |
| FP(False Positive,假阳性) | 真实不是 fire,但预测为 fire | 第1行(预测=fire)中,除第1列外的和: • smoke 列:0 • background 列:72 | 0 + 72 = 72 |
| FN(False Negative,假阴性) | 真实是 fire,但预测不是 fire | 第1列(真实=fire)中,除第1行外的和: • smoke 行:0 • background 行:52 | 0 + 52 = 52 |
| TN(True Negative,真阴性) | 真实不是 fire,且预测也不是 fire | 所有非 fire 真实样本中,未被预测为 fire 的数量: • smoke 列中非 fire 行:226(smoke)+ 173(background)= 399 • background 列中非 fire 行:155(smoke)+ 0(background)= 155 → TN = 399 + 155 = 554 | 554 |
关于 TN 的说明:
虽然 TN 可在此封闭矩阵中计算为 554,但在目标检测中,该值不反映真实负样本判别能力,因为:
- 大量背景区域未生成预测框,未被统计;
- 主流指标(Precision、Recall、mAP)均不使用 TN;
- TN 仅用于理论完整性,实际评估中忽略。
7、各类别 TP / FP / FN 统计表
| 类别 | TP(真阳性) | FP(假阳性) | FN(假阴性) | 真实总数 (TP+FN) | 预测总数 (TP+FP) |
|---|---|---|---|---|---|
| fire | 194 | 0(smoke)+ 72(background) = 72 | 0(smoke)+ 52(background) = 52 | 246 | 266 |
| smoke | 226 | 0(fire)+ 155(background) = 155 | 0(fire)+ 173(background) = 173 | 399 | 381 |
说明:
- FP 主要来自 background 列 → 模型在正常图像上误报烟火;
- FN 全部来自 background 行 → 无类别间错分,只有漏检;
- 无 fire ↔ smoke 互相错分(非对角线交叉项均为 0),说明两类特征区分度高。
8、关于 background(背景)的特殊说明
- background 列(72 + 155 = 227):表示模型在无烟火图像上共产生 227 个误报(72 个火 + 155 个烟);
- background 行(52 + 173 = 225):表示共 225 个真实烟火目标未被检出(52 火 + 173 烟);
- 右下角为 0:因模型不主动预测 background,故无"正确识别背景"的统计。
9、召回率、精确率计算
基于混淆矩阵统计结果,各类别的召回率(Recall)与精确率(Precision)计算如下:
| 类别 | TP(真阳性) | FN(假阴性) | FP(假阳性) | 真实总数(TP + FN) | 预测总数(TP + FP) | 召回率(Recall = TP / (TP + FN)) | 精确率(Precision = TP / (TP + FP)) |
|---|---|---|---|---|---|---|---|
| fire | 194 | 52 | 72 | 194 + 52 = 246 | 194 + 72 = 266 | 194 / 246 ≈ 78.9% | 194 / 266 ≈ 72.9% |
| smoke | 226 | 173 | 155 | 226 + 173 = 399 | 226 + 155 = 381 | 226 / 399 ≈ 56.6% | 226 / 381 ≈ 59.3% |
2.6.5.3、精确率-置信度曲线(BoxP_curve.png)
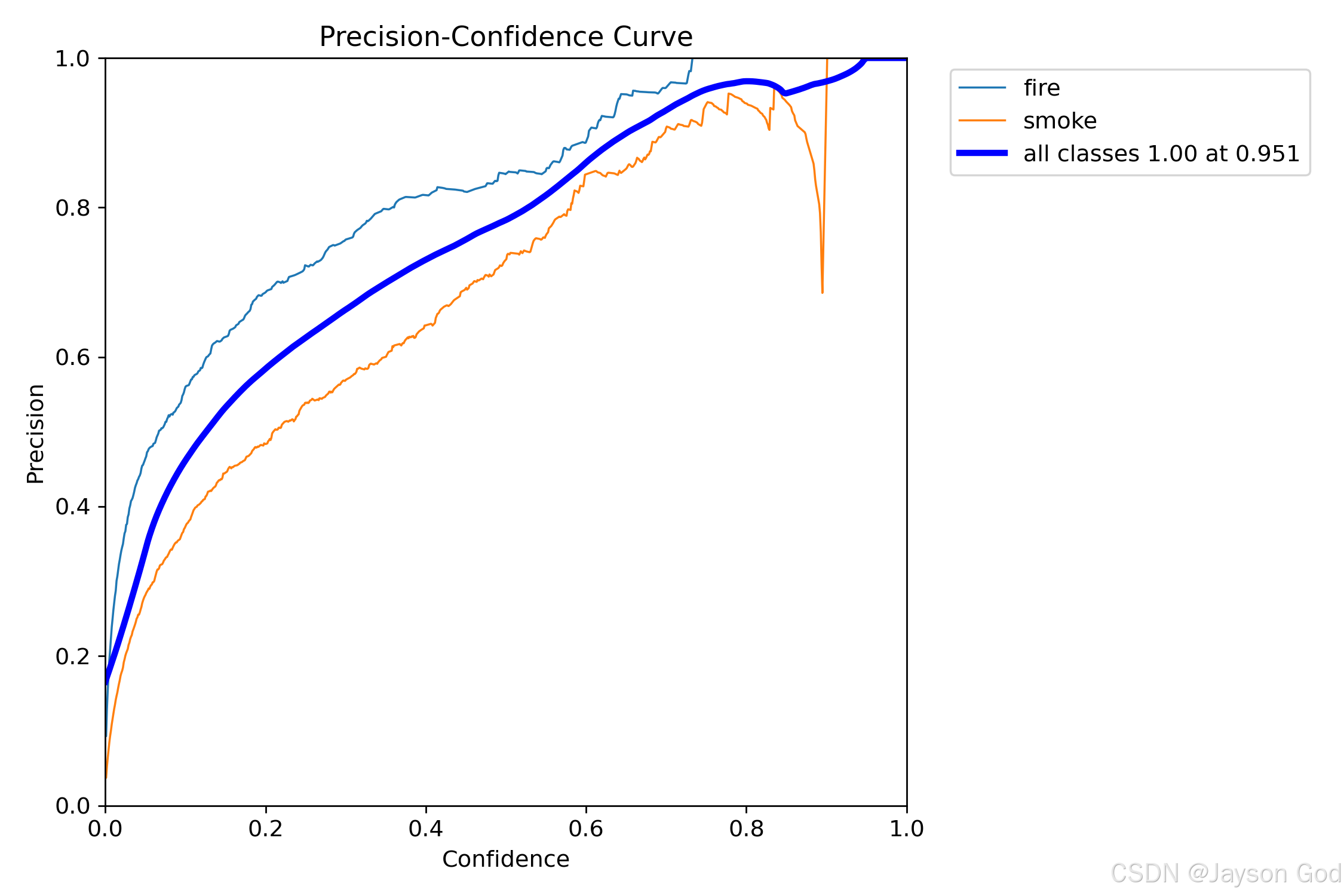
1、什么是 Precision-Confidence 曲线?
Precision-Confidence 曲线反映了模型在不同置信度阈值(Confidence)下的精确率(Precision)表现,纵轴为精确率,横轴为置信度阈值,每一条曲线代表一个类别的表现。
精确率(Precision) 是指:在所有被模型预测为正类的样本中,有多少是真正正确的。

它衡量的是"预测结果的可靠性",越高越好。
当置信度逐渐升高时,只有高置信度的预测被保留,因此 FP 减少,Precision 通常会提升。
2、图中内容解读
图中展示了 3 个类别(fire、smoke 和 all classes)在不同置信度阈值下的精确率变化曲线:
fire(蓝色虚线)------ 火焰检测
- 曲线整体上升趋势平滑,且在较高置信度下仍保持稳定;
- 在置信度 > 0.7 时,精确率接近 1.0;
- 表明火焰检测的误报率极低,模型对火的判断非常可靠;
- 即使在高置信度下,仍能保持高精度,说明火的特征清晰、不易混淆。
结论:火焰检测具有很高的精确性,适合用于高安全要求场景。
smoke(橙色实线)------ 烟雾检测
- 曲线上升较慢,且在置信度接近 0.9 时出现剧烈波动甚至骤降;
- 在置信度 ≈ 0.85~0.9 之间,精确率突然下降 → 可能存在少量高置信度但错误的预测(如背景误判为烟);
- 整体低于 fire,说明烟雾检测更容易产生假阳性(FP);
- 高置信度下性能不稳定,可能因训练数据中弱烟雾样本不足或噪声干扰。
结论:烟雾检测的精确率相对较低,需优化模型鲁棒性或增加高质量标注数据。
all classes(深蓝色粗线)------ 所有类别平均
- 曲线呈平稳上升趋势,最终趋于 1.0;
- 最大精确率为 1.0,出现在置信度 0.951;
- 这意味着:当置信度设置为 0.951 时,模型输出的所有预测都是正确的(即无误报);
- 但由于此时召回率可能很低,实际应用中需权衡。
说明:all classes 曲线是综合性能体现,反映整体预测质量。
3、最佳阈值选择
图中标注 all classes 1.00 at 0.951 表示:
- 当置信度阈值设置为 0.951 时,所有类别的平均精确率达到 1.00;
- 此时模型输出的每一个预测都没有误报(FP = 0),即"零误报"状态;
- 但代价是:许多真实目标(尤其是低置信度的)被过滤掉 → 召回率(Recall)会显著下降。
建议:
- 若应用场景极度敏感于误报(如火灾报警系统不允许误触发),可将阈值设为 0.95 左右,实现"零误报";
- 若更关注检出能力(如监控系统需要尽可能发现所有烟火),则应降低阈值至 0.4~0.6 区间,以平衡精确率与召回率。
4、总结:
| 类别 | 精确率表现 | 关键问题 | 应用建议 |
|---|---|---|---|
| fire | 高,稳定 | --- | 推荐使用 0.7~0.8 阈值,兼顾精度与召回 |
| smoke | 中等,波动大 | 易误报,高置信度下不稳定 | 优化数据质量,避免过拟合噪声 |
| all classes | 最终可达 1.0 | 高阈值下漏检严重 | 根据业务需求选择阈值 |
一句话总结:
这张图告诉我们:火焰检测极其精准,烟雾检测易误报;若追求"零误报",可设阈值为 0.951,但会牺牲检出率。
2.6.5.4、召回率-置信度曲线(BoxR_curve.png)
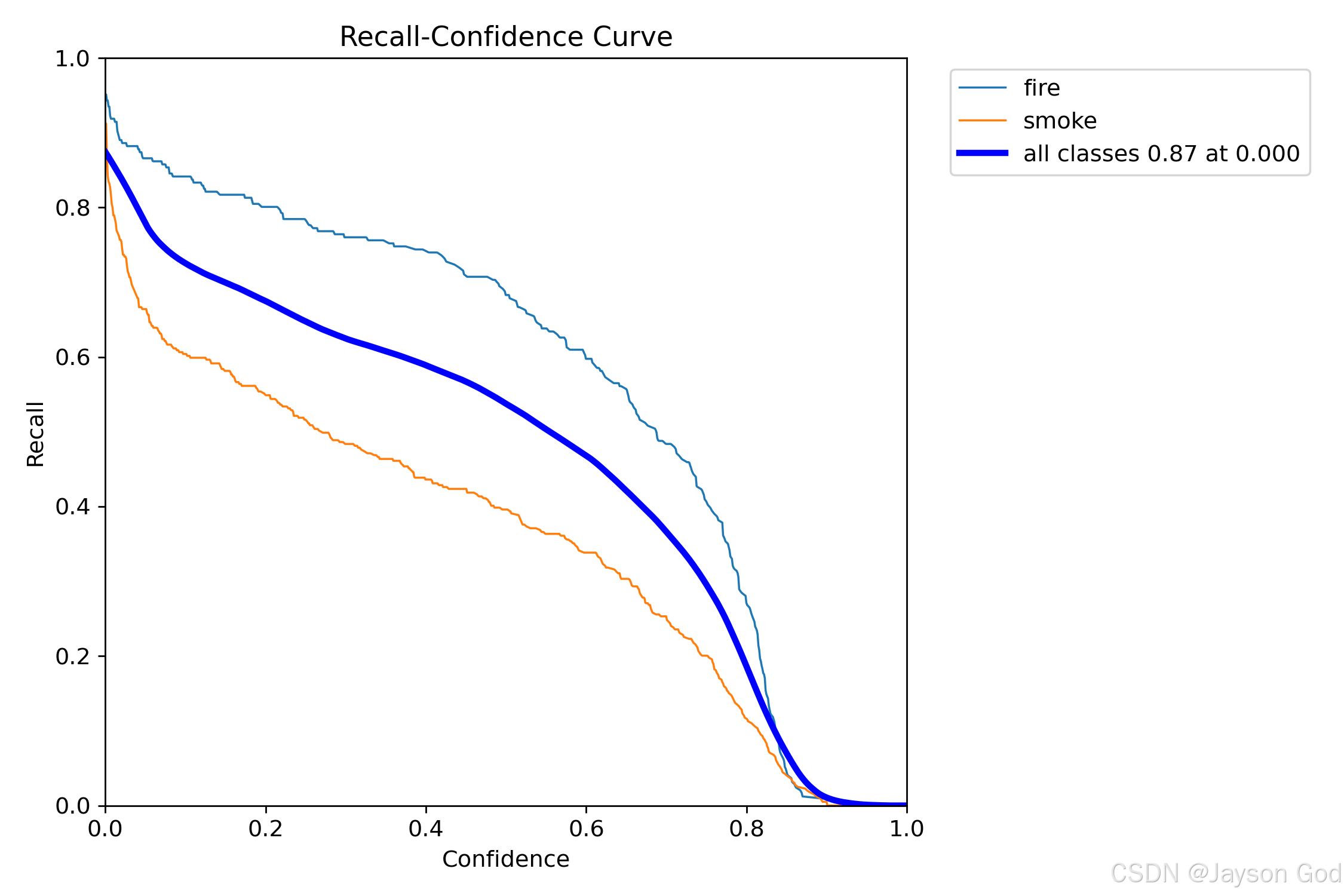
1、什么是 Recall-Confidence 曲线?
Recall-Confidence 曲线反映了模型在不同置信度阈值(Confidence)下的召回率(Recall)表现,纵轴为召回率,横轴为置信度阈值,每一条曲线代表一个类别的表现。
召回率(Recall) 是指:在所有真实存在的目标中,有多少被模型成功检测到。
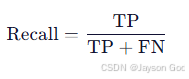
它衡量的是"查全能力",越高越好。
当置信度逐渐升高时,只有高置信度的预测被保留,导致许多低置信度但真实的正样本被过滤掉,因此召回率会随着阈值上升而下降
2、图中内容解读
图中展示了 3 个类别(fire、smoke 和 all classes)在不同置信度阈值下的召回率变化曲线:
- fire(蓝色虚线)------ 火焰检测
- 曲线起始点接近 0.95,说明在极低置信度下(如 0.0),火的召回率非常高;
- 随着置信度提升,召回率缓慢下降,在置信度 ≈ 0.8 时仍保持在 0.4 左右;
- 表明火焰检测具有较强的查全能力,即使在较低置信度下也能检出大多数真实火源;
- 下降趋势平缓,说明模型对火的检测鲁棒性强,不易漏检。
结论:火焰检测的召回性能优异,适合用于需要高检出率的场景。
smoke(橙色实线)------ 烟雾检测
- 起始点约为 0.8,略低于 fire;
- 随着置信度上升,召回率快速下降,在置信度 > 0.6 后显著衰减;
- 说明烟雾检测在高置信度下漏检严重,可能是因为弱烟雾或模糊背景难以被模型识别;
- 整体曲线位于 fire 下方,表明其查全能力较弱。
结论:烟雾检测存在明显漏检问题,尤其在高置信度下,需优化小目标或低对比度样本的训练策略。
all classes(深蓝色粗线)------ 所有类别平均
- 曲线整体呈平滑下降趋势;
- 最大召回率为 0.87,出现在置信度 0.000(即无任何阈值限制);
- 这意味着:当不设置置信度阈值时,模型能检出约 87% 的真实目标;
- 随着阈值提高,召回率迅速下降,反映出模型在严格筛选下牺牲了检出能力。
说明:all classes 曲线是综合查全能力的体现,反映整体漏检情况。
3、最佳阈值选择
图中标注 all classes 0.87 at 0.000 表示:
- 当置信度阈值设置为 0.000(即不进行过滤)时,所有类别的平均召回率达到 0.87;
- 此时模型输出所有预测框,检出能力最强,但包含大量误报(FP);
- 因此该点仅作为理论最大召回参考,实际应用中不可直接使用。
建议:
- 若应用场景要求尽可能少漏检(如火灾预警系统),可将阈值设为 0.1~0.3 区间,以维持较高召回率;
- 若更关注减少误报,则需提高阈值至 0.5 以上,但会牺牲部分召回率;
- 推荐结合 Precision-Confidence Curve 一起分析,寻找精度与召回之间的最佳平衡点。
4、总结:
| 类别 | 召回率表现 | 关键问题 | 应用建议 |
|---|---|---|---|
| fire | 高,下降平缓 | --- | 推荐使用 0.1~0.4 阈值,兼顾检出与精度 |
| smoke | 中等,下降快 | 漏检严重,高阈值下性能差 | 增加弱烟雾样本训练,提升小目标检测能力 |
| all classes | 最大召回 0.87(在 0.000) | 高阈值下漏检剧增 | 根据业务需求权衡阈值 |
一句话总结:
这张图告诉我们:火焰检测几乎不漏检,烟雾检测易漏检;若追求"不漏检",可设阈值为 0.1~0.3,但需接受一定误报风险。
2.6.5.5、精确率-召回率曲线(BoxPR_curve.png)
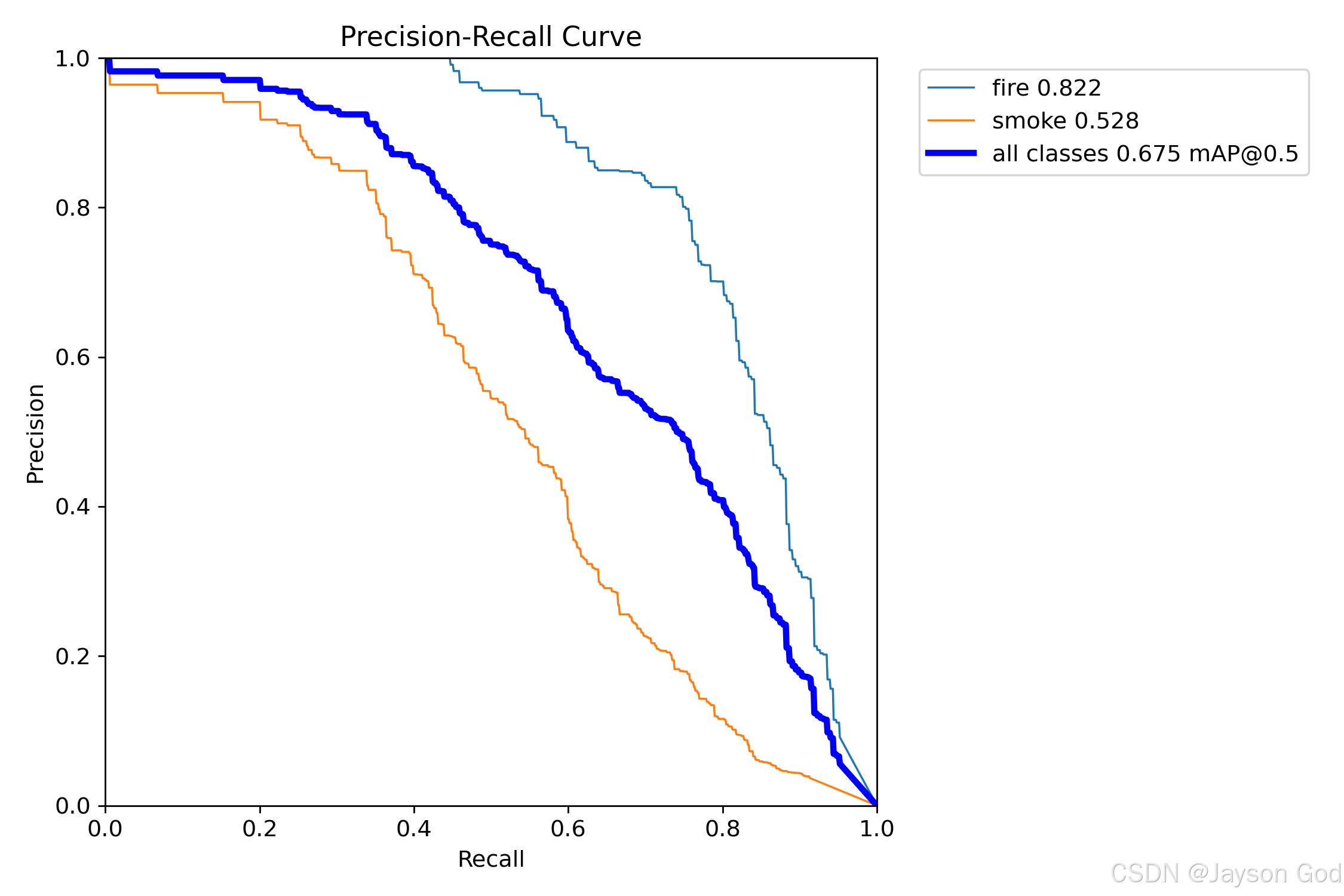
1、什么是 Precision-Recall 曲线?
Precision-Recall 曲线反映了模型在不同召回率(Recall)水平下的精确率(Precision)表现,纵轴为精确率,横轴为召回率,每一条曲线代表一个类别的性能。
曲线越靠近右上角越好,表示在高召回的同时保持高精度。
2、图中内容解读
图中展示了 3 个类别(fire、smoke 和 all classes)的 Precision-Recall 曲线:
fire(蓝色虚线)------ 火焰检测
-
曲线起始点接近 (0, 1.0),说明在极低召回率下也能维持极高精确率;
-
随着召回率上升,精确率缓慢下降,在召回率达到 0.8 时仍保持在 0.7 以上;
-
整体位于上方且平缓,表明:
-
模型对火的判断非常可靠,误报极少;
-
即使为了提高检出率而降低阈值,也不会引入大量假阳性;
-
最终 AUC(曲线下面积)为 0.822,反映其综合性能优秀。
结论:火焰检测具有高精度与强鲁棒性,适合用于高安全性场景。
-
smoke(橙色实线)------ 烟雾检测
-
曲线起始点约为 (0, 0.95),但随着召回率提升,精确率迅速下降;
-
在召回率 > 0.4 后,精确率快速跌至 0.5 以下;
-
表明:
-
初始阶段漏检少,但一旦放宽阈值,就会出现大量误报;
-
模型难以区分烟雾与背景或干扰物(如蒸汽、尘埃);
-
最终 AUC 为 0.528,显著低于 fire,说明整体检测能力较弱。
结论:烟雾检测存在严重误报问题,尤其在高召回需求下,需优化特征提取或数据增强策略。
all classes(深蓝色粗线)------ 所有类别平均
- 是 fire 和 smoke 的加权平均曲线;
- 曲线整体呈下降趋势,但比 smoke 更平缓;
- 最终 mAP@0.5(平均精度)为 0.675,即该模型在 IoU ≥ 0.5 条件下的平均精度为 67.5%;
- 反映了整个模型在多类别任务中的综合性能。
说明:mAP 是目标检测中最核心的评价指标之一,越高越好。
3、最佳阈值选择
图中标注:
- fire 0.822:fire 类别的 PR 曲线 AUC 为 0.822;
- smoke 0.528:smoke 类别的 PR 曲线 AUC 为 0.528;
- all classes 0.675 mAP@0.5:所有类别的平均精度为 0.675。
这些数值直接对应于模型的最终评估结果,可用于横向对比不同模型或训练策略。
2.6.5.6、F1-置信度曲线(BoxF1_curve.png)
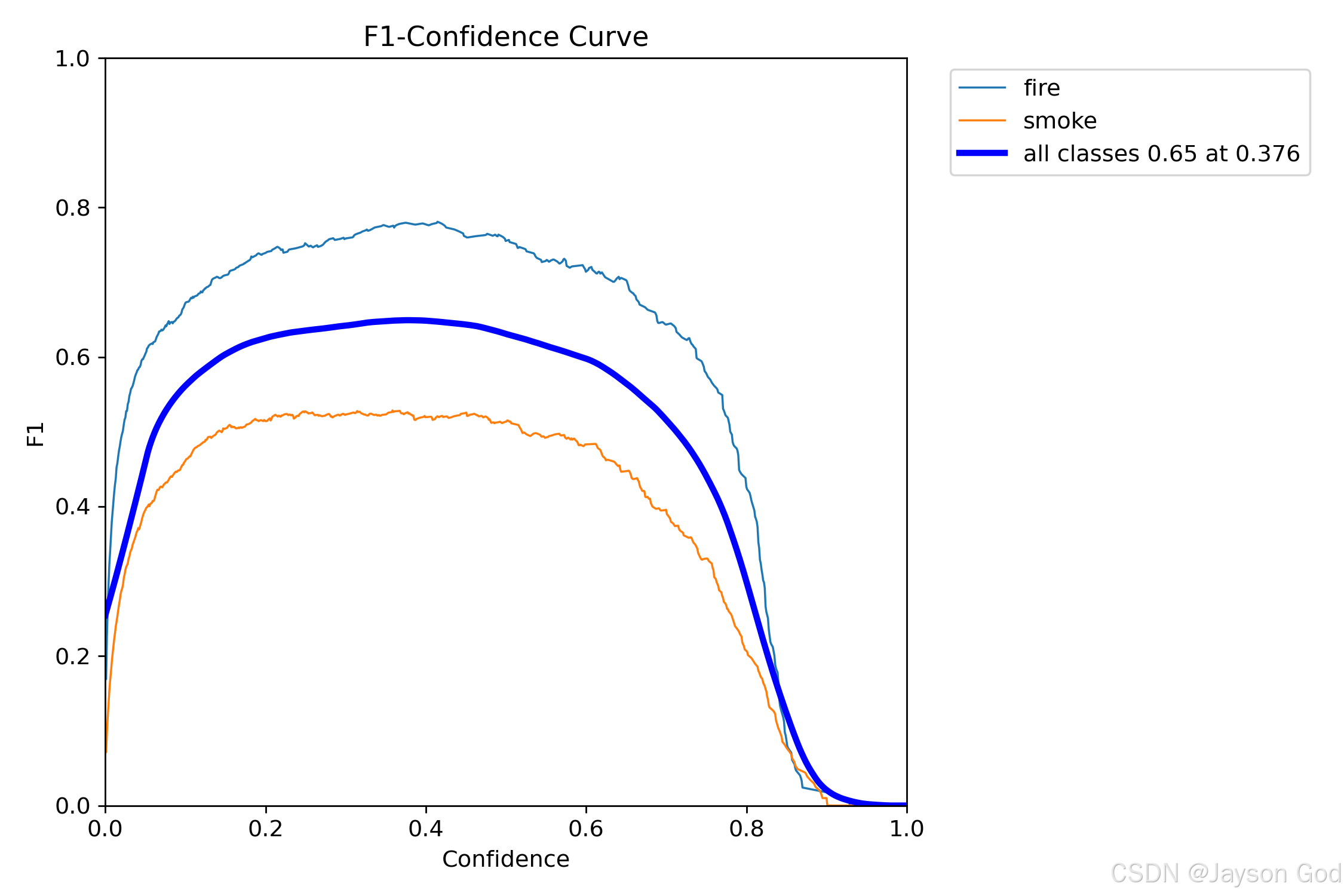
1、什么是 F1 曲线?
F1 曲线反映了模型在不同置信度阈值(Confidence)下的预测表现,纵轴为 F1 分数,横轴为置信度阈值,每一条曲线代表一个类别的表现。
F1 分数 是精确率(Precision)和召回率(Recall)的调和平均值:
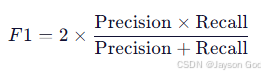
2、图中内容解读
图中展示了 3 个类别(fire、smoke 和 all classes)在不同置信度阈值下的 F1 分数曲线:
fire(蓝色虚线)------ 火焰检测
- 峰值约在 0.4~0.5 区间,F1 ≈ 0.78
- 在较低置信度下表现良好,说明火焰特征明显,容易识别
- 当置信度 > 0.8 后迅速下降 → 高阈值下漏检严重
结论:火的检测效果好,建议使用 0.4 左右的置信度阈值
smoke(橙色实线)------ 烟雾检测
- 峰值在 0.3~0.4 区间,F1 ≈ 0.52
- 整体低于 fire,说明烟雾更难检测(可能因模糊、背景干扰)
- 上升缓慢,且在高置信度下快速衰减
结论:烟雾检测能力较弱,需优化数据增强或模型结构
all classes(深蓝色粗线)------ 所有类别平均
- 最大 F1 = 0.65,出现在置信度 0.376
- 是整个模型综合性能的体现
3、最佳阈值选择
图中标注 all classes 0.65 at 0.376 表示:
- 当置信度阈值设置为 0.376 时,所有类别的平均 F1 分数达到了 0.65;
- 该点可作为当前模型的最佳置信度阈值参考,能在精确率与召回率之间实现良好平衡。
2.6.5.7、数据分布可视化图(labels.jpg)
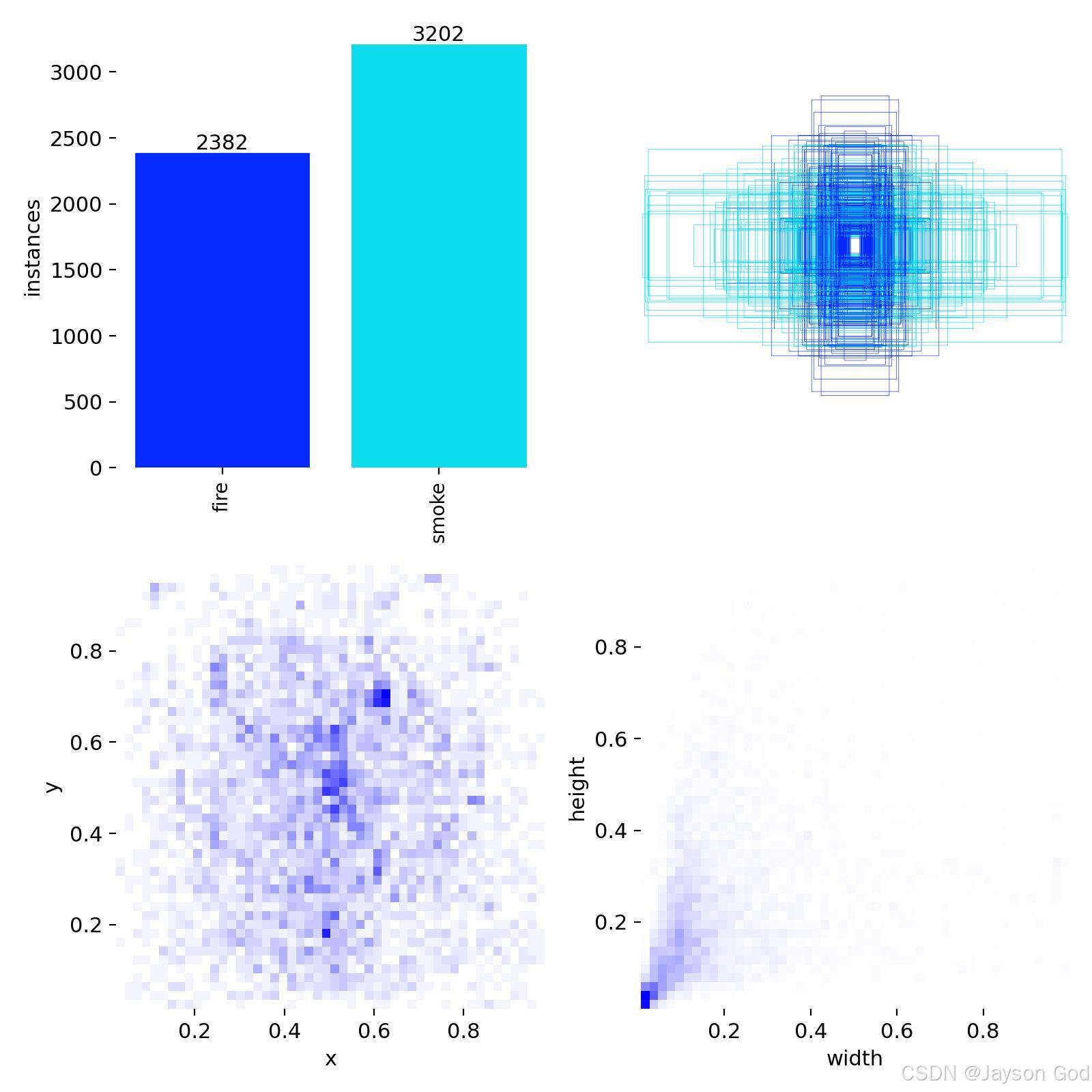
1、图片整体结构
该图分为 4 个子图,分别从不同角度展示数据集的统计特征:
左上角:类别数量分布(柱状图)
右上角:边界框尺寸分布(箱形图 / 密度图)
左下角:目标中心点位置分布(x, y)
右下角:目标宽高比分布(width, height)
a、左上角:类别数量分布(每个类别的实例数)
fire: 2382
smoke: 3202表示在训练集中:
- 真实标注的"火"类目标有 2382 个实例
- "烟"类目标有 3202 个实例
- 烟雾样本数量多于火焰,说明数据集中烟雾更常见或标注更多。
- 若后续模型表现偏差(如对火识别差),可能与类别不平衡有关。
建议:若火的检测效果较差,可考虑对 fire 类进行过采样或使用类别权重调整损失函数。
b、右上角:边界框尺寸分布(Bounding Box Size Distribution)
- 显示了所有目标框的宽度和高度分布;
- 使用轮廓线(contour lines) 表示密度,颜色越深、线条越密 → 密度越高;
- 中心区域密集 → 大多数目标集中在某个尺寸范围;
可观察到:
- 目标以中等大小为主(例如 width ~ 0.2~0.6,height ~ 0.3~0.7);
- 小目标(<0.1)和大目标(>0.8)较少;
- 分布呈椭圆状,说明宽高比例相对稳定。
说明:大多数烟火目标为中等尺度,适合当前网络结构(如 YOLOv5/v8 的中层特征提取)。
提示:如果小目标很多但检测差,可考虑:
- 使用 FPN 或 PANet 结构增强小目标特征;
- 调整锚框(anchor boxes)以适应小目标;
- 数据增强(如随机裁剪、缩放)。
c、左下角:目标中心点位置分布(Center Coordinates: x, y)
- 横轴 x:目标中心点的水平坐标(归一化到 0,1)
- 纵轴 y:目标中心点的垂直坐标(归一化到 0,1)
- 点的密度表示该区域出现目标的频率
观察发现:
- 中心点主要分布在图像中部偏上区域(x ≈ 0.4~0.7, y ≈ 0.4~0.8);
- 边缘区域(如角落)目标稀疏;
- 整体呈现非均匀分布,说明烟火多出现在画面中央区域。
注意:如果模型在边缘漏检严重,可能是因为训练数据中边缘目标少,导致泛化能力弱。
建议:
- 在数据增强时加入随机平移/旋转,提升边缘检测能力;
- 或在测试时对图像边缘做重点扫描。
d、右下角:目标宽高比分布(Width vs Height)
- 横轴 width:目标框宽度(归一化)
- 纵轴 height:目标框高度(归一化)
- 点的分布反映目标的形状特征
观察发现:
- 大部分点集中在左下角(width < 0.2, height < 0.2)→ 表明多数目标较小且接近正方形;
- 存在少量较长条形目标(如 width > 0.5, height < 0.3)→ 可能是长条状烟雾;
- 整体趋势:宽度大于高度,即横向延伸较多。
说明:烟火目标多为短小、近似方形或横向拉伸的矩形,符合真实场景(火焰呈圆形/椭圆,烟雾呈上升带状)。
建议:
- 设计锚框时应包含多种宽高比(如 1:1, 2:1, 3:1);
- 若烟雾太细长,可考虑增加"窄高"锚框。
2、总结:如何看懂这张图?
| 子图 | 用途 | 关键信息 |
|---|---|---|
| 左上 | 类别平衡 | smoke > fire,需注意类别不均衡 |
| 右上 | 尺寸分布 | 多数目标为中等尺寸,小目标较少 |
| 左下 | 位置分布 | 目标集中在图像中部偏上,边缘稀疏 |
| 右下 | 形状分布 | 多为小矩形,部分呈横向拉伸 |
3、实际应用建议
| 问题 | 对策 |
|---|---|
| 火焰检测差 | 增加 fire 样本,或使用类别权重 |
| 小目标漏检 | 优化锚框设计,增强浅层特征 |
| 边缘漏检 | 加强数据增强,模拟边缘场景 |
| 烟雾误报 | 分析背景干扰,改进负样本处理 |
一句话总结:
这张图告诉我们:烟雾样本更多、目标多集中在画面中央、尺寸中等且偏向横向,模型应重点关注这些分布特征,优化锚框与数据增强策略。
2.6.5.8、训练结果指标(results.png)
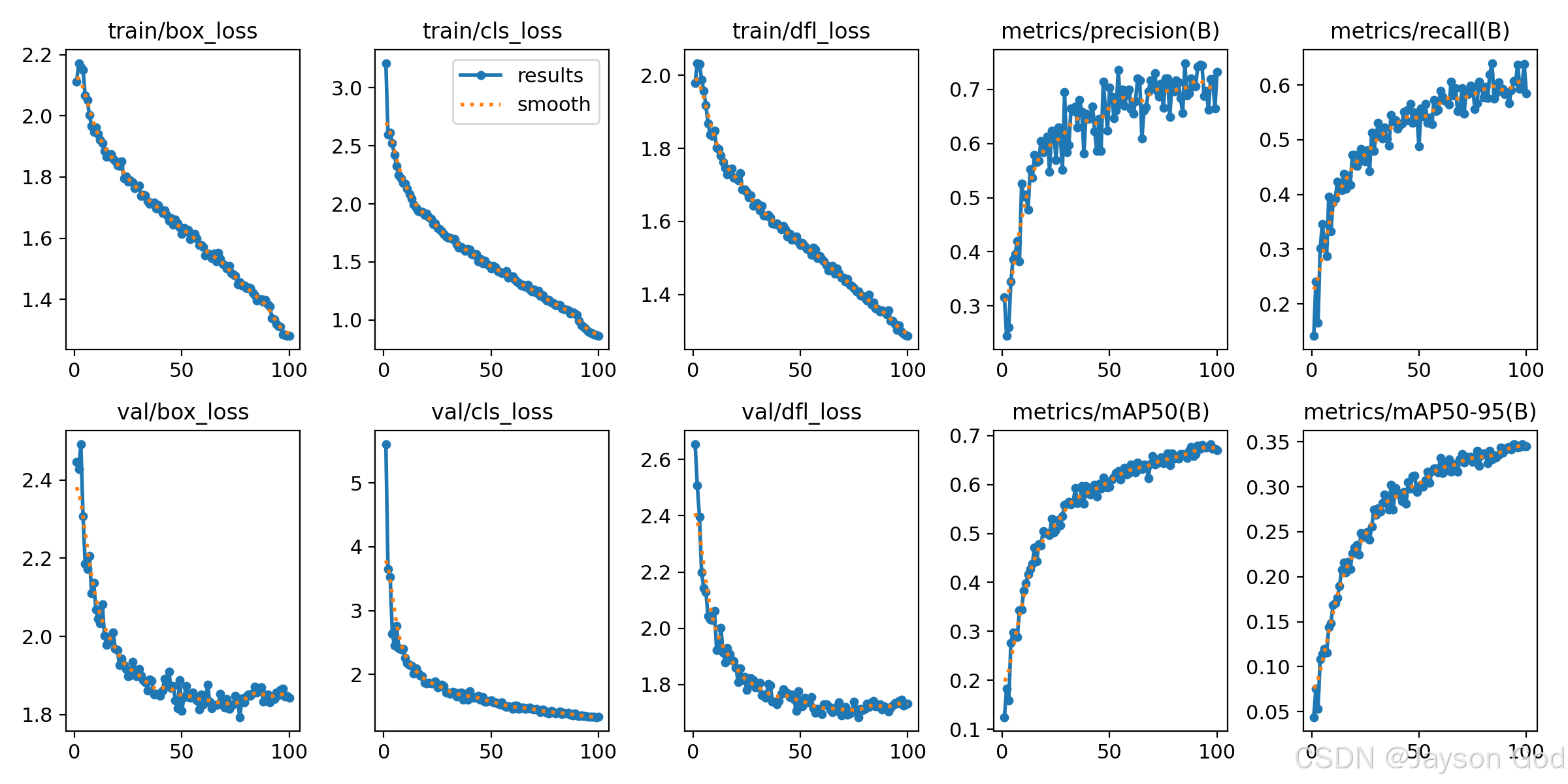
1、图片整体说明
results.png 是 YOLO 模型在训练过程中自动生成的性能监控图,共包含 10 个子图,分为三类:
- 训练损失(3个):模型在训练集上的"学习代价"
- 验证损失(3个):模型在验证集上的"泛化代价"
- 验证指标(4个):模型在验证集上的"实际表现"
所有损失和指标均基于 整个数据集(fire + smoke) 计算,不单独区分类别(除 mAP 外)。
2、训练损失(上排)
a. train/box_loss ------ 定位不准的代价
- 定义:衡量预测边界框与真实边界框之间几何差异的损失。YOLO 支持多种 IoU-based 损失(如 GIoU、DIoU、CIoU),此处以 CIoU 为例。
- 符号说明:

- 公式:
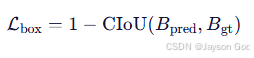
其中 CIoU 在 IoU 基础上增加中心点距离和宽高比惩罚项,使回归更稳定。
- 例子:
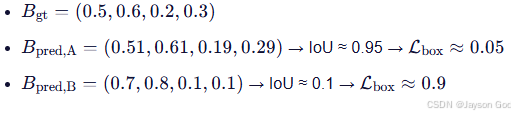
b. train/cls_loss ------ 分类错误的代价
- 定义:使用 二元交叉熵损失(BCE),因 YOLO 将多类别检测视为多标签分类问题。
- 公式(对单个样本、单个类别):
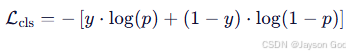

- 总 cls_loss:对所有正样本的所有类别求平均。
- 例子(真实为 fire,即 y=1):
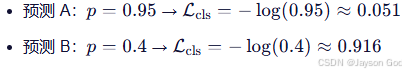
c. train/dfl_loss ------ 边界框坐标估计粗糙的代价
- 定义:YOLOv8 引入的 Distribution Focal Loss(DFL),将每个坐标建模为离散概率分布。
- 公式(简化):
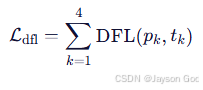

- 作用:提升定位精度,尤其对小目标(如远处烟雾)有效。
3、验证损失(下排左侧)
| 子图 | 含义 | 正常现象 |
|---|---|---|
val/box_loss |
验证集定位误差 | 略高于 train loss(如 1.8 > 1.3) |
val/cls_loss |
验证集分类误差 | 初期高,后下降 |
val/dfl_loss |
验证集坐标分布误差 | 与 train 同步下降 |
若 val loss 上升而 train loss 下降 → 过拟合!
4、验证指标(右侧)
a. metrics/precision(B) ------ 预测结果有多可靠?
- 公式(micro-average):
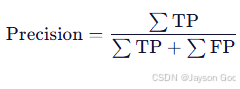
- TP(True Positive):正确检出的目标;
- FP(False Positive):误报(如把云、蒸汽、灯光当成烟火)。
- 例子:
在一次验证集中,模型共输出 120 个预测框,其中:
- 85 个 与真实烟火框 IoU ≥ 0.5 → TP = 85
- 35 个 无对应真实目标(如将远处白墙反光误判为 smoke)→ FP = 35
- 则:
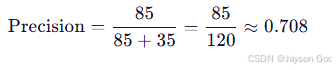
b. metrics/recall(B) ------ 真实目标有多少被找出来了?
- 公式:
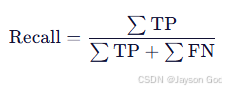
- FN(False Negative):漏检的真实目标。
- 例子:
验证集中共有 100 个真实标注目标(60 个 fire + 40 个 smoke),模型:
- 成功检出 62 个(TP = 62)
- 漏检了 38 个(如微弱烟雾未被发现)→ FN = 38
- 则:
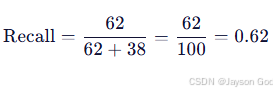
c. metrics/mAP50(B) ------ mAP@0.5
- 公式:
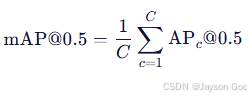
- C=2(fire, smoke)
- 示例计算:
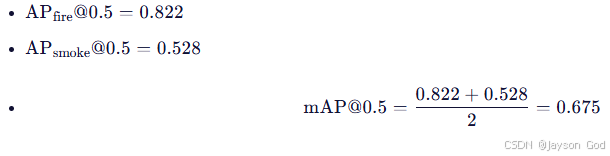
d. metrics/mAP50-95(B) ------ mAP@0.5:0.95
- 公式:
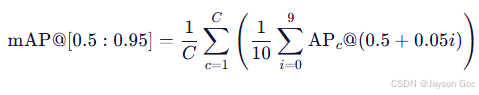
- 意义:反映模型在高精度定位下的鲁棒性。
5、一张表看懂 results.png
| 子图 | 类型 | 计算范围 | 是否区分类别 | 实际含义 | 好的表现 | 性能等级划分 |
|---|---|---|---|---|---|---|
train/box_loss |
损失 | 所有训练样本 | ❌ 否 | 定位不准的平均代价 | 持续下降 | • 优秀 :< 0.8 • 良好 :0.8--1.2 • 一般 :1.2--1.8 • 较差 :1.8--2.5 • 差:> 2.5 |
train/cls_loss |
损失 | 所有训练样本 | ❌ 否 | 分类错误的平均代价 | 快速下降 | • 优秀 :< 0.5 • 良好 :0.5--1.0 • 一般 :1.0--1.8 • 较差 :1.8--3.0 • 差:> 3.0 |
train/dfl_loss |
损失 | 所有训练样本 | ❌ 否 | 坐标估计粗糙的代价 | 平稳下降 | • 优秀 :< 0.8 • 良好 :0.8--1.2 • 一般 :1.2--1.6 • 较差 :1.6--2.0 • 差:> 2.0 |
val/box_loss |
损失 | 所有验证样本 | ❌ 否 | 泛化定位误差 | 接近 train loss | 同 train/box_loss(允许略高 0.2~0.4) |
val/cls_loss |
损失 | 所有验证样本 | ❌ 否 | 泛化分类误差 | < 2.0 且稳定 | 同 train/cls_loss |
val/dfl_loss |
损失 | 所有验证样本 | ❌ 否 | 泛化坐标误差 | 与 train 同步 | 同 train/dfl_loss |
precision |
指标 | 所有验证样本 | ❌ 否 | 整体查准率 | 越高越好 | • 优秀 :≥ 0.85 • 良好 :0.75--0.84 • 一般 :0.60--0.74 • 较差 :0.40--0.59 • 差:< 0.40 |
recall |
指标 | 所有验证样本 | ❌ 否 | 整体查全率 | 越高越好 | • 优秀 :≥ 0.80 • 良好 :0.70--0.79 • 一般 :0.55--0.69 • 较差 :0.35--0.54 • 差:< 0.35 |
mAP@0.5 |
指标 | 每类 AP 平均 | ✅ 是 | 中等 IoU 下综合能力 | ≥ 0.7 | • 顶尖 :≥ 0.85 • 优秀 :0.75--0.84 • 良好 :0.65--0.74 • 可用 :0.50--0.64 • 较差 :0.30--0.49 • 差:< 0.30 |
mAP@[0.5:0.95] |
指标 | 每类 AP@0.5:0.95 平均 | ✅ 是 | 严苛 IoU 下鲁棒性 | ≥ 0.4 | • 顶尖 :≥ 0.50 • 优秀 :0.40--0.49 • 良好 :0.30--0.39 • 一般 :0.20--0.29 • 较差 :0.10--0.19 • 差:< 0.10 |
总结:这张图用数学语言讲述了一个 AI 模型如何从"画不准、认不清"成长为"精准识别烟火"的全过程
2.6.5.9、详细数据表格(results.csv)
每个 epoch 的训练/验证指标记录,表现内容如下。
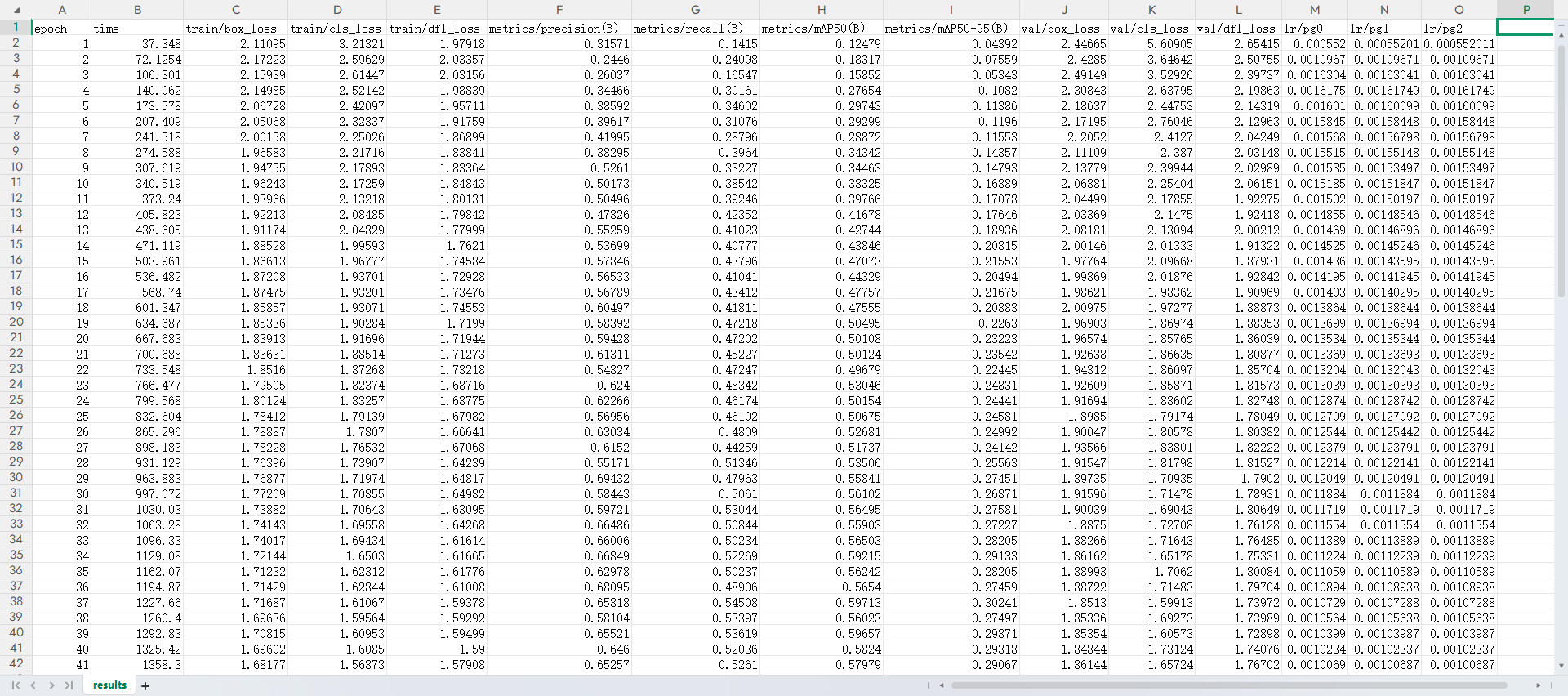
每个字段的解析
| 字段名 | 中文名称 | 含义解释 | 典型良好范围 & 判断标准 |
|---|---|---|---|
| epoch | 训练轮次 | 当前已完成的训练轮数 | 结合 loss/mAP 是否收敛判断是否足够 |
| time | 耗时 | 完成当前 epoch 所用时间 | 仅用于效率评估,不影响模型质量 |
| train/box_loss | 训练集边界框损失 | 预测框与真实框的位置误差 | ✅ 良好 : • YOLOv8s/v8m:0.5 ~ 1.2 • 若 >2.0 → 定位严重不准 • 若 <0.3 → 可能过拟合或数据简单 |
| train/cls_loss | 训练集分类损失 | 类别预测误差(BCE loss) | ✅ 良好 : • 多分类(>3类):0.3 ~ 1.0 • 二分类:0.1 ~ 0.5 • 若 >2.0 → 分类混乱或标签错误 |
| train/dfl_loss | 训练集分布焦点损失 | 边界框坐标的细粒度回归损失 | ✅ 良好 : • 0.8 ~ 1.5 (YOLOv8+) • 通常略高于 box_loss • 若 >2.0 → 回归头未收敛 |
| metrics/precision(B) | 验证集精确率 | 检出结果中有多少是对的 | ✅ 优秀 :>0.85 ✅ 良好 :0.7~0.85 ⚠️ 较差:<0.6 → 误检严重 |
| metrics/recall(B) | 验证集召回率 | 真实目标中有多少被检出 | ✅ 优秀 :>0.8 ✅ 良好 :0.65~0.8 ⚠️ 较差:<0.5 → 漏检严重 |
| metrics/mAP50(B) | mAP@IoU=0.5 | IoU=0.5 下的平均精度 | ✅ 优秀 :>0.85 ✅ 良好 :0.7~0.85 ⚠️ 一般 :0.5~0.7 ❌ 差:<0.5(除非数据极难) |
| metrics/mAP50-95(B) | mAP@0.5:0.95 | 多 IoU 阈值下的平均 mAP(COCO 标准) | ✅ 优秀 :>0.6(COCO 上 YOLOv8m 约 0.50~0.53) ✅ 良好 :0.4~0.6 ⚠️ 一般 :0.25~0.4 ❌ 差:<0.25(需检查数据或训练) |
| val/box_loss | 验证集边界框损失 | 验证集上的定位误差 | ✅ 应略高于 train/box_loss(如高 0.1~0.3) ❌ 若远高于(如 +1.0)→ 过拟合或验证集分布不同 |
| val/cls_loss | 验证集分类损失 | 验证集上的分类误差 | ✅ 应与 train/cls_loss 接近 ❌ 若显著更高 → 泛化能力差 |
| val/dfl_loss | 验证集分布焦点损失 | 验证集上的 DFL 误差 | ✅ 良好范围:0.9 ~ 1.7 ❌ 若 >2.0 且 train/dfl_loss 正常 → 过拟合 |
| lr/pg0 | 学习率(权重) | 卷积权重当前学习率 | 初始通常 0.01(SGD)或 0.001(AdamW),末期降至 0.0001 左右;应平滑衰减 |
| lr/pg1 | 学习率(偏置) | 偏置参数当前学习率 | 通常为 pg0 的 2 倍(如初始 0.02);趋势应与 pg0 一致 |
| lr/pg2 | 学习率(BN 参数) | BN 层参数当前学习率 | 通常等于 pg0;用于确认调度器正常工作 |
关键训练结果分析:
训练参数调整建议:
| 参数 | 当前值(默认/推测) | 建议新值 | 调整理由 |
|---|---|---|---|
epochs |
100 | 150 | mAP 尚未充分收敛,延长训练有助于提升召回率和定位精度。 |
box |
7.5 | 10.0 | 验证集边界框损失过高(≈1.84),提高权重以强化定位学习。 |
cls |
0.5 | 1.0 | 分类损失偏高且烟火类别易混淆,需增强分类判别能力。 |
dfl |
1.5 | 2.0 | 提升边界框坐标的精细度,直接改善 mAP50-95。 |
lr0 |
0.01 | 0.005 | 损失下降缓慢,适当降低初始学习率使优化更稳定。 |
lrf |
0.01 | 0.001 | 降低最终学习率,利于训练末期精细收敛。 |
close_mosaic |
10 | 0 | 保持 Mosaic 增强到最后一轮,持续帮助小目标学习。 |
hsv_h |
0.015 | 0.02 | 增强色调扰动,更好区分火焰(红/橙)与干扰光源(如车灯、夕阳)。 |
degrees |
0.0 | 10.0 | 引入 ±10° 随机旋转,模拟实际监控视角变化,提升鲁棒性。 |
translate |
0.1 | 0.2 | 增大平移比例,减少模型对图像中心区域的依赖。 |
scale |
0.5 | 0.7 | 扩大尺度变化范围(0.3× ~ 1.7×),增强对不同大小烟火的适应能力。 |
batch |
16 | -1 | 自动选择最大安全 batch size,充分利用 GPU 显存而不溢出。 |
2.6.5.10、三类可视化图像
- train_batch*.jpg



训练批次可视化图,展示当前训练 batch 中的原始输入图像及其对应的真实标注(ground truth labels)。
文件名中的 * 是数字(如 train_batch0.jpg, train_batch1.jpg),通常只在训练开始时生成前几个 batch 的图像。
图像内容:
- 每张图包含一个 batch(如 16 张)的小图拼接(无论 batch_size 是多少(包括 -1),train_batch*.jpg 和 val_batch*.jpg 都只生成 1 张拼图(即 1 个文件),且这张图最多显示 16 张小图);
- 每张小图上用彩色框(如红色=fire,蓝色=smoke)标出真实目标的位置和类别;
- 无模型预测结果,仅显示"标准答案"。
生成时机:
仅在 训练开始时(epoch 0) 自动生成一次,用于快速检查:
- 数据加载是否正常;
- 标注是否正确(有无错标、漏标、坐标偏移);
- 数据增强(如 Mosaic、HSV 调整)是否生效。
作用:
- 调试数据管道:确认图像和标签对齐;
- 验证标注质量:发现标注错误可及时修正;
- 确认增强效果:查看 Mosaic、旋转、裁剪等是否合理。
注意:训练过程中不会持续生成此图,仅用于初始化验证。
- val_batch*_labels.jpg



验证批次的真实标签图,展示验证集中某 batch 的图像及其真实标注。
通常与 val_batch*_pred.jpg 成对出现(如 val_batch0_labels.jpg 和 val_batch0_pred.jpg)。
图像内容:
- 同样是 batch 图像拼接;
- 每张图上绘制真实边界框和类别标签(如 "fire", "smoke");
- 颜色通常按类别固定(便于区分)。
生成时机:
- 在每个验证周期(validation epoch)结束时生成;
- 默认只保存最后一个验证 batch 的 labels 和 preds 图。
作用:
- 提供"标准答案"作为对比基准;
- 与预测图并排查看,直观判断模型哪里检错了、漏了或误报了。
- val_batch*_pred.jpg



验证批次的模型预测图,展示同一 batch 图像上模型的预测结果。
与 val_batch*_labels.jpg 使用完全相同的输入图像,便于逐图对比。
图像内容:
- 每张小图上绘制模型输出的预测框;
- 框上标注:类别名 + 置信度分数(如 "smoke 0.87");
- 通常只显示置信度高于某个阈值(如 0.25)的预测。
生成时机:
与 val_batch*_labels.jpg 同步生成,每个验证周期一次。
作用:
- 直观评估模型性能:
- 是否漏检(recall 低)?→ 看 labels 有框但 pred 无;
- 是否误报(precision 低)?→ 看 pred 有框但 labels 无;
- 定位是否准确?→ 对比框位置是否重合;
- 分类是否正确?→ 看类别标签是否匹配。
- 辅助调参:调整置信度阈值、NMS IoU 阈值后,可观察预测图变化。
4、三者关系总结
| 图像类型 | 内容 | 用途 | 是否含预测 | 是否含真实标签 |
|---|---|---|---|---|
train_batch*.jpg |
训练 batch + 真实标签 | 调试数据加载与增强 | ❌ 否 | ✅ 是 |
val_batch*_labels.jpg |
验证 batch + 真实标签 | 作为"标准答案"参考 | ❌ 否 | ✅ 是 |
val_batch*_pred.jpg |
验证 batch + 模型预测 | 评估模型实际表现 | ✅ 是 | ❌ 否 |
最佳实践:将 val_batch0_labels.jpg 和 val_batch0_pred.jpg 并排打开,逐图对比,是快速诊断模型问题的最有效方式之一
2.6.5.11、weights 文件夹
训练 YOLO 模型时,系统会自动保存两个权重文件:
对比表格
| 文件 | 用途 | 是否推荐部署 | 是否适合继续训练 |
|---|---|---|---|
best.pt |
验证效果最好的模型 | ✅ 是 | ❌ 否 |
last.pt |
训练最后保存的模型 | ⚠️ 可能过拟合,不优先推荐 | ✅ 是 |
三、验证
Ultralytics 提供了两种命令python与CLI,本文使用python,详细文档请看
使用 Ultralytics YOLO 进行模型验证 - Ultralytics YOLO 文档
3.1、无参数验证
验证训练好的模型 准确性 在数据集上。无需任何参数,因为 model 保留其训练 data 并将参数作为模型属性。
python
from ultralytics import YOLO
# 加载模型
model = YOLO("path/to/best.pt") # 加载自定义模型
# 验证模型
metrics = model.val() # 无需参数,数据集和设置已记住
metrics.box.map # mAP50-95(平均精度均值,IoU阈值从0.5到0.95)
metrics.box.map50 # mAP50(IoU阈值为0.5时的平均精度)
metrics.box.map75 # mAP75(IoU阈值为0.75时的平均精度)
metrics.box.maps # 包含每个类别的mAP50-95的列表3.2、自定义参数验证
在验证 YOLO 模型时,可以微调多个参数以优化评估过程。这些参数控制着输入图像大小、批量处理和性能阈值等方面。
python
from ultralytics import YOLO
# 加载模型
model = YOLO("path/to/best.pt") # 加载官方预训练模型
# 自定义验证设置
metrics = model.val(
data="data.yaml", # 数据集配置文件路径
imgsz=640, # 输入图像尺寸,统一调整为640x640像素
batch=16, # 批次大小,每次处理16张图像
conf=0.25, # 检测置信度阈值,较低值可检测更多目标
iou=0.6, # 非极大值抑制的IoU阈值
device="0" # 指定使用GPU设备0进行验证
)3.3、模型验证的常用参数
最常用的 3 个自定义验证参数
| 参数 | 默认值 | 作用 | 什么时候需要改? |
|---|---|---|---|
data |
训练时用的 data.yaml |
指定验证使用的数据集 | ✅ 必须显式指定 如果: • 想在新数据集 上测试泛化能力 • 想只验证某个子集(如只测 smoke 类别) |
imgsz |
训练时的 imgsz(如 640) |
输入图像尺寸 | ✅ 常改 如果: • 部署时用更高分辨率(如 1280) • 测试模型对不同尺度的鲁棒性 |
conf |
0.001(内部计算 mAP 用低阈值) |
置信度阈值(影响 Precision/Recall/F1) | ✅ 调试时必调 如果: • 想看实际部署效果(通常设为 0.25~0.5) • 绘制 PR 曲线或找最佳 F1 阈值 |
较少改动的参数(一般用默认)
| 参数 | 默认值 | 说明 | |
|---|---|---|---|
batch |
自动(如 16) | 只影响验证速度,不影响结果;显存不足时可调小(如 8) | |
iou |
0.6(NMS 阈值) |
对 mAP 影响极小,除非特殊需求(如密集目标),否则不用改 | |
device |
'cpu' 或自动检测 GPU |
仅指定运行设备,不影响评估逻辑 | |
half |
False |
是否用 FP16 加速,不影响精度(现代 GPU 可开) |
详细参数查看官网:
使用 Ultralytics YOLO 进行模型验证 - Ultralytics YOLO 文档
3.4、验证实例(烟火)
3.4.1、验证代码
python
from ultralytics import YOLO
import torch
if __name__ == "__main__":
# 加载预训练模型
model_path = "runs/train/train_fire/weights/best.pt" # 模型权重文件路径
model = YOLO(model_path) # 创建YOLO模型实例
# 验证配置参数
data_path = 'D:/datasets/FireSmoke/data.yaml' # 数据集配置文件路径
project = "runs/val" # 验证结果保存的项目目录
name = "val_fire" # 验证任务名称
# 执行模型验证
results = model.val(
data=data_path, # 数据集配置文件路径
batch=16, # 批次大小,每次处理16张图像
imgsz=640, # 输入图像尺寸,统一调整为640x640像素
device=0 if torch.cuda.is_available() else 'cpu', # 自动选择GPU(0)或CPU进行计算
workers=8, # 数据加载线程数,提高数据读取效率
project=project, # 验证结果保存的项目路径
name=name, # 验证任务的名称
save_json=True, # 保存验证结果为JSON格式
save_hybrid=False, # 不保存混合格式标签
conf=0.001, # 检测置信度阈值,较低值可检测更多目标
iou=0.6, # 非极大值抑制的IoU阈值
max_det=300, # 每张图像最多检测目标数量
half=False, # 不使用半精度浮点数进行推理
dnn=False, # 不使用OpenCV DNN加速推理
plots=True, # 生成验证结果图表
exist_ok=False # 不覆盖已存在的项目目录
)
print("模型验证完成!")
# 输出验证指标
print(f"mAP50: {results.box.map50}") # 输出IoU阈值为0.5时的平均精度
print(f"mAP50-95: {results.box.map}") # 输出IoU阈值0.5-0.95的平均精度
print(f"精确率: {results.box.p}") # 输出整体精确率
print(f"召回率: {results.box.r}") # 输出整体召回率3.4.2、开始验证
结果分析:
3.4.2.1、环境与模型信息
html
Ultralytics 8.3.241 Python-3.11.9 torch-2.5.1+cu121 CUDA:0 (NVIDIA GeForce RTX 4060, 8188MiB)
YOLO11s summary (fused): 100 layers, 9,413,574 parameters, 0 gradients- Ultralytics 8.3.241:使用的 YOLO 库版本。
- Python / PyTorch / CUDA:运行环境。
- GPU:NVIDIA RTX 4060,显存 8GB。
模型结构:
- 名称:YOLO11s;
- 层数:100 层;
- 参数量:约 941 万(轻量级模型,适合边缘部署);
- gradients:验证阶段不计算梯度,正常。
3.4.2.2、数据加载性能
html
val: Fast image access (ping: 0.30.1 ms, read: 4.62.2 MB/s, size: 33.7 KB)- 表示图像读取速度很快,无 I/O 瓶颈。
- 平均每张图 33.7 KB,读取速度 4.6 MB/s。
3.4.2.3、验证集扫描结果
html
val: Scanning D:\datasets\FireSmoke\valid\labels.cache... 285 images, 0 backgrounds, 0 corrupt: 100% ━━━━━━━━━━━━ 285/285 0.0s- images:验证集共 285 张图像;
- backgrounds:没有纯背景图(即每张图至少有一个目标);
- corrupt:无损坏图像;
- 使用缓存文件 labels.cache 加速加载。
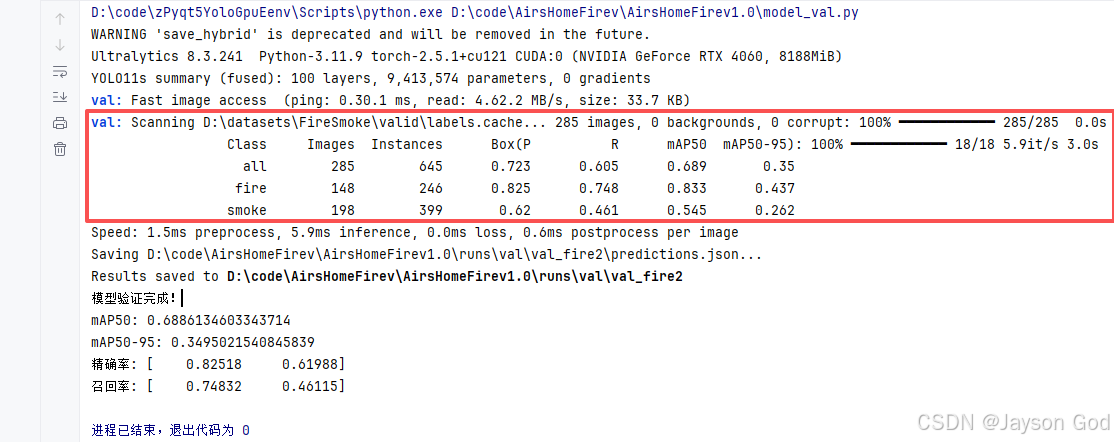
3.4.2.4、核心评估指标(重点!)
html
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 18/18 5.9it/s 3.0s
all 285 645 0.723 0.605 0.689 0.35
fire 148 246 0.825 0.748 0.833 0.437
smoke 198 399 0.62 0.461 0.545 0.262字段解释:
| 列名 | 含义 |
|---|---|
| Class | 类别名称(all = 所有类别的综合) |
| Images | 该类别出现的图像数量(注意:一张图可含多个类别) |
| Instances | 该类别的真实目标总数 |
| Box(P) | Precision(查准率):预测为正例中真正正确的比例 |
| R | Recall(查全率):所有真实目标中被成功检出的比例 |
| mAP50 | IoU=0.5 时的平均精度(常用指标) |
| mAP50-95 | IoU 从 0.5 到 0.95(步长 0.05)的平均 mAP,衡量高精度定位能力 |
具体分析:
整体(all):
- Precision = 72.3% → 每 100 个预测框,约 72 个是正确的;
- Recall = 60.5% → 所有真实烟火目标中,只找回了 60.5%;
- mAP@0.5 = 68.9% → 中等水平,属于"良好"等级(参考前文标准);
- mAP@0.5:0.95 = 35.0% → 定位精度一般,高 IoU 下表现较弱。
fire(火焰):
- 表现优秀:mAP@0.5 = 83.3%,Precision 82.5%,Recall 74.8%;
- 说明模型对明显、高对比度的火焰识别能力强。
smoke(烟雾):
- 明显弱于 fire:mAP@0.5 = 54.5%,Recall 仅 46.1%;
- 主要短板:烟雾透明、边界模糊,导致漏检严重(Recall 低);
- 这也是拉低整体 mAP 的主因。
3.4.2.5、推理速度(关键部署指标)
html
Speed: 1.5ms preprocess, 5.9ms inference, 0.0ms loss, 0.6ms postprocess per image- Preprocess(预处理):1.5 ms(图像缩放、归一化等);
- Inference(推理):5.9 ms(模型前向计算);
- Postprocess(后处理):0.6 ms(NMS、阈值过滤等);
- 总计 ≈ 8.0 ms/图 → 约 125 FPS(在 RTX 4060 上);
3.4.2.6、结果保存路径
html
Saving D:\code\AirsHomeFirev\AirsHomeFirev1.0\runs\val\val_fire2\predictions.json...
Results saved to D:\code\AirsHomeFirev\AirsHomeFirev1.0\runs\val\val_fire- 所有预测结果(含坐标、类别、置信度)已保存为 predictions.json;
- 完整验证报告(包括图表、指标、可视化图)存放在:runs/val/val_fire/
3.4.2.7、验证结果文件作用简要说明
注意:以下文件与训练过程中生成的结果文件含义完全相同(如 PR 曲线、混淆矩阵等),仅数据来源为验证集而非训练集;训练阶段的详细说明已在前文给出。
| 文件名 | 作用说明 |
|---|---|
BoxF1_curve.png |
展示 F1 分数随置信度阈值变化 的曲线。帮助找到使 F1 最大的最佳置信度(如 0.42),用于部署时平衡 Precision 和 Recall。 |
BoxPR_curve.png |
Precision-Recall 曲线,反映模型在不同置信度下的查准率与查全率权衡。曲线下面积越大,模型越好。 |
BoxP_curve.png |
Precision 随置信度变化曲线:置信度越高,Precision 越高(误报少),但可能漏检更多。 |
BoxR_curve.png |
Recall 随置信度变化曲线:置信度越低,Recall 越高(漏检少),但误报增多。 |
confusion_matrix.png |
混淆矩阵(原始计数):显示每个类别的预测结果 vs 真实标签,可看出 fire/smoke 是否被错分或漏检。 |
confusion_matrix_normalized.png |
归一化混淆矩阵:每行按真实类别归一化(0~1),便于比较各类别错误比例(如 smoke 有 30% 被判为背景)。 |
predictions.json |
所有验证图像的完整预测结果(含坐标、类别、置信度),可用于后续分析、可视化或提交评测。 |
val_batch0_labels.jpg val_batch1_labels.jpg val_batch2_labels.jpg |
验证集中前几个 batch 的真实标注图,展示"标准答案"------目标在哪、是什么类别。 |
val_batch0_pred.jpg val_batch1_pred.jpg val_batch2_pred.jpg |
对应 batch 的模型预测图,展示模型"看到什么"------框的位置、类别和置信度。 |
四、预测
4.1、返回类型
Ultralytics YOLO 模型返回一个 Python 对象列表 Results 对象或内存高效的生成器 Results 当 stream=True 在推理期间传递给模型时:
返回一个列表stream=False
python
from ultralytics import YOLO
# 加载模型
model = YOLO("path/to/best.pt") # 加载练的模型
# 对图像列表进行批量推理
results = model(["image1.jpg", "image2.jpg"]) # 返回Results对象的列表
# 处理结果列表
for result in results:
boxes = result.boxes # 边界框对象,用于边界框输出
masks = result.masks # 分割掩码对象,用于分割掩码输出
keypoints = result.keypoints # 关键点对象,用于姿态估计输出
probs = result.probs # 概率对象,用于分类输出
obb = result.obb # 有向边界框对象,用于OBB(定向边界框)输出
result.show() # 在屏幕上显示结果
result.save(filename="result.jpg") # 保存结果到磁盘返回一个生成器stream=True
python
from ultralytics import YOLO
# 加载模型
model = YOLO("path/to/best.pt") # 加载训练的模型
# 对图像列表进行批量推理(流式处理)
results = model(["image1.jpg", "image2.jpg"], stream=True) # 返回Results对象的生成器
# 处理结果生成器
for result in results:
boxes = result.boxes # 边界框对象,用于边界框输出
masks = result.masks # 分割掩码对象,用于分割掩码输出
keypoints = result.keypoints # 关键点对象,用于姿态估计输出
probs = result.probs # 概率对象,用于分类输出
obb = result.obb # 有向边界框对象,用于OBB(定向边界框)输出
result.show() # 在屏幕上显示结果
result.save(filename="result.jpg") # 保存结果到磁盘Results 对象具有以下属性:
| 属性 | 类型 | 描述 |
|---|---|---|
orig_img |
np.ndarray |
原始图像,以 numpy 数组形式呈现。 |
orig_shape |
tuple |
原始图像的形状,格式为(高度,宽度)。 |
boxes |
Boxes, optional |
一个 Boxes 对象,包含检测到的边界框。 |
masks |
Masks, optional |
一个 Masks 对象,包含检测到的掩码。 |
probs |
Probs, optional |
一个 Probs 对象,包含分类任务中每个类别的概率。 |
keypoints |
Keypoints, optional |
一个 Keypoints 对象,包含每个对象检测到的关键点。 |
obb |
OBB, optional |
包含旋转框检测的 OBB 对象。 |
speed |
dict |
一个字典,包含预处理、推理和后处理的速度,单位为毫秒/图像。 |
names |
dict |
一个将类索引映射到类名称的字典。 |
path |
str |
图像文件的路径。 |
save_dir |
str, optional |
用于保存结果的目录。 |
边界框
以下是 Boxes 类的方法和属性表,包括它们的名称、类型和描述:
| 名称 | 类型 | 描述 |
|---|---|---|
cpu() |
方法 | 将对象移动到 CPU 内存。 |
numpy() |
方法 | 将对象转换为 numpy 数组。 |
cuda() |
方法 | 将对象移动到 CUDA 内存。 |
to() |
方法 | 将对象移动到指定的设备。 |
xyxy |
属性 (torch.Tensor) |
返回 xyxy 格式边界框。 |
conf |
属性 (torch.Tensor) |
返回边界框的置信度值。 |
cls |
属性 (torch.Tensor) |
返回边界框的类别值。 |
id |
属性 (torch.Tensor) |
返回边界框的跟踪 ID(如果可用)。 |
xywh |
属性 (torch.Tensor) |
返回 xywh 格式边界框。 |
xyxyn |
属性 (torch.Tensor) |
返回按原始图像尺寸归一化的 xyxy 格式边界框。 |
xywhn |
属性 (torch.Tensor) |
返回按原始图像尺寸归一化的 xywh 格式边界框。 |
掩码
masks 类的方法和属性 参考官网
关键点
Keypoints 类的方法和属性 参考官网
OBB
OBB 类的方法和属性 参考官网
使用 Ultralytics YOLO 进行模型预测 - Ultralytics YOLO 文档
Results 对象具有以下方法:
| 方法 | 返回类型 | 描述 |
|---|---|---|
update() |
None |
使用新的检测数据(边界框、掩码、概率、obb、关键点)更新 Results 对象。 |
cpu() |
Results |
返回 Results 对象的副本,其中所有 tensor 都已移动到 CPU 内存。 |
numpy() |
Results |
返回 Results 对象的副本,其中所有 tensor 都已转换为 numpy 数组。 |
cuda() |
Results |
返回 Results 对象的副本,其中所有 tensor 都已移动到 GPU 内存。 |
to() |
Results |
返回 Results 对象的副本,其中 tensor 已移动到指定的设备和数据类型。 |
new() |
Results |
创建一个新的 Results 对象,该对象具有相同的图像、路径、名称和速度属性。 |
plot() |
np.ndarray |
在输入的 RGB 图像上绘制检测结果,并返回带注释的图像。 |
show() |
None |
显示带有注释的推理结果的图像。 |
save() |
str |
将带注释的推理结果图像保存到文件并返回文件名。 |
verbose() |
str |
返回每个任务的日志字符串,详细说明检测和分类结果。 |
save_txt() |
str |
将检测结果保存到文本文件,并返回保存文件的路径。 |
save_crop() |
None |
将裁剪的检测图像保存到指定目录。 |
summary() |
List[Dict[str, Any]] |
将推理结果转换为汇总字典,可以选择进行归一化。 |
to_df() |
DataFrame |
将检测结果转换为 Polars DataFrame。 |
to_csv() |
str |
将检测结果转换为 CSV 格式。 |
to_json() |
str |
将检测结果转换为 JSON 格式。 |
plot() 方法参数
| 参数 | 类型 | 描述 | 默认值 |
|---|---|---|---|
conf |
bool |
包括检测置信度分数。 | True |
line_width |
float |
边界框的线条宽度。如果图像大小为,则缩放 None. |
None |
font_size |
float |
文本字体大小。如果图像大小为,则缩放 None. |
None |
font |
str |
文本注释的字体名称。 | 'Arial.ttf' |
pil |
bool |
将图像作为 PIL 图像对象返回。 | False |
img |
np.ndarray |
用于绘制图像的替代图像。如果未提供,则使用原始图像。 None. |
None |
im_gpu |
torch.Tensor |
用于更快进行掩码绘制的 GPU 加速图像。形状:(1, 3, 640, 640)。 | None |
kpt_radius |
int |
绘制的关键点半径。 | 5 |
kpt_line |
bool |
用线条连接关键点。 | True |
labels |
bool |
在注释中包含类别标签。 | True |
boxes |
bool |
在图像上叠加边界框。 | True |
masks |
bool |
在图像上叠加掩码。 | True |
probs |
bool |
包含分类概率。 | True |
show |
bool |
使用默认图像查看器直接显示带注释的图像。 | False |
save |
bool |
将带注释的图像保存到指定的文件中。 filename. |
False |
filename |
str |
如果指定了 ,则为保存带注释图像的文件的路径和名称。 save 是 True. |
None |
color_mode |
str |
指定颜色模式,例如"instance"或"class"。 | 'class' |
txt_color |
tuple[int, int, int] |
用于边界框和图像分类标签的 RGB 文本颜色。 | (255, 255, 255) |
4.2、推理来源
| 来源 | 示例 | 类型 | 备注 |
|---|---|---|---|
| 图像 | 'image.jpg' |
str 或 Path |
单个图像文件。 |
| URL | 'https://ultralytics.com/images/bus.jpg' |
str |
图像的URL。 |
| 截图 | 'screen' |
str |
截取屏幕截图。 |
| PIL | Image.open('image.jpg') |
PIL.Image |
具有RGB通道的HWC格式。 |
| OpenCV | cv2.imread('image.jpg') |
np.ndarray |
具有BGR通道的HWC格式 uint8 (0-255). |
| numpy | np.zeros((640,1280,3)) |
np.ndarray |
具有BGR通道的HWC格式 uint8 (0-255). |
| torch | torch.zeros(16,3,320,640) |
torch.Tensor |
具有RGB通道的BCHW格式 float32 (0.0-1.0). |
| CSV | 'sources.csv' |
str 或 Path |
包含图像、视频或目录路径的CSV文件。 |
| 视频 ✅ | 'video.mp4' |
str 或 Path |
MP4、AVI等格式的视频文件。 |
| 目录 ✅ | 'path/' |
str 或 Path |
包含图像或视频的目录的路径。 |
| glob ✅ | 'path/*.jpg' |
str |
用于匹配多个文件的Glob模式。使用 * 字符作为通配符。 |
| YouTube ✅ | 'https://youtu.be/LNwODJXcvt4' |
str |
YouTube视频的URL。 |
| 流 ✅ | 'rtsp://example.com/media.mp4' |
str |
用于流媒体协议的URL,例如RTSP、RTMP、TCP或IP地址。 |
| 多流 ✅ | 'list.streams' |
str 或 Path |
*.streams 文本文件,每行包含一个流 URL,即 8 个流将以批处理大小为 8 运行。 |
| 网络摄像头 ✅ | 0 |
int |
用于运行推理的已连接摄像头设备的索引。 |
示例代码:
python
from ultralytics import YOLO
# 加载练的模型
model = YOLO("path/to/best.pt")
# 定义图像文件路径
source = "path/to/image.jpg"
# 定义远程图像或视频URL
source = "https://ultralytics.com/images/bus.jpg"
# 摄像头ID
source=0
# RTSP、RTMP、TCP或IP流地址
source = "rtsp://example.com/media.mp4"
# 在源图像上运行推理
results = model(source) # Results对象的列表4.3、推理参数
python
from ultralytics import YOLO
model = YOLO("path/to/best.pt")
model.predict("https://ultralytics.com/images/bus.jpg", save=True, imgsz=320, conf=0.5)常用参数:
| 参数 | 类型 | 默认值 | 描述 |
|---|---|---|---|
source |
str / Path / int |
必填(无默认) | 推理输入源:图像路径、视频文件、文件夹、摄像头ID(如 0)或 RTSP 流地址。 |
imgsz |
int / list |
640 |
输入图像尺寸(高和宽会被统一缩放为该值,需为 32 的倍数)。 |
conf |
float |
0.25 |
置信度阈值:低于此值的预测框将被过滤,值越低检出越多(但误报增加)。 |
iou |
float |
0.7 |
NMS(非极大值抑制)的 IoU 阈值:用于合并重叠框。值越大,保留的框越多;值越小,保留的框越少。 |
device |
str |
自动检测 | 运行设备:'cpu'、'0'(GPU 0)、'0,1'(多 GPU)等。 |
show |
bool |
False |
是否实时显示带预测框的图像(适用于本地测试)。 |
save |
bool |
True |
是否保存推理结果(图像/视频)到磁盘。 |
save_txt |
bool |
False |
是否将预测结果以 YOLO 格式(归一化坐标)保存为 .txt 文件。 |
save_conf |
bool |
False |
保存 .txt 时是否包含置信度分数(需配合 save_txt=True)。 |
classes |
list[int] |
None |
只检测指定类别(如 [0] 表示只检测 fire),其余类别忽略。 |
max_det |
int |
300 |
单张图像最多检测的目标数量,防止密集场景输出过多框。 |
vid_stride |
int |
1 |
视频推理时的帧采样步长(1=每帧,2=隔一帧),加快处理速度。 |
stream |
bool |
False |
是否启用流式推理(适用于大视频或摄像头,节省内存)。 |
详细参数:
使用 Ultralytics YOLO 进行模型预测 - Ultralytics YOLO 文档
4.4、预测实例(烟火)
4.4.1、推理代码
python
from ultralytics import YOLO
import torch
if __name__ == "__main__":
model_path = "runs/train/train_fire/weights/best.pt" # 定义模型权重文件路径
model = YOLO(model_path) # 实例化YOLO模型对象
project="runs/detect" # 训练结果保存的项目目录
name = "predict_fire" # 训练任务名称
source_path = "D:/datasets/FireSmoke/test/images" # 定义推理图像源路径
#source_path = "D:/datasets/FireSmoke/test/images/fire_smoke__00537.jpg" # 定义推理图像源路径
# 执行模型推理
results = model.predict(
source=source_path, # 推理源路径
project=project, # 推理结果保存的项目目录
name=name, # 推理任务名称
save=True, # 保存推理结果图像
save_frames=True, # 保存视频帧(如果是视频输入)
save_txt=False, # 保存检测结果为txt格式
imgsz=640, # 推理图像尺寸
conf=0.25, # 检测置信度阈值
iou=0.7, # 非极大值抑制IOU阈值
half=True if torch.cuda.is_available() else False, # 使用半精度推理(GPU可用时)
device=0 if torch.cuda.is_available() else 'cpu', # 指定推理设备(GPU或CPU)
batch=1 # 批次大小
)
# 遍历推理结果并打印检测信息
for i, r in enumerate(results):
# 打印当前处理的图片文件名
if hasattr(r.orig_img, 'filename'):
print(f"图片文件: {r.orig_img.filename}")
elif hasattr(r, 'path'):
print(f"图片路径: {r.path}")
else:
print(f"图片索引: {i}")
print(f"检测到 {len(r.boxes)} 个目标") # 打印检测到的目标数量
# 如果存在检测框,则打印详细信息
if r.boxes is not None and len(r.boxes) > 0:
for j, box in enumerate(r.boxes):
# 获取边界框坐标 [x1, y1, x2, y2]
xyxy = box.xyxy[0].cpu().numpy()
# 获取置信度
conf = box.conf.item()
# 获取类别ID
cls_id = int(box.cls.item())
print(f" 目标 {j + 1}:")
print(f" 坐标: [{xyxy[0]:.2f}, {xyxy[1]:.2f}, {xyxy[2]:.2f}, {xyxy[3]:.2f}]")
print(f" 置信度: {conf:.3f}")
print(f" 类别ID: {cls_id}")
# 如果有掩码信息也打印出来
if r.masks is not None:
print(f" 掩码数量: {len(r.masks)}")
# 如果有关键点信息也打印出来
if r.keypoints is not None:
print(f" 关键点数量: {len(r.keypoints)}")
else:
print(" 未检测到任何目标")
print("-" * 50) # 分隔线,便于区分不同图片的结果4.4.2、开始推理
image 类型
1/142 当前第几个/总数
D:\datasets\FireSmoke\test\images\fire_smoke__00012.jpg: 图片路径
640x640 图片分辨率
1 fire, 预测到1个火
1 smoke, 预测到一个1烟
10.1ms 推理耗时
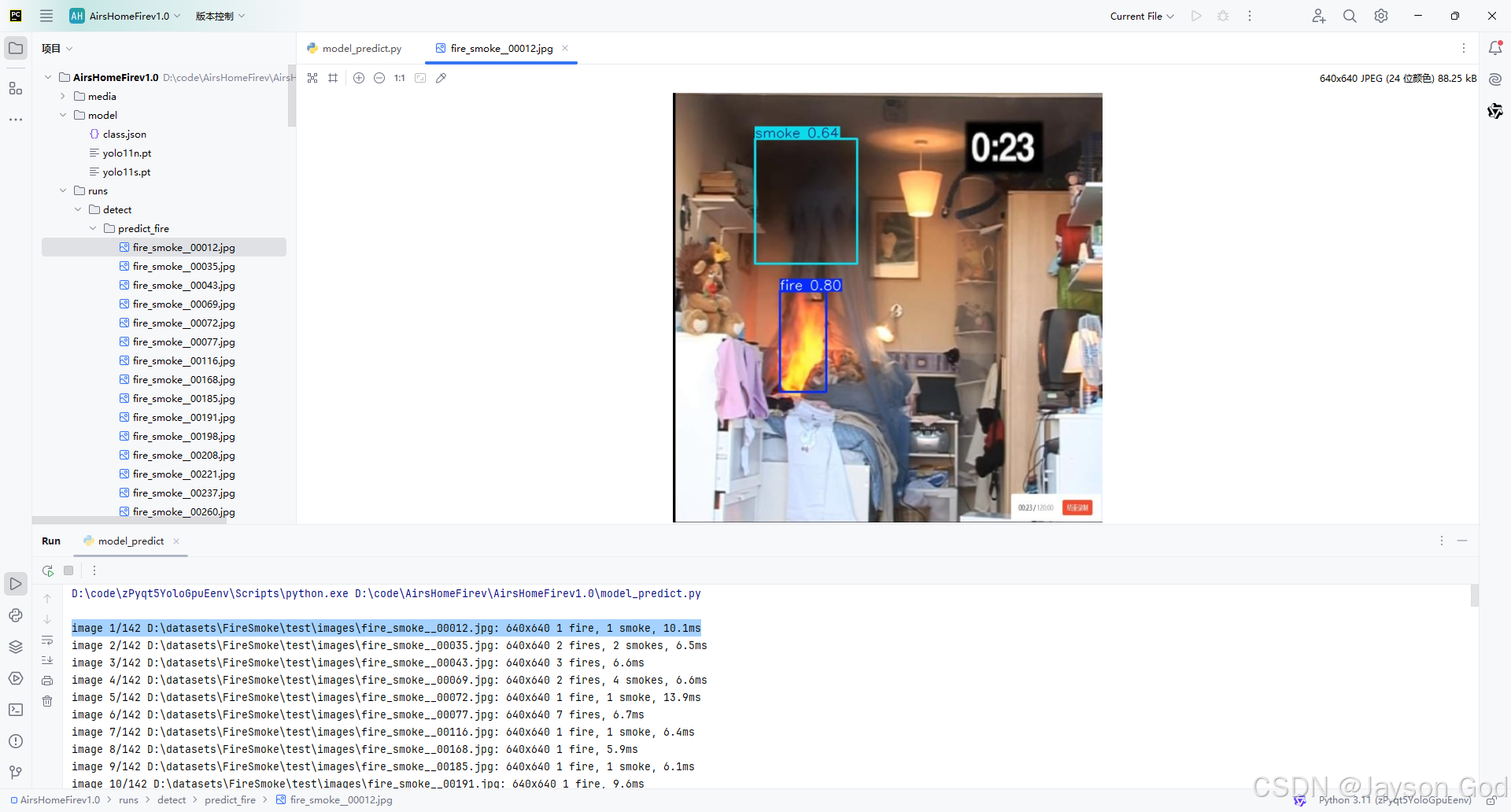
4.4.3、推理结果
五、导出
导出的模型经过优化,可加快推理时间
5.1、导出示例
python
from ultralytics import YOLO
# 加载模型
model = YOLO("path/to/best.pt") # 加载自定义训练模型
# 导出模型
model.export(format="onnx") # 将模型导出为ONNX格式5.2、常用的参数
| 参数 | 类型 | 默认值 | 描述 |
|---|---|---|---|
format |
str |
'torchscript' |
导出格式,常用:'onnx', 'engine' (TensorRT), 'openvino', 'coreml', 'tflite', 'pb' (TensorFlow), 'torchscript' |
imgsz |
int / list |
640 |
输入图像尺寸(必须与训练时一致或兼容,如 [640, 640]) |
batch |
int |
1 |
导出模型的 batch size(-1 表示动态 batch,仅部分格式支持) |
half |
bool |
False |
是否使用 FP16(半精度)导出,可减小模型体积、提升推理速度(需硬件支持) |
int8 |
bool |
False |
是否启用 INT8 量化(仅 TensorRT 等格式支持),大幅加速但有精度损失 |
device |
str |
'cpu' |
导出时使用的设备('cpu' 或 '0'),不影响导出后模型的运行设备 |
simplify |
bool |
False |
ONNX 专用 :是否对 ONNX 模型进行结构简化(推荐设为 True,提升兼容性) |
opset |
int |
12 |
ONNX 专用 :ONNX 算子集版本(建议 ≥12,YOLOv8 推荐 12 或 17) |
dynamic |
bool |
False |
ONNX/TensorRT 专用:是否启用动态输入尺寸(如动态高/宽/batch) |
workspace |
int |
4 |
TensorRT 专用:最大工作空间大小(GB),影响优化程度 |
nms |
bool |
False |
是否在导出模型中嵌入 NMS 后处理(部分部署平台需要) |
详细参数
使用 Ultralytics YOLO 导出模型 - Ultralytics YOLO 文档
5.3、导出实例(烟火)
5.3.1、导出代码
python
from ultralytics import YOLO
import torch
if __name__ == "__main__":
# 加载训练好的模型
model_path = "runs/train/train_fire/weights/best.pt"
model = YOLO(model_path)
# 导出为 ONNX 格式
onnx_results = model.export(
format="onnx", # 导出格式
imgsz=640, # 图像尺寸
batch=1, # 批次大小
device=0 if torch.cuda.is_available() else 'cpu',
half=True if torch.cuda.is_available() else False, # 是否使用半精度
int8=False, # 是否使用INT8量化
dynamic=False, # 是否使用动态轴
simplify=True, # 是否简化模型
opset=12, # ONNX操作集版本
nms=False, # 是否包含NMS层
)
print(f"ONNX模型导出完成: {onnx_results}")5.3.2、开始导出
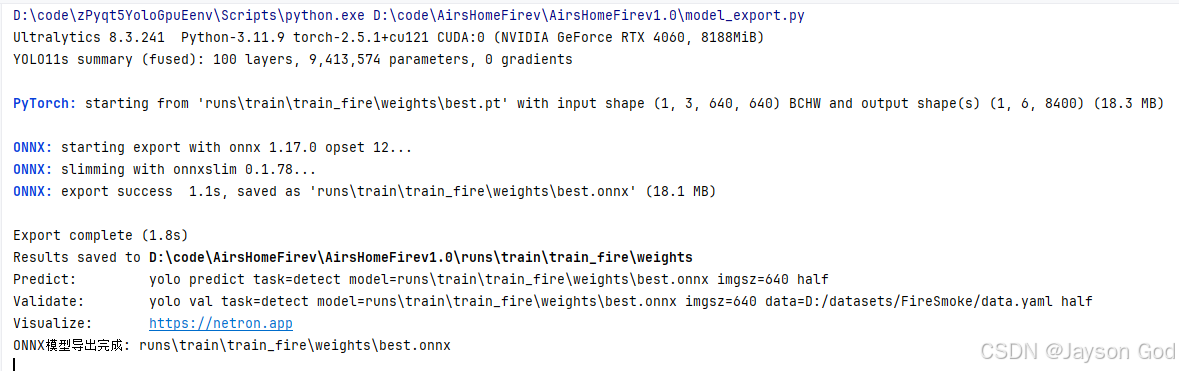
- 环境与硬件信息
python
Ultralytics 8.3.241 Python-3.11.9 torch-2.5.1+cu121 CUDA:0 (NVIDIA GeForce RTX 4060, 8188MiB)-
YOLO 库版本:Ultralytics v8.3.241
-
Python + PyTorch:3.11.9 + 2.5.1(支持 CUDA 12.1)
-
运行设备:GPU(NVIDIA RTX 4060,显存 8GB)
- 模型结构摘要
python
YOLO11s summary (fused): 100 layers, 9,413,574 parameters, 0 gradients-
模型名称:
YOLO11s -
层数:100 层
-
参数量:约 941 万(轻量级,适合实时检测)
-
0 gradients:导出阶段无需反向传播,正常现象。
- 加载原始 PyTorch 模型
python
PyTorch: starting from 'runs\train\train_fire\weights\best.pt' with input shape (1, 3, 640, 640) BCHW and output shape(s) (1, 6, 8400) (18.3 MB)-
源文件:训练得到的最佳权重 best.pt
-
输入张量:(batch=1, channel=3, height=640, width=640) ------ 单张 RGB 图像
-
输出张量:(1, 6, 8400)
-
= x, y, w, h, confidence, class_id
-
= 默认检测点总数(密集预测头)
-
模型大小:18.3 MB(FP32 精度)
- 开始 ONNX 导出
python
ONNX: starting export with onnx 1.17.0 opset 12...-
使用 ONNX 1.17.0 库
-
opset=12:选择兼容性良好的 ONNX 算子集版本(主流推理引擎如 ONNX Runtime、OpenVINO、TensorRT 均支持)
- 模型优化(关键步骤)
python
ONNX: slimming with onnxslim 0.1.78...-
调用
onnxslim工具对模型进行自动图优化:-
删除冗余节点(如恒等操作、未使用输出)
-
合并可融合算子
-
-
目的:提升推理速度、减小体积、增强跨平台兼容性(避免 OpenCV DNN 等报错)
- 导出成功
python
ONNX: export success 1.1s, saved as 'runs\train\train_fire\weights\best.onnx' (18.1 MB)-
耗时:1.1 秒(GPU 加速下非常快)
-
输出文件:
best.onnx -
大小:18.1 MB(略小于
.pt,因 ONNX 存储更紧凑)
- 总结与结果路径
python
Export complete (1.8s)
Results saved to D:\code\AirsHomeFirev\AirsHomeFirev1.0\runs\train\train_fire\weights-
总耗时:1.8 秒(含加载、转换、优化、保存)
-
保存目录:与训练权重同路径,便于管理
- 后续使用命令
python
Predict: yolo predict task=detect model=runs\train\train_fire\weights\best.onnx imgsz=640 half
Validate: yolo val task=detect model=runs\train\train_fire\weights\best.onnx imgsz=640 data=D:/datasets/FireSmoke/data.yaml half
Visualize: https://netron.app-
预测命令:直接用 CLI 推理(支持
half,若部署设备支持 FP16 可加速) -
验证命令:用 ONNX 模型重新跑一遍验证,确认 mAP 无损(应 ≈
.pt模型) -
可视化:用 Netron 在线查看模型结构(输入/输出节点、算子类型等)
- 最终提示
python
ONNX模型导出完成: runs\train\train_fire\weights\best.onnx